IBM Netezza から移行する
このドキュメントは、Netezza から BigQuery への移行方法の全体的なガイダンスを提供します。Netezza と BigQuery の基本的なアーキテクチャの違いと、BigQuery が提供する追加機能について説明します。また、既存のデータモデルと抽出、変換、読み込み(ETL)プロセスを見直し、BigQuery のメリットを最大化する方法についても説明します。
このドキュメントは、Netezza から BigQuery に移行し、移行プロセスの技術的な課題を解決したいと考えているエンタープライズ アーキテクト、DBA、アプリケーション デベロッパー、IT セキュリティ専門家を対象としています。このドキュメントでは、移行プロセスの次のフェーズについて詳しく説明します。
- データのエクスポート
- データの取り込み
- サードパーティ ツールの活用
また、バッチ SQL 変換を使用して複数の SQL スクリプトを一括で移行することも、インタラクティブ SQL 変換を使用してアドホック クエリ変換することもできます。IBM Netezza SQL/NZPLSQL は、プレビューの両方のツールでサポートされています。
アーキテクチャの比較
Netezza は、膨大な量のデータの保存と分析に役立つ強力なシステムです。ただし Netezza のようなシステムでは、ハードウェア、メンテナンス、ライセンスに多額の投資が必要となります。このため、ノード管理の課題、ソースあたりのデータ量、アーカイブのコストが原因で、スケーリングが困難な場合があります。Netezza では、ストレージと処理容量がハードウェア アプライアンスによって制限されます。最大使用率に達すると、アプライアンスの容量拡張プロセスは複雑になり、不可能なこともあります。
BigQuery では、インフラストラクチャを管理する必要がなく、データベース管理者も不要です。BigQuery は、ペタバイト規模のフルマネージド サーバーレス データ ウェアハウスであり、インデックスが設定されていない数十億行のデータを数十秒でスキャンできます。BigQuery は Google のインフラストラクチャを共有しているため、各クエリを並列化し、数万台のサーバー上でクエリを同時に実行できます。BigQuery を差別化するコア テクノロジーは次のとおりです。
- カラム型ストレージ。データが行単位ではなく列単位で保存されるため、高い圧縮率とスキャン スループットを実現できます。
- ツリー アーキテクチャ。クエリがツリー状にディスパッチされ、数千台のマシンで処理された結果がわずか数秒で集約されます。
Netezza アーキテクチャ
Netezza は、ソフトウェア データ抽象化レイヤを備えたハードウェア アクセラレーション アプライアンスです。データ抽象化レイヤは、アプライアンスでのデータ分散を管理し、基盤となる CPU と FPGA 間でデータ処理を分散してクエリを最適化します。
Netezza TwinFin および Striper モデルは、2019 年 6 月にサポートが終了しました。
次の図は、Netezza 内のデータ抽象化レイヤを示しています。
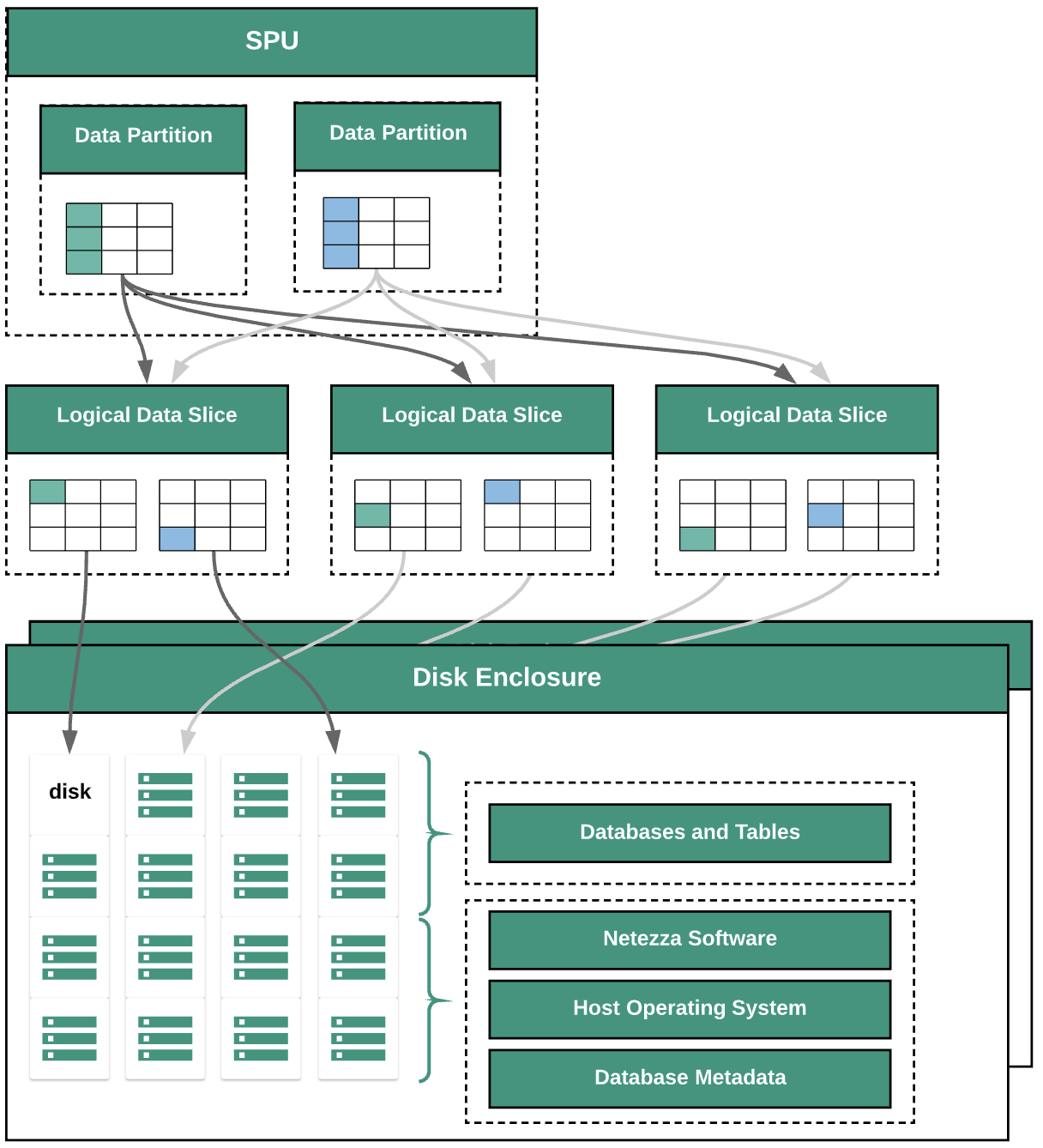
この図は、次のデータ抽象化レイヤを示しています。
- ディスク エンクロージャー。ディスクがマウントされているアプライアンス内の物理スペース。
- ディスク。ディスク エンクロージャー内の物理ディスクにデータベースとテーブルが保存されます。
- データスライス。ディスクに保存されているデータの論理的な表現。データは、分散キーを使用してデータスライス間で分散されます。データスライスのステータスをモニタリングするには、
nzdsコマンドを使用します。 - データ パーティション。特定のスニペット プロセッシング ユニット(SPU)によって管理されるデータスライスの論理的表現。各 SPU は、クエリで SPU が処理を担当するユーザーデータを含んだ 1 つ以上のデータ パーティションを所有します。
すべてのシステム コンポーネントはネットワーク ファブリックによって接続されています。Netezza アプライアンスは、IP アドレスに基づいてカスタマイズされたプロトコルを実行します。
BigQuery アーキテクチャ
BigQuery は、ML、地理空間分析、ビジネス インテリジェンスなどの組み込み機能を使用してデータの管理と分析を支援する、フルマネージドのエンタープライズ データ ウェアハウスです。詳細については、BigQuery とはをご覧ください。
BigQuery はストレージと計算を処理して、分析クエリに対する耐久性の高いデータ ストレージと高パフォーマンスのレスポンスを提供します。詳細については、BigQuery の説明をご覧ください。
BigQuery の料金については、BigQuery の迅速なスケーリングとシンプルな料金についてをご覧ください。
移行前
データ ウェアハウスの移行を確実に成功させるには、プロジェクトのタイムラインの早期段階で移行戦略の計画を始めてください。移行作業を体系的に計画する方法については、移行の対象と方法: 移行フレームワークをご覧ください。
BigQuery のキャパシティ プランニング
BigQuery の分析のスループットはスロット単位で測定されます。BigQuery スロットとは、SQL クエリを実行するために必要なコンピューティング、RAM、ネットワーク スループットに関する Google 独自の単位です。BigQuery では、クエリのサイズと複雑さに応じて、クエリごとに必要なスロットの数が自動的に計算されます。
BigQuery でクエリを実行するには、次のいずれかの料金モデルを選択します。
- オンデマンド。デフォルトの料金モデル。各クエリで処理されたバイト数に対して料金が請求されます。
- 容量ベースの料金。スロット(仮想 CPU)を購入します。スロットを購入すると、クエリの実行に使用できる専用の処理容量を購入したことになります。スロットは次のコミットメント プランで使用できます。
- 年間。365 日間の利用を確約します。
- 3 年。365 × 3 日間の利用を確約します。
BigQuery スロットには、CPU、メモリ、データの処理など、Netezza の SPU との共通点がありますが、同じ測定単位を表すものではありません。Netezza SPU には、基盤となるハードウェア コンポーネントへの固定マッピングがありますが、BigQuery スロットは、クエリの実行に使用される仮想 CPU です。スロットの見積もりを行う場合は、Cloud Monitoring を使用した BigQuery のモニタリングおよび BigQuery を使用した監査ログの分析をセットアップすることをおすすめします。BigQuery スロットの使用率は、Looker Studio や Looker などのツールで可視化することもできます。スロットの使用状況を定期的にモニタリングし、分析することで、組織の成長に合わせて Google Cloudに必要となる合計スロット数を見積もることができます。
たとえば、最初に 2,000 個の BigQuery スロットを予約して、複雑さが中程度の 50 個のクエリを同時に実行すると仮定します。クエリの実行に常に数時間以上かかり、ダッシュボードでスロット使用率が高い場合は、クエリが最適化されていないか、ワークロードをサポートするために追加の BigQuery スロットが必要である可能性があります。年間または 3 年間のコミットメントでスロットを購入するには、 Google Cloud コンソールまたは bq コマンドライン ツールを使用して BigQuery 予約を作成します。容量ベースの購入においてオフライン契約を結んだ場合は、ここに記載するプランとは詳細が異なる場合があります。
BigQuery でストレージとクエリの処理コストの両方を制御する方法については、ワークロードを最適化するをご覧ください。
Google Cloudのセキュリティ
以降のセクションでは、Netezza の一般的なセキュリティ管理と、 Google Cloud 環境でデータ ウェアハウスを保護する方法について説明します。
ID とアクセスの管理
Netezza データベースでは、一連のアクセス制御機能がシステムに完全に組み込まれており、これにより、ユーザーは承認されたリソースにアクセスできます。
ネットワークを介した Netezza アプライアンスへのアクセスは、オペレーティング システムにログインできる Linux ユーザー アカウントを管理することで制御できます。Netezza データベース、オブジェクト、タスクへのアクセスは、システムに対して SQL 接続を確立できる Netezza データベース ユーザー アカウントを使用して管理できます。
BigQuery は、Google の Identity and Access Management(IAM)サービスを使用してリソースへのアクセスを管理します。BigQuery で使用できるリソースは、組織、プロジェクト、データセット、テーブル、ビューです。IAM ポリシー階層では、データセットはプロジェクトの子リソースになります。テーブルに対する権限は、そのテーブルを含むデータセットから継承されます。
リソースへのアクセス権を付与するには、ユーザー、グループ、サービス アカウントに、1 つ以上のロールを割り当てます。組織とプロジェクトのロールでは、ジョブの実行やプロジェクトの管理を行うためのアクセス権が制御され、データセットのロールでは、プロジェクト内のデータを表示または変更するアクセス権が制御されます。
IAM には次のタイプのロールがあります。
- 事前定義ロール。一般的なユースケースとアクセス制御パターンをサポートします。
- 基本ロール。オーナー、編集者、閲覧者のロールがあります。基本ロールは、特定のサービスへのアクセスを細かく制御します。また、 Google Cloudにより管理されます。
- カスタムロール。ユーザー指定の権限のリストに応じたきめ細かなアクセス権が提供されます。
事前定義ロールと基本ロールの両方をユーザーに割り当てると、それぞれのロールの権限を結合した権限が付与されます。
行レベルのセキュリティ
マルチレベル セキュリティは、行セキュリティ テーブル(RST)へのユーザー アクセスを制御するルールを定義するために Netezza が使用する抽象セキュリティ モデルです。行セキュリティ テーブルは、適切な権限のないユーザーを除外するためのセキュリティ ラベルが行に設定されているデータベース テーブルです。クエリで返される結果は、クエリを行ったユーザーが持っている権限に応じて異なります。
BigQuery で行レベルのセキュリティを実現するには、承認済みビューと行レベルのアクセス ポリシーを使用できます。これらのポリシーの設計と実装の方法については、BigQuery の行レベルのセキュリティの概要をご覧ください。
データ暗号化
Netezza アプライアンスは、アプライアンスに保存されたデータを保護してセキュリティを強化するために自己暗号化ドライブ(SED)を使用します。SED では、ディスクに書き込まれる際にデータが暗号化されます。各ディスクには、工場で設定され保存されたディスク暗号鍵(DEK)があります。ディスクは DEK を使用して、データの書き込み時にデータを暗号化し、ディスクからの読み取り時にデータを復号します。ディスクでの処理、および暗号化と復号は、データの読み取りと書き込みを行うユーザーに意識させずに行われます。このデフォルトの暗号化および復号モードは、完全消去モードと呼ばれます。
完全消去モードでは、データを復号して読み取るための認証鍵とパスワードは不要です。SED には、ディスクを別の目的で再利用したりサポートや保証のために返却したりする必要がある場合に、簡単迅速かつ安全にデータを消去できる強化された機能が用意されています。
Netezza では対称暗号化が使用されます。データがフィールド レベルで暗号化されている場合、次の復号関数を使用してデータの読み取りとエクスポートを行うことができます。
varchar = decrypt(varchar text, varchar key [, int algorithm [, varchar IV]]); nvarchar = decrypt(nvarchar text, nvarchar key [, int algorithm[, varchar IV]]);
BigQuery 内に保存されているすべてのデータは、暗号化されています。ユーザー自身で暗号化を制御する場合は、BigQuery の顧客管理の暗号鍵(CMEK)を使用できます。CMEK を使用すると、データを保護する鍵暗号鍵を Google が管理するのではなく、ユーザーが Cloud Key Management Service で制御および管理します。詳細については、保存時の暗号化をご覧ください。
パフォーマンス ベンチマーク
移行プロセス全体を通じて進捗や改善状況を追跡するには、現在の Netezza 環境に関するベースライン パフォーマンスを確立することが重要です。ベースラインを確立するには、使用するアプリケーション(Tableau や Cognos など)からキャプチャされる一連の表現クエリを選択します。
| 環境 | Netezza | BigQuery |
|---|---|---|
| データサイズ | size TB | - |
| クエリ 1: name(テーブル全体のスキャン) | mm:ss.ms | - |
| クエリ 2: name | mm:ss.ms | - |
| クエリ 3: name | mm:ss.ms | - |
| 合計 | mm:ss.ms | - |
基礎となるプロジェクトの設定
データを移行するためのストレージ リソースをプロビジョニングする前に、プロジェクトの設定を完了しておく必要があります。
- プロジェクトを設定し、プロジェクト レベルで IAM を有効にするには、Google Cloud Well-Architected Framework をご覧ください。
- クラウド デプロイメントをエンタープライズ対応にするための基本リソースを設計するには、 Google Cloudでのランディング ゾーンの設計をご覧ください。
- オンプレミスのデータ ウェアハウスを BigQuery に移行する際に必要なデータ ガバナンスと統制については、データ セキュリティとガバナンスの概要をご覧ください。
ネットワーク接続
オンプレミス データセンター(Netezza インスタンスが実行されている場所)と Google Cloud環境の間には、信頼性があり安全なネットワーク接続が必要です。接続を保護する方法については、BigQuery のデータ ガバナンスの概要をご覧ください。抽出データをアップロードする際に、ネットワーク帯域幅が制限要因となることがあります。データ転送の要件を満たす方法については、ネットワーク帯域幅の増強をご覧ください。
サポートされているデータ型とプロパティ
Netezza のデータ型は、BigQuery のデータ型と異なります。BigQuery のデータ型については、データ型をご覧ください。Netezza と BigQuery のデータ型の詳細な比較については、IBM Netezza SQL 変換ガイドをご覧ください。
SQL の比較
Netezza データの SQL は、DDL、DML、Netezza のみのデータ制御言語(DCL)で構成されており、GoogleSQL とは異なります。GoogleSQL には SQL 2011 標準との互換性があり、ネストされ繰り返されたデータのクエリをサポートする拡張機能が含まれています。BigQuery のレガシー SQL を使用している場合は、レガシー SQL 関数と演算子をご覧ください。Netezza と BigQuery の SQL と関数の詳細な比較については、IBM Netezza SQL 変換ガイドをご覧ください。
SQL コードの移行に役立つ情報として、一括 SQL 変換を使用して SQL コードを一括で移行する方法、またはインタラクティブな SQL 変換を使用してアドホック クエリを変換する方法があります。
関数の比較
Netezza の関数がどのように BigQuery の関数にマッピングされるかを理解することが重要です。たとえば、Netezza の Months_Between 関数は小数を出力しますが、BigQuery の DateDiff 関数は整数を出力します。したがって、正しいデータ型を出力するにはカスタム UDF 関数を使用する必要があります。Netezza SQL 関数と GoogleSQL 関数の詳細な比較については、IBM Netezza SQL 変換ガイドをご覧ください。
データの移行
Netezza から BigQuery にデータを移行するには、Netezza からデータをエクスポートし、 Google Cloudへデータを転送してステージングしてから、データを BigQuery に読み込みます。このセクションでは、データ移行プロセスの概要について説明します。データ移行プロセスの詳細については、スキーマとデータの移行プロセスをご覧ください。Netezza と BigQuery でサポートされているデータ型の詳細な比較については、IBM Netezza SQL 変換ガイドをご覧ください。
Netezza からデータをエクスポートする
Netezza データベース テーブルのデータを調べるには、CSV 形式で外部テーブルにエクスポートすることをおすすめします。詳細については、リモート クライアント システムへのデータのアンロードをご覧ください。また、JDBC/ODBC コネクタを使用する Informatica などのサードパーティ システム(またはカスタム ETL)を使用してデータを読み取り、CSV ファイルを生成することもできます。
Netezza では、各テーブルの非圧縮フラット ファイル(CSV)のエクスポートのみがサポートされています。ただし、大きなテーブルをエクスポートする場合は、圧縮されていない CSV のサイズが非常に大きくなる可能性があります。可能であれば、CSV を Parquet、Avro、ORC などのスキーマ対応形式に変換することを検討してください。これにより、エクスポート ファイルが小さくなり、信頼性が高まります。使用できる形式が CSV のみである場合は、 Google Cloudにアップロードする前に、エクスポート ファイルを圧縮してファイルサイズを小さくすることをおすすめします。ファイルサイズを小さくすると、アップロードが速くなり、転送の信頼性が向上します。Cloud Storage にファイルを転送する場合は、gcloud storage cp コマンドで --gzip-local フラグを使用できます。このコマンドは、アップロード前にファイルを圧縮します。
データ転送とステージング
エクスポートされたデータは、Google Cloudに転送してステージングする必要があります。データを転送するには、転送するデータの量と利用可能なネットワーク帯域幅に応じて、いくつかのオプションがあります。詳細については、スキーマとデータ転送の概要をご覧ください。
Google Cloud CLI を使用すると、Cloud Storage へのファイル転送の自動化と並列化を行うことができます。BigQuery に高速に読み込めるように、ファイルサイズは 4 TB(非圧縮)以下にします。ただし、事前にスキーマをエクスポートしておく必要があります。ここで、パーティショニングやクラスタリングを使用して BigQuery を最適化することをおすすめします。
gcloud storage bucket create を使用して、エクスポートされたデータを保存するステージング バケットを作成し、gcloud storage cp を使用して、エクスポートされたデータファイルを Cloud Storage バケットに転送します。
gcloud CLI は、マルチスレッドとマルチ処理を組み合わせてコピー操作を自動的に実行します。
BigQuery へのデータの読み込み
データが Google Cloudにステージングされた後、データを BigQuery に読み込む方法はいくつかあります。詳細については、BigQuery にスキーマとデータを読み込むをご覧ください。
パートナーのツールとサポート
移行の過程でパートナー サポートを利用できます。SQL コードの移行を容易にするために、バッチ SQL 変換を使用して SQL コードを一括で移行する方法があります。
多くの Google Cloud パートナーは、データ ウェアハウス移行サービスも提供しています。パートナーと各パートナーが提供するソリューションの一覧については、BigQuery の専門知識を持つパートナーとの連携をご覧ください。
移行後
データの移行が完了したら、Google Cloud の使用を最適化してビジネスニーズの解決に着手できます。たとえば、Google Cloudの探索および可視化ツールを使用することで、ビジネス関係者に役立つ分析情報を引き出す、パフォーマンスの低いクエリを最適化する、ユーザーの導入を支援するためのプログラムを開発するなどです。
インターネット経由で BigQuery API に接続する
次の図は、外部アプリケーションが API を使用して BigQuery に接続する方法を示しています。
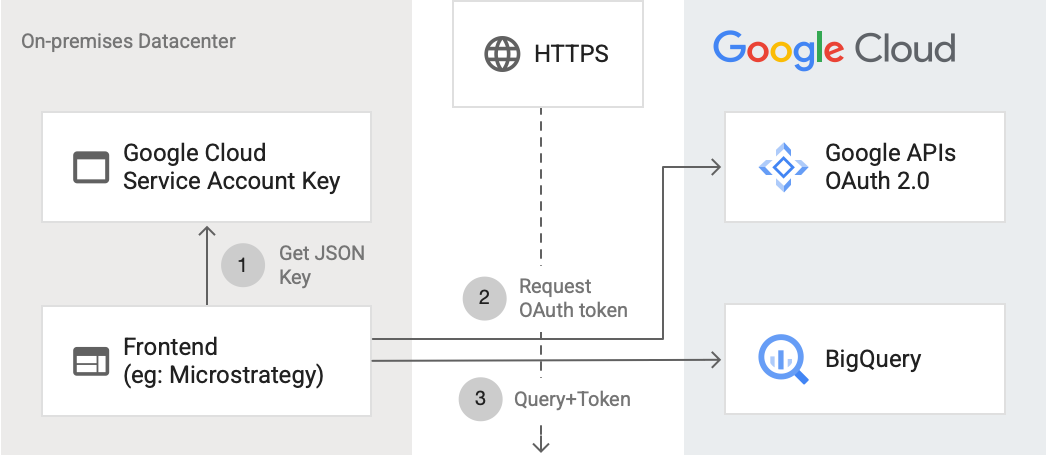
この図は以下のステップを説明しています。
- Google Cloudで、IAM 権限を持つサービス アカウントが作成されます。JSON 形式のサービス アカウント キーが生成され、フロントエンド サーバー(MicroStrategy など)にコピーされます。
- フロントエンドはキーを読み取り、HTTPS を使用して Google API に OAuth トークンを要求します。
- その後、フロントエンドから BigQuery に、BigQuery リクエストとトークンが送信されます。
詳細については、API リクエストの承認をご覧ください。
BigQuery のための最適化
GoogleSQL は SQL 2011 標準に対応しており、ネストされ繰り返しデータのクエリをサポートする拡張機能があります。パフォーマンスの向上とレスポンス時間の改善においては、BigQuery のクエリの最適化が重要です。
BigQuery で Months_Between 関数を UDF に置き換える
Netezza では 1 か月が 31 日として扱われます。次のカスタム UDF は、Netezza 関数を高い精度で再作成します。この関数をクエリから呼び出すことができます。
CREATE TEMP FUNCTION months_between(date_1 DATE, date_2 DATE) AS ( CASE WHEN date_1 = date_2 THEN 0 WHEN EXTRACT(DAY FROM DATE_ADD(date_1, INTERVAL 1 DAY)) = 1 AND EXTRACT(DAY FROM DATE_ADD(date_2, INTERVAL 1 DAY)) = 1 THEN date_diff(date_1,date_2, MONTH) WHEN EXTRACT(DAY FROM date_1) = 1 AND EXTRACT(DAY FROM DATE_ADD(date_2, INTERVAL 1 DAY)) = 1 THEN date_diff(DATE_ADD(date_1, INTERVAL -1 DAY), date_2, MONTH) + 1/31 ELSE date_diff(date_1, date_2, MONTH) - 1 + ((EXTRACT(DAY FROM date_1) + (31 - EXTRACT(DAY FROM date_2))) / 31) END );
Netezza ストアド プロシージャを移行する
ETL ワークロードで Netezza ストアド プロシージャを使用してファクト テーブルを作成する場合は、これらのストアド プロシージャを BigQuery 互換の SQL クエリに移行する必要があります。Netezza では、NZPLSQL スクリプト言語を使用してストアド プロシージャを記述します。NZPLSQL は Postgres PL/pgSQL 言語をベースとしています。詳細については、IBM Netezza SQL 変換ガイドをご覧ください。
Netezza の ASCII をエミュレートするカスタム UDF
次の BigQuery 用のカスタム UDF は、列のエンコード エラーを修正します。
CREATE TEMP FUNCTION ascii(X STRING) AS (TO_CODE_POINTS(x)[ OFFSET (0)]);
次のステップ
- 全体的なパフォーマンスの最適化と費用削減に向けてワークロードを最適化する方法を確認する。
- BigQuery でストレージを最適化する方法を学習する。
- IBM Netezza SQL 変換ガイドを確認する。