Understanding BigQuery’s rapid scaling and simple pricing
Tino Tereshko
Product Manager, Google BigQuery
In a previous blog post, we demonstrated how BigQuery can execute a multi-terabyte query in a short period of time. We estimated that such a query would require at least 3000 cores to execute. Today we talk about what this functionality means in terms of elasticity and cost efficiency.
To run the query in the previous blog post, we utilized the equivalent of 3000+ cores for just 30 seconds. In other words, we went from 0 cores to 3000+ cores and then back down to 0 in only 30 seconds!
The Cloud-Native Approach
BigQuery's pricing model doesn’t charge for each specific resource that goes into the execution of your SQL. For example, a typical query can involve thousands of CPUs, extensive networking, various API calls and other resources. Instead of charging you for each of those resources, BigQuery uses a predictable, easy to understand price proxy — bytes processed. This smooths out the large variability associated with analytics workloads and provides a simple metric that's related to the size of your data source.While we can’t draw a direct comparison of elasticity and pricing between BigQuery and traditional VM-based technologies, we have demonstrated that BigQuery scales out extremely quickly and provides simple and predictable pricing.
In traditional VM terms, BigQuery gives you the equivalent of both:
- Per-second billing
- Per-second scaling
- We keep vast resources deployed under the hood to avoid having to rapidly scale
- These resources are multi-tenant, and we instantly allocate large chunks for seconds at a time
- Economies of scale assure that BigQuery efficiently allocates resources across users
- Finally, we charge you only for the jobs you run, rather than for deployed resources, so you never pay for resources you don’t use
Traditional Architectures
So BigQuery gives you the luxury of per-second billing and per-second scaling, but how do other technologies stack up?Databases that run on top of virtual machines can only scale so quickly. It takes time to launch instances and load them with pre-configured software. In addition, cloud vendors do not charge per second: per-minute in Google Compute Engine’s case, and per-hour for Amazon’s EC2.
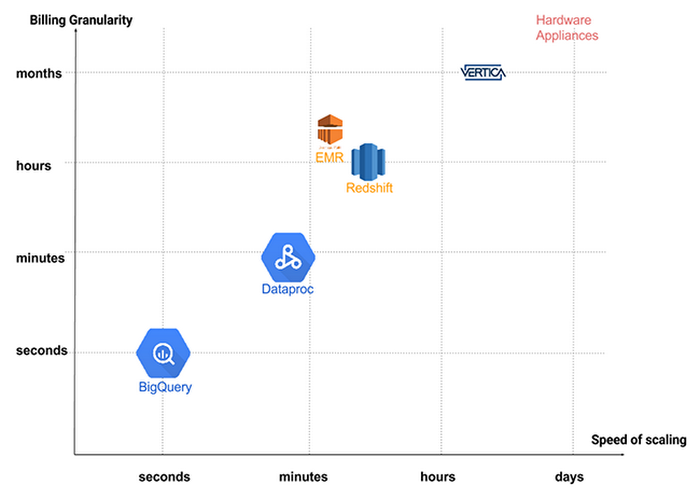
Google Cloud Dataproc is Google’s managed Hadoop and Spark service. Dataproc lets you deploy large clusters in under 90 seconds, while leveraging Compute Engine's per-minute billing.Other managed Hadoop and Spark services are frequently subject to per-hour billing, as well as bootup times associated with the underlying IaaS layer. This is, of course, also true if you deploy your own database on VMs.
Meanwhile, physical or virtual Big Data appliances are subject to one-time pricing, ongoing contracts, as well as ongoing cost support, and are incredibly difficult to scale up. In that sense, comparing these appliances to cloud native or cloud-based approaches is a challenge, in terms of both time to scale and granularity of billing.
The above chart compares various technologies by both metrics — granularity of billing and speed of scaling.
Conclusion
BigQuery is incredibly elastic — it scales to any size, quickly and seamlessly. In addition, BigQuery is highly cost efficient — charging you only for the resources consumed, rather than resources deployed or negotiated in a contract.We accomplish this by having a large, multi-tenant, highly-available and durable Serverless service, leveraging economies of scale for efficiency, and charging our customers per-job.
You get the benefit of never having to size or deploy resources, setup and configure clusters, and measure cluster utilization to understand resource efficiency.
For more information about BigQuery, go to https://cloud.google.com/bigquery.



