迁移评估
借助 BigQuery 迁移评估,您可以计划和查看将现有数据仓库迁移到 BigQuery 的过程。您可以运行 BigQuery 迁移评估来生成报告,以评估在 BigQuery 中存储数据的费用,了解 BigQuery 如何优化现有工作负载以节省费用,并制定迁移计划来概述完成将数据仓库迁移到 BigQuery 所需的时间和工作量。
本文档介绍如何使用 BigQuery 迁移评估,以及查看评估结果的不同方式。本文档面向熟悉 Google Cloud 控制台和批量 SQL 转换器的用户。
准备工作
如需准备并运行 BigQuery 迁移评估,请按以下步骤操作:
使用
dwh-migration-dumper工具从数据仓库中提取元数据和查询日志。将元数据和查询日志上传到 Cloud Storage 存储桶。
可选:查询评估结果,以查找详细或特定的评估信息。
从数据仓库中提取元数据和查询日志
您需要同时提供元数据和查询日志,才能准备包含建议的评估。
如需提取运行评估所需的元数据和查询日志,请选择您的数据仓库:
TeraData
要求
- 连接到源 Teradata 数据仓库的机器(支持 Teradata 15 及更高版本)
- 具有 Cloud Storage 存储桶(用于存储数据)的 Google Cloud 账号
- 用于存储结果的空 BigQuery 数据集
- 对数据集的读取权限,用于查看结果
- 推荐:使用提取工具访问系统表时,拥有源数据库的管理员级访问权限
要求:启用日志记录
dwh-migration-dumper 工具会提取三种类型的日志:查询日志、实用程序日志和资源使用情况日志。您需要为以下类型的日志启用日志记录,才能查看更全面的分析数据:
- 查询日志:从视图
dbc.QryLogV和表dbc.DBQLSqlTbl中提取。通过指定WITH SQL选项来启用日志记录。 - 实用程序日志:从表
dbc.DBQLUtilityTbl中提取。通过指定WITH UTILITYINFO选项来启用日志记录。 - 资源用量日志:从表
dbc.ResUsageScpu和dbc.ResUsageSpma中提取。为这两个表启用 RSS 日志记录。
运行 dwh-migration-dumper 工具
下载 SHA256SUMS.txt 文件并运行以下命令以验证 ZIP 文件的正确性:
Bash
sha256sum --check SHA256SUMS.txt
Windows PowerShell
(Get-FileHash RELEASE_ZIP_FILENAME).Hash -eq ((Get-Content SHA256SUMS.txt) -Split " ")[0]
将 RELEASE_ZIP_FILENAME 替换为 dwh-migration-dumper 命令行提取工具版本的下载 ZIP 文件名,例如 dwh-migration-tools-v1.0.52.zip
True 结果表示校验和验证成功。
False 结果表示验证错误。确保校验和以及 ZIP 文件从同一发布版本下载并放在同一目录中。
如需详细了解如何设置和使用提取工具,请参阅生成元数据以进行转换和评估。
使用该提取工具从 Teradata 数据仓库将日志和元数据提取为两个 ZIP 文件。在有权访问源数据仓库的机器上运行以下命令,以生成文件。
生成元数据 ZIP 文件:
dwh-migration-dumper \ --connector teradata \ --database DATABASES \ --driver path/terajdbc4.jar \ --host HOST \ --assessment \ --user USER \ --password PASSWORD
注意:对于 teradata 连接器,--database 标志是可选的。如果省略,则提取所有数据库的元数据。此标志仅对 teradata 连接器有效,不能与 teradata-logs 搭配使用。
生成包含查询日志的 ZIP 文件:
dwh-migration-dumper \ --connector teradata-logs \ --driver path/terajdbc4.jar \ --host HOST \ --assessment \ --user USER \ --password PASSWORD
注意:使用 teradata-logs 连接器提取查询日志时,不会使用 --database 标志。系统始终会提取所有数据库的查询日志。
替换以下内容:
PATH:要用于此连接的驱动程序 JAR 文件的绝对或相对路径。VERSION:您的驱动程序版本HOST:主机地址USER:要用于数据库连接的用户名。DATABASES:(可选)要提取的数据库名称的英文逗号分隔列表。如果未提供,则提取所有数据库。PASSWORD:(可选)用于数据库连接的密码。如果留空,则系统会提示用户输入密码。
默认情况下,查询日志会从视图 dbc.QryLogV 和表 dbc.DBQLSqlTbl 中提取。如果您需要从其他位置提取查询日志,则可以使用 -Dteradata-logs.query-logs-table 和 -Dteradata-logs.sql-logs-table 标志指定表或视图的名称。
默认情况下,实用程序日志会从 dbc.DBQLUtilityTbl 表中提取。如果您需要从备用位置提取实用程序日志,可以使用 -Dteradata-logs.utility-logs-table 标志指定表的名称。
默认情况下,资源使用情况日志会从表 dbc.ResUsageScpu 和 dbc.ResUsageSpma 中提取。如果您需要从备用位置提取资源使用情况日志,可以使用 -Dteradata-logs.res-usage-scpu-table 和 -Dteradata-logs.res-usage-spma-table 标志指定表的名称。
例如:
Bash
dwh-migration-dumper \ --connector teradata-logs \ --driver path/terajdbc4.jar \ --host HOST \ --assessment \ --user USER \ --password PASSWORD \ -Dteradata-logs.query-logs-table=pdcrdata.QryLogV_hst \ -Dteradata-logs.sql-logs-table=pdcrdata.DBQLSqlTbl_hst \ -Dteradata-logs.log-date-column=LogDate \ -Dteradata-logs.utility-logs-table=pdcrdata.DBQLUtilityTbl_hst \ -Dteradata-logs.res-usage-scpu-table=pdcrdata.ResUsageScpu_hst \ -Dteradata-logs.res-usage-spma-table=pdcrdata.ResUsageSpma_hst
Windows PowerShell
dwh-migration-dumper ` --connector teradata-logs ` --driver path\terajdbc4.jar ` --host HOST ` --assessment ` --user USER ` --password PASSWORD ` "-Dteradata-logs.query-logs-table=pdcrdata.QryLogV_hst" ` "-Dteradata-logs.sql-logs-table=pdcrdata.DBQLSqlTbl_hst" ` "-Dteradata-logs.log-date-column=LogDate" ` "-Dteradata-logs.utility-logs-table=pdcrdata.DBQLUtilityTbl_hst" ` "-Dteradata-logs.res-usage-scpu-table=pdcrdata.ResUsageScpu_hst" ` "-Dteradata-logs.res-usage-spma-table=pdcrdata.ResUsageSpma_hst"
默认情况下,dwh-migration-dumper 工具会提取过去七天的查询日志。
Google 建议您至少提供两周的查询日志,以便能够查看更全面的数据分析。您可以使用 --query-log-start 和 --query-log-end 标志指定自定义时间范围。例如:
dwh-migration-dumper \ --connector teradata-logs \ --driver path/terajdbc4.jar \ --host HOST \ --assessment \ --user USER \ --password PASSWORD \ --query-log-start "2023-01-01 00:00:00" \ --query-log-end "2023-01-15 00:00:00"
您还可以生成多个 ZIP 文件,其中包含涵盖不同时间段的查询日志,并提供所有这些内容以供评估。
Redshift
要求
- 连接到源 Amazon Redshift 数据仓库的机器
- 具有 Cloud Storage 存储桶(用于存储数据)的 Google Cloud 账号
- 用于存储结果的空 BigQuery 数据集
- 对数据集的读取权限,用于查看结果
- 推荐:使用提取工具访问系统表时超级用户对数据库的访问权限
运行 dwh-migration-dumper 工具
下载 dwh-migration-dumper 命令行提取工具。
下载 SHA256SUMS.txt 文件并运行以下命令以验证 ZIP 文件的正确性:
Bash
sha256sum --check SHA256SUMS.txt
Windows PowerShell
(Get-FileHash RELEASE_ZIP_FILENAME).Hash -eq ((Get-Content SHA256SUMS.txt) -Split " ")[0]
将 RELEASE_ZIP_FILENAME 替换为 dwh-migration-dumper 命令行提取工具版本的下载 ZIP 文件名,例如 dwh-migration-tools-v1.0.52.zip
True 结果表示校验和验证成功。
False 结果表示验证错误。确保校验和以及 ZIP 文件从同一发布版本下载并放在同一目录中。
如需详细了解如何使用 dwh-migration-dumper 工具,请参阅生成元数据页面。
使用 dwh-migration-dumper 工具从 Amazon Redshift 数据仓库将日志和元数据提取为两个 ZIP 文件。在有权访问源数据仓库的机器上运行以下命令,以生成文件。
生成元数据 ZIP 文件:
dwh-migration-dumper \ --connector redshift \ --database DATABASE \ --driver PATH/redshift-jdbc42-VERSION.jar \ --host host.region.redshift.amazonaws.com \ --assessment \ --user USER \ --iam-profile IAM_PROFILE_NAME
生成包含查询日志的 ZIP 文件:
dwh-migration-dumper \ --connector redshift-raw-logs \ --database DATABASE \ --driver PATH/redshift-jdbc42-VERSION.jar \ --host host.region.redshift.amazonaws.com \ --assessment \ --user USER \ --iam-profile IAM_PROFILE_NAME
替换以下内容:
DATABASE:要连接的数据库名称。PATH:要用于此连接的驱动程序 JAR 文件的绝对或相对路径。VERSION:您的驱动程序版本USER:要用于数据库连接的用户名。IAM_PROFILE_NAME:Amazon Redshift IAM 配置文件名称。必须完成 Amazon Redshift 身份验证才能访问 AWS API。如需获取 Amazon Redshift 集群的说明,请使用 AWS API。
默认情况下,Amazon Redshift 会存储 3 到 5 天的查询日志。
默认情况下,dwh-migration-dumper 工具会提取过去七天的查询日志。
Google 建议您至少提供两周的查询日志,以便能够查看更全面的数据分析。您可能需要在两周内运行几次提取工具,才能获得最佳结果。您可以使用 --query-log-start 和 --query-log-end 标志指定自定义范围。
例如:
dwh-migration-dumper \ --connector redshift-raw-logs \ --database DATABASE \ --driver PATH/redshift-jdbc42-VERSION.jar \ --host host.region.redshift.amazonaws.com \ --assessment \ --user USER \ --iam-profile IAM_PROFILE_NAME \ --query-log-start "2023-01-01 00:00:00" \ --query-log-end "2023-01-02 00:00:00"
您还可以生成多个 ZIP 文件,其中包含涵盖不同时间段的查询日志,并提供所有这些内容以供评估。
Redshift Serverless
要求
- 连接到源 Amazon Redshift Serverless 数据仓库的机器
- 具有 Cloud Storage 存储桶(用于存储数据)的 Google Cloud 账号
- 用于存储结果的空 BigQuery 数据集
- 对数据集的读取权限,用于查看结果
- 推荐:使用提取工具访问系统表时超级用户对数据库的访问权限
运行 dwh-migration-dumper 工具
下载 dwh-migration-dumper 命令行提取工具。
如需详细了解如何使用 dwh-migration-dumper 工具,请参阅生成元数据页面。
使用 dwh-migration-dumper 工具从您的 Amazon Redshift Serverless 命名空间中提取用量日志和元数据,并将其保存为两个 ZIP 文件。在有权访问源数据仓库的机器上运行以下命令以生成文件。
生成元数据 ZIP 文件:
dwh-migration-dumper \ --connector redshift \ --database DATABASE \ --driver PATH/redshift-jdbc42-VERSION.jar \ --host host.region.redshift-serverless.amazonaws.com \ --assessment \ --user USER \ --iam-profile IAM_PROFILE_NAME
生成包含查询日志的 ZIP 文件:
dwh-migration-dumper \ --connector redshift-serverless-logs \ --database DATABASE \ --driver PATH/redshift-jdbc42-VERSION.jar \ --host host.region.redshift-serverless.amazonaws.com \ --assessment \ --user USER \ --iam-profile IAM_PROFILE_NAME
替换以下内容:
DATABASE:要连接的数据库名称。PATH:要用于此连接的驱动程序 JAR 文件的绝对或相对路径。VERSION:您的驱动程序版本USER:要用于数据库连接的用户名。IAM_PROFILE_NAME:Amazon Redshift IAM 配置文件名称。必须完成 Amazon Redshift 身份验证才能访问 AWS API。如需获取 Amazon Redshift 集群的说明,请使用 AWS API。
Amazon Redshift Serverless 会存储 7 天的用量日志。如果需要涵盖更广的时间范围,Google 建议您在更长的时间段内分多次提取数据。
Snowflake
要求
您必须满足以下要求,才能从 Snowflake 提取元数据和查询日志:
- 可连接到 Snowflake 实例的机器。
- 具有 Cloud Storage 存储桶(用于存储数据)的 Google Cloud 账号。
- 用于存储结果的空 BigQuery 数据集。或者,您也可以在使用 Google Cloud 控制台界面创建评估作业时创建 BigQuery 数据集。
- 对数据库
Snowflake具有IMPORTED PRIVILEGES访问权限的 Snowflake 用户。我们建议您创建一个采用密钥对身份验证的SERVICE用户。此方法可安全地访问 Snowflake 数据平台,且无需生成 MFA 令牌。- 如需创建新的服务用户,请按照官方 Snowflake 指南操作。您必须生成 RSA 密钥对,并将公钥分配给相应的 Snowflake 用户。
- 服务用户应具有
ACCOUNTADMIN角色,或者由账号管理员授予对数据库Snowflake具有IMPORTED PRIVILEGES权限的角色。 - 除了密钥对身份验证之外,您还可以使用基于密码的身份验证。不过,自 2025 年 8 月起,Snowflake 将对所有基于密码的用户强制执行 MFA。这需要您在使用提取工具时批准 MFA 推送通知。
运行 dwh-migration-dumper 工具
下载 dwh-migration-dumper 命令行提取工具。
下载 SHA256SUMS.txt 文件并运行以下命令以验证 ZIP 文件的正确性:
Bash
sha256sum --check SHA256SUMS.txt
Windows PowerShell
(Get-FileHash RELEASE_ZIP_FILENAME).Hash -eq ((Get-Content SHA256SUMS.txt) -Split " ")[0]
将 RELEASE_ZIP_FILENAME 替换为 dwh-migration-dumper 命令行提取工具版本的下载 ZIP 文件名,例如 dwh-migration-tools-v1.0.52.zip
True 结果表示校验和验证成功。
False 结果表示验证错误。确保校验和以及 ZIP 文件从同一发布版本下载并放在同一目录中。
如需详细了解如何使用 dwh-migration-dumper 工具,请参阅生成元数据页面。
使用 dwh-migration-dumper 工具从 Snowflake 数据仓库将日志和元数据提取为两个 ZIP 文件。在有权访问源数据仓库的机器上运行以下命令以生成文件。
生成元数据 ZIP 文件:
dwh-migration-dumper \ --connector snowflake \ --host HOST_NAME \ --user USER_NAME \ --role ROLE_NAME \ --warehouse WAREHOUSE \ --assessment \ --private-key-file PRIVATE_KEY_PATH \ --private-key-password PRIVATE_KEY_PASSWORD
生成包含查询日志的 ZIP 文件:
dwh-migration-dumper \ --connector snowflake-logs \ --host HOST_NAME \ --user USER_NAME \ --role ROLE_NAME \ --warehouse WAREHOUSE \ --query-log-start STARTING_DATE \ --query-log-end ENDING_DATE \ --assessment \ --private-key-file PRIVATE_KEY_PATH \ --private-key-password PRIVATE_KEY_PASSWORD
替换以下内容:
HOST_NAME:Snowflake 实例的主机名。USER_NAME:要用于数据库连接的用户名,其中用户必须具有要求部分中详述的访问权限。PRIVATE_KEY_PATH:用于身份验证的 RSA 私钥的路径。PRIVATE_KEY_PASSWORD:(可选)创建 RSA 私钥时使用的密码。仅当私钥经过加密时,才需要提供此参数。ROLE_NAME:(可选)运行dwh-migration-dumper工具时的用户角色,例如ACCOUNTADMIN。WAREHOUSE:用于执行转储操作的仓库。如果您有多个虚拟数据仓库,可以指定任何数据仓库来执行此查询。使用要求部分中详述的访问权限运行此查询,即可提取此账号中的所有数据仓库制品。STARTING_DATE:(可选)用于指示查询日志日期范围内的开始日期,采用YYYY-MM-DD格式写入。ENDING_DATE:(可选)用于指示查询日志日期范围内的结束日期,采用YYYY-MM-DD格式写入。
您还可以生成多个 zip 文件,其中包含涵盖非重叠时间段的查询日志,并提供所有这些文件以进行评估。
Oracle
如需针对此功能请求反馈或支持,请发送邮件至 bq-edw-migration-support@google.com。
要求
您必须满足以下要求,才能从 Oracle 提取元数据和查询日志:
- 您的 Oracle 数据库必须为 11g R1 或更高版本。
- 可连接到 Oracle 实例的机器。
- Java 8 或更高版本。
- 具有 Cloud Storage 存储桶(用于存储数据)的 Google Cloud 账号。
- 用于存储结果的空 BigQuery 数据集。或者,您也可以在使用 Google Cloud 控制台界面创建评估作业时创建 BigQuery 数据集。
- 具有 SYSDBA 权限的 Oracle 普通用户。
运行 dwh-migration-dumper 工具
下载 dwh-migration-dumper 命令行提取工具。
下载 SHA256SUMS.txt 文件并运行以下命令以验证 ZIP 文件的正确性:
sha256sum --check SHA256SUMS.txt
如需详细了解如何使用 dwh-migration-dumper 工具,请参阅生成元数据页面。
使用 dwh-migration-dumper 工具将元数据和性能统计信息提取到 ZIP 文件中。默认情况下,系统会从 Oracle AWR 中提取统计信息,这需要 Oracle 调优和诊断软件包。如果此数据不可用,dwh-migration-dumper 会改用 STATSPACK。
对于多租户数据库,必须在根容器中执行 dwh-migration-dumper 工具。在其中一个可插入数据库中运行该脚本会导致缺少其他可插入数据库的性能统计信息和元数据。
生成元数据 ZIP 文件:
dwh-migration-dumper \ --connector oracle-stats \ --host HOST_NAME \ --port PORT \ --oracle-service SERVICE_NAME \ --assessment \ --driver JDBC_DRIVER_PATH \ --user USER_NAME \ --password
替换以下内容:
HOST_NAME:Oracle 实例的主机名。PORT:连接端口号。默认值为 1521。SERVICE_NAME:要用于连接的 Oracle 服务名称。JDBC_DRIVER_PATH:驱动程序 JAR 文件的绝对或相对路径。您可以从 Oracle JDBC 驱动程序下载页面下载此文件。您应选择与数据库版本兼容的驱动程序版本。USER_NAME:用于连接到 Oracle 实例的用户的名称。用户必须拥有要求部分中详述的访问权限。
Hadoop/Cloudera
如需针对此功能请求反馈或支持,请发送邮件至 bq-edw-migration-support@google.com。
要求
如需从 Cloudera 提取元数据,您必须具备以下条件:
- 可连接到 Cloudera Manager API 的机器。
- 具有 Cloud Storage 存储桶(用于存储数据)的 Google Cloud 账号。
- 用于存储结果的空 BigQuery 数据集。或者,您也可以在创建评估作业时创建 BigQuery 数据集。
运行 dwh-migration-dumper 工具
在命令行环境中,验证 ZIP 文件的正确性:
sha256sum --check SHA256SUMS.txt
如需详细了解如何使用
dwh-migration-dumper工具,请参阅生成元数据以进行转换和评估。使用
dwh-migration-dumper工具将元数据和性能统计信息提取到 ZIP 文件中:dwh-migration-dumper \ --connector cloudera-manager \ --user USER_NAME \ --password PASSWORD \ --url URL_PATH \ --yarn-application-types "APP_TYPES" \ --pagination-page-size PAGE_SIZE \ --start-date START_DATE \ --end-date END_DATE \ --assessment
替换以下内容:
USER_NAME:用于连接到 Cloudera Manager 实例的用户名。PASSWORD:Cloudera Manager 实例的密码。URL_PATH:Cloudera Manager API 的网址路径,例如https://localhost:7183/api/v55/。APP_TYPES(可选):从集群转储的 YARN 应用类型,以逗号分隔。默认值为MAPREDUCE,SPARK,Oozie Launcher。PAGE_SIZE(可选):每个 Cloudera 响应中的记录数。默认值为1000。START_DATE(可选):历史记录转储的开始日期(采用 ISO 8601 格式,例如2025-05-29)。默认值为当前日期的 90 天前。END_DATE(可选):历史记录转储的结束日期(采用 ISO 8601 格式,例如2025-05-30)。默认值为当前日期。
在 Cloudera 集群中使用 Oozie
如果您在 Cloudera 集群中使用 Oozie,则可以使用 Oozie 连接器转储 Oozie 作业记录。您可以将 Oozie 与 Kerberos 身份验证或基本身份验证结合使用。
对于 Kerberos 身份验证,请运行以下命令:
kinit dwh-migration-dumper \ --connector oozie \ --url URL_PATH \ --assessment
替换以下内容:
URL_PATH(可选):Oozie 服务器的网址路径。如果您未指定网址路径,系统会从OOZIE_URL环境变量中获取网址路径。
对于基本身份验证,请运行以下命令:
dwh-migration-dumper \ --connector oozie \ --user USER_NAME \ --password PASSWORD \ --url URL_PATH \ --assessment
替换以下内容:
USER_NAME:Oozie 用户名。PASSWORD:用户密码。URL_PATH(可选):Oozie 服务器的网址路径。如果您未指定网址路径,系统会从OOZIE_URL环境变量中获取网址路径。
在 Cloudera 集群中使用 Airflow
如果您在 Cloudera 集群中使用 Airflow,则可以使用 Airflow 连接器转储 DAG 历史记录:
dwh-migration-dumper \ --connector airflow \ --user USER_NAME \ --password PASSWORD \ --url URL \ --driver "DRIVER_PATH" \ --start-date START_DATE \ --end-date END_DATE \ --assessment
替换以下内容:
USER_NAME:Airflow 用户名PASSWORD:用户密码URL:指向 Airflow 数据库的 JDBC 字符串DRIVER_PATH:JDBC 驱动程序的路径START_DATE(可选):历史记录转储的开始日期(采用 ISO 8601 格式)END_DATE(可选):历史记录转储的结束日期(采用 ISO 8601 格式)
在 Cloudera 集群中使用 Hive
如需使用 Hive 连接器,请参阅“Apache Hive”标签页。
Apache Hive
要求
- 连接到源 Apache Hive 数据仓库的机器(BigQuery 迁移评估支持 Hive on Tez 和 Hive on MapReduce,并且支持 2.2 到 3.1 之间的 Apache Hive 版本,包括 2.2 和 3.1)
- 具有 Cloud Storage 存储桶(用于存储数据)的 Google Cloud 账号
- 用于存储结果的空 BigQuery 数据集
- 对数据集的读取权限,用于查看结果
- 有权访问源 Apache Hive 数据仓库以配置查询日志提取
- 最新的表、分区和列统计信息
BigQuery 迁移评估使用表、分区和列统计信息来更好地了解 Apache Hive 数据仓库,并提供全面的数据分析。如果源 Apache Hive 数据仓库中的 hive.stats.autogather 配置设置设为 false,则 Google 建议您在运行 dwh-migration-dumper 工具之前手动将其启用或更新统计信息。
运行 dwh-migration-dumper 工具
下载 dwh-migration-dumper 命令行提取工具。
下载 SHA256SUMS.txt 文件并运行以下命令以验证 ZIP 文件的正确性:
Bash
sha256sum --check SHA256SUMS.txt
Windows PowerShell
(Get-FileHash RELEASE_ZIP_FILENAME).Hash -eq ((Get-Content SHA256SUMS.txt) -Split " ")[0]
将 RELEASE_ZIP_FILENAME 替换为 dwh-migration-dumper 命令行提取工具版本的下载 ZIP 文件名,例如 dwh-migration-tools-v1.0.52.zip
True 结果表示校验和验证成功。
False 结果表示验证错误。确保校验和以及 ZIP 文件从同一发布版本下载并放在同一目录中。
如需详细了解如何使用 dwh-migration-dumper 工具,请参阅生成元数据以进行转换和评估。
使用 dwh-migration-dumper 工具从 Hive 数据仓库生成元数据的 ZIP 文件。
不进行身份验证
若要生成元数据 ZIP 文件,请在有权访问源数据仓库的机器上运行以下命令:
dwh-migration-dumper \ --connector hiveql \ --database DATABASES \ --host hive.cluster.host \ --port 9083 \ --assessment
进行 Kerberos 身份验证
如需向 metastore 进行身份验证,请以有权访问 Apache Hive metastore 的用户身份登录,并生成 Kerberos 票据。然后,使用以下命令生成元数据 ZIP 文件:
JAVA_OPTS="-Djavax.security.auth.useSubjectCredsOnly=false" \ dwh-migration-dumper \ --connector hiveql \ --database DATABASES \ --host hive.cluster.host \ --port 9083 \ --hive-kerberos-url PRINCIPAL/HOST \ -Dhiveql.rpc.protection=hadoop.rpc.protection \ --assessment
替换以下内容:
DATABASES:要提取的数据库名称的逗号分隔列表如果未提供,则提取所有数据库。PRINCIPAL:票据发放到的 Kerberos 主账号HOST:票证发放到的 Kerberos 主机名hadoop.rpc.protection:简单身份验证和安全层 (SASL) 配置级别的保护质量 (QOP),等于/etc/hadoop/conf/core-site.xml文件中hadoop.rpc.protection参数的值,具有以下值之一:authenticationintegrityprivacy
使用 hadoop-migration-assessment 日志记录钩子提取查询日志
如需提取查询日志,请按照以下步骤操作:
上传 hadoop-migration-assessment 日志记录钩子
下载包含 Hive 日志记录钩子 JAR 文件的
hadoop-migration-assessment查询日志提取日志记录钩子。提取 JAR 文件。
如果您需要审核工具以确保它符合合规性要求,请查看
hadoop-migration-assessment日志记录钩子 GitHub 代码库中的源代码,并编译您自己的二进制文件。将 JAR 文件复制到计划启用查询日志记录的所有集群上的辅助库文件夹中。根据您的供应商,您需要在集群设置中找到辅助库文件夹,并将 JAR 文件转移到 Hive 集群上的辅助库文件夹。
设置
hadoop-migration-assessment日志记录钩子的配置属性。您需要使用界面控制台来修改集群设置,具体操作取决于您的 Hadoop 供应商。修改/etc/hive/conf/hive-site.xml文件,或通过配置管理器应用配置。
配置属性
如果以下配置键已有其他值,请使用英文逗号 (,) 附加这些设置。若要设置 hadoop-migration-assessment 日志记录钩子,需要以下配置设置:
hive.exec.failure.hooks:com.google.cloud.bigquery.dwhassessment.hooks.MigrationAssessmentLoggingHookhive.exec.post.hooks:com.google.cloud.bigquery.dwhassessment.hooks.MigrationAssessmentLoggingHookhive.exec.pre.hooks:com.google.cloud.bigquery.dwhassessment.hooks.MigrationAssessmentLoggingHookhive.aux.jars.path:包括日志记录钩子 JAR 文件的路径,例如file://。/HiveMigrationAssessmentQueryLogsHooks_deploy.jar dwhassessment.hook.base-directory:查询日志输出文件夹的路径。例如hdfs://tmp/logs/。您还可以设置以下可选配置:
dwhassessment.hook.queue.capacity:查询事件日志记录线程的队列容量。默认值为64。dwhassessment.hook.rollover-interval:必须按此频率执行文件轮替。例如600s。默认值为 3600 秒(1 小时)。dwhassessment.hook.rollover-eligibility-check-interval:文件轮替资格检查在后台触发的频率。例如600s。默认值为 600 秒(10 分钟)。
验证日志记录钩子
重启 hive-server2 进程后,运行测试查询并分析调试日志。您可以看到以下消息:
Logger successfully started, waiting for query events. Log directory is '[dwhassessment.hook.base-directory value]'; rollover interval is '60' minutes; rollover eligibility check is '10' minutes
日志记录钩子会在配置的文件夹中创建一个按日期分区的子文件夹。在 dwhassessment.hook.rollover-interval 间隔或 hive-server2 进程终止后,包含查询事件的 Avro 文件会显示在该文件夹中。您可以在调试日志中查找类似的消息,以查看轮替操作的状态:
Updated rollover time for logger ID 'my_logger_id' to '2023-12-25T10:15:30'
Performed rollover check for logger ID 'my_logger_id'. Expected rollover time is '2023-12-25T10:15:30'
轮替操作会按照指定的时间间隔执行或在日期发生变化时执行。当日期发生变化时,日志记录钩子还会为该日期创建一个新的子文件夹。
Google 建议您至少提供两周的查询日志,以便能够查看更全面的数据分析。
您还可以生成包含不同 Hive 集群的查询日志的文件夹,并提供所有这些日志以进行单个评估。
Informatica
如需针对此功能请求反馈或支持,请发送邮件至 bq-edw-migration-support@google.com。
要求
- 对 Informatica PowerCenter Repository Manager 客户端的访问权限
- 具有 Cloud Storage 存储桶(用于存储数据)的 Google Cloud 账号。
- 用于存储结果的空 BigQuery 数据集。或者,您也可以在使用 Google Cloud 控制台创建评估作业时创建 BigQuery 数据集。
要求:导出对象文件
您可以使用 Informatica PowerCenter Repository Manager GUI 导出对象文件。如需了解详情,请参阅导出对象的步骤
或者,您也可以运行 pmrep 命令来导出对象文件,具体步骤如下:
- 运行
pmrep connect命令以连接到代码库:
pmrep connect -r `REPOSITORY_NAME` -d `DOMAIN_NAME` -n `USERNAME` -x `PASSWORD`
替换以下内容:
REPOSITORY_NAME:要连接的代码库的名称DOMAIN_NAME:代码库的网域名称USERNAME:用于连接到代码库的用户名PASSWORD:用户名的密码
- 连接到代码库后,使用
pmrep objectexport命令导出所需的对象:
pmrep objectexport -n `OBJECT_NAME` -o `OBJECT_TYPE` -f `FOLDER_NAME` -u `OUTPUT_FILE_NAME.xml`
替换以下内容:
OBJECT_NAME:要导出的特定对象的名称OBJECT_TYPE:指定对象的对象类型FOLDER_NAME:包含要导出的对象的文件夹的名称OUTPUT_FILE_NAME:包含对象信息的 XML 文件的名称
将元数据和查询日志上传到 Cloud Storage
从数据仓库中提取元数据和查询日志后,您可以将文件上传到 Cloud Storage 存储桶,以继续迁移评估。
TeraData
将元数据和包含查询日志的一个或多个 ZIP 文件上传到您的 Cloud Storage 存储桶。如需详细了解如何创建存储桶并将文件上传到 Cloud Storage,请参阅创建存储桶,以及从文件系统上传对象。元数据 zip 文件中的所有文件在压缩前的总大小限制为 50 GB。
包含查询日志的所有 ZIP 文件中的条目分为以下内容:
- 前缀为
query_history_的查询历史记录文件。 - 前缀为
utility_logs_、dbc.ResUsageScpu_和dbc.ResUsageSpma_的时序文件。
所有查询历史记录文件在压缩前的总大小限制为 5 TB。 所有时序文件的压缩前总大小限制为 1 TB。
如果查询日志归档在其他数据库中,请参阅本部分前面的 -Dteradata-logs.query-logs-table 和 -Dteradata-logs.sql-logs-table 标志说明,其中介绍了如何为查询日志提供替代位置。
Redshift
将元数据和包含查询日志的一个或多个 ZIP 文件上传到您的 Cloud Storage 存储桶。如需详细了解如何创建存储桶并将文件上传到 Cloud Storage,请参阅创建存储桶,以及从文件系统上传对象。元数据 zip 文件中的所有文件在压缩前的总大小限制为 50 GB。
包含查询日志的所有 ZIP 文件中的条目分为以下内容:
- 前缀为
querytext_和ddltext_的查询历史记录文件。 - 前缀为
query_queue_info_、wlm_query_和querymetrics_的时序文件。
所有查询历史记录文件在压缩前的总大小限制为 5 TB。 所有时序文件的压缩前总大小限制为 1 TB。
Redshift Serverless
将元数据和包含查询日志的一个或多个 ZIP 文件上传到您的 Cloud Storage 存储桶。如需详细了解如何创建存储桶并将文件上传到 Cloud Storage,请参阅创建存储桶,以及从文件系统上传对象。
Snowflake
将包含查询日志和使用情况历史记录的元数据和 zip 文件上传到您的 Cloud Storage 存储桶。将这些文件上传到 Cloud Storage 时,必须满足以下要求:
- 元数据 zip 文件中所有文件的压缩前总大小不得超过 50 GB。
- 元数据 ZIP 文件和包含查询日志的 ZIP 文件必须上传到 Cloud Storage 文件夹。如果您有多个包含非重叠查询日志的 zip 文件,则可以上传所有 zip 文件。
- 您必须将所有文件上传到同一个 Cloud Storage 文件夹。
- 您必须按照
dwh-migration-dumper工具输出的原样上传所有元数据和查询日志的 ZIP 文件。请勿解压缩、合并或以其他方式修改这些文件。 - 所有查询历史记录文件在压缩前的总大小不得超过 5 TB。
Oracle
如需针对此功能请求反馈或支持,请发送电子邮件至 bq-edw-migration-support@google.com。
将包含元数据和性能统计信息的 ZIP 文件上传到 Cloud Storage 存储桶。默认情况下,ZIP 文件的文件名为 dwh-migration-oracle-stats.zip,但您可以通过在 --output 标志中指定该文件名来进行自定义。zip 文件中的所有文件在压缩前的总大小限制为 50 GB。
Hadoop/Cloudera
如需针对此功能请求反馈或支持,请发送邮件至 bq-edw-migration-support@google.com。
将包含元数据和性能统计信息的 ZIP 文件上传到 Cloud Storage 存储桶。默认情况下,ZIP 文件的文件名为 dwh-migration-cloudera-manager-RUN_DATE.zip(例如 dwh-migration-cloudera-manager-20250312T145808.zip),但您可以使用 --output 标志来自定义文件名。ZIP 文件中的所有文件在压缩前的总大小上限为 50 GB。
Apache Hive
将包含查询日志的元数据和文件夹从一个或多个 Hive 集群上传到 Cloud Storage 存储桶。如需详细了解如何创建存储桶并将文件上传到 Cloud Storage,请参阅创建存储桶,以及从文件系统上传对象。
元数据 zip 文件中的所有文件在压缩前的总大小限制为 50 GB。
您可以使用 Cloud Storage 连接器将查询日志直接复制到 Cloud Storage 文件夹。包含查询日志的子文件夹的文件夹必须上传到元数据 ZIP 文件所上传到的同一 Cloud Storage 文件夹。
查询日志文件夹包含前缀为 dwhassessment_ 的查询历史记录文件。所有查询历史记录文件在压缩前的总大小限制为 5 TB。
Informatica
如需针对此功能请求反馈或支持,请发送电子邮件至 bq-edw-migration-support@google.com。
将包含 Informatica XML 资源库对象的 ZIP 文件上传到 Cloud Storage 存储分区。此 ZIP 文件还必须包含一个 compilerworks-metadata.yaml 文件,其中包含以下内容:
product: arguments: "ConnectorArguments{connector=informatica, assessment=true}"
zip 文件中的所有文件在压缩前的总大小限制为 50 GB。
运行 BigQuery 迁移评估
请按照以下步骤运行 BigQuery 迁移评估。这些步骤假定您已将元数据文件上传到 Cloud Storage 存储桶,如上一部分所述。
所需权限
如果要启用 BigQuery Migration Service,您需要以下 Identity and Access Management (IAM) 权限:
resourcemanager.projects.getresourcemanager.projects.updateserviceusage.services.enableserviceusage.services.get
如果要访问和使用 BigQuery Migration Service,您需要项目的以下权限:
bigquerymigration.workflows.createbigquerymigration.workflows.getbigquerymigration.workflows.listbigquerymigration.workflows.deletebigquerymigration.subtasks.getbigquerymigration.subtasks.list
如果要运行 BigQuery Migration Service,您需要以下额外权限。
访问 Cloud Storage 存储桶以获取输入和输出文件的权限:
- 针对源 Cloud Storage 存储桶的
storage.objects.get权限 - 针对源 Cloud Storage 存储桶的
storage.objects.list权限 - 针对目标 Cloud Storage 存储桶的
storage.objects.create权限 - 针对目标 Cloud Storage 存储桶的
storage.objects.delete权限 - 针对目标 Cloud Storage 存储桶的
storage.objects.update权限 storage.buckets.getstorage.buckets.list
- 针对源 Cloud Storage 存储桶的
读取和更新 BigQuery Migration Service 在其中写入结果的 BigQuery 数据集的权限:
bigquery.datasets.updatebigquery.datasets.getbigquery.datasets.createbigquery.datasets.deletebigquery.jobs.createbigquery.jobs.deletebigquery.jobs.listbigquery.jobs.updatebigquery.tables.createbigquery.tables.getbigquery.tables.getDatabigquery.tables.listbigquery.tables.updateData
如需与用户共享 Looker Studio 报告,您需要授予以下角色:
roles/bigquery.dataViewerroles/bigquery.jobUser
如需自定义本文档以在命令中使用您自己的项目和用户,请修改以下变量:PROJECT、USER_EMAIL。
创建一个具备使用 BigQuery 迁移评估所需权限的自定义角色:
gcloud iam roles create BQMSrole \ --project=PROJECT \ --title=BQMSrole \ --permissions=bigquerymigration.subtasks.get,bigquerymigration.subtasks.list,bigquerymigration.workflows.create,bigquerymigration.workflows.get,bigquerymigration.workflows.list,bigquerymigration.workflows.delete,resourcemanager.projects.update,resourcemanager.projects.get,serviceusage.services.enable,serviceusage.services.get,storage.objects.get,storage.objects.list,storage.objects.create,storage.objects.delete,storage.objects.update,bigquery.datasets.get,bigquery.datasets.update,bigquery.datasets.create,bigquery.datasets.delete,bigquery.tables.get,bigquery.tables.create,bigquery.tables.updateData,bigquery.tables.getData,bigquery.tables.list,bigquery.jobs.create,bigquery.jobs.update,bigquery.jobs.list,bigquery.jobs.delete,storage.buckets.list,storage.buckets.get
将自定义角色 BQMSrole 授予用户:
gcloud projects add-iam-policy-binding \ PROJECT \ --member=user:USER_EMAIL \ --role=projects/PROJECT/roles/BQMSrole
将所需角色授予您要与之共享报告的用户:
gcloud projects add-iam-policy-binding \ PROJECT \ --member=user:USER_EMAIL \ --role=roles/bigquery.dataViewer gcloud projects add-iam-policy-binding \ PROJECT \ --member=user:USER_EMAIL \ --role=roles/bigquery.jobUser
支持的位置
BigQuery 迁移评估功能支持两种类型的位置:
单区域位置是具体的地理位置,如伦敦。
多区域位置是至少包含两个区域的大型地理区域,如美国。与单区域相比,多区域位置可提供更高的配额。
如需详细了解地区和区域,请参阅地理位置和地区。
区域
下表列出了提供 BigQuery 迁移评估的美洲区域。| 区域说明 | 区域名称 | 详细信息 |
|---|---|---|
| 俄亥俄州,哥伦布 | us-east5 |
|
| 达拉斯 | us-south1 |
|
| 艾奥瓦 | us-central1 |
|
| 南卡罗来纳 | us-east1 |
|
| 北弗吉尼亚 | us-east4 |
|
| 俄勒冈 | us-west1 |
|
| 洛杉矶 | us-west2 |
|
| 盐湖城 | us-west3 |
| 区域说明 | 区域名称 | 详细信息 |
|---|---|---|
| 新加坡 | asia-southeast1 |
|
| 东京 | asia-northeast1 |
| 区域说明 | 区域名称 | 详细信息 |
|---|---|---|
| 比利时 | europe-west1 |
|
| 芬兰 | europe-north1 |
|
| 法兰克福 | europe-west3 |
|
| 伦敦 | europe-west2 |
|
| 马德里 | europe-southwest1 |
|
| 荷兰 | europe-west4 |
|
| 巴黎 | europe-west9 |
|
| 都灵 | europe-west12 |
|
| 华沙 | europe-central2 |
|
| 苏黎世 | europe-west6 |
|
多区域
下表列出了提供 BigQuery 迁移评估的多区域。| 多区域说明 | 多区域名称 |
|---|---|
| 欧盟成员国的数据中心 | EU |
| 美国的数据中心 | US |
准备工作
在运行评估之前,您必须启用 BigQuery Migration API 并创建 BigQuery 数据集来存储评估结果。
启用 BigQuery Migration API
启用 BigQuery Migration API,如下所示:
在 Google Cloud 控制台中,前往 BigQuery Migration API 页面。
点击启用。
为评估结果创建数据集
BigQuery 迁移评估会将评估结果写入 BigQuery 中的表。在开始之前,请先创建数据集来保存这些表。共享 Looker Studio 报告时,您还必须授予用户读取此数据集的权限。如需了解详情,请参阅将报告提供给用户。
运行迁移评估
控制台
在 Google Cloud 控制台中,前往 BigQuery 页面。
在导航菜单中,点击评估。
点击开始评估。
填写评估配置对话框。
- 在显示名称部分,输入可以包含字母、数字或下划线的名称。此名称仅用于显示目的,不必是唯一的。
在数据位置列表中,选择评估作业的位置。评估作业必须与提取的文件输入 Cloud Storage 存储桶和输出 BigQuery 数据集位于同一位置。 不过,如果 Cloud Storage 存储桶或 BigQuery 数据集位于多区域中,则评估作业必须位于此多区域中的任一区域。
如果评估位置是
US或EU多区域,则 Cloud Storage 存储桶位置和 BigQuery 数据集位置必须位于同一多区域或该多区域内的位置。如需详细了解位置限制,请参阅 BigQuery 加载数据位置注意事项。在评估数据源中,选择您的数据仓库。
在输入文件的路径中,输入包含提取文件的 Cloud Storage 存储桶的路径。
如需选择评估结果的存储方式,请执行以下任一选项:
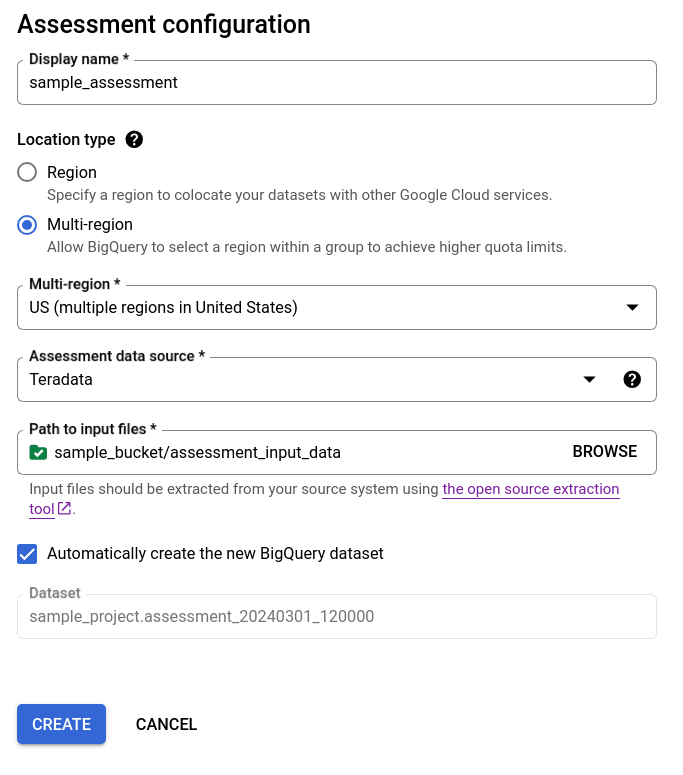
- 请保持自动创建新的 BigQuery 数据集复选框处于选中状态,以便系统自动创建 BigQuery 数据集。系统会自动生成数据集的名称。
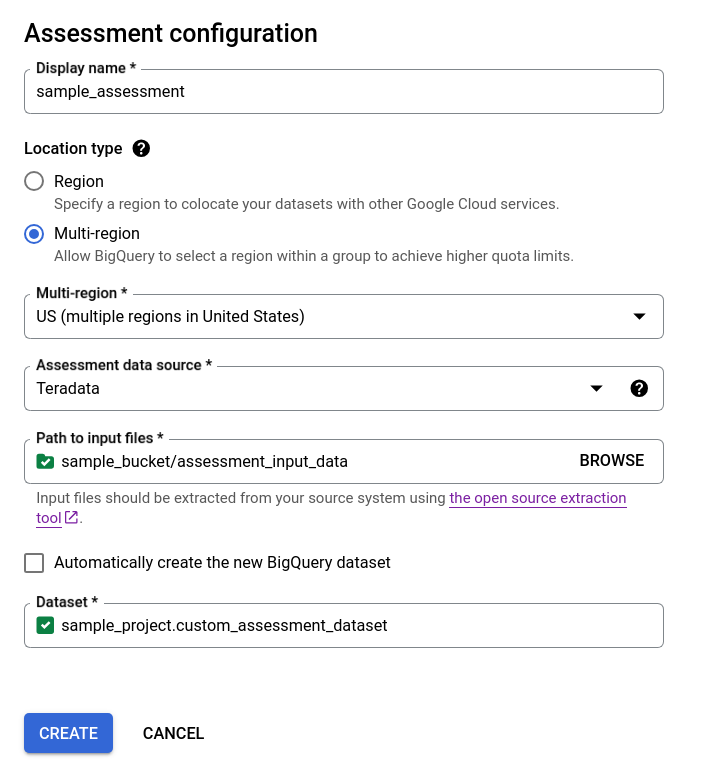
- 清除自动创建新的 BigQuery 数据集复选框,然后选择使用
projectId.datasetId格式的现有空 BigQuery 数据集,或创建新数据集名称。在此选项中,您可以选择 BigQuery 数据集名称。
选项 1 - 自动生成 BigQuery 数据集(默认)
选项 2 - 手动创建 BigQuery 数据集:
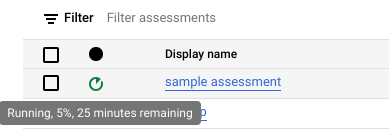
点击创建。您可以在评估作业列表中查看作业的状态。
在评估运行期间,您可以在状态图标的提示中查看评估的进度和预计完成时间。
在评估运行期间,您可以点击评估作业列表中的查看报告链接,在 Looker Studio 中查看包含部分数据的评估报告。在评估运行期间,查看报告链接可能需要一些时间才能显示。该报告将在新标签页中打开。
报告会在处理新数据时进行更新。刷新包含报告的标签页,或再次点击查看报告以查看更新后的报告。
评估完成后,点击查看报告以查看 Looker Studio 中的完整评估报告。该报告将在新标签页中打开。
API
然后,调用 start 方法启动评估工作流。
评估会在您之前创建的 BigQuery 数据集中创建表。您可以通过查询了解现有数据仓库中使用的表和查询的相关信息。 如需了解转换的输出文件,请参阅批量 SQL 转换器。
可共享的汇总评估结果
对于 Amazon Redshift、Teradata 和 Snowflake 评估,除了之前创建的 BigQuery 数据集之外,工作流程还会创建另一个名称相同且带有 _shareableRedactedAggregate 后缀的轻量级数据集。此数据集包含从输出数据集中派生出来的高度汇总数据,并且不包含个人身份信息 (PII)。
如需查找、检查和安全地与其他用户共享数据集,请参阅查询迁移评估输出表。
该功能默认处于开启状态,但您可以使用公共 API 选择停用此功能。
评估详细信息
如需查看评估详情页,请点击评估作业列表中的显示名称。

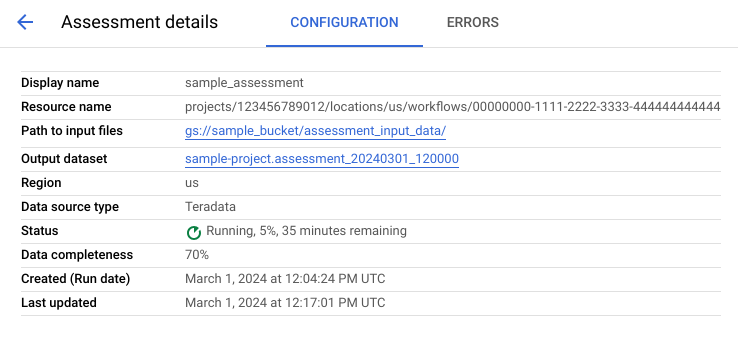
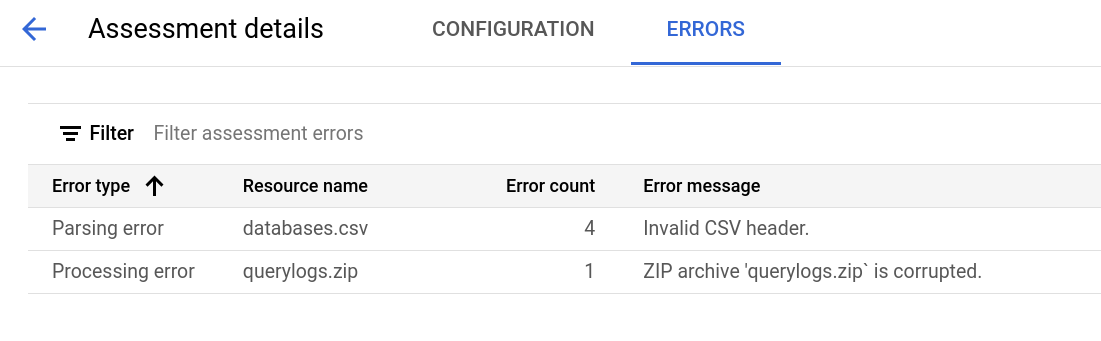
评估详情页包含配置标签页,您可以在其中查看有关评估作业的更多信息;还包含错误标签页,您可以在其中查看评估处理期间发生的所有错误。
查看配置标签页,查看评估的属性。
查看错误标签页,查看评估处理期间发生的错误。
审核并共享 Looker Studio 报告
评估任务完成后,您可以创建和共享结果的 Looker Studio 报告。
审核报告
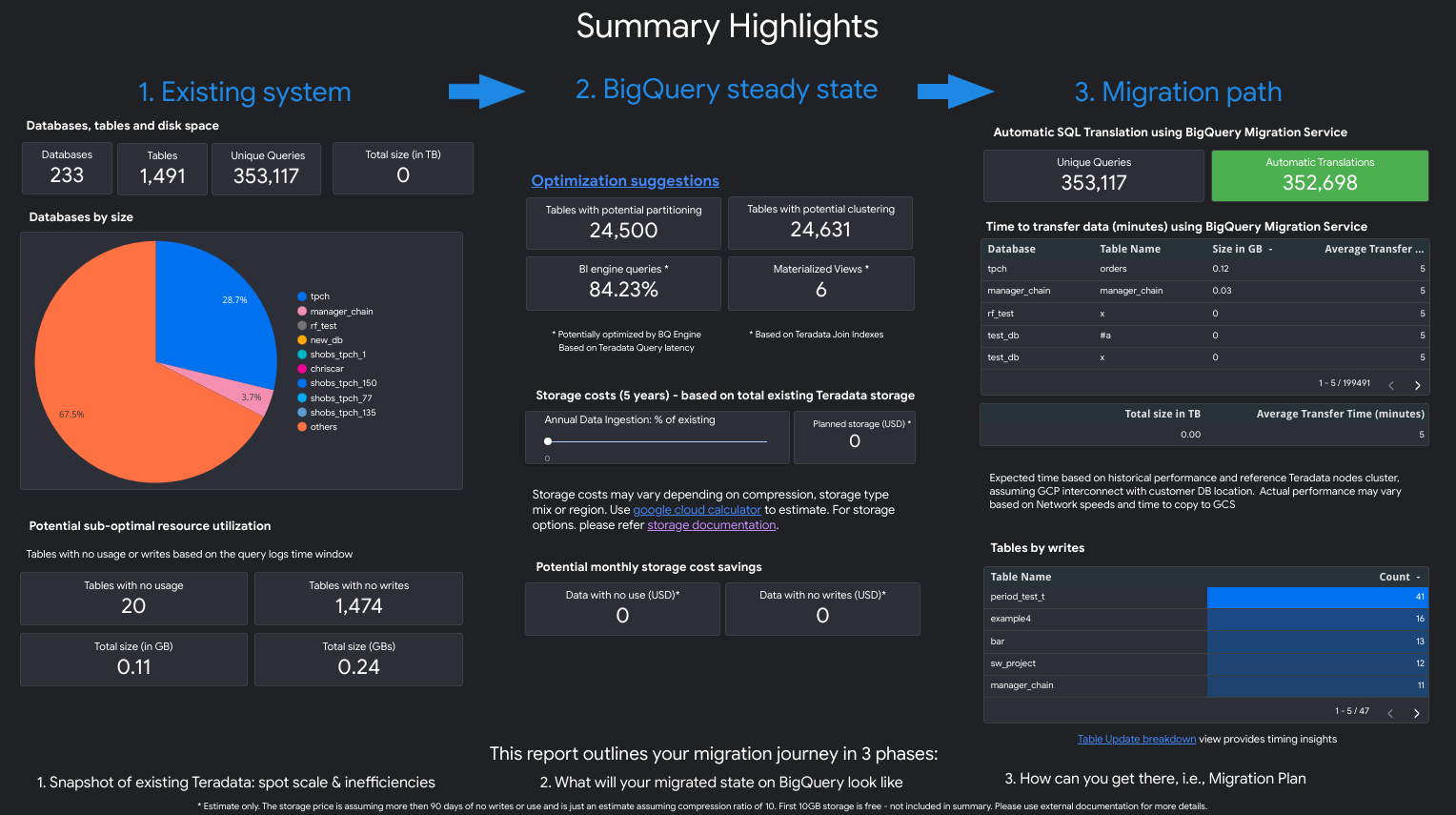
点击单个评估任务旁边列出的查看报告链接。Looker 数据洞察报告会在新标签页中打开,以预览模式显示。您可以使用预览模式查看报告的内容,然后再进一步共享。
报告类似于以下屏幕截图:
如需查看报告中包含的视图,请选择您的数据仓库:
TeraData
该报告是由三部分组成的说明,以摘要重要信息页面开头。该页面包含以下部分:
- 现有系统。此部分是现有 Teradata 系统和使用情况的快照,包括数据库数量、架构、表和总大小(以 TB 为单位)。它还按大小列出架构并指向可能的次优资源利用率(没有写入或读取次数很少的表)。
- BigQuery 稳定状态转换(建议)。 此部分介绍了迁移后系统在 BigQuery 中的外观。其中包括有关在 BigQuery 中优化工作负载(并避免浪费)的建议。
- 迁移计划。此部分介绍了迁移工作本身,例如从现有系统迁移到 BigQuery 稳定状态。此部分包含自动转换的查询数量,以及将每个表迁移到 BigQuery 的预期时间。
各部分的详细信息包含以下内容:
现有系统
- 计算和查询
- CPU 利用率:
- 每小时平均 CPU 利用率热图(整体系统资源利用率视图)
- 具有 CPU 利用率的查询,按小时和天
- 具有 CPU 利用率的查询,按类型(读取/写入)
- 具有 CPU 利用率的应用
- 每小时 CPU 利用率与平均每小时查询性能和平均每小时应用性能的叠加
- 按类型和查询时长的查询直方图
- 应用详情视图(应用、用户、唯一查询、报告与 ETL 细分)
- CPU 利用率:
- 存储概览
- 按数量、视图和访问速率的数据库
- 包含访问速率的表(按用户、查询、写入和临时表创建)
- 应用:访问速率和 IP 地址
BigQuery 稳定状态转换(建议)
- 转换为具体化视图的联接索引
- 基于元数据和使用情况的聚类和分区候选项
- 识别为 BigQuery BI Engine 候选项的低延迟查询
- 配置了默认值的列,使用列说明功能来存储默认值
- Teradata 中的唯一索引(用于防止表中具有非唯一键的行)使用暂存表和
MERGE语句仅将唯一记录插入到目标表,然后舍弃重复项 - 其余查询和架构会按原样转换
迁移计划
- 包含自动转换的查询的详细视图
- 能够按用户、应用、受影响的表、查询的表和查询类型过滤的查询的总数
- 具有类似模式的查询分桶,这些分桶归为一组并显示,以便用户能够按查询类型查看转换理念
- 需要人工干预的查询
- 违反 BigQuery 词法结构的查询
- 用户定义的函数和过程
- BigQuery 预留关键字
- 按写入和读取的表时间表(对表进行分组以进行迁移)
- 使用 BigQuery Data Transfer Service 进行数据迁移:按表估算的迁移时间
现有系统部分包含以下视图:
- 系统概览
- “系统概览”视图提供指定时间段内现有系统中关键组件的概要指标。评估的时间轴取决于 BigQuery 迁移评估所分析的日志。此视图可让您快速了解源数据仓库的利用率,用于进行迁移规划。
- 表量
- “表量”视图提供有关 BigQuery 迁移评估发现的最大表和数据库的统计信息。由于从源数据仓库系统中提取大型表可能需要更长的时间,因此此视图有助于迁移计划和排序。
- 表使用情况
- “表使用情况”视图提供在源数据仓库系统中大量使用的表的统计信息。大量使用的表可以帮助您了解哪些表可能包含许多依赖项,并且需要在迁移过程中进行额外规划。
- 应用
- “应用使用情况”视图和“应用模式”视图提供在处理日志期间找到的应用的统计信息。这些视图使用户可以了解一段时间内特定应用的使用情况以及对资源使用情况的影响。在迁移期间,请务必直观呈现数据的注入和使用,以更好地了解数据仓库的依赖项,以及分析同时移动各种依赖应用的影响。IP 地址表可用于确定通过 JDBC 连接使用数据仓库的确切应用。
- 查询
- “查询”视图细分了执行的 SQL 语句类型及其使用情况的统计信息。您可以使用查询类型和时间的直方图来识别低系统利用率和一天中最佳的时间来传输数据。您还可以使用此视图来识别频繁执行的查询以及调用这些执行的用户。
- 数据库
- “数据库”视图会提供有关源数据仓库系统中定义的大小、表、视图和过程的指标。此视图可让您深入了解您需要迁移的对象量。
- 数据库耦合
- “数据库耦合”视图提供在单个查询中同时访问的数据库和表的简要视图。此视图可以显示经常引用的表和数据库以及可用于迁移规划的内容。
BigQuery 稳定状态部分包含以下视图:
- 未使用的表
- “无使用记录的表”视图显示 BigQuery 迁移评估在分析的日志时间段内找不到任何使用情况的表。缺少使用可能表示您不需要在迁移过程中将该表转移到 BigQuery,或者将数据存储在 BigQuery 中的费用可能较低。您应验证未使用的表列表,因为它们可能在日志时间段之外使用,例如每三到六个月只使用一次的表。
- 未写入的表
- “未写入的表”视图显示 BigQuery 迁移评估在分析的日志时间段内找不到任何更新的表。缺少写入可能表示您可以降低 BigQuery 的存储费用的位置。
- 低延迟查询
- “低延迟查询”视图根据分析的日志数据显示查询运行时的分布情况。如果查询时长分布图显示大量运行时不到 1 秒的查询,请考虑启用 BigQuery BI Engine 来加快 BI 和其他低延迟工作负载。
- 具体化视图
- 具体化视图提供了进一步优化建议,可提高 BigQuery 的性能。
- 聚类和分区
“分区和聚类”视图显示可通过分区和/或聚类优化的表。
元数据建议是通过分析源数据仓库架构(例如源表中的分区和主键)并找到可以实现类似的优化特征的最接近的 BigQuery 等效项而得出的。
工作负载建议是通过分析源查询日志而得出的。建议通过分析工作负载(尤其是分析的查询日志中的
WHERE或JOIN子句)来确定。- 聚类建议
“分区”视图根据分区限制条件定义显示分区数可能超过 10,000 的表。这些表通常非常适合 BigQuery 聚类,可实现精细的表分区。
- 唯一的限制条件
“唯一的限制条件”视图显示源数据仓库中定义的
SET表和唯一索引。在 BigQuery 中,建议使用暂存表和MERGE语句,以便仅将唯一记录插入目标表。使用此视图的内容可帮助您确定在迁移过程中可能需要调整 ETL 的表。- 默认值/检查限制条件
此视图显示了使用检查限制条件来设置默认列值的表。在 BigQuery 中,请参阅指定默认列值。
报告的迁移路径部分包含以下视图:
- SQL 转换
- “SQL 转换”视图列出了由 BigQuery 迁移评估自动转换且无需人工干预的查询的数量和详细信息。如果提供了元数据,自动化 SQL 转换通常可实现较高的转换速率。此视图是交互式的,可分析常见查询及其转换方式。
- 离线工作
- “离线工作”视图捕获需要人工干预的方面,包括特定 UDF 以及可能存在违反词法结构和语法的表和列。
- BigQuery 预留关键字
- “BigQuery 预留关键字”视图显示检测到使用在 GoogleSQL 语言中具有特殊含义的关键字,除非用反引号 (
`) 字符括起,否则这些关键字不能用作标识符。 - 表更新时间表
- “表更新时间表”视图显示表的更新时间和频率,可帮助您规划迁移方式和时间。
- 将数据迁移到 BigQuery
- “将数据迁移到 BigQuery”视图概述了迁移路径以及使用 BigQuery Data Transfer Service 迁移数据的预期时间。 如需了解详情,请参阅适用于 Teradata 的 BigQuery Data Transfer Service 指南。
“附录”部分包含以下视图:
- 区分大小写
- “区分大小写”视图显示源数据仓库中配置为执行不区分大小写的比较操作的表。 默认情况下,BigQuery 中的字符串比较区分大小写。如需了解详情,请参阅排序规则。
Redshift
- 迁移重要信息
- “迁移重要信息”视图提供报告中三个部分的内容提要 :
- 现有系统面板提供有关数据库、架构、表和现有 Redshift 系统总大小的信息。此外,它还会按大小和可能的次优资源利用率列出架构。您可以使用此信息通过移除表、对表进行分区或聚簇来优化数据。
- BigQuery 稳定状态面板提供有关迁移后数据在 BigQuery 中的外观的信息,包括可使用 BigQuery Migration Service 自动转换的查询数量。 本部分还根据年度数据提取费率显示了在 BigQuery 中存储数据的费用,以及针对表、预配和空间的优化建议。
- 迁移路径面板提供有关迁移工作本身的信息。对于每个表,它都会显示迁移的预期时间、表中的行数及其大小。
现有系统部分包含以下视图:
- 查询(按类型和计划)
- “查询(按类型和计划)”视图将查询分类为 ETL/写入和报告/聚合。了解一段时间内的查询组合有助于您了解现有的使用模式,并识别可能会影响费用和性能的突发性问题和潜在超额预配问题。
- 查询排队
- “查询排队”视图提供有关系统负载的其他详细信息,包括查询量、组合以及排队导致的任何性能影响,例如资源不足。
- 查询和 WLM 扩缩
- “查询和 WLM 扩缩”视图会将并发扩缩识别为一项增加费用和配置复杂性的操作。它显示 Redshift 系统如何根据您指定的规则路由查询,还会显示排队、并发扩缩和逐出查询导致的性能影响。
- 排队和等待
- 通过“排队和等待”视图,可深入了解随时间变化的查询队列和等待时间。
- WLM 类和性能
- “WLM 类和性能”视图提供了将规则映射到 BigQuery 的可选方法。不过,我们建议您让 BigQuery 自动路由您的查询。
- 查询和表量数据洞见
- “查询和表量数据洞见”视图按大小、频率和热门用户列出查询。这有助于您将系统上的负载来源进行分类,并计划如何迁移工作负载。
- 数据库和架构
- “数据库和架构”视图会提供有关源数据仓库系统中定义的大小、表、视图和过程的指标。这使您可以深入了解需要迁移的对象量。
- 表量
- “表量”视图提供最大表和数据库的统计信息,显示它们的访问方式。由于从源数据仓库系统中提取大型表可能需要更长的时间,因此此视图有助于迁移计划和排序。
- 表使用情况
- “表使用情况”视图提供在源数据仓库系统中大量使用的表的统计信息。您可以利用大量使用的表来了解哪些表可能包含许多依赖项,并且需要在迁移过程中进行额外规划。
- 导入工具和导出工具
- “导入工具和导出工具”视图提供有关数据导入(使用
COPY查询)和数据导出(使用UNLOAD查询)所涉及的数据和用户的信息。此视图有助于识别与提取和导出相关的暂存层和流程。 - 集群使用情况
- “集群使用情况”视图提供有关所有可用集群的常规信息,并显示每个集群的 CPU 利用率。此视图可帮助您了解系统容量预留。
BigQuery 稳定状态部分包含以下视图:
- 聚类和分区
“分区和聚类”视图显示可通过分区和/或聚类优化的表。
元数据建议是通过分析源数据仓库架构(例如源表中的排序键和分布键)并找到可以实现类似的优化特征的最接近的 BigQuery 等效项而得出的。
工作负载建议是通过分析源查询日志而得出的。建议通过分析工作负载(尤其是分析的查询日志中的
WHERE或JOIN子句)来确定。页面底部是经过转换的 create table 语句,其中包含提供的所有优化。所有转换后的 DDL 语句也可以从数据集中提取。转换后的 DDL 语句存储在
SchemaConversion表的CreateTableDDL列中。报告中的建议仅适用于大于 1 GB 的表,因为小表不会从聚类和分区中受益。不过,
SchemaConversion表中提供了所有表(包括小于 1 GB 的表)的 DDL。- 未使用的表
“未使用的表”视图显示 BigQuery 迁移评估在分析的日志时间段内找不到任何使用情况的表。缺少使用可能表示您不需要在迁移过程中将该表转移到 BigQuery,或者将数据存储在 BigQuery 中的费用可能较低(按长期存储结算)。您必须验证未使用的表列表,因为它们可能在日志时间段之外使用,例如每三到六个月只使用一次的表。
- 未写入的表
“未写入的表”视图显示 BigQuery 迁移评估在分析的日志时间段内未发现任何更新的表。缺少写入可能表示您可以降低 BigQuery 的存储费用(按长期存储结算)。
- BigQuery BI Engine 和具体化视图
BigQuery BI Engine 和具体化视图提供了进一步的优化建议,可提高 BigQuery 的性能。
迁移路径部分包含以下视图:
- SQL 转换
- “SQL 转换”视图列出了由 BigQuery 迁移评估自动转换且无需人工干预的查询的数量和详细信息。如果提供了元数据,自动化 SQL 转换通常可实现较高的转换速率。
- SQL 转换离线工作
- “SQL 转换离线工作”视图会捕获需要手动干预的领域,包括特定的 UDF 和可能存在转换歧义的查询。
- Alter Table Append 支持
- “Alter Table Append 支持”视图显示了常见 Redshift SQL 结构的详细信息,这些结构没有直接的 BigQuery 对应项。
- 复制命令支持
- “复制命令支持”视图显示了常见 Redshift SQL 结构的详细信息,这些结构没有直接的 BigQuery 对应项。
- SQL 警告
- SQL 警告视图会捕获已成功转换但需要审核的区域。
- 词汇结构和语法违规
- “词汇结构和语法违规”视图会显示违反 BigQuery 语法的列、表、函数和过程的名称。
- BigQuery 预留关键字
- “BigQuery 预留关键字”视图显示检测到使用在 GoogleSQL 语言中具有特殊含义的关键字,除非用反引号 (
`) 字符括起,否则这些关键字不能用作标识符。 - 架构耦合
- “架构耦合”视图提供在单个查询中同时访问的数据库、架构和表的简要视图。此视图可以显示经常引用的表、架构和数据库以及可用于迁移规划的内容。
- 表更新时间表
- “表更新时间表”视图显示表的更新时间和频率,可帮助您规划移动方式和时间。
- 表扩缩
- “表扩缩”视图会列出列数最多的表。
- 将数据迁移到 BigQuery
- “将数据迁移到 BigQuery”视图概述了迁移路径以及使用 BigQuery Migration Service Data Transfer Service 迁移数据的预期时间。如需了解详情,请参阅适用于 Redshift 的 BigQuery Data Transfer Service 指南。
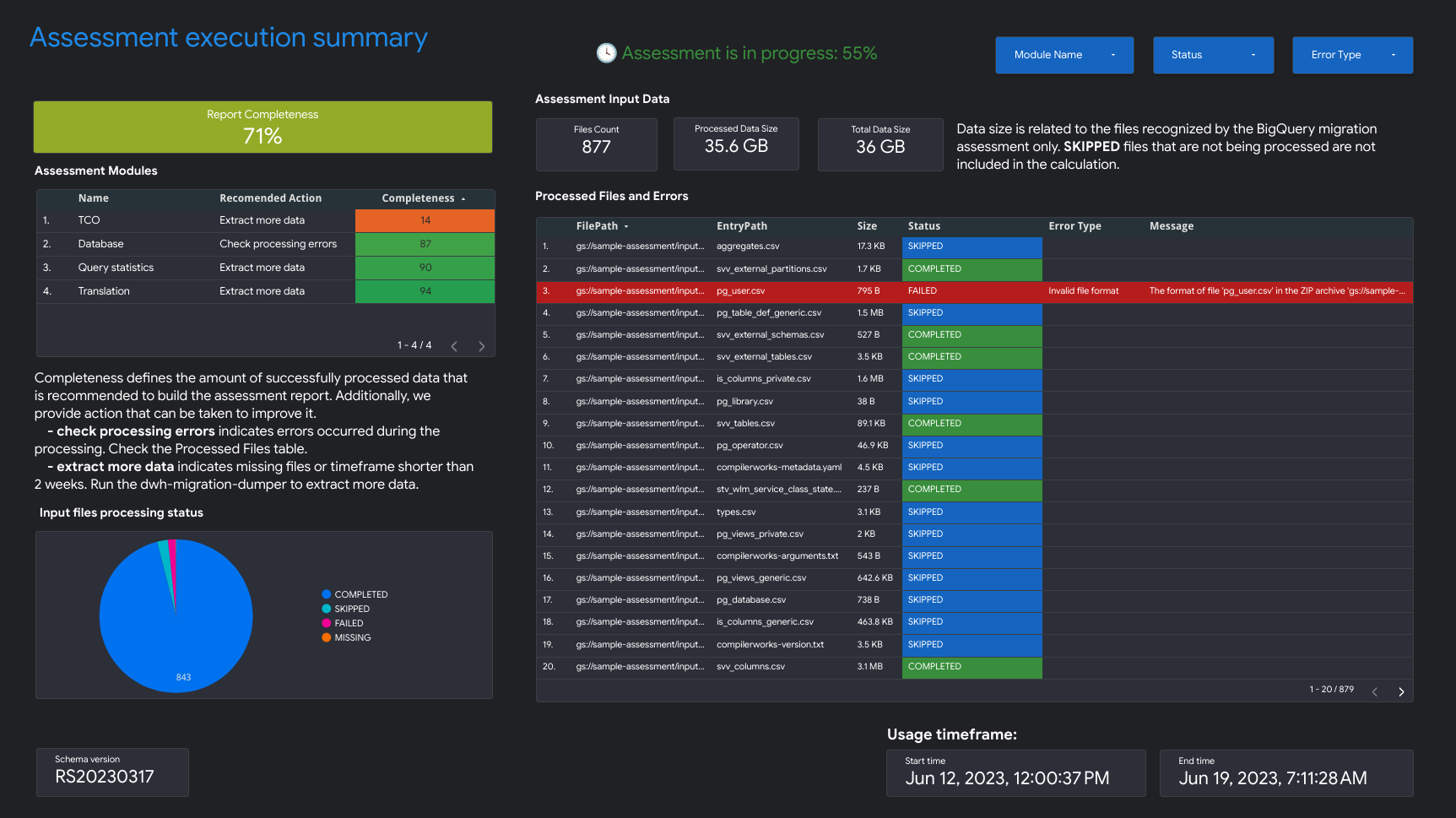
- 评估执行摘要
“评估执行摘要”包含报告完整度、正在进行的评估的进度以及已处理文件和错误的状态。
报告完整度表示在评估报告中显示有意义的数据洞见的成功处理数据所占的百分比。如果报告的某个特定部分缺少数据,则会在评估模块表格中的报告完整度指标下列出此信息。
进度指标表示到目前为止已处理的数据所占的百分比,以及处理所有数据所需的估计剩余时间。处理完成后,系统不会显示进度指标。
Redshift Serverless
- 迁移重要信息
- 此报告页面显示了现有 Amazon Redshift Serverless 数据库的摘要,包括表的大小和数量。此外,它还会提供年化合同价值 (ACV) 的大致估算值,即 BigQuery 中的计算和存储空间费用。“迁移重要信息”视图提供报告中三个部分的摘要。
现有系统部分包含以下视图:
- 数据库和架构
- 提供每个数据库、架构或表的总存储空间大小(以 GB 为单位)的细分数据。
- 外部数据库和架构
- 提供每个外部数据库、架构或表的总存储空间大小(以 GB 为单位)的细分数据。
- 系统利用率
- 提供有关历史系统利用率的常规信息。此视图显示 RPU(Amazon Redshift 处理单元)的历史用量和每日存储空间用量。此视图可帮助您了解系统容量预留。
BigQuery 稳定状态部分提供有关迁移后数据在 BigQuery 中的外观的信息,包括可使用 BigQuery Migration Service 自动转换的查询数量。本部分还根据年度数据注入费率显示了在 BigQuery 中存储数据的费用,以及针对表、预配和空间的优化建议。“稳定状态”部分包含以下视图:
- Amazon Redshift Serverless 与 BigQuery 定价的对比
- 提供 Amazon Redshift Serverless 与 BigQuery 定价模式的比较,以帮助您了解迁移到 BigQuery 后可获得的优势和潜在的节省费用。
- BigQuery 计算费用 (TCO)
- 可让您估算 BigQuery 中的计算费用。该计算器中有四个手动输入项:BigQuery 版本、区域、合约期和基准值。默认情况下,计算器会提供最具成本效益的基准费用承诺,您可以手动替换。
- 总拥有成本
- 可让您估算年化合同价值 (ACV) - BigQuery 中的计算和存储空间费用。您还可以使用该计算器来计算存储空间费用,具体取决于分析时间段内对表的修改情况,活跃存储空间费用和长期存储空间费用各不相同。如需了解详情,请参阅存储价格。
附录部分包含以下视图:
- 评估执行摘要
- 提供评估执行详情,包括已处理文件列表、错误和报告完整度。您可以使用此页面来调查报告中缺失的数据,并更好地了解报告的完整性。
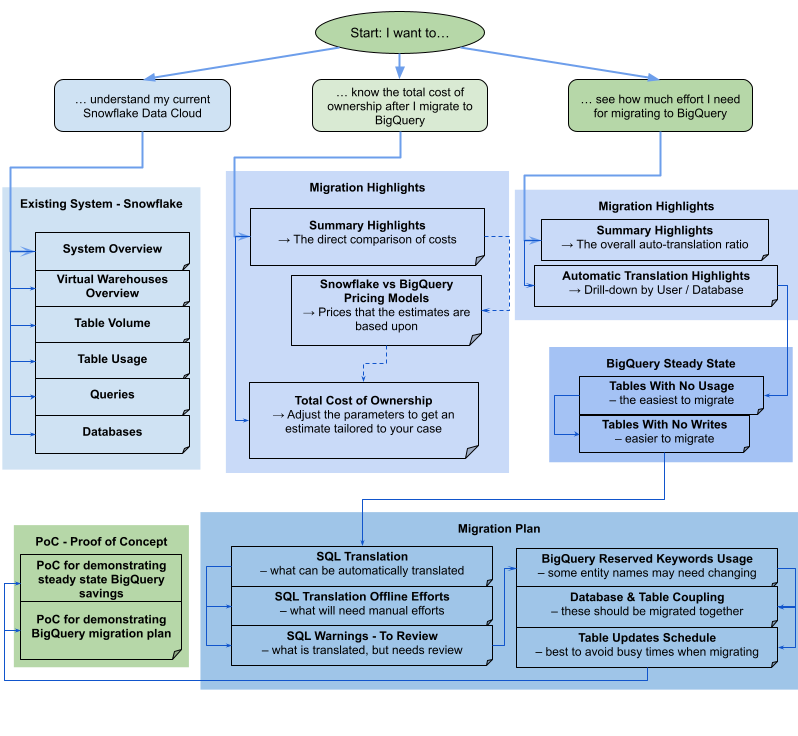
Snowflake
该报告由不同的部分组成,这些部分可以单独使用,也可以一起使用。下图将这些部分归纳为三个常见的用户目标,以帮助您评估迁移需求:
迁移亮点视图
迁移亮点部分包含以下视图:
- Snowflake 与 BigQuery 价格模式的对比
- 不同层级/版本的价格清单。此外,还说明了与 Snowflake 相比,BigQuery 自动扩缩如何帮助节省更多费用。
- 总拥有成本
- 交互式表格,可让用户定义以下内容:BigQuery 版本、承诺、基准槽位承诺、活跃存储空间百分比以及加载或更改的数据百分比。有助于更好地估算自定义用例的费用。
- 自动转换亮点
- 聚合转换比率(按用户或数据库分组,按升序或降序排序)。还包含自动转换失败的最常见错误消息。
现有系统视图
现有系统部分包含以下视图:
- 系统概览
- “系统概览”视图提供指定时间段内现有系统中关键组件的概要指标。评估的时间轴取决于 BigQuery 迁移评估所分析的日志。此视图可让您快速了解源数据仓库的利用率,用于进行迁移规划。
- 虚拟仓库概览
- 显示按数据仓库划分的 Snowflake 费用,以及在该时间段内基于节点的重新缩放情况。
- 表量
- “表量”视图提供有关 BigQuery 迁移评估发现的最大表和数据库的统计信息。由于从源数据仓库系统中提取大型表可能需要更长的时间,因此此视图有助于迁移计划和排序。
- 表使用情况
- “表使用情况”视图提供在源数据仓库系统中大量使用的表的统计信息。大量使用的表可以帮助您了解哪些表可能包含许多依赖项,并且需要在迁移过程中进行额外规划。
- 查询
- “查询”视图细分了执行的 SQL 语句类型及其使用情况的统计信息。您可以使用查询类型和时间的直方图来识别低系统利用率和一天中最佳的时间来传输数据。您还可以使用此视图来识别频繁执行的查询以及调用这些执行的用户。
- 数据库
- “数据库”视图会提供有关源数据仓库系统中定义的大小、表、视图和过程的指标。此视图可让您深入了解您需要迁移的对象量。
BigQuery 稳定状态视图
BigQuery 稳定状态部分包含以下视图:
- 未使用的表
- “无使用记录的表”视图显示 BigQuery 迁移评估在分析的日志时间段内找不到任何使用情况的表。这可以表示在迁移过程中不需要转移到 BigQuery 的表,或者将数据存储在 BigQuery 中的费用可能较低。您必须验证未使用表的列表,因为它们可能在分析的日志时间段之外使用。例如,每个季度或每半年只使用一次的表。
- 未写入的表
- “未写入的表”视图显示 BigQuery 迁移评估在分析的日志时间段内找不到任何更新的表。这表示在 BigQuery 中存储数据的费用可能较低。
迁移计划视图
报告的迁移计划部分包含以下视图:
- SQL 转换
- “SQL 转换”视图列出了由 BigQuery 迁移评估自动转换且无需人工干预的查询的数量和详细信息。如果提供了元数据,自动化 SQL 转换通常可实现较高的转换速率。此视图是交互式的,可分析常见查询及其转换方式。
- SQL 转换离线工作
- “离线工作”视图捕获需要人工干预的方面,包括特定 UDF 以及可能存在违反词法结构和语法的表和列。
- SQL 警告 - 需要审核
- “需要审核的警告”视图会捕获最常转换的区域,但需要一些人工检查。
- BigQuery 预留关键字
- “BigQuery 预留关键字”视图显示检测到使用在 GoogleSQL 语言中具有特殊含义的关键字,除非用反引号 (
`) 字符括起,否则这些关键字不能用作标识符。 - 数据库和表耦合
- “数据库耦合”视图提供在单个查询中同时访问的数据库和表的简要视图。此视图可以显示经常引用的表和数据库以及可用于迁移规划的内容。
- 表更新时间表
- “表更新时间表”视图显示表的更新时间和频率,可帮助您规划迁移方式和时间。
概念验证视图
PoC(概念验证)部分包含以下视图:
- 用于演示稳定状态的 BigQuery 费用节省的 PoC
- 包含最常见的查询、读取数据最多的查询、速度最慢的查询以及受上述查询影响的表。
- 用于演示 BigQuery 迁移方案的 PoC
- 介绍 BigQuery 如何转换最复杂的查询及其影响的表。
Oracle
如需针对此功能请求反馈或支持,请发送邮件至 bq-edw-migration-support@google.com。
迁移重要信息
迁移亮点部分包含以下视图:
- 现有系统:现有 Oracle 系统和使用情况的快照,包括数据库数量、架构、表和总大小(以 GB 为单位)。它还会为每个数据库提供工作负载分类摘要,以帮助您确定 BigQuery 是否是合适的迁移目标。
- 兼容性:提供有关迁移工作本身的信息。对于每个分析过的数据库,它都会显示预计的迁移时间以及可以使用 Google 提供的工具自动迁移的数据库对象数。
- BigQuery 稳定状态:包含有关数据在 BigQuery 上迁移后的外观信息,包括根据您的年度数据注入率在 BigQuery 中存储数据的费用和计算费用估算值。此外,它还可提供有关未充分利用的表的分析数据。
现有系统
现有系统部分包含以下视图:
- 工作负载特征:根据分析的性能指标描述每个数据库的工作负载类型。每个数据库都被归类为 OLAP、混合或 OLTP。这些信息可帮助您决定哪些数据库可以迁移到 BigQuery。
- 数据库和架构:提供每个数据库、架构或表的总存储空间大小(以 GB 为单位)的细分数据。此外,您还可以使用此视图来识别具体化视图和外部表。
- 数据库功能和关联:显示数据库中使用的 Oracle 功能的列表,以及迁移后可使用的 BigQuery 等效功能或服务。此外,您还可以探索数据库链接,以更好地了解数据库之间的关联。
- 数据库连接:提供有关用户或应用启动的数据库会话的数据分析信息。通过分析这些数据,您可以确定在迁移过程中可能需要额外付出努力的外部应用。
- 查询类型:细分了执行的 SQL 语句类型及其使用情况的统计信息。您可以使用查询执行或查询 CPU 时间的每小时直方图来识别低系统利用率和一天中最佳的时间来传输数据。
- PL/SQL 源代码:提供对 PL/SQL 对象(例如函数或过程)以及每个数据库和架构的大小的深入了解。此外,每小时执行次数直方图可用于确定执行大多数 PL/SQL 的峰值时段。
- 系统利用率:提供有关历史系统利用率的常规信息。此视图显示每小时的 CPU 使用情况和每日存储空间用量。此视图可帮助您了解系统容量预留。
BigQuery 稳定状态
BigQuery 稳定状态部分包含以下视图:
- Exadata 与 BigQuery 价格:提供 Exadata 与 BigQuery 价格模式的一般比较,以帮助您了解迁移到 BigQuery 后可获得的优势和潜在的节省费用。
- BigQuery 数据库读取/写入:提供有关数据库物理磁盘操作的分析数据。通过分析这些数据,您可以找到从 Oracle 到 BigQuery 执行数据迁移的最佳时间。
- BigQuery 计算费用:可让您估算 BigQuery 中的计算费用。该计算器中有四个手动输入项:BigQuery 版本、区域、承诺周期和基准值。默认情况下,计算器会提供最具成本效益的基准费用承诺,您可以手动替换。“年度自动扩展槽时数”值提供承诺量以外使用的槽小时数。此值是根据系统利用率计算得出的。本页面末尾提供了基准、自动扩缩和利用率之间的关系的直观解释。每个估算值都会显示可能的数量和估算范围。
- 总拥有成本 (TCO):可让您估算年度合同价值 (ACV) - BigQuery 中的计算和存储空间费用。您还可以使用该计算器来计算存储空间费用。您还可以使用该计算器来计算存储空间费用,具体取决于分析时间段内对表的修改情况,活跃存储空间费用和长期存储空间费用各不相同。如需详细了解存储空间价格,请参阅 Cloud Storage 价格。
- 未充分利用的表:根据分析时间段的使用情况指标,提供有关未使用和只读表的信息。缺少使用可能表示您不需要在迁移过程中将该表转移到 BigQuery,或者将数据存储在 BigQuery 中的费用可能较低(按长期存储结算)。我们建议您验证未使用表的列表,以防它们在分析的时间段之外使用。
迁移提示
迁移提示部分包含以下视图:
- 数据库对象兼容性:简要介绍数据库对象与 BigQuery 的兼容性,包括可以使用 Google 提供的工具自动迁移的对象数量或需要手动操作的对象数量。系统会针对每个数据库、架构和数据库对象类型显示此信息。
- 数据库对象迁移工作量:显示每个数据库、架构或数据库对象类型的迁移工作量估算值(以小时为单位)。此外,它还会根据迁移工作显示小型、中型和大型对象的百分比。
- 数据库架构迁移工作量:提供所有检测到的数据库对象类型的列表、数量、与 BigQuery 的兼容性以及估算的迁移工作量(以小时为单位)。
- 数据库架构迁移工作详情:提供有关数据库架构迁移工作的更深入分析,包括每个对象的信息。
概念验证视图
概念验证视图部分包含以下视图:
- 概念验证迁移:显示迁移工作量最少且适合初始迁移的数据库建议列表。此外,它还会显示热门查询,以便使用概念验证来证明 BigQuery 可节省时间和费用以及具有的价值。
附录
附录部分包含以下视图:
- 评估执行摘要:提供评估执行详情,包括已处理文件列表、错误和报告完整度。您可以使用此页面来调查报告中缺失的数据,并更好地了解报告的整体完整性。
Apache Hive
该报告是由三部分组成的说明,以摘要重要信息页面开头,该页面包含以下部分:
现有系统 - Apache Hive。本部分包含现有 Apache Hive 系统和使用情况(包括数据库数量、表数量、总大小 (GB) 以及处理的查询日志数量)的快照。本部分还按大小列出了数据库并指出了可能的次优资源利用率(没有任何写入或读取次数少的表)和预配。此部分的详细信息包括:
- 计算和查询
- CPU 利用率:
- 具有 CPU 利用率的查询,按小时和天
- 按类型(读/写)分组的查询
- 队列和应用
- 每小时 CPU 利用率与平均每小时查询性能和平均每小时应用性能的叠加
- 按类型和查询时长的查询直方图
- 排队并等待页面
- 队列详细视图(队列、用户、唯一查询、报告与 ETL 细分[按指标])
- CPU 利用率:
- 存储概览
- 按数量、视图和访问速率的数据库
- 包含访问速率的表(按用户、查询、写入和临时表创建)
- 队列和应用:访问速率和客户端 IP 地址
- 计算和查询
BigQuery 稳定状态。此部分介绍了迁移后系统在 BigQuery 中的外观。其中包括有关在 BigQuery 中优化工作负载(并避免浪费)的建议。此部分的详细信息包括:
- 识别为具体化视图候选项的表。
- 基于元数据和使用情况的聚类和分区候选项。
- 识别为 BigQuery BI Engine 候选项的低延迟查询
- 没有读写用量的表。
- 包含数据倾斜的分区表。
迁移计划。本部分提供有关迁移工作本身的信息。例如,从现有系统迁移到 BigQuery 稳定状态。本部分包含每个表的已识别的存储目标,已识别为对迁移有重要意义的表以及自动转换的查询数量。此部分的详细信息包括:
- 包含自动转换的查询的详细视图
- 能够按用户、应用、受影响的表、查询的表和查询类型过滤的查询的总数。
- 具有类似模式的查询存储桶归为一组,这样用户便可按查询类型了解转换理念。
- 需要人工干预的查询
- 违反 BigQuery 词法结构的查询
- 用户定义的函数和过程
- BigQuery 预留关键字
- 需要审核的查询
- 按写入和读取的表时间表(对表进行分组以进行迁移)
- 外部表和代管式表的已识别的存储目标
- 包含自动转换的查询的详细视图
现有系统 - Hive 部分包含以下视图:
- 系统概览
- 此视图提供指定时间段内现有系统中关键组件的概要容量指标。评估的时间轴取决于 BigQuery 迁移评估所分析的日志。此视图可让您快速了解源数据仓库的利用率,用于进行迁移规划。
- 表量
- 此视图提供有关 BigQuery 迁移评估发现的最大表和数据库的统计信息。由于从源数据仓库系统中提取大型表可能需要更长的时间,因此此视图有助于迁移计划和排序。
- 表使用情况
- 此视图提供在源数据仓库系统中大量使用的表的统计信息。大量使用的表可以帮助您了解哪些表可能包含许多依赖项,并且需要在迁移过程中进行额外规划。
- 队列利用率
- 此视图提供在处理日志期间找到的 YARN 队列使用情况的统计信息。这些视图使用户可以了解一段时间内特定队列和应用的使用情况以及对资源使用情况的影响。这些视图还有助于识别要迁移的工作负载并确定其优先级。在迁移期间,请务必直观呈现数据的注入和使用,以更好地了解数据仓库的依赖项,以及分析同时移动各种依赖应用的影响。IP 地址表可用于确定通过 JDBC 连接使用数据仓库的确切应用。
- 队列指标
- 此视图提供了处理日志期间发现的 YARN 队列上不同指标的细分数据。此视图可让用户了解特定队列中的使用模式以及对迁移的影响。您还可以使用此视图来识别查询中访问的表与执行查询的队列之间的关联。
- 排队和等待
- 此视图提供源数据仓库中查询队列时间的数据分析。排队时间表示由于预配不足导致性能下降,额外的预配需要增加硬件和维护费用。
- 查询
- 此视图提供了执行的 SQL 语句类型及其使用情况的细分数据。您可以使用查询类型和时间的直方图来识别低系统利用率和一天中最佳的时间来传输数据。您还可以使用此视图来识别最常用的 Hive 执行引擎、经常执行的查询以及用户详细信息。
- 数据库
- 此视图提供有关源数据仓库系统中定义的大小、表、视图和过程的指标。此视图可让您深入了解您需要迁移的对象量。
- 数据库和表耦合
- 此视图提供在单个查询中同时访问的数据库和表的简要视图。此视图可以显示经常引用的表和数据库以及可用于迁移规划的内容。
BigQuery 稳定状态部分包含以下视图:
- 未使用的表
- “无使用记录的表”视图显示 BigQuery 迁移评估在分析的日志时间段内找不到任何使用情况的表。缺少使用可能表示您不需要在迁移过程中将该表转移到 BigQuery,或者将数据存储在 BigQuery 中的费用可能较低。您必须验证未使用的表列表,因为它们可能在日志时间段之外使用,例如每三到六个月只使用一次的表。
- 未写入的表
- “未写入的表”视图显示 BigQuery 迁移评估在分析的日志时间段内找不到任何更新的表。缺少写入可能表示您可以降低 BigQuery 的存储费用的位置。
- 聚簇和分区建议
此视图显示将受益于分区和/或聚类的表。
元数据建议是通过分析源数据仓库架构(例如源表中的分区和主键)并找到可以实现类似的优化特征的最接近的 BigQuery 等效项而得出的。
工作负载建议是通过分析源查询日志而得出的。建议通过分析工作负载(尤其是分析的查询日志中的
WHERE或JOIN子句)来确定。- 转换为集群的分区
此视图根据分区限制条件定义显示包含的分区数超过 10,000 的表。这些表通常非常适合 BigQuery 聚类,可实现精细的表分区。
- 偏差分区
“偏差分区”视图显示基于元数据分析并且在一个或多个分区上存在数据倾斜的表。这些表非常适合进行架构更改,因为针对偏差分区的查询可能效果不佳。
- BI Engine 和具体化视图
“低延迟查询和具体化视图”视图根据分析的日志数据显示查询运行时的分布情况,并进一步提供优化建议以提升 BigQuery 的性能。如果查询时长分布图显示大量运行时不到 1 秒的查询,请考虑启用 BI Engine 来加快 BI 和其他低延迟工作负载。
报告的迁移计划部分包含以下视图:
- SQL 转换
- “SQL 转换”视图列出了由 BigQuery 迁移评估自动转换且无需人工干预的查询的数量和详细信息。如果提供了元数据,自动化 SQL 转换通常可实现较高的转换速率。此视图是交互式的,可分析常见查询及其转换方式。
- SQL 转换离线工作
- “离线工作”视图捕获需要人工干预的方面,包括特定 UDF 以及可能存在违反词法结构和语法的表和列。
- SQL 警告
- SQL 警告视图会捕获已成功转换但需要审核的区域。
- BigQuery 预留关键字
- “BigQuery 预留关键字”视图显示检测到使用在 GoogleSQL 语言中具有特殊含义的关键字。除非使用反引号 (
`) 字符括起,否则这些关键字不能用作标识符。 - 表更新时间表
- “表更新时间表”视图显示表的更新时间和频率,可帮助您规划迁移方式和时间。
- BigLake 外部表
- “BigLake 外部表”视图概述了识别为要迁移到 BigLake(而非 BigQuery)的目标的表。
报告的附录部分包含以下视图:
- 详细的 SQL 转换离线工作分析
- 详细的离线工作分析视图可让您进一步深入了解需要人工干预的 SQL 区域。
- 详细的 SQL 警告分析
- “详细的警告分析”视图提供已成功转换但需要审核的 SQL 区域的额外数据分析。
共享报告
Looker Studio 报告是迁移评估的前端信息中心。它依赖于底层数据集访问权限。如需共享报告,接收方必须有权访问 Looker 数据洞察报告本身以及包含评估结果的 BigQuery 数据集。
从 Google Cloud 控制台中打开报告时,您将以预览模式查看报告。如需创建报告并与其他用户共享,请执行以下步骤:
- 点击修改和共享。Looker 数据洞察会提示您将新创建的 Looker 数据洞察连接器附加到新报告中。
- 点击添加到报告。该报告会接收单独的报告 ID,您可以使用此 ID 来访问该报告。
- 如需与其他用户共享 Looker 数据洞察报告,请按照与查看者和修改者共享报告中的步骤操作。
- 授予用户查看用于运行评估任务的 BigQuery 数据集的权限。如需了解详情,请参阅授予对数据集的访问权限。
查询迁移评估输出表
虽然 Looker Studio 报告是查看评估结果的最简单方法,但您也可以在 BigQuery 数据集中查看和查询底层数据。
查询示例
以下示例获取唯一查询总数、失败的转换查询数量以及失败的转换的唯一查询百分比。
SELECT QueryCount.v AS QueryCount, ErrorCount.v as ErrorCount, (ErrorCount.v * 100) / QueryCount.v AS FailurePercentage FROM ( SELECT COUNT(*) AS v FROM `your_project.your_dataset.TranslationErrors` WHERE Severity = "ERROR" ) AS ErrorCount, ( SELECT COUNT(DISTINCT(QueryHash)) AS v FROM `your_project.your_dataset.Queries` ) AS QueryCount;
与其他项目中的用户共享数据集
检查数据集后,如果您想与项目外的用户共享,可以利用 BigQuery Sharing(以前称为 Analytics Hub)的发布方工作流程来实现。
在 Google Cloud 控制台中,前往 BigQuery 页面。
点击相应数据集以查看其详细信息。
依次点击共享>以清单形式发布。
在打开的对话框中,按照提示创建清单。
如果您已拥有数据交换,请跳过第 5 步。
创建数据交换并设置权限。如要允许用户在此交换中查看您的清单,请将其添加到订阅者列表中。
输入清单详情。
显示名称是此清单的名称,为必填字段;其他字段为可选字段。
点击发布。
此时会创建非公开清单。
对于您的清单,请选择操作下的更多操作。
点击复制共享链接。
您可以与有权订阅您的交换或清单的用户共享该链接。
评估表架构
如需查看 BigQuery 迁移评估写入 BigQuery 的表及其架构,请选择您的数据仓库:
TeraData
AllRIChildren
下表提供了表子项的参照完整性信息。
| 列 | 类型 | 说明 |
|---|---|---|
IndexId |
INTEGER |
引用索引编号。 |
IndexName |
STRING |
索引的名称。 |
ChildDB |
STRING |
引用数据库的名称,会转换为小写。 |
ChildDBOriginal |
STRING |
引用数据库的名称,保留大小写。 |
ChildTable |
STRING |
引用表的名称,会转换为小写。 |
ChildTableOriginal |
STRING |
引用表的名称,保留大小写。 |
ChildKeyColumn |
STRING |
引用键中的列名称,会转换为小写。 |
ChildKeyColumnOriginal |
STRING |
引用键中的列名称,保留大小写。 |
ParentDB |
STRING |
被引用数据库的名称,会转换为小写。 |
ParentDBOriginal |
STRING |
被引用数据库的名称,保留大小写。 |
ParentTable |
STRING |
被引用表的名称,会转换为小写。 |
ParentTableOriginal |
STRING |
被引用表的名称,保留大小写。 |
ParentKeyColumn |
STRING |
被引用键中的列名称,会转换为小写。 |
ParentKeyColumnOriginal |
STRING |
被引用键中的列名称,保留大小写。 |
AllRIParents
下表提供了表父级的参照完整性信息。
| 列 | 类型 | 说明 |
|---|---|---|
IndexId |
INTEGER |
引用索引编号。 |
IndexName |
STRING |
索引的名称。 |
ChildDB |
STRING |
引用数据库的名称,会转换为小写。 |
ChildDBOriginal |
STRING |
引用数据库的名称,保留大小写。 |
ChildTable |
STRING |
引用表的名称,会转换为小写。 |
ChildTableOriginal |
STRING |
引用表的名称,保留大小写。 |
ChildKeyColumn |
STRING |
引用键中的列名称,会转换为小写。 |
ChildKeyColumnOriginal |
STRING |
引用键中的列名称,保留大小写。 |
ParentDB |
STRING |
被引用数据库的名称,会转换为小写。 |
ParentDBOriginal |
STRING |
被引用数据库的名称,保留大小写。 |
ParentTable |
STRING |
被引用表的名称,会转换为小写。 |
ParentTableOriginal |
STRING |
被引用表的名称,保留大小写。 |
ParentKeyColumn |
STRING |
被引用键中的列名称,会转换为小写。 |
ParentKeyColumnOriginal |
STRING |
被引用键中的列名称,保留大小写。 |
Columns
下表提供了有关列的信息。
| 列 | 类型 | 说明 |
|---|---|---|
DatabaseName |
STRING |
数据库的名称,会转换为小写。 |
DatabaseNameOriginal |
STRING |
数据库的名称,保留大小写。 |
TableName |
STRING |
表名称,会转换为小写。 |
TableNameOriginal |
STRING |
表名称,保留大小写。 |
ColumnName |
STRING |
列名称,会转换为小写。 |
ColumnNameOriginal |
STRING |
列名称,保留大小写。 |
ColumnType |
STRING |
列的 BigQuery 类型,例如 STRING。 |
OriginalColumnType |
STRING |
列的原始类型,例如 VARCHAR。 |
ColumnLength |
INTEGER |
列的最大字节数,例如 VARCHAR(30) 则表示最大字节数为 30。 |
DefaultValue |
STRING |
默认值(如果存在)。 |
Nullable |
BOOLEAN |
列是否可以为 null。 |
DiskSpace
下表提供了有关每个数据库的磁盘空间使用情况的信息。
| 列 | 类型 | 说明 |
|---|---|---|
DatabaseName |
STRING |
数据库的名称,会转换为小写。 |
DatabaseNameOriginal |
STRING |
数据库的名称,保留大小写。 |
MaxPerm |
INTEGER |
分配给永久空间的最大字节数。 |
MaxSpool |
INTEGER |
分配给假脱机空间的最大字节数。 |
MaxTemp |
INTEGER |
分配给临时空间的最大字节数。 |
CurrentPerm |
INTEGER |
分配给永久空间的字节数。 |
CurrentSpool |
INTEGER |
分配给假脱机空间的字节数。 |
CurrentTemp |
INTEGER |
分配给临时空间的字节数。 |
PeakPerm |
INTEGER |
自上次重置永久空间以来使用的峰值字节数。 |
PeakSpool |
INTEGER |
自上次重置假脱机空间以来使用的峰值字节数。 |
PeakPersistentSpool |
INTEGER |
自上次重置永久性空间以来使用的峰值字节数。 |
PeakTemp |
INTEGER |
自上次重置临时空间以来使用的峰值字节数。 |
MaxProfileSpool |
INTEGER |
用户的假脱机空间限制。 |
MaxProfileTemp |
INTEGER |
用户的临时空间限制。 |
AllocatedPerm |
INTEGER |
当前分配的永久空间。 |
AllocatedSpool |
INTEGER |
当前分配的假脱机空间。 |
AllocatedTemp |
INTEGER |
当前分配的临时空间。 |
Functions
下表提供了有关函数的信息。
| 列 | 类型 | 说明 |
|---|---|---|
DatabaseName |
STRING |
数据库的名称,会转换为小写。 |
DatabaseNameOriginal |
STRING |
数据库的名称,保留大小写。 |
FunctionName |
STRING |
函数的名称。 |
LanguageName |
STRING |
语言的名称。 |
Indices
此表提供有关索引的信息。
| 列 | 类型 | 说明 |
|---|---|---|
DatabaseName |
STRING |
数据库的名称,会转换为小写。 |
DatabaseNameOriginal |
STRING |
数据库的名称,保留大小写。 |
TableName |
STRING |
表名称,会转换为小写。 |
TableNameOriginal |
STRING |
表名称,保留大小写。 |
IndexName |
STRING |
索引的名称。 |
ColumnName |
STRING |
列名称,会转换为小写。 |
ColumnNameOriginal |
STRING |
列名称,保留大小写。 |
OrdinalPosition |
INTEGER |
列的位置。 |
UniqueFlag |
BOOLEAN |
指示索引是否强制执行唯一性。 |
Queries
此表提供有关提取的查询的信息。
| 列 | 类型 | 说明 |
|---|---|---|
QueryHash |
STRING |
查询的哈希。 |
QueryText |
STRING |
查询的文本。 |
QueryLogs
此表提供有关提取的查询的一些执行统计信息。
| 列 | 类型 | 说明 |
|---|---|---|
QueryText |
STRING |
查询的文本。 |
QueryHash |
STRING |
查询的哈希。 |
QueryId |
STRING |
查询的 ID。 |
QueryType |
STRING |
查询的类型,即 Query 或 DDL。 |
UserId |
BYTES |
执行查询的用户的 ID。 |
UserName |
STRING |
执行查询的用户的名称。 |
StartTime |
TIMESTAMP |
提交查询时的时间戳。 |
Duration |
STRING |
查询的时长(以毫秒为单位)。 |
AppId |
STRING |
执行查询的应用的 ID。 |
ProxyUser |
STRING |
通过中间层级使用的代理用户。 |
ProxyRole |
STRING |
通过中间层级使用的代理角色。 |
QueryTypeStatistics
此表提供有关查询类型的统计信息。
| 列 | 类型 | 说明 |
|---|---|---|
QueryHash |
STRING |
查询的哈希。 |
QueryType |
STRING |
查询的类型。 |
UpdatedTable |
STRING |
查询更新的表(如果有)。 |
QueriedTables |
ARRAY<STRING> |
查询的表列表。 |
ResUsageScpu
下表提供了有关 CPU 资源使用情况的信息。
| 列 | 类型 | 说明 |
|---|---|---|
EventTime |
TIMESTAMP |
事件发生的时间。 |
NodeId |
INTEGER |
节点 ID |
CabinetId |
INTEGER |
节点的物理机柜编号。 |
ModuleId |
INTEGER |
节点的物理模块编号。 |
NodeType |
STRING |
节点类型。 |
CpuId |
INTEGER |
此节点中的 CPU ID。 |
MeasurementPeriod |
INTEGER |
测量周期(以毫秒表示)。 |
SummaryFlag |
STRING |
S - 摘要行,N - 非摘要行 |
CpuFrequency |
FLOAT |
CPU 频率(以 MHz 为单位)。 |
CpuIdle |
FLOAT |
CPU 空闲时间(以毫秒表示)。 |
CpuIoWait |
FLOAT |
CPU 等待 I/O 的时间(以毫秒表示)。 |
CpuUServ |
FLOAT |
CPU 执行用户代码的时间(以毫秒表示)。 |
CpuUExec |
FLOAT |
CPU 执行服务代码的时间(以毫秒表示)。 |
Roles
下表提供了角色的相关信息。
| 列 | 类型 | 说明 |
|---|---|---|
RoleName |
STRING |
角色的名称。 |
Grantor |
STRING |
授予角色的数据库的名称。 |
Grantee |
STRING |
被授予角色的用户。 |
WhenGranted |
TIMESTAMP |
授予角色的时间。 |
WithAdmin |
BOOLEAN |
是否为所授予的角色设置管理员选项。 |
SchemaConversion
此表提供有关与聚簇和分区相关的架构转换的信息。
| 列名 | 列类型 | 说明 |
|---|---|---|
DatabaseName |
STRING |
针对其提供建议的源数据库的名称。数据库映射到 BigQuery 中的数据集。 |
TableName |
STRING |
针对其提供建议的表的名称。 |
PartitioningColumnName |
STRING |
BigQuery 中建议的分区列的名称。 |
ClusteringColumnNames |
ARRAY |
BigQuery 中建议的聚簇列的名称。 |
CreateTableDDL |
STRING |
用于在 BigQuery 中创建表的 CREATE TABLE statement。 |
TableInfo
此表提供表的相关信息。
| 列 | 类型 | 说明 |
|---|---|---|
DatabaseName |
STRING |
数据库的名称,会转换为小写。 |
DatabaseNameOriginal |
STRING |
数据库的名称,保留大小写。 |
TableName |
STRING |
表名称,会转换为小写。 |
TableNameOriginal |
STRING |
表名称,保留大小写。 |
LastAccessTimestamp |
TIMESTAMP |
上次访问表的时间。 |
LastAlterTimestamp |
TIMESTAMP |
上次更改表的时间。 |
TableKind |
STRING |
表的类型。 |
TableRelations
此表提供表的相关信息。
| 列 | 类型 | 说明 |
|---|---|---|
QueryHash |
STRING |
已建立关系的查询的哈希值。 |
DatabaseName1 |
STRING |
第一个数据库的名称。 |
TableName1 |
STRING |
第一个表的名称。 |
DatabaseName2 |
STRING |
第二个数据库的名称。 |
TableName2 |
STRING |
第二个表的名称。 |
Relation |
STRING |
两个表之间的关系类型。 |
TableSizes
下表提供了表大小的相关信息。
| 列 | 类型 | 说明 |
|---|---|---|
DatabaseName |
STRING |
数据库的名称,会转换为小写。 |
DatabaseNameOriginal |
STRING |
数据库的名称,保留大小写。 |
TableName |
STRING |
表名称,会转换为小写。 |
TableNameOriginal |
STRING |
表名称,保留大小写。 |
TableSizeInBytes |
INTEGER |
表的大小(以字节为单位)。 |
Users
下表提供了用户的相关信息。
| 列 | 类型 | 说明 |
|---|---|---|
UserName |
STRING |
用户的名称。 |
CreatorName |
STRING |
创建此用户的实体的名称。 |
CreateTimestamp |
TIMESTAMP |
创建此用户时的时间戳。 |
LastAccessTimestamp |
TIMESTAMP |
此用户上次访问数据库时的时间戳。 |
Redshift
Columns
Columns 表来自以下某个表:SVV_COLUMNS、INFORMATION_SCHEMA.COLUMNS 或 PG_TABLE_DEF(按优先级排序)。该工具首先尝试从优先级最高的表加载数据。如果此操作失败,则它会尝试从下一个优先级最高的表加载数据。如需详细了解架构和使用情况,请参阅 Amazon Redshift 或 PostgreSQL 文档。
| 列 | 类型 | 说明 |
|---|---|---|
DatabaseName |
STRING |
数据库的名称。 |
SchemaName |
STRING |
架构的名称。 |
TableName |
STRING |
表的名称。 |
ColumnName |
STRING |
列的名称。 |
DefaultValue |
STRING |
默认值(如有)。 |
Nullable |
BOOLEAN |
列是否可以具有 null 值。 |
ColumnType |
STRING |
列的类型,例如 VARCHAR。 |
ColumnLength |
INTEGER |
列的大小,例如 30 表示 VARCHAR(30)。 |
CreateAndDropStatistic
下表提供了有关创建和删除表的信息。
| 列 | 类型 | 说明 |
|---|---|---|
QueryHash |
STRING |
查询的哈希。 |
DefaultDatabase |
STRING |
默认数据库。 |
EntityType |
STRING |
实体的类型,例如 TABLE。 |
EntityName |
STRING |
实体的名称。 |
Operation |
STRING |
操作:CREATE 或 DROP。 |
Databases
该表直接来自 Amazon Redshift 中的 PG_DATABASE_INFO 表。PG 表中的原始字段名称包含在说明中。如需详细了解架构和使用情况,请参阅 Amazon Redshift 和 PostgreSQL 文档。
| 列 | 类型 | 说明 |
|---|---|---|
DatabaseName |
STRING |
数据库的名称。来源名称:datname |
Owner |
STRING |
数据库所有者。例如,创建数据库的用户。来源名称:datdba |
ExternalColumns
该表包含直接来自 Amazon Redshift 的 SVV_EXTERNAL_COLUMNS 表中的信息。如需详细了解架构和使用情况,请参阅 Amazon Redshift 文档。
| 列 | 类型 | 说明 |
|---|---|---|
SchemaName |
STRING |
外部架构名称。 |
TableName |
STRING |
外部表名称。 |
ColumnName |
STRING |
外部列名称。 |
ColumnType |
STRING |
列的类型。 |
Nullable |
BOOLEAN |
列是否可以具有 null 值。 |
ExternalDatabases
该表包含直接来自 Amazon Redshift 的 SVV_EXTERNAL_DATABASES 表中的信息。如需详细了解架构和使用情况,请参阅 Amazon Redshift 文档。
| 列 | 类型 | 说明 |
|---|---|---|
DatabaseName |
STRING |
外部数据库名称。 |
Location |
STRING |
数据库的位置。 |
ExternalPartitions
该表包含直接来自 Amazon Redshift 的 SVV_EXTERNAL_PARTITIONS 表中的信息。如需详细了解架构和使用情况,请参阅 Amazon Redshift 文档。
| 列 | 类型 | 说明 |
|---|---|---|
SchemaName |
STRING |
外部架构名称。 |
TableName |
STRING |
外部表名称。 |
Location |
STRING |
分区的位置。列大小不得超过 128 个字符。较长的值会被截断。 |
ExternalSchemas
该表包含直接来自 Amazon Redshift 的 SVV_EXTERNAL_SCHEMAS 表中的信息。如需详细了解架构和使用情况,请参阅 Amazon Redshift 文档。
| 列 | 类型 | 说明 |
|---|---|---|
SchemaName |
STRING |
外部架构名称。 |
DatabaseName |
STRING |
外部数据库名称。 |
ExternalTables
该表包含直接来自 Amazon Redshift 的 SVV_EXTERNAL_TABLES 表中的信息。如需详细了解架构和使用情况,请参阅 Amazon Redshift 文档。
| 列 | 类型 | 说明 |
|---|---|---|
SchemaName |
STRING |
外部架构名称。 |
TableName |
STRING |
外部表名称。 |
Functions
该表包含直接来自 Amazon Redshift 的 PG_PROC 表中的信息。如需详细了解架构和使用情况,请参阅 Amazon Redshift 和 PostgreSQL 文档。
| 列 | 类型 | 说明 |
|---|---|---|
SchemaName |
STRING |
架构的名称。 |
FunctionName |
STRING |
函数的名称。 |
LanguageName |
STRING |
此函数的实现语言或调用接口。 |
Queries
此表是使用 QueryLogs 表中的信息生成的。与 QueryLogs 表不同,Queries 表中的每一行都包含一个存储在 QueryText 列中的查询语句。 该表提供了用于生成统计信息表和转换输出的源数据。
| 列 | 类型 | 说明 |
|---|---|---|
QueryText |
STRING |
查询的文本。 |
QueryHash |
STRING |
查询的哈希。 |
QueryLogs
下表提供了有关查询执行的信息。
| 列 | 类型 | 说明 |
|---|---|---|
QueryText |
STRING |
查询的文本。 |
QueryHash |
STRING |
查询的哈希。 |
QueryID |
STRING |
查询的 ID。 |
UserID |
STRING |
用户的 ID。 |
StartTime |
TIMESTAMP |
开始时间。 |
Duration |
INTEGER |
持续时间(以毫秒为单位)。 |
QueryTypeStatistics
| 列 | 类型 | 说明 |
|---|---|---|
QueryHash |
STRING |
查询的哈希。 |
DefaultDatabase |
STRING |
默认数据库。 |
QueryType |
STRING |
查询的类型。 |
UpdatedTable |
STRING |
已更新的表。 |
QueriedTables |
ARRAY<STRING> |
查询的表。 |
TableInfo
该表包含从 Amazon Redshift 中的 SVV_TABLE_INFO 表中提取的信息。
| 列 | 类型 | 说明 |
|---|---|---|
DatabaseName |
STRING |
数据库的名称。 |
SchemaName |
STRING |
架构的名称。 |
TableId |
INTEGER |
表 ID。 |
TableName |
STRING |
表的名称。 |
SortKey1 |
STRING |
排序键中的第一列。 |
SortKeyNum |
INTEGER |
定义为排序键的列数。 |
MaxVarchar |
INTEGER |
使用 VARCHAR 数据类型的最大列的大小。 |
Size |
INTEGER |
表的大小,以 1 MB 数据块为单位。 |
TblRows |
INTEGER |
表中的总行数。 |
TableRelations
| 列 | 类型 | 说明 |
|---|---|---|
QueryHash |
STRING |
已建立关系的查询(例如,JOIN 查询)的哈希值。 |
DefaultDatabase |
STRING |
默认数据库。 |
TableName1 |
STRING |
关系的第一个表。 |
TableName2 |
STRING |
关系的第二个表。 |
Relation |
STRING |
关系的种类。采用以下值之一:COMMA_JOIN、CROSS_JOIN、FULL_OUTER_JOIN、INNER_JOIN、LEFT_OUTER_JOIN、RIGHT_OUTER_JOIN、CREATED_FROM 或 INSERT_INTO。 |
Count |
INTEGER |
观察到这种关系的频率。 |
TableSizes
下表提供了有关表大小的信息。
| 列 | 类型 | 说明 |
|---|---|---|
DatabaseName |
STRING |
数据库的名称。 |
SchemaName |
STRING |
架构的名称。 |
TableName |
STRING |
表的名称。 |
TableSizeInBytes |
INTEGER |
表的大小(以字节为单位)。 |
Tables
该表包含从 Amazon Redshift 的 SVV_TABLES 表中提取的信息。如需详细了解架构和使用情况,请参阅 Amazon Redshift 文档。
| 列 | 类型 | 说明 |
|---|---|---|
DatabaseName |
STRING |
数据库的名称。 |
SchemaName |
STRING |
架构的名称。 |
TableName |
STRING |
表的名称。 |
TableType |
STRING |
表的类型。 |
TranslatedQueries
下表提供了查询转换。
| 列 | 类型 | 说明 |
|---|---|---|
QueryHash |
STRING |
查询的哈希。 |
TranslatedQueryText |
STRING |
从源方言转换为 GoogleSQL 的结果。 |
TranslationErrors
下表提供了有关查询转换错误的信息。
| 列 | 类型 | 说明 |
|---|---|---|
QueryHash |
STRING |
查询的哈希。 |
Severity |
STRING |
错误的严重程度,例如 ERROR。 |
Category |
STRING |
错误类别,例如 AttributeNotFound。 |
Message |
STRING |
包含错误详情的消息。 |
LocationOffset |
INTEGER |
错误位置的字符位置。 |
LocationLine |
INTEGER |
错误的行号。 |
LocationColumn |
INTEGER |
错误的列号。 |
LocationLength |
INTEGER |
错误位置的字符长度。 |
UserTableRelations
| 列 | 类型 | 说明 |
|---|---|---|
UserID |
STRING |
用户 ID。 |
TableName |
STRING |
表的名称。 |
Relation |
STRING |
关系。 |
Count |
INTEGER |
数量。 |
Users
该表包含从 Amazon Redshift 的 PG_USER 表中提取的信息。如需详细了解架构和使用情况,请参阅 PostgreSQL 文档。
| 列 | 类型 | 说明 | |
|---|---|---|---|
UserName |
STRING |
用户的名称。 | |
UserId |
STRING |
用户 ID。 |
Snowflake
Warehouses
| 列 | 类型 | 说明 | 状态 |
|---|---|---|---|
WarehouseName |
STRING |
仓库的名称。 | 总是 |
State |
STRING |
仓库的状态。可能的值:STARTED、SUSPENDED、RESIZING。 |
总是 |
Type |
STRING |
仓库类型。可能的值:STANDARD、SNOWPARK-OPTIMIZED。 |
总是 |
Size |
STRING |
仓库的大小。可能的值:X-Small、Small、Medium、Large、X-Large、2X-Large … 6X-Large。 |
总是 |
Databases
| 列 | 类型 | 说明 | 状态 |
|---|---|---|---|
DatabaseNameOriginal |
STRING |
数据库的名称,保留大小写。 | 总是 |
DatabaseName |
STRING |
数据库的名称,会转换为小写。 | 总是 |
Schemata
| 列 | 类型 | 说明 | 状态 |
|---|---|---|---|
DatabaseNameOriginal |
STRING |
架构所属数据库的名称,保留大小写。 | 总是 |
DatabaseName |
STRING |
架构所属数据库的名称,转换为小写。 | 总是 |
SchemaNameOriginal |
STRING |
架构的名称,保留大小写。 | 总是 |
SchemaName |
STRING |
架构的名称,转换为小写。 | 总是 |
Tables
| 列 | 类型 | 说明 | 状态 |
|---|---|---|---|
DatabaseNameOriginal |
STRING |
表所属数据库的名称,保留大小写。 | 总是 |
DatabaseName |
STRING |
表所属数据库的名称,会转换为小写。 | 总是 |
SchemaNameOriginal |
STRING |
表所属架构的名称,保留大小写。 | 总是 |
SchemaName |
STRING |
表所属架构的名称,转换为小写。 | 总是 |
TableNameOriginal |
STRING |
表名称,保留大小写。 | 总是 |
TableName |
STRING |
表名称,会转换为小写。 | 总是 |
TableType |
STRING |
表类型(视图/具体化视图/基表)。 | 总是 |
RowCount |
BIGNUMERIC |
表中的行数。 | 总是 |
Columns
| 列 | 类型 | 说明 | 状态 |
|---|---|---|---|
DatabaseName |
STRING |
数据库的名称,会转换为小写。 | 总是 |
DatabaseNameOriginal |
STRING |
数据库的名称,保留大小写。 | 总是 |
SchemaName |
STRING |
架构的名称,转换为小写。 | 总是 |
SchemaNameOriginal |
STRING |
架构的名称,保留大小写。 | 总是 |
TableName |
STRING |
表名称,会转换为小写。 | 总是 |
TableNameOriginal |
STRING |
表名称,保留大小写。 | 总是 |
ColumnName |
STRING |
列名称,会转换为小写。 | 总是 |
ColumnNameOriginal |
STRING |
列名称,保留大小写。 | 总是 |
ColumnType |
STRING |
列的类型。 | 总是 |
CreateAndDropStatistics
| 列 | 类型 | 说明 | 状态 |
|---|---|---|---|
QueryHash |
STRING |
查询的哈希。 | 总是 |
DefaultDatabase |
STRING |
默认数据库。 | 总是 |
EntityType |
STRING |
实体的类型,例如 TABLE。 |
总是 |
EntityName |
STRING |
实体的名称。 | 总是 |
Operation |
STRING |
操作:CREATE 或 DROP。 |
总是 |
Queries
| 列 | 类型 | 说明 | 状态 |
|---|---|---|---|
QueryText |
STRING |
查询的文本。 | 总是 |
QueryHash |
STRING |
查询的哈希。 | 总是 |
QueryLogs
| 列 | 类型 | 说明 | 状态 |
|---|---|---|---|
QueryText |
STRING |
查询的文本。 | 总是 |
QueryHash |
STRING |
查询的哈希。 | 总是 |
QueryID |
STRING |
查询的 ID。 | 总是 |
UserID |
STRING |
用户的 ID。 | 总是 |
StartTime |
TIMESTAMP |
开始时间。 | 总是 |
Duration |
INTEGER |
持续时间(以毫秒为单位)。 | 总是 |
QueryTypeStatistics
| 列 | 类型 | 说明 | 状态 |
|---|---|---|---|
QueryHash |
STRING |
查询的哈希。 | 总是 |
DefaultDatabase |
STRING |
默认数据库。 | 总是 |
QueryType |
STRING |
查询的类型。 | 总是 |
UpdatedTable |
STRING |
已更新的表。 | 总是 |
QueriedTables |
REPEATED STRING |
查询的表。 | 总是 |
TableRelations
| 列 | 类型 | 说明 | 状态 |
|---|---|---|---|
QueryHash |
STRING |
已建立关系的查询(例如,JOIN 查询)的哈希值。 |
总是 |
DefaultDatabase |
STRING |
默认数据库。 | 总是 |
TableName1 |
STRING |
关系的第一个表。 | 总是 |
TableName2 |
STRING |
关系的第二个表。 | 总是 |
Relation |
STRING |
关系的种类。 | 总是 |
Count |
INTEGER |
观察到这种关系的频率。 | 总是 |
TranslatedQueries
| 列 | 类型 | 说明 | 状态 |
|---|---|---|---|
QueryHash |
STRING |
查询的哈希。 | 总是 |
TranslatedQueryText |
STRING |
从源方言转换为 BigQuery SQL 的结果。 | 总是 |
TranslationErrors
| 列 | 类型 | 说明 | 状态 |
|---|---|---|---|
QueryHash |
STRING |
查询的哈希。 | 总是 |
Severity |
STRING |
错误的严重程度,例如 ERROR。 |
总是 |
Category |
STRING |
错误类别,例如 AttributeNotFound。 |
总是 |
Message |
STRING |
包含错误详情的消息。 | 总是 |
LocationOffset |
INTEGER |
错误位置的字符位置。 | 总是 |
LocationLine |
INTEGER |
错误的行号。 | 总是 |
LocationColumn |
INTEGER |
错误的列号。 | 总是 |
LocationLength |
INTEGER |
错误位置的字符长度。 | 总是 |
UserTableRelations
| 列 | 类型 | 说明 | 状态 |
|---|---|---|---|
UserID |
STRING |
用户 ID。 | 总是 |
TableName |
STRING |
表的名称。 | 总是 |
Relation |
STRING |
关系。 | 总是 |
Count |
INTEGER |
数量。 | 总是 |
Apache Hive
Columns
下表提供了有关列的信息:
| 列 | 类型 | 说明 |
|---|---|---|
DatabaseName |
STRING |
数据库的名称,保留大小写。 |
TableName |
STRING |
表名称,保留大小写。 |
ColumnName |
STRING |
列名称,保留大小写。 |
ColumnType |
STRING |
列的 BigQuery 类型,例如 STRING。 |
OriginalColumnType |
STRING |
列的原始类型,例如 VARCHAR。 |
CreateAndDropStatistic
下表提供了有关创建和删除表的信息:
| 列 | 类型 | 说明 |
|---|---|---|
QueryHash |
STRING |
查询的哈希。 |
DefaultDatabase |
STRING |
默认数据库。 |
EntityType |
STRING |
实体的类型,例如 TABLE。 |
EntityName |
STRING |
实体的名称。 |
Operation |
STRING |
对表执行的操作(CREATE 或 DROP)。 |
Databases
下表提供了有关数据库的信息:
| 列 | 类型 | 说明 |
|---|---|---|
DatabaseName |
STRING |
数据库的名称,保留大小写。 |
Owner |
STRING |
数据库所有者。例如,创建数据库的用户。 |
Location |
STRING |
数据库在文件系统中的位置。 |
Functions
下表提供了有关函数的信息:
| 列 | 类型 | 说明 |
|---|---|---|
DatabaseName |
STRING |
数据库的名称,保留大小写。 |
FunctionName |
STRING |
函数的名称。 |
LanguageName |
STRING |
语言的名称。 |
ClassName |
STRING |
函数的类名称。 |
ObjectReferences
下表提供有关查询中引用的对象的信息:
| 列 | 类型 | 说明 |
|---|---|---|
QueryHash |
STRING |
查询的哈希。 |
DefaultDatabase |
STRING |
默认数据库。 |
Clause |
STRING |
显示对象的子句。例如 SELECT。 |
ObjectName |
STRING |
对象的名称。 |
Type |
STRING |
对象的类型。 |
Subtype |
STRING |
对象的子类型。 |
PartitionKeys
下表提供了分区键的相关信息:
| 列 | 类型 | 说明 |
|---|---|---|
DatabaseName |
STRING |
数据库的名称,保留大小写。 |
TableName |
STRING |
表名称,保留大小写。 |
ColumnName |
STRING |
列名称,保留大小写。 |
ColumnType |
STRING |
列的 BigQuery 类型,例如 STRING。 |
Partitions
下表提供了有关表分区的信息:
| 列 | 类型 | 说明 |
|---|---|---|
DatabaseName |
STRING |
数据库的名称,保留大小写。 |
TableName |
STRING |
表名称,保留大小写。 |
PartitionName |
STRING |
分区的名称。 |
CreateTimestamp |
TIMESTAMP |
创建此分区时的时间戳。 |
LastAccessTimestamp |
TIMESTAMP |
上次访问此分区时的时间戳。 |
LastDdlTimestamp |
TIMESTAMP |
上次更改此分区时的时间戳。 |
TotalSize |
INTEGER |
分区的压缩大小(以字节为单位)。 |
Queries
此表是使用 QueryLogs 表中的信息生成的。与 QueryLogs 表不同,Queries 表中的每一行都包含一个存储在 QueryText 列中的查询语句。该表提供了用于生成统计信息表和转换输出的源数据:
| 列 | 类型 | 说明 |
|---|---|---|
QueryHash |
STRING |
查询的哈希。 |
QueryText |
STRING |
查询的文本。 |
QueryLogs
此表提供有关提取的查询的一些执行统计信息:
| 列 | 类型 | 说明 |
|---|---|---|
QueryText |
STRING |
查询的文本。 |
QueryHash |
STRING |
查询的哈希。 |
QueryId |
STRING |
查询的 ID。 |
QueryType |
STRING |
查询的类型,Query 或 DDL。 |
UserName |
STRING |
执行查询的用户的名称。 |
StartTime |
TIMESTAMP |
提交查询时的时间戳。 |
Duration |
STRING |
查询的时长(以毫秒为单位)。 |
QueryTypeStatistics
此表提供有关查询类型的统计信息:
| 列 | 类型 | 说明 |
|---|---|---|
QueryHash |
STRING |
查询的哈希。 |
QueryType |
STRING |
查询的类型。 |
UpdatedTable |
STRING |
查询更新的表(如果有)。 |
QueriedTables |
ARRAY<STRING> |
查询的表列表。 |
QueryTypes
此表提供有关查询类型的统计信息:
| 列 | 类型 | 说明 |
|---|---|---|
QueryHash |
STRING |
查询的哈希。 |
Category |
STRING |
查询的类别。 |
Type |
STRING |
查询的类型。 |
Subtype |
STRING |
查询的子类型。 |
SchemaConversion
此表提供有关与聚类和分区相关的架构转换的信息:
| 列名 | 列类型 | 说明 |
|---|---|---|
DatabaseName |
STRING |
针对其提供建议的源数据库的名称。数据库映射到 BigQuery 中的数据集。 |
TableName |
STRING |
针对其提供建议的表的名称。 |
PartitioningColumnName |
STRING |
BigQuery 中建议的分区列的名称。 |
ClusteringColumnNames |
ARRAY |
BigQuery 中建议的聚簇列的名称。 |
CreateTableDDL |
STRING |
用于在 BigQuery 中创建表的 CREATE TABLE statement。 |
TableRelations
此表提供表的相关信息:
| 列 | 类型 | 说明 |
|---|---|---|
QueryHash |
STRING |
已建立关系的查询的哈希值。 |
DatabaseName1 |
STRING |
第一个数据库的名称。 |
TableName1 |
STRING |
第一个表的名称。 |
DatabaseName2 |
STRING |
第二个数据库的名称。 |
TableName2 |
STRING |
第二个表的名称。 |
Relation |
STRING |
两个表之间的关系类型。 |
TableSizes
下表提供了表大小的相关信息:
| 列 | 类型 | 说明 |
|---|---|---|
DatabaseName |
STRING |
数据库的名称,保留大小写。 |
TableName |
STRING |
表名称,保留大小写。 |
TotalSize |
INTEGER |
表的大小(以字节为单位)。 |
Tables
此表提供表的相关信息:
| 列 | 类型 | 说明 |
|---|---|---|
DatabaseName |
STRING |
数据库的名称,保留大小写。 |
TableName |
STRING |
表名称,保留大小写。 |
Type |
STRING |
表的类型。 |
TranslatedQueries
下表提供了查询转换:
| 列 | 类型 | 说明 |
|---|---|---|
QueryHash |
STRING |
查询的哈希。 |
TranslatedQueryText |
STRING |
从源方言转换为 GoogleSQL 的结果。 |
TranslationErrors
下表提供了有关查询转换错误的信息:
| 列 | 类型 | 说明 |
|---|---|---|
QueryHash |
STRING |
查询的哈希。 |
Severity |
STRING |
错误的严重程度,例如 ERROR。 |
Category |
STRING |
错误类别,例如 AttributeNotFound。 |
Message |
STRING |
包含错误详情的消息。 |
LocationOffset |
INTEGER |
错误位置的字符位置。 |
LocationLine |
INTEGER |
错误的行号。 |
LocationColumn |
INTEGER |
错误的列号。 |
LocationLength |
INTEGER |
错误位置的字符长度。 |
UserTableRelations
| 列 | 类型 | 说明 |
|---|---|---|
UserID |
STRING |
用户 ID。 |
TableName |
STRING |
表的名称。 |
Relation |
STRING |
关系。 |
Count |
INTEGER |
数量。 |
问题排查
本部分介绍了将数据仓库迁移到 BigQuery 时的一些常见问题和问题排查方法。
dwh-migration-dumper 工具错误
如需排查元数据或查询日志提取期间发生的 dwh-migration-dumper 工具终端输出中的错误和警告,请参阅生成元数据问题排查。
Hive 迁移错误
本部分介绍在您计划将数据仓库从 Hive 迁移到 BigQuery 时可能会遇到的常见问题。
日志记录钩子会在 hive-server2 日志中写入调试日志消息。如果您遇到任何问题,请查看包含 MigrationAssessmentLoggingHook 字符串的日志记录钩子调试日志。
处理 ClassNotFoundException 错误
该错误可能是由日志记录钩子 JAR 文件错误导致的。确保您已将 JAR 文件添加到 Hive 集群上的 auxlib 文件夹。您也可以在 hive.aux.jars.path 属性中指定 JAR 文件的完整路径,例如 file://。
子文件夹不显示在已配置的文件夹中
此问题可能是由日志记录钩子初始化期间配置错误或出现问题引起的。
在您的 hive-server2 调试日志中搜索以下日志记录钩子消息:
Unable to initialize logger, logging disabled
Log dir configuration key 'dwhassessment.hook.base-directory' is not set, logging disabled.
Error while trying to set permission
请查看问题详情,看看是否需要进行更正,以修复相关问题。
文件不显示在文件夹中
此问题可能是由事件处理期间或向文件写入时遇到问题导致的。
在您的 hive-server2 调试日志中搜索以下日志记录钩子消息:
Failed to close writer for file
Got exception while processing event
Error writing record for query
请查看问题详情,看看是否需要进行更正,以修复相关问题。
缺少某些查询事件
此问题可能是由日志记录钩子线程队列溢出引起的。
在您的 hive-server2 调试日志中搜索以下日志记录钩子消息:
Writer queue is full. Ignoring event
如果存在此类消息,请考虑增大 dwhassessment.hook.queue.capacity 参数。
后续步骤
如需详细了解 dwh-migration-dumper 工具,请参阅 dwh-migration-tools。
您还可以详细了解数据仓库迁移中的以下步骤: