从 Teradata 迁移架构和数据
结合使用 BigQuery Data Transfer Service 和特殊迁移代理,您可以将数据从 Teradata 本地数据仓库实例复制到 BigQuery。本文档介绍了使用 BigQuery Data Transfer Service 从 Teradata 迁移数据的分步过程。
准备工作
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the BigQuery, BigQuery Data Transfer Service, Cloud Storage, and Pub/Sub APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Create a service account:
-
Ensure that you have the Create Service Accounts IAM role
(
roles/iam.serviceAccountCreator). Learn how to grant roles. -
In the Google Cloud console, go to the Create service account page.
Go to Create service account - Select your project.
-
In the Service account name field, enter a name. The Google Cloud console fills in the Service account ID field based on this name.
In the Service account description field, enter a description. For example,
Service account for quickstart. - Click Create and continue.
-
Grant the following roles to the service account: roles/bigquery.user, roles/storage.objectAdmin, roles/iam.serviceAccountTokenCreator.
To grant a role, find the Select a role list, then select the role.
To grant additional roles, click Add another role and add each additional role.
- Click Continue.
-
Click Done to finish creating the service account.
Do not close your browser window. You will use it in the next step.
-
Ensure that you have the Create Service Accounts IAM role
(
-
Create a service account key:
- In the Google Cloud console, click the email address for the service account that you created.
- Click Keys.
- Click Add key, and then click Create new key.
- Click Create. A JSON key file is downloaded to your computer.
- Click Close.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the BigQuery, BigQuery Data Transfer Service, Cloud Storage, and Pub/Sub APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Create a service account:
-
Ensure that you have the Create Service Accounts IAM role
(
roles/iam.serviceAccountCreator). Learn how to grant roles. -
In the Google Cloud console, go to the Create service account page.
Go to Create service account - Select your project.
-
In the Service account name field, enter a name. The Google Cloud console fills in the Service account ID field based on this name.
In the Service account description field, enter a description. For example,
Service account for quickstart. - Click Create and continue.
-
Grant the following roles to the service account: roles/bigquery.user, roles/storage.objectAdmin, roles/iam.serviceAccountTokenCreator.
To grant a role, find the Select a role list, then select the role.
To grant additional roles, click Add another role and add each additional role.
- Click Continue.
-
Click Done to finish creating the service account.
Do not close your browser window. You will use it in the next step.
-
Ensure that you have the Create Service Accounts IAM role
(
-
Create a service account key:
- In the Google Cloud console, click the email address for the service account that you created.
- Click Keys.
- Click Add key, and then click Create new key.
- Click Create. A JSON key file is downloaded to your computer.
- Click Close.
- Logs Viewer (
roles/logging.viewer) - Storage Admin (
roles/storage.admin) 或授予以下权限的自定义角色:storage.objects.createstorage.objects.getstorage.objects.list
- BigQuery Admin (
roles/bigquery.admin) 或授予以下权限的自定义角色:bigquery.datasets.createbigquery.jobs.createbigquery.jobs.getbigquery.jobs.listAllbigquery.transfers.getbigquery.transfers.update
- 迁移代理使用与 Teradata 实例和 Google Cloud API 的 JDBC 连接。确保网络访问不被防火墙阻止。
- 确保已安装 Java 8 运行时环境或更高版本。
- 确保您有足够的存储空间用于您选择的提取方法(如提取方法中所述)。
- 如果您决定使用 Teradata Parallel Transporter (TPT) 提取,请确保已安装
tbuild实用程序。如需详细了解如何选择提取方法,请参阅提取方法。 确保您获得对系统表和要迁移的表具有读取权限的用户的用户名和密码。
确保您知道用于连接到 Teradata 实例的主机名和端口号。
client_emailprivate_key:复制-----BEGIN PRIVATE KEY-----和-----END PRIVATE KEY-----之间的所有字符,包括所有/n字符,但不包括外围的双引号。ACCESS_ID:访问密钥 ID,或服务账号密钥文件中的client_email值。ACCESS_KEY:密钥访问密钥,或服务账号密钥文件中的private_key值。在 Google Cloud 控制台中,前往 BigQuery 页面。
点击数据传输。
点击创建转移作业。
在来源类型部分,执行以下操作:
- 选择迁移:Teradata。
- 对于转移配置名称,请输入转移作业的显示名称,例如
My Migration。显示名可以是任何容易辨识的值,让您以后在需要修改转移作业时时能够轻松识别。 - 可选:对于时间表选项,您可以保留默认值每天(基于创建时间),也可以选择其他时间(如果您需要周期性增量转移)。否则,请为一次性转移选择按需。
在目标设置部分,选择相应的数据集。
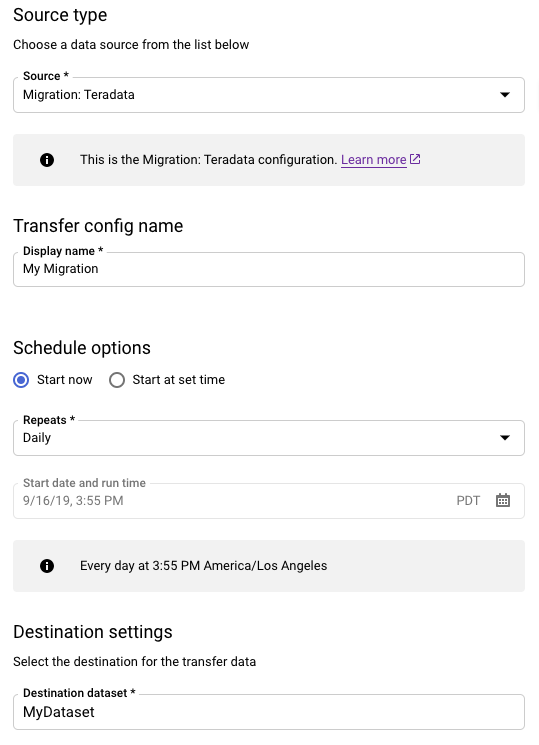
在数据源详细信息部分中,继续设置 Teradata 转移作业的特定详细信息。
- 对于数据库类型,选择 Teradata。
- 对于 Cloud Storage 存储桶,请浏览 Cloud Storage 存储桶的名称以暂存迁移数据。请勿输入前缀
gs://- 请仅输入存储桶名称。 - 对于数据库名称,请输入 Teradata 中源数据库的名称。
对于表名称模式 (Table name patterns),输入匹配源数据库中的表名称的模式。您可以使用正则表达式指定模式。例如:
sales|expenses匹配名为sales和expenses的表。.*匹配所有表。
对于服务账号电子邮件地址,输入与迁移代理使用的服务账号凭据关联的电子邮件地址。
可选:对于架构文件路径,请输入自定义架构文件的路径和文件名。如需详细了解如何创建自定义架构文件,请参阅自定义架构文件。您可以将此字段留空,让 BigQuery 为您自动检测您的源表架构。
可选:对于转换输出根目录,请输入 BigQuery 转换引擎提供的架构映射文件的路径和文件名。如需详细了解如何生成架构映射文件,请参阅将转换引擎输出用于架构(预览版)。您可以将此字段留空,让 BigQuery 为您自动检测您的源表架构。
可选:对于启用直接卸载到 GCS,请选中相应复选框以启用 Cloud Storage 的访问模块。
在服务账号菜单中,从与您的Google Cloud 项目关联的服务账号中选择一个服务账号。您可以将服务账号与转移作业相关联,而不是使用用户凭据。如需详细了解如何将服务账号用于数据转移,请参阅使用服务账号。
可选:在通知选项部分中,执行以下操作:
点击保存。
在转移详情页面上,点击配置标签页。
记下转移作业的资源名称,因为您需要它来运行迁移代理。
--data_source--display_name--target_dataset--params- project ID 是项目 ID。如果未提供
--project_id来指定具体项目,则系统会使用默认项目。 - dataset 是您要为转移作业配置指定的数据集 (
--target_dataset)。 - name 表示转移作业配置的显示名称 (
--display_name)。转移作业的显示名称可以是任何可让您在需要修改转移作业时识别该转移作业的名称。 - service_account 是用于对转移作业进行身份验证的服务账号名称。该服务账号应属于用于创建转移作业的同一
project_id,并且应具有所有列出的所需权限。 - parameters 包含所创建转移作业配置的参数 (
--params),采用 JSON 格式,例如:--params='{"param":"param_value"}'。- 对于 Teradata 迁移,请使用以下参数:
bucket是将在迁移过程中充当暂存区域的 Cloud Storage 存储桶。database_type是 Teradata。agent_service_account是与您创建的服务账号关联的电子邮件地址。database_name是 Teradata 中源数据库的名称。table_name_patterns是用于匹配源数据库中表名的模式。您可以使用正则表达式指定模式。此模式应遵循 Java 正则表达式语法。 例如:sales|expenses匹配名为sales和expenses的表。.*匹配所有表。
is_direct_gcs_unload_enabled是一个布尔值标志,用于启用直接卸载到 Cloud Storage。
- 对于 Teradata 迁移,请使用以下参数:
- data_source 是数据源 (
--data_source):on_premises。 打开一个新会话。在命令行上,发出初始化命令,该命令遵循以下格式:
java -cp \ OS-specific-separated-paths-to-jars (JDBC and agent) \ com.google.cloud.bigquery.dms.Agent \ --initialize
以下示例展示了 JDBC 驱动程序和迁移代理 JAR 文件位于本地
migration目录时的初始化命令:Unix、Linux、MacOS
java -cp \ /usr/local/migration/terajdbc4.jar:/usr/local/migration/mirroring-agent.jar \ com.google.cloud.bigquery.dms.Agent \ --initialize
Windows
将所有文件复制到
C:\migration文件夹中(或调整命令中的路径),然后运行:java -cp C:\migration\terajdbc4.jar;C:\migration\mirroring-agent.jar com.google.cloud.bigquery.dms.Agent --initialize
出现提示时,请配置以下选项:
- 选择是否将 Teradata Parallel Transporter (TPT) 模板保存到磁盘。如果计划使用 TPT 提取方法,则可以使用适合 Teradata 实例的参数修改保存的模板。
- 输入转移作业可用于文件提取的本地目录的路径。确保您拥有提取方法中所述建议的最小存储空间。
- 输入数据库主机名。
- 输入数据库端口。
- 选择是否使用 Teradata Parallel Transporter (TPT) 作为提取方法。
- 可选:输入数据库凭据文件的路径。
选择是否指定 BigQuery Data Transfer Service 配置名称。
如果您要为已设置的转移作业初始化迁移代理,请执行以下操作:
- 输入转移作业的资源名称。您可以在转移作业的转移详情页面的配置标签页中找到此信息。
- 出现提示时,输入将要创建的迁移代理配置文件的路径和文件名。您可以在运行迁移代理时引用此文件以开始转移。
- 跳过其余步骤。
如果您要使用迁移代理来设置转移作业,请按 Enter 键跳到下一个提示。
输入 Google Cloud 项目 ID。
输入 Teradata 中源数据库的名称。
输入匹配源数据库中的表名称的模式。您可以使用正则表达式指定模式。例如:
sales|expenses匹配名为sales和expenses的表。.*匹配所有表。
可选:输入本地 JSON 架构文件的路径。对于周期性转移作业,强烈建议提供此信息。
如果您没有使用架构文件,或者希望迁移代理为您创建一个架构文件,请按 Enter 键跳到下一个提示。
选择是否创建新的架构文件。
如果您想要创建架构文件,请执行以下操作:
- 输入
yes。 - 输入对系统表和要迁移的表具有读取权限的 teradata 用户的用户名。
输入该用户的密码。
迁移代理会创建架构文件并输出其位置。
修改架构文件以标记分区、聚类、主键和更改跟踪列,并验证您是否希望将此架构用于转移作业配置。如需查看提示,请参阅自定义架构文件。
按
Enter键跳到下一个提示。
如果您不想创建架构文件,请输入
no。- 输入
输入目标 Cloud Storage 存储桶的名称以暂存迁移数据,然后再加载到 BigQuery 中。如果您已让迁移代理创建自定义架构文件,则该文件也会上传到此存储桶。
输入 BigQuery 中目标数据集的名称。
输入转移作业配置的显示名称。
输入将创建的迁移代理配置文件的路径和文件名。
输入所有请求的参数后,迁移代理将创建一个配置文件并将其输出到您指定的本地路径。如需详细了解配置文件,请参阅下一部分。
transfer-configuration:有关 BigQuery 中转移作业配置的信息。teradata-config:特定于此 Teradata 提取的信息:connection:主机名和端口的相关信息local-processing-space:代理将表数据提取到的提取文件夹,后面会再将其上传到 Cloud Storage。database-credentials-file-path:(可选)包含自动连接到 Teradata 数据库的凭据的文件路径。凭据在该文件中应该占两行。您可以使用用户名/密码,如以下示例所示:username=abc password=123
username=abc secret_resource_id=projects/my-project/secrets/my-secret-name/versions/1
max-local-storage:在指定暂存目录中用于提取的本地存储空间上限。默认值为50GB。支持的格式为:numberKB|MB|GB|TB。在所有提取模式中,文件在上传到 Cloud Storage 后都会从本地暂存目录中删除。
use-tpt:指示迁移代理使用 Teradata Parallel Transporter (TPT) 作为提取方法。对于每个表,迁移代理都会生成 TPT 脚本、启动
tbuild进程并等待完成。tbuild进程完成后,代理会列出提取的文件并将其上传到 Cloud Storage,然后删除 TPT 脚本。如需了解详情,请参阅提取方法。transfer-views:指示迁移代理也从视图转移数据。仅当您在迁移过程中需要数据自定义时,才应使用此选项。在其他情况下,请将视图迁移到 BigQuery 视图。此选项有以下前提条件:- 此选项只能与 Teradata 16.10 及更高版本搭配使用。
- 视图应定义一个整数列“分区”,指向底层表中给定行的分区 ID。
max-sessions:指定提取作业(FastExport 或 TPT)使用的会话数上限。如果设置为 0,则 Teradata 数据库将会决定每个提取作业的会话数上限。gcs-upload-chunk-size:大文件以文件块形式上传到 Cloud Storage。此参数以及max-parallel-upload用于控制同时上传到 Cloud Storage 的数据量。例如,如果gcs-upload-chunk-size为 64 MB,max-parallel-upload为 10 MB,则理论上迁移代理可以同时上传 640 MB (64 MB * 10) 的数据。如果文件块上传失败,则必须重试整个文件块。文件块大小必须较小。max-parallel-upload:此值用于确定迁移代理将文件上传到 Cloud Storage 时使用的线程数上限。如果未指定,则默认为 Java 虚拟机可用的处理器数量。一般经验法则是根据您在运行代理的机器中拥有的核心数选择值。因此,如果您有n个核心,则最佳线程数应为n。如果核心为超线程,则最佳数量应为(2 * n)。在调整max-parallel-upload时,您还必须考虑网络带宽等其他设置。调整此参数可以提高数据上传到 Cloud Storage 的性能。spool-mode:在大多数情况下,NoSpool 模式是最佳选择。NoSpool是代理配置中的默认值。如果您的情况符合任何 NoSpool 缺点,您可以更改此参数。max-unload-file-size:决定提取的最大文件大小。不强制 TPT 提取使用此参数。max-parallel-extract-threads:此配置仅在 FastExport 模式下使用。它决定了用于从 Teradata 中提取数据的并行线程数。调整此参数可以提高提取的性能。tpt-template-path:使用此配置以提供自定义 TPT 提取脚本作为输入。您可以使用此参数将转换应用于您的迁移数据。schema-mapping-rule-path:(可选)包含替换默认映射规则的架构映射的路径。 某些映射类型仅适用于 Teradata Parallel Transporter (TPT) 模式。示例:从 Teradata 类型
TIMESTAMP映射到 BigQuery 类型DATETIME:{ "rules": [ { "database": { "name": "database.*", "tables": [ { "name": "table.*" } ] }, "match": { "type": "COLUMN_TYPE", "value": "TIMESTAMP" }, "action": { "type": "MAPPING", "value": "DATETIME" } } ] }
属性:
database:(可选)name是要包含的数据库的正则表达式。默认情况下包含所有数据库。tables:(可选)包含表数组。name是要包含的表的正则表达式。默认情况下,所有表均包含在内。match:(必填)type支持的值:COLUMN_TYPE。value支持的值:TIMESTAMP、DATETIME。
action:(必填)type支持的值:MAPPING。value支持的值:TIMESTAMP、DATETIME。
compress-output:(可选)指示在 Cloud Storage 上存储之前是否应压缩数据。此设置仅适用于 tpt-mode。默认情况下,此值为false。gcs-module-config-dir:(可选)用于访问 Cloud Storage 存储桶的凭据文件的路径。默认目录为$HOME/.gcs,但您可以使用此参数更改目录。gcs-module-connection-count:(可选)指定与 Cloud Storage 服务的 TCP 连接数。默认值为 10。gcs-module-buffer-size:(可选)指定用于 TCP 连接的缓冲区的大小。默认值为 8 MB(8388608 字节)。为方便起见,您可以使用以下乘数:k (1000)K (1024)m (1000 * 1000)M (1024*1024)
gcs-module-buffer-count:(可选)指定要用于gcs-module-connection-count所指定 TCP 连接的缓冲区数量。建议使用的值等于与 Cloud Storage 服务的 TCP 连接数的两倍。默认值为 2 *gcs-module-connection-count。gcs-module-max-object-size:(可选)此参数用于控制 Cloud Storage 对象的大小。此形参的值可以是整数,也可以是整数后跟(不含空格)以下乘数之一:k (1000)K (1024)m (1000 * 1000)M (1024*1024)
gcs-module-writer-instances:(可选)此参数用于指定 Cloud Storage writer 实例的数量。默认值为 1。您可以增加此值,以提高 TPT 导出写入阶段的吞吐量。
通过指定 JDBC 驱动程序、迁移代理以及在前面的初始化步骤中创建的配置文件来运行代理。
java -cp \ OS-specific-separated-paths-to-jars (JDBC and agent) \ com.google.cloud.bigquery.dms.Agent \ --configuration-file=path to configuration file
Unix、Linux、MacOS
java -cp \ /usr/local/migration/Teradata/JDBC/terajdbc4.jar:mirroring-agent.jar \ com.google.cloud.bigquery.dms.Agent \ --configuration-file=config.json
Windows
将所有文件复制到
C:\migration文件夹中(或调整命令中的路径),然后运行:java -cp C:\migration\terajdbc4.jar;C:\migration\mirroring-agent.jar com.google.cloud.bigquery.dms.Agent --configuration-file=config.json
如果您已准备好继续迁移,请按
Enter键,代理会在初始化期间提供的类路径有效时继续运行。出现提示时,输入用于数据库连接的用户名和密码。如果用户名和密码有效,则数据迁移便会开始。
可选:在开始迁移的命令中,您也可以使用将凭据文件传递给代理的标志,而不是每次都输入用户名和密码。如需了解详情,请参阅代理配置文件中的可选参数
database-credentials-file-path。使用凭据文件时,请采取适当的步骤来控制对本地文件系统上存储该文件的文件夹的访问,因为它不会被加密。保持此会话的打开状态,直到迁移完成。如果您创建了定期迁移转移作业,请无限期保持此会话的打开状态。如果此会话中断,则当前和将来的转移作业运行会失败。
定期监控代理是否正在运行。如果转移作业正在运行,并且代理在 24 小时内没有响应,则转移作业运行会失败。
如果迁移代理在转移作业进行时或安排后停止工作, Google Cloud 控制台会显示错误状态并提示您重启代理。如需重新启动迁移代理,请从本部分的开头使用运行迁移代理的命令继续运行迁移代理。您无需重复执行初始化命令。转移作业会从表未完成的位置恢复运行。
- 尝试 Teradata 到 BigQuery 的测试迁移。
- 详细了解 BigQuery Data Transfer Service。
- 使用批量 SQL 转换迁移 SQL 代码。
设置所需权限
确保创建转移作业的主账号在包含转移作业的项目中具有以下角色:
创建数据集
创建 BigQuery 数据集来存储数据。您不需要创建任何表。
创建 Cloud Storage 存储桶
创建 Cloud Storage 存储桶,用于在转移作业期间暂存数据。
准备本地环境
完成本部分中的任务,以便为转移作业准备本地环境。
本地机器要求
Teradata 连接详情
下载 JDBC 驱动程序
将 terajdbc4.jar JDBC 驱动程序文件从 Teradata 下载到可以连接到数据仓库的机器上。
设置 GOOGLE_APPLICATION_CREDENTIALS 变量
设置环境变量 GOOGLE_APPLICATION_CREDENTIALS,使其为您在准备工作部分中下载的服务账号密钥。
更新 VPC Service Controls 出站规则
将 BigQuery Data Transfer Service 管理的 Google Cloud 项目(项目编号:990232121269)添加到 VPC Service Controls 边界中的出站规则。
在本地运行的代理与 BigQuery Data Transfer Service 之间的通信渠道是为每个传输主题发布 Pub/Sub 消息。BigQuery Data Transfer Service 需要向代理发送命令以提取数据,并且代理需要将消息发布回 BigQuery Data Transfer Service 以更新状态并返回数据提取响应。
创建自定义架构文件
如需使用自定义架构文件而不是自动架构检测,请手动创建一个架构文件,或者让迁移代理在您初始化代理为您创建一个架构文件。
如果您手动创建架构文件并且打算使用 Google Cloud 控制台创建转移作业,请将架构文件上传到您计划用于该转移作业的项目中的 Cloud Storage 存储桶。
下载迁移代理
将迁移代理下载到可以连接到数据仓库的机器。将迁移代理 JAR 文件移动到 Teradata JDBC 驱动程序 JAR 文件所在的目录中。
为访问模块设置凭据文件
如果您使用 Teradata Parallel Transporter (TPT) 实用程序搭配 Cloud Storage 访问模块进行提取,则需要提供凭据文件。
在创建凭据文件之前,您必须已创建服务账号。从下载的服务账号密钥文件中获取以下信息:
获得所需信息后,请创建凭据文件。以下是凭据文件示例,其默认位置为 $HOME/.gcs/credentials:
[default] gcs_access_key_id = ACCESS_ID gcs_secret_access_key = ACCESS_KEY
替换以下内容:
设置转移作业
使用 BigQuery Data Transfer Service 创建转移作业。
如果您希望自动创建自定义架构文件,请使用迁移代理来设置转移作业。
您无法使用 bq 命令行工具创建按需转移作业;必须改用 Google Cloud 控制台或 BigQuery Data Transfer Service API。
如果您要创建周期性转移作业,我们强烈建议您指定架构文件,以便后续转移作业中的数据在加载到 BigQuery 时被正确分区。如果没有架构文件,BigQuery Data Transfer Service 会根据正在转移的源数据推断表架构,有关分区、聚类、主键和更改跟踪的所有信息都会丢失。此外,初始转移后,后续转移会跳过之前迁移的表。如需详细了解如何创建架构文件,请参阅自定义架构文件。
控制台
bq
使用 bq 工具创建 Cloud Storage 转移作业时,转移作业配置会设置为每 24 小时重复一次。对于按需转移作业,请使用 Google Cloud 控制台或 BigQuery Data Transfer Service API。
您无法使用 bq 工具配置通知。
输入 bq mk 命令并提供转移作业创建标志 --transfer_config。此外,还必须提供以下标志:
bq mk \ --transfer_config \ --project_id=project ID \ --target_dataset=dataset \ --display_name=name \ --service_account_name=service_account \ --params='parameters' \ --data_source=data source
其中:
例如,以下命令使用 Cloud Storage 存储桶 mybucket 和目标数据集 mydataset 创建名为 My Transfer 的 Teradata 转移作业。该转移作业将迁移 Teradata 数据仓库 mydatabase 中的所有表,并且可选架构文件为 myschemafile.json。
bq mk \ --transfer_config \ --project_id=123456789876 \ --target_dataset=MyDataset \ --display_name='My Migration' \ --params='{"bucket": "mybucket", "database_type": "Teradata", "database_name":"mydatabase", "table_name_patterns": ".*", "agent_service_account":"myemail@mydomain.com", "schema_file_path": "gs://mybucket/myschemafile.json", "is_direct_gcs_unload_enabled": true}' \ --data_source=on_premises
运行命令后,您会收到类似如下的消息:
[URL omitted] Please copy and paste the above URL into your web browser and
follow the instructions to retrieve an authentication code.
请按照说明操作,并将身份验证代码粘贴到命令行中。
API
使用 projects.locations.transferConfigs.create 方法并提供一个 TransferConfig 资源实例。
Java
试用此示例之前,请按照 BigQuery 快速入门:使用客户端库中的 Java 设置说明进行操作。 如需了解详情,请参阅 BigQuery Java API 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为客户端库设置身份验证。
迁移代理
您可以选择直接通过迁移代理设置转移作业。如需了解详情,请参阅初始化迁移代理。
初始化迁移代理
您必须为新的转移作业初始化迁移代理。无论转移作业是否为周期性,都只需要对其进行一次初始化。初始化操作仅会配置迁移代理,不会开始转移。
如果您要使用迁移代理创建自定义架构文件,请确保您的工作目录下有一个可写目录,其名称与要用于转移作业的项目相同。这是迁移代理创建架构文件的位置。例如,如果您正在使用 /home 目录并在项目 myProject 中设置转移作业,请创建目录 /home/myProject 并确保用户可以写入该目录。
迁移代理的配置文件
在初始化步骤中创建的配置文件类似于以下示例:
{
"agent-id": "81f452cd-c931-426c-a0de-c62f726f6a6f",
"transfer-configuration": {
"project-id": "123456789876",
"location": "us",
"id": "61d7ab69-0000-2f6c-9b6c-14c14ef21038"
},
"source-type": "teradata",
"console-log": false,
"silent": false,
"teradata-config": {
"connection": {
"host": "localhost"
},
"local-processing-space": "extracted",
"database-credentials-file-path": "",
"max-local-storage": "50GB",
"gcs-upload-chunk-size": "32MB",
"use-tpt": true,
"transfer-views": false,
"max-sessions": 0,
"spool-mode": "NoSpool",
"max-parallel-upload": 4,
"max-parallel-extract-threads": 1,
"session-charset": "UTF8",
"max-unload-file-size": "2GB"
}
}
迁移代理配置文件中的转移作业选项
运行迁移代理
初始化迁移代理并创建配置文件后,请使用以下步骤来运行代理并开始迁移:
跟踪迁移的进度
您可以在 Google Cloud 控制台中查看迁移的状态。您还可以设置 Pub/Sub 或电子邮件通知。请参阅 BigQuery Data Transfer Service 通知。
BigQuery Data Transfer Service 会根据在创建转移作业配置时指定的时间表来计划和启动转移作业运行。当转移作业运行处于有效状态时,请务必确保迁移代理正在运行。如果代理端在 24 小时内没有更新,则转移作业运行会失败。
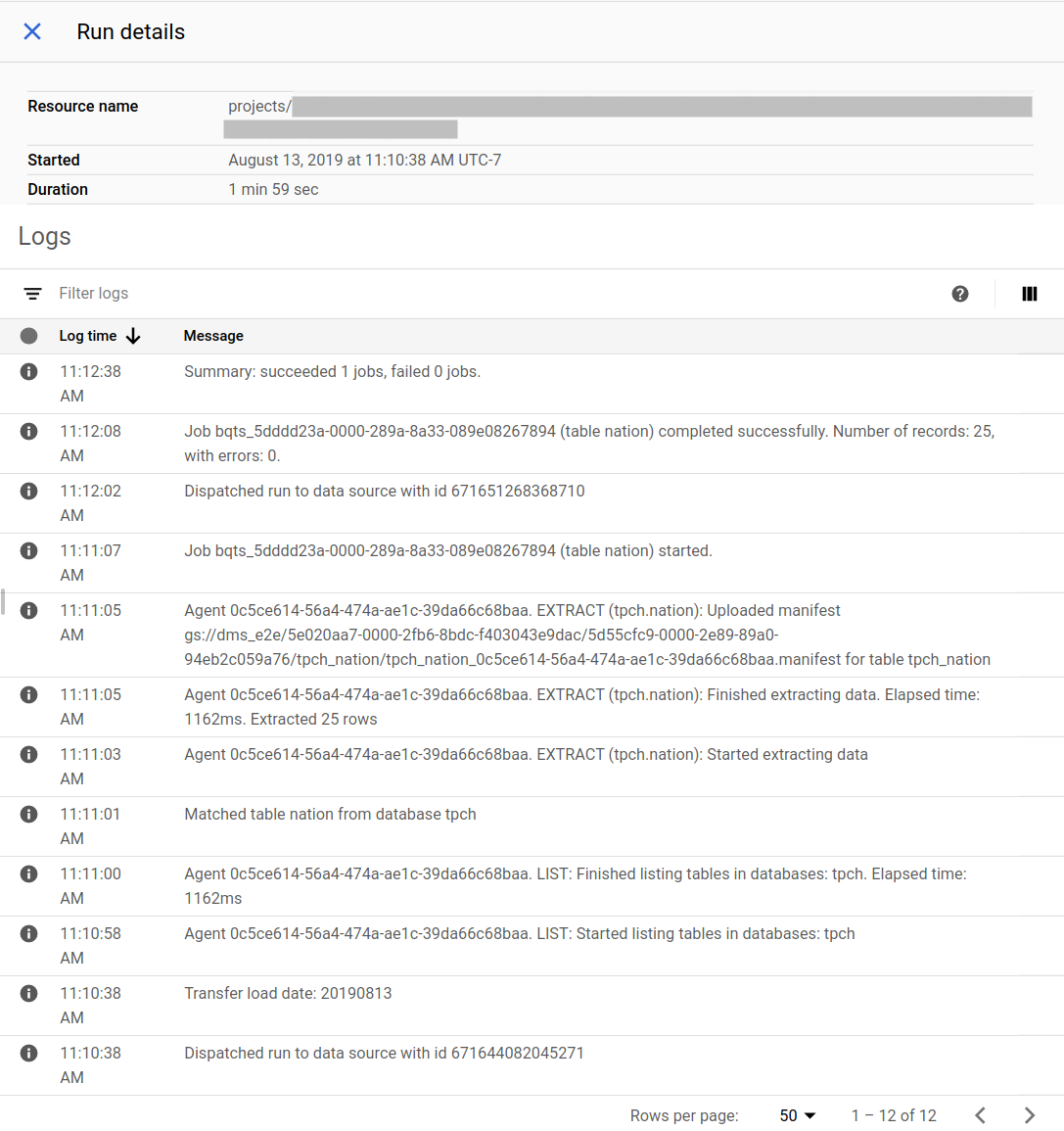
Google Cloud 控制台中的迁移状态示例:
升级迁移代理
如果有新版本的迁移代理可用,您必须手动更新迁移代理。如需接收有关 BigQuery Data Transfer Service 的通知,请订阅版本说明。