Valutazione della migrazione
La valutazione della migrazione di BigQuery ti consente di pianificare e rivedere la migrazione del tuo data warehouse esistente in BigQuery. Puoi eseguire la valutazione della migrazione a BigQuery per generare un report che valuti il costo di archiviazione dei tuoi dati in BigQuery, per vedere come BigQuery può ottimizzare il tuo workload esistente per ridurre i costi e per preparare un piano di migrazione che delinei il tempo e l'impegno necessari per completare la migrazione del data warehouse a BigQuery.
Questo documento descrive come utilizzare la valutazione della migrazione di BigQuery e i diversi modi in cui puoi esaminare i risultati della valutazione. Questo documento è destinato agli utenti che hanno familiarità con la consoleGoogle Cloud e con il traduttore SQL batch.
Prima di iniziare
Per preparare ed eseguire una valutazione della migrazione di BigQuery:
Estrai metadati e log delle query dal tuo data warehouse utilizzando lo strumento
dwh-migration-dumper.Carica i log di metadati e query nel bucket Cloud Storage.
(Facoltativo) Esegui query sui risultati del test per trovare informazioni dettagliate o specifiche sul test.
Estrarre i metadati e i log delle query dal data warehouse
Per preparare il test con i consigli, sono necessari sia i metadati che i log delle query.
Per estrarre i metadati e i log delle query necessari per eseguire la valutazione, seleziona il tuo data warehouse:
Teradata
Requisiti
- Una macchina connessa al data warehouse Teradata di origine (sono supportate le versioni Teradata 15 e successive)
- Un account Google Cloud con un bucket Cloud Storage per archiviare i dati
- Un set di dati BigQuery vuoto in cui archiviare i risultati
- Autorizzazioni di lettura sul set di dati per visualizzare i risultati
- Consigliato: diritti di accesso a livello di amministratore al database di origine quando utilizzi lo strumento di estrazione per accedere alle tabelle di sistema
Requisito: abilita la registrazione
Lo strumento dwh-migration-dumper estrae tre tipi di log: log delle query, log delle utilità e log di utilizzo delle risorse. Per visualizzare insight più approfonditi, devi abilitare la registrazione per i seguenti tipi di log:
- Log delle query:estratti dalla visualizzazione
dbc.QryLogVe dalla tabelladbc.DBQLSqlTbl. Attiva la registrazione specificando l'opzioneWITH SQL. - Log di utilità:estratti dalla tabella
dbc.DBQLUtilityTbl. Attiva la registrazione specificando l'opzioneWITH UTILITYINFO. - Log di utilizzo delle risorse:estratti dalle tabelle
dbc.ResUsageScpuedbc.ResUsageSpma. Abilita il logging RSS per queste due tabelle.
Esegui lo strumento dwh-migration-dumper
Scarica lo strumento dwh-migration-dumper.
Scarica il
file SHA256SUMS.txt
ed esegui il seguente comando per verificare la correttezza del file zip:
Bash
sha256sum --check SHA256SUMS.txt
Windows PowerShell
(Get-FileHash RELEASE_ZIP_FILENAME).Hash -eq ((Get-Content SHA256SUMS.txt) -Split " ")[0]
Sostituisci RELEASE_ZIP_FILENAME con il nome del file ZIP scaricato della release dello strumento di estrazione da riga di comando dwh-migration-dumper, ad esempio dwh-migration-tools-v1.0.52.zip.
Il risultato True conferma la verifica riuscita del checksum.
Il risultato False indica un errore di verifica. Assicurati che i file checksum
e zip vengano scaricati dalla stessa versione della release e inseriti
nella stessa directory.
Per informazioni dettagliate su come configurare e utilizzare lo strumento di estrazione, consulta Generare metadati per la traduzione e la valutazione.
Utilizza lo strumento di estrazione per estrarre log e metadati dal tuo data warehouse Teradata come due file zip. Esegui i seguenti comandi su una macchina con accesso al data warehouse di origine per generare i file.
Genera il file ZIP dei metadati:
dwh-migration-dumper \ --connector teradata \ --database DATABASES \ --driver path/terajdbc4.jar \ --host HOST \ --assessment \ --user USER \ --password PASSWORD
Nota: il flag --database è facoltativo per il connettore
teradata. Se omesso, vengono estratti i metadati di tutti i database. Questo flag è valido solo per il connettore teradata
e non può essere utilizzato con teradata-logs.
Genera il file zip contenente i log delle query:
dwh-migration-dumper \ --connector teradata-logs \ --driver path/terajdbc4.jar \ --host HOST \ --assessment \ --user USER \ --password PASSWORD
Nota: il flag --database non viene utilizzato durante l'estrazione
dei log delle query con il connettore teradata-logs. I log delle query vengono
sempre estratti per tutti i database.
Sostituisci quanto segue:
PATH: il percorso assoluto o relativo del file JAR del driver da utilizzare per questa connessioneVERSION: la versione del driverHOST: l'indirizzo hostUSER: il nome utente da utilizzare per la connessione al databaseDATABASES: (facoltativo) l'elenco separato da virgole dei nomi dei database da estrarre. Se non viene fornito alcun valore, vengono estratte tutte le banche dati.PASSWORD: (facoltativo) la password da utilizzare per la connessione al database. Se lasciato vuoto, all'utente viene richiesta la password.
Per impostazione predefinita, i log delle query vengono estratti
dalla vista dbc.QryLogV e dalla tabella dbc.DBQLSqlTbl. Se devi
estrarre i log delle query da una posizione alternativa, puoi
specificare i nomi delle tabelle o delle viste utilizzando i flag
-Dteradata-logs.query-logs-table e -Dteradata-logs.sql-logs-table.
Per impostazione predefinita, i log dell'utilità vengono estratti dalla tabella
dbc.DBQLUtilityTbl. Se devi estrarre i log dell'utilità da una
posizione alternativa, puoi specificare il nome della tabella utilizzando il
flag -Dteradata-logs.utility-logs-table.
Per impostazione predefinita, i log di utilizzo delle risorse vengono estratti dalle tabelle
dbc.ResUsageScpu e dbc.ResUsageSpma. Se devi estrarre i log di utilizzo delle risorse da una posizione alternativa, puoi specificare i nomi delle tabelle utilizzando i flag -Dteradata-logs.res-usage-scpu-table e -Dteradata-logs.res-usage-spma-table.
Ad esempio:
Bash
dwh-migration-dumper \ --connector teradata-logs \ --driver path/terajdbc4.jar \ --host HOST \ --assessment \ --user USER \ --password PASSWORD \ -Dteradata-logs.query-logs-table=pdcrdata.QryLogV_hst \ -Dteradata-logs.sql-logs-table=pdcrdata.DBQLSqlTbl_hst \ -Dteradata-logs.log-date-column=LogDate \ -Dteradata-logs.utility-logs-table=pdcrdata.DBQLUtilityTbl_hst \ -Dteradata-logs.res-usage-scpu-table=pdcrdata.ResUsageScpu_hst \ -Dteradata-logs.res-usage-spma-table=pdcrdata.ResUsageSpma_hst
Windows PowerShell
dwh-migration-dumper ` --connector teradata-logs ` --driver path\terajdbc4.jar ` --host HOST ` --assessment ` --user USER ` --password PASSWORD ` "-Dteradata-logs.query-logs-table=pdcrdata.QryLogV_hst" ` "-Dteradata-logs.sql-logs-table=pdcrdata.DBQLSqlTbl_hst" ` "-Dteradata-logs.log-date-column=LogDate" ` "-Dteradata-logs.utility-logs-table=pdcrdata.DBQLUtilityTbl_hst" ` "-Dteradata-logs.res-usage-scpu-table=pdcrdata.ResUsageScpu_hst" ` "-Dteradata-logs.res-usage-spma-table=pdcrdata.ResUsageSpma_hst"
Per impostazione predefinita, lo strumento dwh-migration-dumper estrae gli ultimi sette giorni di
log delle query.
Google consiglia di fornire almeno due settimane di log delle query per poter visualizzare approfondimenti più dettagliati. Puoi specificare un intervallo di tempo personalizzato utilizzando i flag --query-log-start e --query-log-end. Ad esempio:
dwh-migration-dumper \ --connector teradata-logs \ --driver path/terajdbc4.jar \ --host HOST \ --assessment \ --user USER \ --password PASSWORD \ --query-log-start "2023-01-01 00:00:00" \ --query-log-end "2023-01-15 00:00:00"
Puoi anche generare più file ZIP contenenti log delle query che coprono periodi diversi e fornirli tutti per la valutazione.
Redshift
Requisiti
- Una macchina connessa al data warehouse Amazon Redshift di origine
- Un account Google Cloud con un bucket Cloud Storage per archiviare i dati
- Un set di dati BigQuery vuoto in cui archiviare i risultati
- Autorizzazioni di lettura sul set di dati per visualizzare i risultati
- Consigliato: accesso superutente al database quando utilizzi lo strumento di estrazione per accedere alle tabelle di sistema
Esegui lo strumento dwh-migration-dumper
Scarica lo strumento di estrazione da riga di comando dwh-migration-dumper.
Scarica il
file SHA256SUMS.txt
ed esegui il seguente comando per verificare la correttezza del file zip:
Bash
sha256sum --check SHA256SUMS.txt
Windows PowerShell
(Get-FileHash RELEASE_ZIP_FILENAME).Hash -eq ((Get-Content SHA256SUMS.txt) -Split " ")[0]
Sostituisci RELEASE_ZIP_FILENAME con il nome del file ZIP scaricato della release dello strumento di estrazione da riga di comando dwh-migration-dumper, ad esempio dwh-migration-tools-v1.0.52.zip.
Il risultato True conferma la verifica riuscita del checksum.
Il risultato False indica un errore di verifica. Assicurati che i file checksum
e zip vengano scaricati dalla stessa versione della release e inseriti
nella stessa directory.
Per informazioni dettagliate su come utilizzare lo strumento dwh-migration-dumper,
consulta la pagina
Generare metadati.
Utilizza lo strumento dwh-migration-dumper per estrarre log e metadati dal tuo
data warehouse Amazon Redshift come due file zip.
Esegui i seguenti comandi su una macchina con accesso al data warehouse di origine per generare i file.
Genera il file ZIP dei metadati:
dwh-migration-dumper \ --connector redshift \ --database DATABASE \ --driver PATH/redshift-jdbc42-VERSION.jar \ --host host.region.redshift.amazonaws.com \ --assessment \ --user USER \ --iam-profile IAM_PROFILE_NAME
Genera il file zip contenente i log delle query:
dwh-migration-dumper \ --connector redshift-raw-logs \ --database DATABASE \ --driver PATH/redshift-jdbc42-VERSION.jar \ --host host.region.redshift.amazonaws.com \ --assessment \ --user USER \ --iam-profile IAM_PROFILE_NAME
Sostituisci quanto segue:
DATABASE: il nome del database a cui connettersiPATH: il percorso assoluto o relativo del file JAR del driver da utilizzare per questa connessioneVERSION: la versione del driverUSER: il nome utente da utilizzare per la connessione al databaseIAM_PROFILE_NAME: il nome del profilo IAM Amazon Redshift. Obbligatorio per l'autenticazione Amazon Redshift e per l'accesso all'API AWS. Per ottenere la descrizione dei cluster Amazon Redshift, utilizza l'API AWS.
Per impostazione predefinita, Amazon Redshift archivia i log delle query per un periodo compreso tra tre e cinque giorni.
Per impostazione predefinita, lo strumento dwh-migration-dumper estrae gli ultimi sette giorni di log delle query.
Google consiglia di fornire almeno due settimane di log delle query per poter visualizzare approfondimenti più dettagliati. Potresti dover eseguire lo strumento di estrazione più volte nel corso di due settimane per ottenere i risultati migliori. Puoi specificare un intervallo
personalizzato utilizzando i flag --query-log-start e --query-log-end.
Ad esempio:
dwh-migration-dumper \ --connector redshift-raw-logs \ --database DATABASE \ --driver PATH/redshift-jdbc42-VERSION.jar \ --host host.region.redshift.amazonaws.com \ --assessment \ --user USER \ --iam-profile IAM_PROFILE_NAME \ --query-log-start "2023-01-01 00:00:00" \ --query-log-end "2023-01-02 00:00:00"
Puoi anche generare più file ZIP contenenti log delle query che coprono periodi diversi e fornirli tutti per la valutazione.
Redshift Serverless
Requisiti
- Una macchina connessa al data warehouse serverless Amazon Redshift di origine
- Un account Google Cloud con un bucket Cloud Storage per archiviare i dati
- Un set di dati BigQuery vuoto in cui archiviare i risultati
- Autorizzazioni di lettura sul set di dati per visualizzare i risultati
- Consigliato: accesso superutente al database quando utilizzi lo strumento di estrazione per accedere alle tabelle di sistema
Esegui lo strumento dwh-migration-dumper
Scarica lo strumento di estrazione da riga di comando dwh-migration-dumper.
Per informazioni dettagliate su come utilizzare lo strumento dwh-migration-dumper, consulta la pagina
Generare metadati.
Utilizza lo strumento dwh-migration-dumper per estrarre i log di utilizzo e i metadati dallo spazio dei nomi Amazon Redshift Serverless come due file zip. Esegui i seguenti
comandi su una macchina con accesso al data warehouse di origine per generare
i file.
Genera il file ZIP dei metadati:
dwh-migration-dumper \ --connector redshift \ --database DATABASE \ --driver PATH/redshift-jdbc42-VERSION.jar \ --host host.region.redshift-serverless.amazonaws.com \ --assessment \ --user USER \ --iam-profile IAM_PROFILE_NAME
Genera il file zip contenente i log delle query:
dwh-migration-dumper \ --connector redshift-serverless-logs \ --database DATABASE \ --driver PATH/redshift-jdbc42-VERSION.jar \ --host host.region.redshift-serverless.amazonaws.com \ --assessment \ --user USER \ --iam-profile IAM_PROFILE_NAME
Sostituisci quanto segue:
DATABASE: il nome del database a cui connettersiPATH: il percorso assoluto o relativo del file JAR del driver da utilizzare per questa connessioneVERSION: la versione del driverUSER: il nome utente da utilizzare per la connessione al databaseIAM_PROFILE_NAME: il nome del profilo IAM Amazon Redshift. Obbligatorio per l'autenticazione Amazon Redshift e per l'accesso all'API AWS. Per ottenere la descrizione dei cluster Amazon Redshift, utilizza l'API AWS.
Amazon Redshift Serverless archivia i log di utilizzo per sette giorni. Se è necessario un intervallo più ampio, Google consiglia di estrarre i dati più volte in un periodo di tempo più lungo.
Snowflake
Requisiti
Per estrarre i metadati e i log delle query da Snowflake, devi soddisfare i seguenti requisiti:
- Una macchina che può connettersi alle tue istanze Snowflake.
- Un account Google Cloud con un bucket Cloud Storage per archiviare i dati.
- Un set di dati BigQuery vuoto in cui archiviare i risultati. In alternativa, puoi creare un set di dati BigQuery quando crei il job di valutazione utilizzando l'interfaccia utente della console Google Cloud .
- Utente Snowflake con accesso
IMPORTED PRIVILEGESal databaseSnowflake. Ti consigliamo di creare un utenteSERVICEcon autenticazione basata su coppia di chiavi. In questo modo viene fornito il metodo sicuro per accedere alla piattaforma di dati Snowflake senza la necessità di generare token MFA.- Per creare un nuovo utente del servizio, segui la guida ufficiale di Snowflake. Dovrai generare la coppia di chiave RSA e assegnare la chiave pubblica all'utente Snowflake.
- L'utente del servizio deve disporre del ruolo
ACCOUNTADMINo gli deve essere concesso un ruolo con i privilegiIMPORTED PRIVILEGESsul databaseSnowflakeda un amministratore account. - In alternativa all'autenticazione con coppia di chiavi, puoi utilizzare l'autenticazione basata su password. Tuttavia, a partire da agosto 2025, Snowflake applicaMFAù fattori a tutti gli utenti basati su password. Ciò richiede l'approvazione della notifica push MFA quando utilizzi il nostro strumento di estrazione.
Esegui lo strumento dwh-migration-dumper
Scarica lo strumento di estrazione da riga di comando dwh-migration-dumper.
Scarica il
file SHA256SUMS.txt
ed esegui il seguente comando per verificare la correttezza del file zip:
Bash
sha256sum --check SHA256SUMS.txt
Windows PowerShell
(Get-FileHash RELEASE_ZIP_FILENAME).Hash -eq ((Get-Content SHA256SUMS.txt) -Split " ")[0]
Sostituisci RELEASE_ZIP_FILENAME con il nome del file ZIP scaricato della release dello strumento di estrazione da riga di comando dwh-migration-dumper, ad esempio dwh-migration-tools-v1.0.52.zip.
Il risultato True conferma la verifica riuscita del checksum.
Il risultato False indica un errore di verifica. Assicurati che i file checksum
e zip vengano scaricati dalla stessa versione della release e inseriti
nella stessa directory.
Per informazioni dettagliate su come utilizzare lo strumento dwh-migration-dumper,
consulta la pagina
Generare metadati.
Utilizza lo strumento dwh-migration-dumper per estrarre log e metadati dal tuo
data warehouse Snowflake come due file zip. Esegui i seguenti
comandi su una macchina con accesso al data warehouse di origine per generare
i file.
Genera il file ZIP dei metadati:
dwh-migration-dumper \ --connector snowflake \ --host HOST_NAME \ --user USER_NAME \ --role ROLE_NAME \ --warehouse WAREHOUSE \ --assessment \ --private-key-file PRIVATE_KEY_PATH \ --private-key-password PRIVATE_KEY_PASSWORD
Genera il file zip contenente i log delle query:
dwh-migration-dumper \ --connector snowflake-logs \ --host HOST_NAME \ --user USER_NAME \ --role ROLE_NAME \ --warehouse WAREHOUSE \ --query-log-start STARTING_DATE \ --query-log-end ENDING_DATE \ --assessment \ --private-key-file PRIVATE_KEY_PATH \ --private-key-password PRIVATE_KEY_PASSWORD
Sostituisci quanto segue:
HOST_NAME: il nome host dell'istanza Snowflake.USER_NAME: il nome utente da utilizzare per la connessione al database, in cui l'utente deve disporre delle autorizzazioni di accesso descritte in dettaglio nella sezione dei requisiti.PRIVATE_KEY_PATH: il percorso della chiave privata RSA utilizzata per l'autenticazione.PRIVATE_KEY_PASSWORD: (facoltativa) la password utilizzata durante la creazione della chiave privata RSA. È obbligatoria solo se la chiave privata è criptata.ROLE_NAME: (facoltativo) il ruolo utente durante l'esecuzione dello strumentodwh-migration-dumper, ad esempioACCOUNTADMIN.WAREHOUSE: il warehouse utilizzato per eseguire le operazioni di dumping. Se hai più magazzini virtuali, puoi specificare qualsiasi magazzino per eseguire questa query. L'esecuzione di questa query con le autorizzazioni di accesso descritte nella sezione dei requisiti estrae tutti gli artefatti del warehouse in questo account.STARTING_DATE: (facoltativo) utilizzato per indicare la data di inizio in un intervallo di date dei log delle query, scritta nel formatoYYYY-MM-DD.ENDING_DATE: (facoltativo) utilizzato per indicare la data di fine in un intervallo di date dei log delle query, scritto nel formatoYYYY-MM-DD.
Puoi anche generare più file zip contenenti log delle query che coprono periodi non sovrapposti e fornirli tutti per la valutazione.
Oracle
Per richiedere un feedback o assistenza per questa funzionalità, invia un'email all'indirizzo bq-edw-migration-support@google.com.
Requisiti
Per estrarre i metadati e i log delle query da Oracle, devi soddisfare i seguenti requisiti:
- Il tuo database Oracle deve essere la versione 11g R1 o successive.
- Una macchina che può connettersi alle tue istanze Oracle.
- Java 8 o versioni successive.
- Un account Google Cloud con un bucket Cloud Storage per archiviare i dati.
- Un set di dati BigQuery vuoto in cui archiviare i risultati. In alternativa, puoi creare un set di dati BigQuery quando crei il job di valutazione utilizzando l'interfaccia utente della console Google Cloud .
- Un utente comune Oracle con privilegi SYSDBA.
Esegui lo strumento dwh-migration-dumper
Scarica lo strumento di estrazione da riga di comando dwh-migration-dumper.
Scarica il
file SHA256SUMS.txt
ed esegui il seguente comando per verificare la correttezza del file zip:
sha256sum --check SHA256SUMS.txt
Per informazioni dettagliate su come utilizzare lo strumento dwh-migration-dumper,
consulta la pagina
Generare metadati.
Utilizza lo strumento dwh-migration-dumper per estrarre i metadati e le statistiche
sul rendimento nel file ZIP. Per impostazione predefinita, le statistiche vengono estratte da
Oracle AWR, che richiede Oracle Tuning and Diagnostics
Pack. Se questi dati non sono disponibili, dwh-migration-dumper utilizza STATSPACK.
Per i database multitenant, lo strumento dwh-migration-dumper deve essere eseguito
nel container radice. L'esecuzione in uno dei database plug-in comporta
la mancanza di statistiche sulle prestazioni e metadati relativi ad altri database plug-in.
Genera il file ZIP dei metadati:
dwh-migration-dumper \ --connector oracle-stats \ --host HOST_NAME \ --port PORT \ --oracle-service SERVICE_NAME \ --assessment \ --driver JDBC_DRIVER_PATH \ --user USER_NAME \ --password
Sostituisci quanto segue:
HOST_NAME: il nome host dell'istanza Oracle.PORT: il numero di porta della connessione. Il valore predefinito è 1521.SERVICE_NAME: il nome del servizio Oracle da utilizzare per la connessione.JDBC_DRIVER_PATH: il percorso assoluto o relativo del file JAR del driver. Puoi scaricare questo file dalla pagina Download del driver Oracle JDBC. Devi selezionare la versione del driver compatibile con la versione del tuo database.USER_NAME: il nome dell'utente utilizzato per connettersi all'istanza Oracle. L'utente deve disporre delle autorizzazioni di accesso descritte in dettaglio nella sezione dei requisiti.
Hadoop / Cloudera
Per richiedere un feedback o assistenza per questa funzionalità, invia un'email all'indirizzo bq-edw-migration-support@google.com.
Requisiti
Per estrarre i metadati da Cloudera, devi disporre di quanto segue:
- Una macchina che può connettersi all'API Cloudera Manager.
- Un account Google Cloud con un bucket Cloud Storage per archiviare i dati.
- Un set di dati BigQuery vuoto in cui archiviare i risultati. In alternativa, puoi creare un set di dati BigQuery quando crei il job di valutazione.
Esegui lo strumento dwh-migration-dumper
Scarica lo strumento di estrazione da riga di comando
dwh-migration-dumper.Scarica il file
SHA256SUMS.txt.Nell'ambiente a riga di comando, verifica la correttezza del file zip:
sha256sum --check SHA256SUMS.txt
Per informazioni dettagliate su come utilizzare lo strumento
dwh-migration-dumper, vedi Generare metadati per la traduzione e la valutazione.Utilizza lo strumento
dwh-migration-dumperper estrarre i metadati e le statistiche sul rendimento nel file ZIP:dwh-migration-dumper \ --connector cloudera-manager \ --user USER_NAME \ --password PASSWORD \ --url URL_PATH \ --yarn-application-types "APP_TYPES" \ --pagination-page-size PAGE_SIZE \ --start-date START_DATE \ --end-date END_DATE \ --assessment
Sostituisci quanto segue:
USER_NAME: il nome dell'utente a cui connetterti all'istanza di Cloudera Manager.PASSWORD: la password per l'istanza di Cloudera Manager.URL_PATH: il percorso URL dell'API Cloudera Manager, ad esempiohttps://localhost:7183/api/v55/.APP_TYPES(facoltativo): i tipi di applicazioni YARN separati da virgole di cui viene eseguito il dump dal cluster. Il valore predefinito èMAPREDUCE,SPARK,Oozie Launcher.PAGE_SIZE(facoltativo): il numero di record per risposta Cloudera. Il valore predefinito è1000.START_DATE(facoltativo): la data di inizio del dump della cronologia in formato ISO 8601, ad esempio2025-05-29. Il valore predefinito è 90 giorni prima della data corrente.END_DATE(facoltativo): la data di fine del dump della cronologia in formato ISO 8601, ad esempio2025-05-30. Il valore predefinito è la data corrente.
Utilizzare Oozie nel cluster Cloudera
Se utilizzi Oozie nel tuo cluster Cloudera, puoi scaricare la cronologia dei job Oozie con il connettore Oozie. Puoi utilizzare Oozie con l'autenticazione Kerberos o l'autenticazione di base.
Per l'autenticazione Kerberos, esegui questo comando:
kinit dwh-migration-dumper \ --connector oozie \ --url URL_PATH \ --assessment
Sostituisci quanto segue:
URL_PATH(facoltativo): il percorso dell'URL del server Oozie. Se non specifichi il percorso dell'URL, questo viene ricavato dalla variabile di ambienteOOZIE_URL.
Per l'autenticazione di base, esegui questo comando:
dwh-migration-dumper \ --connector oozie \ --user USER_NAME \ --password PASSWORD \ --url URL_PATH \ --assessment
Sostituisci quanto segue:
USER_NAME: il nome dell'utente Oozie.PASSWORD: la password dell'utente.URL_PATH(facoltativo): il percorso dell'URL del server Oozie. Se non specifichi il percorso dell'URL, questo viene ricavato dalla variabile di ambienteOOZIE_URL.
Utilizzare Airflow nel cluster Cloudera
Se utilizzi Airflow nel tuo cluster Cloudera, puoi scaricare la cronologia dei DAG con il connettore Airflow:
dwh-migration-dumper \ --connector airflow \ --user USER_NAME \ --password PASSWORD \ --url URL \ --driver "DRIVER_PATH" \ --start-date START_DATE \ --end-date END_DATE \ --assessment
Sostituisci quanto segue:
USER_NAME: il nome dell'utente AirflowPASSWORD: la password dell'utenteURL: la stringa JDBC al database AirflowDRIVER_PATH: il percorso del driver JDBCSTART_DATE(facoltativo): la data di inizio del dump della cronologia in formato ISO 8601END_DATE(facoltativo): la data di fine del dump della cronologia nel formato ISO 8601
Utilizzare Hive nel cluster Cloudera
Per utilizzare il connettore Hive, vedi la scheda Apache Hive.
Apache Hive
Requisiti
- Una macchina connessa al data warehouse Apache Hive di origine (la valutazione della migrazione a BigQuery supporta Hive su Tez e MapReduce e le versioni di Apache Hive comprese tra 2.2 e 3.1, inclusi)
- Un account Google Cloud con un bucket Cloud Storage per archiviare i dati
- Un set di dati BigQuery vuoto in cui archiviare i risultati
- Autorizzazioni di lettura sul set di dati per visualizzare i risultati
- Accesso al data warehouse Apache Hive di origine per configurare l'estrazione dei log delle query
- Statistiche aggiornate su tabelle, partizioni e colonne
La valutazione della migrazione di BigQuery utilizza le statistiche di tabelle, partizioni e colonne per
comprendere meglio il data warehouse Apache Hive e fornire
approfondimenti dettagliati. Se l'impostazione di configurazione hive.stats.autogather è impostata su false nel data warehouse Apache Hive di origine, Google consiglia di attivarla o aggiornare manualmente le statistiche prima di eseguire lo strumento dwh-migration-dumper.
Esegui lo strumento dwh-migration-dumper
Scarica lo strumento di estrazione da riga di comando dwh-migration-dumper.
Scarica il
file SHA256SUMS.txt
ed esegui il seguente comando per verificare la correttezza del file zip:
Bash
sha256sum --check SHA256SUMS.txt
Windows PowerShell
(Get-FileHash RELEASE_ZIP_FILENAME).Hash -eq ((Get-Content SHA256SUMS.txt) -Split " ")[0]
Sostituisci RELEASE_ZIP_FILENAME con il nome del file ZIP scaricato della release dello strumento di estrazione da riga di comando dwh-migration-dumper, ad esempio dwh-migration-tools-v1.0.52.zip.
Il risultato True conferma la verifica riuscita del checksum.
Il risultato False indica un errore di verifica. Assicurati che i file checksum
e zip vengano scaricati dalla stessa versione della release e inseriti
nella stessa directory.
Per informazioni dettagliate su come utilizzare lo strumento dwh-migration-dumper, vedi
Generare metadati per la traduzione e la valutazione.
Utilizza lo strumento dwh-migration-dumper per generare i metadati dal tuo data warehouse Hive come file ZIP.
Senza autenticazione
Per generare il file zip dei metadati, esegui il comando seguente su una macchina che ha accesso al data warehouse di origine:
dwh-migration-dumper \ --connector hiveql \ --database DATABASES \ --host hive.cluster.host \ --port 9083 \ --assessment
Con l'autenticazione Kerberos
Per eseguire l'autenticazione al metastore, accedi come utente che ha accesso al metastore Apache Hive e genera un ticket Kerberos. Poi, genera il file zip dei metadati con il seguente comando:
JAVA_OPTS="-Djavax.security.auth.useSubjectCredsOnly=false" \ dwh-migration-dumper \ --connector hiveql \ --database DATABASES \ --host hive.cluster.host \ --port 9083 \ --hive-kerberos-url PRINCIPAL/HOST \ -Dhiveql.rpc.protection=hadoop.rpc.protection \ --assessment
Sostituisci quanto segue:
DATABASES: l'elenco separato da virgole dei nomi dei database da estrarre. Se non viene fornito alcun valore, vengono estratte tutte le banche dati.PRINCIPAL: l'entità Kerberos a cui viene rilasciato il ticketHOST: il nome host Kerberos a cui viene rilasciato il tickethadoop.rpc.protection: la qualità della protezione (QOP) del livello di configurazione SASL (Simple Authentication and Security Layer), uguale al valore del parametrohadoop.rpc.protectionall'interno del file/etc/hadoop/conf/core-site.xml, con uno dei seguenti valori:authenticationintegrityprivacy
Estrai i log delle query con l'hook di logging hadoop-migration-assessment
Per estrarre i log delle query:
- Carica l'hook di logging
hadoop-migration-assessment. - Configura le proprietà dell'hook di logging.
- Verifica l'hook di logging.
Carica l'hook di logging hadoop-migration-assessment
Scarica l'hook di logging di estrazione dei log delle query
hadoop-migration-assessmentche contiene il file JAR dell'hook di logging Hive.Estrai il file JAR.
Se devi controllare lo strumento per assicurarti che soddisfi i requisiti di conformità, esamina il codice sorgente del repository GitHub del hook di logging
hadoop-migration-assessmente compila il tuo binario.Copia il file JAR nella cartella della libreria ausiliaria su tutti i cluster in cui prevedi di attivare la registrazione delle query. A seconda del fornitore, devi individuare la cartella della libreria ausiliaria nelle impostazioni del cluster e trasferire il file JAR nella cartella della libreria ausiliaria sul cluster Hive.
Configura le proprietà di configurazione per l'hook di logging
hadoop-migration-assessment. A seconda del fornitore Hadoop, devi utilizzare la console UI per modificare le impostazioni del cluster. Modifica il file/etc/hive/conf/hive-site.xmlo applica la configurazione con Configuration Manager.
Configurare le proprietà
Se hai già altri valori per le seguenti
chiavi di configurazione, aggiungi le impostazioni utilizzando una virgola (,).
Per configurare l'hook di logging hadoop-migration-assessment, sono necessarie le seguenti impostazioni di configurazione:
hive.exec.failure.hooks:com.google.cloud.bigquery.dwhassessment.hooks.MigrationAssessmentLoggingHookhive.exec.post.hooks:com.google.cloud.bigquery.dwhassessment.hooks.MigrationAssessmentLoggingHookhive.exec.pre.hooks:com.google.cloud.bigquery.dwhassessment.hooks.MigrationAssessmentLoggingHookhive.aux.jars.path: includi il percorso del file JAR dell'hook di logging, ad esempiofile://./HiveMigrationAssessmentQueryLogsHooks_deploy.jar dwhassessment.hook.base-directory: il percorso della cartella di output dei log delle query. Ad esempio,hdfs://tmp/logs/.Puoi anche impostare le seguenti configurazioni facoltative:
dwhassessment.hook.queue.capacity: la capacità della coda per i thread di logging degli eventi di query. Il valore predefinito è64.dwhassessment.hook.rollover-interval: la frequenza con cui deve essere eseguito il rollover dei file. Ad esempio,600s. Il valore predefinito è 3600 secondi (1 ora).dwhassessment.hook.rollover-eligibility-check-interval: la frequenza con cui viene attivato in background il controllo dell'idoneità al rollover dei file. Ad esempio,600s. Il valore predefinito è 600 secondi (10 minuti).
Verifica l'hook di logging
Dopo aver riavviato il processo hive-server2, esegui una query di test e analizza i log di debug. Puoi visualizzare il seguente messaggio:
Logger successfully started, waiting for query events. Log directory is '[dwhassessment.hook.base-directory value]'; rollover interval is '60' minutes; rollover eligibility check is '10' minutes
L'hook di logging crea una sottocartella partizionata per data nella cartella configurata. Il file Avro con gli eventi della query viene visualizzato in questa cartella dopo l'intervallo dwhassessment.hook.rollover-interval o l'interruzione del processo hive-server2. Puoi cercare messaggi simili
nei log di debug per visualizzare lo stato dell'operazione di rollover:
Updated rollover time for logger ID 'my_logger_id' to '2023-12-25T10:15:30'
Performed rollover check for logger ID 'my_logger_id'. Expected rollover time is '2023-12-25T10:15:30'
Il rollover avviene agli intervalli specificati o al cambio di giorno. Quando cambia la data, l'hook di logging crea anche una nuova sottocartella per quella data.
Google consiglia di fornire almeno due settimane di log delle query per poter visualizzare approfondimenti più dettagliati.
Puoi anche generare cartelle contenenti log delle query da diversi cluster Hive e fornirle tutte per una singola valutazione.
Informatica
Per richiedere un feedback o assistenza per questa funzionalità, invia un'email all'indirizzo bq-edw-migration-support@google.com.
Requisiti
- Accesso al client Informatica PowerCenter Repository Manager
- Un account Google Cloud con un bucket Cloud Storage per archiviare i dati.
- Un set di dati BigQuery vuoto in cui archiviare i risultati. In alternativa, puoi creare un set di dati BigQuery quando crei il job di valutazione utilizzando la console Google Cloud .
Requisito: esportare i file oggetto
Puoi utilizzare la GUI di Informatica PowerCenter Repository Manager per esportare i file oggetto. Per informazioni, vedi Passaggi per esportare gli oggetti.
In alternativa, puoi anche eseguire il comando pmrep per esportare i file oggetto
con i seguenti passaggi:
- Esegui il comando
pmrep connectper connetterti al repository:
pmrep connect -r `REPOSITORY_NAME` -d `DOMAIN_NAME` -n `USERNAME` -x `PASSWORD`
Sostituisci quanto segue:
REPOSITORY_NAME: il nome del repository a cui vuoi connettertiDOMAIN_NAME: il nome del dominio per il repositoryUSERNAME: nome utente per connettersi al repositoryPASSWORD: password del nome utente
- Una volta connesso al repository, utilizza il comando
pmrep objectexportper esportare gli oggetti richiesti:
pmrep objectexport -n `OBJECT_NAME` -o `OBJECT_TYPE` -f `FOLDER_NAME` -u `OUTPUT_FILE_NAME.xml`
Sostituisci quanto segue:
OBJECT_NAME: il nome di un oggetto specifico da esportareOBJECT_TYPE: tipo di oggetto dell'oggetto specificatoFOLDER_NAME: il nome della cartella contenente l'oggetto da esportareOUTPUT_FILE_NAME: il nome del file XML che conterrà le informazioni sull'oggetto
Carica i metadati e i log delle query su Cloud Storage
Una volta estratti i metadati e i log delle query dal data warehouse, puoi caricare i file in un bucket Cloud Storage per procedere con la valutazione della migrazione.
Teradata
Carica i metadati e uno o più file ZIP contenenti i log delle query nel bucket Cloud Storage. Per saperne di più sulla creazione di bucket e sul caricamento di file in Cloud Storage, consulta Crea bucket e Carica oggetti da un file system. Il limite per le dimensioni totali non compresse di tutti i file all'interno del file ZIP dei metadati è 50 GB.
Le voci di tutti i file ZIP contenenti i log delle query sono suddivise in:
- File della cronologia delle query con il prefisso
query_history_. - File di serie temporali con i prefissi
utility_logs_,dbc.ResUsageScpu_edbc.ResUsageSpma_.
Il limite per le dimensioni totali non compresse di tutti i file della cronologia delle query è 5 TB. Il limite per le dimensioni totali non compresse di tutti i file delle serie temporali è 1 TB.
Se i log delle query sono archiviati in un database diverso, consulta
la descrizione dei flag -Dteradata-logs.query-logs-table e
-Dteradata-logs.sql-logs-table riportata in precedenza in questa sezione, che spiega
come fornire una posizione alternativa per i log delle query.
Redshift
Carica i metadati e uno o più file ZIP contenenti i log delle query nel bucket Cloud Storage. Per saperne di più sulla creazione di bucket e sul caricamento di file in Cloud Storage, consulta Crea bucket e Carica oggetti da un file system. Il limite per le dimensioni totali non compresse di tutti i file all'interno del file ZIP dei metadati è 50 GB.
Le voci di tutti i file ZIP contenenti i log delle query sono suddivise in:
- File della cronologia delle query con i prefissi
querytext_eddltext_. - File di serie temporali con i prefissi
query_queue_info_,wlm_query_equerymetrics_.
Il limite per le dimensioni totali non compresse di tutti i file della cronologia delle query è 5 TB. Il limite per le dimensioni totali non compresse di tutti i file delle serie temporali è 1 TB.
Redshift Serverless
Carica i metadati e uno o più file ZIP contenenti i log delle query nel bucket Cloud Storage. Per saperne di più sulla creazione di bucket e sul caricamento di file in Cloud Storage, consulta Crea bucket e Carica oggetti da un file system.
Snowflake
Carica i metadati e i file zip contenenti i log delle query e le cronologie di utilizzo nel bucket Cloud Storage. Quando carichi questi file in Cloud Storage, devono essere soddisfatti i seguenti requisiti:
- La dimensione totale non compressa di tutti i file all'interno del file ZIP dei metadati deve essere inferiore a 50 GB.
- Il file zip dei metadati e il file zip contenente i log delle query devono essere caricati in una cartella Cloud Storage. Se hai più file ZIP contenenti log delle query non sovrapposti, puoi caricarli tutti.
- Devi caricare tutti i file nella stessa cartella Cloud Storage.
- Devi caricare tutti i file zip di metadati e log delle query esattamente come
vengono generati dallo strumento
dwh-migration-dumper. Non estrarli, combinarli o modificarli in altro modo. - La dimensione totale non compressa di tutti i file della cronologia delle query deve essere inferiore a 5 TB.
Per saperne di più sulla creazione di bucket e sul caricamento di file in Cloud Storage, consulta Crea bucket e Carica oggetti da un file system.
Oracle
Per richiedere un feedback o assistenza per questa funzionalità, invia un'email all'indirizzo bq-edw-migration-support@google.com.
Carica il file ZIP contenente i metadati e le statistiche sul rendimento in un bucket Cloud Storage. Per impostazione predefinita, il nome del file zip è
dwh-migration-oracle-stats.zip, ma puoi personalizzarlo specificandolo
nel flag --output. Il limite per le dimensioni totali non compresse di tutti i
file all'interno del file ZIP è 50 GB.
Per saperne di più sulla creazione di bucket e sul caricamento di file in Cloud Storage, consulta Crea bucket e Carica oggetti da un file system.
Hadoop / Cloudera
Per richiedere un feedback o assistenza per questa funzionalità, invia un'email all'indirizzo bq-edw-migration-support@google.com.
Carica il file ZIP contenente i metadati e le statistiche sul rendimento in un bucket Cloud Storage. Per impostazione predefinita, il nome del file ZIP è
dwh-migration-cloudera-manager-RUN_DATE.zip (ad esempio
dwh-migration-cloudera-manager-20250312T145808.zip), ma puoi
personalizzarlo con il flag --output. Il limite per le dimensioni totali non compresse
di tutti i file all'interno del file ZIP è 50 GB.
Per ulteriori informazioni sulla creazione di bucket e sul caricamento di file in Cloud Storage, consulta Creare un bucket e Caricare oggetti da un file system.
Apache Hive
Carica i metadati e le cartelle contenenti i log delle query da uno o più cluster Hive nel bucket Cloud Storage. Per saperne di più sulla creazione di bucket e sul caricamento di file in Cloud Storage, consulta Crea bucket e Carica oggetti da un file system.
Il limite per le dimensioni totali non compresse di tutti i file all'interno del file ZIP dei metadati è 50 GB.
Puoi utilizzare il connettore Cloud Storage per copiare i log delle query direttamente nella cartella Cloud Storage. Le cartelle contenenti le sottocartelle con i log delle query devono essere caricate nella stessa cartella Cloud Storage in cui viene caricato il file ZIP dei metadati.
Le cartelle dei log delle query contengono file della cronologia delle query con il prefisso dwhassessment_. Il limite per le dimensioni totali non compresse di tutti i file della cronologia delle query è 5 TB.
Informatica
Per richiedere un feedback o assistenza per questa funzionalità, invia un'email all'indirizzo bq-edw-migration-support@google.com.
Carica un file ZIP contenente gli oggetti del repository XML di Informatica in un bucket Cloud Storage. Questo file ZIP deve includere anche un file
compilerworks-metadata.yaml che contiene quanto segue:
product: arguments: "ConnectorArguments{connector=informatica, assessment=true}"
Il limite per le dimensioni totali non compresse di tutti i file all'interno del file ZIP è 50 GB.
Per saperne di più sulla creazione di bucket e sul caricamento di file in Cloud Storage, consulta Crea bucket e Carica oggetti da un file system.
Esegui una valutazione della migrazione di BigQuery
Segui questi passaggi per eseguire la valutazione della migrazione di BigQuery. Questi passaggi presuppongono che tu abbia caricato i file di metadati in un bucket Cloud Storage, come descritto nella sezione precedente.
Autorizzazioni obbligatorie
Per abilitare BigQuery Migration Service, devi disporre delle seguenti autorizzazioni Identity and Access Management (IAM):
resourcemanager.projects.getresourcemanager.projects.updateserviceusage.services.enableserviceusage.services.get
Per accedere e utilizzare BigQuery Migration Service, devi disporre delle seguenti autorizzazioni per il progetto:
bigquerymigration.workflows.createbigquerymigration.workflows.getbigquerymigration.workflows.listbigquerymigration.workflows.deletebigquerymigration.subtasks.getbigquerymigration.subtasks.list
Per eseguire BigQuery Migration Service, devi disporre delle seguenti autorizzazioni aggiuntive.
Autorizzazione per accedere ai bucket Cloud Storage per i file di input e output:
storage.objects.getsul bucket Cloud Storage di originestorage.objects.listsul bucket Cloud Storage di originestorage.objects.createsul bucket Cloud Storage di destinazionestorage.objects.deletesul bucket Cloud Storage di destinazionestorage.objects.updatesul bucket Cloud Storage di destinazionestorage.buckets.getstorage.buckets.list
L'autorizzazione per leggere e aggiornare il set di dati BigQuery in cui BigQuery Migration Service scrive i risultati:
bigquery.datasets.updatebigquery.datasets.getbigquery.datasets.createbigquery.datasets.deletebigquery.jobs.createbigquery.jobs.deletebigquery.jobs.listbigquery.jobs.updatebigquery.tables.createbigquery.tables.getbigquery.tables.getDatabigquery.tables.listbigquery.tables.updateData
Per condividere il report di Looker Studio con un utente, devi concedere i seguenti ruoli:
roles/bigquery.dataViewerroles/bigquery.jobUser
Per personalizzare questo documento in modo da utilizzare il tuo progetto e il tuo utente nei comandi, modifica queste variabili:
PROJECT,
USER_EMAIL.
Crea un ruolo personalizzato con le autorizzazioni necessarie per utilizzare la valutazione della migrazione di BigQuery:
gcloud iam roles create BQMSrole \ --project=PROJECT \ --title=BQMSrole \ --permissions=bigquerymigration.subtasks.get,bigquerymigration.subtasks.list,bigquerymigration.workflows.create,bigquerymigration.workflows.get,bigquerymigration.workflows.list,bigquerymigration.workflows.delete,resourcemanager.projects.update,resourcemanager.projects.get,serviceusage.services.enable,serviceusage.services.get,storage.objects.get,storage.objects.list,storage.objects.create,storage.objects.delete,storage.objects.update,bigquery.datasets.get,bigquery.datasets.update,bigquery.datasets.create,bigquery.datasets.delete,bigquery.tables.get,bigquery.tables.create,bigquery.tables.updateData,bigquery.tables.getData,bigquery.tables.list,bigquery.jobs.create,bigquery.jobs.update,bigquery.jobs.list,bigquery.jobs.delete,storage.buckets.list,storage.buckets.get
Concedi il ruolo personalizzato BQMSrole a un utente:
gcloud projects add-iam-policy-binding \ PROJECT \ --member=user:USER_EMAIL \ --role=projects/PROJECT/roles/BQMSrole
Concedi i ruoli richiesti a un utente con cui vuoi condividere il report:
gcloud projects add-iam-policy-binding \ PROJECT \ --member=user:USER_EMAIL \ --role=roles/bigquery.dataViewer gcloud projects add-iam-policy-binding \ PROJECT \ --member=user:USER_EMAIL \ --role=roles/bigquery.jobUser
Località supportate
La funzionalità di valutazione della migrazione di BigQuery è supportata in due tipi di località:
Una regione è un luogo geografico ben preciso, come Londra.
Una località a più regioni è una realtà geografica di grandi dimensioni, come gli Stati Uniti, che contiene due o più regioni. Le località multiregionali possono fornire quote più grandi rispetto alle singole regioni.
Per saperne di più su regioni e zone, consulta Area geografica e regioni.
Regioni
La seguente tabella elenca le regioni delle Americhe in cui è disponibile la valutazione della migrazione di BigQuery.| Descrizione della regione | Nome regione | Dettagli |
|---|---|---|
| Columbus, Ohio | us-east5 |
|
| Dallas | us-south1 |
|
| Iowa | us-central1 |
|
| Carolina del Sud | us-east1 |
|
| Virginia del Nord | us-east4 |
|
| Oregon | us-west1 |
|
| Los Angeles | us-west2 |
|
| Salt Lake City | us-west3 |
| Descrizione della regione | Nome regione | Dettagli |
|---|---|---|
| Singapore | asia-southeast1 |
|
| Tokyo | asia-northeast1 |
| Descrizione della regione | Nome regione | Dettagli |
|---|---|---|
| Belgio | europe-west1 |
|
| Finlandia | europe-north1 |
|
| Francoforte | europe-west3 |
|
| Londra | europe-west2 |
|
| Madrid | europe-southwest1 |
|
| Paesi Bassi | europe-west4 |
|
| Parigi | europe-west9 |
|
| Torino | europe-west12 |
|
| Varsavia | europe-central2 |
|
| Zurigo | europe-west6 |
|
Più regioni
La tabella seguente elenca le multiregioni in cui è disponibile la valutazione della migrazione di BigQuery.| Descrizione multiregionale | Nome multiregionale |
|---|---|
| Data center all'interno degli stati membri dell'Unione Europea | EU |
| Data center negli Stati Uniti | US |
Prima di iniziare
Prima di eseguire la valutazione, devi abilitare l'API BigQuery Migration e creare un set di dati BigQuery per archiviare i risultati della valutazione.
Abilita l'API BigQuery Migration
Abilita l'API BigQuery Migration nel seguente modo:
Nella console Google Cloud , vai alla pagina API BigQuery Migration.
Fai clic su Attiva.
Creare un set di dati per i risultati del test
La valutazione della migrazione di BigQuery scrive i risultati della valutazione nelle tabelle di BigQuery. Prima di iniziare, crea un set di dati in cui archiviare queste tabelle. Quando condividi il report di Looker Studio, devi anche concedere agli utenti l'autorizzazione a leggere questo set di dati. Per saperne di più, vedi Rendere disponibile il report agli utenti.
Esegui la valutazione della migrazione
Console
Nella console Google Cloud , vai alla pagina BigQuery.
Nel menu di navigazione, fai clic su Valutazione.
Fai clic su Inizia valutazione.
Compila la finestra di dialogo di configurazione del test.
- Per Nome visualizzato, inserisci il nome che può contenere lettere, numeri o trattini bassi. Questo nome è solo a scopo di visualizzazione e non deve essere univoco.
Nell'elenco Località dei dati, scegli una località per il job di valutazione. Il job di valutazione deve trovarsi nella stessa località del bucket Cloud Storage di input dei file estratti e del set di dati BigQuery di output. Tuttavia, se il bucket Cloud Storage o il set di dati BigQuery si trova in una regione multipla, il job di valutazione deve trovarsi in una delle regioni all'interno di questa regione multipla.
Se la località di valutazione è una regione multipla
USoEU, la località del bucket Cloud Storage e la località del set di dati BigQuery devono trovarsi nella stessa regione multipla o nella località all'interno di questa regione multipla. Per ulteriori informazioni sui vincoli di località, consulta Considerazioni sulla località di caricamento dei dati di BigQuery .Per Origine dati di valutazione, scegli il data warehouse.
In Percorso dei file di input, inserisci il percorso del bucket Cloud Storage che contiene i file estratti.
Per scegliere come archiviare i risultati del test, seleziona una delle seguenti opzioni:
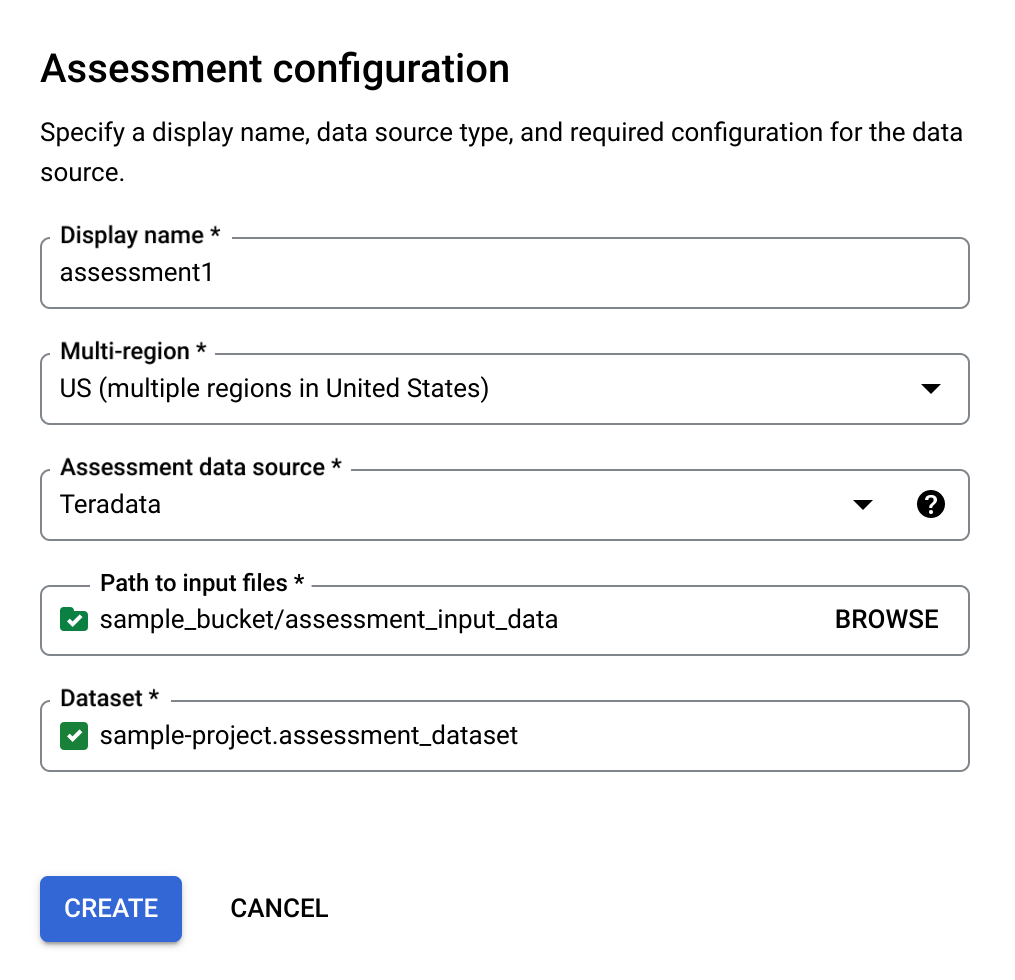
- Mantieni selezionata la casella di controllo Crea automaticamente il nuovo set di dati BigQuery per creare automaticamente il set di dati BigQuery. Il nome del set di dati viene generato automaticamente.
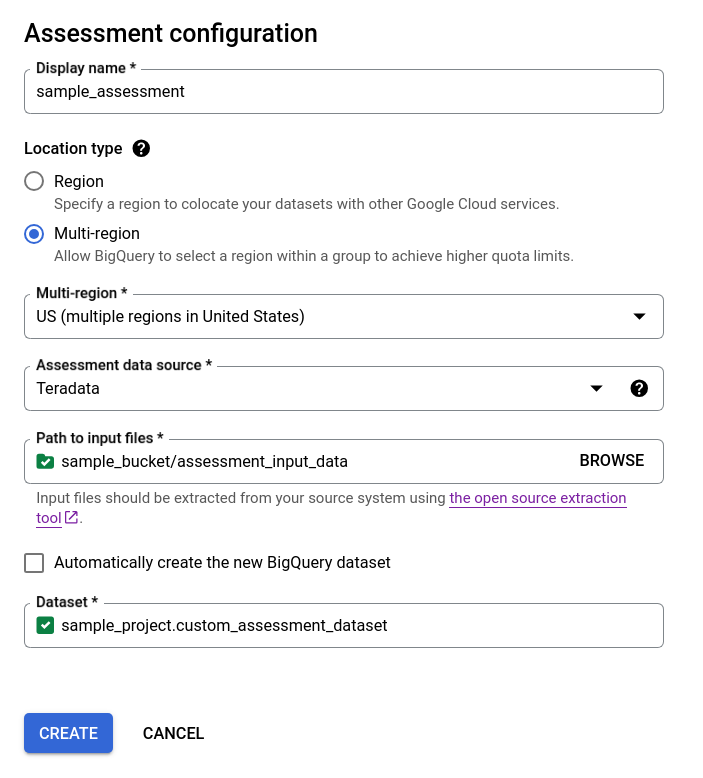
- Deseleziona la casella di controllo Crea automaticamente il nuovo set di dati BigQuery e scegli il set di dati BigQuery vuoto esistente utilizzando il formato
projectId.datasetIdoppure crea un nuovo nome del set di dati. In questa opzione puoi scegliere il nome del set di dati BigQuery.
Opzione 1: generazione automatica del set di dati BigQuery (impostazione predefinita)
Opzione 2: creazione manuale del set di dati BigQuery:
Fai clic su Crea. Puoi visualizzare lo stato del job nell'elenco dei job di valutazione.
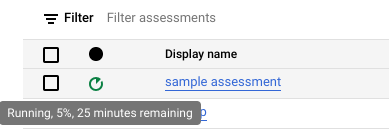
Durante l'esecuzione della valutazione, puoi controllare l'avanzamento e il tempo stimato per il completamento nella descrizione comando dell'icona di stato.
Durante l'esecuzione del test, puoi fare clic sul link Visualizza report nell'elenco dei job di test per visualizzare il report con dati parziali in Looker Studio. Il link Visualizza report potrebbe impiegare un po' di tempo per essere visualizzato durante l'esecuzione del test. Il report si apre in una nuova scheda.
Il report viene aggiornato con i nuovi dati man mano che vengono elaborati. Aggiorna la scheda con il report o fai di nuovo clic su Visualizza report per visualizzare il report aggiornato.
Al termine della valutazione, fai clic su Visualizza report per visualizzare il report completo della valutazione in Looker Studio. Il report si apre in una nuova scheda.
API
Chiama il metodo create con un workflow definito.
Quindi chiama il metodo start
per avviare il flusso di lavoro di valutazione.
La valutazione crea tabelle nel set di dati BigQuery creato in precedenza. Puoi eseguire query su questi per informazioni sulle tabelle e sulle query utilizzate nel tuo data warehouse esistente. Per informazioni sui file di output della traduzione, consulta Traduttore SQL batch.
Risultato aggregato del test condivisibile
Per le valutazioni di Amazon Redshift, Teradata e Snowflake, oltre al set di dati BigQuery creato in precedenza, il flusso di lavoro crea un altro set di dati leggero con lo stesso nome, più il suffisso _shareableRedactedAggregate. Questo set di dati contiene dati altamente aggregati derivati dal set di dati di output e non contiene informazioni che consentono l'identificazione personale (PII).
Per trovare, esaminare e condividere in modo sicuro il set di dati con altri utenti, consulta Eseguire query sulle tabelle di output della valutazione della migrazione.
La funzionalità è attiva per impostazione predefinita, ma puoi disattivarla utilizzando l'API pubblica.
Dettagli valutazione
Per visualizzare la pagina dei dettagli del test, fai clic sul nome visualizzato nell'elenco dei job di test.

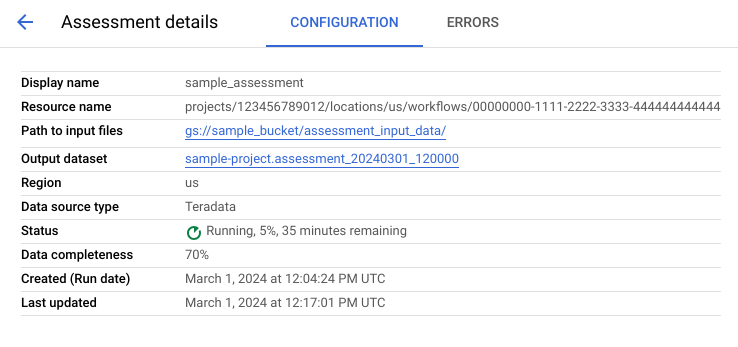
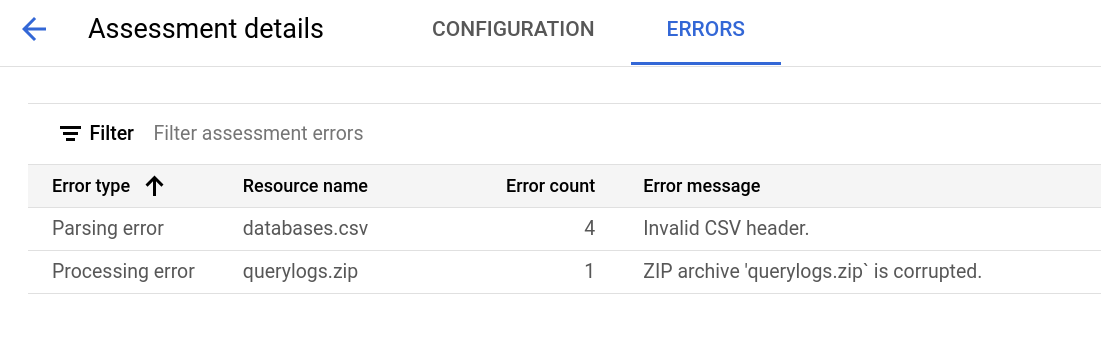
La pagina dei dettagli della valutazione contiene la scheda Configurazione, in cui puoi visualizzare ulteriori informazioni su un job di valutazione, e la scheda Errori, in cui puoi esaminare gli errori che si sono verificati durante l'elaborazione della valutazione.
Visualizza la scheda Configurazione per vedere le proprietà della valutazione.
Visualizza la scheda Errori per vedere gli errori che si sono verificati durante l'elaborazione del test.
Esaminare e condividere il report di Looker Studio
Al termine dell'attività di valutazione, puoi creare e condividere un report di Looker Studio sui risultati.
Esaminare il report
Fai clic sul link Visualizza report elencato accanto all'attività di valutazione individuale. Il report di Looker Studio si apre in una nuova scheda, in modalità di anteprima. Puoi utilizzare la modalità di anteprima per esaminare i contenuti del report prima di condividerli ulteriormente.
Il report è simile alla seguente schermata:
Per visualizzare le viste contenute nel report, seleziona il data warehouse:
Teradata
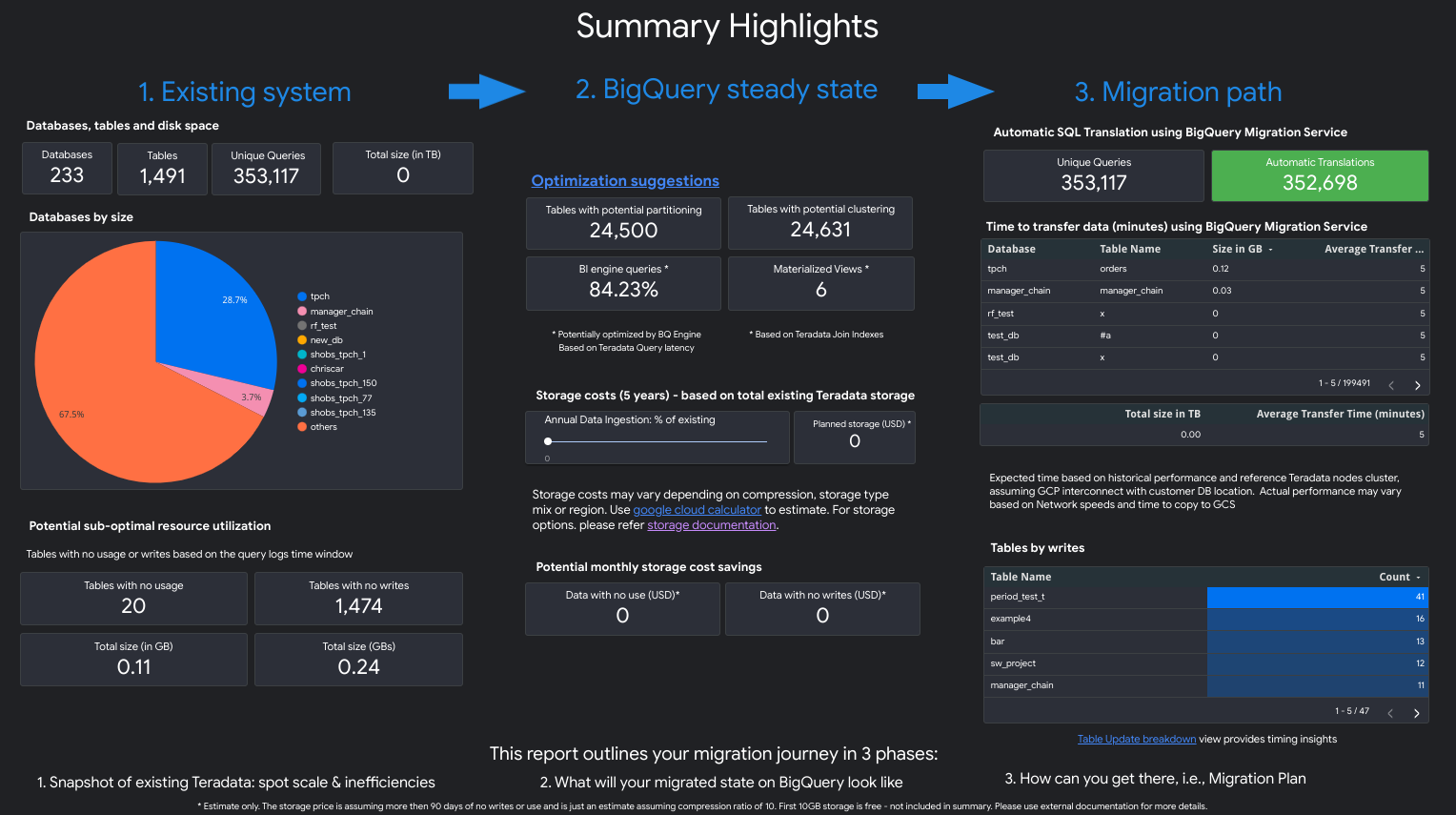
Il report è una narrazione in tre parti preceduta da una pagina di riepilogo con i punti salienti. Questa pagina include le seguenti sezioni:
- Sistema esistente. Questa sezione è un'istantanea del sistema e dell'utilizzo di Teradata esistenti, incluso il numero di database, schemi, tabelle e dimensioni totali in TB. Elenca inoltre gli schemi per dimensione e indica un potenziale utilizzo non ottimale delle risorse (tabelle senza scritture o con poche letture).
- Trasformazioni di stato stazionario di BigQuery (suggerimenti). Questa sezione mostra l'aspetto del sistema su BigQuery dopo la migrazione. Include suggerimenti per ottimizzare i workload su BigQuery (ed evitare sprechi).
- Piano di migrazione. Questa sezione fornisce informazioni sull'impegno di migrazione stesso, ad esempio il passaggio dal sistema esistente allo stato stabile di BigQuery. Questa sezione include il conteggio delle query che sono state tradotte automaticamente e il tempo previsto per spostare ogni tabella in BigQuery.
I dettagli di ogni sezione includono quanto segue:
Sistema esistente
- Calcolo e query
- Utilizzo CPU:
- Mappa termica dell'utilizzo medio orario della CPU (visualizzazione dell'utilizzo complessivo delle risorse di sistema)
- Query per ora e giorno con utilizzo della CPU
- Query per tipo (lettura/scrittura) con utilizzo della CPU
- Applicazioni con utilizzo della CPU
- Sovrapposizione dell'utilizzo orario della CPU con le prestazioni medie orarie delle query e le prestazioni medie orarie delle applicazioni
- Istogramma delle query per tipo e durata
- Visualizzazione dei dettagli delle applicazioni (app, utente, query uniche, suddivisione dei report rispetto all'ETL)
- Utilizzo CPU:
- Panoramica dello spazio di archiviazione
- Database per volume, visualizzazioni e tassi di accesso
- Tabelle con tassi di accesso per utenti, query, scritture e creazioni di tabelle temporanee
- Applicazioni: tassi di accesso e indirizzi IP
Trasformazioni di stato stazionario di BigQuery (suggerimenti)
- Indici di join convertiti in viste materializzate
- Candidati per il clustering e il partizionamento in base a metadati e utilizzo
- Query a bassa latenza identificate come candidate per BigQuery BI Engine
- Colonne configurate con valori predefiniti che utilizzano la funzionalità di descrizione della colonna per memorizzare i valori predefiniti
- Gli indici univoci in Teradata
(per impedire righe con chiavi non univoche in
una tabella) utilizzano tabelle di staging e un'istruzione
MERGEper inserire solo record univoci nelle tabelle di destinazione e poi eliminare i duplicati - Query rimanenti e schema tradotto così com'è
Piano di migrazione
- Visualizzazione dettagliata con query tradotte automaticamente
- Conteggio delle query totali con possibilità di filtrare per utente, applicazione, tabelle interessate, tabelle sottoposte a query e tipo di query
- Bucket di query con pattern simili raggruppati e mostrati insieme in modo che l'utente possa vedere la filosofia di traduzione per tipi di query
- Query che richiedono l'intervento umano
- Query con violazioni della struttura lessicale di BigQuery
- Funzioni e procedure definite dall'utente
- Parole chiave riservate di BigQuery
- Tabelle pianificate per scritture e letture (per raggrupparle per lo spostamento)
- Migrazione dei dati con BigQuery Data Transfer Service: Tempo stimato per la migrazione per tabella
La sezione Sistema esistente contiene le seguenti visualizzazioni:
- Panoramica del sistema
- La visualizzazione Panoramica del sistema fornisce le metriche di volume di alto livello dei componenti chiave nel sistema esistente per un periodo di tempo specificato. La sequenza temporale valutata dipende dai log analizzati dalla valutazione della migrazione di BigQuery. Questa visualizzazione fornisce informazioni rapide sull'utilizzo del data warehouse di origine, che puoi utilizzare per la pianificazione della migrazione.
- Volume della tabella
- La visualizzazione Volume tabella fornisce statistiche sulle tabelle e sui database più grandi trovati dalla valutazione della migrazione BigQuery. Poiché le tabelle di grandi dimensioni potrebbero richiedere più tempo per l'estrazione dal sistema di data warehouse di origine, questa visualizzazione può essere utile per la pianificazione e il sequenziamento della migrazione.
- Utilizzo della tabella
- La visualizzazione Utilizzo tabella fornisce statistiche sulle tabelle più utilizzate all'interno del sistema di data warehouse di origine. Le tabelle più utilizzate possono aiutarti a capire quali tabelle potrebbero avere molte dipendenze e richiedere una pianificazione aggiuntiva durante il processo di migrazione.
- Applicazioni
- Le visualizzazioni Utilizzo delle applicazioni e Pattern delle applicazioni forniscono statistiche sulle applicazioni trovate durante l'elaborazione dei log. Queste visualizzazioni consentono agli utenti di comprendere l'utilizzo di applicazioni specifiche nel tempo e l'impatto sull'utilizzo delle risorse. Durante una migrazione, è importante visualizzare l'importazione e il consumo dei dati per comprendere meglio le dipendenze del data warehouse e analizzare l'impatto dello spostamento di varie applicazioni dipendenti insieme. La tabella Indirizzo IP può essere utile per individuare l'applicazione esatta che utilizza il data warehouse tramite connessioni JDBC.
- Query
- La visualizzazione Query fornisce una suddivisione dei tipi di istruzioni SQL eseguite e statistiche sul loro utilizzo. Puoi utilizzare l'istogramma di Tipo di query e Ora per identificare i periodi di bassa utilizzazione del sistema e le ore ottimali della giornata per trasferire i dati. Puoi anche utilizzare questa visualizzazione per identificare le query eseguite di frequente e gli utenti che le richiamano.
- Database
- La visualizzazione Database fornisce metriche su dimensioni, tabelle, viste e procedure definite nel sistema di data warehouse di origine. Questa visualizzazione può fornire informazioni sul volume di oggetti di cui devi eseguire la migrazione.
- Accoppiamento del database
- La visualizzazione Accoppiamento database fornisce una panoramica generale dei database e delle tabelle a cui si accede insieme in una singola query. Questa visualizzazione può mostrare le tabelle e i database a cui viene fatto spesso riferimento e cosa puoi utilizzare per la pianificazione della migrazione.
La sezione Stato stazionario di BigQuery contiene le seguenti visualizzazioni:
- Tabelle senza utilizzo
- La visualizzazione Tabelle senza utilizzo mostra le tabelle in cui la valutazione della migrazione BigQuery non ha trovato alcun utilizzo durante il periodo dei log analizzato. La mancanza di utilizzo potrebbe indicare che non è necessario trasferire la tabella a BigQuery durante la migrazione o che i costi di archiviazione dei dati in BigQuery potrebbero essere inferiori. Devi convalidare l'elenco delle tabelle inutilizzate perché potrebbero essere utilizzate al di fuori del periodo dei log, ad esempio una tabella utilizzata solo una volta ogni tre o sei mesi.
- Tabelle senza scritture
- La visualizzazione Tabelle senza scritture mostra le tabelle in cui la valutazione della migrazione di BigQuery non è riuscita a trovare aggiornamenti durante il periodo dei log analizzati. La mancanza di scritture può indicare dove potresti ridurre i costi di archiviazione in BigQuery.
- Query a bassa latenza
- La visualizzazione Query a bassa latenza mostra una distribuzione dei tempi di esecuzione delle query in base ai dati di log analizzati. Se il grafico della distribuzione della durata delle query mostra un numero elevato di query con un tempo di esecuzione inferiore a 1 secondo, valuta la possibilità di attivare BigQuery BI Engine per accelerare la BI e altri carichi di lavoro a bassa latenza.
- Viste materializzate
- La vista materializzata fornisce ulteriori suggerimenti di ottimizzazione per migliorare le prestazioni su BigQuery.
- Clustering e partizionamento
La visualizzazione Partizionamento e clustering mostra le tabelle che trarrebbero vantaggio dal partizionamento, dal clustering o da entrambi.
I suggerimenti per i metadati vengono ottenuti analizzando lo schema del data warehouse di origine (ad esempio il partizionamento e la chiave primaria nella tabella di origine) e trovando l'equivalente BigQuery più vicino per ottenere caratteristiche di ottimizzazione simili.
I suggerimenti per il workload vengono ottenuti analizzando i log delle query di origine. Il consiglio viene determinato analizzando i workload, in particolare le clausole
WHEREoJOINnei log delle query analizzati.- Suggerimento di clustering
La visualizzazione Partizionamento mostra le tabelle che potrebbero avere più di 10.000 partizioni, in base alla definizione del vincolo di partizionamento. Queste tabelle tendono a essere buone candidate per il clustering BigQuery, che consente partizioni di tabelle granulari.
- Vincoli univoci
La visualizzazione Vincoli univoci mostra sia le tabelle
SETsia gli indici univoci definiti all'interno del data warehouse di origine. In BigQuery, è consigliabile utilizzare tabelle di gestione temporanea e un'istruzioneMERGEper inserire solo record univoci in una tabella di destinazione. Utilizza i contenuti di questa visualizzazione per determinare le tabelle per cui potrebbe essere necessario modificare l'ETL durante la migrazione.- Valori predefiniti / Vincoli di controllo
Questa visualizzazione mostra le tabelle che utilizzano i vincoli di controllo per impostare i valori predefiniti delle colonne. In BigQuery, vedi Specificare i valori predefiniti delle colonne.
La sezione Percorso di migrazione del report contiene le seguenti visualizzazioni:
- Traduzione SQL
- La visualizzazione Traduzione SQL elenca il conteggio e i dettagli delle query che sono state convertite automaticamente dalla valutazione della migrazione BigQuery e non richiedono un intervento manuale. La traduzione SQL automatica in genere raggiunge tassi di traduzione elevati se vengono forniti i metadati. Questa visualizzazione è interattiva e consente di analizzare le query comuni e la loro traduzione.
- Impegno offline
- La visualizzazione Sforzo offline acquisisce le aree che richiedono un intervento manuale, incluse UDF specifiche e potenziali violazioni della struttura lessicale e della sintassi per tabelle o colonne.
- Parole chiave riservate di BigQuery
- La visualizzazione BigQuery Reserved Keywords mostra l'utilizzo rilevato
di parole chiave che hanno un significato speciale nel linguaggio GoogleSQL
e non possono essere utilizzate come identificatori a meno che non siano racchiuse tra caratteri
di apice inverso (
`). - Pianificazione degli aggiornamenti delle tabelle
- La visualizzazione Pianificazione aggiornamenti tabelle mostra quando e con quale frequenza vengono aggiornate le tabelle per aiutarti a pianificare come e quando spostarle.
- Migrazione dei dati a BigQuery
- La visualizzazione Migrazione dei dati a BigQuery delinea il percorso di migrazione con il tempo previsto per eseguire la migrazione dei dati utilizzando BigQuery Data Transfer Service. Per saperne di più, consulta la guida a BigQuery Data Transfer Service per Teradata.
La sezione Appendice contiene le seguenti visualizzazioni:
- Distinzione tra maiuscole e minuscole
- La visualizzazione Distinzione tra maiuscole e minuscole mostra le tabelle nel data warehouse di origine configurate per eseguire confronti senza distinzione tra maiuscole e minuscole. Per impostazione predefinita, i confronti tra stringhe in BigQuery fanno distinzione tra maiuscole e minuscole. Per ulteriori informazioni, vedi Collation.
Redshift
- Punti salienti della migrazione
- La visualizzazione Punti salienti della migrazione fornisce un riepilogo delle tre sezioni del report:
- Il riquadro Sistema esistente fornisce informazioni sul numero di database, schemi, tabelle e sulle dimensioni totali del sistema Redshift esistente. Elenca inoltre gli schemi in base alle dimensioni e al potenziale utilizzo non ottimale delle risorse. Puoi utilizzare queste informazioni per ottimizzare i dati rimuovendo, partizionando o raggruppando in cluster le tabelle.
- Il riquadro Stato stazionario di BigQuery fornisce informazioni su come appariranno i tuoi dati dopo la migrazione su BigQuery, incluso il numero di query che possono essere tradotte automaticamente utilizzando BigQuery Migration Service. Questa sezione mostra anche i costi di archiviazione dei dati in BigQuery in base al tasso di importazione annuale dei dati, insieme a suggerimenti per l'ottimizzazione di tabelle, provisioning e spazio.
- Il riquadro Percorso di migrazione fornisce informazioni sullo sforzo di migrazione stesso. Per ogni tabella vengono visualizzati il tempo previsto per la migrazione, il numero di righe nella tabella e le dimensioni.
La sezione Sistema esistente contiene le seguenti visualizzazioni:
- Query per tipo e pianificazione
- La visualizzazione Query per tipo e pianificazione classifica le query in ETL/Scrittura e Report/Aggregazione. Visualizzare il mix di query nel tempo ti aiuta a comprendere i pattern di utilizzo esistenti e a identificare i picchi e il potenziale overprovisioning che possono influire su costi e prestazioni.
- Inserimento in coda delle query
- La visualizzazione Accodamento query fornisce ulteriori dettagli sul carico del sistema, tra cui volume e mix di query, nonché eventuali impatti sulle prestazioni dovuti all'accodamento, ad esempio risorse insufficienti.
- Query e scalabilità WLM
- La visualizzazione Scalabilità di query e WLM identifica la scalabilità della concorrenza come costo aggiuntivo e complessità di configurazione. Mostra in che modo il sistema Redshift instrada le query in base alle regole specificate e gli impatti sul rendimento dovuti a code, scalabilità della concorrenza e query eliminate.
- In coda e in attesa
- La visualizzazione Accodamento e attesa offre una visione più approfondita dei tempi di attesa e di accodamento delle query nel tempo.
- Classi WLM e prestazioni
- La visualizzazione Classi e prestazioni WLM offre un modo facoltativo per mappare le regole a BigQuery. Tuttavia, ti consigliamo di lasciare che BigQuery esegua automaticamente il routing delle query.
- Query & Table volume insights
- La visualizzazione Approfondimenti sul volume di query e tabelle elenca le query in base a dimensioni, frequenza e utenti principali. Ciò ti aiuta a classificare le origini del carico sul sistema e a pianificare la migrazione dei workload.
- Database e schemi
- La visualizzazione Database e schemi fornisce metriche su dimensioni, tabelle, viste e procedure definite nel sistema di data warehouse di origine. Ciò fornisce informazioni sul volume di oggetti di cui è necessaria la migrazione.
- Volume della tabella
- La visualizzazione Volume tabella fornisce statistiche sulle tabelle e sui database più grandi, mostrando come vengono consultati. Poiché le tabelle di grandi dimensioni potrebbero richiedere più tempo per l'estrazione dal sistema di data warehouse di origine, questa visualizzazione ti aiuta con la pianificazione e il sequenziamento della migrazione.
- Utilizzo della tabella
- La visualizzazione Utilizzo tabella fornisce statistiche sulle tabelle più utilizzate all'interno del sistema di data warehouse di origine. Le tabelle utilizzate di frequente possono essere sfruttate per comprendere le tabelle che potrebbero avere molte dipendenze e richiedere una pianificazione aggiuntiva durante il processo di migrazione.
- Importatori ed esportatori
- La visualizzazione Importatori ed esportatori fornisce informazioni sui dati e sugli utenti
coinvolti nell'importazione dei dati (utilizzando query
COPY) e nell'esportazione dei dati (utilizzando queryUNLOAD). Questa visualizzazione consente di identificare il livello di gestione temporanea e i processi correlati all'importazione e alle esportazioni. - Utilizzo del cluster
- La visualizzazione Utilizzo cluster fornisce informazioni generali su tutti i cluster disponibili e mostra l'utilizzo della CPU per ciascun cluster. Questa visualizzazione può aiutarti a comprendere la riserva di capacità del sistema.
La sezione Stato stazionario di BigQuery contiene le seguenti visualizzazioni:
- Clustering e partizionamento
La visualizzazione Partizionamento e clustering mostra le tabelle che trarrebbero vantaggio dal partizionamento, dal clustering o da entrambi.
I suggerimenti per i metadati vengono ottenuti analizzando lo schema del data warehouse di origine (come la chiave di ordinamento e la chiave di distribuzione nella tabella di origine) e trovando l'equivalente BigQuery più vicino per ottenere caratteristiche di ottimizzazione simili.
I suggerimenti per il workload vengono ottenuti analizzando i log delle query di origine. Il consiglio viene determinato analizzando i workload, in particolare le clausole
WHEREoJOINnei log delle query analizzati.Nella parte inferiore della pagina è presente un'istruzione CREATE TABLE tradotta con tutte le ottimizzazioni fornite. Tutte le istruzioni DDL tradotte possono essere estratte anche dal set di dati. Le istruzioni DDL tradotte vengono memorizzate nella tabella
SchemaConversionnella colonnaCreateTableDDL.I suggerimenti nel report vengono forniti solo per le tabelle più grandi di 1 GB, perché le tabelle piccole non traggono vantaggio dal clustering e dal partizionamento. Tuttavia, il DDL per tutte le tabelle (incluse quelle più piccole di 1 GB) è disponibile nella tabella
SchemaConversion.- Tabelle senza utilizzo
La visualizzazione Tabelle senza utilizzo mostra le tabelle in cui la valutazione della migrazione BigQuery non ha identificato alcun utilizzo durante il periodo dei log analizzati. La mancanza di utilizzo potrebbe indicare che non è necessario trasferire la tabella a BigQuery durante la migrazione o che i costi di archiviazione dei dati in BigQuery potrebbero essere inferiori (fatturati come Archiviazione a lungo termine). Ti consigliamo di convalidare l'elenco delle tabelle inutilizzate perché potrebbero essere utilizzate al di fuori del periodo dei log, ad esempio una tabella utilizzata solo una volta ogni tre o sei mesi.
- Tabelle senza scritture
La visualizzazione Tabelle senza scritture mostra le tabelle in cui la valutazione della migrazione BigQuery non ha identificato aggiornamenti durante il periodo dei log analizzati. La mancanza di scritture può indicare dove potresti ridurre i costi di archiviazione in BigQuery (fatturati come Archiviazione a lungo termine).
- BigQuery BI Engine e viste materializzate
BigQuery BI Engine e le viste materializzate forniscono ulteriori suggerimenti per l'ottimizzazione per migliorare le prestazioni su BigQuery.
La sezione Percorso di migrazione contiene le seguenti viste:
- Traduzione SQL
- La visualizzazione Traduzione SQL elenca il conteggio e i dettagli delle query che sono state convertite automaticamente dalla valutazione della migrazione BigQuery e non richiedono un intervento manuale. La traduzione SQL automatica in genere raggiunge tassi di traduzione elevati se vengono forniti i metadati.
- SQL Translation Offline Effort
- La visualizzazione Sforzo di traduzione SQL offline acquisisce le aree che richiedono un intervento manuale, incluse query e funzioni definite dall'utente specifiche con potenziali ambiguità di traduzione.
- Supporto per l'aggiunta di tabelle
- La visualizzazione Supporto di Alter Table Append mostra i dettagli dei costrutti SQL Redshift comuni che non hanno una controparte BigQuery diretta.
- Supporto del comando Copia
- La visualizzazione Supporto del comando COPY mostra i dettagli dei costrutti SQL Redshift comuni che non hanno una controparte BigQuery diretta.
- Avvisi SQL
- La visualizzazione Avvisi SQL acquisisce le aree tradotte correttamente, ma che richiedono una revisione.
- Violazioni della struttura lessicale e della sintassi
- La visualizzazione Violazioni della struttura lessicale e della sintassi mostra i nomi di colonne, tabelle, funzioni e procedure che violano la sintassi BigQuery.
- Parole chiave riservate di BigQuery
- La visualizzazione BigQuery Reserved Keywords mostra l'utilizzo rilevato
di parole chiave che hanno un significato speciale nel linguaggio GoogleSQL
e non possono essere utilizzate come identificatori a meno che non siano racchiuse tra caratteri
di apice inverso (
`). - Schema Coupling
- La visualizzazione Accoppiamento schema fornisce una panoramica di database, schemi e tabelle a cui si accede insieme in una singola query. Questa visualizzazione può mostrare le tabelle, gli schemi e i database a cui viene fatto spesso riferimento e cosa puoi utilizzare per la pianificazione della migrazione.
- Pianificazione degli aggiornamenti delle tabelle
- La visualizzazione Pianificazione aggiornamenti tabelle mostra quando e con quale frequenza vengono aggiornate le tabelle per aiutarti a pianificare come e quando spostarle.
- Scala della tabella
- La visualizzazione Scala tabella elenca le tabelle con il maggior numero di colonne.
- Migrazione dei dati a BigQuery
- La visualizzazione Migrazione dei dati a BigQuery delinea il percorso di migrazione con il tempo previsto per eseguire la migrazione dei dati utilizzando BigQuery Migration Service Data Transfer Service. Per ulteriori informazioni, consulta la guida a BigQuery Data Transfer Service per Redshift.
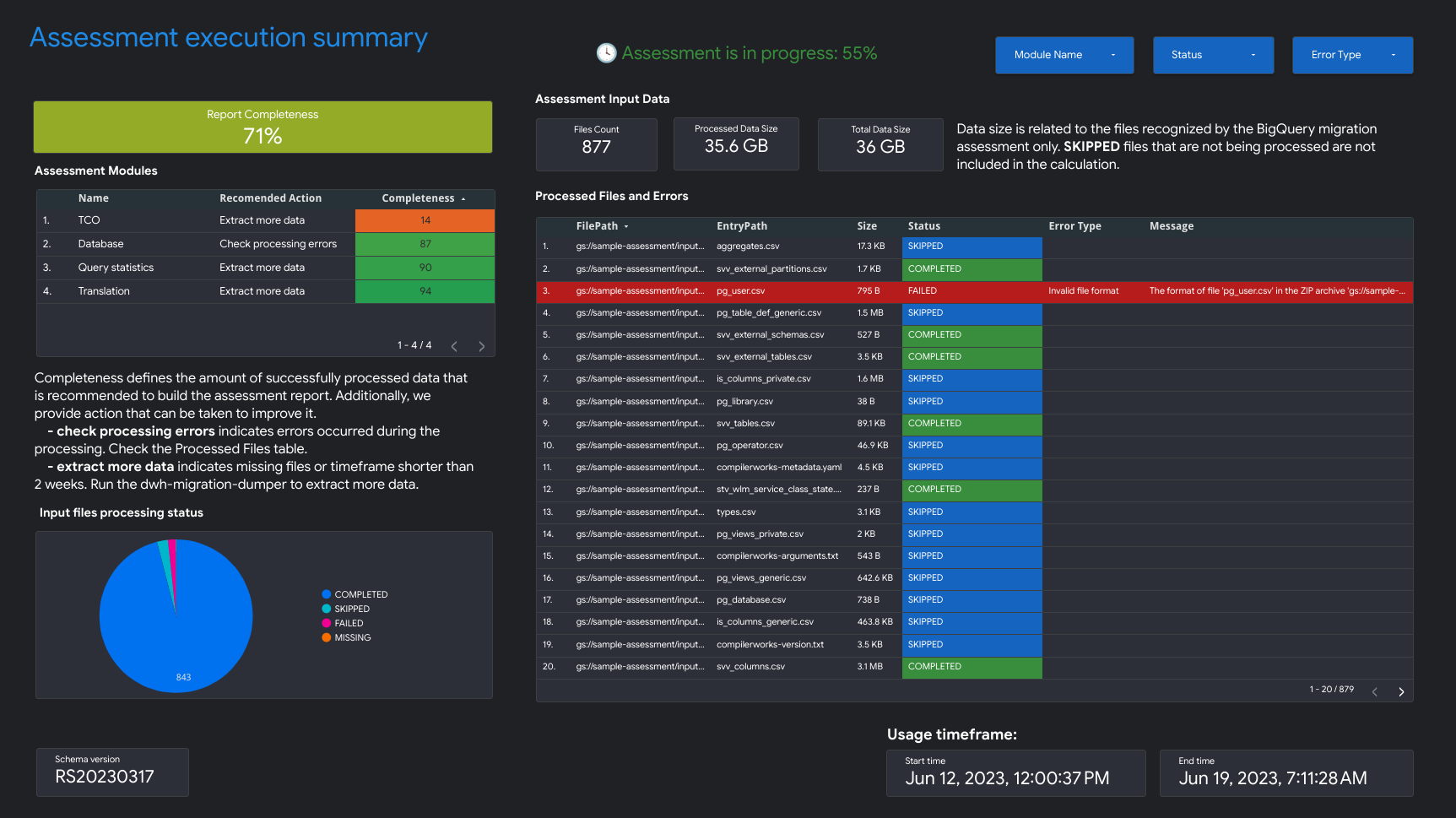
- Riepilogo dell'esecuzione del test
Il riepilogo dell'esecuzione della valutazione contiene il completamento del report, l'avanzamento della valutazione in corso e lo stato dei file elaborati e degli errori.
La completezza del report rappresenta la percentuale di dati elaborati correttamente che è consigliabile visualizzare per ottenere approfondimenti significativi nel report di valutazione. Se mancano i dati per una determinata sezione del report, queste informazioni sono elencate nella tabella Moduli di valutazione sotto l'indicatore Completezza del report.
La metrica Avanzamento indica la percentuale di dati elaborati finora, insieme alla stima del tempo rimanente per elaborare tutti i dati. Al termine dell'elaborazione, la metrica di avanzamento non viene visualizzata.
Redshift Serverless
- Punti salienti della migrazione
- Questa pagina del report mostra il riepilogo dei database Amazon Redshift Serverless esistenti, inclusi le dimensioni e il numero di tabelle. Inoltre, fornisce la stima di alto livello del valore del contratto annuale (ACV), ovvero il costo di calcolo e archiviazione in BigQuery. La visualizzazione Punti salienti della migrazione fornisce un riepilogo esecutivo delle tre sezioni del report.
La sezione Sistema esistente presenta le seguenti visualizzazioni:
- Database e schemi
- Fornisce una suddivisione delle dimensioni totali di archiviazione in GB per ogni database, schema o tabella.
- Database e schemi esterni
- Fornisce una suddivisione delle dimensioni totali di archiviazione in GB per ogni database, schema o tabella esterni.
- Utilizzo del sistema
- Fornisce informazioni generali sull'utilizzo storico del sistema. Questa visualizzazione mostra l'utilizzo storico delle RPU (Amazon Redshift Processing Units) e il consumo giornaliero di spazio di archiviazione. Questa visualizzazione può aiutarti a comprendere la riserva di capacità del sistema.
La sezione Stato stazionario di BigQuery fornisce informazioni sull'aspetto dei dati dopo la migrazione su BigQuery, incluso il numero di query che possono essere tradotte automaticamente utilizzando BigQuery Migration Service. Questa sezione mostra anche i costi di archiviazione dei dati in BigQuery in base alla velocità di importazione annuale dei dati, insieme a suggerimenti di ottimizzazione per tabelle, provisioning e spazio. La sezione Stato stazionario presenta le seguenti visualizzazioni:
- Prezzi di Amazon Redshift Serverless e BigQuery
- Fornisce un confronto tra i modelli di prezzi di Amazon Redshift Serverless e BigQuery per aiutarti a comprendere i vantaggi e i potenziali risparmi sui costi dopo la migrazione a BigQuery.
- Costo di calcolo di BigQuery (TCO)
- Consente di stimare il costo del calcolo in BigQuery. Il calcolatore prevede quattro input manuali: BigQuery Edition, regione, periodo di impegno e baseline. Per impostazione predefinita, il calcolatore fornisce impegni di base ottimali ed economici che puoi ignorare manualmente.
- Costo totale di proprietà
- Consente di stimare il valore annuo del contratto (ACV), ovvero il costo di computing e spazio di archiviazione in BigQuery. Il calcolatore consente anche di calcolare il costo di archiviazione, che varia per l'archiviazione attiva e l'archiviazione a lungo termine, a seconda delle modifiche alla tabella durante il periodo di tempo analizzato. Per maggiori informazioni, consulta la pagina Prezzi di archiviazione.
La sezione Appendice contiene questa visualizzazione:
- Riepilogo esecuzione valutazione
- Fornisce i dettagli di esecuzione della valutazione, inclusi l'elenco dei file elaborati, gli errori e il completamento del report. Puoi utilizzare questa pagina per analizzare i dati mancanti nel report e per comprendere meglio la completezza del report.
Snowflake
Il report è composto da diverse sezioni che possono essere utilizzate separatamente o insieme. Il seguente diagramma organizza queste sezioni in tre obiettivi utente comuni per aiutarti a valutare le tue esigenze di migrazione:
Visualizzazioni degli highlight della migrazione
La sezione Punti salienti della migrazione contiene le seguenti visualizzazioni:
- Modelli di determinazione dei prezzi di Snowflake e BigQuery
- Elenco dei prezzi con diversi livelli/versioni. Include anche un'illustrazione di come la scalabilità automatica di BigQuery può contribuire a risparmiare più costi rispetto a Snowflake.
- Costo totale di proprietà
- Tabella interattiva che consente all'utente di definire: edizione BigQuery, impegno, impegno di slot di base, percentuale di spazio di archiviazione attivo e percentuale di dati caricati o modificati. Consente di stimare meglio il costo per i casi personalizzati.
- Caratteristiche principali della traduzione automatica
- Rapporto di traduzione aggregato, raggruppato per utente o database, ordinato in ordine crescente o decrescente. Include anche il messaggio di errore più comune per la traduzione automatica non riuscita.
Viste di sistema esistenti
La sezione Sistema esistente contiene le seguenti visualizzazioni:
- Panoramica del sistema
- La visualizzazione Panoramica del sistema fornisce le metriche di volume di alto livello dei componenti chiave del sistema esistente per un periodo di tempo specificato. La cronologia valutata dipende dai log analizzati dalla valutazione della migrazione di BigQuery. Questa visualizzazione fornisce informazioni rapide sull'utilizzo del data warehouse di origine, che puoi utilizzare per la pianificazione della migrazione.
- Panoramica dei warehouse virtuali
- Mostra il costo di Snowflake per warehouse, nonché il ridimensionamento basato sui nodi nel periodo.
- Volume della tabella
- La visualizzazione Volume tabella fornisce statistiche sulle tabelle e sui database più grandi trovati dalla valutazione della migrazione BigQuery. Poiché le tabelle di grandi dimensioni potrebbero richiedere più tempo per l'estrazione dal sistema di data warehouse di origine, questa vista può essere utile per la pianificazione e il sequenziamento della migrazione.
- Utilizzo della tabella
- La visualizzazione Utilizzo tabella fornisce statistiche sulle tabelle più utilizzate all'interno del sistema di data warehouse di origine. Le tabelle più utilizzate possono aiutarti a capire quali potrebbero avere molte dipendenze e richiedere una pianificazione aggiuntiva durante il processo di migrazione.
- Query
- La visualizzazione Query fornisce una suddivisione dei tipi di istruzioni SQL eseguite e le statistiche del loro utilizzo. Puoi utilizzare l'istogramma di Tipo di query e Tempo per identificare i periodi di bassa utilizzazione del sistema e gli orari ottimali della giornata per trasferire i dati. Puoi anche utilizzare questa visualizzazione per identificare le query eseguite di frequente e gli utenti che le richiamano.
- Database
- La visualizzazione Database fornisce metriche su dimensioni, tabelle, viste e procedure definite nel sistema di data warehouse di origine. Questa visualizzazione fornisce informazioni sul volume di oggetti di cui devi eseguire la migrazione.
Viste di stato stazionario BigQuery
La sezione Stato stazionario di BigQuery contiene le seguenti visualizzazioni:
- Tabelle senza utilizzo
- La visualizzazione Tabelle senza utilizzo mostra le tabelle in cui la valutazione della migrazione BigQuery non ha trovato alcun utilizzo durante il periodo dei log analizzati. Ciò può indicare quali tabelle potrebbero non dover essere trasferite a BigQuery durante la migrazione o che i costi di archiviazione dei dati in BigQuery potrebbero essere inferiori. Devi convalidare l'elenco delle tabelle inutilizzate, poiché potrebbero essere utilizzate al di fuori del periodo dei log analizzato, ad esempio una tabella utilizzata solo una volta al trimestre o al semestre.
- Tabelle senza scritture
- La visualizzazione Tabelle senza scritture mostra le tabelle in cui la valutazione della migrazione di BigQuery non è riuscita a trovare aggiornamenti durante il periodo dei log analizzati. Ciò può indicare che i costi di archiviazione dei dati in BigQuery potrebbero essere inferiori.
Visualizzazioni del piano di migrazione
La sezione Piano di migrazione del report contiene le seguenti visualizzazioni:
- Traduzione SQL
- La visualizzazione Traduzione SQL elenca il conteggio e i dettagli delle query che sono state convertite automaticamente dalla valutazione della migrazione BigQuery e non richiedono un intervento manuale. La traduzione SQL automatica in genere raggiunge tassi di traduzione elevati se vengono forniti i metadati. Questa visualizzazione è interattiva e consente di analizzare le query comuni e la loro traduzione.
- SQL Translation Offline Effort
- La visualizzazione Sforzo offline acquisisce le aree che richiedono un intervento manuale, incluse UDF specifiche e potenziali violazioni della struttura lessicale e della sintassi per tabelle o colonne.
- Avvisi SQL - Da rivedere
- La visualizzazione Avvisi da esaminare mostra le aree che sono state tradotte per la maggior parte, ma che richiedono un'ispezione umana.
- Parole chiave riservate di BigQuery
- La visualizzazione BigQuery Reserved Keywords mostra l'utilizzo rilevato
di parole chiave che hanno un significato speciale nel linguaggio GoogleSQL
e non possono essere utilizzate come identificatori a meno che non siano racchiuse tra caratteri
di apice inverso (
`). - Accoppiamento di database e tabelle
- La visualizzazione Accoppiamento database fornisce una panoramica generale dei database e delle tabelle a cui si accede insieme in una singola query. Questa visualizzazione può mostrare quali tabelle e database vengono spesso consultati e quali possono essere utilizzati per la pianificazione della migrazione.
- Pianificazione degli aggiornamenti delle tabelle
- La visualizzazione Pianificazione aggiornamenti tabelle mostra quando e con quale frequenza vengono aggiornate le tabelle per aiutarti a pianificare come e quando spostarle.
Visualizzazioni del proof of concept
La sezione PoC (proof of concept) contiene le seguenti visualizzazioni:
- Prova di concetto per dimostrare i risparmi di BigQuery in stato stazionario
- Include le query più frequenti, le query che leggono più dati, le query più lente e le tabelle interessate da queste query.
- PoC per dimostrare il piano di migrazione a BigQuery
- Mostra come BigQuery traduce le query più complesse e le tabelle che interessano.
Oracle
Per richiedere un feedback o assistenza per questa funzionalità, invia un'email all'indirizzo bq-edw-migration-support@google.com.
Punti salienti della migrazione
La sezione Punti salienti della migrazione contiene le seguenti visualizzazioni:
- Sistema esistente: uno snapshot del sistema Oracle esistente e dell'utilizzo, incluso il numero di database, schemi, tabelle e dimensioni totali in GB. Fornisce anche il riepilogo della classificazione dei workload per ogni database per aiutarti a decidere se BigQuery è la destinazione di migrazione giusta.
- Compatibilità: fornisce informazioni sull'impegno di migrazione stesso. Per ogni database analizzato, mostra il tempo previsto per la migrazione e il numero di oggetti di database che possono essere migrati automaticamente con gli strumenti forniti da Google.
- Stato stazionario di BigQuery: contiene informazioni sull'aspetto dei dati dopo la migrazione su BigQuery, inclusi i costi di archiviazione dei dati in BigQuery in base al tasso di importazione annuale dei dati e alla stima dei costi di calcolo. Inoltre, fornisce informazioni dettagliate su eventuali tabelle sottoutilizzate.
Sistema esistente
La sezione Sistema esistente contiene le seguenti visualizzazioni:
- Caratteristica dei carichi di lavoro: descrive il tipo di carico di lavoro per ogni database in base alle metriche di rendimento analizzate. Ogni database è classificato come OLAP, Misto o OLTP. Queste informazioni possono aiutarti a decidere quali database possono essere migrati a BigQuery.
- Database e schemi: fornisce una suddivisione delle dimensioni totali di archiviazione in GB per ogni database, schema o tabella. Inoltre, puoi utilizzare questa visualizzazione per identificare le viste materializzate e le tabelle esterne.
- Funzionalità e link del database: mostra l'elenco delle funzionalità Oracle utilizzate nel database, insieme alle funzionalità o ai servizi BigQuery equivalenti che possono essere utilizzati dopo la migrazione. Inoltre, puoi esplorare i collegamenti ai database per comprendere meglio le connessioni tra i database.
- Connessioni al database: fornisce informazioni dettagliate sulle sessioni del database avviate dall'utente o dall'applicazione. L'analisi di questi dati può aiutarti a identificare le applicazioni esterne che potrebbero richiedere un impegno aggiuntivo durante la migrazione.
- Tipi di query: fornisce una suddivisione dei tipi di istruzioni SQL eseguite e statistiche sul loro utilizzo. Puoi utilizzare l'istogramma orario di esecuzioni di query o tempo CPU query per identificare i periodi di bassa utilizzazione del sistema e gli orari ottimali della giornata per trasferire i dati.
- Codice sorgente PL/SQL: fornisce informazioni sugli oggetti PL/SQL, come funzioni o procedure, e sulle loro dimensioni per ogni database e schema. Inoltre, l'istogramma delle esecuzioni orarie può essere utilizzato per identificare le ore di punta con il maggior numero di esecuzioni PL/SQL.
- Utilizzo del sistema: fornisce informazioni generali sull'utilizzo storico del sistema. Questa visualizzazione mostra l'utilizzo orario della CPU e il consumo giornaliero di spazio di archiviazione. Questa visualizzazione può aiutarti a comprendere la riserva di capacità del sistema.
Stato stazionario di BigQuery
La sezione BigQuery Steady State contiene le seguenti visualizzazioni:
- Prezzi di Exadata e BigQuery: fornisce il confronto generale dei modelli di prezzi di Exadata e BigQuery per aiutarti a comprendere i vantaggi e i potenziali risparmi sui costi dopo la migrazione a BigQuery.
- Letture/scritture del database BigQuery: fornisce informazioni sulle operazioni del disco fisico del database. L'analisi di questi dati può aiutarti a trovare il momento migliore per eseguire la migrazione dei dati da Oracle a BigQuery.
- Costo di calcolo di BigQuery: consente di stimare il costo del calcolo in BigQuery. Nel calcolatore sono presenti quattro input manuali: edizione BigQuery, regione, periodo di impegno e baseline. Per impostazione predefinita, il calcolatore fornisce un impegno di base ottimale ed economicamente vantaggioso che puoi ignorare manualmente. Il valore Ore di slot con scalabilità automatica annuali indica il numero di ore di slot utilizzate al di fuori dell'impegno. Questo valore viene calcolato utilizzando l'utilizzo del sistema. La spiegazione visiva delle relazioni tra baseline, scalabilità automatica e utilizzo è fornita alla fine della pagina. Ogni stima mostra il numero probabile e un intervallo di stima.
- Costo totale di proprietà (TCO): consente di stimare il valore del contratto annuale (ACV), ovvero il costo di calcolo e archiviazione in BigQuery. Il calcolatore ti consente anche di calcolare il costo dello spazio di archiviazione. Il calcolatore consente anche di calcolare il costo di archiviazione, che varia per l'archiviazione attiva e l'archiviazione a lungo termine, a seconda delle modifiche alla tabella durante il periodo di tempo analizzato. Per maggiori informazioni sui prezzi di archiviazione, consulta Prezzi di archiviazione.
- Tabelle sottoutilizzate: fornisce informazioni sulle tabelle non utilizzate e di sola lettura in base alle metriche di utilizzo del periodo di tempo analizzato. Una mancanza di utilizzo potrebbe indicare che non è necessario trasferire la tabella a BigQuery durante una migrazione o che i costi di archiviazione dei dati in BigQuery potrebbero essere inferiori (fatturati come archiviazione a lungo termine). Ti consigliamo di convalidare l'elenco delle tabelle inutilizzate nel caso in cui vengano utilizzate al di fuori del periodo di tempo analizzato.
Suggerimenti per la migrazione
La sezione Suggerimenti per la migrazione contiene le seguenti visualizzazioni:
- Compatibilità degli oggetti di database: fornisce la panoramica della compatibilità degli oggetti di database con BigQuery, incluso il numero di oggetti che possono essere migrati automaticamente con gli strumenti forniti da Google o che richiedono un intervento manuale. Queste informazioni vengono mostrate per ogni database, schema e tipo di oggetto di database.
- Impegno per la migrazione degli oggetti del database: mostra la stima dell'impegno per la migrazione in ore per ogni database, schema o tipo di oggetto del database. Inoltre, mostra la percentuale di oggetti piccoli, medi e grandi in base all'impegno di migrazione.
- Impegno per la migrazione dello schema del database: fornisce l'elenco di tutti i tipi di oggetti di database rilevati, il loro numero, la compatibilità con BigQuery e l'impegno stimato per la migrazione in ore.
- Database Schema Migration Effort Detailed: fornisce informazioni più approfondite sull'impegno di migrazione dello schema del database, incluse le informazioni per ogni singolo oggetto.
Visualizzazioni del proof of concept
La sezione Viste Proof of Concept contiene le seguenti viste:
- Migrazione proof of concept: mostra l'elenco suggerito di database con il minore sforzo di migrazione, che sono buoni candidati per la migrazione iniziale. Inoltre, mostra le query principali che possono contribuire a dimostrare il risparmio di tempo e costi e il valore di BigQuery utilizzando una prova di concetto.
Appendice
La sezione Appendice contiene le seguenti visualizzazioni:
- Riepilogo dell'esecuzione della valutazione: fornisce i dettagli dell'esecuzione della valutazione, inclusi l'elenco dei file elaborati, gli errori e il completamento del report. Puoi utilizzare questa pagina per esaminare i dati mancanti nel report e comprendere meglio la completezza complessiva del report.
Apache Hive
Il report, costituito da una narrazione in tre parti, è preceduto da una pagina di riepilogo che include le seguenti sezioni:
Sistema esistente: Apache Hive. Questa sezione è costituita da uno snapshot del sistema e dell'utilizzo di Apache Hive esistenti, incluso il numero di database, tabelle, le loro dimensioni totali in GB e il numero di log delle query elaborati. Questa sezione elenca anche i database in base alle dimensioni e indica un potenziale utilizzo e provisioning delle risorse non ottimale (tabelle senza scritture o con poche letture). I dettagli di questa sezione includono quanto segue:
- Calcolo e query
- Utilizzo CPU:
- Query per ora e giorno con utilizzo della CPU
- Query per tipo (lettura/scrittura)
- Code e applicazioni
- Sovrapposizione dell'utilizzo orario della CPU con le prestazioni medie orarie delle query e le prestazioni medie orarie delle applicazioni
- Istogramma delle query per tipo e durata
- Pagina di coda e attesa
- Visualizzazione dettagliata delle code (coda, utente, query uniche, suddivisione dei report rispetto all'ETL, per metriche)
- Utilizzo CPU:
- Panoramica dello spazio di archiviazione
- Database per volume, visualizzazioni e tassi di accesso
- Tabelle con tassi di accesso per utenti, query, scritture e creazioni di tabelle temporanee
- Code e applicazioni: tassi di accesso e indirizzi IP client
- Calcolo e query
BigQuery Steady State. Questa sezione mostra l'aspetto del sistema su BigQuery dopo la migrazione. Include suggerimenti per ottimizzare i workload su BigQuery (ed evitare sprechi). I dettagli di questa sezione includono quanto segue:
- Tabelle identificate come candidate per le viste materializzate.
- Candidati per il clustering e il partizionamento in base a metadati e utilizzo.
- Query a bassa latenza identificate come candidate per BigQuery BI Engine.
- Tabelle senza utilizzo di lettura o scrittura.
- Tabelle partizionate con la distorsione dei dati.
Piano di migrazione. Questa sezione fornisce informazioni sull'impegno di migrazione. Ad esempio, il passaggio dal sistema esistente allo stato stabile di BigQuery. Questa sezione contiene le destinazioni di archiviazione identificate per ogni tabella, le tabelle identificate come significative per la migrazione e il conteggio delle query che sono state tradotte automaticamente. I dettagli di questa sezione includono quanto segue:
- Visualizzazione dettagliata con query tradotte automaticamente
- Conteggio delle query totali con possibilità di filtrare per utente, applicazione, tabelle interessate, tabelle sottoposte a query e tipo di query.
- Bucket di query con pattern simili raggruppati, consentendo agli utenti di visualizzare la filosofia di traduzione in base ai tipi di query.
- Query che richiedono l'intervento umano
- Query con violazioni della struttura lessicale di BigQuery
- Funzioni e procedure definite dall'utente
- Parole chiave riservate di BigQuery
- Query che richiede la revisione
- Tabelle pianificate per scritture e letture (per raggrupparle per lo spostamento)
- Destinazione di archiviazione identificata per tabelle esterne e gestite
- Visualizzazione dettagliata con query tradotte automaticamente
La sezione Sistema esistente - Hive contiene le seguenti visualizzazioni:
- Panoramica del sistema
- Questa visualizzazione fornisce le metriche di volume di alto livello dei componenti chiave nel sistema esistente per un periodo di tempo specificato. La sequenza temporale valutata dipende dai log analizzati dalla valutazione della migrazione di BigQuery. Questa visualizzazione fornisce informazioni rapide sull'utilizzo del data warehouse di origine, che puoi utilizzare per la pianificazione della migrazione.
- Volume della tabella
- Questa visualizzazione fornisce statistiche sulle tabelle e sui database più grandi trovati dalla valutazione della migrazione BigQuery. Poiché le tabelle di grandi dimensioni potrebbero richiedere più tempo per l'estrazione dal sistema di data warehouse di origine, questa visualizzazione può essere utile per la pianificazione e il sequenziamento della migrazione.
- Utilizzo della tabella
- Questa visualizzazione fornisce statistiche sulle tabelle più utilizzate all'interno del sistema di data warehouse di origine. Le tabelle più utilizzate possono aiutarti a capire quali tabelle potrebbero avere molte dipendenze e richiedere una pianificazione aggiuntiva durante il processo di migrazione.
- Utilizzo delle code
- Questa visualizzazione fornisce statistiche sull'utilizzo delle code YARN trovato durante l'elaborazione dei log. Queste visualizzazioni consentono agli utenti di comprendere l'utilizzo di code e applicazioni specifiche nel tempo e l'impatto sull'utilizzo delle risorse. Queste visualizzazioni aiutano anche a identificare e dare la priorità ai carichi di lavoro per la migrazione. Durante una migrazione, è importante visualizzare l'importazione e il consumo dei dati per comprendere meglio le dipendenze del data warehouse e analizzare l'impatto dello spostamento di varie applicazioni dipendenti insieme. La tabella degli indirizzi IP può essere utile per individuare l'applicazione esatta che utilizza il data warehouse tramite connessioni JDBC.
- Metriche delle code
- Questa visualizzazione fornisce una suddivisione delle diverse metriche delle code YARN trovate durante l'elaborazione dei log. Questa visualizzazione consente agli utenti di comprendere i pattern di utilizzo in code specifiche e l'impatto sulla migrazione. Puoi anche utilizzare questa visualizzazione per identificare le connessioni tra le tabelle a cui è stato eseguito l'accesso nelle query e nelle code in cui è stata eseguita la query.
- In coda e in attesa
- Questa visualizzazione fornisce informazioni sul tempo di attesa della query nel data warehouse di origine. I tempi di accodamento indicano un peggioramento delle prestazioni dovuto a un provisioning insufficiente e un provisioning aggiuntivo richiede un aumento dei costi di hardware e manutenzione.
- Query
- Questa visualizzazione fornisce una suddivisione dei tipi di istruzioni SQL eseguite e statistiche sul loro utilizzo. Puoi utilizzare l'istogramma di Tipo di query e Ora per identificare i periodi di bassa utilizzazione del sistema e le ore ottimali della giornata per trasferire i dati. Puoi anche utilizzare questa visualizzazione per identificare i motori di esecuzione Hive più utilizzati e le query eseguite di frequente, insieme ai dettagli utente.
- Database
- Questa visualizzazione fornisce metriche su dimensioni, tabelle, viste e procedure definite nel sistema di data warehouse di origine. Questa visualizzazione può fornire informazioni sul volume di oggetti di cui devi eseguire la migrazione.
- Accoppiamento di database e tabelle
- Questa visualizzazione fornisce una panoramica di alto livello dei database e delle tabelle a cui si accede insieme in una singola query. Questa visualizzazione può mostrare le tabelle e i database a cui viene fatto spesso riferimento e cosa puoi utilizzare per la pianificazione della migrazione.
La sezione BigQuery Steady State contiene le seguenti visualizzazioni:
- Tabelle senza utilizzo
- La visualizzazione Tabelle senza utilizzo mostra le tabelle in cui la valutazione della migrazione BigQuery non ha trovato alcun utilizzo durante il periodo dei log analizzato. La mancanza di utilizzo potrebbe indicare che non è necessario trasferire la tabella a BigQuery durante la migrazione o che i costi di archiviazione dei dati in BigQuery potrebbero essere inferiori. Devi convalidare l'elenco delle tabelle inutilizzate perché potrebbero essere utilizzate al di fuori del periodo dei log, ad esempio una tabella utilizzata solo una volta ogni tre o sei mesi.
- Tabelle senza scritture
- La visualizzazione Tabelle senza scritture mostra le tabelle in cui la valutazione della migrazione di BigQuery non è riuscita a trovare aggiornamenti durante il periodo dei log analizzati. La mancanza di scritture può indicare dove potresti ridurre i costi di archiviazione in BigQuery.
- Suggerimenti per il clustering e il partizionamento
Questa visualizzazione mostra le tabelle che trarrebbero vantaggio dal partizionamento, dal clustering o da entrambi.
I suggerimenti per i metadati vengono ottenuti analizzando lo schema del data warehouse di origine (ad esempio il partizionamento e la chiave primaria nella tabella di origine) e trovando l'equivalente BigQuery più vicino per ottenere caratteristiche di ottimizzazione simili.
I suggerimenti per il workload vengono ottenuti analizzando i log delle query di origine. Il consiglio viene determinato analizzando i workload, in particolare le clausole
WHEREoJOINnei log delle query analizzati.- Partizioni convertite in cluster
Questa visualizzazione mostra le tabelle con più di 10.000 partizioni, in base alla definizione del vincolo di partizionamento. Queste tabelle tendono a essere buone candidate per il clustering BigQuery, che consente partizioni di tabelle granulari.
- Partizioni distorte
La visualizzazione Partizioni distorte mostra le tabelle basate sull'analisi dei metadati e che presentano una distorsione dei dati in una o più partizioni. Queste tabelle sono buoni candidati per la modifica dello schema, poiché le query sulle partizioni distorte potrebbero non funzionare correttamente.
- BI Engine e viste materializzate
La visualizzazione Query a bassa latenza e viste materializzate mostra una distribuzione dei tempi di esecuzione delle query in base ai dati di log analizzati e ulteriori suggerimenti per l'ottimizzazione per migliorare il rendimento su BigQuery. Se il grafico della distribuzione della durata delle query mostra un numero elevato di query con tempo di esecuzione inferiore a 1 secondo, valuta la possibilità di attivare BI Engine per accelerare la BI e altri carichi di lavoro a bassa latenza.
La sezione Piano di migrazione del report contiene le seguenti visualizzazioni:
- Traduzione SQL
- La visualizzazione Traduzione SQL elenca il conteggio e i dettagli delle query che sono state convertite automaticamente dalla valutazione della migrazione BigQuery e non richiedono un intervento manuale. La traduzione SQL automatica in genere raggiunge tassi di traduzione elevati se vengono forniti i metadati. Questa visualizzazione è interattiva e consente di analizzare le query comuni e la loro traduzione.
- SQL Translation Offline Effort
- La visualizzazione Sforzo offline acquisisce le aree che richiedono un intervento manuale, incluse UDF specifiche e potenziali violazioni della struttura lessicale e della sintassi per tabelle o colonne.
- Avvisi SQL
- La visualizzazione Avvisi SQL acquisisce le aree tradotte correttamente, ma che richiedono una revisione.
- Parole chiave riservate di BigQuery
- La visualizzazione BigQuery Reserved Keywords mostra l'utilizzo rilevato
di parole chiave che hanno un significato speciale nel linguaggio GoogleSQL.
Queste parole chiave non possono essere utilizzate come identificatori, a meno che non siano racchiuse tra
caratteri backtick (
`). - Pianificazione degli aggiornamenti delle tabelle
- La visualizzazione Pianificazione aggiornamenti tabelle mostra quando e con quale frequenza vengono aggiornate le tabelle per aiutarti a pianificare come e quando spostarle.
- Tabelle esterne BigLake
- La visualizzazione Tabelle esterne BigLake mostra le tabelle identificate come destinazioni per la migrazione a BigLake anziché a BigQuery.
La sezione Appendice del report contiene le seguenti visualizzazioni:
- Analisi dettagliata dell'impegno di traduzione offline SQL
- La visualizzazione Analisi dettagliata dell'impegno offline fornisce ulteriori informazioni sulle aree SQL che richiedono un intervento manuale.
- Analisi dettagliata degli avvisi SQL
- La visualizzazione Analisi degli avvisi dettagliata fornisce un'ulteriore informazione sulle aree SQL che sono state tradotte correttamente, ma richiedono una revisione.
Condividi il report
Il report di Looker Studio è una dashboard frontend per la valutazione della migrazione. Si basa sulle autorizzazioni di accesso al set di dati sottostante. Per condividere il report, il destinatario deve avere accesso sia al report Looker Studio stesso sia al set di dati BigQuery che contiene i risultati della valutazione.
Quando apri il report dalla console Google Cloud , lo visualizzi in modalità di anteprima. Per creare e condividere il report con altri utenti, segui questi passaggi:
- Fai clic su Modifica e condividi. Looker Studio ti chiede di collegare i connettori Looker Studio appena creati al nuovo report.
- Fai clic su Aggiungi al report. La segnalazione riceve un ID univoco, che puoi utilizzare per accedervi.
- Per condividere il report di Looker Studio con altri utenti, segui i passaggi descritti in Condividere i report con visualizzatori ed editor.
- Concedi agli utenti l'autorizzazione per visualizzare il set di dati BigQuery utilizzato per eseguire l'attività di valutazione. Per saperne di più, vedi Concedere l'accesso a un set di dati.
Esegui una query sulle tabelle di output della valutazione della migrazione
Sebbene i report di Looker Studio siano il modo più comodo per visualizzare i risultati della valutazione, puoi anche visualizzare ed eseguire query sui dati sottostanti nel set di dati BigQuery.
Query di esempio
Il seguente esempio recupera il numero totale di query uniche, il numero di query per cui la traduzione non è riuscita e la percentuale di query uniche per cui la traduzione non è riuscita.
SELECT QueryCount.v AS QueryCount, ErrorCount.v as ErrorCount, (ErrorCount.v * 100) / QueryCount.v AS FailurePercentage FROM ( SELECT COUNT(*) AS v FROM `your_project.your_dataset.TranslationErrors` WHERE Severity = "ERROR" ) AS ErrorCount, ( SELECT COUNT(DISTINCT(QueryHash)) AS v FROM `your_project.your_dataset.Queries` ) AS QueryCount;
Condividere il set di dati con utenti di altri progetti
Dopo aver esaminato il set di dati, se vuoi condividerlo con un utente che non fa parte del tuo progetto, puoi farlo utilizzando il flusso di lavoro del publisher di BigQuery sharing (in precedenza Analytics Hub).
Nella console Google Cloud , vai alla pagina BigQuery.
Fai clic sul set di dati per visualizzarne i dettagli.
Fai clic su Condivisione > Pubblica come scheda.
Nella finestra di dialogo visualizzata, crea una scheda come richiesto.
Se hai già uno scambio di dati, salta il passaggio 5.
Crea uno scambio di dati e imposta le autorizzazioni. Per consentire a un utente di visualizzare le tue schede in questo scambio, aggiungilo all'elenco Iscritti.
Inserisci i dettagli della scheda.
Il nome visualizzato è il nome di questa scheda ed è obbligatorio; gli altri campi sono facoltativi.
Fai clic su Pubblica.
Viene creata una scheda privata.
Per la tua scheda, seleziona Altre azioni in Azioni.
Fai clic su Copia link di condivisione.
Puoi condividere il link con gli utenti che hanno accesso in abbonamento alla tua borsa o al tuo annuncio.
Schemi delle tabelle di valutazione
Per visualizzare le tabelle e i relativi schemi che la valutazione della migrazione BigQuery scrive in BigQuery, seleziona il tuo data warehouse:
Teradata
AllRIChildren
Questa tabella fornisce le informazioni sull'integrità referenziale delle tabelle secondarie.
| Colonna | Tipo | Descrizione |
|---|---|---|
IndexId |
INTEGER |
Il numero di indice del riferimento. |
IndexName |
STRING |
Il nome dell'indice. |
ChildDB |
STRING |
Il nome del database di riferimento, convertito in lettere minuscole. |
ChildDBOriginal |
STRING |
Il nome del database di riferimento con la distinzione tra maiuscole e minuscole mantenuta. |
ChildTable |
STRING |
Il nome della tabella di riferimento, convertito in minuscolo. |
ChildTableOriginal |
STRING |
Il nome della tabella di riferimento con la distinzione tra maiuscole e minuscole mantenuta. |
ChildKeyColumn |
STRING |
Il nome di una colonna nella chiave di riferimento, convertito in lettere minuscole. |
ChildKeyColumnOriginal |
STRING |
Il nome di una colonna nella chiave di riferimento con la distinzione tra maiuscole e minuscole mantenuta. |
ParentDB |
STRING |
Il nome del database a cui viene fatto riferimento, convertito in minuscolo. |
ParentDBOriginal |
STRING |
Il nome del database a cui viene fatto riferimento con la distinzione tra maiuscole e minuscole mantenuta. |
ParentTable |
STRING |
Il nome della tabella a cui viene fatto riferimento, convertito in minuscolo. |
ParentTableOriginal |
STRING |
Il nome della tabella a cui viene fatto riferimento con la distinzione tra maiuscole e minuscole mantenuta. |
ParentKeyColumn |
STRING |
Il nome della colonna in una chiave a cui viene fatto riferimento, convertito in lettere minuscole. |
ParentKeyColumnOriginal |
STRING |
Il nome della colonna in una chiave a cui viene fatto riferimento con la distinzione tra maiuscole e minuscole mantenuta. |
AllRIParents
Questa tabella fornisce le informazioni sull'integrità referenziale delle tabelle padre.
| Colonna | Tipo | Descrizione |
|---|---|---|
IndexId |
INTEGER |
Il numero di indice del riferimento. |
IndexName |
STRING |
Il nome dell'indice. |
ChildDB |
STRING |
Il nome del database di riferimento, convertito in lettere minuscole. |
ChildDBOriginal |
STRING |
Il nome del database di riferimento con la distinzione tra maiuscole e minuscole mantenuta. |
ChildTable |
STRING |
Il nome della tabella di riferimento, convertito in minuscolo. |
ChildTableOriginal |
STRING |
Il nome della tabella di riferimento con la distinzione tra maiuscole e minuscole mantenuta. |
ChildKeyColumn |
STRING |
Il nome di una colonna nella chiave di riferimento, convertito in lettere minuscole. |
ChildKeyColumnOriginal |
STRING |
Il nome di una colonna nella chiave di riferimento con la distinzione tra maiuscole e minuscole mantenuta. |
ParentDB |
STRING |
Il nome del database a cui viene fatto riferimento, convertito in minuscolo. |
ParentDBOriginal |
STRING |
Il nome del database a cui viene fatto riferimento con la distinzione tra maiuscole e minuscole mantenuta. |
ParentTable |
STRING |
Il nome della tabella a cui viene fatto riferimento, convertito in minuscolo. |
ParentTableOriginal |
STRING |
Il nome della tabella a cui viene fatto riferimento con la distinzione tra maiuscole e minuscole mantenuta. |
ParentKeyColumn |
STRING |
Il nome della colonna in una chiave a cui viene fatto riferimento, convertito in lettere minuscole. |
ParentKeyColumnOriginal |
STRING |
Il nome della colonna in una chiave a cui viene fatto riferimento con la distinzione tra maiuscole e minuscole mantenuta. |
Columns
Questa tabella fornisce informazioni sulle colonne.
| Colonna | Tipo | Descrizione |
|---|---|---|
DatabaseName |
STRING |
Il nome del database, convertito in minuscolo. |
DatabaseNameOriginal |
STRING |
Il nome del database con la distinzione tra maiuscole e minuscole mantenuta. |
TableName |
STRING |
Il nome della tabella, convertito in minuscolo. |
TableNameOriginal |
STRING |
Il nome della tabella con la distinzione tra maiuscole e minuscole. |
ColumnName |
STRING |
Il nome della colonna, convertito in minuscolo. |
ColumnNameOriginal |
STRING |
Il nome della colonna con la distinzione tra maiuscole e minuscole. |
ColumnType |
STRING |
Il tipo BigQuery della colonna, ad esempio STRING. |
OriginalColumnType |
STRING |
Il tipo originale della colonna, ad esempio VARCHAR. |
ColumnLength |
INTEGER |
Il numero massimo di byte della colonna, ad esempio 30 per VARCHAR(30). |
DefaultValue |
STRING |
Il valore predefinito, se esistente. |
Nullable |
BOOLEAN |
Indica se la colonna può ammettere valori nulli. |
DiskSpace
Questa tabella fornisce informazioni sull'utilizzo dello spazio su disco per ogni database.
| Colonna | Tipo | Descrizione |
|---|---|---|
DatabaseName |
STRING |
Il nome del database, convertito in minuscolo. |
DatabaseNameOriginal |
STRING |
Il nome del database con la distinzione tra maiuscole e minuscole mantenuta. |
MaxPerm |
INTEGER |
Il numero massimo di byte allocati allo spazio permanente. |
MaxSpool |
INTEGER |
Il numero massimo di byte allocati allo spazio di spooling. |
MaxTemp |
INTEGER |
Il numero massimo di byte allocati allo spazio temporaneo. |
CurrentPerm |
INTEGER |
Il numero di byte allocati allo spazio permanente. |
CurrentSpool |
INTEGER |
Il numero di byte allocati allo spazio di spool. |
CurrentTemp |
INTEGER |
Il numero di byte allocati allo spazio temporaneo. |
PeakPerm |
INTEGER |
Numero massimo di byte utilizzati dall'ultimo ripristino per lo spazio permanente. |
PeakSpool |
INTEGER |
Numero massimo di byte utilizzati dall'ultimo ripristino per lo spazio di spool. |
PeakPersistentSpool |
INTEGER |
Numero massimo di byte utilizzati dall'ultimo ripristino per lo spazio persistente. |
PeakTemp |
INTEGER |
Numero massimo di byte utilizzati dall'ultimo ripristino per lo spazio temporaneo. |
MaxProfileSpool |
INTEGER |
Il limite per lo spazio di spooling per l'utente. |
MaxProfileTemp |
INTEGER |
Il limite per lo spazio temporaneo per l'utente. |
AllocatedPerm |
INTEGER |
Assegnazione attuale dello spazio permanente. |
AllocatedSpool |
INTEGER |
Allocazione attuale dello spazio spool. |
AllocatedTemp |
INTEGER |
Allocazione attuale dello spazio temporaneo. |
Functions
Questa tabella fornisce informazioni sulle funzioni.
| Colonna | Tipo | Descrizione |
|---|---|---|
DatabaseName |
STRING |
Il nome del database, convertito in minuscolo. |
DatabaseNameOriginal |
STRING |
Il nome del database con la distinzione tra maiuscole e minuscole mantenuta. |
FunctionName |
STRING |
Il nome della funzione. |
LanguageName |
STRING |
Il nome della lingua. |
Indices
Questa tabella fornisce informazioni sugli indici.
| Colonna | Tipo | Descrizione |
|---|---|---|
DatabaseName |
STRING |
Il nome del database, convertito in minuscolo. |
DatabaseNameOriginal |
STRING |
Il nome del database con la distinzione tra maiuscole e minuscole mantenuta. |
TableName |
STRING |
Il nome della tabella, convertito in minuscolo. |
TableNameOriginal |
STRING |
Il nome della tabella con la distinzione tra maiuscole e minuscole. |
IndexName |
STRING |
Il nome dell'indice. |
ColumnName |
STRING |
Il nome della colonna, convertito in minuscolo. |
ColumnNameOriginal |
STRING |
Il nome della colonna con la distinzione tra maiuscole e minuscole. |
OrdinalPosition |
INTEGER |
La posizione della colonna. |
UniqueFlag |
BOOLEAN |
Indica se l'indice impone l'unicità. |
Queries
Questa tabella fornisce informazioni sulle query estratte.
| Colonna | Tipo | Descrizione |
|---|---|---|
QueryHash |
STRING |
L'hash della query. |
QueryText |
STRING |
Il testo della query. |
QueryLogs
Questa tabella fornisce alcune statistiche di esecuzione sulle query estratte.
| Colonna | Tipo | Descrizione |
|---|---|---|
QueryText |
STRING |
Il testo della query. |
QueryHash |
STRING |
L'hash della query. |
QueryId |
STRING |
L'ID della query. |
QueryType |
STRING |
Il tipo di query, Query o DDL. |
UserId |
BYTES |
L'ID dell'utente che ha eseguito la query. |
UserName |
STRING |
Il nome dell'utente che ha eseguito la query. |
StartTime |
TIMESTAMP |
Timestamp di invio della query. |
Duration |
STRING |
Durata della query in millisecondi. |
AppId |
STRING |
L'ID dell'applicazione che ha eseguito la query. |
ProxyUser |
STRING |
L'utente proxy se utilizzato tramite un livello intermedio. |
ProxyRole |
STRING |
Il ruolo proxy quando viene utilizzato tramite un livello intermedio. |
QueryTypeStatistics
Questa tabella fornisce statistiche sui tipi di query.
| Colonna | Tipo | Descrizione |
|---|---|---|
QueryHash |
STRING |
L'hash della query. |
QueryType |
STRING |
Il tipo di query. |
UpdatedTable |
STRING |
La tabella aggiornata dalla query, se presente. |
QueriedTables |
ARRAY<STRING> |
Un elenco delle tabelle su cui è stata eseguita la query. |
ResUsageScpu
Questa tabella fornisce informazioni sull'utilizzo delle risorse CPU.
| Colonna | Tipo | Descrizione |
|---|---|---|
EventTime |
TIMESTAMP |
L'ora dell'evento. |
NodeId |
INTEGER |
ID nodo |
CabinetId |
INTEGER |
Il numero dell'armadio fisico del nodo. |
ModuleId |
INTEGER |
Il numero del modulo fisico del nodo. |
NodeType |
STRING |
Tipo di nodo. |
CpuId |
INTEGER |
ID della CPU all'interno di questo nodo. |
MeasurementPeriod |
INTEGER |
Il periodo di misurazione espresso in centisecondi. |
SummaryFlag |
STRING |
S - riga di riepilogo, N - riga non di riepilogo |
CpuFrequency |
FLOAT |
Frequenza della CPU in MHz. |
CpuIdle |
FLOAT |
Il tempo di inattività della CPU espresso in centisecondi. |
CpuIoWait |
FLOAT |
Il tempo in cui la CPU è in attesa di I/O espresso in centisecondi. |
CpuUServ |
FLOAT |
Il tempo in cui la CPU esegue il codice utente espresso in centisecondi. |
CpuUExec |
FLOAT |
Il tempo in cui la CPU esegue il codice del servizio espresso in centisecondi. |
Roles
Questa tabella fornisce informazioni sui ruoli.
| Colonna | Tipo | Descrizione |
|---|---|---|
RoleName |
STRING |
Il nome del ruolo. |
Grantor |
STRING |
Il nome del database che ha concesso il ruolo. |
Grantee |
STRING |
L'utente a cui viene concesso il ruolo. |
WhenGranted |
TIMESTAMP |
Quando è stato concesso il ruolo. |
WithAdmin |
BOOLEAN |
L'opzione Amministratore è impostata per il ruolo concesso. |
SchemaConversion
Questa tabella fornisce informazioni sulle conversioni dello schema correlate al clustering e al partizionamento.
| Nome colonna | Tipo di colonna | Descrizione |
|---|---|---|
DatabaseName |
STRING |
Il nome del database di origine per cui viene fornito il suggerimento. Un database viene mappato a un set di dati in BigQuery. |
TableName |
STRING |
Il nome della tabella per cui viene fornito il suggerimento. |
PartitioningColumnName |
STRING |
Il nome della colonna di partizionamento suggerita in BigQuery. |
ClusteringColumnNames |
ARRAY |
I nomi delle colonne di clustering suggerite in BigQuery. |
CreateTableDDL |
STRING |
CREATE TABLE statement
per creare la tabella in BigQuery. |
TableInfo
Questa tabella fornisce informazioni sulle tabelle.
| Colonna | Tipo | Descrizione |
|---|---|---|
DatabaseName |
STRING |
Il nome del database, convertito in minuscolo. |
DatabaseNameOriginal |
STRING |
Il nome del database con la distinzione tra maiuscole e minuscole mantenuta. |
TableName |
STRING |
Il nome della tabella, convertito in minuscolo. |
TableNameOriginal |
STRING |
Il nome della tabella con la distinzione tra maiuscole e minuscole. |
LastAccessTimestamp |
TIMESTAMP |
L'ultima volta che è stata eseguita l'accesso alla tabella. |
LastAlterTimestamp |
TIMESTAMP |
L'ultima volta che la tabella è stata modificata. |
TableKind |
STRING |
Il tipo di tabella. |
TableRelations
Questa tabella fornisce informazioni sulle tabelle.
| Colonna | Tipo | Descrizione |
|---|---|---|
QueryHash |
STRING |
L'hash della query che ha stabilito la relazione. |
DatabaseName1 |
STRING |
Il nome del primo database. |
TableName1 |
STRING |
Il nome della prima tabella. |
DatabaseName2 |
STRING |
Il nome del secondo database. |
TableName2 |
STRING |
Il nome della seconda tabella. |
Relation |
STRING |
Il tipo di relazione tra le due tabelle. |
TableSizes
Questa tabella fornisce informazioni sulle dimensioni delle tabelle.
| Colonna | Tipo | Descrizione |
|---|---|---|
DatabaseName |
STRING |
Il nome del database, convertito in minuscolo. |
DatabaseNameOriginal |
STRING |
Il nome del database con la distinzione tra maiuscole e minuscole mantenuta. |
TableName |
STRING |
Il nome della tabella, convertito in minuscolo. |
TableNameOriginal |
STRING |
Il nome della tabella con la distinzione tra maiuscole e minuscole. |
TableSizeInBytes |
INTEGER |
Le dimensioni della tabella in byte. |
Users
Questa tabella fornisce informazioni sugli utenti.
| Colonna | Tipo | Descrizione |
|---|---|---|
UserName |
STRING |
Il nome dell'utente. |
CreatorName |
STRING |
Il nome dell'entità che ha creato questo utente. |
CreateTimestamp |
TIMESTAMP |
Il timestamp della creazione di questo utente. |
LastAccessTimestamp |
TIMESTAMP |
Il timestamp dell'ultimo accesso di questo utente a un database. |
Redshift
Columns
La tabella Columns deriva da una delle seguenti tabelle:
SVV_COLUMNS,
INFORMATION_SCHEMA.COLUMNS
o
PG_TABLE_DEF,
ordinate per priorità. Lo strumento tenta di caricare i dati dalla tabella con la priorità più alta. Se l'operazione non va a buon fine, tenta di caricare i dati dalla
tabella con la priorità più alta successiva. Per ulteriori dettagli sullo schema e sull'utilizzo, consulta la documentazione di Amazon Redshift o PostgreSQL.
| Colonna | Tipo | Descrizione |
|---|---|---|
DatabaseName |
STRING |
Il nome del database. |
SchemaName |
STRING |
Il nome dello schema. |
TableName |
STRING |
Il nome della tabella. |
ColumnName |
STRING |
Il nome della colonna. |
DefaultValue |
STRING |
Il valore predefinito, se disponibile. |
Nullable |
BOOLEAN |
Indica se una colonna può avere un valore nullo. |
ColumnType |
STRING |
Il tipo di colonna, ad esempio VARCHAR. |
ColumnLength |
INTEGER |
La dimensione della colonna, ad esempio 30 per un
VARCHAR(30). |
CreateAndDropStatistic
Questa tabella fornisce informazioni sulla creazione e sull'eliminazione delle tabelle.
| Colonna | Tipo | Descrizione |
|---|---|---|
QueryHash |
STRING |
L'hash della query. |
DefaultDatabase |
STRING |
Il database predefinito. |
EntityType |
STRING |
Il tipo di entità, ad esempio TABLE. |
EntityName |
STRING |
Il nome dell'entità. |
Operation |
STRING |
L'operazione: CREATE o DROP. |
Databases
Questa tabella proviene direttamente dalla tabella PG_DATABASE_INFO di Amazon Redshift. I nomi dei campi originali della tabella PG sono inclusi nelle descrizioni. Per ulteriori dettagli su schema e utilizzo, consulta la documentazione di Amazon Redshift e PostgreSQL.
| Colonna | Tipo | Descrizione |
|---|---|---|
DatabaseName |
STRING |
Il nome del database. Nome origine: datname |
Owner |
STRING |
Il proprietario del database. Ad esempio, l'utente che ha creato il database. Nome origine: datdba |
ExternalColumns
Questa tabella contiene informazioni della tabella SVV_EXTERNAL_COLUMNS di Amazon Redshift. Per maggiori dettagli sullo schema e sull'utilizzo, consulta la documentazione di Amazon Redshift.
| Colonna | Tipo | Descrizione |
|---|---|---|
SchemaName |
STRING |
Il nome dello schema esterno. |
TableName |
STRING |
Il nome della tabella esterna. |
ColumnName |
STRING |
Il nome della colonna esterna. |
ColumnType |
STRING |
Il tipo di colonna. |
Nullable |
BOOLEAN |
Indica se una colonna può avere un valore nullo. |
ExternalDatabases
Questa tabella contiene informazioni della tabella SVV_EXTERNAL_DATABASES di Amazon Redshift direttamente. Per maggiori dettagli sullo schema e sull'utilizzo, consulta la documentazione di Amazon Redshift.
| Colonna | Tipo | Descrizione |
|---|---|---|
DatabaseName |
STRING |
Il nome del database esterno. |
Location |
STRING |
La posizione del database. |
ExternalPartitions
Questa tabella contiene informazioni della tabella SVV_EXTERNAL_PARTITIONS di Amazon Redshift direttamente. Per maggiori dettagli sullo schema e sull'utilizzo, consulta la documentazione di Amazon Redshift.
| Colonna | Tipo | Descrizione |
|---|---|---|
SchemaName |
STRING |
Il nome dello schema esterno. |
TableName |
STRING |
Il nome della tabella esterna. |
Location |
STRING |
La posizione della partizione. La dimensione della colonna è limitata a 128 caratteri. I valori più lunghi vengono troncati. |
ExternalSchemas
Questa tabella contiene informazioni della tabella SVV_EXTERNAL_SCHEMAS di Amazon Redshift. Per maggiori dettagli sullo schema e sull'utilizzo, consulta la documentazione di Amazon Redshift.
| Colonna | Tipo | Descrizione |
|---|---|---|
SchemaName |
STRING |
Il nome dello schema esterno. |
DatabaseName |
STRING |
Il nome del database esterno. |
ExternalTables
Questa tabella contiene informazioni della tabella SVV_EXTERNAL_TABLES di Amazon Redshift. Per maggiori dettagli sullo schema e sull'utilizzo, consulta la documentazione di Amazon Redshift.
| Colonna | Tipo | Descrizione |
|---|---|---|
SchemaName |
STRING |
Il nome dello schema esterno. |
TableName |
STRING |
Il nome della tabella esterna. |
Functions
Questa tabella contiene informazioni provenienti direttamente dalla tabella PG_PROC di Amazon Redshift. Per ulteriori dettagli su schema e utilizzo, consulta la documentazione di Amazon Redshift e PostgreSQL.
| Colonna | Tipo | Descrizione |
|---|---|---|
SchemaName |
STRING |
Il nome dello schema. |
FunctionName |
STRING |
Il nome della funzione. |
LanguageName |
STRING |
Il linguaggio di implementazione o l'interfaccia di chiamata di questa funzione. |
Queries
Questa tabella viene generata utilizzando le informazioni della tabella QueryLogs. A differenza della tabella QueryLogs, ogni riga della tabella Query contiene una sola istruzione di query memorizzata nella colonna QueryText. Questa tabella fornisce i dati di origine
per generare le tabelle delle statistiche e gli output di traduzione.
| Colonna | Tipo | Descrizione |
|---|---|---|
QueryText |
STRING |
Il testo della query. |
QueryHash |
STRING |
L'hash della query. |
QueryLogs
Questa tabella fornisce informazioni sull'esecuzione delle query.
| Colonna | Tipo | Descrizione |
|---|---|---|
QueryText |
STRING |
Il testo della query. |
QueryHash |
STRING |
L'hash della query. |
QueryID |
STRING |
L'ID della query. |
UserID |
STRING |
L'ID dell'utente. |
StartTime |
TIMESTAMP |
L'ora di inizio. |
Duration |
INTEGER |
Durata in millisecondi. |
QueryTypeStatistics
| Colonna | Tipo | Descrizione |
|---|---|---|
QueryHash |
STRING |
L'hash della query. |
DefaultDatabase |
STRING |
Il database predefinito. |
QueryType |
STRING |
Il tipo di query. |
UpdatedTable |
STRING |
La tabella aggiornata. |
QueriedTables |
ARRAY<STRING> |
Le tabelle su cui è stata eseguita la query. |
TableInfo
Questa tabella contiene informazioni estratte dalla tabella SVV_TABLE_INFO in Amazon Redshift.
| Colonna | Tipo | Descrizione |
|---|---|---|
DatabaseName |
STRING |
Il nome del database. |
SchemaName |
STRING |
Il nome dello schema. |
TableId |
INTEGER |
L'ID tabella. |
TableName |
STRING |
Il nome della tabella. |
SortKey1 |
STRING |
La prima colonna nella chiave di ordinamento. |
SortKeyNum |
INTEGER |
Numero di colonne definite come chiavi di ordinamento. |
MaxVarchar |
INTEGER |
Dimensioni della colonna più grande che utilizza un tipo di dati VARCHAR. |
Size |
INTEGER |
Dimensione della tabella, in blocchi di dati da 1 MB. |
TblRows |
INTEGER |
Numero totale di righe nella tabella. |
TableRelations
| Colonna | Tipo | Descrizione |
|---|---|---|
QueryHash |
STRING |
L'hash della query che ha stabilito la relazione (ad esempio una query JOIN). |
DefaultDatabase |
STRING |
Il database predefinito. |
TableName1 |
STRING |
La prima tabella della relazione. |
TableName2 |
STRING |
La seconda tabella della relazione. |
Relation |
STRING |
Il tipo di relazione. Assume uno dei seguenti valori:
COMMA_JOIN, CROSS_JOIN,
FULL_OUTER_JOIN, INNER_JOIN,
LEFT_OUTER_JOIN,
RIGHT_OUTER_JOIN, CREATED_FROM o
INSERT_INTO. |
Count |
INTEGER |
La frequenza con cui è stata osservata questa relazione. |
TableSizes
Questa tabella fornisce informazioni sulle dimensioni delle tabelle.
| Colonna | Tipo | Descrizione |
|---|---|---|
DatabaseName |
STRING |
Il nome del database. |
SchemaName |
STRING |
Il nome dello schema. |
TableName |
STRING |
Il nome della tabella. |
TableSizeInBytes |
INTEGER |
Le dimensioni della tabella in byte. |
Tables
Questa tabella contiene informazioni estratte dalla tabella SVV_TABLES in Amazon Redshift. Per ulteriori dettagli sullo schema e sull'utilizzo, consulta la documentazione di Amazon Redshift.
| Colonna | Tipo | Descrizione |
|---|---|---|
DatabaseName |
STRING |
Il nome del database. |
SchemaName |
STRING |
Il nome dello schema. |
TableName |
STRING |
Il nome della tabella. |
TableType |
STRING |
Il tipo di tabella. |
TranslatedQueries
Questa tabella fornisce le traduzioni delle query.
| Colonna | Tipo | Descrizione |
|---|---|---|
QueryHash |
STRING |
L'hash della query. |
TranslatedQueryText |
STRING |
Risultato della traduzione dal dialetto di origine a GoogleSQL. |
TranslationErrors
Questa tabella fornisce informazioni sugli errori di traduzione delle query.
| Colonna | Tipo | Descrizione |
|---|---|---|
QueryHash |
STRING |
L'hash della query. |
Severity |
STRING |
La gravità dell'errore, ad esempio ERROR. |
Category |
STRING |
La categoria dell'errore, ad esempio
AttributeNotFound. |
Message |
STRING |
Il messaggio con i dettagli dell'errore. |
LocationOffset |
INTEGER |
La posizione del carattere in cui si è verificato l'errore. |
LocationLine |
INTEGER |
Il numero di riga dell'errore. |
LocationColumn |
INTEGER |
Il numero di colonna dell'errore. |
LocationLength |
INTEGER |
La lunghezza in caratteri della posizione dell'errore. |
UserTableRelations
| Colonna | Tipo | Descrizione |
|---|---|---|
UserID |
STRING |
L'ID utente. |
TableName |
STRING |
Il nome della tabella. |
Relation |
STRING |
La relazione. |
Count |
INTEGER |
Il conteggio. |
Users
Questa tabella contiene informazioni estratte dalla tabella PG_USER in Amazon Redshift. Per ulteriori dettagli sullo schema e sull'utilizzo, consulta la documentazione di PostgreSQL.
| Colonna | Tipo | Descrizione | |
|---|---|---|---|
UserName |
STRING |
Il nome dell'utente. | |
UserId |
STRING |
L'ID utente. |
Snowflake
Warehouses
| Colonna | Tipo | Descrizione | Presenza |
|---|---|---|---|
WarehouseName |
STRING |
Il nome del magazzino. | Sempre |
State |
STRING |
Lo stato del magazzino. Valori possibili: STARTED, SUSPENDED, RESIZING. |
Sempre |
Type |
STRING |
Tipo di magazzino. Valori possibili: STANDARD, SNOWPARK-OPTIMIZED. |
Sempre |
Size |
STRING |
Dimensioni del magazzino. Valori possibili: X-Small, Small, Medium, Large, X-Large, 2X-Large ... 6X-Large. |
Sempre |
Databases
| Colonna | Tipo | Descrizione | Presenza |
|---|---|---|---|
DatabaseNameOriginal |
STRING |
Il nome del database, con la distinzione tra maiuscole e minuscole. | Sempre |
DatabaseName |
STRING |
Il nome del database, convertito in minuscolo. | Sempre |
Schemata
| Colonna | Tipo | Descrizione | Presenza |
|---|---|---|---|
DatabaseNameOriginal |
STRING |
Il nome del database a cui appartiene lo schema, con la distinzione tra maiuscole e minuscole mantenuta. | Sempre |
DatabaseName |
STRING |
Il nome del database a cui appartiene lo schema, convertito in minuscolo. | Sempre |
SchemaNameOriginal |
STRING |
Il nome dello schema, con la distinzione tra maiuscole e minuscole. | Sempre |
SchemaName |
STRING |
Il nome dello schema, convertito in minuscolo. | Sempre |
Tables
| Colonna | Tipo | Descrizione | Presenza |
|---|---|---|---|
DatabaseNameOriginal |
STRING |
Il nome del database a cui appartiene la tabella, con la distinzione tra maiuscole e minuscole mantenuta. | Sempre |
DatabaseName |
STRING |
Il nome del database a cui appartiene la tabella, convertito in minuscolo. | Sempre |
SchemaNameOriginal |
STRING |
Il nome dello schema a cui appartiene la tabella, con la distinzione tra maiuscole e minuscole mantenuta. | Sempre |
SchemaName |
STRING |
Il nome dello schema a cui appartiene la tabella, convertito in minuscolo. | Sempre |
TableNameOriginal |
STRING |
Il nome della tabella, con la distinzione tra maiuscole e minuscole. | Sempre |
TableName |
STRING |
Il nome della tabella, convertito in minuscolo. | Sempre |
TableType |
STRING |
Tipo di tabella (vista / vista materializzata / tabella di base). | Sempre |
RowCount |
BIGNUMERIC |
Numero di righe nella tabella. | Sempre |
Columns
| Colonna | Tipo | Descrizione | Presenza |
|---|---|---|---|
DatabaseName |
STRING |
Il nome del database, convertito in minuscolo. | Sempre |
DatabaseNameOriginal |
STRING |
Il nome del database, con la distinzione tra maiuscole e minuscole. | Sempre |
SchemaName |
STRING |
Il nome dello schema, convertito in minuscolo. | Sempre |
SchemaNameOriginal |
STRING |
Il nome dello schema, con la distinzione tra maiuscole e minuscole. | Sempre |
TableName |
STRING |
Il nome della tabella, convertito in minuscolo. | Sempre |
TableNameOriginal |
STRING |
Il nome della tabella con la distinzione tra maiuscole e minuscole. | Sempre |
ColumnName |
STRING |
Il nome della colonna, convertito in minuscolo. | Sempre |
ColumnNameOriginal |
STRING |
Il nome della colonna con la distinzione tra maiuscole e minuscole. | Sempre |
ColumnType |
STRING |
Il tipo di colonna. | Sempre |
CreateAndDropStatistics
| Colonna | Tipo | Descrizione | Presenza |
|---|---|---|---|
QueryHash |
STRING |
L'hash della query. | Sempre |
DefaultDatabase |
STRING |
Il database predefinito. | Sempre |
EntityType |
STRING |
Il tipo di entità, ad esempio TABLE. |
Sempre |
EntityName |
STRING |
Il nome dell'entità. | Sempre |
Operation |
STRING |
L'operazione: CREATE o DROP. |
Sempre |
Queries
| Colonna | Tipo | Descrizione | Presenza |
|---|---|---|---|
QueryText |
STRING |
Il testo della query. | Sempre |
QueryHash |
STRING |
L'hash della query. | Sempre |
QueryLogs
| Colonna | Tipo | Descrizione | Presenza |
|---|---|---|---|
QueryText |
STRING |
Il testo della query. | Sempre |
QueryHash |
STRING |
L'hash della query. | Sempre |
QueryID |
STRING |
L'ID della query. | Sempre |
UserID |
STRING |
L'ID dell'utente. | Sempre |
StartTime |
TIMESTAMP |
L'ora di inizio. | Sempre |
Duration |
INTEGER |
Durata in millisecondi. | Sempre |
QueryTypeStatistics
| Colonna | Tipo | Descrizione | Presenza |
|---|---|---|---|
QueryHash |
STRING |
L'hash della query. | Sempre |
DefaultDatabase |
STRING |
Il database predefinito. | Sempre |
QueryType |
STRING |
Il tipo di query. | Sempre |
UpdatedTable |
STRING |
La tabella aggiornata. | Sempre |
QueriedTables |
REPEATED STRING |
Le tabelle su cui è stata eseguita la query. | Sempre |
TableRelations
| Colonna | Tipo | Descrizione | Presenza |
|---|---|---|---|
QueryHash |
STRING |
L'hash della query che ha stabilito la relazione (ad esempio una query JOIN). |
Sempre |
DefaultDatabase |
STRING |
Il database predefinito. | Sempre |
TableName1 |
STRING |
La prima tabella della relazione. | Sempre |
TableName2 |
STRING |
La seconda tabella della relazione. | Sempre |
Relation |
STRING |
Il tipo di relazione. | Sempre |
Count |
INTEGER |
La frequenza con cui è stata osservata questa relazione. | Sempre |
TranslatedQueries
| Colonna | Tipo | Descrizione | Presenza |
|---|---|---|---|
QueryHash |
STRING |
L'hash della query. | Sempre |
TranslatedQueryText |
STRING |
Risultato della traduzione dal dialetto di origine a BigQuery SQL. | Sempre |
TranslationErrors
| Colonna | Tipo | Descrizione | Presenza |
|---|---|---|---|
QueryHash |
STRING |
L'hash della query. | Sempre |
Severity |
STRING |
La gravità dell'errore, ad esempio ERROR. |
Sempre |
Category |
STRING |
La categoria dell'errore, ad esempio AttributeNotFound. |
Sempre |
Message |
STRING |
Il messaggio con i dettagli dell'errore. | Sempre |
LocationOffset |
INTEGER |
La posizione del carattere in cui si è verificato l'errore. | Sempre |
LocationLine |
INTEGER |
Il numero di riga dell'errore. | Sempre |
LocationColumn |
INTEGER |
Il numero di colonna dell'errore. | Sempre |
LocationLength |
INTEGER |
La lunghezza in caratteri della posizione dell'errore. | Sempre |
UserTableRelations
| Colonna | Tipo | Descrizione | Presenza |
|---|---|---|---|
UserID |
STRING |
ID utente. | Sempre |
TableName |
STRING |
Il nome della tabella. | Sempre |
Relation |
STRING |
La relazione. | Sempre |
Count |
INTEGER |
Il conteggio. | Sempre |
Apache Hive
Columns
Questa tabella fornisce informazioni sulle colonne:
| Colonna | Tipo | Descrizione |
|---|---|---|
DatabaseName |
STRING |
Il nome del database con la distinzione tra maiuscole e minuscole mantenuta. |
TableName |
STRING |
Il nome della tabella con la distinzione tra maiuscole e minuscole. |
ColumnName |
STRING |
Il nome della colonna con la distinzione tra maiuscole e minuscole. |
ColumnType |
STRING |
Il tipo BigQuery della colonna, ad esempio STRING. |
OriginalColumnType |
STRING |
Il tipo originale della colonna, ad esempio VARCHAR. |
CreateAndDropStatistic
Questa tabella fornisce informazioni sulla creazione e l'eliminazione delle tabelle:
| Colonna | Tipo | Descrizione |
|---|---|---|
QueryHash |
STRING |
L'hash della query. |
DefaultDatabase |
STRING |
Il database predefinito. |
EntityType |
STRING |
Il tipo di entità, ad esempio TABLE. |
EntityName |
STRING |
Il nome dell'entità. |
Operation |
STRING |
L'operazione eseguita sulla tabella (CREATE o DROP). |
Databases
Questa tabella fornisce informazioni sui database:
| Colonna | Tipo | Descrizione |
|---|---|---|
DatabaseName |
STRING |
Il nome del database con la distinzione tra maiuscole e minuscole mantenuta. |
Owner |
STRING |
Il proprietario del database. Ad esempio, l'utente che ha creato il database. |
Location |
STRING |
Posizione del database nel file system. |
Functions
Questa tabella fornisce informazioni sulle funzioni:
| Colonna | Tipo | Descrizione |
|---|---|---|
DatabaseName |
STRING |
Il nome del database con la distinzione tra maiuscole e minuscole mantenuta. |
FunctionName |
STRING |
Il nome della funzione. |
LanguageName |
STRING |
Il nome della lingua. |
ClassName |
STRING |
Il nome della classe della funzione. |
ObjectReferences
Questa tabella fornisce informazioni sugli oggetti a cui viene fatto riferimento nelle query:
| Colonna | Tipo | Descrizione |
|---|---|---|
QueryHash |
STRING |
L'hash della query. |
DefaultDatabase |
STRING |
Il database predefinito. |
Clause |
STRING |
La clausola in cui appare l'oggetto. Ad esempio, SELECT. |
ObjectName |
STRING |
Il nome dell'oggetto. |
Type |
STRING |
Il tipo di oggetto. |
Subtype |
STRING |
Il sottotipo dell'oggetto. |
ParititionKeys
Questa tabella fornisce informazioni sulle chiavi di partizione:
| Colonna | Tipo | Descrizione |
|---|---|---|
DatabaseName |
STRING |
Il nome del database con la distinzione tra maiuscole e minuscole mantenuta. |
TableName |
STRING |
Il nome della tabella con la distinzione tra maiuscole e minuscole. |
ColumnName |
STRING |
Il nome della colonna con la distinzione tra maiuscole e minuscole. |
ColumnType |
STRING |
Il tipo BigQuery della colonna, ad esempio STRING. |
Parititions
Questa tabella fornisce informazioni sulle partizioni delle tabelle:
| Colonna | Tipo | Descrizione |
|---|---|---|
DatabaseName |
STRING |
Il nome del database con la distinzione tra maiuscole e minuscole mantenuta. |
TableName |
STRING |
Il nome della tabella con la distinzione tra maiuscole e minuscole. |
PartitionName |
STRING |
Il nome della partizione. |
CreateTimestamp |
TIMESTAMP |
Il timestamp della creazione di questa partizione. |
LastAccessTimestamp |
TIMESTAMP |
Il timestamp dell'ultimo accesso a questa partizione. |
LastDdlTimestamp |
TIMESTAMP |
Il timestamp dell'ultima modifica di questa partizione. |
TotalSize |
INTEGER |
Le dimensioni compresse della partizione in byte. |
Queries
Questa tabella viene generata utilizzando le informazioni della tabella QueryLogs. A differenza della tabella QueryLogs, ogni riga della tabella Query contiene una sola istruzione di query memorizzata nella colonna QueryText. Questa tabella fornisce i dati di origine per generare le tabelle delle statistiche e gli output di traduzione:
| Colonna | Tipo | Descrizione |
|---|---|---|
QueryHash |
STRING |
L'hash della query. |
QueryText |
STRING |
Il testo della query. |
QueryLogs
Questa tabella fornisce alcune statistiche di esecuzione sulle query estratte:
| Colonna | Tipo | Descrizione |
|---|---|---|
QueryText |
STRING |
Il testo della query. |
QueryHash |
STRING |
L'hash della query. |
QueryId |
STRING |
L'ID della query. |
QueryType |
STRING |
Il tipo di query, Query o DDL. |
UserName |
STRING |
Il nome dell'utente che ha eseguito la query. |
StartTime |
TIMESTAMP |
Il timestamp di invio della query. |
Duration |
STRING |
La durata della query in millisecondi. |
QueryTypeStatistics
Questa tabella fornisce statistiche sui tipi di query:
| Colonna | Tipo | Descrizione |
|---|---|---|
QueryHash |
STRING |
L'hash della query. |
QueryType |
STRING |
Il tipo di query. |
UpdatedTable |
STRING |
La tabella aggiornata dalla query, se presente. |
QueriedTables |
ARRAY<STRING> |
Un elenco delle tabelle su cui è stata eseguita la query. |
QueryTypes
Questa tabella fornisce statistiche sui tipi di query:
| Colonna | Tipo | Descrizione |
|---|---|---|
QueryHash |
STRING |
L'hash della query. |
Category |
STRING |
La categoria della query. |
Type |
STRING |
Il tipo di query. |
Subtype |
STRING |
Il sottotipo della query. |
SchemaConversion
Questa tabella fornisce informazioni sulle conversioni dello schema correlate a clustering e partizionamento:
| Nome colonna | Tipo di colonna | Descrizione |
|---|---|---|
DatabaseName |
STRING |
Il nome del database di origine per cui viene fornito il suggerimento. Un database viene mappato a un set di dati in BigQuery. |
TableName |
STRING |
Il nome della tabella per cui viene fornito il suggerimento. |
PartitioningColumnName |
STRING |
Il nome della colonna di partizionamento suggerita in BigQuery. |
ClusteringColumnNames |
ARRAY |
I nomi delle colonne di clustering suggerite in BigQuery. |
CreateTableDDL |
STRING |
CREATE TABLE statement
per creare la tabella in BigQuery. |
TableRelations
Questa tabella fornisce informazioni sulle tabelle:
| Colonna | Tipo | Descrizione |
|---|---|---|
QueryHash |
STRING |
L'hash della query che ha stabilito la relazione. |
DatabaseName1 |
STRING |
Il nome del primo database. |
TableName1 |
STRING |
Il nome della prima tabella. |
DatabaseName2 |
STRING |
Il nome del secondo database. |
TableName2 |
STRING |
Il nome della seconda tabella. |
Relation |
STRING |
Il tipo di relazione tra le due tabelle. |
TableSizes
Questa tabella fornisce informazioni sulle dimensioni delle tabelle:
| Colonna | Tipo | Descrizione |
|---|---|---|
DatabaseName |
STRING |
Il nome del database con la distinzione tra maiuscole e minuscole mantenuta. |
TableName |
STRING |
Il nome della tabella con la distinzione tra maiuscole e minuscole. |
TotalSize |
INTEGER |
Le dimensioni della tabella in byte. |
Tables
Questa tabella fornisce informazioni sulle tabelle:
| Colonna | Tipo | Descrizione |
|---|---|---|
DatabaseName |
STRING |
Il nome del database con la distinzione tra maiuscole e minuscole mantenuta. |
TableName |
STRING |
Il nome della tabella con la distinzione tra maiuscole e minuscole. |
Type |
STRING |
Il tipo di tabella. |
TranslatedQueries
Questa tabella fornisce le traduzioni delle query:
| Colonna | Tipo | Descrizione |
|---|---|---|
QueryHash |
STRING |
L'hash della query. |
TranslatedQueryText |
STRING |
Il risultato della traduzione dal dialetto di origine a GoogleSQL. |
TranslationErrors
Questa tabella fornisce informazioni sugli errori di traduzione delle query:
| Colonna | Tipo | Descrizione |
|---|---|---|
QueryHash |
STRING |
L'hash della query. |
Severity |
STRING |
La gravità dell'errore, ad esempio ERROR. |
Category |
STRING |
La categoria dell'errore, ad esempio
AttributeNotFound. |
Message |
STRING |
Il messaggio con i dettagli dell'errore. |
LocationOffset |
INTEGER |
La posizione del carattere in cui si è verificato l'errore. |
LocationLine |
INTEGER |
Il numero di riga dell'errore. |
LocationColumn |
INTEGER |
Il numero di colonna dell'errore. |
LocationLength |
INTEGER |
La lunghezza in caratteri della posizione dell'errore. |
UserTableRelations
| Colonna | Tipo | Descrizione |
|---|---|---|
UserID |
STRING |
L'ID utente. |
TableName |
STRING |
Il nome della tabella. |
Relation |
STRING |
La relazione. |
Count |
INTEGER |
Il conteggio. |
Risoluzione dei problemi
Questa sezione illustra alcuni problemi comuni e tecniche di risoluzione dei problemi per la migrazione del data warehouse a BigQuery.
dwh-migration-dumper errori dello strumento
Per risolvere i problemi relativi a errori e avvisi nell'output del terminale dello strumento dwh-migration-dumper
che si sono verificati durante l'estrazione dei metadati o dei log delle query, consulta
Risoluzione dei problemi relativi alla generazione dei metadati.
Errori di migrazione di Hive
Questa sezione descrive i problemi comuni che potresti riscontrare quando pianifichi la migrazione del data warehouse da Hive a BigQuery.
L'hook di logging scrive i messaggi di log di debug nei log
hive-server2. Se riscontri problemi, esamina i log di debug dell'hook di logging, che contengono la stringa MigrationAssessmentLoggingHook.
Gestire l'errore ClassNotFoundException
L'errore potrebbe essere causato dal posizionamento errato del file JAR dell'hook di logging. Assicurati di aver aggiunto il file JAR alla cartella auxlib sul
cluster Hive. In alternativa, puoi specificare il percorso completo del file JAR nella proprietà hive.aux.jars.path, ad esempio file://.
Le sottocartelle non vengono visualizzate nella cartella configurata
Questo problema potrebbe essere causato da un'errata configurazione o da problemi durante l'inizializzazione dell'hook di logging.
Cerca nei log di debug di hive-server2 i seguenti
messaggi di hook di logging:
Unable to initialize logger, logging disabled
Log dir configuration key 'dwhassessment.hook.base-directory' is not set, logging disabled.
Error while trying to set permission
Esamina i dettagli del problema e verifica se devi correggere qualcosa per risolverlo.
I file non vengono visualizzati nella cartella
Questo problema potrebbe essere causato dai problemi riscontrati durante l'elaborazione di un evento o durante la scrittura in un file.
Cerca nei log di debug di hive-server2 i seguenti
messaggi di hook di logging:
Failed to close writer for file
Got exception while processing event
Error writing record for query
Esamina i dettagli del problema e verifica se devi correggere qualcosa per risolverlo.
Alcuni eventi di query non vengono rilevati
Questo problema potrebbe essere causato dall'overflow della coda del thread di hook di logging.
Cerca nei log di debug di hive-server2 il seguente messaggio
di hook di logging:
Writer queue is full. Ignoring event
Se sono presenti questi messaggi, valuta la possibilità di aumentare il parametro
dwhassessment.hook.queue.capacity.
Passaggi successivi
Per saperne di più sullo strumento dwh-migration-dumper, consulta
dwh-migration-tools.
Puoi anche scoprire di più sui seguenti passaggi della migrazione del data warehouse:
- Panoramica della migrazione
- Panoramica del trasferimento di schemi e dati
- Pipeline di dati
- Traduzione SQL batch
- Traduzione SQL interattiva
- Sicurezza e governance dei dati
- Strumento di convalida dei dati