Usa el complemento de JupyterLab de BigQuery
Si deseas solicitar comentarios o asistencia para esta función, envía un correo electrónico a bigquery-ide-plugin@google.com.
En este documento, se muestra cómo instalar y usar el complemento de JupyterLab de BigQuery para hacer lo siguiente:
- Explorar tus datos de BigQuery.
- Usa la API de BigQuery DataFrames.
- Implementa un notebook de BigQuery DataFrames en Cloud Composer.
El complemento de BigQuery JupyterLab incluye todas la funcionalidad del Complemento de JupyterLab de Dataproc, como crear una plantilla del entorno de ejecución de Dataproc Serverless, iniciar y administrar notebooks, desarrollar con Apache Spark, implementar código y administrar tus recursos.
Instala el complemento de JupyterLab de BigQuery
Para instalar y usar el complemento de BigQuery JupyterLab, sigue estos pasos pasos:
En tu terminal local, verifica que tengas instalado Python 3.8 o una versión posterior en tu sistema:
python3 --versionEn tu terminal local, inicializa la CLI de gcloud:
gcloud initInstala Pipenv, una herramienta de entorno virtual de Python:
pip3 install pipenvCrea un nuevo entorno virtual:
pipenv shellInstala JupyterLab en el entorno virtual nuevo:
pipenv install jupyterlabInstala el complemento de JupyterLab de BigQuery:
pipenv install bigquery-jupyter-pluginSi la versión instalada de JupyterLab es anterior a la 4.0.0, habilita la extensión del complemento:
jupyter server extension enable bigquery_jupyter_pluginInicia JupyterLab:
jupyter labJupyterLab se abre en tu navegador.
Actualiza la configuración del proyecto y la región
De forma predeterminada, la sesión se ejecuta en el proyecto y en la región que estableciste cuando ejecutaste gcloud init. Para cambiar la configuración del proyecto y la región de tu sesión, haz lo siguiente:
- En el menú de JupyterLab, haz clic en Configuración > Configuración de Google BigQuery.
Debes reiniciar el complemento para que se apliquen los cambios.
Explorar datos
Para trabajar con tus datos de BigQuery en JupyterLab, haz lo siguiente:
- En la barra lateral de JupyterLab, abre el panel Explorador de conjuntos de datos. Para ello, haz clic en el ícono
 de conjuntos de datos.
de conjuntos de datos. Para expandir un proyecto, en el panel Explorador de conjuntos de datos, haz clic en la flecha de expansión junto al nombre del proyecto.
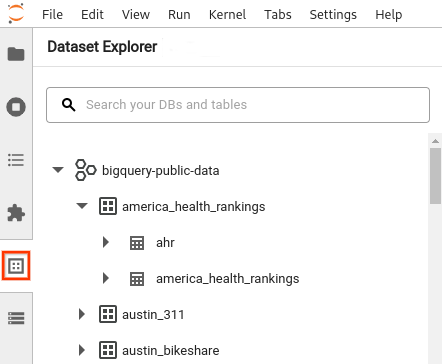
En el panel Explorador de conjuntos de datos muestra todos los conjuntos de datos de un proyecto que se encuentran en la región de BigQuery que configuraste para la sesión. Puedes interactuar con un proyecto y un conjunto de datos de varias maneras:
- Para ver información sobre un conjunto de datos, haz clic en el nombre del conjunto de datos.
- Para mostrar todas las tablas en un conjunto de datos, haz clic en la flecha de expansión junto al conjunto de datos.
- Para ver información sobre una tabla, haz clic en el nombre de la tabla.
- Para cambiar el proyecto o la región de BigQuery, actualiza tu configuración.
Ejecutar notebooks
Para consultar tus datos de BigQuery desde JupyterLab, haz lo siguiente:
- Para abrir la página del selector, haz clic en Archivo > Nuevo selector.
- En la sección Notebooks de BigQuery, haz clic en la tarjeta BigQuery DataFrames. Se abrirá un notebook nuevo en el que se muestra cómo comenzar a usar BigQuery DataFrames
Los notebooks de BigQuery DataFrames admiten el desarrollo en Python en un kernel de Python local. Las operaciones de BigQuery DataFrames se ejecutan de forma remota en BigQuery, pero el resto del código se ejecuta de forma local en tu máquina. Cuando se ejecuta una operación en BigQuery, aparece un ID de trabajo de consulta y un vínculo al trabajo debajo de la celda de código.
- Para ver el trabajo en la consola de Google Cloud , haz clic en Abrir trabajo.
Implementa un notebook de BigQuery DataFrames
Puedes implementar un notebook de BigQuery DataFrames en Cloud Composer mediante una plantilla de entorno de ejecución de Dataproc Serverless. Debes usar la versión 2.1 o posterior del entorno de ejecución.
- En tu notebook de JupyterLab, haz clic en calendar_monthProgramador de trabajos.
- En Nombre del trabajo, ingresa un nombre único para tu trabajo.
- En Entorno, ingresa el nombre del entorno de Cloud Composer en el que deseas implementar el trabajo.
- Si tu notebook está parametrizado, agrega parámetros.
- Ingresa el nombre de la Plantilla del entorno de ejecución sin servidores.
- A fin de controlar las fallas de ejecución de notebooks, ingresa un número entero para el Recuento de reintentos y un valor (en minutos) para el Retraso de los reintentos.
Selecciona qué notificaciones de ejecución quieres enviar y, luego, ingresa los destinatarios.
Las notificaciones se envían con la configuración de SMTP de Airflow.
Selecciona un programa para el notebook.
Haz clic en Crear.
Cuando programas de forma correcta tu notebook, aparece en la lista de trabajos programados del entorno de Cloud Composer seleccionado.
¿Qué sigue?
- Prueba la Guía de inicio rápido de BigQuery DataFrames
- Obtén más información sobre la API de Python de BigQuery DataFrames.
- Usa JupyterLab para sesiones de notebooks y por lotes sin servidores con Dataproc.