Esportazione modelli
Questa pagina mostra come esportare i modelli BigQuery ML. Puoi esportare i modelli BigQuery ML in Cloud Storage e utilizzarli per la previsione online o modificarli in Python. Puoi esportare un modello BigQuery ML:
- Utilizzo della Google Cloud console.
- Utilizzo dell'istruzione
EXPORT MODEL. - Utilizzo del comando
bq extractnello strumento a riga di comando bq. - Invio di un job
extracttramite l'API o le librerie client.
Puoi esportare i seguenti tipi di modelli:
AUTOENCODERAUTOML_CLASSIFIERAUTOML_REGRESSORBOOSTED_TREE_CLASSIFIERBOOSTED_TREE_REGRESSORDNN_CLASSIFIERDNN_REGRESSORDNN_LINEAR_COMBINED_CLASSIFIERDNN_LINEAR_COMBINED_REGRESSORKMEANSLINEAR_REGLOGISTIC_REGMATRIX_FACTORIZATIONRANDOM_FOREST_CLASSIFIERRANDOM_FOREST_REGRESSORTENSORFLOW(modelli TensorFlow importati)PCATRANSFORM_ONLY
Esportare formati ed esempi di modelli
La tabella seguente mostra i formati di destinazione dell'esportazione per ogni tipo di modello BigQuery ML e fornisce un esempio di file scritti nel bucket Cloud Storage.
| Tipo di modello | Formato di esportazione del modello | Esempio di file esportati |
|---|---|---|
| AUTOML_CLASSIFIER | TensorFlow SavedModel (TF 2.1.0) | gcs_bucket/
|
| AUTOML_REGRESSOR | ||
| AUTOENCODER | TensorFlow SavedModel (TF 1.15 o versioni successive) | |
| DNN_CLASSIFIER | ||
| DNN_REGRESSOR | ||
| DNN_LINEAR_COMBINED_CLASSIFIER | ||
| DNN_LINEAR_COMBINED_REGRESSOR | ||
| KMEANS | ||
| LINEAR_REGRESSOR | ||
| LOGISTIC_REG | ||
| MATRIX_FACTORIZATION | ||
| PCA | ||
| TRANSFORM_ONLY | ||
| BOOSTED_TREE_CLASSIFIER | Booster (XGBoost 0.82) | gcs_bucket/
main.py è per l'esecuzione locale. Per ulteriori dettagli, consulta Deployment dei modelli.
|
| BOOSTED_TREE_REGRESSOR | ||
| RANDOM_FOREST_REGRESSOR | ||
| RANDOM_FOREST_REGRESSOR | ||
| TENSORFLOW (importato) | TensorFlow SavedModel | Esattamente gli stessi file presenti al momento dell'importazione del modello |
Esportare il modello addestrato con TRANSFORM
Se il modello viene addestrato con la
clausola TRANSFORM,
un modello di pre-elaborazione aggiuntivo esegue la stessa logica nella
clausola TRANSFORM e viene salvato nel
formato SavedModel di TensorFlow nella sottodirectory transform.
Puoi eseguire il deployment di un modello addestrato con la clausola TRANSFORM
su Vertex AI e localmente. Per saperne di più, consulta la sezione
Deployment dei modelli.
| Formato di esportazione del modello | Esempio di file esportati |
|---|---|
|
Modello di previsione: TensorFlow SavedModel o Booster (XGBoost 0.82).
Modello di pre-elaborazione per la clausola TRANSFORM: TensorFlow SavedModel (TF 2.5 o versioni successive) |
gcs_bucket/
|
Il modello non contiene le informazioni sull'ingegneria delle funzionalità
eseguita al di fuori della clausola TRANSFORM
durante l'addestramento. Ad esempio, qualsiasi elemento nella dichiarazione SELECT . Pertanto, devi convertire manualmente i dati di input prima di inserirli nel modello di pre-elaborazione.
Tipi di dati supportati
Quando esporti modelli addestrati con la clausola TRANSFORM,
i seguenti tipi di dati sono supportati per l'inserimento nella
clausola TRANSFORM.
| Tipo di input TRANSFORM | Esempi di input di TRANSFORM | Esempi di input del modello di preelaborazione esportato |
|---|---|---|
| INT64 |
10,
|
tf.constant(
|
| NUMERIC |
NUMERIC 10,
|
tf.constant(
|
| BIGNUMERIC |
BIGNUMERIC 10,
|
tf.constant(
|
| FLOAT64 |
10.0,
|
tf.constant(
|
| BOOL |
TRUE,
|
tf.constant(
|
| STRING |
'abc',
|
tf.constant(
|
| BYTES |
b'abc',
|
tf.constant(
|
| DATA |
DATE '2020-09-27',
|
tf.constant(
|
| DATETIME |
DATETIME '2023-02-02 02:02:01.152903',
|
tf.constant(
|
| TEMPO |
TIME '16:32:36.152903',
|
tf.constant(
|
| TIMESTAMP |
TIMESTAMP '2017-02-28 12:30:30.45-08',
|
tf.constant(
|
| ARRAY |
['a', 'b'],
|
tf.constant(
|
| ARRAY< STRUCT< INT64, FLOAT64>> |
[(1, 1.0), (2, 1.0)],
|
tf.sparse.from_dense(
|
| NULL |
NULL,
|
tf.constant(
|
Funzioni SQL supportate
Quando esporti modelli addestrati con la clausola TRANSFORM,
puoi utilizzare le seguenti funzioni SQL all'interno della clausola TRANSFORM.
- Operatori
+,-,*,/,=,<,>,<=,>=,!=,<>,[NOT] BETWEEN,[NOT] IN,IS [NOT] NULL,IS [NOT] TRUE,IS [NOT] FALSE,NOT,AND,OR.
- Espressioni condizionali
CASE expr,CASE,COALESCE,IF,IFNULL,NULLIF.
- Funzioni matematiche
ABS,ACOS,ACOSH,ASINH,ATAN,ATAN2,ATANH,CBRT,CEIL,CEILING,COS,COSH,COT,COTH,CSC,CSCH,EXP,FLOOR,IS_INF,IS_NAN,LN,LOG,LOG10,MOD,POW,POWER,SEC,SECH,SIGN,SIN,SINH,SQRT,TAN,TANH.
- Funzioni di conversione
CAST AS INT64,CAST AS FLOAT64,CAST AS NUMERIC,CAST AS BIGNUMERIC,CAST AS STRING,SAFE_CAST AS INT64,SAFE_CAST AS FLOAT64
- Funzioni stringa
CONCAT,LEFT,LENGTH,LOWER,REGEXP_REPLACE,RIGHT,SPLIT,SUBSTR,SUBSTRING,TRIM,UPPER.
- Funzioni data
Date,DATE_ADD,DATE_SUB,DATE_DIFF,DATE_TRUNC,EXTRACT,FORMAT_DATE,PARSE_DATE,SAFE.PARSE_DATE.
- Funzioni di data/ora
DATETIME,DATETIME_ADD,DATETIME_SUB,DATETIME_DIFF,DATETIME_TRUNC,EXTRACT,PARSE_DATETIME,SAFE.PARSE_DATETIME.
- Funzioni temporali
TIME,TIME_ADD,TIME_SUB,TIME_DIFF,TIME_TRUNC,EXTRACT,FORMAT_TIME,PARSE_TIME,SAFE.PARSE_TIME.
- Funzioni di timestamp
TIMESTAMP,TIMESTAMP_ADD,TIMESTAMP_SUB,TIMESTAMP_DIFF,TIMESTAMP_TRUNC,FORMAT_TIMESTAMP,PARSE_TIMESTAMP,SAFE.PARSE_TIMESTAMP,TIMESTAMP_MICROS,TIMESTAMP_MILLIS,TIMESTAMP_SECONDS,EXTRACT,STRING,UNIX_MICROS,UNIX_MILLIS,UNIX_SECONDS.
- Funzioni di pre-elaborazione manuale
ML.IMPUTER,ML.HASH_BUCKETIZE,ML.LABEL_ENCODER,ML.MULTI_HOT_ENCODER,ML.NGRAMS,ML.ONE_HOT_ENCODER,ML.BUCKETIZE,ML.MAX_ABS_SCALER,ML.MIN_MAX_SCALER,ML.NORMALIZER,ML.QUANTILE_BUCKETIZE,ML.ROBUST_SCALER,ML.STANDARD_SCALER.
Limitazioni
Quando esporti i modelli, si applicano le seguenti limitazioni:
L'esportazione del modello non è supportata se durante l'addestramento è stata utilizzata una delle seguenti funzionalità:
- I tipi di funzionalità
ARRAY,TIMESTAMPoGEOGRAPHYerano presenti nei dati di input.
- I tipi di funzionalità
I modelli esportati per i tipi di modello
AUTOML_REGRESSOReAUTOML_CLASSIFIERnon supportano il deployment di Vertex AI per la previsione online.Il limite di dimensioni del modello è di 1 GB per l'esportazione del modello di fattorizzazione matriciale. Le dimensioni del modello sono proporzionali a
num_factors, quindi puoi ridurrenum_factorsdurante l'addestramento per ridurre le dimensioni del modello se raggiungi il limite.Per i modelli addestrati con la clausola BigQuery ML
TRANSFORMper l'elaborazione manuale delle funzionalità, consulta i tipi di dati e le funzioni supportati per l'esportazione.I modelli addestrati con la clausola BigQuery ML
TRANSFORMprima del 18 settembre 2023 devono essere riaddestrati prima di poter essere eseguiti il deployment tramite Model Registry per la previsione online.Durante l'esportazione del modello,
ARRAY<STRUCT<INT64, FLOAT64>>,ARRAYeTIMESTAMPsono supportati come dati pre-trasformati, ma non come dati post-trasformati.
Esportare modelli BigQuery ML
Per esportare un modello, seleziona una delle seguenti opzioni:
Console
Apri la pagina BigQuery nella console Google Cloud .
Nel riquadro a sinistra, fai clic su Explorer:

Se non vedi il riquadro a sinistra, fai clic su Espandi riquadro a sinistra per aprirlo.
Nel riquadro Explorer, espandi il progetto, fai clic su Set di dati e poi sul tuo set di dati.
Fai clic su Panoramica > Modelli e fai clic sul nome del modello che stai esportando.
Fai clic su Altro > Esporta:
Nella finestra di dialogo Esporta modello in Google Cloud Storage:
- Per Seleziona posizione GCS, cerca il bucket o la posizione della cartella in cui vuoi esportare il modello e fai clic su Seleziona.
- Fai clic su Invia per esportare il modello.
Per controllare l'avanzamento del job, nel riquadro Explorer, fai clic su Cronologia dei job e cerca un job di tipo ESTRAI.
SQL
L'istruzione EXPORT MODEL consente di esportare i modelli BigQuery ML
in Cloud Storage utilizzando la sintassi delle query GoogleSQL.
Per esportare un modello BigQuery ML nella console Google Cloud utilizzando l'istruzione EXPORT MODEL, segui questi passaggi:
Nella console Google Cloud , apri la pagina BigQuery.
Fai clic su Crea nuova query.
Nel campo Editor di query, digita l'istruzione
EXPORT MODEL.La seguente query esporta un modello denominato
myproject.mydataset.mymodelin un bucket Cloud Storage con URIgs://bucket/path/to/saved_model/.EXPORT MODEL `myproject.mydataset.mymodel` OPTIONS(URI = 'gs://bucket/path/to/saved_model/')
Fai clic su Esegui. Una volta completata la query, nel riquadro Risultati query viene visualizzato:
Successfully exported model.
bq
Utilizza il comando bq extract con il flag --model.
(Facoltativo) Fornisci il flag --destination_format e scegli il formato del
modello esportato.
(Facoltativo) Fornisci il flag --location e imposta il valore sulla tua posizione.
bq --location=location extract \ --destination_format format \ --model project_id:dataset.model \ gs://bucket/model_folder
Dove:
- location è il nome della tua sede. Il flag
--locationè facoltativo. Ad esempio, se utilizzi BigQuery nella regione di Tokyo, puoi impostare il valore del flag suasia-northeast1. Puoi impostare un valore predefinito per la località utilizzando il file.bigqueryrc. - destination_format è il formato del modello esportato:
ML_TF_SAVED_MODEL(predefinito) oML_XGBOOST_BOOSTER. - project_id è l'ID progetto.
- dataset è il nome del set di dati di origine.
- model è il modello che stai esportando.
- bucket è il nome del bucket Cloud Storage in cui stai esportando i dati. Il set di dati BigQuery e il bucket Cloud Storage devono trovarsi nella stessa posizione.
- model_folder è il nome della cartella in cui verranno scritti i file del modello esportato.
Esempi:
Ad esempio, il seguente comando esporta mydataset.mymodel nel formato TensorFlow SavedModel
in un bucket Cloud Storage denominato mymodel_folder.
bq extract --model \ 'mydataset.mymodel' \ gs://example-bucket/mymodel_folder
Il valore predefinito di destination_format è ML_TF_SAVED_MODEL.
Il comando seguente esporta mydataset.mymodel nel formato XGBoost Booster
in un bucket Cloud Storage denominato mymodel_folder.
bq extract --model \ --destination_format ML_XGBOOST_BOOSTER \ 'mydataset.mytable' \ gs://example-bucket/mymodel_folder
API
Per esportare il modello, crea un job extract e compila la configurazione del job.
(Facoltativo) Specifica la tua posizione nella proprietà location nella sezione jobReference della risorsa job.
Crea un job di estrazione che rimandi al modello BigQuery ML e alla destinazione Cloud Storage.
Specifica il modello di origine utilizzando l'oggetto di configurazione
sourceModelche contiene l'ID progetto, l'ID set di dati e l'ID modello.La proprietà
destination URI(s)deve essere completa, nel formato gs://bucket/model_folder.Specifica il formato di destinazione impostando la proprietà
configuration.extract.destinationFormat. Ad esempio, per esportare un modello ad albero potenziato, imposta questa proprietà sul valoreML_XGBOOST_BOOSTER.Per controllare lo stato del job, chiama jobs.get(job_id) con l'ID del job restituito dalla richiesta iniziale.
- Se
status.state = DONE, il job è stato completato correttamente. - Se è presente la proprietà
status.errorResult, la richiesta non è riuscita e l'oggetto includerà informazioni che descrivono cosa è andato storto. - Se
status.errorResultnon è presente, il job è stato completato correttamente, anche se potrebbero essersi verificati alcuni errori non irreversibili. Gli errori non fatali sono elencati nella proprietàstatus.errorsdell'oggetto job restituito.
- Se
Note sull'API:
Come best practice, genera un ID univoco e passalo come
jobReference.jobIdquando chiamijobs.insertper creare un job. Questo approccio è più resistente agli errori di rete perché il client può eseguire il polling o riprovare con l'ID job noto.La chiamata di
jobs.insertsu un determinato ID job è idempotente, il che significa che puoi riprovare tutte le volte che vuoi sullo stesso ID job e al massimo una di queste operazioni andrà a buon fine.
Java
Prima di provare questo esempio, segui le istruzioni di configurazione di Java nella guida rapida di BigQuery per l'utilizzo delle librerie client. Per saperne di più, consulta la documentazione di riferimento dell'API BigQuery Java.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per saperne di più, vedi Configurare l'autenticazione per le librerie client.
Deployment del modello
Puoi eseguire il deployment del modello esportato in Vertex AI e localmente. Se la
clausola TRANSFORM del modello contiene funzioni di data, ora, data e ora o timestamp, devi
utilizzare la libreria bigquery-ml-utils
nel container. L'eccezione è se esegui il deployment tramite Model Registry, che non richiede modelli esportati o container di servizio.
Deployment di Vertex AI
| Formato di esportazione del modello | Deployment |
|---|---|
| SavedModel TensorFlow (modelli non AutoML) | Esegui il deployment di un SavedModel TensorFlow. Devi creare il file SavedModel utilizzando una versione supportata di TensorFlow. |
| SavedModel TensorFlow (modelli AutoML) | Non supportati. |
| XGBoost Booster |
Utilizza una routine di previsione personalizzata. Per i modelli XGBoost Booster, le informazioni di pre-elaborazione e post-elaborazione
vengono salvate nei file esportati e una routine di previsione
personalizzata consente di eseguire il deployment del modello con i file
esportati aggiuntivi.
Devi creare i file del modello utilizzando una versione supportata di XGBoost. |
Deployment locale
| Formato di esportazione del modello | Deployment |
|---|---|
| SavedModel TensorFlow (modelli non AutoML) |
SavedModel è un formato standard e puoi eseguirne il deployment nel container Docker di TensorFlow Serving. Puoi anche sfruttare l'esecuzione locale della previsione online di Vertex AI. |
| SavedModel TensorFlow (modelli AutoML) | Inserisci il modello in un container ed eseguilo. |
| XGBoost Booster |
Per eseguire localmente i modelli XGBoost Booster, puoi utilizzare il file main.py
esportato:
|
Formato di output della previsione
Questa sezione fornisce il formato dell'output di previsione dei modelli esportati per ogni tipo di modello. Tutti i modelli esportati supportano la previsione batch e possono gestire più righe di input contemporaneamente. Ad esempio, in ognuno dei seguenti esempi di formato di output sono presenti due righe di input.
AUTOENCODER
| Formato di output della previsione | Esempio di output |
|---|---|
+------------------------+------------------------+------------------------+
| LATENT_COL_1 | LATENT_COL_2 | ... |
+------------------------+------------------------+------------------------+
| [FLOAT] | [FLOAT] | ... |
+------------------------+------------------------+------------------------+
|
+------------------+------------------+------------------+------------------+
| LATENT_COL_1 | LATENT_COL_2 | LATENT_COL_3 | LATENT_COL_4 |
+------------------------+------------+------------------+------------------+
| 0.21384512 | 0.93457112 | 0.64978097 | 0.00480489 |
+------------------+------------------+------------------+------------------+
|
AUTOML_CLASSIFIER
| Formato di output della previsione | Esempio di output |
|---|---|
+------------------------------------------+
| predictions |
+------------------------------------------+
| [{"scores":[FLOAT], "classes":[STRING]}] |
+------------------------------------------+
|
+---------------------------------------------+
| predictions |
+---------------------------------------------+
| [{"scores":[1, 2], "classes":['a', 'b']}, |
| {"scores":[3, 0.2], "classes":['a', 'b']}] |
+---------------------------------------------+
|
AUTOML_REGRESSOR
| Formato di output della previsione | Esempio di output |
|---|---|
+-----------------+
| predictions |
+-----------------+
| [FLOAT] |
+-----------------+
|
+-----------------+
| predictions |
+-----------------+
| [1.8, 2.46] |
+-----------------+
|
BOOSTED_TREE_CLASSIFIER e RANDOM_FOREST_CLASSIFIER
| Formato di output della previsione | Esempio di output |
|---|---|
+-------------+--------------+-----------------+
| LABEL_PROBS | LABEL_VALUES | PREDICTED_LABEL |
+-------------+--------------+-----------------+
| [FLOAT] | [STRING] | STRING |
+-------------+--------------+-----------------+
|
+-------------+--------------+-----------------+
| LABEL_PROBS | LABEL_VALUES | PREDICTED_LABEL |
+-------------+--------------+-----------------+
| [0.1, 0.9] | ['a', 'b'] | ['b'] |
+-------------+--------------+-----------------+
| [0.8, 0.2] | ['a', 'b'] | ['a'] |
+-------------+--------------+-----------------+
|
BOOSTED_TREE_REGRESSOR E RANDOM_FOREST_REGRESSOR
| Formato di output della previsione | Esempio di output |
|---|---|
+-----------------+
| predicted_label |
+-----------------+
| FLOAT |
+-----------------+
|
+-----------------+
| predicted_label |
+-----------------+
| [1.8] |
+-----------------+
| [2.46] |
+-----------------+
|
DNN_CLASSIFIER
| Formato di output della previsione | Esempio di output |
|---|---|
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| ALL_CLASS_IDS | ALL_CLASSES | CLASS_IDS | CLASSES | LOGISTIC (binary only) | LOGITS | PROBABILITIES |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [INT64] | [STRING] | INT64 | STRING | FLOAT | [FLOAT]| [FLOAT] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
|
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| ALL_CLASS_IDS | ALL_CLASSES | CLASS_IDS | CLASSES | LOGISTIC (binary only) | LOGITS | PROBABILITIES |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [0, 1] | ['a', 'b'] | [0] | ['a'] | [0.36] | [-0.53]| [0.64, 0.36] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [0, 1] | ['a', 'b'] | [0] | ['a'] | [0.2] | [-1.38]| [0.8, 0.2] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
|
DNN_REGRESSOR
| Formato di output della previsione | Esempio di output |
|---|---|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| FLOAT |
+-----------------+
|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| [1.8] |
+-----------------+
| [2.46] |
+-----------------+
|
DNN_LINEAR_COMBINED_CLASSIFIER
| Formato di output della previsione | Esempio di output |
|---|---|
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| ALL_CLASS_IDS | ALL_CLASSES | CLASS_IDS | CLASSES | LOGISTIC (binary only) | LOGITS | PROBABILITIES |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [INT64] | [STRING] | INT64 | STRING | FLOAT | [FLOAT]| [FLOAT] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
|
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| ALL_CLASS_IDS | ALL_CLASSES | CLASS_IDS | CLASSES | LOGISTIC (binary only) | LOGITS | PROBABILITIES |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [0, 1] | ['a', 'b'] | [0] | ['a'] | [0.36] | [-0.53]| [0.64, 0.36] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [0, 1] | ['a', 'b'] | [0] | ['a'] | [0.2] | [-1.38]| [0.8, 0.2] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
|
DNN_LINEAR_COMBINED_REGRESSOR
| Formato di output della previsione | Esempio di output |
|---|---|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| FLOAT |
+-----------------+
|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| [1.8] |
+-----------------+
| [2.46] |
+-----------------+
|
KMEANS
| Formato di output della previsione | Esempio di output |
|---|---|
+--------------------+--------------+---------------------+
| CENTROID_DISTANCES | CENTROID_IDS | NEAREST_CENTROID_ID |
+--------------------+--------------+---------------------+
| [FLOAT] | [INT64] | INT64 |
+--------------------+--------------+---------------------+
|
+--------------------+--------------+---------------------+
| CENTROID_DISTANCES | CENTROID_IDS | NEAREST_CENTROID_ID |
+--------------------+--------------+---------------------+
| [1.2, 1.3] | [1, 2] | [1] |
+--------------------+--------------+---------------------+
| [0.4, 0.1] | [1, 2] | [2] |
+--------------------+--------------+---------------------+
|
LINEAR_REG
| Formato di output della previsione | Esempio di output |
|---|---|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| FLOAT |
+-----------------+
|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| [1.8] |
+-----------------+
| [2.46] |
+-----------------+
|
LOGISTIC_REG
| Formato di output della previsione | Esempio di output |
|---|---|
+-------------+--------------+-----------------+
| LABEL_PROBS | LABEL_VALUES | PREDICTED_LABEL |
+-------------+--------------+-----------------+
| [FLOAT] | [STRING] | STRING |
+-------------+--------------+-----------------+
|
+-------------+--------------+-----------------+
| LABEL_PROBS | LABEL_VALUES | PREDICTED_LABEL |
+-------------+--------------+-----------------+
| [0.1, 0.9] | ['a', 'b'] | ['b'] |
+-------------+--------------+-----------------+
| [0.8, 0.2] | ['a', 'b'] | ['a'] |
+-------------+--------------+-----------------+
|
MATRIX_FACTORIZATION
Nota:al momento supportiamo solo l'acquisizione di un utente di input e l'output delle 50 coppie (predicted_rating, predicted_item) principali ordinate in base a predicted_rating in ordine decrescente.
| Formato di output della previsione | Esempio di output |
|---|---|
+--------------------+--------------+
| PREDICTED_RATING | PREDICTED_ITEM |
+------------------+----------------+
| [FLOAT] | [STRING] |
+------------------+----------------+
|
+--------------------+--------------+
| PREDICTED_RATING | PREDICTED_ITEM |
+------------------+----------------+
| [5.5, 1.7] | ['A', 'B'] |
+------------------+----------------+
| [7.2, 2.7] | ['B', 'A'] |
+------------------+----------------+
|
TENSORFLOW (importato)
| Formato di output della previsione |
|---|
| Uguale al modello importato |
PCA
| Formato di output della previsione | Esempio di output |
|---|---|
+-------------------------+---------------------------------+
| PRINCIPAL_COMPONENT_IDS | PRINCIPAL_COMPONENT_PROJECTIONS |
+-------------------------+---------------------------------+
| [INT64] | [FLOAT] |
+-------------------------+---------------------------------+
|
+-------------------------+---------------------------------+
| PRINCIPAL_COMPONENT_IDS | PRINCIPAL_COMPONENT_PROJECTIONS |
+-------------------------+---------------------------------+
| [1, 2] | [1.2, 5.0] |
+-------------------------+---------------------------------+
|
TRANSFORM_ONLY
| Formato di output della previsione |
|---|
Uguale alle colonne specificate nella clausola TRANSFORM del modello
|
Visualizzazione del modello XGBoost
Puoi visualizzare gli alberi potenziati utilizzando l'API Python plot_tree dopo l'esportazione del modello. Ad esempio, puoi utilizzare Colab senza installare le dipendenze:
- Esporta il modello ad albero potenziato in un bucket Cloud Storage.
- Scarica il file
model.bstdal bucket Cloud Storage. - In un notebook di Colab,
carica il file
model.bstsuFiles. Esegui questo codice nel notebook:
import xgboost as xgb import matplotlib.pyplot as plt model = xgb.Booster(model_file="model.bst") num_iterations = <iteration_number> for tree_num in range(num_iterations): xgb.plot_tree(model, num_trees=tree_num) plt.show
Questo esempio traccia più alberi (un albero per iterazione):
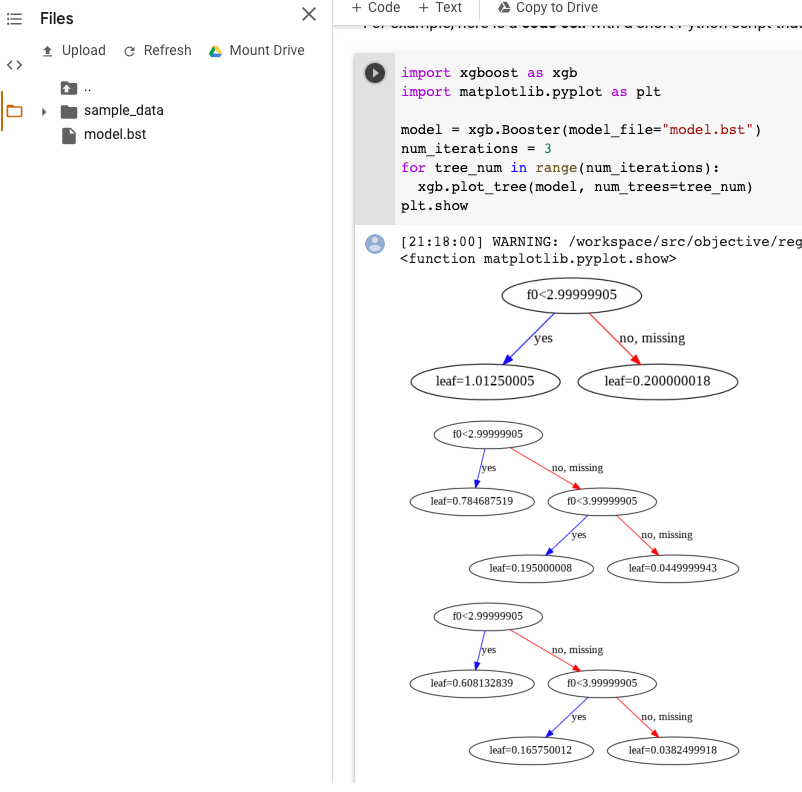
Al momento non salviamo i nomi delle funzionalità nel modello, quindi vedrai nomi
come "f0", "f1" e così via. Puoi trovare i nomi delle funzionalità corrispondenti nel file assets/model_metadata.json esportato utilizzando questi nomi (ad esempio "f0") come indici.
Autorizzazioni obbligatorie
Per esportare un modello BigQuery ML in Cloud Storage, devi disporre delle autorizzazioni per accedere al modello BigQuery ML, per eseguire un job di estrazione e per scrivere i dati nel bucket Cloud Storage.
Autorizzazioni BigQuery
Per esportare il modello, devi disporre almeno delle autorizzazioni
bigquery.models.export. I seguenti ruoli IAM (Identity and Access Management) predefiniti dispongono delle autorizzazionibigquery.models.export:bigquery.dataViewerbigquery.dataOwnerbigquery.dataEditorbigquery.admin
Come minimo, per eseguire un job di esportazione, devi disporre delle autorizzazioni
bigquery.jobs.create. I seguenti ruoli IAM predefiniti dispongono delle autorizzazionibigquery.jobs.create:bigquery.userbigquery.jobUserbigquery.admin
Autorizzazioni Cloud Storage
Per scrivere i dati in un bucket Cloud Storage esistente, devi disporre delle autorizzazioni
storage.objects.create. I seguenti ruoli IAM predefiniti dispongono delle autorizzazionistorage.objects.create:storage.objectCreatorstorage.objectAdminstorage.admin
Per saperne di più su ruoli e autorizzazioni IAM in BigQuery ML, consulta Controllo dell'accesso.
Spostare i dati BigQuery tra le località
Non puoi modificare la posizione di un set di dati dopo la creazione, ma puoi crearne una copia.
Criteri per le quote
Per informazioni sulle quote dei job di estrazione, consulta la sezione Job di estrazione nella pagina Quote e limiti.
Prezzi
L'esportazione dei modelli BigQuery ML non prevede costi, ma è soggetta a quote e limiti di BigQuery. Per ulteriori informazioni sui prezzi di BigQuery, consulta la pagina Prezzi.
Una volta esportati i dati, ti viene addebitato il costo di archiviazione dei dati in Cloud Storage. Per maggiori informazioni sui prezzi di Cloud Storage, consulta la pagina Prezzi di Cloud Storage.
Passaggi successivi
- Segui il tutorial Esportare un modello BigQuery ML per la previsione online.