Creazione di set di dati
Questo documento descrive come creare set di dati in BigQuery.
Puoi creare set di dati nei seguenti modi:
- Utilizzo della console Google Cloud .
- Utilizzando una query SQL.
- Utilizzo del comando
bq mknello strumento a riga di comando bq. - Chiamata del metodo API
datasets.insert. - Utilizzo delle librerie client.
- Copia di un set di dati esistente.
Per visualizzare i passaggi per copiare un set di dati, anche tra regioni, consulta Copiare i set di dati.
Questo documento descrive come lavorare con i set di dati regolari che archiviano i dati in BigQuery. Per scoprire come utilizzare i set di dati esterni Spanner, consulta Creare set di dati esterni Spanner. Per scoprire come lavorare con i set di dati federati di AWS Glue, consulta Creare set di dati federati di AWS Glue.
Per scoprire come eseguire query sulle tabelle in un set di dati pubblico, consulta Esegui una query su un set di dati pubblico con la console Google Cloud .
Limitazioni dei set di dati
I set di dati BigQuery sono soggetti alle seguenti limitazioni:
- La posizione del set di dati può essere impostata solo al momento della creazione. Una volta creato un set di dati, la sua posizione non può essere modificata.
- Tutte le tabelle a cui viene fatto riferimento in una query devono essere archiviate in set di dati nella stessa posizione.
I set di dati esterni non supportano la scadenza delle tabelle, le repliche, lo spostamento nel tempo, le regole di confronto predefinite, la modalità di arrotondamento predefinita o l'opzione per attivare o disattivare i nomi delle tabelle senza distinzione tra maiuscole e minuscole.
Quando copi una tabella, i set di dati che contengono la tabella di origine e la tabella di destinazione devono trovarsi nella stessa posizione.
I nomi dei set di dati devono essere univoci per ogni progetto.
Se modifichi il modello di fatturazione dello spazio di archiviazione di un set di dati, devi attendere 14 giorni prima di poterlo modificare di nuovo.
Prima di iniziare
Concedi i ruoli IAM (Identity and Access Management) che forniscono agli utenti le autorizzazioni necessarie per eseguire ogni attività descritta in questo documento.
Autorizzazioni obbligatorie
Per creare un set di dati, devi disporre dell'autorizzazione IAM bigquery.datasets.create.
Ciascuno dei seguenti ruoli IAM predefiniti include le autorizzazioni necessarie per creare un set di dati:
roles/bigquery.dataEditorroles/bigquery.dataOwnerroles/bigquery.userroles/bigquery.admin
Per saperne di più sui ruoli IAM in BigQuery, consulta Ruoli e autorizzazioni predefiniti.
Creazione di set di dati
Per creare un set di dati:
Console
- Apri la pagina BigQuery nella console Google Cloud . Vai alla pagina BigQuery
- Nel riquadro a sinistra, fai clic su Esplora.
- Seleziona il progetto in cui vuoi creare il set di dati.
- Fai clic su Visualizza azioni, quindi fai clic su Crea set di dati.
- Nella pagina Crea set di dati:
- In ID set di dati, inserisci un nome univoco per il set di dati.
- Per Tipo di località, scegli una località geografica per il set di dati. Una volta creato un set di dati, la posizione non può essere modificata.
- (Facoltativo) Seleziona Link a un set di dati esterno se stai creando un set di dati esterno.
- Se non devi configurare altre opzioni come tag e scadenze delle tabelle, fai clic su Crea set di dati. Altrimenti, espandi la sezione seguente per configurare le opzioni aggiuntive del set di dati.
- (Facoltativo) Espandi la sezione Tag per aggiungere tag al tuo set di dati.
- Per applicare un tag esistente:
- Fai clic sulla freccia menu a discesa accanto a Seleziona ambito e scegli Ambito corrente: Seleziona l'organizzazione corrente o Seleziona il progetto corrente.
- Per Chiave 1 e Valore 1, scegli i valori appropriati dagli elenchi.
- Per inserire manualmente un nuovo tag:
- Fai clic sulla freccia menu a discesa accanto a Seleziona un ambito e scegli Inserisci manualmente gli ID > Organizzazione, Progetto o Tag.
- Se stai creando un tag per il tuo progetto o la tua organizzazione,
nella finestra di dialogo, inserisci
PROJECT_IDoORGANIZATION_ID, quindi fai clic su Salva. - Per Chiave 1 e Valore 1, scegli i valori appropriati dagli elenchi.
- Per aggiungere altri tag alla tabella, fai clic su Aggiungi tag e segui i passaggi precedenti.
- (Facoltativo) Espandi la sezione Opzioni avanzate per configurare una o più delle seguenti opzioni.
- Per modificare l'opzione Crittografia in modo da utilizzare la tua chiave crittografica con Cloud Key Management Service, seleziona Chiave Cloud KMS.
- Per utilizzare nomi di tabelle senza distinzione tra maiuscole e minuscole, seleziona Abilita nomi di tabelle senza distinzione tra maiuscole e minuscole.
- Per modificare la specifica delle regole di confronto predefinite, scegli il tipo di regole di confronto dall'elenco.
- Per impostare una scadenza per le tabelle nel set di dati, seleziona Abilita scadenza della tabella, quindi specifica la Durata massima predefinita della tabella in giorni.
- Per impostare una modalità di arrotondamento predefinita, scegli la modalità di arrotondamento dall'elenco.
- Per attivare il modello di fatturazione dell'archiviazione, scegli il modello di fatturazione dall'elenco.
- Per impostare la finestra di spostamento cronologico del set di dati, scegli la dimensione della finestra dall'elenco.
- Fai clic su Crea set di dati.
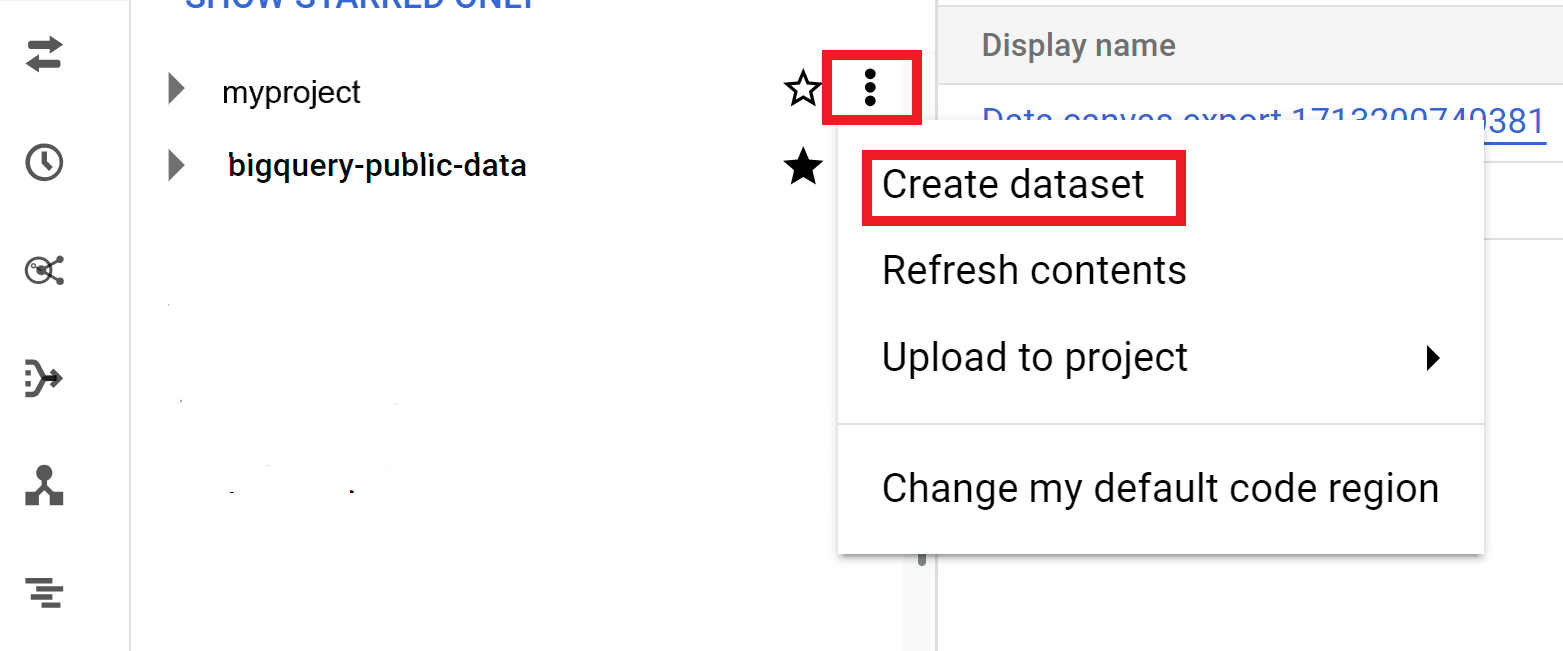
Opzioni aggiuntive per i set di dati
In alternativa, fai clic su Seleziona ambito per cercare una risorsa o per visualizzare un elenco delle risorse attuali.
Quando modifichi il modello di fatturazione di un set di dati, sono necessarie 24 ore prima che la modifica abbia effetto.
Dopo aver modificato il modello di fatturazione dello spazio di archiviazione di un set di dati, devi attendere 14 giorni prima di poterlo modificare di nuovo.
SQL
Utilizza l'istruzione CREATE SCHEMA.
Per creare un set di dati in un progetto diverso da quello predefinito, aggiungi l'ID progetto all'ID set di dati nel seguente formato:
PROJECT_ID.DATASET_ID.
Nella console Google Cloud , vai alla pagina BigQuery.
Nell'editor di query, inserisci la seguente istruzione:
CREATE SCHEMA PROJECT_ID.DATASET_ID OPTIONS ( default_kms_key_name = 'KMS_KEY_NAME', default_partition_expiration_days = PARTITION_EXPIRATION, default_table_expiration_days = TABLE_EXPIRATION, description = 'DESCRIPTION', labels = [('KEY_1','VALUE_1'),('KEY_2','VALUE_2')], location = 'LOCATION', max_time_travel_hours = HOURS, storage_billing_model = BILLING_MODEL);
Sostituisci quanto segue:
PROJECT_ID: il tuo ID progettoDATASET_ID: l'ID del set di dati che stai creandoKMS_KEY_NAME: il nome della chiave Cloud Key Management Service predefinita utilizzata per proteggere le tabelle appena create in questo set di dati, a meno che non venga fornita una chiave diversa al momento della creazione. Non puoi creare una tabella criptata da Google in un set di dati con questo parametro impostato.PARTITION_EXPIRATION: la durata predefinita (in giorni) per le partizioni nelle tabelle partizionate appena create. La scadenza partizione predefinita non ha un valore minimo. La scadenza corrisponde alla data della partizione più il valore intero. Qualsiasi partizione creata in una tabella partizionata nel set di dati viene eliminataPARTITION_EXPIRATIONgiorni dopo la data della partizione. Se fornisci l'opzionetime_partitioning_expirationquando crei o aggiorni una tabella partizionata, la scadenza della partizione a livello di tabella ha la precedenza sulla scadenza della partizione predefinita a livello di set di dati.TABLE_EXPIRATION: la durata predefinita (in giorni) per le tabelle appena create. Il valore minimo è 0,042 giorni (un'ora). La scadenza corrisponde all'ora corrente più il valore intero. Qualsiasi tabella creata nel set di dati viene eliminataTABLE_EXPIRATIONgiorni dopo la creazione. Questo valore viene applicato se non imposti una scadenza della tabella quando crei la tabella.DESCRIPTION: una descrizione del set di datiKEY_1:VALUE_1: la coppia chiave-valore che vuoi impostare come prima etichetta di questo set di datiKEY_2:VALUE_2: la coppia chiave-valore che vuoi impostare come seconda etichettaLOCATION: la posizione del dataset. Una volta creato un set di dati, la posizione non può essere modificata.HOURS: la durata in ore della finestra di spostamento nel tempo per il nuovo set di dati. Il valore diHOURSdeve essere un numero intero espresso in multipli di 24 (48, 72, 96, 120, 144, 168) compreso tra 48 (2 giorni) e 168 (7 giorni). 168 ore è il valore predefinito se questa opzione non è specificata.BILLING_MODEL: imposta il modello di fatturazione dell'archiviazione per il set di dati. Imposta il valore diBILLING_MODELsuPHYSICALper utilizzare i byte fisici durante il calcolo degli addebiti per lo spazio di archiviazione oppure suLOGICALper utilizzare i byte logici.LOGICALè il valore predefinito.Quando modifichi il modello di fatturazione di un set di dati, sono necessarie 24 ore prima che la modifica abbia effetto.
Dopo aver modificato il modello di fatturazione dello spazio di archiviazione di un set di dati, devi attendere 14 giorni prima di poterlo modificare di nuovo.
Fai clic su Esegui.
Per saperne di più su come eseguire le query, consulta Eseguire una query interattiva.
bq
Per creare un nuovo set di dati, utilizza il
comando bq mk
con il flag --location. Per un elenco completo dei possibili parametri, consulta la
documentazione di riferimento del
comando bq mk --dataset.
Per creare un set di dati in un progetto diverso da quello predefinito, aggiungi l'ID progetto al nome del set di dati nel seguente formato:
PROJECT_ID:DATASET_ID.
bq --location=LOCATION mk \ --dataset \ --default_kms_key=KMS_KEY_NAME \ --default_partition_expiration=PARTITION_EXPIRATION \ --default_table_expiration=TABLE_EXPIRATION \ --description="DESCRIPTION" \ --label=KEY_1:VALUE_1 \ --label=KEY_2:VALUE_2 \ --add_tags=KEY_3:VALUE_3[,...] \ --max_time_travel_hours=HOURS \ --storage_billing_model=BILLING_MODEL \ PROJECT_ID:DATASET_ID
Sostituisci quanto segue:
LOCATION: la posizione del set di dati. Una volta creato un set di dati, la posizione non può essere modificata. Puoi impostare un valore predefinito per la posizione utilizzando il file.bigqueryrc.KMS_KEY_NAME: il nome della chiave Cloud Key Management Service predefinita utilizzata per proteggere le tabelle appena create in questo set di dati, a meno che non venga fornita una chiave diversa al momento della creazione. Non puoi creare una tabella criptata da Google in un set di dati con questo parametro impostato.PARTITION_EXPIRATION: la durata predefinita (in secondi) per le partizioni nelle tabelle partizionate appena create. La scadenza predefinita della partizione non ha un valore minimo. Il tempo di scadenza corrisponde alla data della partizione più il valore intero. Qualsiasi partizione creata in una tabella partizionata nel set di dati viene eliminataPARTITION_EXPIRATIONsecondi dopo la data della partizione. Se fornisci il flag--time_partitioning_expirationquando crei o aggiorni una tabella partizionata, la scadenza della partizione a livello di tabella ha la precedenza sulla scadenza della partizione predefinita a livello di set di dati.TABLE_EXPIRATION: la durata predefinita (in secondi) per le tabelle appena create. Il valore minimo è 3600 secondi (1 ora). La scadenza corrisponde all'ora corrente più il valore intero. Qualsiasi tabella creata nel set di dati viene eliminataTABLE_EXPIRATIONsecondi dopo l'ora di creazione. Questo valore viene applicato se non imposti una scadenza della tabella quando crei la tabella.DESCRIPTION: una descrizione del set di datiKEY_1:VALUE_1: la coppia chiave-valore che vuoi impostare come prima etichetta di questo set di dati eKEY_2:VALUE_2è la coppia chiave-valore che vuoi impostare come seconda etichetta.KEY_3:VALUE_3: la coppia chiave-valore che vuoi impostare come tag nel set di dati. Aggiungi più tag con lo stesso flag separati da virgole tra le coppie chiave:valore.HOURS: la durata in ore della finestra di Time Travel per il nuovo set di dati. Il valore diHOURSdeve essere un numero intero espresso in multipli di 24 (48, 72, 96, 120, 144, 168) compreso tra 48 (2 giorni) e 168 (7 giorni). 168 ore è il valore predefinito se questa opzione non è specificata.BILLING_MODEL: imposta il modello di fatturazione dell'archiviazione per il set di dati. Imposta il valore diBILLING_MODELsuPHYSICALper utilizzare i byte fisici durante il calcolo degli addebiti per lo spazio di archiviazione oppure suLOGICALper utilizzare i byte logici.LOGICALè il valore predefinito.Quando modifichi il modello di fatturazione di un set di dati, sono necessarie 24 ore prima che la modifica abbia effetto.
Dopo aver modificato il modello di fatturazione dello spazio di archiviazione di un set di dati, devi attendere 14 giorni prima di poterlo modificare di nuovo.
PROJECT_ID: il tuo ID progetto.DATASET_IDè l'ID del set di dati che stai creando.
Ad esempio, il seguente comando crea un set di dati denominato mydataset con la posizione dei dati impostata su US, una scadenza predefinita della tabella di 3600 secondi (1 ora) e una descrizione di This is my dataset. Anziché utilizzare il flag --dataset, il
comando utilizza la scorciatoia -d. Se ometti -d e --dataset, il comando
crea un set di dati per impostazione predefinita.
bq --location=US mk -d \ --default_table_expiration 3600 \ --description "This is my dataset." \ mydataset
Per confermare che il set di dati sia stato creato, inserisci il comando bq ls. Inoltre,
puoi creare una tabella quando crei un nuovo set di dati utilizzando il
seguente formato: bq mk -t dataset.table.
Per saperne di più sulla creazione di tabelle, vedi
Creare una tabella.
Terraform
Utilizza la risorsa
google_bigquery_dataset.
Per eseguire l'autenticazione in BigQuery, configura le credenziali predefinite dell'applicazione. Per saperne di più, vedi Configurare l'autenticazione per le librerie client.
Creare un set di dati
L'esempio seguente crea un set di dati denominato mydataset:
Quando crei un set di dati utilizzando la risorsa google_bigquery_dataset,
viene concesso automaticamente l'accesso al set di dati a tutti gli account che sono
membri dei ruoli di base a livello di progetto.
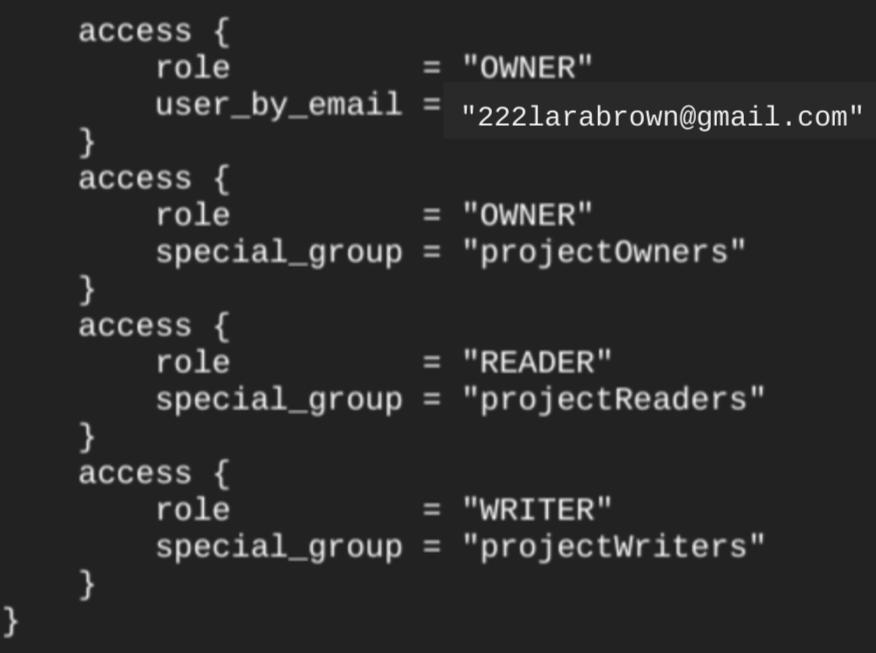
Se esegui il
comando terraform show
dopo aver creato il set di dati, il
blocco access per il set di dati è simile al
seguente:
Per concedere l'accesso al set di dati, ti consigliamo di utilizzare una delle
risorse google_bigquery_iam, come mostrato nell'esempio seguente, a meno che tu non preveda
di creare oggetti autorizzati, ad esempio
viste autorizzate, all'interno del set di dati.
In questo caso, utilizza la
risorsa google_bigquery_dataset_access. Per alcuni esempi, consulta la documentazione.
Creare un set di dati e concedere l'accesso
L'esempio seguente crea un set di dati denominato mydataset, quindi utilizza la risorsa
google_bigquery_dataset_iam_policy per concedere
l'accesso.
Crea un set di dati con una chiave di crittografia gestita dal cliente
L'esempio seguente crea un set di dati denominato mydataset e utilizza anche le risorse
google_kms_crypto_key
e
google_kms_key_ring
per specificare una chiave Cloud Key Management Service per il set di dati. Prima di eseguire questo esempio, devi abilitare l'API Cloud Key Management Service.
Per applicare la configurazione di Terraform in un progetto Google Cloud , completa i passaggi nelle sezioni seguenti.
Prepara Cloud Shell
- Avvia Cloud Shell.
-
Imposta il progetto Google Cloud predefinito in cui vuoi applicare le configurazioni Terraform.
Devi eseguire questo comando una sola volta per progetto e puoi eseguirlo in qualsiasi directory.
export GOOGLE_CLOUD_PROJECT=PROJECT_ID
Le variabili di ambiente vengono sostituite se imposti valori espliciti nel file di configurazione Terraform.
Prepara la directory
Ogni file di configurazione Terraform deve avere la propria directory (chiamata anche modulo radice).
-
In Cloud Shell, crea una directory e un nuovo file al suo interno. Il nome file deve avere l'estensione
.tf, ad esempiomain.tf. In questo tutorial, il file viene denominatomain.tf.mkdir DIRECTORY && cd DIRECTORY && touch main.tf
-
Se stai seguendo un tutorial, puoi copiare il codice campione in ogni sezione o passaggio.
Copia il codice campione nel
main.tfappena creato.(Facoltativo) Copia il codice da GitHub. Questa operazione è consigliata quando lo snippet Terraform fa parte di una soluzione end-to-end.
- Rivedi e modifica i parametri di esempio da applicare al tuo ambiente.
- Salva le modifiche.
-
Inizializza Terraform. Devi effettuare questa operazione una sola volta per directory.
terraform init
(Facoltativo) Per utilizzare l'ultima versione del provider Google, includi l'opzione
-upgrade:terraform init -upgrade
Applica le modifiche
-
Rivedi la configurazione e verifica che le risorse che Terraform creerà o
aggiornerà corrispondano alle tue aspettative:
terraform plan
Apporta le correzioni necessarie alla configurazione.
-
Applica la configurazione di Terraform eseguendo il comando seguente e inserendo
yesal prompt:terraform apply
Attendi che Terraform visualizzi il messaggio "Apply complete!".
- Apri il tuo Google Cloud progetto per visualizzare i risultati. Nella console Google Cloud , vai alle risorse nell'interfaccia utente per assicurarti che Terraform le abbia create o aggiornate.
API
Chiama il metodo datasets.insert con una risorsa dataset definita.
C#
Prima di provare questo esempio, segui le istruzioni di configurazione di C# nella guida rapida di BigQuery per l'utilizzo delle librerie client. Per saperne di più, consulta la documentazione di riferimento dell'API BigQuery C#.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per saperne di più, vedi Configurare l'autenticazione per le librerie client.
Vai
Prima di provare questo esempio, segui le istruzioni di configurazione di Go nella guida rapida di BigQuery per l'utilizzo delle librerie client. Per saperne di più, consulta la documentazione di riferimento dell'API BigQuery Go.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per saperne di più, vedi Configurare l'autenticazione per le librerie client.
Java
Prima di provare questo esempio, segui le istruzioni di configurazione di Java nella guida rapida di BigQuery per l'utilizzo delle librerie client. Per saperne di più, consulta la documentazione di riferimento dell'API BigQuery Java.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per saperne di più, vedi Configurare l'autenticazione per le librerie client.
Node.js
Prima di provare questo esempio, segui le istruzioni di configurazione di Node.js nella guida rapida di BigQuery per l'utilizzo delle librerie client. Per saperne di più, consulta la documentazione di riferimento dell'API BigQuery Node.js.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per saperne di più, vedi Configurare l'autenticazione per le librerie client.
PHP
Prima di provare questo esempio, segui le istruzioni di configurazione di PHP nella guida rapida di BigQuery per l'utilizzo delle librerie client. Per saperne di più, consulta la documentazione di riferimento dell'API BigQuery PHP.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per saperne di più, vedi Configurare l'autenticazione per le librerie client.
Python
Prima di provare questo esempio, segui le istruzioni di configurazione di Python nella guida rapida di BigQuery per l'utilizzo delle librerie client. Per saperne di più, consulta la documentazione di riferimento dell'API BigQuery Python.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per saperne di più, vedi Configurare l'autenticazione per le librerie client.
Ruby
Prima di provare questo esempio, segui le istruzioni di configurazione di Ruby nella guida rapida di BigQuery per l'utilizzo delle librerie client. Per saperne di più, consulta la documentazione di riferimento dell'API BigQuery Ruby.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per saperne di più, vedi Configurare l'autenticazione per le librerie client.
Assegnare un nome ai set di dati
Quando crei un set di dati in BigQuery, il nome del set di dati deve essere univoco per ogni progetto. Il nome del set di dati può contenere:
- Fino a 1024 caratteri.
- Lettere (maiuscole o minuscole), numeri e trattini bassi.
Per impostazione predefinita, i nomi dei set di dati sono sensibili alle maiuscole. mydataset e MyDataset possono
coesistere nello stesso progetto, a meno che uno dei due non abbia la distinzione tra maiuscole e minuscole
disattivata. Per esempi, vedi
Creazione di un set di dati senza distinzione tra maiuscole e minuscole
e Risorsa: set di dati.
I nomi dei set di dati non possono contenere spazi o caratteri speciali come -, &, @
o %.
Set di dati nascosti
Un set di dati nascosto è un set di dati il cui nome inizia con un trattino basso. Puoi eseguire query su tabelle e viste nei set di dati nascosti allo stesso modo di qualsiasi altro set di dati. I set di dati nascosti presentano le seguenti limitazioni:
- Sono nascosti nel riquadro Explorer della console Google Cloud .
- Non vengono visualizzati in nessuna visualizzazione
INFORMATION_SCHEMA. - Non possono essere utilizzati con i set di dati collegati.
- Non possono essere utilizzati come set di dati di origine con le seguenti risorse autorizzate:
- Non vengono visualizzati in Data Catalog (ritirato) o Dataplex Universal Catalog.
Sicurezza del set di dati
Per controllare l'accesso ai set di dati in BigQuery, vedi Controllo dell'accesso ai set di dati. Per informazioni sulla crittografia dei dati, vedi Crittografia at-rest.
Passaggi successivi
- Per ulteriori informazioni sull'elenco dei set di dati in un progetto, consulta la sezione Elenco dei set di dati.
- Per ulteriori informazioni sui metadati dei set di dati, vedi Recuperare informazioni sui set di dati.
- Per saperne di più sulla modifica delle proprietà dei set di dati, consulta Aggiornamento dei set di dati.
- Per saperne di più sulla creazione e la gestione delle etichette, consulta la pagina Creare e gestire le etichette.
Provalo
Se non conosci Google Cloud, crea un account per valutare le prestazioni di BigQuery in scenari reali. I nuovi clienti ricevono anche 300 $ di crediti per l'esecuzione, il test e il deployment di workload senza costi aggiuntivi.
Prova BigQuery gratuitamente