공간 분석 권장사항
이 문서에서는 BigQuery에서 지리적 쿼리 성능을 최적화하기 위한 권장사항을 설명합니다. 이러한 권장사항을 사용하여 성능을 개선하고 비용과 지연 시간을 줄일 수 있습니다.
데이터 세트에는 도로, 필지, 홍수 지역과 같은 복잡한 지형지물을 나타내는 다각형, 여러 다각형 도형, 유도선의 대규모 컬렉션이 포함될 수 있습니다. 각 도형은 수천 개의 점을 포함할 수 있습니다. BigQuery의 대부분의 공간 작업(예: 교차점 및 거리 계산)에서 기본 알고리즘은 일반적으로 각 도형의 대부분의 점을 방문하여 결과를 생성합니다. 일부 작업의 경우 알고리즘이 모든 지점을 방문합니다. 복잡한 도형의 경우 각 지점을 방문하면 공간 작업의 비용과 시간이 늘어날 수 있습니다. 이 가이드에 설명된 전략과 방법을 사용하여 이러한 일반적인 공간 작업을 최적화하여 성능을 개선하고 비용을 절감할 수 있습니다.
이 문서에서는 BigQuery 지리 공간 테이블이 지역 열에 클러스터링되어 있다고 가정합니다.
도형 단순화
권장사항: 단순화 및 그리드에 맞추기 함수를 사용하여 원본 데이터 세트의 단순화된 버전을 구체화된 뷰로 저장합니다.
많은 수의 점이 있는 복잡한 도형을 정밀도를 크게 손상시키지 않고도 단순화할 수 있습니다. BigQuery ST_SIMPLIFY 및 ST_SNAPTOGRID 함수를 개별적으로 또는 함께 사용하여 복잡한 도형의 점 수를 줄입니다.
이러한 함수를 BigQuery 구체화된 뷰와 결합하여 원본 데이터 세트의 단순화된 버전을 기본 테이블에 대해 자동으로 최신 상태로 유지되는 구체화된 뷰로 저장합니다.
도형을 단순화하는 것은 다음과 같은 사용 사례에서 데이터 세트의 비용과 성능을 개선하는 데 가장 유용합니다.
- 실제 도형과 높은 유사성을 유지해야 합니다.
- 고정밀, 고정확도 작업을 수행해야 합니다.
- 도형 세부정보가 눈에 띄게 손실되지 않고 시각화 속도를 높이려 합니다.
다음 코드 샘플은 geom이라는 GEOGRAPHY 열이 있는 기본 테이블에서 ST_SIMPLIFY 함수를 사용하는 방법을 보여줍니다. 이 코드는 도형의 가장자리를 지정된 허용 오차인 1.0미터 이상으로 영향을 주지 않고 도형을 단순화하고 점을 삭제합니다.
CREATE MATERIALIZED VIEW project.dataset.base_mv
CLUSTER BY geom
AS (
SELECT
* EXCEPT (geom),
ST_SIMPLIFY(geom, 1.0) AS geom
FROM base_table
)
다음 코드 샘플은 ST_SNAPTOGRID 함수를 사용하여 해상도가 0.00001도인 그리드에 점을 맞추는 방법을 보여줍니다.
CREATE MATERIALIZED VIEW project.dataset.base_mv
CLUSTER BY geom
AS (
SELECT
* EXCEPT (geom),
ST_SNAPTOGRID(geom, -5) AS geom
FROM base_table
)
이 함수의 grid_size 인수는 지수 역할을 하며, 이는 10e-5 = 0.00001을 의미합니다. 이 해상도는 최악의 경우 적도에서 발생하는 약 1m에 해당합니다.
이러한 뷰를 만든 후 기본 테이블을 쿼리할 때 사용하는 것과 동일한 쿼리 시맨틱스를 사용하여 base_mv 뷰를 쿼리합니다. 이 기법을 사용하여 더 심층적으로 분석해야 하는 도형 컬렉션을 빠르게 식별한 다음 기본 표에서 두 번째 심층 분석을 실행할 수 있습니다. 쿼리를 테스트하여 데이터에 가장 적합한 기준 값을 확인합니다.
측정 사용 사례의 경우 사용 사례에 필요한 정확성 수준을 결정합니다. ST_SIMPLIFY 함수를 사용할 때는 threshold_meters 파라미터를 필요한 정확도 수준으로 설정합니다. 도시 규모 이상의 거리를 측정하려면 기준을 10m로 설정합니다. 건물과 가장 가까운 수역 간의 거리를 측정할 때와 같이 더 작은 규모의 경우 1m 이하의 더 작은 기준을 사용하는 것이 좋습니다. 더 작은 기준값을 사용하면 지정된 도형에서 삭제되는 점이 줄어듭니다.
웹 서비스에서 지도 레이어를 제공할 때는 BigQuery에서 공간 레이어를 제공할 수 있는 Geoserver의 드라이버인 bigquery-geotools 프로젝트를 사용하여 다양한 확대/축소 수준의 구체화된 뷰를 미리 계산할 수 있습니다. 이 드라이버는 확대/축소 수준이 높을수록 세부정보가 적게 제공되도록 다양한 ST_SIMPLIFY 기준 파라미터를 사용하여 여러 구체화된 뷰를 만듭니다.
점 및 직사각형 사용
권장사항: 도형을 점 또는 직사각형으로 줄여 위치를 나타냅니다.
도형을 단일 지점 또는 직사각형으로 줄여 쿼리 성능을 개선할 수 있습니다. 이 섹션의 메서드는 도형의 세부정보와 비율을 정확하게 나타내지 않고 도형의 위치를 나타내도록 최적화합니다.
도형의 지리적 중심점(중심)을 사용하여 전체 도형의 위치를 나타낼 수 있습니다. 도형이 포함된 직사각형을 사용하여 도형의 범위를 만듭니다. 이 범위는 도형의 위치를 나타내고 상대 크기에 관한 정보를 유지하는 데 사용할 수 있습니다.
점과 직사각형을 사용하면 두 도시 간의 거리와 같이 두 지점 간의 거리를 측정해야 할 때 데이터 세트의 비용과 성능을 개선하는 데 가장 유용합니다.
예를 들어 미국의 필지 데이터베이스를 BigQuery 테이블에 로드한 후 가장 가까운 수역을 결정해 보겠습니다.
이 경우 이 문서의 도형 단순화 섹션에 설명된 메서드와 함께 ST_CENTROID 함수를 사용하여 필지 중심을 미리 계산하면 ST_DISTANCE 또는 ST_DWITHIN 함수를 사용할 때 실행되는 비교 횟수를 줄일 수 있습니다. ST_CENTROID 함수를 사용할 때는 계산에 필지 중심을 고려해야 합니다. 이 방법으로 필지 중심을 사전 계산하면 필지 모양에 따라 점의 개수가 다를 수 있으므로 성능의 변동성도 줄일 수 있습니다.
이 메서드의 변형은 ST_CENTROID 함수 대신 ST_BOUNDINGBOX 함수를 사용하여 입력 도형 주위의 직사각형 봉투를 계산하는 것입니다. 단일 지점을 사용하는 것만큼 효율적이지는 않지만 특정 특이 사례의 발생을 줄일 수 있습니다. 이 변형은 여전히 우수하고 일관된 성능을 제공합니다. ST_BOUNDINGBOX 함수의 출력에는 항상 고려해야 할 네 지점만 포함되기 때문입니다. 경계 상자 결과는 STRUCT 유형이므로 거리를 수동으로 계산하거나 이 문서의 뒷부분에 설명된 벡터 색인 메서드를 사용해야 합니다.
껍질 사용
권장사항: 껍질을 사용하여 도형의 위치를 나타내는 데 최적화하세요.
도형을 축소 래핑하고 축소 래핑의 경계를 계산한다고 가정하면 이 경계를 껍질이라고 합니다. 볼록 껍질에서 결과 도형의 모든 각도는 볼록합니다. 도형의 범위와 마찬가지로 볼록 껍질은 기본 도형의 상대적 크기와 비율에 관한 일부 정보를 유지합니다. 하지만 껍질을 사용하면 후속 분석에서 더 많은 지점을 저장하고 고려해야 합니다.
ST_CONVEXHULL 함수를 사용하여 도형의 위치를 나타내도록 최적화할 수 있습니다. 이 함수를 사용하면 정확성이 향상되지만 성능은 저하됩니다. ST_CONVEXHULL 함수는 ST_EXTENT 함수와 유사하지만 출력 도형에 더 많은 점이 포함되어 있고 입력 도형의 복잡도에 따라 점 수가 달라집니다. 복잡하지 않은 도형의 작은 데이터 세트의 경우 성능 이점이 무시할 만하지만 크고 복잡한 도형이 있는 매우 큰 데이터 세트의 경우 ST_CONVEXHULL 함수가 비용, 성능, 정확도 간에 적절한 균형을 제공합니다.
그리드 시스템 사용
권장사항: 지리 공간 그리드 시스템을 사용하여 영역을 비교하세요.
현지화된 영역 내에서 데이터를 집계하고 해당 영역의 통계 집계를 서로 비교하는 사용 사례의 경우 표준화된 그리드 시스템을 활용하여 여러 영역을 비교하는 것이 좋습니다.
예를 들어 소매업체는 매장이 위치하거나 새 매장 건설을 고려 중인 지역에서 시간 경과에 따른 인구통계 변화를 분석할 수 있습니다. 또는 보험 회사에서는 특정 지역에서 우세한 자연 재해 위험을 분석하여 자산 위험에 대한 이해를 높이려고 할 수 있습니다.
S2 및 H3과 같은 표준 그리드 시스템을 사용하면 이러한 통계 집계 및 공간 분석을 더 빠르게 처리할 수 있습니다. 이러한 그리드 시스템을 사용하면 분석 개발을 간소화하고 개발 효율성을 개선할 수도 있습니다.
예를 들어 미국에서 인구 조사 지역을 사용한 비교는 크기가 일관되지 않으므로 인구 조사 지역 간에 동일한 비교를 수행하려면 수정 계수를 적용해야 합니다. 또한 인구 조사 지역 및 기타 행정 경계는 시간이 지남에 따라 변경되며 이러한 변경사항을 수정하기 위해 노력해야 합니다. 공간 분석에 그리드 시스템을 사용하면 이러한 문제를 해결할 수 있습니다.
벡터 검색 및 벡터 색인 사용
권장사항: 최근접 이웃 지리 공간 쿼리에 벡터 검색 및 벡터 색인을 사용하세요.
시맨틱 검색, 유사성 인식, 검색 증강 생성과 같은 머신러닝 사용 사례를 지원하기 위해 벡터 검색 기능이 BigQuery에 도입되었습니다. 이러한 사용 사례를 사용 설정하는 데 중요한 것은 근사 최근접 이웃 검색이라는 색인 생성 방법입니다. 벡터 검색을 사용하여 공간의 점을 나타내는 벡터를 비교하여 최근접 이웃 지리 공간 쿼리의 속도를 높이고 간소화할 수 있습니다.
벡터 검색을 사용하여 반경으로 지형지물을 검색할 수 있습니다. 먼저 검색 반경을 설정합니다. 최근접 이웃 검색의 결과 집합에서 최적의 반경을 찾을 수 있습니다. 반경을 설정한 후 ST_DWITHIN 함수를 사용하여 근처 지형지물을 식별합니다.
예를 들어 이미 위치를 알고 있는 특정 앵커 빌딩에 가장 가까운 10개의 빌딩을 찾는 경우를 생각해 보세요. 각 건물의 중심을 새 테이블에 벡터로 저장하고 테이블에 색인을 생성한 후 벡터 검색을 사용하여 검색할 수 있습니다.
이 예시에서는 BigQuery의 Overture 지도 데이터를 사용하여 관심 지역에 해당하는 건물 도형의 별도 테이블과 geom_vector라는 벡터를 만들 수도 있습니다. 이 예시에서 관심 지역은 다음 코드 샘플과 같이 FIPS 코드 51710으로 표시된 미국 버지니아주 노퍽입니다.
CREATE TABLE vector_search.norfolk_buildings
AS (
SELECT
*,
[
ST_X(ST_CENTROID(building.geometry)),
ST_Y(ST_CENTROID(building.geometry))] AS geom_vector
FROM `bigquery-public-data.overture_maps.building` AS building
INNER JOIN `bigquery-public-data.geo_us_boundaries.counties` AS county
ON (st_intersects(county.county_geom, building.geometry))
WHERE county.county_fips_code = '51710'
)
다음 코드 샘플은 테이블에 벡터 색인을 만드는 방법을 보여줍니다.
CREATE
vector index building_vector_index
ON
vector_search.norfolk_buildings(geom_vector)
OPTIONS (index_type = 'IVF')
이 쿼리는 특정 앵커 건물에 가장 가까운 건물 10개를 식별합니다.
SELECT base.*
FROM
VECTOR_SEARCH(
TABLE vector_search.norfolk_buildings,
'geom_vector',
(
SELECT
geom_vector
FROM
vector_search.norfolk_buildings
WHERE id = '56873794-9873-4fe1-871a-5987bb3a0efb'
),
top_k => 10,
distance_type => 'EUCLIDEAN',
options => '{"fraction_lists_to_search":0.1}')
쿼리 결과 창에서 시각화 탭을 클릭합니다. 지도에는 앵커 건물에 가장 가까운 건물 도형의 클러스터가 표시됩니다.
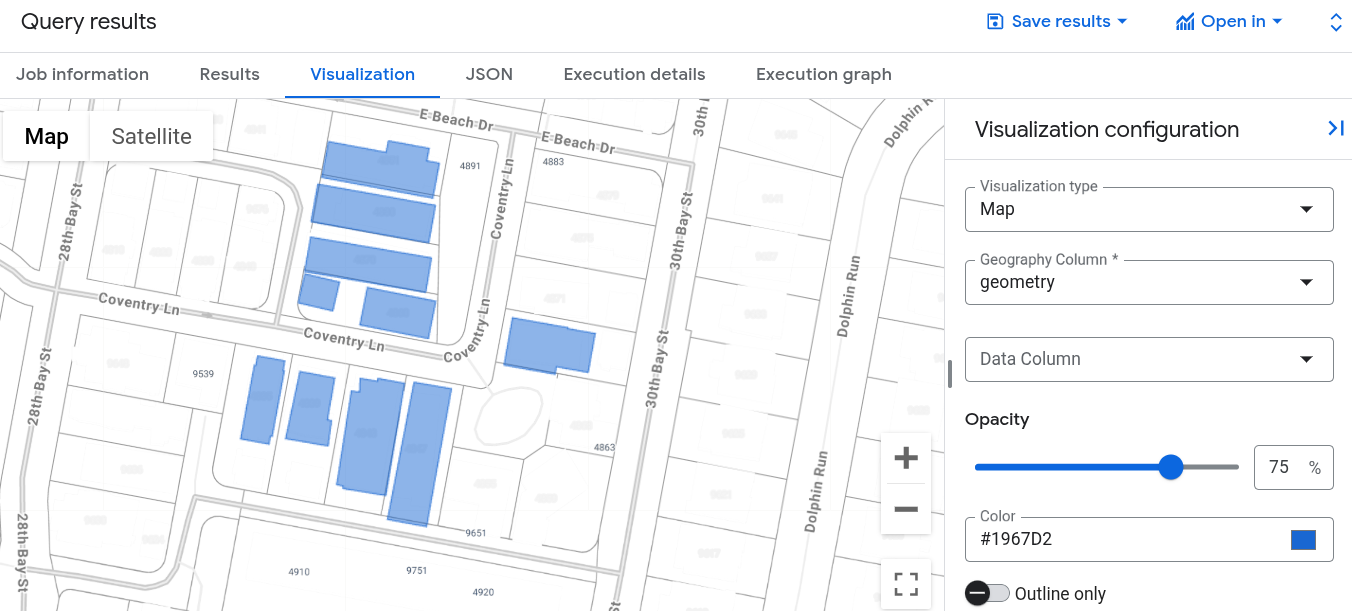
Google Cloud 콘솔에서 이 쿼리를 실행할 때 작업 정보를 클릭하고 벡터 색인 사용 모드가 FULLY_USED로 설정되어 있는지 확인합니다. 이는 쿼리가 이전에 만든 building_vector_index 벡터 색인을 활용하고 있음을 나타냅니다.
큰 도형 나누기
권장사항: 큰 도형을 ST_SUBDIVIDE 함수로 나눕니다.
ST_SUBDIVIDE 함수를 사용하여 큰 도형이나 긴 줄 문자열을 더 작은 도형으로 나눕니다.
다음 단계
- 공간 분석에 그리드 시스템을 사용하는 방법 알아보기
- BigQuery 지리 함수에 대해 자세히 알아보기
- 벡터 색인을 관리하는 방법 알아보기
- BigQuery의 공간 색인 생성 및 클러스터링 권장사항에 대해 자세히 알아보기
- BigQuery에서 지리 공간 데이터를 분석하고 시각화하는 방법에 관한 자세한 내용은 지리 공간 분석 시작하기를 참조하세요.