Preveja séries de tempo hierárquicas com um modelo univariado ARIMA_PLUS
Este tutorial ensina a usar um
ARIMA_PLUS modelo de série temporal univariado
para prever séries temporais hierárquicas. Prevê o valor futuro
para uma determinada coluna, com base nos valores do histórico dessa coluna,
e também calcula os valores agregados dessa coluna para uma ou mais dimensões de
interesse.
Os valores previstos são calculados para cada ponto temporal, para cada valor numa ou mais colunas que especificam as dimensões de interesse. Por exemplo, se quiser prever incidentes de trânsito diários e especificar uma coluna de dimensão que contenha dados de estado, os dados previstos vão conter valores para cada dia do estado A, seguidos dos valores para cada dia do estado B e assim sucessivamente. Se quisesse prever incidentes de trânsito diários e especificasse colunas de dimensões que contivessem dados de estado e cidade, os dados previstos conteriam valores para cada dia para o estado A e a cidade A, depois valores para cada dia para o estado A e a cidade B, e assim sucessivamente. Nos modelos de séries cronológicas hierárquicos, a conciliação hierárquica é usada para agregar e conciliar cada série cronológica secundária com a respetiva série cronológica principal. Por exemplo, a soma dos valores previstos para todas as cidades no estado A tem de ser igual ao valor previsto para o estado A.
Neste tutorial, vai criar dois modelos de séries cronológicas com os mesmos dados, um que usa a previsão hierárquica e outro que não usa. Isto permite-lhe comparar os resultados devolvidos pelos modelos.
Este tutorial usa dados da tabela pública
bigquery-public-data.iowa_liquor.sales.sales. Esta tabela contém informações sobre mais de 1 milhão de produtos de bebidas alcoólicas em diferentes lojas com dados públicos de vendas de bebidas alcoólicas do Iowa.
Antes de ler este tutorial, recomendamos vivamente que leia o artigo Preveja várias séries cronológicas com um modelo univariado.
Autorizações necessárias
Para criar o conjunto de dados, precisa da autorização
bigquery.datasets.createIAM.Para criar o modelo, precisa das seguintes autorizações:
bigquery.jobs.createbigquery.models.createbigquery.models.getDatabigquery.models.updateData
Para executar a inferência, precisa das seguintes autorizações:
bigquery.models.getDatabigquery.jobs.create
Para mais informações acerca das funções e autorizações do IAM no BigQuery, consulte o artigo Introdução ao IAM.
Objetivos
Neste tutorial, vai usar o seguinte:
- Criar um modelo de várias séries cronológicas e um modelo de várias séries cronológicas hierárquicas para prever os valores de vendas de garrafas através da declaração
CREATE MODEL. - Obter os valores de vendas de garrafas previstos dos modelos através da função
ML.FORECAST.
Custos
Este tutorial usa componentes faturáveis do Google Cloud, incluindo o seguinte:
- BigQuery
- BigQuery ML
Para mais informações acerca dos custos do BigQuery, consulte a página de preços do BigQuery.
Para mais informações acerca dos custos do BigQuery ML, consulte os preços do BigQuery ML.
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
- O BigQuery é ativado automaticamente em novos projetos.
Para ativar o BigQuery num projeto pré-existente, aceda a
Enable the BigQuery API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. Na Google Cloud consola, aceda à página BigQuery.
No painel Explorador, clique no nome do projeto.
Clique em Ver ações > Criar conjunto de dados
Na página Criar conjunto de dados, faça o seguinte:
Para o ID do conjunto de dados, introduza
bqml_tutorial.Em Tipo de localização, selecione Várias regiões e, de seguida, selecione EUA (várias regiões nos Estados Unidos).
Deixe as restantes predefinições como estão e clique em Criar conjunto de dados.
Crie um conjunto de dados com o nome
bqml_tutorialcom a localização dos dados definida comoUSe uma descrição deBigQuery ML tutorial dataset:bq --location=US mk -d \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
Em vez de usar a flag
--dataset, o comando usa o atalho-d. Se omitir-de--dataset, o comando cria um conjunto de dados por predefinição.Confirme que o conjunto de dados foi criado:
bq lsNa Google Cloud consola, aceda à página BigQuery.
No editor de consultas, cole a seguinte consulta e clique em Executar:
CREATE OR REPLACE MODEL `bqml_tutorial.liquor_forecast` OPTIONS ( MODEL_TYPE = 'ARIMA_PLUS', TIME_SERIES_TIMESTAMP_COL = 'date', TIME_SERIES_DATA_COL = 'total_bottles_sold', TIME_SERIES_ID_COL = ['store_number', 'zip_code', 'city', 'county'], HOLIDAY_REGION = 'US') AS SELECT store_number, zip_code, city, county, date, SUM(bottles_sold) AS total_bottles_sold FROM `bigquery-public-data.iowa_liquor_sales.sales` WHERE date BETWEEN DATE('2015-01-01') AND DATE('2015-12-31') AND county IN ('POLK', 'LINN', 'SCOTT') GROUP BY store_number, date, city, zip_code, county;
A consulta demora aproximadamente 37 segundos a ser concluída. Depois, pode aceder ao modelo
liquor_forecast. Uma vez que a consulta usa uma declaraçãoCREATE MODELpara criar um modelo, não existem resultados de consulta.Na Google Cloud consola, aceda à página BigQuery.
No editor de consultas, cole a seguinte consulta e clique em Executar:
SELECT * FROM ML.FORECAST( MODEL `bqml_tutorial.liquor_forecast`, STRUCT(20 AS horizon, 0.8 AS confidence_level)) ORDER BY store_number, county, city, zip_code, forecast_timestamp;
Os resultados devem ter um aspeto semelhante ao seguinte:
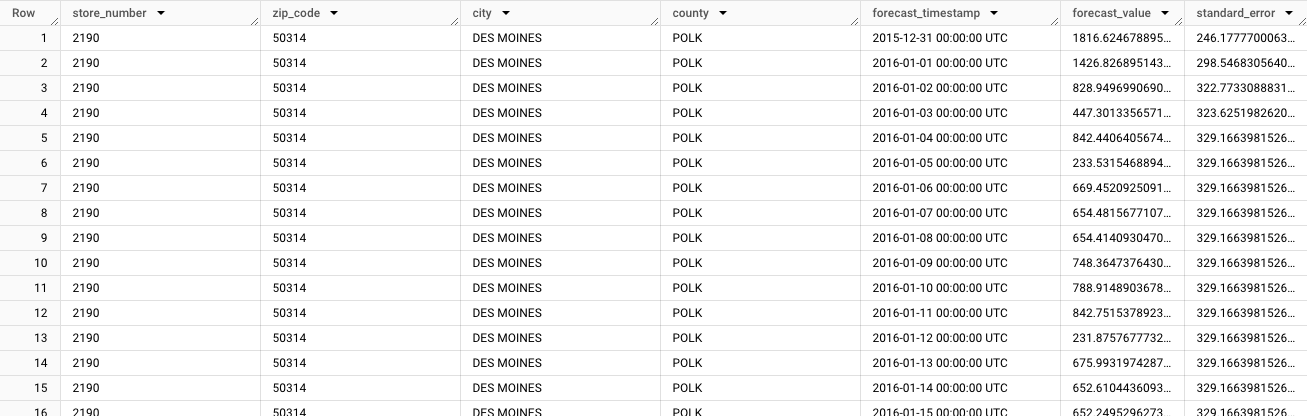
O resultado começa com os dados previstos para o primeiro intervalo temporal:
store_number=2190,zip_code=50314,city=DES MOINESecounty=POLK. À medida que desloca a página pelos dados, vê as previsões para cada série temporal única subsequente. Para gerar previsões que agreguem totais para diferentes dimensões, como previsões para um concelho específico, tem de gerar uma previsão hierárquica.Na Google Cloud consola, aceda à página BigQuery.
No editor de consultas, cole a seguinte consulta e clique em Executar:
CREATE OR REPLACE MODEL `bqml_tutorial.liquor_forecast_hierarchical` OPTIONS ( MODEL_TYPE = 'ARIMA_PLUS', TIME_SERIES_TIMESTAMP_COL = 'date', TIME_SERIES_DATA_COL = 'total_bottles_sold', TIME_SERIES_ID_COL = ['store_number', 'zip_code', 'city', 'county'], HIERARCHICAL_TIME_SERIES_COLS = ['zip_code', 'store_number'], HOLIDAY_REGION = 'US') AS SELECT store_number, zip_code, city, county, date, SUM(bottles_sold) AS total_bottles_sold FROM `bigquery-public-data.iowa_liquor_sales.sales` WHERE date BETWEEN DATE('2015-01-01') AND DATE('2015-12-31') AND county IN ('POLK', 'LINN', 'SCOTT') GROUP BY store_number, date, city, zip_code, county;
A consulta demora aproximadamente 45 segundos a ser concluída. Após este período, pode aceder ao modelo
bqml_tutorial.liquor_forecast_hierarchicalno painel Explorador. Uma vez que a consulta usa uma declaraçãoCREATE MODELpara criar um modelo, não existem resultados da consulta.Na Google Cloud consola, aceda à página BigQuery.
No editor de consultas, cole a seguinte consulta e clique em Executar:
SELECT * FROM ML.FORECAST( MODEL `bqml_tutorial.liquor_forecast_hierarchical`, STRUCT(30 AS horizon, 0.8 AS confidence_level)) WHERE city = 'LECLAIRE' ORDER BY county, city, zip_code, store_number, forecast_timestamp;
Os resultados devem ter um aspeto semelhante ao seguinte:
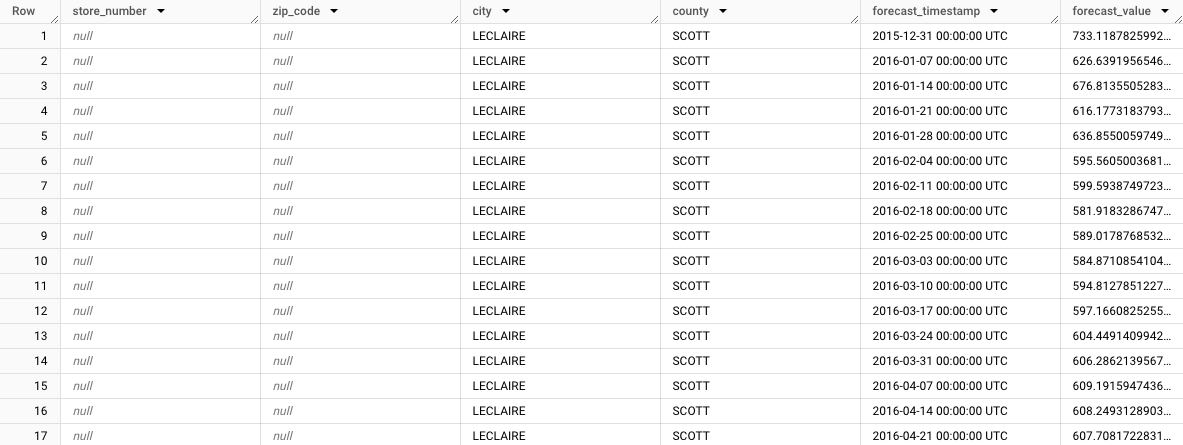
Repare como a previsão agregada é apresentada para a cidade de LeClaire,
store_number=NULL,zip_code=NULL,city=LECLAIREecounty=SCOTT. À medida que analisa as restantes linhas, repare nas previsões dos outros subgrupos. Por exemplo, a imagem seguinte mostra as previsões agregadas para o código postal52753,store_number=NULL,zip_code=52753,city=LECLAIRE,county=SCOTT: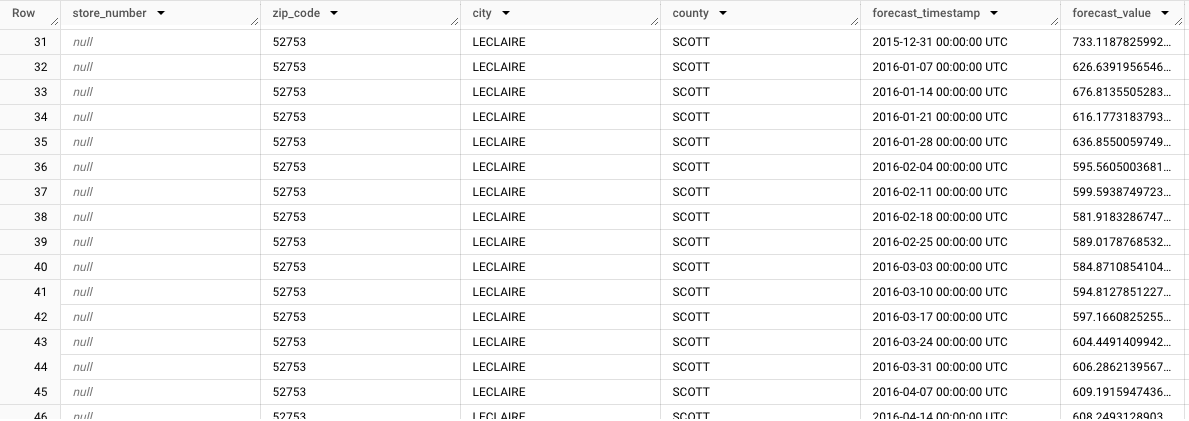
- Pode eliminar o projeto que criou.
- Em alternativa, pode manter o projeto e eliminar o conjunto de dados.
Se necessário, abra a página do BigQuery na Google Cloud consola.
Na navegação, clique no conjunto de dados bqml_tutorial que criou.
Clique em Eliminar conjunto de dados no lado direito da janela. Esta ação elimina o conjunto de dados, a tabela e todos os dados.
Na caixa de diálogo Eliminar conjunto de dados, confirme o comando de eliminação escrevendo o nome do conjunto de dados (
bqml_tutorial) e, de seguida, clique em Eliminar.- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
- Saiba como prever uma única série cronológica com um modelo univariado
- Saiba como prever várias séries cronológicas com um modelo univariado
- Saiba como dimensionar um modelo univariado quando prevê várias séries cronológicas em muitas linhas.
- Saiba como prever uma única série cronológica com um modelo multivariável
- Para uma vista geral do BigQuery ML, consulte o artigo Introdução à IA e ao ML no BigQuery.
Crie um conjunto de dados
Crie um conjunto de dados do BigQuery para armazenar o seu modelo de ML.
Consola
bq
Para criar um novo conjunto de dados, use o comando
bq mk
com a flag --location. Para uma lista completa de parâmetros possíveis, consulte a referência do comando bq mk --dataset.
API
Chame o método datasets.insert
com um recurso de conjunto de dados definido.
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
DataFrames do BigQuery
Antes de experimentar este exemplo, siga as instruções de configuração dos DataFrames do BigQuery no início rápido do BigQuery com os DataFrames do BigQuery. Para mais informações, consulte a documentação de referência do BigQuery DataFrames.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure o ADC para um ambiente de desenvolvimento local.
Crie um modelo de séries cronológicas
Crie um modelo de séries cronológicas com os dados de vendas de bebidas alcoólicas do Iowa.
A seguinte consulta GoogleSQL cria um modelo que prevê o número total diário de garrafas vendidas em 2015 nos condados de Polk, Linn e Scott.
Na consulta seguinte, a cláusula
OPTIONS(model_type='ARIMA_PLUS', time_series_timestamp_col='date', ...)
indica que está a criar um modelo de série cronológica baseado em
ARIMA. Use a opção TIME_SERIES_ID da declaração CREATE MODEL para especificar uma ou mais colunas nos dados de entrada para as quais quer obter previsões. A opção auto_arima_max_order da declaração CREATE MODEL controla o espaço de pesquisa para o ajuste de hiperparâmetros no algoritmo auto.ARIMA. A opção
decompose_time_series
da declaração CREATE MODEL tem como predefinição TRUE, para que as informações sobre os dados da série cronológica sejam devolvidas quando avaliar o modelo no passo seguinte.
A cláusula OPTIONS(model_type='ARIMA_PLUS', time_series_timestamp_col='date', ...)
indica que está a criar um modelo de intervalo temporal baseado em
ARIMA. Por predefinição,
auto_arima=TRUE,
pelo que o algoritmo auto.ARIMA ajusta automaticamente os hiperparâmetros nos
modelos ARIMA_PLUS. O algoritmo ajusta dezenas de modelos candidatos e escolhe o melhor modelo, que é o modelo com o critério de informação de Akaike (AIC) mais baixo.
A definição da opção holiday_region para US permite uma modelagem mais precisa nesses pontos temporais de feriados dos Estados Unidos se existirem padrões de feriados dos Estados Unidos na série cronológica.
Siga estes passos para criar o modelo:
Use o modelo para prever dados
Preveja valores de séries cronológicas futuras através da função ML.FORECAST.
Na consulta seguinte, a cláusula STRUCT(20 AS horizon, 0.8 AS confidence_level) indica que a consulta prevê 20 pontos temporais futuros e gera um intervalo de previsão com um nível de confiança de 80%.
Siga estes passos para prever dados com o modelo:
Crie um modelo de série cronológica hierárquico
Crie uma previsão de séries cronológicas hierárquicas com os dados de vendas de bebidas alcoólicas do Iowa.
A seguinte consulta GoogleSQL cria um modelo que gera previsões hierárquicas para o número total diário de garrafas vendidas em 2015 nos condados de Polk, Linn e Scott.
Na consulta seguinte, a opção HIERARCHICAL_TIME_SERIES_COLS na declaração CREATE MODEL indica que está a criar uma previsão hierárquica com base num conjunto de colunas que especifica. Cada uma destas colunas é agregada. Por exemplo, na consulta anterior, isto significa que o valor da coluna store_number é agregado para mostrar previsões para cada valor de county, city e zip_code. Em separado, os valores de zip_code e store_number
também são agregados para mostrar previsões para cada valor de county e city.
A ordem das colunas é importante porque define a estrutura da hierarquia.
Siga estes passos para criar o modelo:
Use o modelo hierárquico para prever dados
Recupere dados de previsão hierárquica do modelo através da função ML.FORECAST.
Siga estes passos para prever dados com o modelo:
Limpar
Para evitar incorrer em custos na sua Google Cloud conta pelos recursos usados neste tutorial, elimine o projeto que contém os recursos ou mantenha o projeto e elimine os recursos individuais.
Elimine o conjunto de dados
A eliminação do projeto remove todos os conjuntos de dados e todas as tabelas no projeto. Se preferir reutilizar o projeto, pode eliminar o conjunto de dados que criou neste tutorial:
Elimine o projeto
Para eliminar o projeto: