Este tutorial ensina a usar um ARIMA_PLUSmodelo de série temporal univariado para prever o valor futuro de uma determinada coluna com base nos valores do histórico dessa coluna.
Este tutorial prevê um único intervalo temporal. Os valores previstos são calculados uma vez para cada ponto temporal nos dados de entrada.
Este tutorial usa dados da bigquery-public-data.google_analytics_sample.ga_sessionstabela de exemplo pública. Esta tabela contém dados de comércio eletrónico ocultos da Google Merchandise Store.
Crie um conjunto de dados
Crie um conjunto de dados do BigQuery para armazenar o seu modelo de ML.
Consola
Na Google Cloud consola, aceda à página BigQuery.
No painel Explorador, clique no nome do projeto.
Clique em Ver ações > Criar conjunto de dados
Na página Criar conjunto de dados, faça o seguinte:
Para o ID do conjunto de dados, introduza
bqml_tutorial.Em Tipo de localização, selecione Várias regiões e, de seguida, selecione EUA (várias regiões nos Estados Unidos).
Deixe as restantes predefinições como estão e clique em Criar conjunto de dados.
bq
Para criar um novo conjunto de dados, use o comando
bq mk
com a flag --location. Para uma lista completa de parâmetros possíveis, consulte a referência do comando bq mk --dataset.
Crie um conjunto de dados com o nome
bqml_tutorialcom a localização dos dados definida comoUSe uma descrição deBigQuery ML tutorial dataset:bq --location=US mk -d \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
Em vez de usar a flag
--dataset, o comando usa o atalho-d. Se omitir-de--dataset, o comando cria um conjunto de dados por predefinição.Confirme que o conjunto de dados foi criado:
bq ls
API
Chame o método datasets.insert
com um recurso de conjunto de dados definido.
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
DataFrames do BigQuery
Antes de experimentar este exemplo, siga as instruções de configuração dos DataFrames do BigQuery no início rápido do BigQuery com os DataFrames do BigQuery. Para mais informações, consulte a documentação de referência do BigQuery DataFrames.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure o ADC para um ambiente de desenvolvimento local.
Visualize os dados de entrada
Antes de criar o modelo, pode visualizar opcionalmente os dados de séries cronológicas de entrada para ter uma ideia da distribuição. Pode fazê-lo através do Looker Studio.
Siga estes passos para visualizar os dados de séries cronológicas:
SQL
Na consulta GoogleSQL seguinte, a declaração SELECT analisa a coluna date da tabela de entrada para o tipo TIMESTAMP, muda-lhe o nome para parsed_date e usa a cláusula SUM(...) e a cláusula GROUP BY date para criar um valor totals.visits diário.
Na Google Cloud consola, aceda à página BigQuery.
No editor de consultas, cole a seguinte consulta e clique em Executar:
SELECT PARSE_TIMESTAMP("%Y%m%d", date) AS parsed_date, SUM(totals.visits) AS total_visits FROM `bigquery-public-data.google_analytics_sample.ga_sessions_*` GROUP BY date;
Quando a consulta estiver concluída, clique em Explorar dados > Explorar com o Looker Studio. O Looker Studio é aberto num novo separador. Conclua os seguintes passos no novo separador.
No Looker Studio, clique em Inserir > Gráfico de intervalos temporais.
No painel Gráfico, escolha o separador Configuração.
Na secção Métrica, adicione o campo total_visits e remova a métrica Contagem de registos predefinida. O gráfico resultante tem um aspeto semelhante ao seguinte:
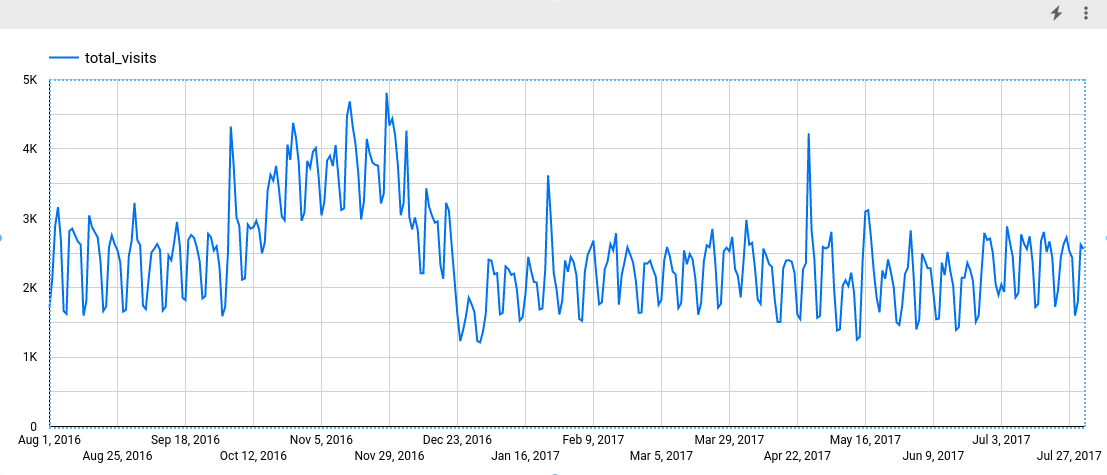
Ao analisar o gráfico, pode ver que a série cronológica de entrada tem um padrão sazonal semanal.
DataFrames do BigQuery
Antes de experimentar este exemplo, siga as instruções de configuração dos DataFrames do BigQuery no início rápido do BigQuery com os DataFrames do BigQuery. Para mais informações, consulte a documentação de referência do BigQuery DataFrames.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure o ADC para um ambiente de desenvolvimento local.
O resultado é semelhante ao seguinte:
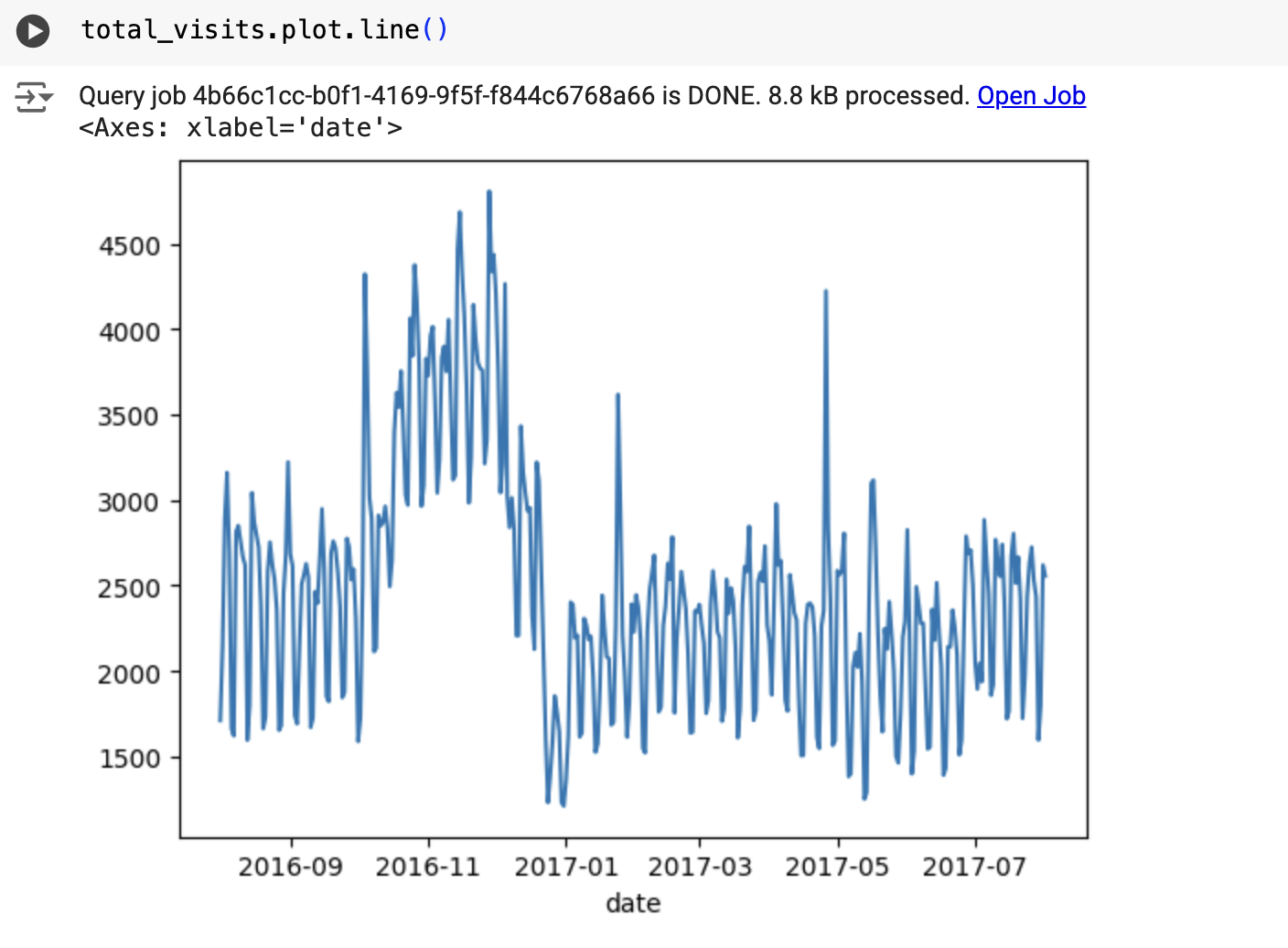
Crie o modelo de séries cronológicas
Crie um modelo de séries cronológicas para prever o total de visitas ao site, representado pela coluna totals.visits, e prepare-o com os dados do Google Analytics 360.
SQL
Na consulta seguinte, a cláusula
OPTIONS(model_type='ARIMA_PLUS', time_series_timestamp_col='date', ...)
indica que está a criar um modelo de série cronológica baseado em
ARIMA. A opção auto_arima da declaração CREATE MODEL tem como predefinição TRUE, pelo que o algoritmo auto.ARIMA
ajusta automaticamente os hiperparâmetros no modelo. O algoritmo
ajusta dezenas de modelos candidatos e escolhe o melhor modelo, que é o modelo
com o critério de informação de Akaike (AIC) mais baixo.
A opção
data_frequency
das declarações CREATE MODEL tem como predefinição AUTO_FREQUENCY, pelo que o processo de preparação infere automaticamente a frequência dos dados da série cronológica de entrada. A opção
decompose_time_series
da declaração CREATE MODEL tem como predefinição TRUE, para que as informações sobre os dados da série cronológica sejam devolvidas quando avaliar o modelo no passo seguinte.
Siga estes passos para criar o modelo:
Na Google Cloud consola, aceda à página BigQuery.
No editor de consultas, cole a seguinte consulta e clique em Executar:
CREATE OR REPLACE MODEL `bqml_tutorial.ga_arima_model` OPTIONS (model_type = 'ARIMA_PLUS', time_series_timestamp_col = 'parsed_date', time_series_data_col = 'total_visits', auto_arima = TRUE, data_frequency = 'AUTO_FREQUENCY', decompose_time_series = TRUE ) AS SELECT PARSE_TIMESTAMP("%Y%m%d", date) AS parsed_date, SUM(totals.visits) AS total_visits FROM `bigquery-public-data.google_analytics_sample.ga_sessions_*` GROUP BY date;
A consulta demora cerca de 4 segundos a ser concluída. Depois disso, pode aceder ao
ga_arima_modelmodelo. Uma vez que a consulta usa uma declaraçãoCREATE MODELpara criar um modelo, não vê os resultados da consulta.
DataFrames do BigQuery
Antes de experimentar este exemplo, siga as instruções de configuração dos DataFrames do BigQuery no início rápido do BigQuery com os DataFrames do BigQuery. Para mais informações, consulte a documentação de referência do BigQuery DataFrames.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure o ADC para um ambiente de desenvolvimento local.
Avalie os modelos candidatos
SQL
Avalie os modelos de séries cronológicas através da função ML.ARIMA_EVALUATE. A função ML.ARIMA_EVALUATE mostra as métricas de avaliação de todos os modelos candidatos avaliados durante o processo de otimização automática de hiperparâmetros.
Siga estes passos para avaliar o modelo:
Na Google Cloud consola, aceda à página BigQuery.
No editor de consultas, cole a seguinte consulta e clique em Executar:
SELECT * FROM ML.ARIMA_EVALUATE(MODEL `bqml_tutorial.ga_arima_model`);
Os resultados devem ter um aspeto semelhante ao seguinte:

DataFrames do BigQuery
Antes de experimentar este exemplo, siga as instruções de configuração dos DataFrames do BigQuery no início rápido do BigQuery com os DataFrames do BigQuery. Para mais informações, consulte a documentação de referência do BigQuery DataFrames.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure o ADC para um ambiente de desenvolvimento local.
As colunas de saída non_seasonal_p, non_seasonal_d, non_seasonal_q e has_drift
definem um modelo ARIMA no pipeline de preparação. As colunas de saída log_likelihood, AIC e variance são relevantes para o processo de ajuste do modelo ARIMA.
O algoritmo auto.ARIMA usa o
teste KPSS para determinar o melhor valor
para non_seasonal_d, que, neste caso, é 1. Quando non_seasonal_d é 1,
o algoritmo auto.ARIMA prepara 42 modelos ARIMA candidatos diferentes em paralelo.
Neste exemplo, todos os 42 modelos candidatos são válidos, pelo que a saída contém 42 linhas, uma para cada modelo ARIMA candidato. Nos casos em que alguns dos modelos não são válidos, são excluídos da saída. Estes modelos candidatos são devolvidos por ordem ascendente de AIC. O modelo na primeira linha tem o AIC mais baixo e é considerado o melhor modelo. O melhor modelo é guardado como o modelo final e é usado quando chama funções como ML.FORECAST no modelo
A coluna seasonal_periods contém informações sobre o padrão sazonal identificado nos dados de séries cronológicas. Não tem nada a ver com a modelagem ARIMA, pelo que tem o mesmo valor em todas as linhas de saída. Comunica um padrão semanal, o que concorda com os resultados que viu se optou por visualizar os dados de entrada.
As colunas has_holiday_effect, has_spikes_and_dips e has_step_changes
só são preenchidas quando decompose_time_series=TRUE. Estas colunas também refletem
informações sobre os dados de séries cronológicas de entrada e não estão relacionadas com a modelagem ARIMA. Estas colunas também têm os mesmos valores em todas as linhas de saída.
A coluna error_message mostra os erros ocorridos durante o processo de ajuste.auto.ARIMA Um dos motivos possíveis para os erros é quando as colunas non_seasonal_p, non_seasonal_d, non_seasonal_q e has_drift selecionadas não conseguem estabilizar a série cronológica. Para obter a mensagem de erro de todos os modelos candidatos, defina a opção show_all_candidate_models como TRUE quando criar o modelo.
Para mais informações sobre as colunas de saída, consulte a função ML.ARIMA_EVALUATE.
Inspecione os coeficientes do modelo
SQL
Inspeccione os coeficientes do modelo de séries cronológicas através da função ML.ARIMA_COEFFICIENTS.
Siga estes passos para obter os coeficientes do modelo:
Na Google Cloud consola, aceda à página BigQuery.
No editor de consultas, cole a seguinte consulta e clique em Executar:
SELECT * FROM ML.ARIMA_COEFFICIENTS(MODEL `bqml_tutorial.ga_arima_model`);
A coluna de saída ar_coefficients mostra os coeficientes do modelo da parte autorregressiva (AR) do modelo ARIMA. Da mesma forma, a coluna ma_coefficientsoutput mostra os coeficientes do modelo da parte de média móvel (MA) do modelo ARIMA. Ambas as colunas contêm valores de matriz, cujos comprimentos são iguais a non_seasonal_p e non_seasonal_q, respetivamente. No resultado da função ML.ARIMA_EVALUATE, viu que o melhor modelo tem um valor non_seasonal_p de 2 e um valor non_seasonal_q de 3. Por conseguinte, na saída ML.ARIMA_COEFFICIENTS, o valor ar_coefficients é uma matriz de 2 elementos e o valor ma_coefficients é uma matriz de 3 elementos. O valor intercept_or_drift é o termo constante no modelo ARIMA.
Para mais informações sobre as colunas de saída, consulte a função
ML.ARIMA_COEFFICIENTS.
DataFrames do BigQuery
Inspeccione os coeficientes do modelo de séries cronológicas através da função coef_.
Antes de experimentar este exemplo, siga as instruções de configuração dos DataFrames do BigQuery no início rápido do BigQuery com os DataFrames do BigQuery. Para mais informações, consulte a documentação de referência do BigQuery DataFrames.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure o ADC para um ambiente de desenvolvimento local.
A coluna de saída ar_coefficients mostra os coeficientes do modelo da parte autorregressiva (AR) do modelo ARIMA. Da mesma forma, a coluna ma_coefficientsoutput mostra os coeficientes do modelo da parte de média móvel (MA) do modelo ARIMA. Ambas as colunas contêm valores de matriz, cujos comprimentos são iguais a non_seasonal_p e non_seasonal_q, respetivamente.
Use o modelo para prever dados
SQL
Preveja valores de séries cronológicas futuras através da função ML.FORECAST.
Na consulta GoogleSQL seguinte, a cláusula STRUCT(30 AS horizon, 0.8 AS confidence_level)indica que a consulta prevê 30 pontos temporais futuros e gera um intervalo de previsão com um nível de confiança de 80%.
Siga estes passos para prever dados com o modelo:
Na Google Cloud consola, aceda à página BigQuery.
No editor de consultas, cole a seguinte consulta e clique em Executar:
SELECT * FROM ML.FORECAST(MODEL `bqml_tutorial.ga_arima_model`, STRUCT(30 AS horizon, 0.8 AS confidence_level));
Os resultados devem ter um aspeto semelhante ao seguinte:
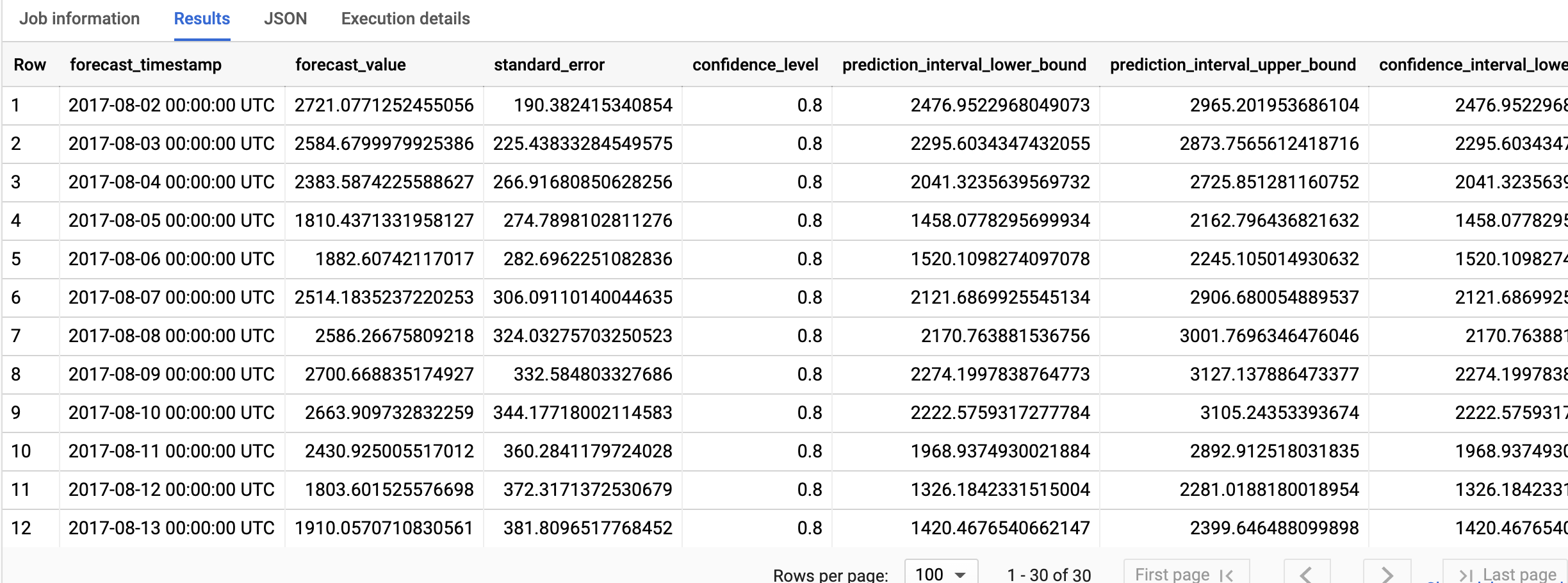
DataFrames do BigQuery
Preveja valores de séries cronológicas futuros através da função predict.
Antes de experimentar este exemplo, siga as instruções de configuração dos DataFrames do BigQuery no início rápido do BigQuery com os DataFrames do BigQuery. Para mais informações, consulte a documentação de referência do BigQuery DataFrames.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure o ADC para um ambiente de desenvolvimento local.
As linhas de saída estão por ordem cronológica do valor da coluna forecast_timestamp. Na previsão de séries cronológicas, o intervalo de previsão, representado pelos valores das colunas prediction_interval_lower_bound e prediction_interval_upper_bound, é tão importante quanto o valor da coluna forecast_value. O valor forecast_value é o ponto médio
do intervalo de previsão. O intervalo de previsão depende dos valores das colunas standard_error e confidence_level.
Para mais informações sobre as colunas de saída, consulte a função
ML.FORECAST.
Explicar os resultados da previsão
SQL
Pode obter métricas de explicabilidade, além dos dados de previsão, usando a função ML.EXPLAIN_FORECAST. A função ML.EXPLAIN_FORECAST prevê
valores de séries cronológicas futuras e também devolve todos os componentes separados das
séries cronológicas.
Semelhante à função ML.FORECAST, a cláusula STRUCT(30 AS horizon, 0.8 AS confidence_level) usada na função ML.EXPLAIN_FORECAST indica que a consulta prevê 30 pontos temporais futuros e gera um intervalo de previsão com 80% de confiança.
Siga estes passos para explicar os resultados do modelo:
Na Google Cloud consola, aceda à página BigQuery.
No editor de consultas, cole a seguinte consulta e clique em Executar:
SELECT * FROM ML.EXPLAIN_FORECAST(MODEL `bqml_tutorial.ga_arima_model`, STRUCT(30 AS horizon, 0.8 AS confidence_level));
Os resultados devem ter um aspeto semelhante ao seguinte:
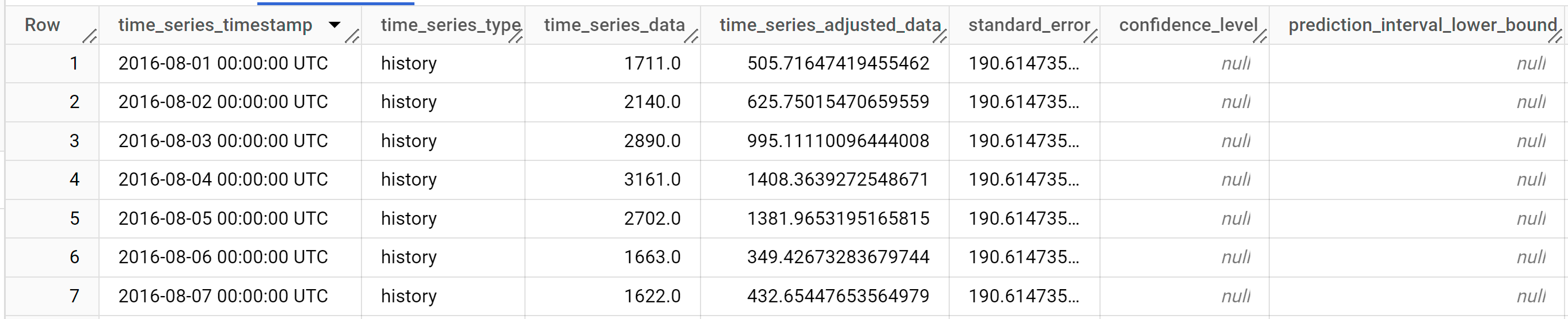
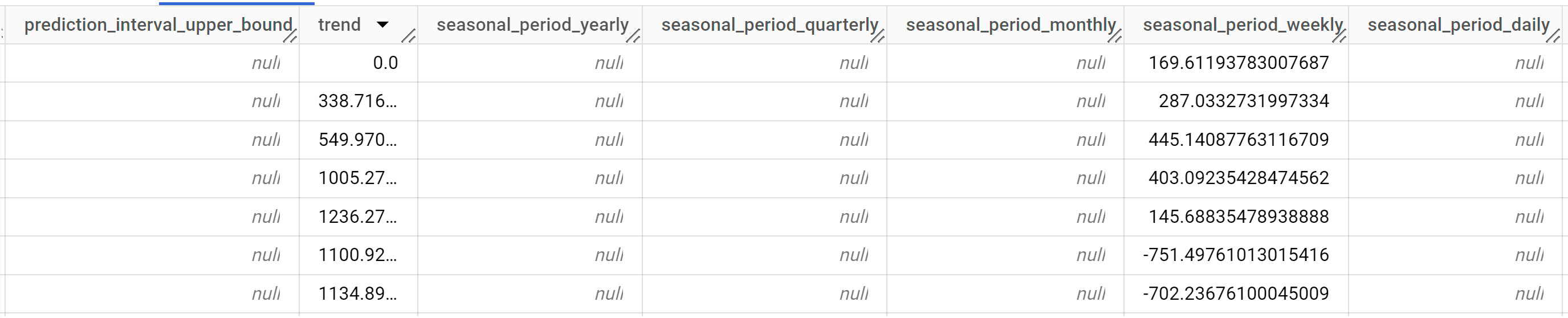
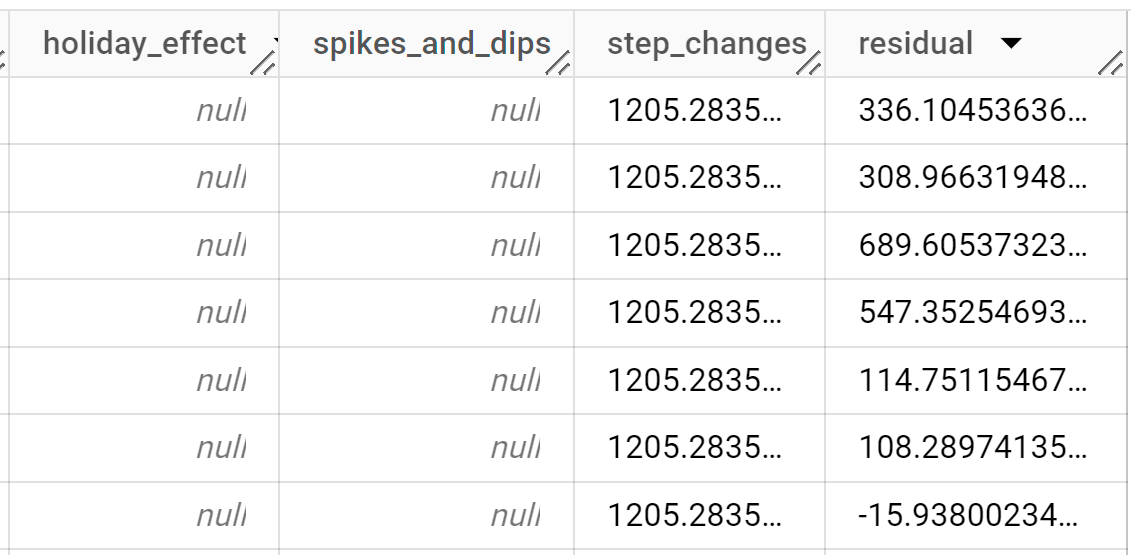
As linhas de saída são ordenadas cronologicamente pelo valor da coluna
time_series_timestamp.Para mais informações sobre as colunas de saída, consulte a função
ML.EXPLAIN_FORECAST.
DataFrames do BigQuery
Pode obter métricas de explicabilidade, além dos dados de previsão, usando a função predict_explain. A função predict_explain prevê
valores futuros de séries cronológicas e também devolve todos os componentes separados das
séries cronológicas.
Semelhante à função predict, a cláusula horizon=30, confidence_level=0.8 usada na função predict_explain indica que a consulta prevê 30 pontos temporais futuros e gera um intervalo de previsão com 80% de confiança.
Antes de experimentar este exemplo, siga as instruções de configuração dos DataFrames do BigQuery no início rápido do BigQuery com os DataFrames do BigQuery. Para mais informações, consulte a documentação de referência do BigQuery DataFrames.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure o ADC para um ambiente de desenvolvimento local.
Se quiser visualizar os resultados, pode usar o Looker Studio, conforme descrito na secção Visualize os dados de entrada para criar um gráfico com as seguintes colunas como métricas:
time_series_dataprediction_interval_lower_boundprediction_interval_upper_boundtrendseasonal_period_weeklystep_changes