在本教程中,您将学习如何使用 google_analytics_sample.ga_sessions 示例表创建一个时序模型,以进行单个时序预测。
ga_sessions 表包含由 Google Analytics 360 收集并发送到 BigQuery 的会话数据切片的相关信息。
目标
在本教程中,您将使用以下内容:
CREATE MODEL语句:用于创建一个时序模型。ML.ARIMA_EVALUATE函数:用于评估模型。ML.ARIMA_COEFFICIENTS函数:用于检查模型系数。ML.FORECAST函数:用于预测每日总访问次数。ML.EXPLAIN_FORECAST函数:用于检索时序的各个组件(例如季节性和趋势),可用于说明预测结果。- Looker 数据洞察:直观呈现预测结果。
费用
本教程使用 Google Cloud 的收费组件,包括以下组件:
- BigQuery
- BigQuery ML
如需详细了解 BigQuery 费用,请参阅 BigQuery 价格页面。
如需详细了解 BigQuery ML 费用,请参阅 BigQuery ML 价格。
准备工作
- 登录您的 Google Cloud 账号。如果您是 Google Cloud 新手,请创建一个账号来评估我们的产品在实际场景中的表现。新客户还可获享 $300 赠金,用于运行、测试和部署工作负载。
-
在 Google Cloud Console 中的项目选择器页面上,选择或创建一个 Google Cloud 项目。
-
在 Google Cloud Console 中的项目选择器页面上,选择或创建一个 Google Cloud 项目。
- 新项目会自动启用 BigQuery。如需在现有项目中激活 BigQuery,请转到
启用 BigQuery API。
第一步:创建数据集
创建 BigQuery 数据集以存储您的机器学习模型:
在 Google Cloud 控制台中,转到 BigQuery 页面。
在探索器窗格中,点击您的项目名称。
点击 查看操作 > 创建数据集。

在创建数据集页面上,执行以下操作:
在数据集 ID 部分,输入
bqml_tutorial。在位置类型部分,选择多区域,然后选择 US (multiple regions in United States)(美国[美国的多个区域])。
公共数据集存储在
US多区域中。为简单起见,请将数据集存储在同一位置。保持其余默认设置不变,然后点击创建数据集。

第二步(可选):直观呈现您要预测的时间序列
在创建模型之前,最好先查看输入时序的情况。您可以使用 Looker 数据洞察执行此操作。
在以下 GoogleSQL 查询中,FROM bigquery-public-data.google_analytics_sample.ga_sessions_* 子句指示您正在查询 google_analytics_sample 数据集中的 ga_sessions_* 表。这些表是分区表。
在 SELECT 语句中,查询将输入表中的 date 列解析为 TIMESTAMP 类型,并将其重命名为 parsed_date。该查询使用 SUM(...) 子句和 GROUP BY date 子句每天累积 totals.visits。
#standardSQL
SELECT
PARSE_TIMESTAMP("%Y%m%d", date) AS parsed_date,
SUM(totals.visits) AS total_visits
FROM
`bigquery-public-data.google_analytics_sample.ga_sessions_*`
GROUP BY date
如需运行查询,请按以下步骤操作:
在 Google Cloud 控制台中,点击编写新查询按钮。
在查询编辑器文本区域中输入以下 GoogleSQL 查询。
#standardSQL SELECT PARSE_TIMESTAMP("%Y%m%d", date) AS parsed_date, SUM(totals.visits) AS total_visits FROM `bigquery-public-data.google_analytics_sample.ga_sessions_*` GROUP BY date点击运行。
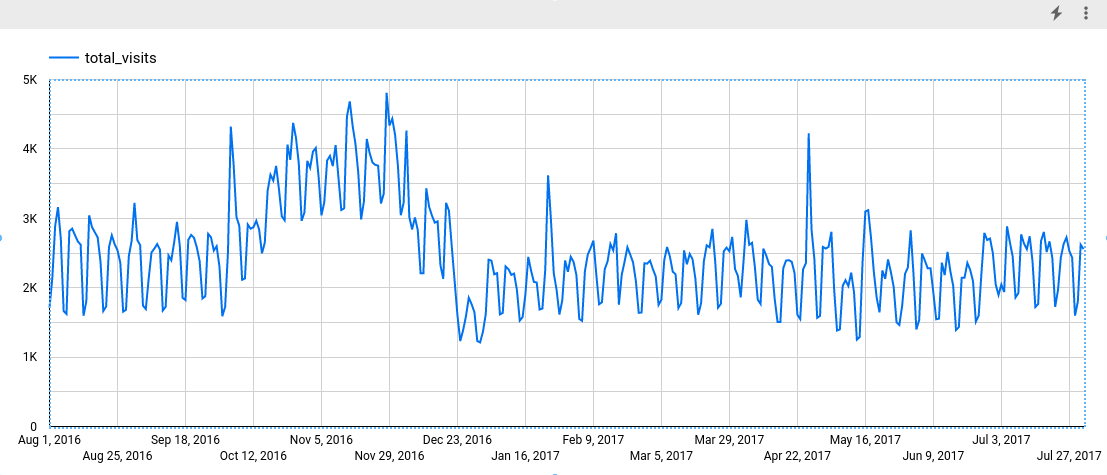
查询大约需要 7 秒才能完成。此查询运行后,输出类似于以下屏幕截图。在屏幕截图中,您可以看到此时序有 366 个数据点。点击探索数据按钮,然后点击 Explore with Looker Studio(使用 Looker 数据洞察探索)。Looker 数据洞察将在新标签页中打开。在该新标签页中完成以下步骤。
在图表面板中,选择时序图表 (Time series chart):
在数据面板中的图表面板下方,转到指标部分。添加 total_visits 字段,然后移除默认指标记录计数 (Record Count)。如下图所示。
完成这些步骤后,系统将显示以下图表。该图表显示输入时序具有每周的季节性模式。
第三步:创建时序模型
接下来,使用 Google Analytics(分析)360 数据创建一个时序模型。
以下 GoogleSQL 查询会创建一个用于预测 totals.visits 的模型。
CREATE MODEL 子句将创建并训练一个名为 bqml_tutorial.ga_arima_model 的模型。
#standardSQL
CREATE OR REPLACE MODEL `bqml_tutorial.ga_arima_model`
OPTIONS
(model_type = 'ARIMA_PLUS',
time_series_timestamp_col = 'parsed_date',
time_series_data_col = 'total_visits',
auto_arima = TRUE,
data_frequency = 'AUTO_FREQUENCY',
decompose_time_series = TRUE
) AS
SELECT
PARSE_TIMESTAMP("%Y%m%d", date) AS parsed_date,
SUM(totals.visits) AS total_visits
FROM
`bigquery-public-data.google_analytics_sample.ga_sessions_*`
GROUP BY date
OPTIONS(model_type='ARIMA_PLUS', time_series_timestamp_col='date', ...) 子句指示您正在创建一个基于 ARIMA 的时序模型。默认情况下,auto_arima=TRUE,因此 auto.ARIMA 算法会自动调整 ARIMA_PLUS 模型中的超参数。该算法适合数十个候选模型,选择具有最低 Akaike 信息标准 (AIC) 的模型。此外,由于默认设置为 data_frequency='AUTO_FREQUENCY',因此训练过程会自动推断输入时序的数据频率。最后,CREATE MODEL 语句默认使用 decompose_time_series=TRUE,用户也可以通过获取单独的时序组件(例如季节性和节假日效应)来进一步了解如何预测时序。
运行 CREATE MODEL 查询以创建并训练模型:
在 Google Cloud 控制台中,点击编写新查询按钮。
在查询编辑器文本区域中输入以下 GoogleSQL 查询。
#standardSQL CREATE OR REPLACE MODEL `bqml_tutorial.ga_arima_model` OPTIONS (model_type = 'ARIMA_PLUS', time_series_timestamp_col = 'parsed_date', time_series_data_col = 'total_visits', auto_arima = TRUE, data_frequency = 'AUTO_FREQUENCY', decompose_time_series = TRUE ) AS SELECT PARSE_TIMESTAMP("%Y%m%d", date) AS parsed_date, SUM(totals.visits) AS total_visits FROM `bigquery-public-data.google_analytics_sample.ga_sessions_*` GROUP BY date点击运行。
查询大约需要 43 秒才能完成,之后您的模型 (
ga_arima_model) 会显示在导航面板中。由于查询使用CREATE MODEL语句来创建模型,因此您看不到查询结果。
第四步:检查所有评估模型的评估指标
创建模型后,您可以使用 ML.ARIMA_EVALUATE 函数查看自动超参数调整过程中评估的所有候选模型的评估指标。
在以下 GoogleSQL 查询中,FROM 子句对模型 bqml_tutorial.ga_arima_model 使用 ML.ARIMA_EVALUATE 函数。默认情况下,此查询会返回所有候选模型的评估指标。
如需运行 ML.ARIMA_EVALUATE 查询,请按以下步骤操作:
在 Google Cloud 控制台中,点击编写新查询按钮。
在查询编辑器文本区域中输入以下 GoogleSQL 查询。
#standardSQL SELECT * FROM ML.ARIMA_EVALUATE(MODEL `bqml_tutorial.ga_arima_model`)
点击运行。
查询只需不到一秒的时间即可完成。查询完成后,点击查询文本区域下方的结果标签页。结果应类似于以下屏幕截图:

结果包括以下列:
non_seasonal_pnon_seasonal_dnon_seasonal_qhas_driftlog_likelihoodAICvarianceseasonal_periodshas_holiday_effecthas_spikes_and_dipshas_step_changeserror_message
以下四列(
non_seasonal_{p,d,q}和has_drift)定义了训练流水线中的 ARIMA 模型。后面的三个指标(log_likelihood、AIC、variance)与 ARIMA 模型拟合过程相关。auto.ARIMA算法首先使用 KPSS 测试来确定non_seasonal_d的最佳值为 1。当non_seasonal_d为 1 时,auto.ARIMA 会并行训练 42 个不同的候选 ARIMA 模型。请注意,当non_seasonal_d不为 1 时,auto.ARIMA 会训练 21 个不同的候选模型。在此示例中,所有 42 个候选模型均有效。因此,输出将包含 42 行,其中每行都与一个候选 ARIMA 模型相关联。请注意,对于某些时序,某些候选模型是无效的,因为它们不可逆或不固定。这些无效的模型会从输出中排除,这将使输出少于 42 行。这些候选模型将按照 AIC 升序排序。第一行中的模型具有最低的 AIC,它被视为最佳模型。此最佳模型将保存为最终模型,并在您调用ML.EXPLAIN_FORECAST、ML.FORECAST和ML.ARIMA_COEFFICIENTS时使用,如以下步骤所示。seasonal_periods列是关于输入时序内的季节性模式。它与 ARIMA 建模无关,因此在所有输出行中都具有相同的值。它会报告每周模式,这与我们在上面的第二步中所述的情况一致。仅当
decompose_time_series=TRUE时,才会填充has_holiday_effect、has_spikes_and_dips和has_step_changes列。它们与输入时序中的节假日效应、高峰期和低谷期以及步进变化有关,与 ARIMA 建模无关。因此,除这些失败模型外,它们在所有输出行中都是相同的。error_message列显示auto.ARIMA拟合过程中可能发生的错误。可能的原因是所选non_seasonal_p、non_seasonal_d、non_seasonal_q和has_drift列无法稳定时序。如需检索所有候选模型的可能错误消息,请设置show_all_candidate_models=true。
第五步:检查模型的系数
ML.ARIMA_COEFFICIENTS 函数会检索 ARIMA_PLUS 模型 bqml_tutorial.ga_arima_model 的模型系数。ML.ARIMA_COEFFICIENTS 接受该模型作为唯一输入。
运行 ML.ARIMA_COEFFICIENTS 查询:
在 Google Cloud 控制台中,点击编写新查询按钮。
在查询编辑器文本区域中输入以下 GoogleSQL 查询。
#standardSQL SELECT * FROM ML.ARIMA_COEFFICIENTS(MODEL `bqml_tutorial.ga_arima_model`)
点击运行。
查询只需不到一秒的时间即可完成。结果应如下所示:

结果包括以下列:
ar_coefficientsma_coefficientsintercept_or_drift
ar_coefficients显示了 ARIMA 模型的自动回归 (AR) 部分的模型系数。同样,ma_coefficients显示了移动平均 (MA) 部分的模型系数。它们都是数组,其长度分别等于non_seasonal_p和non_seasonal_q。在ML.ARIMA_EVALUATE的输出中,最上面一行的最佳模型的non_seasonal_p为 2,non_seasonal_q为 3。因此,ar_coefficients是长度为 2 的数组,ma_coefficients是长度为 3 的数组。intercept_or_drift是 ARIMA 模型中的常量项。
第六步:使用模型预测时序
ML.FORECAST 函数使用模型 bqml_tutorial.ga_arima_model 预测未来的时序值以及预测区间。
在以下 GoogleSQL 查询中,STRUCT(30 AS horizon, 0.8 AS confidence_level) 子句指示查询会预测 30 个未来的时间点,并生成置信度为 80% 的预测区间。ML.FORECAST 采用该模型以及几个可选的参数。
如需运行 ML.FORECAST 查询,请按以下步骤操作:
在 Google Cloud 控制台中,点击编写新查询按钮。
在查询编辑器文本区域中输入以下 GoogleSQL 查询。
#standardSQL SELECT * FROM ML.FORECAST(MODEL `bqml_tutorial.ga_arima_model`, STRUCT(30 AS horizon, 0.8 AS confidence_level))点击运行。
查询只需不到一秒的时间即可完成。结果应如下所示:
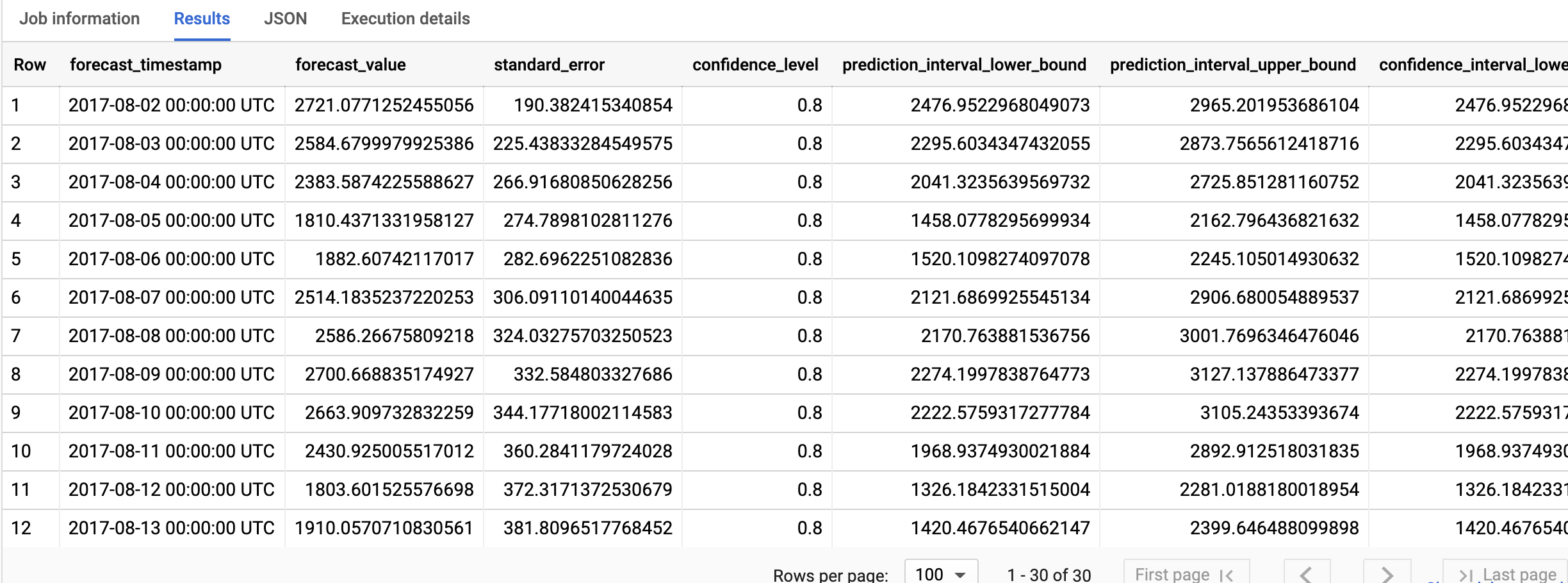
结果包括以下列:
forecast_timestampforecast_valuestandard_errorconfidence_levelprediction_interval_lower_boundprediction_interval_upper_boundconfidence_interval_lower_bound(即将弃用)confidence_interval_upper_bound(即将弃用)
输出行将按照
forecast_timestamp的时间顺序排序。在时序预测中,由下限和上限捕获的预测区间与forecast_value一样重要。forecast_value是预测区间的中点。预测区间取决于standard_error和confidence_level。
第七步:说明和直观呈现预测结果
若要了解时序的预测方式,以及直观呈现预测的时序以及历史时序和所有独立组件,ML.EXPLAIN_FORECAST 函数会使用模型 bqml_tutorial.ga_arima_model 预测未来的时序值以及预测间隔,同时返回该时序的所有单独的组件。
与 ML.FORECAST 函数一样,STRUCT(30 AS horizon, 0.8 AS confidence_level) 子句指示查询预测 30 个未来的时间点,并生成置信度为 80% 的预测区间。ML.EXPLAIN_FORECAST 函数采用该模型以及几个可选的参数。
如需运行 ML.EXPLAIN_FORECAST 查询,请按以下步骤操作:
在 Google Cloud 控制台中,点击编写新查询按钮。
在查询编辑器文本区域中输入以下 GoogleSQL 查询。
#standardSQL SELECT * FROM ML.EXPLAIN_FORECAST(MODEL `bqml_tutorial.ga_arima_model`, STRUCT(30 AS horizon, 0.8 AS confidence_level))点击运行。
查询只需不到一秒的时间即可完成。结果应如下所示:
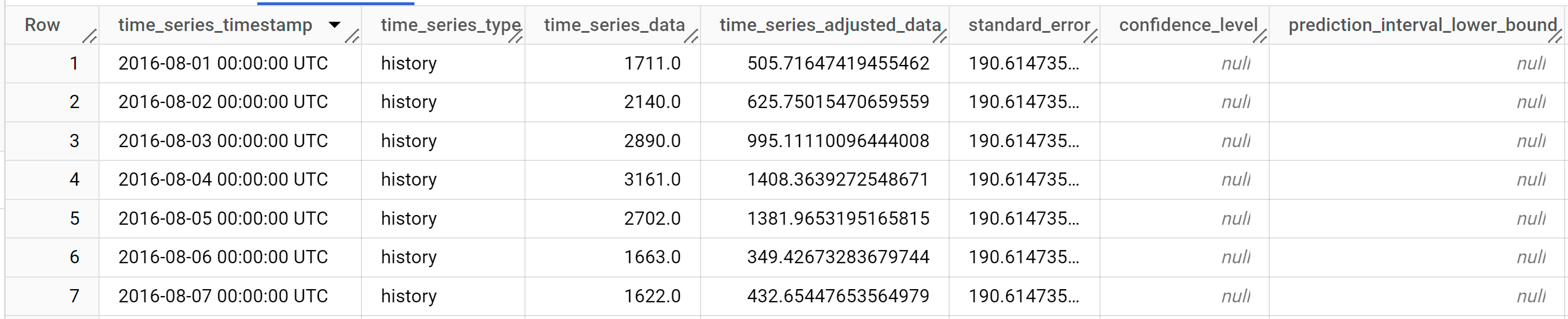
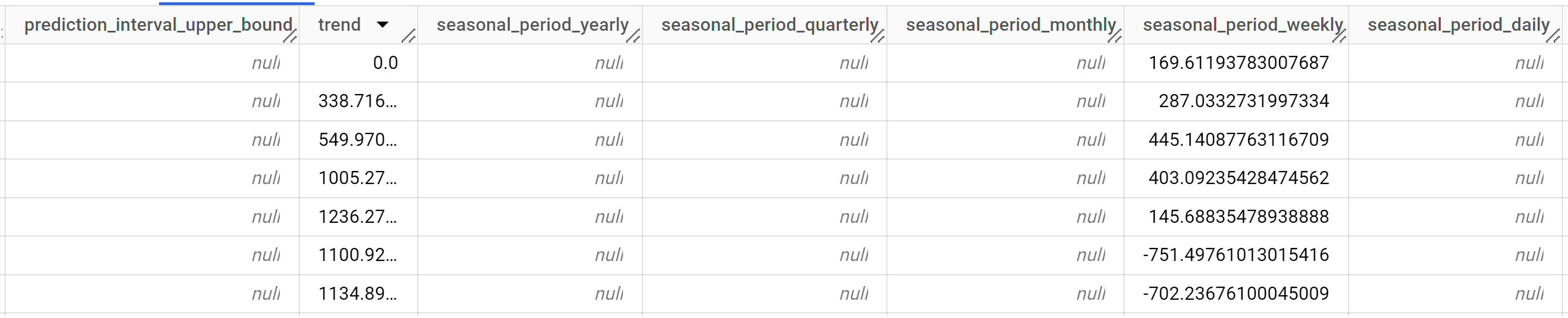
结果包括以下列:
time_series_timestamptime_series_typetime_series_datatime_series_adjusted_datastandard_errorconfidence_levelprediction_interval_lower_boundprediction_interval_lower_boundtrendseasonal_period_yearlyseasonal_period_quarterlyseasonal_period_monthlyseasonal_period_weeklyseasonal_period_dailyholiday_effectspikes_and_dipsstep_changesresidual
输出行将按照
time_series_timestamp的时间顺序排序。不同的组件以不同输出列的形式列出。如需了解详情,请参阅ML.EXPLAIN_FORECAST的定义。查询完成后,点击探索数据按钮,然后点击 Explore with Looker Studio(使用 Looker 数据洞察探索)。Looker 数据洞察将在新标签页中打开。
在图表面板中,选择时序图表 (Time series chart):
在数据面板中,执行以下操作:
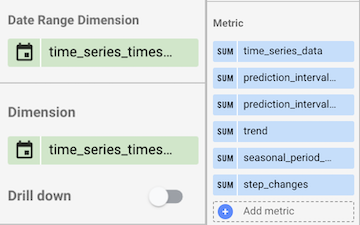
- 在日期范围维度部分中,选择
time_series_timestamp (Date)。 - 在维度部分中,选择
time_series_timestamp (Date)。 - 在指标部分中,移除默认指标
Record Count,并添加以下内容:time_series_dataprediction_interval_lower_boundprediction_interval_upper_boundtrendseasonal_period_weeklystep_changes
- 在日期范围维度部分中,选择
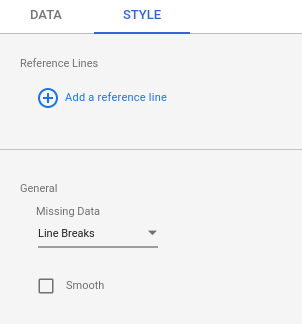
在样式面板中,向下滚动到缺失数据选项,然后使用换行符,而不是换行到零。
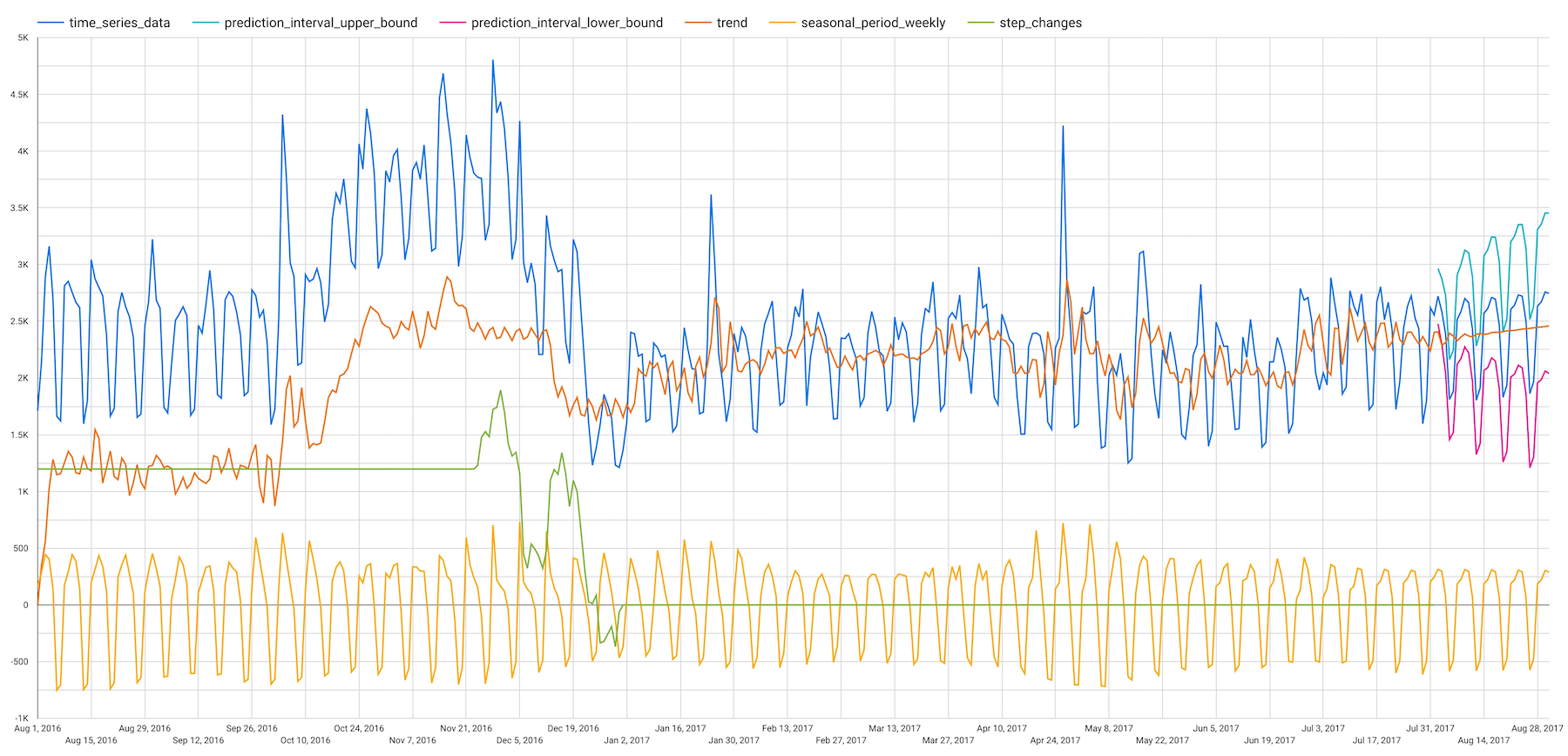
此时将显示以下绘图:
第八步(可选):在不启用 decompose_time_series 的情况下直观呈现预测结果
如果在 ARIMA_PLUS 训练中将 decompose_time_series 设置为 false,则可以使用 UNION ALL 子句和 ML.FORECAST 函数将历史时序和预测的时序连接起来。
在以下查询中,UNION ALL 子句之前的 SQL 会生成历史记录时序。UNION ALL 子句之后的 SQL 会使用 ML.FORECAST 函数生成预测的时序以及预测间隔。该查询对 history_value 和 forecasted_value 使用不同的字段,以不同颜色绘制它们。
如需运行查询,请按以下步骤操作:
在 Google Cloud 控制台中,点击编写新查询按钮。
在查询编辑器文本区域中输入以下 GoogleSQL 查询。
#standardSQL SELECT history_timestamp AS timestamp, history_value, NULL AS forecast_value, NULL AS prediction_interval_lower_bound, NULL AS prediction_interval_upper_bound FROM ( SELECT PARSE_TIMESTAMP("%Y%m%d", date) AS history_timestamp, SUM(totals.visits) AS history_value FROM `bigquery-public-data.google_analytics_sample.ga_sessions_*` GROUP BY date ORDER BY date ASC ) UNION ALL SELECT forecast_timestamp AS timestamp, NULL AS history_value, forecast_value, prediction_interval_lower_bound, prediction_interval_upper_bound FROM ML.FORECAST(MODEL `bqml_tutorial.ga_arima_model`, STRUCT(30 AS horizon, 0.8 AS confidence_level))点击运行。
查询完成后,点击探索数据按钮,然后点击 Explore with Looker Studio(使用 Looker 数据洞察探索)。Looker 数据洞察将在新标签页中打开。在该新标签页中完成以下步骤。
在图表面板中,选择时序图表 (Time series chart):
在数据面板中的图表面板下方,转到指标部分。添加以下指标:
history_value、forecast_value、prediction_interval_lower_bound、prediction_interval_upper_bound。然后,移除默认指标Record Count。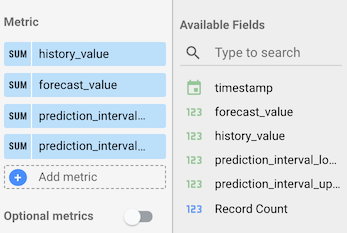
在样式 (Style) 面板中,向下滚动到缺失数据选项,然后使用换行符 (Line Breaks),而不是换行到零 (Line to Zero)。
完成这些步骤后,左侧面板中将显示以下图表。输入历史记录时序为蓝色,而预测的序列为绿色。预测区间是下限序列和上限序列之间的区域。
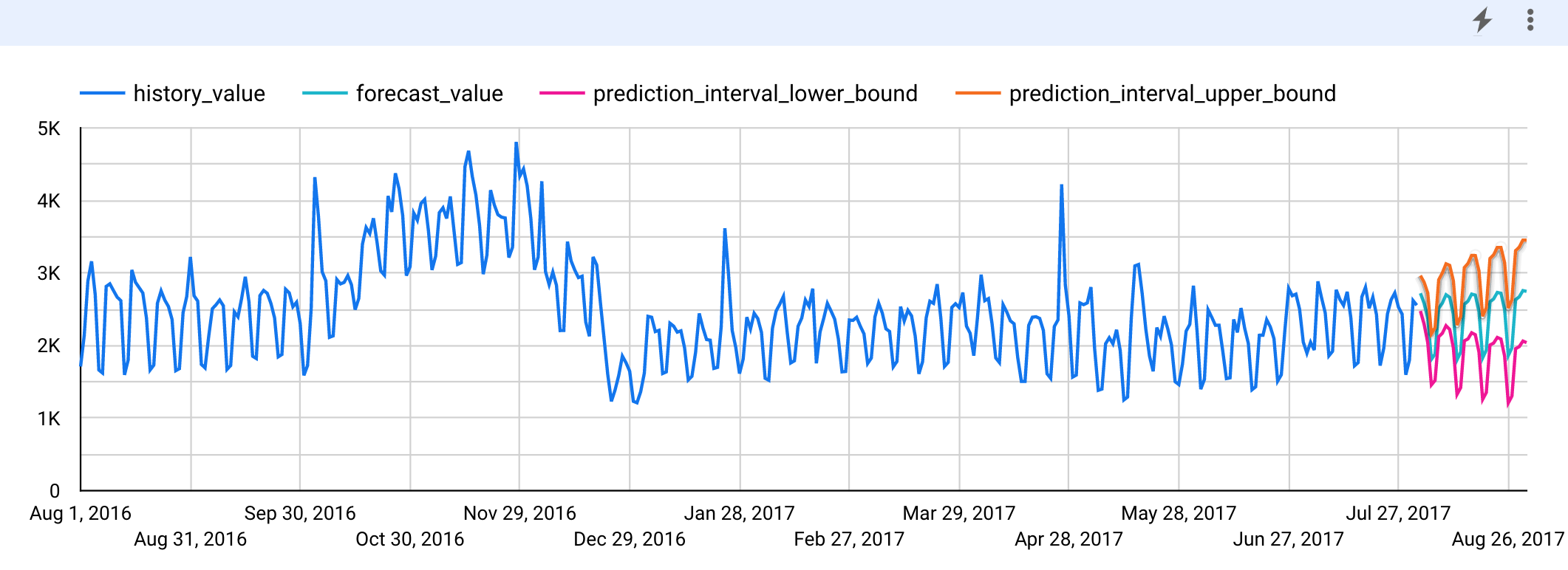
清除数据
为避免因本教程中使用的资源导致您的 Google Cloud 账号产生费用,请删除包含这些资源的项目,或者保留项目但删除各个资源。
- 删除您在教程中创建的项目。
- 或者,保留项目但删除数据集。
删除数据集
删除项目也将删除项目中的所有数据集和所有表。如果您希望重复使用该项目,则可以删除在本教程中创建的数据集:
如有必要,请在 Google Cloud 控制台中打开 BigQuery 页面。
在导航窗格中,点击您创建的 bqml_tutorial 数据集。
点击窗口右侧的删除数据集。此操作会删除相关数据集、表和所有数据。
在删除数据集对话框中,输入您的数据集的名称 (
bqml_tutorial),然后点击删除以确认删除命令。
删除项目
要删除项目,请执行以下操作:
- 在 Google Cloud 控制台中,进入管理资源页面。
- 在项目列表中,选择要删除的项目,然后点击删除。
- 在对话框中输入项目 ID,然后点击关闭以删除项目。
后续步骤
- 了解如何使用纽约市花旗单车行程数据的单一查询进行多时序预测
- 了解如何加速 ARIMA_PLUS 以在数小时内预测一百万个时序。
- 要详细了解机器学习,请参阅机器学习速成课程。
- 如需大致了解 BigQuery ML,请参阅 BigQuery ML 简介。
- 如需详细了解 Google Cloud 控制台,请参阅使用 Google Cloud 控制台。