本教程介绍了如何使用 ARIMA_PLUS 单变量时序模型根据给定列的历史值来预测该列的未来值。
本教程将介绍如何预测多个时序。系统会针对每个时间点,为一个或多个指定列中的每个值计算预测值。例如,如果您想预测天气并指定了一个包含城市数据的列,则预测数据会包含城市 A 在所有时间点的预测值,然后是城市 B 在所有时间点的预测值,依此类推。
本教程使用来自公开的 bigquery-public-data.new_york.citibike_trips 表中的数据。此表包含有关纽约市花旗单车行程的信息。
在阅读本教程之前,我们强烈建议您阅读使用单变量模型预测单个时序。
创建数据集
创建 BigQuery 数据集以存储机器学习模型。
控制台
在 Google Cloud 控制台中,前往 BigQuery 页面。
在探索器窗格中,点击您的项目名称。
点击 查看操作 > 创建数据集
在 创建数据集 页面上,执行以下操作:
在数据集 ID 部分,输入
bqml_tutorial。在位置类型部分,选择多区域,然后选择 US (multiple regions in United States)(美国[美国的多个区域])。
保持其余默认设置不变,然后点击创建数据集。
bq
如需创建新数据集,请使用带有 --location 标志的 bq mk 命令。 如需查看完整的潜在参数列表,请参阅 bq mk --dataset 命令参考文档。
创建一个名为
bqml_tutorial的数据集,并将数据位置设置为US,说明为BigQuery ML tutorial dataset:bq --location=US mk -d \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
该命令使用的不是
--dataset标志,而是-d快捷方式。如果省略-d和--dataset,该命令会默认创建一个数据集。确认已创建数据集:
bq ls
API
使用已定义的数据集资源调用 datasets.insert 方法。
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
BigQuery DataFrame
在尝试此示例之前,请按照《BigQuery 快速入门:使用 BigQuery DataFrames》中的 BigQuery DataFrames 设置说明进行操作。如需了解详情,请参阅 BigQuery DataFrames 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为本地开发环境设置 ADC。
直观呈现输入数据
在创建模型之前,您可以选择直观呈现输入时序数据,以了解分布情况。您可以使用 Looker Studio 执行此操作。
SQL
以下查询的 SELECT 语句使用 EXTRACT 函数从 starttime 列中提取日期信息。该查询使用 COUNT(*) 子句获取花旗单车的每日总行程数。
请按照以下步骤直观呈现时序数据:
在 Google Cloud 控制台中,前往 BigQuery 页面。
在查询编辑器中,粘贴以下查询,然后点击运行:
SELECT EXTRACT(DATE from starttime) AS date, COUNT(*) AS num_trips FROM `bigquery-public-data.new_york.citibike_trips` GROUP BY date;
查询完成后,依次点击探索数据 > 使用 Looker Studio 探索。Looker Studio 将在新标签页中打开。在该新标签页中完成以下步骤。
在 Looker Studio 中,依次点击插入 > 时序图表。
在图表窗格中,选择设置标签页。
在指标部分,添加 num_trips 字段,并移除默认的记录数指标。生成的图表如下所示:
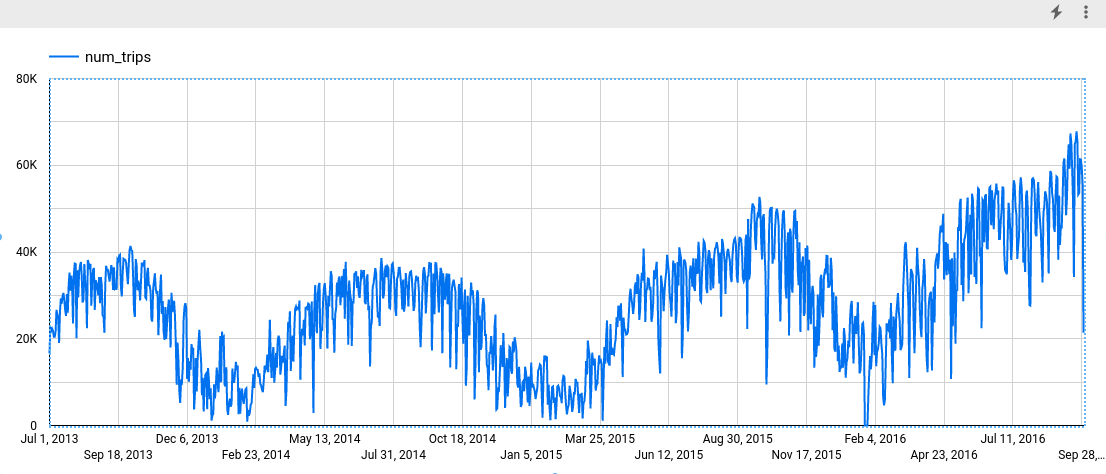
BigQuery DataFrame
在尝试此示例之前,请按照《BigQuery 快速入门:使用 BigQuery DataFrames》中的 BigQuery DataFrames 设置说明进行操作。如需了解详情,请参阅 BigQuery DataFrames 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为本地开发环境设置 ADC。
创建时序模型
您希望预测每个花旗单车站点的单车行程数,这需要使用多个时序模型;输入数据中包含的每个花旗单车站点都需要一个模型。您可以创建多个模型来实现此目的,但这可能会是一个单调乏味且耗时的过程,尤其是当您有大量时序时。您可以改为使用单个查询来创建和拟合一组时序模型,以便一次预测多个时序。
SQL
在以下查询中,OPTIONS(model_type='ARIMA_PLUS', time_series_timestamp_col='date', ...) 子句指示您正在创建一个基于 ARIMA 的时序模型。您可以使用 CREATE MODEL 语句的 time_series_id_col 选项来指定输入数据中要获取预测结果的一个或多个列,在本例中为花旗单车站点,由 start_station_name 列表示。您可以使用 WHERE 子句将起始站点限定为名称中包含 Central Park 的站点。CREATE MODEL 语句的 auto_arima_max_order 选项可控制 auto.ARIMA 算法中用于超参数调优的搜索空间。CREATE MODEL 语句的 decompose_time_series 选项默认为 TRUE,以便在您在下一步中评估模型时返回有关时序数据的信息。
请按照以下步骤创建模型:
在 Google Cloud 控制台中,前往 BigQuery 页面。
在查询编辑器中,粘贴以下查询,然后点击运行:
CREATE OR REPLACE MODEL `bqml_tutorial.nyc_citibike_arima_model_group` OPTIONS (model_type = 'ARIMA_PLUS', time_series_timestamp_col = 'date', time_series_data_col = 'num_trips', time_series_id_col = 'start_station_name', auto_arima_max_order = 5 ) AS SELECT start_station_name, EXTRACT(DATE from starttime) AS date, COUNT(*) AS num_trips FROM `bigquery-public-data.new_york.citibike_trips` WHERE start_station_name LIKE '%Central Park%' GROUP BY start_station_name, date;
查询大约需要 24 秒才能完成,之后您就可以访问
nyc_citibike_arima_model_group模型了。由于查询使用CREATE MODEL语句,因此您看不到查询结果。
此查询将创建 12 个时序模型,输入数据中的 12 个花旗单车起始站点各自对应一个模型。由于是并行执行,因此时间成本(大约 24 秒)只是创建单个时序模型的时间成本的 1.4 倍。但是,如果您移除 WHERE ... LIKE ... 子句,则系统将预测 600 多个时序;由于槽容量有限,系统将无法完全并行预测这些时序。在这种情况下,查询大约需要 15 分钟才能完成。如需减少查询运行时间,同时接受可能出现的模型质量略微下降,您可以降低 auto_arima_max_order 的值。这会缩小 auto.ARIMA 算法中超参数调优的搜索空间。如需了解详情,请参阅 Large-scale time series forecasting best practices。
BigQuery DataFrame
在以下代码段中,您在创建一个基于 ARIMA 的时序模型。
在尝试此示例之前,请按照《BigQuery 快速入门:使用 BigQuery DataFrames》中的 BigQuery DataFrames 设置说明进行操作。如需了解详情,请参阅 BigQuery DataFrames 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为本地开发环境设置 ADC。
这会创建 12 个时序模型,输入数据中的 12 个花旗单车起始站点各自对应一个模型。由于是并行执行,因此时间成本(大约 24 秒)只是创建单个时序模型的时间成本的 1.4 倍。
评估模型
SQL
使用 ML.ARIMA_EVALUATE 函数评估时序模型。ML.ARIMA_EVALUATE 函数会显示在自动超参数调优过程中为模型生成的评估指标。
请按照以下步骤评估模型:
在 Google Cloud 控制台中,前往 BigQuery 页面。
在查询编辑器中,粘贴以下查询,然后点击运行:
SELECT * FROM ML.ARIMA_EVALUATE(MODEL `bqml_tutorial.nyc_citibike_arima_model_group`);
结果应如下所示:
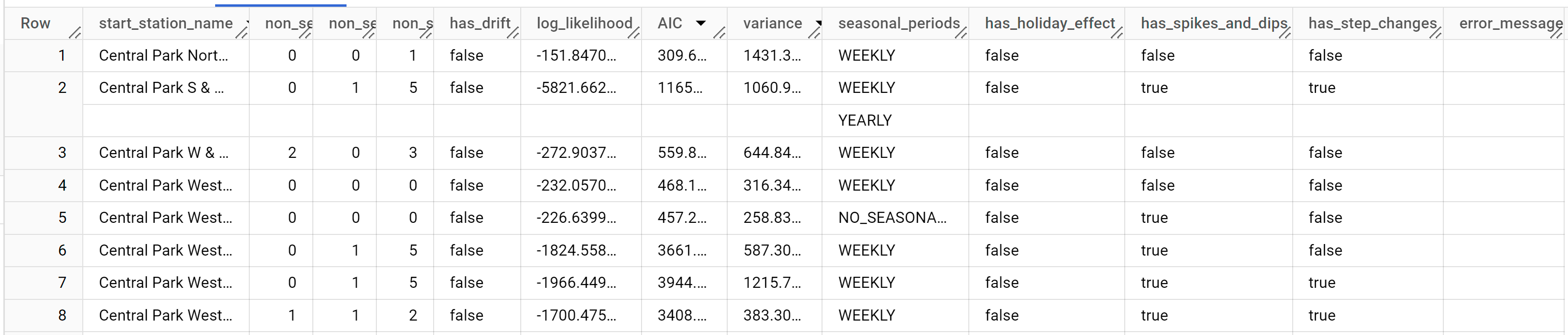
虽然
auto.ARIMA会为每个时序评估几十个候选 ARIMA 模型,但ML.ARIMA_EVALUATE默认只会输出最佳模型的信息,以便使输出表紧凑。如需查看所有候选模型,您可以将ML.ARIMA_EVALUATE函数的show_all_candidate_model参数设置为TRUE。
BigQuery DataFrame
在尝试此示例之前,请按照《BigQuery 快速入门:使用 BigQuery DataFrames》中的 BigQuery DataFrames 设置说明进行操作。如需了解详情,请参阅 BigQuery DataFrames 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为本地开发环境设置 ADC。
start_station_name 列用于标识针对其创建时序的输入数据列。这是您在创建模型时使用 time_series_id_col 选项指定的列。
non_seasonal_p、non_seasonal_d、non_seasonal_q 和 has_drift 输出列定义了训练流水线中的 ARIMA 模型。log_likelihood、AIC 和 variance 输出列与 ARIMA 模型拟合过程相关。拟合过程使用 auto.ARIMA 算法确定最佳 ARIMA 模型(每个时序对应一个最佳模型)。
auto.ARIMA 算法使用 KPSS 测试来确定 non_seasonal_d 的最佳值,在本例中为 1。当 non_seasonal_d 为 1 时,auto.ARIMA 算法会并行训练 42 个不同的候选 ARIMA 模型。在此示例中,所有 42 个候选模型均有效,因此输出包含 42 行,每行对应一个候选 ARIMA 模型;如果某些模型无效,则会从输出中排除。这些候选模型将按照 AIC 升序返回。第一行中的模型具有最低的 AIC,它被视为最佳模型。此最佳模型将保存为最终模型,并在您预测数据、评估模型和检查模型系数时使用,如以下步骤所示。
seasonal_periods 列包含有关时序数据中识别出的季节性模式的信息。每个时序可以有不同的季节性模式。例如,您可以从图中看到一个时序具有一个每年模式,而其他时序则没有。
仅当 decompose_time_series=TRUE 时,才会填充 has_holiday_effect、has_spikes_and_dips 和 has_step_changes 列。这些列还反映了输入时序数据的信息,与 ARIMA 建模无关。这些列在所有输出行中也具有相同的值。
检查模型的系数
SQL
使用 ML.ARIMA_COEFFICIENTS 函数检查时序模型的系数。
请按照以下步骤检索模型的系数:
在 Google Cloud 控制台中,前往 BigQuery 页面。
在查询编辑器中,粘贴以下查询,然后点击运行:
SELECT * FROM ML.ARIMA_COEFFICIENTS(MODEL `bqml_tutorial.nyc_citibike_arima_model_group`);
查询只需不到一秒的时间即可完成。结果应如下所示:
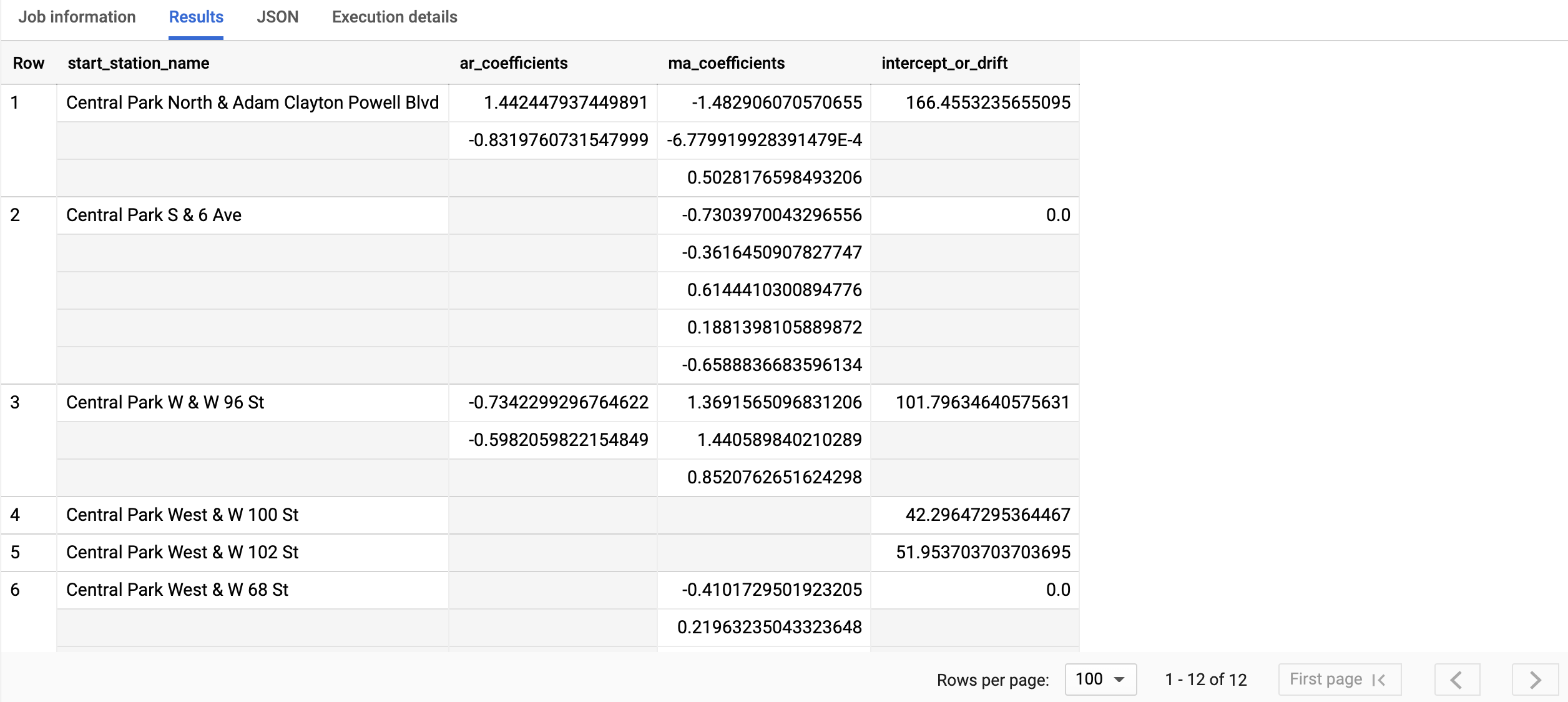
如需详细了解输出列,请参阅
ML.ARIMA_COEFFICIENTS函数。
BigQuery DataFrame
使用 coef_ 函数检查时序模型的系数。
在尝试此示例之前,请按照《BigQuery 快速入门:使用 BigQuery DataFrames》中的 BigQuery DataFrames 设置说明进行操作。如需了解详情,请参阅 BigQuery DataFrames 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为本地开发环境设置 ADC。
start_station_name 列用于标识针对其创建时序的输入数据列。这是您在创建模型时在 time_series_id_col 选项中指定的列。
ar_coefficients 输出列显示了 ARIMA 模型的自动回归 (AR) 部分的模型系数。同样,ma_coefficients 输出列显示了 ARIMA 模型的移动平均值 (MA) 部分的模型系数。这两个列都包含数组值,其长度分别等于 non_seasonal_p 和 non_seasonal_q。intercept_or_drift 值是 ARIMA 模型中的常量项。
使用模型预测数据
SQL
使用 ML.FORECAST 函数预测未来的时序值。
在以下 GoogleSQL 查询中,STRUCT(3 AS horizon, 0.9 AS confidence_level) 子句指示查询会预测 3 个未来的时间点,并生成置信度为 90% 的预测区间。
请按照以下步骤使用模型预测数据:
在 Google Cloud 控制台中,前往 BigQuery 页面。
在查询编辑器中,粘贴以下查询,然后点击运行:
SELECT * FROM ML.FORECAST(MODEL `bqml_tutorial.nyc_citibike_arima_model_group`, STRUCT(3 AS horizon, 0.9 AS confidence_level))
点击运行。
查询只需不到一秒的时间即可完成。结果应如下所示:
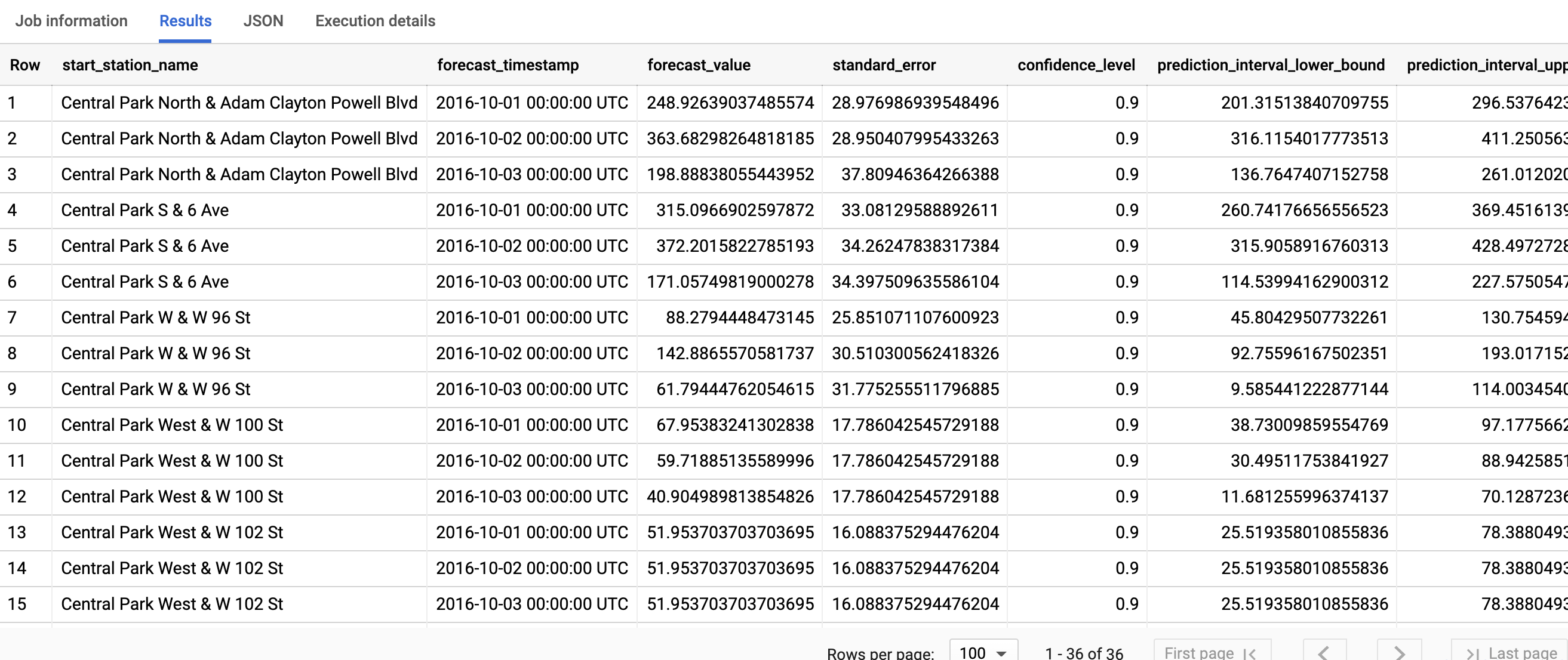
如需详细了解输出列,请参阅 ML.FORECAST 函数。
BigQuery DataFrame
使用 predict 函数预测未来的时序值。
在尝试此示例之前,请按照《BigQuery 快速入门:使用 BigQuery DataFrames》中的 BigQuery DataFrames 设置说明进行操作。如需了解详情,请参阅 BigQuery DataFrames 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为本地开发环境设置 ADC。
第一列 start_station_name 注释系统拟合每个时序模型所依据的时序。每个 start_station_name 都有三行预测结果(由 horizon 值指定)。
对于每个 start_station_name,输出行按 forecast_timestamp 列值的时间顺序排序。在时序预测中,由 prediction_interval_lower_bound 和 prediction_interval_upper_bound 列值表示的预测区间与 forecast_value 列值一样重要。forecast_value 值是预测区间的中点。预测区间取决于 standard_error 和 confidence_level 列值。
解释预测结果
SQL
除了预测数据,您还可以使用 ML.EXPLAIN_FORECAST 函数获取可解释性指标。ML.EXPLAIN_FORECAST 函数会预测未来的时序值,还会返回该时序的所有单独的组件。 如果您只想返回预测数据,请改用 ML.FORECAST 函数,如使用模型预测数据中所示。
ML.EXPLAIN_FORECAST 函数中使用的 STRUCT(3 AS horizon, 0.9 AS confidence_level) 子句指示查询会预测 3 个未来的时间点,并生成置信度为 90% 的预测区间。
请按照以下步骤解释模型的结果:
在 Google Cloud 控制台中,前往 BigQuery 页面。
在查询编辑器中,粘贴以下查询,然后点击运行:
SELECT * FROM ML.EXPLAIN_FORECAST(MODEL `bqml_tutorial.nyc_citibike_arima_model_group`, STRUCT(3 AS horizon, 0.9 AS confidence_level));
查询只需不到一秒的时间即可完成。结果应如下所示:


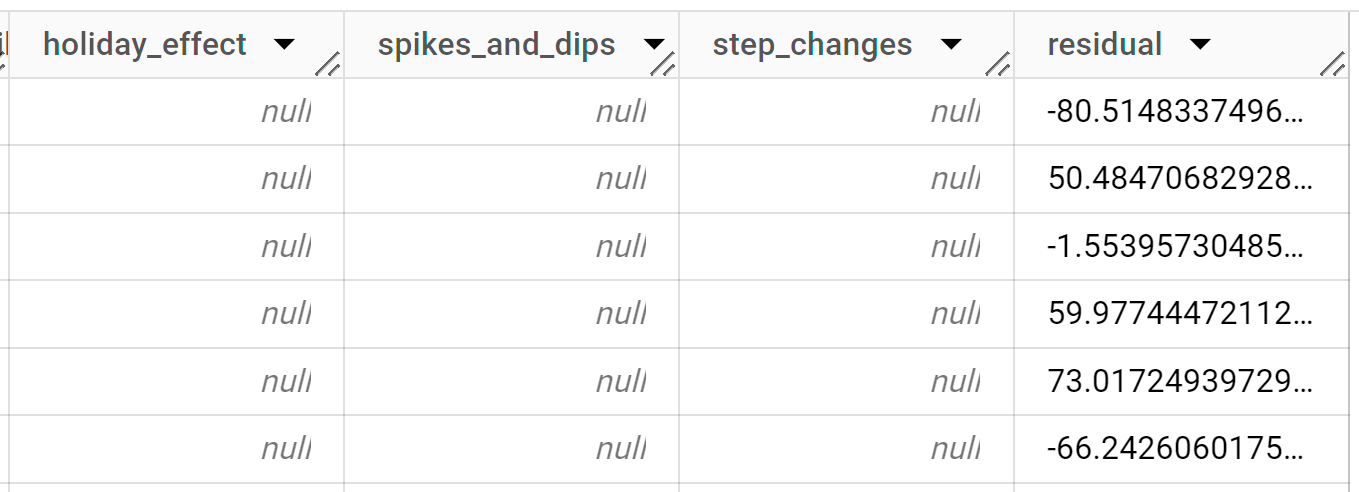
返回的前几千行都是历史数据。您必须滚动浏览结果才能看到预测数据。
输出行先按
start_station_name排序,然后按time_series_timestamp列值的时间顺序排序。在时序预测中,由prediction_interval_lower_bound和prediction_interval_upper_bound列值表示的预测区间与forecast_value列值一样重要。forecast_value值是预测区间的中点。预测区间取决于standard_error和confidence_level列值。如需详细了解输出列,请参阅
ML.EXPLAIN_FORECAST。
BigQuery DataFrame
除了预测数据,您还可以使用 predict_explain 函数获取可解释性指标。predict_explain 函数会预测未来的时序值,还会返回该时序的所有单独的组件。 如果您只想返回预测数据,请改用 predict 函数,如使用模型预测数据中所示。
predict_explain 函数中使用的 horizon=3, confidence_level=0.9 子句指示查询会预测 3 个未来的时间点,并生成置信度为 90% 的预测区间。
在尝试此示例之前,请按照《BigQuery 快速入门:使用 BigQuery DataFrames》中的 BigQuery DataFrames 设置说明进行操作。如需了解详情,请参阅 BigQuery DataFrames 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为本地开发环境设置 ADC。
输出行先按 time_series_timestamp 排序,然后按 start_station_name 列值的时间顺序排序。在时序预测中,由 prediction_interval_lower_bound 和 prediction_interval_upper_bound 列值表示的预测区间与 forecast_value 列值一样重要。forecast_value 值是预测区间的中点。预测区间取决于 standard_error 和 confidence_level 列值。