Vista geral: migre armazéns de dados para o BigQuery
Este documento aborda os conceitos gerais que se aplicam a qualquer tecnologia de armazenamento de dados e descreve uma estrutura que pode usar para organizar e estruturar a sua migração para o BigQuery.
Terminologia
Usamos a seguinte terminologia quando discutimos a migração do armazém de dados:
- Exemplo de utilização
-
Um exemplo de utilização consiste em todos os conjuntos de dados, processamento de dados e interações do sistema e do utilizador necessários para alcançar valor empresarial, como acompanhar os volumes de vendas de um produto ao longo do tempo. No armazenamento de dados, o exemplo de utilização consiste frequentemente no seguinte:
- Pipelines de dados que introduzem dados não processados de várias origens de dados, como a base de dados de gestão das relações com clientes (CRM).
- Os dados armazenados no armazém de dados.
- Scripts e procedimentos para manipular e processar e analisar mais os dados.
- Uma aplicação empresarial que lê ou interage com os dados.
- Carga de trabalho
-
Um conjunto de exemplos de utilização que estão ligados e têm dependências partilhadas. Por
exemplo, um exemplo de utilização pode ter as seguintes relações e dependências:
- Os relatórios de compras podem ser independentes e são úteis para compreender os gastos e pedir descontos.
- Os relatórios de vendas podem ser independentes e são úteis para planear campanhas de marketing.
- No entanto, os relatórios de lucros e perdas dependem das compras e das vendas, e são úteis para determinar o valor da empresa.
- Aplicação empresarial
- Um sistema com o qual os utilizadores finais interagem, por exemplo, um relatório visual ou um painel de controlo. Uma aplicação empresarial também pode assumir a forma de um pipeline de dados operacional ou de um ciclo de feedback. Por exemplo, depois de as alterações aos preços dos produtos terem sido calculadas ou previstas, um pipeline de dados operacionais pode atualizar os novos preços dos produtos numa base de dados transacional.
- Processo a montante
- Os sistemas de origem e os pipelines de dados que carregam dados no armazém de dados.
- Processo a jusante
- Os scripts, os procedimentos e as aplicações comerciais que são usados para processar, consultar e visualizar os dados no armazém de dados.
- Descarga da migração
-
Uma estratégia de migração que visa fazer com que o exemplo de utilização funcione para o
utilizador final no novo ambiente o mais rapidamente possível ou tirar partido
da capacidade adicional disponível no novo ambiente. Os exemplos de utilização são transferidos
fazendo o seguinte:
- Copiar e, em seguida, sincronizar o esquema e os dados do armazém de dados antigo.
- Migrar os scripts, os procedimentos e as aplicações empresariais a jusante.
A transferência da migração pode aumentar a complexidade e o trabalho envolvido na migração de pipelines de dados.
- Migração completa
- Uma abordagem de migração semelhante a uma migração de descarregamento, mas, em vez de copiar e, em seguida, sincronizar o esquema e os dados, configura a migração para carregar dados diretamente no novo armazém de dados na nuvem a partir dos sistemas de origem a montante. Por outras palavras, os pipelines de dados necessários para o exemplo de utilização também são migrados.
- Armazém de dados da empresa (EDW)
- Um armazém de dados que consiste não só numa base de dados analítica, mas em vários componentes e procedimentos analíticos críticos. Estes incluem pipelines de dados, consultas e aplicações empresariais que são necessários para cumprir as cargas de trabalho da organização.
- Armazém de dados na nuvem (CDW)
- Um armazém de dados com as mesmas caraterísticas que um EDW, mas que é executado num serviço totalmente gerido na nuvem, neste caso, o BigQuery.
- Pipeline de dados
- Um processo que liga sistemas de dados através de uma série de funções e tarefas que executam vários tipos de transformação de dados. Para ver detalhes, consulte o artigo O que é um pipeline de dados? desta série.
Por que motivo deve migrar para o BigQuery?
Nas últimas décadas, as organizações dominaram a ciência do armazenamento de dados. Têm aplicado cada vez mais a estatística descritiva a grandes quantidades de dados armazenados, obtendo estatísticas sobre as suas operações comerciais principais. A inteligência empresarial (IE) convencional, que se foca nas consultas, nos relatórios e no processamento analítico online, pode ter sido um fator de diferenciação no passado, que determinava o sucesso ou o fracasso de uma empresa, mas já não é suficiente.
Atualmente, as organizações não só precisam de compreender os eventos passados através da análise descritiva, como também precisam da análise preditiva, que usa frequentemente a aprendizagem automática (AA) para extrair padrões de dados e fazer afirmações probabilísticas sobre o futuro. O objetivo final é desenvolver uma análise prescritiva que combine as aprendizagens do passado com previsões sobre o futuro para orientar automaticamente as ações em tempo real.
As práticas tradicionais de armazéns de dados captam dados não processados de várias origens, que são frequentemente sistemas de processamento de transações online (OLTP). Em seguida, é extraído um subconjunto de dados em lotes, transformado com base num esquema definido e carregado no armazém de dados. Uma vez que os armazéns de dados tradicionais captam um subconjunto de dados em lotes e armazenam dados com base em esquemas rígidos, não são adequados para processar análises em tempo real nem responder a consultas espontâneas. A Google concebeu o BigQuery em parte em resposta a estas limitações inerentes.
As ideias inovadoras são frequentemente travadas pela dimensão e complexidade da organização de TI que implementa e mantém estes armazéns de dados tradicionais. Pode demorar anos e exigir um investimento substancial a criação de uma arquitetura de armazém de dados escalável, de alta disponibilidade e segura. O BigQuery oferece uma tecnologia sofisticada de software como serviço (SaaS) que pode ser usada para operações de armazém de dados sem servidor. Isto permite-lhe concentrar-se no avanço da sua atividade principal enquanto delega a manutenção da infraestrutura e o desenvolvimento da plataforma à Google Cloud.
O BigQuery oferece acesso ao armazenamento, ao tratamento e à análise de dados estruturados que são escaláveis, flexíveis e rentáveis. Estas características são essenciais quando os volumes de dados estão a crescer exponencialmente para disponibilizar recursos de armazenamento e processamento conforme necessário, bem como para obter valor a partir desses dados. Além disso, para as organizações que estão a começar a usar a análise de grandes volumes de dados e a aprendizagem automática, e que querem evitar as potenciais complexidades dos sistemas de grandes volumes de dados nas instalações, o BigQuery oferece uma forma de pagamento conforme a utilização para experimentar serviços geridos.
Com o BigQuery, pode encontrar respostas a problemas anteriormente intratáveis, aplicar a aprendizagem automática para descobrir padrões de dados emergentes e testar novas hipóteses. Como resultado, tem acesso a estatísticas oportunas sobre o desempenho da sua empresa, o que lhe permite modificar os processos para obter melhores resultados. Além disso, a experiência do utilizador final é frequentemente enriquecida com estatísticas relevantes obtidas a partir da análise de big data, como explicamos mais adiante nesta série.
O que e como migrar: a estrutura de migração
Realizar uma migração pode ser um esforço complexo e demorado. Por conseguinte, recomendamos que siga uma estrutura para organizar e estruturar o trabalho de migração em fases:
- Prepare e descubra: prepare-se para a migração com a descoberta da carga de trabalho e do exemplo de utilização.
- Planeie: dê prioridade aos exemplos de utilização, defina medidas de sucesso e planeie a migração.
- Executar: percorra os passos de migração, desde a avaliação à validação.
Prepare e descubra
Na fase inicial, o foco está na preparação e na descoberta. Trata-se de dar a si e aos seus intervenientes uma oportunidade antecipada de descobrir os exemplos de utilização existentes e levantar preocupações iniciais. É importante que também faça uma análise inicial sobre as vantagens esperadas. Estas incluem ganhos de desempenho (por exemplo, concorrência melhorada) e reduções no custo total de propriedade (TCO). Esta fase é crucial para ajudar a estabelecer o valor da migração.
Normalmente, um armazém de dados suporta uma vasta gama de exemplos de utilização e tem um grande número de partes interessadas, desde analistas de dados a decisores empresariais. Recomendamos que envolva representantes destes grupos para compreender bem que exemplos de utilização existem, se estes exemplos de utilização têm um bom desempenho e se as partes interessadas estão a planear novos exemplos de utilização.
O processo da fase de descoberta consiste nas seguintes tarefas:
- Examine a proposta de valor do BigQuery e compare-a com a do seu armazém de dados antigo.
- Realize uma análise inicial do CTP.
- Estabeleça que exemplos de utilização são afetados pela migração.
- Modele as caraterísticas dos conjuntos de dados subjacentes e dos pipelines de dados que quer migrar para identificar dependências.
Para obter estatísticas sobre os exemplos de utilização, pode desenvolver um questionário para recolher informações dos seus especialistas no assunto (SMEs), utilizadores finais e partes interessadas. O questionário deve recolher as seguintes informações:
- Qual é o objetivo do exemplo de utilização? Qual é o valor da empresa?
- Quais são os requisitos não funcionais? Atualidade dos dados, utilização concorrente, etc.
- O exemplo de utilização faz parte de uma carga de trabalho maior? Depende de outros exemplos de utilização?
- Que conjuntos de dados, tabelas e esquemas sustentam o exemplo de utilização?
- O que sabe sobre os pipelines de dados que alimentam esses conjuntos de dados?
- Que ferramentas, relatórios e painéis de controlo de inteligência empresarial são usados atualmente?
- Quais são os requisitos técnicos atuais relativos às necessidades operacionais, ao desempenho, à autenticação e à largura de banda da rede?
O diagrama seguinte mostra uma arquitetura antiga de alto nível antes da migração. Ilustra o catálogo de origens de dados disponíveis, pipelines de dados antigos, pipelines operacionais antigos e ciclos de feedback, bem como relatórios e painéis de controlo de BI antigos aos quais os utilizadores finais acedem.

Plano
A fase de planeamento consiste em usar as informações da fase de preparação e descoberta, avaliar essas informações e, em seguida, usá-las para planear a migração. Esta fase pode ser dividida nas seguintes tarefas:
Catalogue e priorize exemplos de utilização
Recomendamos que divida o processo de migração em iterações. Cataloga exemplos de utilização existentes e novos e atribui-lhes uma prioridade. Para ver detalhes, consulte as secções Migre através de uma abordagem iterativa e Priorize exemplos de utilização deste documento.
Defina medidas de sucesso
É útil definir medidas de sucesso claras, como indicadores essenciais de desempenho (IEDs), antes da migração. As suas medidas permitem-lhe avaliar o sucesso da migração em cada iteração. Isto, por sua vez, permite-lhe fazer melhorias ao processo de migração em iterações posteriores.
Crie uma definição de "concluído"
Com migrações complexas, não é necessariamente óbvio quando terminou a migração de um determinado exemplo de utilização. Por conseguinte, deve definir formalmente o estado final pretendido. Esta definição deve ser suficientemente genérica para poder ser aplicada a todos os casos de utilização que quer migrar. A definição deve funcionar como um conjunto de critérios mínimos para considerar que o caso de utilização foi totalmente migrado. Normalmente, esta definição inclui pontos de verificação para garantir que o exemplo de utilização foi integrado, testado e documentado.
Conceber e propor uma prova de conceito (POC), um estado a curto prazo e um estado final ideal
Depois de dar prioridade aos seus exemplos de utilização, pode começar a pensar neles durante todo o período da migração. Considere a migração do primeiro exemplo de utilização como uma prova de conceito (PoC) para validar a abordagem de migração inicial. Considere o que é alcançável nas primeiras semanas ou meses como o estado a curto prazo. Como é que os seus planos de migração vão afetar os utilizadores? Têm uma solução híbrida ou pode migrar uma carga de trabalho completa primeiro para um subconjunto de utilizadores?
Crie estimativas de tempo e custo
Para garantir um projeto de migração bem-sucedido, é importante produzir estimativas de tempo realistas. Para o conseguir, interaja com todas as partes interessadas relevantes para discutir a respetiva disponibilidade e concordar com o nível de envolvimento ao longo do projeto. Isto ajuda a estimar os custos de mão de obra com maior precisão. Para estimar os custos relacionados com o consumo projetado de recursos da nuvem, consulte os artigos Estimativa dos custos de armazenamento e de consultas e Introdução ao controlo dos custos do BigQuery na documentação do BigQuery.
Identifique e interaja com um parceiro de migração
A documentação do BigQuery descreve muitas ferramentas e recursos que pode usar para realizar a migração. No entanto, pode ser difícil fazer uma migração grande e complexa por conta própria se não tiver experiência anterior ou não tiver todas as competências técnicas necessárias na sua organização. Por isso, recomendamos que, desde o início, identifique e trabalhe com um parceiro de migração. Para mais detalhes, consulte os nossos programas de parceiros globais e de serviços de consultoria.
Migre através de uma abordagem iterativa
Quando migrar uma operação de armazém de dados de grande dimensão para a nuvem, é uma boa ideia adotar uma abordagem iterativa. Por isso, recomendamos que faça a transição para o BigQuery em iterações. Dividir o esforço de migração em iterações facilita o processo geral, reduz o risco e oferece oportunidades de aprendizagem e melhoria após cada iteração.
Uma iteração consiste em todo o trabalho necessário para descarregar ou migrar totalmente um ou mais exemplos de utilização relacionados num período de tempo limitado. Pode considerar uma iteração como um ciclo de sprint na metodologia ágil, que consiste numa ou mais histórias de utilizadores.
Para maior conveniência e facilidade de acompanhamento, pode considerar associar um exemplo de utilização individual a uma ou mais histórias do utilizador. Por exemplo, considere a seguinte história do utilizador: "Enquanto analista de preços, quero analisar as alterações de preços dos produtos ao longo do último ano para poder calcular os preços futuros."
O exemplo de utilização correspondente pode ser:
- Ingerir os dados de uma base de dados transacional que armazena produtos e preços.
- Transformar os dados numa única série cronológica para cada produto e introduzir quaisquer valores em falta.
- Armazenar os resultados numa ou mais tabelas no armazém de dados.
- Disponibilizar os resultados através de um bloco de notas Python (a aplicação empresarial).
O valor empresarial deste exemplo de utilização é apoiar a análise de preços.
Tal como na maioria dos exemplos de utilização, este exemplo de utilização provavelmente vai suportar várias histórias do utilizador.
É provável que um exemplo de utilização transferido seja seguido de uma iteração subsequente para migrar totalmente o exemplo de utilização. Caso contrário, pode continuar a ter uma dependência do data warehouse existente e antigo, porque os dados são copiados a partir daí. A migração completa subsequente é a diferença entre o descarregamento e uma migração completa que não foi precedida de um descarregamento. Por outras palavras, a migração dos pipelines de dados para extrair, transformar e carregar os dados no armazém de dados.
Priorize exemplos de utilização
O ponto de partida e de conclusão da migração depende das necessidades específicas da sua empresa. Decidir a ordem em que migra os exemplos de utilização é importante porque o sucesso inicial durante uma migração é crucial para continuar no seu caminho de adoção da nuvem. A ocorrência de falhas numa fase inicial pode tornar-se um sério revés para o esforço de migração geral. Pode concordar com as vantagens do Google Cloud e do BigQuery, mas o processamento de todos os conjuntos de dados e pipelines de dados que foram criados ou geridos no seu armazém de dados antigo para diferentes exemplos de utilização pode ser complicado e demorado.
Embora não exista uma resposta única, existem práticas recomendadas que pode usar ao avaliar os seus exemplos de utilização no local e aplicações empresariais. Este tipo de planeamento prévio pode facilitar o processo de migração e tornar toda a transição para o BigQuery mais simples.
As secções seguintes exploram possíveis abordagens para dar prioridade aos exemplos de utilização.
Abordagem: explorar as oportunidades atuais
Analise as oportunidades atuais que podem ajudar a maximizar o retorno do investimento de um exemplo de utilização específico. Esta abordagem é especialmente útil se tiver pressão para justificar o valor empresarial da migração para a nuvem. Também oferece uma oportunidade de recolher pontos de dados adicionais para ajudar a avaliar o custo total da migração.
Seguem-se algumas perguntas de exemplo que pode fazer para ajudar a identificar os exemplos de utilização a priorizar:
- O exemplo de utilização consiste em conjuntos de dados ou pipelines de dados que estão atualmente limitados pelo armazém de dados empresarial antigo?
- O seu armazém de dados empresarial existente requer uma atualização de hardware ou prevê a necessidade de expandir o seu hardware? Se for o caso, pode ser atrativo transferir exemplos de utilização para o BigQuery mais cedo do que mais tarde.
A identificação de oportunidades de migração pode criar algumas vitórias rápidas que geram vantagens tangíveis e imediatas para os utilizadores e a empresa.
Abordagem: migre primeiro as cargas de trabalho analíticas
Migre as cargas de trabalho de processamento analítico online (OLAP) antes das cargas de trabalho de processamento de transações online (OLTP). Muitas vezes, um armazém de dados é o único local na organização onde tem todos os dados para criar uma vista única e global das operações da organização. Por conseguinte, é comum as organizações terem alguns pipelines de dados que são usados nos sistemas transacionais para atualizar o estado ou acionar processos, por exemplo, para comprar mais stock quando o inventário de um produto está baixo. As cargas de trabalho OLTP tendem a ser mais complexas e a ter requisitos operacionais mais rigorosos e contratos de nível de serviço (SLAs) do que as cargas de trabalho OLAP. Por isso, também tende a ser mais fácil migrar primeiro as cargas de trabalho OLAP.
Abordagem: concentre-se na experiência do utilizador
Identifique oportunidades para melhorar a experiência do utilizador migrando conjuntos de dados específicos e ativando novos tipos de estatísticas avançadas. Por exemplo, uma forma de melhorar a experiência do utilizador é com estatísticas em tempo real. Pode criar experiências do utilizador sofisticadas em torno de uma transmissão de dados em tempo real quando esta é combinada com dados do histórico. Por exemplo:
- Um funcionário de back-office que recebe um alerta na app para dispositivos móveis sobre o stock baixo.
- Um cliente online que pode beneficiar de saber que gastar mais 1 € o colocaria no nível de recompensa seguinte.
- Uma enfermeira que recebe um alerta sobre os sinais vitais de um paciente no respetivo smartwatch, o que lhe permite tomar a melhor medida consultando o histórico de tratamento do paciente no tablet.
Também pode melhorar a experiência do utilizador com estatísticas preditivas e prescritivas. Para isso, pode usar o BigQuery ML, o Vertex AI AutoML tabular ou os modelos pré-preparados da Google para análise de imagens, análise de vídeo, reconhecimento de voz, linguagem natural> e tradução. Em alternativa, pode apresentar o seu modelo preparado de forma personalizada através da Vertex AI para exemplos de utilização adaptados às suas necessidades empresariais. Isto pode envolver o seguinte:
- Recomendar um produto com base nas tendências de mercado e no comportamento de compra do utilizador.
- Prever um atraso de voo.
- Detetar atividades fraudulentas.
- Denunciar conteúdo impróprio.
- Outras ideias inovadoras que podem diferenciar a sua app da concorrência.
Abordagem: priorizar exemplos de utilização com menor risco
Existem várias perguntas que o departamento de TI pode fazer para ajudar a avaliar que exemplos de utilização são os menos arriscados de migrar, o que os torna mais atrativos para migrar nas fases iniciais da migração. Por exemplo:
- Qual é a criticidade empresarial deste exemplo de utilização?
- Um grande número de funcionários ou clientes depende do exemplo de utilização?
- Qual é o ambiente de destino (por exemplo, desenvolvimento ou produção) para o exemplo de utilização?
- Qual é a compreensão do exemplo de utilização por parte da nossa equipa de TI?
- Quantas dependências e integrações tem o exemplo de utilização?
- A nossa equipa de TI tem documentação adequada, atualizada e detalhada para o exemplo de utilização?
- Quais são os requisitos operacionais (ACNs) para o exemplo de utilização?
- Quais são os requisitos de conformidade legal ou governamental para o exemplo de utilização?
- Quais são as sensibilidades de tempo de inatividade e latência para aceder ao conjunto de dados subjacente?
- Existem proprietários de linhas de negócio ansiosos e dispostos a migrar o respetivo exemplo de utilização antecipadamente?
A análise desta lista de perguntas pode ajudar a classificar os conjuntos de dados e os pipelines de dados do risco mais baixo para o mais elevado. Os recursos de baixo risco devem ser migrados primeiro e os de maior risco devem ser migrados mais tarde.
Execute
Depois de reunir informações sobre os seus sistemas antigos e criar uma lista de pendências priorizada de exemplos de utilização, pode agrupar os exemplos de utilização em cargas de trabalho e prosseguir com a migração em iterações.
Uma iteração pode consistir num único exemplo de utilização, em alguns exemplos de utilização separados ou num número de exemplos de utilização relacionados com uma única carga de trabalho. A opção que escolher para a iteração depende da interconectividade dos exemplos de utilização, das dependências partilhadas e dos recursos que tem disponíveis para realizar o trabalho.
Normalmente, uma migração contém os seguintes passos:
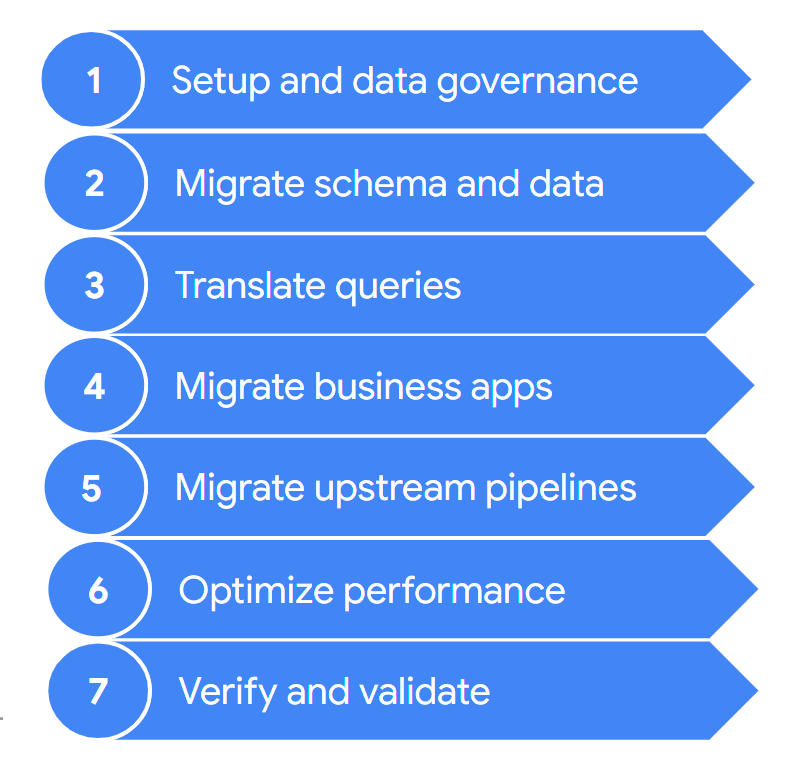
Estes passos são descritos mais detalhadamente nas secções seguintes. Pode não ter de seguir todos estes passos em cada iteração. Por exemplo, numa iteração, pode decidir focar-se na cópia de alguns dados do seu armazém de dados antigo para o BigQuery. Por outro lado, numa iteração subsequente, pode concentrar-se na modificação do pipeline de carregamento a partir de uma origem de dados original diretamente para o BigQuery.
1. Configuração e gestão de dados
A configuração é o trabalho fundamental necessário para permitir que os exemplos de utilização sejam executados no Google Cloud. A configuração pode incluir a configuração dos seus Google Cloud projetos, rede, nuvem virtual privada (VPC) e governação de dados. Também inclui o desenvolvimento de uma boa compreensão do ponto em que se encontra atualmente, ou seja, o que funciona e o que não funciona. Isto ajuda a compreender os requisitos para o seu esforço de migração. Pode usar a funcionalidade de avaliação da migração do BigQuery para ajudar neste passo.
A gestão de dados é uma abordagem baseada em princípios para gerir os dados durante o respetivo ciclo de vida, desde a aquisição à utilização e eliminação. O seu programa de governação de dados descreve claramente as políticas, os procedimentos, as responsabilidades e os controlos relativos às atividades de dados. Este programa ajuda a garantir que as informações são recolhidas, mantidas, usadas e disseminadas de uma forma que cumpre a integridade dos dados e as necessidades de segurança da sua organização. Também ajuda a capacitar os seus funcionários para descobrirem e usarem os dados em todo o seu potencial.
A documentação de governança de dados ajuda a compreender a governança de dados e os controlos necessários quando migra o seu armazém de dados no local para o BigQuery.
2. Migre o esquema e os dados
O esquema do armazém de dados define a estrutura dos seus dados e as relações entre as entidades de dados. O esquema está no centro da estrutura dos dados e influencia muitos processos, tanto a montante como a jusante.
A documentação sobre o esquema e a transferência de dados fornece informações detalhadas sobre como pode mover os seus dados para o BigQuery e recomendações para atualizar o esquema de modo a tirar total partido das funcionalidades do BigQuery.
3. Traduza consultas
Use a tradução de SQL em lote para migrar o seu código SQL em massa ou a tradução de SQL interativa para traduzir consultas ad hoc.
Alguns data warehouses antigos incluem extensões à norma SQL para ativar a funcionalidade do respetivo produto. O BigQuery não suporta estas extensões proprietárias. Em alternativa, está em conformidade com a norma ANSI/ISO SQL:2011. Isto significa que algumas das suas consultas podem ainda precisar de refatoração manual se os tradutores de SQL não as conseguirem interpretar.
4. Migre aplicações empresariais
As aplicações empresariais podem assumir muitas formas, desde painéis de controlo a aplicações personalizadas, passando por pipelines de dados operacionais que fornecem ciclos de feedback aos sistemas transacionais.
Para saber mais acerca das opções de estatísticas quando trabalha com o BigQuery, consulte o artigo Vista geral das estatísticas do BigQuery. Este tópico apresenta uma vista geral das ferramentas de relatórios e análise que pode usar para obter informações relevantes a partir dos seus dados.
A secção sobre ciclos de feedback na documentação do pipeline de dados descreve como pode usar um pipeline de dados para criar um ciclo de feedback para aprovisionar sistemas a montante.
5. Migre data pipelines
A documentação sobre os pipelines de dados apresenta procedimentos, padrões e tecnologias para migrar os seus pipelines de dados antigos para o Google Cloud. Ajuda a compreender o que é um pipeline de dados, que procedimentos e padrões pode usar e que opções e tecnologias de migração estão disponíveis em relação à migração do data warehouse mais abrangente.
6. Otimize o desempenho
O BigQuery processa dados de forma eficiente para conjuntos de dados pequenos e à escala de petabytes. Com a ajuda do BigQuery, as suas tarefas de análise de dados devem ter um bom desempenho sem modificações no armazém de dados migrado recentemente. Se considerar que, em determinadas circunstâncias, o desempenho das consultas não corresponde às suas expetativas, consulte o artigo Introdução à otimização do desempenho das consultas para obter orientações.
7. Valide e confirme
No final de cada iteração, valide se a migração do exemplo de utilização foi bem-sucedida verificando se:
- Os dados e o esquema foram totalmente migrados.
- As preocupações de gestão dos dados foram totalmente satisfeitas e testadas.
- Foram estabelecidos procedimentos de manutenção e monitorização, bem como automatização.
- As consultas foram traduzidas corretamente.
- Os pipelines de dados migrados funcionam como esperado.
- As aplicações empresariais estão configuradas corretamente para aceder aos dados e às consultas migrados.
Pode começar com a ferramenta de validação de dados, uma ferramenta de CLI Python de código aberto que compara os dados dos ambientes de origem e de destino para garantir que correspondem. Suporta vários tipos de ligação, juntamente com a funcionalidade de validação de vários níveis.
Também é uma boa ideia medir o impacto da migração do exemplo de utilização, por exemplo, em termos de melhoria do desempenho, redução do custo ou ativação de novas oportunidades técnicas ou empresariais. Em seguida, pode quantificar com maior precisão o valor do retorno do investimento e comparar o valor com os critérios de sucesso da iteração.
Depois de a iteração ser validada, pode lançar o exemplo de utilização migrado para produção e dar aos utilizadores acesso aos conjuntos de dados e às aplicações empresariais migrados.
Por último, tome notas e documente as lições aprendidas com esta iteração para poder aplicá-las na iteração seguinte e acelerar a migração.
Resumir o esforço de migração
Durante a migração, executa o seu armazém de dados antigo e o BigQuery, conforme detalhado neste documento. A arquitetura de referência no diagrama seguinte realça que ambos os armazéns de dados oferecem funcionalidades e caminhos semelhantes. Ambos podem carregar dados dos sistemas de origem, integrar-se com as aplicações empresariais e fornecer o acesso de utilizador necessário. É importante salientar que o diagrama também realça que os dados são sincronizados do seu armazém de dados para o BigQuery. Isto permite que os exemplos de utilização sejam transferidos durante todo o período do esforço de migração.

Partindo do princípio de que a sua intenção é migrar totalmente do seu armazém de dados para o BigQuery, o estado final da migração é o seguinte:

O que se segue?
Faça uma migração do BigQuery com as seguintes ferramentas:
- Execute uma avaliação da migração para avaliar a viabilidade e as potenciais vantagens da migração do seu armazém de dados para o BigQuery.
- Use as ferramentas de tradução de SQL, como o tradutor de SQL interativo, a API Translation e o tradutor de SQL em lote para automatizar a conversão das suas consultas SQL em GoogleSQL, incluindo a personalização de SQL melhorada pelo Gemini.
- Depois de migrar o seu armazém de dados para o BigQuery, execute a ferramenta de validação de dados para validar os dados recém-migrados.
Saiba mais sobre uma migração do data warehouse com os seguintes recursos:
- O Centro de arquitetura na nuvem oferece recursos de migração para planear e executar a sua migração para o Google Cloud
- Saiba como migrar o esquema e os dados do seu armazém de dados
- Saiba como migrar pipelines de dados do seu armazém de dados
- Saiba mais sobre a governança de dados no BigQuery
Trabalhe com a equipa de serviços profissionais para ajudar a planear e implementar a sua Google Cloud migração. Para mais informações, consulte os Serviços profissionais do Google Cloud
Saiba como migrar de armazéns de dados específicos para o BigQuery: