Introdução à otimização do desempenho das consultas
Este documento oferece uma vista geral das técnicas de otimização que podem melhorar o desempenho das consultas no BigQuery. Em geral, as consultas que requerem menos trabalho têm um desempenho superior. São executados mais rapidamente e consomem menos recursos, o que pode resultar em custos mais baixos e menos falhas.
Desempenho da consulta
A avaliação do desempenho das consultas no BigQuery envolve vários fatores:
- Dados de entrada e origens de dados (I/O): Quantos bytes é que a consulta lê?
- Comunicação entre nós (classificação): quantos bytes é que a consulta transmite para a fase seguinte? Quantos bytes é que a consulta transmite a cada espaço?
- Cálculo: qual é o volume de CPU que a consulta requer?
- Saídas (materialização): Quantos bytes é que a consulta escreve?
- Capacidade e simultaneidade: Quantos espaços estão disponíveis e quantas outras consultas estão a ser executadas ao mesmo tempo?
- Padrões de consulta: as consultas seguem as práticas recomendadas de SQL?
Para avaliar consultas específicas ou se está a ter problemas de contenção de recursos, pode usar o Cloud Monitoring ou os gráficos de recursos administrativos do BigQuery para monitorizar como as suas tarefas do BigQuery consomem recursos ao longo do tempo. Se identificar uma consulta lenta ou que requer muitos recursos, pode focar as otimizações de desempenho nessa consulta.
Alguns padrões de consultas, especialmente os gerados por ferramentas de Business Intelligence, podem ser acelerados através do BigQuery BI Engine. O BI Engine é um serviço de análise na memória rápido que acelera muitas consultas SQL no BigQuery ao armazenar em cache de forma inteligente os dados que usa com maior frequência. O BI Engine está integrado no BigQuery, o que significa que, muitas vezes, pode obter um melhor desempenho sem modificações nas consultas.
Tal como acontece com qualquer sistema, a otimização em função do desempenho envolve, por vezes, chegar a uma solução de compromisso. Por exemplo, a utilização da sintaxe SQL avançada pode, por vezes, introduzir complexidade e reduzir a compreensibilidade das consultas para pessoas que não são especialistas em SQL. Gastar tempo em micro-otimizações para cargas de trabalho não críticas também pode desviar recursos da criação de novas funcionalidades para as suas aplicações ou da identificação de otimizações mais importantes. Para ajudar a alcançar o maior retorno do investimento possível, recomendamos que foque as suas otimizações nas cargas de trabalho que são mais importantes para os seus pipelines de estatísticas de dados.
Otimização para capacidade e concorrência
O BigQuery oferece dois modelos de preços para consultas: preços a pedido e preços com base na capacidade. O modelo a pedido oferece um conjunto partilhado de capacidade, e os preços baseiam-se na quantidade de dados processados por cada consulta que executa.
O modelo baseado na capacidade é recomendado se quiser orçamentar uma despesa mensal consistente ou se precisar de mais capacidade do que a disponível com o modelo a pedido. Quando usa preços baseados na capacidade, atribui capacidade de processamento de consultas dedicada, que é medida em slots. O custo de todos os bytes processados está incluído no preço baseado na capacidade. Além dos compromissos de espaços fixos, pode usar espaços de escalamento automático, que oferecem capacidade dinâmica com base na sua carga de trabalho de consultas.
O desempenho das consultas executadas repetidamente nos mesmos dados pode variar e, geralmente, a variação é maior para consultas que usam slots a pedido do que para consultas que usam reservas de slots.
Durante o processamento de consultas SQL, o BigQuery divide a capacidade computacional necessária para executar cada fase de uma consulta em slots. O BigQuery determina automaticamente o número de consultas que podem ser executadas em simultâneo da seguinte forma:
- Modelo a pedido: número de espaços disponíveis no projeto
- Modelo baseado na capacidade: número de horários disponíveis na reserva
As consultas que requerem mais espaços do que os disponíveis são colocadas em fila até que os recursos de processamento fiquem disponíveis. Depois de uma consulta começar a execução, o BigQuery calcula quantos slots cada fase da consulta usa com base no tamanho e na complexidade da fase, bem como no número de slots disponíveis. O BigQuery usa uma técnica denominada agendamento justo para garantir que cada consulta tem capacidade suficiente para progredir.
O acesso a mais espaços nem sempre resulta num desempenho mais rápido para uma consulta. No entanto, um conjunto maior de espaços pode melhorar o desempenho de consultas grandes ou complexas e o desempenho de cargas de trabalho altamente concorrentes. Para melhorar o desempenho das consultas, pode modificar as suas reservas de espaços ou definir um limite mais elevado para o dimensionamento automático de espaços.
Plano de consulta e linha cronológica
O BigQuery gera um plano de consulta sempre que executa uma consulta. Compreender este plano é fundamental para uma otimização de consultas eficaz. O plano de consulta inclui estatísticas de execução, como bytes lidos e tempo de intervalo consumido. O plano de consulta também inclui detalhes sobre as diferentes fases de execução, o que pode ajudar a diagnosticar e melhorar o desempenho das consultas. O gráfico de execução de consultas oferece uma interface gráfica para ver o plano de consulta e diagnosticar problemas de desempenho de consultas.
Também pode usar o método da API jobs.get
ou a vista INFORMATION_SCHEMA.JOBS
para obter o plano de consulta e as informações da cronologia. Estas informações são usadas pelo
BigQuery Visualiser,
uma ferramenta de código aberto que representa visualmente o fluxo de fases de execução num
trabalho do BigQuery.
Quando o BigQuery executa uma tarefa de consulta, converte a declaração SQL declarativa num gráfico de execução. Este gráfico está dividido numa série de fases de consulta, que, por sua vez, são compostas por conjuntos mais detalhados de passos de execução. O BigQuery usa uma arquitetura paralela altamente distribuída para executar estas consultas. As fases do BigQuery modelam as unidades de trabalho que muitos potenciais trabalhadores podem executar em paralelo. As fases comunicam entre si através de uma arquitetura de aleatorização rápida e distribuída.
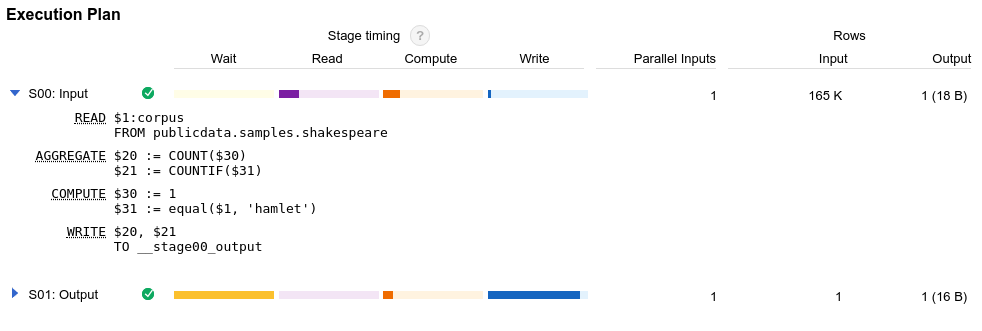
Além do plano de consulta, as tarefas de consulta também expõem uma cronologia de execução. Esta cronologia fornece uma contabilidade das unidades de trabalho concluídas, pendentes e ativas nas trabalhadoras de consultas. Uma consulta pode ter várias fases com trabalhadores ativos em simultâneo, pelo que a cronologia destina-se a mostrar o progresso geral da consulta.
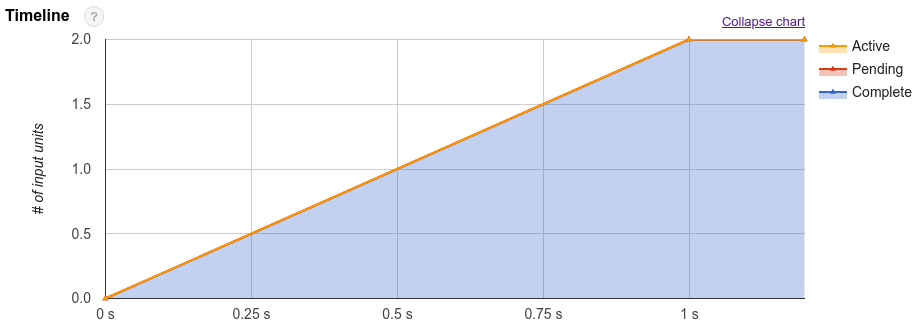
Para estimar o custo computacional de uma consulta, pode analisar o número total de segundos de espaço que a consulta consome. Quanto menor for o número de segundos de intervalo, melhor, porque significa que estão disponíveis mais recursos para outras consultas em execução no mesmo projeto ao mesmo tempo.
O plano de consulta e as estatísticas da cronologia podem ajudar a compreender como o BigQuery executa as consultas e se determinadas fases dominam a utilização de recursos. Por exemplo, uma fase JOIN que gera muito mais linhas de saída do que linhas de entrada pode indicar uma oportunidade de filtrar mais cedo na consulta.
No entanto, a natureza gerida do serviço limita a possibilidade de tomar medidas diretas em relação a alguns detalhes. Para ver práticas recomendadas e técnicas para melhorar a execução e o desempenho das consultas, consulte o artigo Otimize o cálculo das consultas.
O que se segue?
- Saiba como resolver problemas de execução de consultas através dos registos de auditoria do BigQuery.
- Saiba mais sobre outras técnicas de controlo de custos para o BigQuery.
- Veja metadados quase em tempo real sobre tarefas do BigQuery através da vista
INFORMATION_SHEMA.JOBS. - Saiba como monitorizar a sua utilização do BigQuery através dos relatórios de tabelas do sistema do BigQuery.