En este documento se describen las causas habituales de los apagados y reinicios inesperados de las instancias de Compute Engine, así como la forma de prevenirlos.
Los apagados y reinicios de instancias pueden deberse a eventos del sistema o a actividades administrativas. Los reinicios y los apagados de eventos del sistema los generan los sistemas de Google o el sistema operativo de tus instancias. Las acciones de apagado y reinicio de la actividad de administrador se generan mediante una llamada a la API generada por un usuario o una cuenta de servicio. Se registran todos los apagados y reinicios, excepto los reinicios que se inician desde la instancia.
Antes de empezar
-
Si aún no lo has hecho, configura la autenticación.
La autenticación verifica tu identidad para acceder a Google Cloud servicios y APIs. Para ejecutar código o ejemplos desde un entorno de desarrollo local, puedes autenticarte en Compute Engine seleccionando una de las siguientes opciones:
Select the tab for how you plan to use the samples on this page:
Console
When you use the Google Cloud console to access Google Cloud services and APIs, you don't need to set up authentication.
gcloud
-
Instala Google Cloud CLI. Después de la instalación, inicializa la CLI de Google Cloud ejecutando el siguiente comando:
gcloud initSi utilizas un proveedor de identidades (IdP) externo, primero debes iniciar sesión en la CLI de gcloud con tu identidad federada.
- Set a default region and zone.
Diagnosticar los apagados y reinicios de instancias
Para diagnosticar la causa del apagado o reinicio espontáneo de una instancia, debes consultar los registros de tus instancias. Para identificar rápidamente la causa de los futuros apagados o reinicios de las VMs, crea un panel de control que contenga los registros. Después de consultar los registros, revisa los campos
methodyprincipalEmailpara determinar qué evento y qué usuario o servicio iniciaron el apagado o el reinicio.Consultar registros de auditoría de Cloud
Consulta los registros de auditoría de Cloud para ver una lista de eventos del sistema y actividades administrativas que podrían haber provocado el apagado o el reinicio.
Consola
En la Google Cloud consola, ve a la página Explorador de registros.
En el campo Consulta, introduce la siguiente consulta:
resource.type="gce_instance" "VM_NAME" logName:("logs/cloudaudit.googleapis.com%2Fsystem_event" OR "logs/cloudaudit.googleapis.com%2Factivity")Sustituye
VM_NAMEpor el nombre de la VM que se ha apagado o reiniciado.Si el evento que buscas ocurrió hace más de una hora, define un periodo personalizado haciendo clic en el símbolo del reloj e introduciendo un intervalo personalizado.
Haz clic en Realizar una consulta. Los resultados se muestran en la sección Resultados de la consulta.
Haz clic en la flecha de expansión situada junto a cada resultado para ver información detallada.
Consulta Revisar los registros de auditoría de Cloud para obtener más información sobre los campos
methodyprincipalEmailasociados a los apagados y reinicios, y qué puedes hacer para evitarlos.
gcloud
Consulta los registros de auditoría de Cloud con el comando
gcloud logging read:gcloud logging read --freshness=TIME 'resource.type="gce_instance" "VM_NAME" logName:("logs/cloudaudit.googleapis.com%2Fsystem_event" OR "logs/cloudaudit.googleapis.com%2Factivity")'Haz los cambios siguientes:
TIME: el periodo que quieres consultar. Por ejemplo,1hconsulta las entradas de registro de la última hora. Para obtener información sobre los formatos de fecha y hora, consulta el tema de gcloud sobre fechas y horas.VM_NAME: el nombre de la VM que se ha apagado o reiniciado.
Se muestran los resultados.
Consulta Revisar los registros de auditoría de Cloud para obtener más información sobre los campos
methodyprincipalEmailasociados a los apagados y reinicios, y qué puedes hacer para evitarlos.
Revisar registros de auditoría de Cloud
Consulta los campos
methodyprincipalEmailde los registros de auditoría de Cloud para determinar por qué se ha apagado o reiniciado tu VM.Revisa los
methodcampos de los registros de auditoría de Cloud y compáralos con los métodos que se indican en la siguiente tabla.Método Tipo de apagado Descripción compute.instances.repair.recreateInstanceEvento del sistema Si tu VM pertenece a un grupo de instancias gestionado (MIG), el MIG recrea la VM si su estado cambia de
RUNNINGy el MIG no ha iniciado el cambio de estado.Los cambios de estado de la instancia que no inicia el MIG son los siguientes:
- Fallos de hardware.
- Finalizando una instancia interrumpible.
- Eventos de mantenimiento de la infraestructura cuando la instancia de VM no está configurada para migrarse automáticamente.
- Eliminar una instancia de un MIG con uno de los siguientes métodos:
- Método de la API
instances.delete - El comando
gcloud compute instances delete
- Método de la API
compute.instances.hostErrorEvento del sistema Un error de host (
compute.instances.hostError) significa que ha habido un problema de hardware o software en la máquina física o en la infraestructura del centro de datos que aloja tu instancia de cálculo, lo que ha provocado que falle. Un error del host que implique un fallo total del hardware u otros problemas de hardware puede impedir la migración en directo de tu instancia. Si tu instancia está configurada para reiniciarse automáticamente (que es el ajuste predeterminado), Compute Engine la reiniciará, normalmente en un plazo de tres minutos desde que se detectó el error. En función del problema, el reinicio puede tardar hasta 5 minutos y medio.En ocasiones, una instancia de proceso puede dejar de responder antes de que se señale un error de host. Puedes reducir el tiempo que espera Compute Engine para reiniciar o finalizar la instancia configurando el tiempo de espera de recuperación de errores del host. Para obtener más información, consulta Definir políticas de disponibilidad.
Los fallos de hardware y software físicos pueden ocurrir de vez en cuando, pero son poco frecuentes. Para proteger tus aplicaciones y servicios de estos eventos del sistema potencialmente perjudiciales, consulta los siguientes recursos:
- Diseñar sistemas robustos
- Patrones para aplicaciones escalables y resilientes
- Crear grupos de instancias gestionadas
Google también ofrece servicios gestionados, como App Engine y el entorno flexible de App Engine.
compute.instances.automaticRestartEvento del sistema Este evento se produce después de un evento
hostErroroterminateOnHostMaintenancesi la política de mantenimiento del hostautomaticRestartde tu VM se ha definido comotrue. En los registros, hay una entrada de registrohostErroroterminateOnHostMaintenanceantes de este registro.Si quieres cambiar la política de mantenimiento del host de tu VM, consulta Opciones de actualización de una instancia.
compute.instances.guestTerminateEvento del sistema El sistema operativo de tu VM ha iniciado el apagado. compute.instances.terminateOnHostMaintenanceEvento del sistema Si configuras la
onHostMaintenancepolítica de mantenimiento del hostTERMINATEde tu VM enonHostMaintenanceTERMINATE, Compute Engine detendrá tu VM cuando haya un evento de mantenimiento en el que Google deba mover tu VM a otro host.Si quieres cambiar la
onHostMaintenancepolítica de tu máquina virtual, consulta Actualizar las opciones de una instancia.compute.instances.preemptedEvento del sistema Compute Engine ha interrumpido tu Spot VM o tu VM interrumpible antigua:
- Cuando Compute Engine interrumpe temporalmente una Spot VM, la detiene o la elimina en función de su acción de finalización. Las máquinas virtuales de acceso puntual no tienen un tiempo de ejecución máximo.
- Cuando Compute Engine interrumpe una VM interrumpible, la detiene tras un tiempo de ejecución máximo de 24 horas. Para evitar estas limitaciones, usa máquinas virtuales de Spot.
Las máquinas virtuales de acceso puntual y las máquinas virtuales interrumpibles son capacidad excedente de Compute Engine, por lo que Compute Engine puede interrumpirlas temporalmente en cualquier momento si se necesita esa capacidad en otro lugar. Para mitigar los efectos de la expropiación, siga las prácticas recomendadas. Si necesitas máquinas virtuales con tiempos de ejecución controlados por el usuario, crea máquinas virtuales estándar.
compute.instances.stopActividad del administrador Un usuario o una cuenta de servicio ha detenido tu VM.
Ve al siguiente paso para identificar la cuenta de usuario o de servicio que ha detenido tu VM. Para obtener información sobre cómo reiniciar una VM, consulta Reiniciar una instancia detenida.
compute.instances.deleteActividad del administrador o evento del sistema Un usuario o una cuenta de servicio ha eliminado tu máquina virtual, o bien la máquina virtual se ha configurado para que se elimine automáticamente.
En concreto, un registro del método
compute.instances.deletepodría indicar cualquiera de las siguientes solicitudes de tu VM:- Las solicitudes de un usuario o una cuenta de servicio para eliminar directamente tu VM se indican únicamente mediante un método
compute.instances.deletedel usuario o la cuenta de servicio. Las solicitudes que eliminan automáticamente tu máquina virtual se indican con un método
compute.instances.deletedesystem@google.com, pero es posible que el método que explica la causa de la eliminación automática aparezca o no en los registros de auditoría de Cloud.Por ejemplo, si una VM de Spot está configurada para eliminarse automáticamente durante la interrupción y se interrumpe, verás un método
compute.instances.deletedesystem@google.com, pero puede que también veas un métodocompute.instances.preempted.Es posible que las solicitudes a la VM que se hayan producido poco antes o después de un método
compute.instances.deleteaparezcan o no en los registros de auditoría de Cloud.Por ejemplo, si una VM se detiene debido al mantenimiento del host poco antes de que se elimine, verás el método
compute.instances.delete, pero puede que también veas el métodocompute.instances.terminateOnHostMaintenanceo no.
Ve al siguiente paso para identificar al usuario o la cuenta de servicio que ha eliminado tu VM. Para obtener información sobre cómo crear una VM, consulta el artículo Crear e iniciar una VM.
compute.instances.insertActividad del administrador Un usuario o una cuenta de servicio ha creado tu VM.
Continúa con el siguiente paso para identificar al usuario o la cuenta de servicio que creó tu VM. Para obtener información sobre cómo crear una VM, consulta el artículo Crear e iniciar una VM.
compute.instances.resetActividad del administrador Un usuario o una cuenta de servicio ha restablecido tu VM.
Ve al siguiente paso para identificar la cuenta de usuario o de servicio que ha detenido tu VM.
Revisa los campos
principalEmailde los registros de auditoría de Cloud para identificar al usuario o servicio que inició el apagado o el reinicio. En la siguiente tabla se incluyen los servicios gestionados de Google habituales que inician apagados o reinicios.Correo electrónico Descripción system@google.comUn evento del sistema ha provocado el apagado o el reinicio. project-number@cloudservices.gserviceaccount.comUn agente de servicio ha iniciado el apagado.
Para determinar desde qué proyecto ha iniciado el servicio el cierre, consulta el
project-numberdel agente de servicio.Para determinar qué servicio de Google ha enviado la solicitud, consulta el campo
protoPayload.requestMetadata.callerSuppliedUserAgent.Si un usuario ha activado el apagado o el reinicio, su dirección de correo aparecerá en el campo
principalEmail. Por ejemplo,cloudysanfrancisco@gmail.com.Los administradores pueden impedir que los usuarios cambien el estado de las VMs de un proyecto cambiando los permisos de gestión de identidades y accesos en las cuentas de usuario. Para obtener más información, consulta cómo conceder, cambiar y revocar el acceso a los recursos.
Monitorizar eventos del ciclo de vida de las VMs
Puedes monitorizar los eventos del ciclo de vida de las VMs (como los apagados, los reinicios y los errores del host) creando un panel de control de Cloud Monitoring.
Este panel te permite visualizar los eventos del sistema y las actividades de los administradores que se describen con más detalle en la sección Revisar registros de auditoría de este documento.
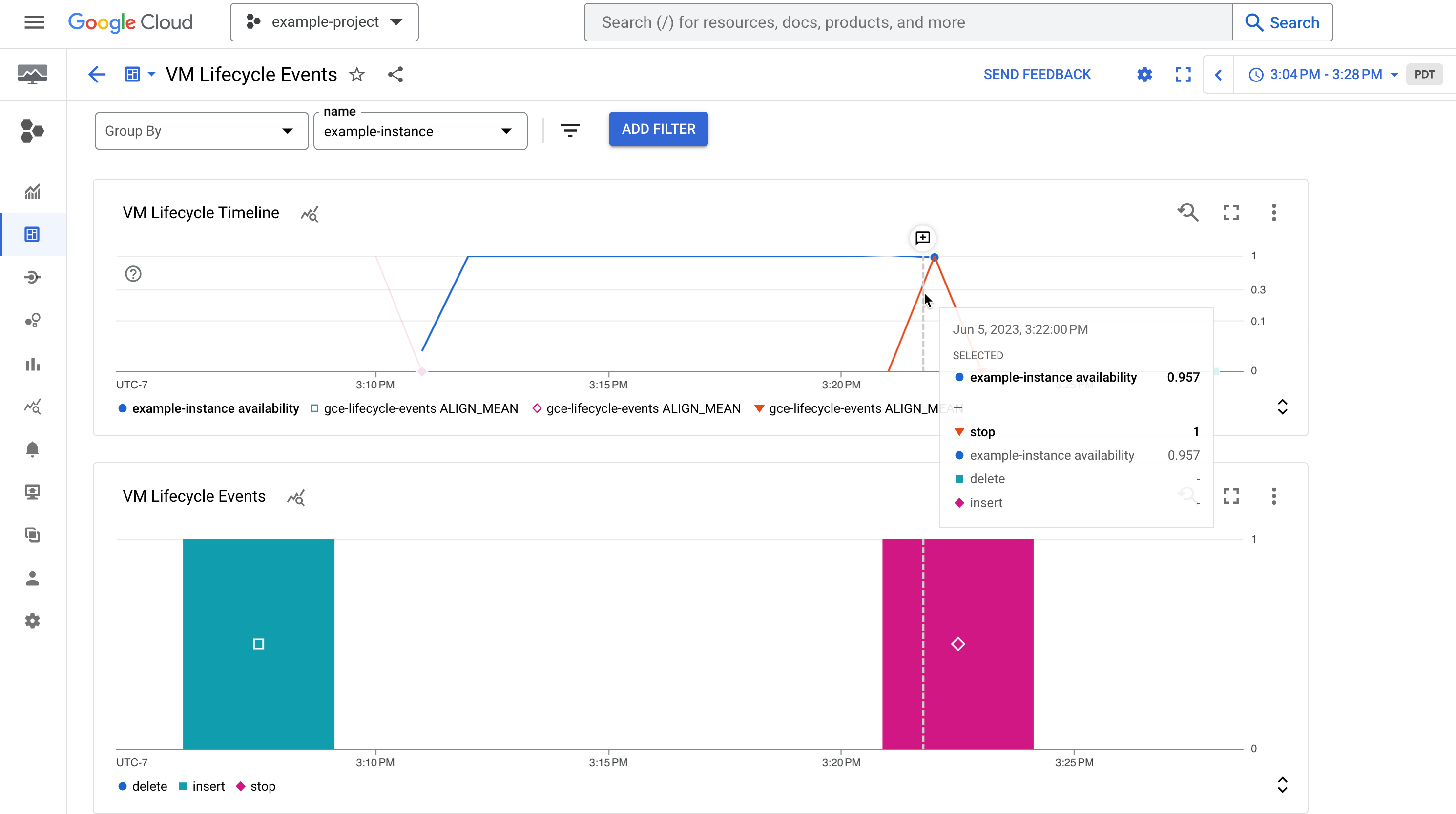 Imagen 1. Un panel de control de ejemplo que muestra la disponibilidad de una instancia y sus eventos del ciclo de vida, como una instancia detenida.
Imagen 1. Un panel de control de ejemplo que muestra la disponibilidad de una instancia y sus eventos del ciclo de vida, como una instancia detenida.Crear una métrica basada en registros
Para registrar eventos del ciclo de vida de las máquinas virtuales, cree una métrica basada en registros definida por el usuario. Esta métrica usa los registros de auditoría para contabilizar el número de veces que se ha producido un evento concreto del ciclo de vida de una máquina virtual.
Para obtener los permisos que necesitas para crear la métrica, pide a tu administrador que te conceda el rol de gestión de identidades y accesos Escritor de registros (
roles/logging.logWriter) en el proyecto. Para obtener más información sobre cómo conceder roles, consulta el artículo Gestionar el acceso a proyectos, carpetas y organizaciones.También puedes conseguir los permisos necesarios a través de roles personalizados u otros roles predefinidos.
Para crear una métrica basada en registros definida por el usuario, haz lo siguiente:
En la Google Cloud consola, ve a la página Métricas basadas en registros.
Haz clic en Crear métrica.
En la sección Tipo de métrica, haga lo siguiente:
- Selecciona
Counter. - Deje Distribución con el ajuste predeterminado (sin seleccionar).
En la sección Detalles, introduce la siguiente información:
- Nombre de la métrica basada en registros:
vm-lifecycle-events. Debes usar este nombre exacto para que el panel de control funcione correctamente. - Descripción: opcional. Escriba una descripción para esta métrica.
- Unidades:
1
En la sección Selección de filtros, especifique lo siguiente:
- En el menú Seleccionar proyecto o contenedor de registro, elija Registros de proyecto.
- En Crear filtro, introduce lo siguiente:
resource.type = "gce_instance" AND log_id("cloudaudit.googleapis.com/activity") OR log_id("cloudaudit.googleapis.com/system_event") operation.first="true"
En la sección Etiquetas, haz clic en Añadir etiqueta.
Especifica lo siguiente:
- Nombre de la etiqueta:
method - Tipo de etiqueta:
STRING - Nombre del campo:
protoPayload.methodName - Expresión regular:
(recreateInstance|hostError|automaticRestart|guestTerminate|terminateOnHostMaintenance|preempted|insert|stop|delete|reset|start)
- Nombre de la etiqueta:
Haz clic en Hecho.
Haz clic en Crear métrica.
Usar el panel de control
No aparecen datos en el panel de control hasta que una instancia experimenta un evento del sistema o una actividad de administrador. Para comprobar que el panel de control funciona, realiza una actividad de administrador, como una operación
stopystart:- Realiza una operación de
stopystarten cualquier instancia o crea una máquina virtual para hacer pruebas.
Para obtener los permisos que necesitas para usar el panel de control, pide a tu administrador que te asigne el rol de gestión de identidades y accesos Lector del panel de control de Monitoring (
roles/monitoring.dashboardViewer) en el proyecto. Para obtener más información sobre cómo conceder roles, consulta el artículo Gestionar el acceso a proyectos, carpetas y organizaciones.También puedes conseguir los permisos necesarios a través de roles personalizados u otros roles predefinidos.
Abre Paneles de control en la consola de Google Cloud .
En la pestaña Lista de paneles de control, abre el panel de control
GCE VM Lifecycle Events Monitoring.Selecciona la máquina virtual en el menú desplegable Nombre.
Acota la serie temporal a un periodo pertinente.
Para ver más formas de filtrar el panel de control, consulta Añadir un filtro temporal.
El panel de control contiene dos gráficos que muestran una cronología de los eventos del sistema y las actividades de los administradores que se producen en una instancia:
El gráfico Cronología del ciclo de vida de la VM muestra lo siguiente:
- La métrica
compute.googleapis.com/instance/uptimeindica si la máquina virtual estaba en funcionamiento en un momento dado. El valor 1 significa que estaba activa y el valor 0, que no. Ten en cuenta que esta métrica refleja la disponibilidad como resultado de la actividad de los usuarios y los eventos del sistema, y no es un indicador del acuerdo de nivel de servicio de Compute Engine. - La métrica basada en registros
vm-lifecycle-eventspara contar el número de acciones del ciclo de vida, comostopostart, que se han realizado en la instancia en un momento dado.
- La métrica
El gráfico Eventos muestra la misma métrica basada en registros
vm-lifecycle-events, pero en una vista ampliada para que sea más fácil de leer. Ten en cuenta que, aunque los ejes X están alineados, los colores no están sincronizados entre los dos gráficos.
Investigar el apagado masivo de VMs en varios proyectos
Compute Engine puede apagar varias VMs conectadas a un proyecto host de VPC compartida si la facturación del proyecto host de VPC compartida está inactiva o inhabilitada.
Para determinar si tus máquinas virtuales se han apagado debido a una solicitud de apagado masivo, busca operaciones de detención iniciadas por
cloud-cluster-manager@prod.google.com.Si inicias una instancia afectada, se devolverá un error similar al siguiente:
Starting instance(s) INSTANCE_NAME...failed. ERROR: (gcloud.compute.instances.start) The default network interface [nic0] is frozen.Para solucionar este problema, sigue estos pasos:
Identifica la VPC compartida que usan las VMs con el comando
gcloud compute instances describe:gcloud compute instances describe VM_NAME \ --format="flattened(networkInterfaces[].network)"
El resultado debería ser similar al siguiente:
networkInterfaces[0].network: https://www.googleapis.com/compute/v1/projects/SHARED_VPC_PROJECT/global/networks/FROZEN_NETWORK
Comprueba si la facturación se ha inhabilitado en el proyecto host de la VPC compartida.
resource.type="project" protoPayload.request.@type="type.googleapis.com/google.internal.cloudbilling.billingaccount.v1.DisableResourceBillingRequest" protoPayload.response.resourceBillingInfo.billingAccountAssignmentType="DISABLED"Si procede, habilita la facturación en el proyecto host.
Para evitar que este problema vuelva a ocurrir, consulta el artículo Proteger la vinculación entre un proyecto y su cuenta de facturación.
A menos que se indique lo contrario, el contenido de esta página está sujeto a la licencia Reconocimiento 4.0 de Creative Commons y las muestras de código están sujetas a la licencia Apache 2.0. Para obtener más información, consulta las políticas del sitio web de Google Developers. Java es una marca registrada de Oracle o sus afiliados.
Última actualización: 2025-10-18 (UTC).
-