VM にディスクを追加するには、Compute Engine が提供するブロック ストレージ オプションのいずれかを選択します。ストレージ オプションによって、料金と性能特性が異なります。
- Google Cloud Hyperdisk ボリュームは Compute Engine のネットワーク ストレージであり、パフォーマンスとボリュームを構成可能で、動的にサイズ変更できます。Persistent Disk と比較して、パフォーマンス、柔軟性、効率が大幅に向上します。Hyperdisk Balanced High Availability(プレビュー)では、2 つのゾーンにあるディスク間でデータを同期的にレプリケートし、ゾーンが利用不能になった場合でもデータを使用できるようにします。
- Hyperdisk ストレージ プールを使用すると、Hyperdisk の容量とパフォーマンスをまとめて購入し、このストレージ プールから VM 用のディスクを作成できます。
- Persistent Disk のボリュームは、高パフォーマンスで冗長性のあるネットワーク ストレージを提供します。各 Persistent Disk ボリュームは、何百もの物理ディスクにストライプ化されます。
- デフォルトでは、VM はゾーン Persistent Disk を使用し、
us-west1-cなどの単一ゾーン内にあるボリュームにデータを保存します。 - また、リージョン Persistent Disk ボリュームを作成すると、2 つのゾーンにあるディスク間でデータを同期的にレプリケートし、ゾーンが利用不能になった場合でもデータを使用できるようにします。
- デフォルトでは、VM はゾーン Persistent Disk を使用し、
- ローカル SSD ディスクは、VM と同じサーバーに直接アタッチされる物理ドライブです。パフォーマンスを改善できますが、一時的なものです。
費用比較については、ディスクの料金体系をご覧ください。どのオプションを使用すればよいかわからない場合、以前の世代のマシンシリーズでは、VM にバランス永続ディスク ボリュームを追加するのが最も一般的なソリューションです。最新のマシンシリーズでは、コンピューティング インスタンスに Hyperdisk ボリュームを追加するのが最も一般的なソリューションです。
Compute Engine には、ブロック ストレージに加えて、ファイル ストレージとオブジェクト ストレージのオプションがあります。ストレージ オプションを確認して比較するには、ストレージ オプションを確認するをご覧ください。
はじめに
Compute Engine の各 VM には、デフォルトでオペレーティング システムを格納しているブートディスクが 1 つあります。通常、ブートディスクのデータは、 Persistent Disk ボリュームまたはHyperdisk Balanced ボリュームに保存されます。アプリケーションに追加の保存容量が必要な場合は、次のストレージ ボリュームのうち 1 つ以上を VM にプロビジョニングできます。
各ストレージ オプションの詳細については、次の表をご覧ください。
| バランス Persistent Disk |
SSD Persistent Disk |
標準 Persistent Disk |
エクストリーム Persistent Disk |
Hyperdisk Balanced | Hyperdisk ML | Hyperdisk Extreme | Hyperdisk Throughput | ローカル SSD | |
|---|---|---|---|---|---|---|---|---|---|
| ストレージの種類 | 費用対効果に優れた信頼性の高いブロック ストレージ | 高速で信頼性の高いブロック ストレージ | 効率的で信頼性の高いブロック ストレージ | IOPS をカスタマイズ可能で最高水準のパフォーマンスを実現する Persistent Disk ブロック ストレージ オプション | 要求の厳しいワークロード向けの高パフォーマンスで予算も抑えられる | ML ワークロード用に最適化された最も高スループットのストレージ。 | IOPS をカスタマイズ可能で最速のブロック ストレージ オプション | スループットをカスタマイズ可能でコスト効率に優れたスループット指向のブロック ストレージ | 高パフォーマンスのローカル ブロック ストレージ |
| ディスク 1 つあたりの最小容量 | ゾーン: 10 GiB リージョン: 10 GiB |
ゾーン: 10 GiB リージョン: 10 GiB |
ゾーン: 10 GiB リージョン: 200 GiB |
500 GiB | ゾーンとリージョン: 4 GiB | 4 GiB | 64 GiB | 2 TiB | Z3 で 375 GiB、3 TiB |
| ディスク 1 つあたりの最大容量 | 64 TiB | 64 TiB | 64 TiB | 64 TiB | 64 TiB | 64 TiB | 64 TiB | 32 TiB | Z3 で 375 GiB、 3 TiB |
| 容量の増分 | 1 GiB | 1 GiB | 1 GiB | 1 GiB | 1 GiB | 1 GiB | 1 GiB | 1 GiB | マシンタイプに応じて異なる† |
| VM あたりの最大容量 | 257 TiB* | 257 TiB* | 257 TiB* | 257 TiB* | 512 TiB* | 512 TiB* | 512 TiB* | 512 TiB* | 36 TiB |
| アクセス範囲 | ゾーン | ゾーン | ゾーン | ゾーン | ゾーン | ゾーン | ゾーン | ゾーン | インスタンス |
| データ冗長性 | ゾーンとマルチゾーン | ゾーンとマルチゾーン | ゾーンとマルチゾーン | ゾーン | ゾーンとマルチゾーン | ゾーン | ゾーン | ゾーン | なし |
| 保存データの暗号化 | ○ | はい | はい | はい | はい | はい | はい | はい | ○ |
| カスタム暗号鍵 | ○ | はい | はい | ○ | ○‡ | ○ | はい | ○ | × |
| 入門 | エクストリーム永続ディスクを追加する | ローカル SSD を追加する | |||||||
Google Cloud が提供するストレージ オプション以外にも、他のストレージ ソリューションを VM にデプロイできます。
- Compute Engine 上にファイル サーバーまたは分散ファイル システムを作成し、ネットワーク ファイル システムとして NFSv3 と SMB3 の機能とともに使用します。
- VM メモリ内に RAM ディスクをマウントし、高スループットかつ低レイテンシのブロック ストレージ ボリュームを作成します。
各ブロック ストレージ リソースのパフォーマンス特性はそれぞれ異なります。VM に適したブロック ストレージのタイプを決定する際は、ストレージ サイズとパフォーマンス要件を考慮してください。
パフォーマンスの上限については、以下をご覧ください。
Persistent Disk
Persistent Disk ボリュームは耐久性のあるネットワーク ストレージ デバイスであり、パソコンやサーバーの物理ディスクと同様に仮想マシン(VM)インスタンスからアクセスできます。Persistent Disk ボリューム上のデータは、複数の物理ディスクに分散されます。Compute Engine は物理ディスクとデータ分散を管理して、冗長性と最適なパフォーマンスを確保します。
Persistent Disk ボリュームは VM とは独立して存在するため、VM を削除した後でも、Persistent Disk ボリュームを切断または移動してデータを保持できます。Persistent Disk のパフォーマンスはサイズに合わせて自動的にスケールされるため、既存の Persistent Disk ボリュームのサイズを変更するか、VM に Persistent Disk ボリュームを追加してパフォーマンスとストレージ容量の要件を満たすことができます。
永続ディスクのタイプ
永続ディスクを構成するときに、次のいずれかのディスクタイプを選択できます。
- バランス永続ディスク(
pd-balanced)- パフォーマンス(pd-ssd)永続ディスクの代替手段。
- パフォーマンスと費用のバランス。大規模なものを除き、ほとんどの VM シェイプの場合、これらのディスクの最大 IOPS は SSD 永続ディスクと同じですが、GiB あたりの IOPS は小さくなります。このディスクタイプは、ほとんどの汎用アプリケーションに適したパフォーマンスを、標準永続ディスクとパフォーマンス(pd-ssd)永続ディスクの中間の価格で提供します。
- ソリッド ステート ドライブ(SSD)によるバックアップ。
- パフォーマンス(SSD)永続ディスク(
pd-ssd)- 標準永続ディスクの場合よりも低いレイテンシと高い IOPS を必要とする、エンタープライズ アプリケーションや高パフォーマンス データベースに適している。
- ソリッド ステート ドライブ(SSD)によるバックアップ。
- 標準永続ディスク(
pd-standard)- シーケンシャル I/O を主に使用する大規模なデータ処理ワークロードに適している。
- 標準ハードディスク ドライブ(HDD)によるバックアップ。
- エクストリーム永続ディスク(
pd-extreme)- ランダム アクセス ワークロードとバルク スループットの両方に対応し、一貫して高いパフォーマンスを発揮。
- ハイエンド データベースのワークロード向けに設計。
- ターゲット IOPS をプロビジョニング可能。
- ソリッド ステート ドライブ(SSD)によるバックアップ。
- 限られた数のマシンタイプで使用。
Google Cloud コンソールでディスクを作成する場合、デフォルトのディスクタイプは pd-balanced です。gcloud CLI または Compute Engine API を使用してディスクを作成する場合、デフォルトのディスクタイプは pd-standard です。
マシンタイプのサポートについては、以下をご覧ください。
永続ディスクの耐久性
ディスクの耐久性は、ハードウェアの障害、壊滅的なイベント、Google データセンターでの隔離方法とエンジニアリング プロセス、各ディスクタイプで使用される内部エンコードによって、通常の 1 年間に一般的なディスクでデータ損失が発生する可能性を表します。永続ディスクのデータ損失が発生することは極めて稀ですが、これまで発生したケースを見ると、調整済みのハードウェアの故障、ソフトウェアのバグ、またはその 2 つが原因で発生しています。また、Google は、業界全体のサイレント データ破損のリスクを軽減するために多くの対策を講じています。お客様が誤ってディスクを削除した場合など、Google Cloud のユーザーによるエラーは、永続ディスクの耐久性の対象外です。
リージョン永続ディスクでは、内部データのエンコードとレプリケーションにより、データ損失が生じるリスクはほとんどありません。リージョン永続ディスクはゾーン永続ディスクの 2 倍のレプリカを備えています。レプリカは、同じリージョン内の 2 つのゾーンに分散されます。これにより、高可用性を実現し、データセンター全体が消失して復元できない場合でも(ただし、この現象はこれまで発生したことはありません)、障害復旧に使用できます。長期間のサービス停止中にプライマリ ゾーンが使用不能になった場合は、2 番目のゾーンの追加レプリカに直ちにアクセスできます。
耐久性はディスクタイプごとに集計されたものであり、返金制度のあるサービスレベル契約(SLA)を表すものではありません。
以下の表は、ディスクタイプごとの耐久性を示しています。99.999% の耐久性とは、1,000 枚のディスクがあれば、100 年間 1 枚も失わずに済む可能性があるということです。
| ゾーン標準永続ディスク | ゾーンバランス永続ディスク | ゾーン SSD 永続ディスク | ゾーン エクストリーム永続ディスク | リージョン標準永続ディスク | リージョン バランス永続ディスク | リージョン SSD 永続ディスク |
|---|---|---|---|---|---|---|
| 99.99% を上回る | 99.999% を上回る | 99.999% を上回る | 99.9999% を上回る | 99.999% を上回る | 99.9999% を上回る | 99.9999% を上回る |
ゾーン永続ディスク
使いやすさ
Compute Engine はほとんどのディスク管理タスクを自動的に処理するため、パーティショニング、冗長ディスクアレイ、サブボリューム管理などについて考える必要はありません。一般的に、より大きい論理ボリュームを作成する必要はありませんが、必要に応じて、追加で接続する Persistent Disk 容量を VM あたり 257 TiB に拡張し、Persistent Disk ボリュームに適用できます。パーティション テーブルを使用せずに 1 つのファイル システムで Persistent Disk ボリュームをフォーマットすることで、時間を節約して最適なパフォーマンスを得ることができます。
データを複数の固有ボリュームに分ける必要がある場合は、既存のディスクを複数のパーティションに分割するのではなく、追加ディスクを作成します。
永続ディスク ボリュームの容量を増やす必要がある場合は、再パーティショニングしてフォーマットするのではなく、ディスクのサイズを変更します。
パフォーマンス
Persistent Disk のパフォーマンスは予測可能であり、VM のプロビジョニングされた vCPU の上限に達するまで、プロビジョニングされた容量に比例してスケールします。パフォーマンスのスケーリングの上限と最適化について詳しくは、パフォーマンス要件を満たすようにディスクを構成するをご覧ください。
標準永続ディスク ボリュームは、順次読み取り / 書き込みオペレーションの処理には効率的かつ経済的な選択肢ですが、1 秒あたりのランダム入出力オペレーション(IOPS)量が多い処理には不向きです。大量のランダム IOPS が必要なアプリでは、SSD またはエクストリーム永続ディスクを使用します。SSD 永続ディスクは、レイテンシが 1 桁のミリ秒となるよう設計されています。観測されるレイテンシはアプリケーション固有です。
Compute Engine は、永続ディスク ボリュームのパフォーマンスとスケーリングを自動的に最適化します。最高のパフォーマンスを得るために、複数のディスクをストライプ化したり、ディスクのプリウォームを行ったりする必要はありません。より多くのディスク容量やより高いパフォーマンスが必要な場合は、ディスクのサイズを変更して、さらに vCPU を追加することで、ストレージ容量、スループット、および IOPS を増やします。Persistent Disk のパフォーマンスは、VM に接続された Persistent Disk の合計容量と VM が保持する vCPU の数に基づいています。
ブートデバイスの場合は、標準 Persistent Disk を使用してコストを削減できます。小規模な 10 GiB の永続ディスク ボリュームは、基本的なブートおよびパッケージ管理のユースケースに適しています。ただし、ブートデバイスの一般的な使用で一貫したパフォーマンスを確保するには、ブートディスクとしてバランス Persistent Disk を使用します。
Persistent Disk への書き込みオペレーションを行うたびに、VM の累積ネットワーク下りトラフィックが増加します。つまり、Persistent Disk の書き込みオペレーションは、VM に対する下り(外向き)ネットワークの上限によって制限されます。
信頼性
永続ディスクには冗長性が組み込まれており、機器の故障からデータを保護し、データセンターのメンテナンス中でもデータの可用性を確保します。永続ディスクのすべてのオペレーションでチェックサムが計算されるため、読み取ったデータは書き込んだデータと必ず一致します。
さらに、Persistent Disk のスナップショットを作成して、ユーザーエラーによりデータが失われるのを防ぐことができます。スナップショットは増分なので、実行中の VM にアタッチされているディスクのスナップショットを作成する場合であっても数分しかかかりません。
マルチライター モード
マルチライター モードでは SSD 永続ディスクを同時に最大 2 台の N2 VM にアタッチできるため、両方の VM でディスクの読み取りと書き込みが可能になります。
マルチライター モードの永続ディスクは、共有ブロック ストレージ機能を備えており、高可用性の共有ファイル システムとデータベースを構築するためのインフラストラクチャ基盤としての役割を果たします。このような専用のファイル システムとデータベースは、共有ブロック ストレージと連携して機能し、SCSI 永続予約などのツールを使用して VM 間のキャッシュ整合性を処理するように設計する必要があります。
ただし、マルチライター モードの Persistent Disk は通常直接使用しないでください。また、EXT4、XFS、NTFS などの多くのファイル システムは共有ブロック ストレージで使用するようには設計されていない点に注意する必要があります。VM 間で Persistent Disk を共有するためのベスト プラクティスについては、ベスト プラクティスをご覧ください。
フルマネージドのファイル ストレージが必要な場合は、Compute Engine VM に Filestore ファイル共有をマウントできます。
新しい永続ディスク ボリュームでマルチライター モードを有効にするには、新しい永続ディスクを作成し、gcloud CLI に --multi-writer フラグを指定するか、か、Compute Engine API に multiWriter プロパティを指定します。詳細については、VM 間で永続ディスク ボリュームを共有するをご覧ください。
永続ディスクの暗号化
Compute Engine は、データが VM の外部から永続ディスクのストレージ領域に移される前にデータを自動的に暗号化します。各永続ディスクは常に、システム定義の暗号鍵または顧客指定の暗号鍵のいずれかで暗号化された状態になっています。永続ディスクデータは複数の物理ディスクに分散されます。分散の方法はユーザーによって制御されません。
永続ディスクを削除すると、Google は暗号鍵を破棄し、データを回復不能にします。このプロセスは元に戻せません。
データの暗号化に使用される暗号鍵を制御する必要がある場合は、顧客指定の暗号鍵でディスクを作成します。
制限事項
別のプロジェクトの VM に Persistent Disk ボリュームを接続することはできません。
最大 10 個の VM にバランス Persistent Disk を読み取り専用モードでアタッチできます。
カスタム マシンタイプか、最小 1 vCPU の事前定義されたマシンタイプの場合、最大で 128 個の Persistent Disk ボリュームを接続できます。
各 Persistent Disk ボリュームの最大サイズは 64 TiB であるため、大きな論理ボリュームを作成するためにディスクのアレイを管理する必要はありません。各 VM が接続できる Persistent Disk の合計容量と個別の Persistent Disk ボリュームの数には上限があります。Persistent Disk の上限は、事前定義されたマシンタイプとカスタム マシンタイプで同じです。
ほとんどの VM で最大 128 TiB の Persistent Disk と、最大 257 TiB のディスク容量を接続できます。VM の合計ディスク容量には、ブートディスクのサイズが含まれます。
共有コア マシンタイプは、16 個の Persistent Disk ボリュームと 3 TiB の合計 Persistent Disk 容量に制限されています。
64 TiB を超える論理ボリュームを作成する場合は、特に考慮しなければならない場合があります。大容量論理ボリュームのパフォーマンスの詳細については、論理ボリューム サイズをご覧ください。
リージョン Persistent Disk
リージョン永続ディスク ボリュームのストレージ品質は、ゾーン永続ディスクと同様です。ただし、リージョン Persistent Disk ボリュームを使用すると、同じリージョン内の 2 つのゾーン間で耐久性の高いデータ ストレージとデータ レプリケーションを実現できます。
ディスクの同期レプリケーションについて
新しい Persistent Disk を作成する場合、1 つのゾーンにディスクを作成することも、同じリージョン内の 2 つのゾーンにディスクをレプリケーションすることもできます。
たとえば、us-west1-a のようにゾーンにディスクを 1 つ作成すると、ディスクのコピーが 1 つ作成されます。これはゾーンディスクと呼ばれます。ディスクの可用性を高めるには、リージョン内の別のゾーン(us-west1-b など)にディスクの別のコピーを保存します。
同じリージョン内の 2 つのゾーンにレプリケートされた Persistent Disk は、リージョン Persistent Disk と呼ばれます。Hyperdisk Balanced High Availability を使用して、Google Cloud Hyperdisk のゾーン間同期レプリケーションを行うこともできます。
1 つのリージョンが完全に停止することはほとんどありませんが、ゾーンの障害は発生する可能性があります。次の図に示すように、異なるゾーンにあるリージョン内でレプリケーションを行うと、可用性が向上し、ディスク レイテンシが短縮されます。両方のレプリケーション ゾーンで障害が発生した場合、リージョン全体の障害とみなされます。
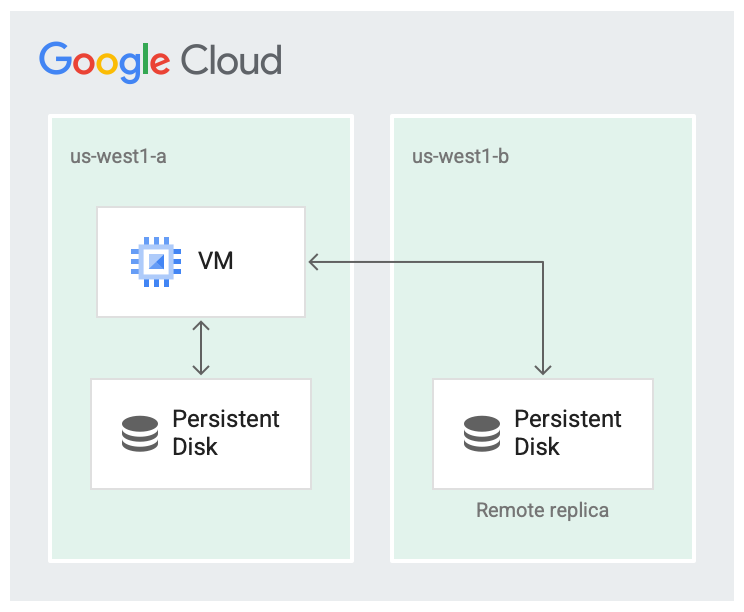
ディスクが 2 つのゾーンにレプリケートされている。
レプリケーションのシナリオでは、データは、仮想マシン(VM)が実行されているローカルゾーン(us-west1-a)で利用できます。その後、データは別のゾーン(us-west1-b)にレプリケートされます。ゾーンの 1 つは、VM が実行されているゾーンと同じにする必要があります。
ゾーンが停止した場合、通常は、リージョン Persistent Disk で実行されているワークロードを別のゾーンにフェイルオーバーできます。詳しくは、リージョン Persistent Disk のフェイルオーバーをご覧ください。
リージョン Persistent Disk の設計上の考慮事項
Compute Engine で堅牢なシステムや高可用性サービスを設計する場合は、リージョン Persistent Disk を使用するだけでなく、スナップショットを使用してデータをバックアップするなど、他のベスト プラクティスを取り入れる必要があります。また、リージョン Persistent Disk ボリュームは、リージョン マネージド インスタンス グループと連携するように設計されています。
パフォーマンス
リージョン Persistent Disk ボリュームは、永続ディスクのスナップショットを使用する場合よりも低い目標復旧時点(RPO)と目標復旧時間(RTO)を必要とするワークロード用に設計されています。
リージョン Persistent Disk は、複数のゾーンにわたるデータ冗長性よりも書き込みパフォーマンスが重要でない場合のオプションです。
ゾーン Persistent Disk と同様に、リージョン Persistent Disk は VM の vCPU 数が多いほど高い IOPS とスループット パフォーマンスを達成できます。この制限とその他の制限の詳細については、パフォーマンス要件を満たすようにディスクを構成するをご覧ください。
より多くのディスク容量またはより高いパフォーマンスが必要なときは、ディスクのサイズを変更して、容量、スループット、IOPS を増強できます。
信頼性
Compute Engine は、リージョン永続ディスクのデータを、ディスクの作成時に選択したゾーンに複製します。各レプリカのデータは、冗長性を確保するためにゾーン内の複数の物理マシンに分散されます。
ゾーン Persistent Disk と同様に、Persistent Disk のスナップショットを作成して、ユーザーエラーによるデータの損失から保護できます。スナップショットは増分なので、実行中の VM にアタッチされているディスクのスナップショットを作成する場合であっても数分しかかかりません。
制限事項
- リージョン Persistent Disk をアタッチできるのは、E2、N1、N2、N2D のマシンタイプを使用する VM のみです。
- Hyperdisk Balanced High Availability は、サポートされているマシンタイプにのみ接続できます。
- リージョン Persistent Disk をイメージから作成することはできません。イメージから作成されたディスクから作成することもできません。
- 読み取り専用モードを使用すると、最大 10 個の VM インスタンスにリージョン バランス Persistent Disk をアタッチできます。
- リージョン標準永続ディスクの最小サイズは 200 GiB です。
- リージョン Persistent Disk またはHyperdisk Balanced High Availability ボリュームのサイズを増やすことはできますが、縮小はできません。
- リージョン Persistent Disk と Hyperdisk Balanced High Availability ボリュームのパフォーマンス特性は、対応するゾーンディスクとは異なります。詳細については、ブロック ストレージのパフォーマンスをご覧ください。
- マルチライター モードの Hyperdisk Balanced High Availability ボリュームをブートディスクとして使用することはできません。
- ゾーンディスクのクローンを作成してレプリケートされたディスクを作成する場合、2 つのゾーンレプリカは作成時には完全には同期しません。作成後、リージョン ディスクのクローンは平均で 3 分以内に使用できるようになります。ただし、ディスクが完全にレプリケートされた状態になり、目標復旧時点(RPO)がゼロに近くなるまで、数十分かかる場合があります。詳細については、レプリケートされたディスクが完全にレプリケートされたかどうかを確認する方法をご覧ください。
Google Cloud Hyperdisk
Google Cloud Hyperdisk は Google の次世代ブロック ストレージです。ストレージ処理をオフロードして動的にスケールアウトすることで、ストレージのパフォーマンスを VM のタイプやサイズから切り離します。Hyperdisk は、Persistent Disk と比べて、パフォーマンス、柔軟性、効率を大幅に向上させます。
Hyperdisk Balanced
Compute Engine 向けの Hyperdisk Balanced は、事業部門(LOB)アプリケーション、ウェブ アプリケーション、Hyperdisk Extreme のパフォーマンスを必要としない中規模のデータベースなど、幅広いユースケースに適しています。同じゾーン内の複数の VM が同じディスクへの書き込みアクセスを同時に必要とするアプリケーションには、Hyperdisk Balanced を使用できます。
Hyperdisk Balanced ボリュームを使用すると、ワークロードの容量、IOPS、スループットを動的に調整できます。
Hyperdisk ML
アクセラレータを使用して ML モデルをトレーニングまたは提供するワークロードには、Hyperdisk ML を使用する必要があります。Hyperdisk ML ボリュームは、カスタマイズ可能なスループットが最も速く、20 GiB を超えるモデルに最適です。Hyperdisk ML は、複数の VM から同じボリュームへの同時読み取りアクセスもサポートしています。
Hyperdisk ML ボリュームの容量とスループットは動的に調整できます。
Hyperdisk Extreme
Hyperdisk Extreme は利用可能な最速のブロック ストレージを提供します。最高水準のスループットと IOPS を必要とするハイエンド ワークロードに適しています。
Hyperdisk Extreme ボリュームを使用すると、ワークロードの容量と IOPS を動的に調整できます。
Hyperdisk Throughput
Hyperdisk Throughput は、Hadoop や Kafka、コストが重視されるアプリのデータドライブ、コールド ストレージなどのスケールアウト分析に適しています。
Hyperdisk Throughput ボリュームを使用すると、ワークロードの容量とスループットを動的に調整できます。ダウンタイムやワークロードの中断なしに、プロビジョニングされたスループット レベルを変更できます。
Hyperdisk Balanced High Availability(プレビュー)
Hyperdisk Balanced High Availability により、第 3 世代以降のマシンシリーズで同期レプリケーションが有効になります。Hyperdisk Balanced High Availability では、リージョン Persistent Disk と同様に、2 つのゾーンにまたがる RPO=0 レプリケーションでデータの復元力を実現します。
Hyperdisk Balanced High Availability ボリュームを使用すると、ワークロードの容量、IOPS、スループットを動的に調整できます。ダウンタイムやワークロードの中断なしに、プロビジョニングされたパフォーマンスと容量のレベルを変更できます。同じリージョン内の複数の VM が同じディスクへの書き込みアクセスを同時に必要とする場合は、Hyperdisk Balanced High Availability を使用します。
Hyperdisk ボリュームは Persistent Disk と同様に作成、管理されます。また、プロビジョニングされた IOPS またはスループット レベルを設定するための追加の機能が用意され、その値をいつでも変更できます。Persistent Disk から Hyperdisk に直接移行することはできません。代わりに、スナップショットを作成して新しい Hyperdisk ボリュームに復元できます。
Hyperdisk の詳細については、Hyperdisk についてをご覧ください。
Hyperdisk の耐久性
ディスクの耐久性は、一般的な年における一般的なディスクのデータ損失確率(設計上)を表します。耐久性は、ハードウェア障害に関する次のような一連の前提条件を使用して計算されます。
- 壊滅的なイベントの可能性
- 分離方法
- Google データセンターのエンジニアリング プロセス
- 各ディスクタイプで使用される内部エンコーディング
Hyperdisk のデータ損失イベントは極めて希です。また、Google は、業界全体のサイレント データ破損のリスクを軽減するために多くの対策を講じています。
お客様が誤ってディスクを削除した場合など、Google Cloud のユーザーによるエラーは、Hyperdisk の耐久性の対象外です。
以下の表は、ディスクタイプごとの耐久性を示しています。99.999% の耐久性とは、1,000 枚のディスクがあれば、100 年間 1 枚も失わずに済む可能性があるということです。
| バランス Hyperdisk | Hyperdisk Extreme | Hyperdisk ML | Hyperdisk Throughput |
|---|---|---|---|
| 99.999% を上回る | 99.9999% を上回る | 99.999% を上回る | 99.999% を上回る |
Hyperdisk の暗号化
Compute Engine は、Hyperdisk ボリュームへの書き込み時にデータを自動的に暗号化します。
Hyperdisk Balanced High Availability
Hyperdisk Balanced High Availability ディスクでは、同じリージョン内の 2 つのゾーン間で耐久性の高いデータ ストレージとレプリケーションが提供されます。Hyperdisk Balanced High Availability ボリュームには、レプリケートされていない Hyperdisk Balanced ディスクと同様のストレージ上限があります。
Compute Engine で堅牢なシステムや高可用性サービスを設計する場合は、Hyperdisk Balanced High Availability ディスクを使用するだけでなく、スナップショットを使用してデータをバックアップするなど、他のベスト プラクティスを取り入れる必要があります。Hyperdisk Balanced High Availability ディスクは、リージョン マネージド インスタンス グループと連携するように設計されています。
万一ゾーンが停止した場合、--force-attach フラグを使用することにより、Hyperdisk Balanced High Availability ディスクで実行されているワークロードを別のゾーンにフェイルオーバーできます。--force-attach フラグを使用すると、元のコンピューティング インスタンスが使用できないためにディスクをそのインスタンスから切断できない場合でも、Hyperdisk Balanced High Availability ディスクをスタンバイ インスタンスにアタッチできます。詳細については、同期レプリケートされたディスクのフェイルオーバーをご覧ください。
パフォーマンス
Hyperdisk Balanced High Availability ディスクは、復元に Hyperdisk スナップショットを使用する場合よりも低い目標復旧時点(RPO)と目標復旧時間(RTO)を必要とするワークロード用に設計されています。
Hyperdisk Balanced High Availability ディスクは、書き込みパフォーマンスよりも、複数のゾーンにわたるデータ冗長性のほうが重要な場合のオプションです。
Hyperdisk Balanced High Availability ディスクには、カスタマイズ可能な IOPS とスループット パフォーマンスがあります。Hyperdisk Balanced High Availability のパフォーマンスと制限事項の詳細については、Hyperdisk についてをご覧ください。
より多くのディスク容量またはより高いパフォーマンスが必要な場合は、Hyperdisk Balanced High Availability ディスクを変更して、容量、スループット、IOPS を増強できます。
信頼性
Compute Engine は、Hyperdisk Balanced High Availability ディスクのデータをディスクの作成時に指定したゾーンにレプリケートします。各レプリカのデータは、冗長性を確保するために、ゾーン内の複数の物理マシンに分散されます。
Hyperdisk と同様に、Hyperdisk Balanced High Availability ディスクのスナップショットを作成して、ユーザーエラーによるデータの損失から保護できます。スナップショットは増分なので、実行中の VM にアタッチされているディスクのスナップショットを作成する場合であっても数分しかかかりません。
VM 間での Hyperdisk ボリュームの共有
特定の Hyperdisk ボリュームについては、ディスク共有を有効にすることで、複数の VM からボリュームへの同時アクセスを有効にできます。ディスク共有はさまざまなユースケースで役立ちます。たとえば、高可用性アプリケーションを構築する場合や、複数の VM が同じモデルまたはトレーニング データにアクセスする必要がある大規模な ML ワークロードなどがあげられます。
詳細については、VM 間でディスクを共有するをご覧ください。
Hyperdisk ストレージ プール
Hyperdisk ストレージ プールを使用すると、ブロック ストレージの総所有コスト(TCO)を簡単に削減し、ブロック ストレージの管理を簡素化できます。Hyperdisk ストレージ プールを使用すると、プロジェクト 1 つあたり最大 1,000 個のディスクで、容量とパフォーマンスのプールを共有できます。ストレージ プールではシン プロビジョニングとデータ削減の各機能を使用できるため、効率を高めることができます。ストレージ プールを使用すると、オンプレミス SAN のクラウドへの移行を簡素化できます。また、ワークロードに必要な容量とパフォーマンスを簡単に提供することもできます。
特定のゾーンにあるプロジェクトのすべてのワークロードの推定容量と推定パフォーマンスでストレージ プールを作成します。次に、このストレージ プールにディスクを作成し、既存の VM にディスクをアタッチします。新しい VM の作成の一環として、ストレージ プールにディスクを作成することもできます。各ストレージ プールには、Hyperdisk Throughput など、1 種類のディスクがあります。Hyperdisk ストレージ プールには次の 2 種類があります。
- Hyperdisk Balanced ストレージ プール: Hyperdisk Balanced ディスクでの処理に最適な汎用ワークロードに使用
- Hyperdisk Throughput ストレージ プール: Hyperdisk Throughput ディスクでの処理に最適なストリーミング、コールドデータ、分析ワークロードに使用
容量のプロビジョニング オプション
Hyperdisk Storage Pool の容量は、次の 2 つの方法のいずれかでプロビジョニングできます。
- 標準的な容量のプロビジョニング
- 標準的な容量のプロビジョニングでは、すべてのディスクの合計サイズがストレージ プールのプロビジョニングされた容量に達するまで、ストレージ プールにディスクを作成します。標準容量プロビジョニングを使用するストレージ プールのディスクは、非プールディスクと同様に容量を消費します。容量はディスクの作成時に消費されます。
- 高度な容量のプロビジョニング
高度な容量プロビジョニングを使用すると、ストレージ プール内のすべてのディスクにシン プロビジョニングとデータ削減ストレージ容量のプールを共有できます。ストレージ プールのプロビジョニング容量に応じて課金されます。
ストレージ プールがプロビジョニングした容量の最大 500% を、高度な容量のストレージ プール内のディスクにプロビジョニングできます。ストレージ プールの容量を消費するのは、ストレージ プール内のディスクに書き込まれたデータ量のみです。データの自動削減により、ストレージ プール容量の消費量をさらに削減できます。
Advanced の容量ストレージ プールの容量使用率がプロビジョニングされた容量の 80% に達すると、Hyperdisk Storage Pool は、容量不足に関連するエラーを回避するために、ストレージ プールに容量を自動的に追加しようとします。
例
プロビジョニングされた容量が 10 TiB あるストレージ プールがあるとします。
標準的な容量のプロビジョニング:
- ストレージ プールにディスクを作成するときに、最大 10 TiB の Hyperdisk 容量をプロビジョニングできます。ストレージ プールのプロビジョニング済み容量 10 TiB に対して課金されます。
- ストレージ プールにサイズが 5 TiB のディスクを 1 つ作成し、ディスクに 2 TiB を書き込むと、ストレージ プールの使用容量は 5 TiB になります。
高度な容量のプロビジョニング:
- ストレージ プールにディスクを作成するときに、最大 50 TiB の Hyperdisk 容量をプロビジョニングできます。ストレージ プールのプロビジョニング済み容量 10 TiB に対して課金されます。
- ストレージ プールにサイズが 5 TiB のディスクを 1 つ作成し、ディスクに 3 TiB のデータを書き込み、データ削減により書き込まれるデータ量が 2 TiB に削減された場合、ストレージ プールの使用容量は 2 TiB になります。
パフォーマンス プロビジョニング オプション
Hyperdisk Storage Pool のパフォーマンスは、次の 2 つの方法のいずれかでプロビジョニングできます。
- 標準パフォーマンスのプロビジョニング
標準パフォーマンスは、次のタイプのワークロードに最適です。
- ストレージ プールのリソースによってパフォーマンスが制限されている場合に成功しないワークロード
- ストレージ プール内のディスクでパフォーマンスの急増が発生する可能性が高いワークロード(毎朝使用率がピークになるデータベースのデータディスクなど)
標準パフォーマンスのストレージ プールはシン プロビジョニングのメリットがなく、パフォーマンスの TCO を大幅に削減することはできません。標準パフォーマンスのプロビジョニングでは、すべてのディスクにプロビジョニングされた IOPS またはスループットの合計がストレージ プールにプロビジョニングされた量に達するまで、ストレージ プールにディスクを作成します。標準パフォーマンスのプロビジョニングを使用するストレージ プールのディスクは、ディスクの作成時に IOPS とスループットの量をプロビジョニングする非プールディスクと同様に IOPS とスループットを消費します。ストレージ プールにプロビジョニングされた IOPS とスループットの合計に対して課金されます。
標準パフォーマンスの Hyperdisk Balanced ストレージ プールでは、ストレージ プール内の各ディスクの最初の 3,000 IOPS と 140 MiBps のスループット(ベースライン)は、ストレージ プールのリソースを消費しません。ストレージ プールにディスクを作成すると、ベースライン値を超える IOPS とスループットは、ストレージ プールから IOPS とスループットを消費します。
標準パフォーマンスのストレージ プールで作成されたディスクは、他のストレージ プールとパフォーマンス リソースを共有しません。ストレージ プール内のすべてのディスクのパフォーマンスの合計量は、ストレージ プールでプロビジョニングされた IOPS またはスループットの合計を超えることはできません。
- 高パフォーマンスのプロビジョニング
高パフォーマンスのプロビジョニングを使用するストレージ プールは、シン プロビジョニングを利用してパフォーマンス効率を高め、ブロック ストレージのパフォーマンスの TCO を削減します。高パフォーマンスのプロビジョニングでは、プロビジョニングされたパフォーマンスのプールをストレージ プール内のすべてのディスクで共有できます。ストレージ プール内のディスクがデータの読み取りと書き込みを行う際に、ストレージ プールはパフォーマンス リソースを動的に割り当てます。ストレージ プール内のディスクで使用される IOPS とスループットの量だけ、ストレージ プールの IOPS とスループットが消費されます。高パフォーマンスのストレージ プールはシン プロビジョニングされているため、ストレージ プールにプロビジョニングした IOPS またはスループットよりも多くの IOPS またはスループット(ストレージ プールにプロビジョニングされた IOPS またはスループットの最大 500%)をストレージ プール内のディスクに割り当てることができます。標準パフォーマンスと同様に、ストレージ プールにプロビジョニングされた IOPS とスループットに対して課金されます。
高パフォーマンスのプロビジョニングを使用する Hyperdisk Balanced ストレージ プールでは、ディスクにベースライン パフォーマンスはありません。ストレージ プール内の Hyperdisk Balanced ディスクの読み取りオペレーションと書き込みオペレーションはすべて、プールのリソースを消費します。
ストレージ プール内のすべてのディスクのパフォーマンスの合計使用率が、ストレージ プールにプロビジョニングされたパフォーマンスの合計量に達すると、ディスクでパフォーマンス競合が発生する可能性があります。このため、高パフォーマンスのプロビジョニングは、使用量のピークが同時に発生する可能性の少ないワークロードに最適です。ワークロードがすべて同時にピーク状態になると、高パフォーマンスのストレージ プールがパフォーマンスの上限に達し、パフォーマンス リソースの競合が発生する可能性があります。
プール内のディスクにおいて、高パフォーマンスのストレージ プールでパフォーマンス リソースの競合が検出されると、自動スケーリング機能は、パフォーマンスの問題を防ぐために、ストレージ プール内のディスクで使用可能な IOPS またはスループットを自動的に増やそうとします。
例
プロビジョニングされた IOPS が 100,000 の Hyperdisk Balanced ストレージ プールがあるとします。
標準パフォーマンスのプロビジョニング:
- ストレージ プールに Hyperdisk Balanced ディスクを作成するときに、最大 100,000 の合計 IOPS をプロビジョニングできます。
- Hyperdisk Balanced ストレージ プールのプロビジョニング済みパフォーマンスの 100,000 IOPS に対して課金されます。
ストレージ プールの外部で作成されたディスクと同様に、標準パフォーマンス ストレージ プールの Hyperdisk Balanced ディスクは、最大 3,000 のベースライン IOPS と 140 MiB/秒のベースライン スループットで自動的にプロビジョニングされます。このベースライン パフォーマンスは、ストレージ プールのプロビジョニング済みパフォーマンスにはカウントされません。ベースラインを超えるプロビジョニング済みのパフォーマンスでディスクをストレージ プールに追加した場合にのみ、ストレージ プールのプロビジョニング済みパフォーマンスに対してカウントされます。次に例を示します。
- 3,000 IOPS でプロビジョニングされたディスクはプール IOPS を 0 個使用します。プールには他のディスクに使用できるプロビジョニング済みの IOPS が 100,000 個残っています。
- 13,000 IOPS でプロビジョニングされたディスクは 10,000 プール IOPS を使用し、プールには 90,000 のプロビジョニング済み IOPS が残っており、ストレージ プールの他のディスクに割り当てることができます。
高パフォーマンス プロビジョニング:
- ストレージ プールにディスクを作成するときに、最大 500,000 IOPS の Hyperdisk パフォーマンスをプロビジョニングできます。
- ストレージ プールでプロビジョニングされた 100,000 IOPS に対して課金されます。
- ストレージ プールに 5,000 IOPS の単一ディスク(
Disk1)を作成した場合、ストレージ プールでプロビジョニングされた IOPS から IOPS は消費されません。ただし、ストレージ プールに作成された新しいディスクにプロビジョニングできる IOPS の量は 495,000 に増えています。 Disk1がデータの読み取りと書き込みを開始し、1 分間に最大 5,000 IOPS を使用する場合、ストレージ プールのプロビジョニング済み IOPS から 5,000 IOPS が消費されます。同じストレージ プールで作成された他のディスクは、競合が発生することなく、同じ 1 分間に最大 95,000 IOPS の合計を使用できます。
Hyperdisk ストレージ プールのプロビジョニングされた容量とパフォーマンスの変更
ワークロードのスケーリングに合わせて、ストレージ プールにプロビジョニングされた容量、IOPS、スループットを増減できます。高度な容量または高パフォーマンスのストレージ プールでは、ストレージ プール内の既存および新規のすべてのディスクで追加の容量やパフォーマンスを利用できます。また、Compute Engine は次のようにストレージ プールを自動的に変更しようとします。
- 高度な容量: ストレージ プールが、使用されているストレージ プールのプロビジョニング容量の 80% に達すると、Compute Engine はストレージ プールに自動的に容量を追加しようとします。
- 高パフォーマンス: ストレージ プールで過剰使用により競合が長時間続く場合、Compute Engine はストレージ プールの IOPS またはスループットの増加を試みます。
Hyperdisk ストレージ プールに関する追加情報
Hyperdisk ストレージ プールの使用方法については、次のリンクをご覧ください。
ローカル SSD ディスク
ローカル SSD ディスクは、VM をホストするサーバーに物理的にアタッチされます。ローカル SSD ディスクは、標準 Persistent Disk または SSD Persistent Disk よりもスループットが高く、レイテンシが低くなります。ローカル SSD ディスクに格納されたデータは、VM が停止または削除されるまで保持されます。vCPU の数に応じて、複数のローカル SSD ディスクを VM にアタッチできます。
各ローカル SSD ディスクのサイズは 375 GiB に固定されています。ただし、サイズが 3 TiB のローカル SSD ディスクを使用する Z3 VM を除きます。ストレージ容量を増やすには、VM の作成時に複数のローカル SSD ディスクを VM に追加します。VM にアタッチできるローカル SSD ディスクの最大数は、マシンタイプと使用されている vCPU の数によって異なります。
ローカル SSD ディスク上のデータの永続性
ローカル SSD のデータがどのようなイベントで保持され、どのようなイベントで回復不能になるかについては、ローカル SSD データの永続性をご覧ください。
ローカル SSD とマシンタイプ
マシンシリーズの比較の表に示すように、ローカル SSD ディスクは Compute Engine で利用可能なほとんどのマシンタイプにアタッチできます。ただし、各マシンタイプでアタッチできるローカル SSD ディスクの数には上限があります。詳細については、有効な数のローカル SSD ディスクを選択するをご覧ください。
ローカル SSD ディスクの容量の上限
VM に使用できるローカル SSD ディスクの最大容量は次のとおりです。
| マシンタイプ | ローカル SSD ディスクサイズ | ディスク数 | 最大容量 |
|---|---|---|---|
| Z3 | 3 TiB | 12 | 36 TiB |
c3d-standard-360-lssd |
375 GiB | 32 | 12 TiB |
c3d-highmem-360-lssd |
375 GiB | 32 | 12 TiB |
c3-standard-176-lssd |
375 GiB | 32 | 12 TiB |
| N1、N2、N2D | 375 GiB | 24 | 9 TiB |
| N1、N2、N2D | 375 GiB | 16 | 6 TiB |
| A3 | 375 GiB | 16 | 6 TiB |
| C2、C2D、A2 標準、M1、M3 | 375 GiB | 8 | 3 TiB |
| A2 Ultra | 375 GiB | 8 | 3 TiB |
ローカル SSD ディスクの制限事項
ローカル SSD には次の制限があります。
- IOPS の上限を達成するには、32 基以上の vCPU を備えた VM を使用します。
- 共有コア マシンタイプの VM は、ローカル SSD ディスクをアタッチできません。
- ローカル SSD ディスクを N4、H3、M2 E2、Tau T2A マシンタイプにアタッチすることはできません。
- ローカル SSD ディスクでは顧客指定の暗号鍵は使用できません。Compute Engine は、データがローカル SSD ストレージ スペースに書き込まれる際に、データを自動的に暗号化します。
パフォーマンス
ローカル SSD ディスクは、非常に高い IOPS と低いレイテンシを実現します。Persistent Disk とは異なり、ローカル SSD ディスクのストライプ化はユーザー自身が管理する必要があります。
ローカル SSD のパフォーマンスは、いくつかの要因に左右されます。詳細については、ローカル SSD のパフォーマンスとローカル SSD のパフォーマンスの最適化をご覧ください。
Cloud Storage バケット
Cloud Storage バケットは、VM 向けの最も柔軟性、スケーラビリティ、耐久性に優れたストレージ オプションです。アプリが低レイテンシの Hyperdisk、Persistent Disk、ローカル SSD を必要としない場合は、データを Cloud Storage バケットに保存できます。
レイテンシやスループットが重要ではなく、複数の VM やゾーン間でデータを簡単に共有する必要がある場合は、VM を Cloud Storage バケットに接続できます。
Cloud Storage バケットのプロパティ
Cloud Storage バケットの動作と特性については、以下のセクションをご覧ください。
パフォーマンス
Cloud Storage バケットのパフォーマンスは、ストレージ クラスの選択と、VM に対する相対的なバケットのロケーションに依存します。
VM と同じロケーションで Cloud Storage の Standard Storage クラスを使用すると、Hyperdisk または Persistent Disk に匹敵するパフォーマンスが得られますが、レイテンシが高くなり、一貫性のあるスループット特性が低下します。デュアルリージョンで Standard Storage クラスを使用すると、データが 2 つのリージョンに冗長的に保存されます。デュアルリージョンを使用する際に最適なパフォーマンスを得るには、VM をデュアルリージョンの一部であるいずれかのリージョンに配置する必要があります。
Nearline Storage クラス、Coldline Storage クラス、Archive Storage クラスは、主に長期間のデータ アーカイブに使用します。Standard Storage クラスとは異なり、これらのクラスには最小保存期間があり、データ取得料金が発生します。したがって、頻繁にアクセスされないデータの長期保存に最適です。
信頼性
すべての Cloud Storage バケットには冗長性が組み込まれており、機器の障害からデータが保護され、データセンターのメンテナンス中でもデータの可用性が保証されます。すべての Cloud Storage オペレーションに対してチェックサムが計算され、読み込まれた内容が確実に書き込まれます。
柔軟性
Hyperdisk や Persistent Diskとは異なり、Cloud Storage バケットは VM が存在するゾーンに限定されません。また、バケットのデータを複数の VM で同時に読み書きできます。たとえば、データを複数のゾーンの Hyperdisk または Persistent Disk ボリュームにレプリケートするのではなく、同じバケット内のデータを読み書きするように複数のゾーンの VM を構成できます。
Cloud Storage の暗号化
Compute Engine は、データが VM から Cloud Storage バケットに移動される前に、データを自動的に暗号化します。バケットに書き込む前に、VM 上のファイルを暗号化する必要はありません。
Persistent Disk ボリュームと同じように、独自の暗号鍵でバケットを暗号化できます。Cloud Storage バケットに対するデータの書き込みと読み取り
Cloud Storage バケットに対してファイルを読み書きするには、gcloud storage コマンドライン ツールまたは Cloud Storage クライアント ライブラリを使用します。
gcloud storage
公開イメージを使用するほとんどの VM に gcloud storage コマンドライン ツールはデフォルトでインストールされています。VM に gcloud storage コマンドライン ツールがない場合は、インストールできます。
SSH またはその他の接続方法を使用して、Linux VM に接続するか、Windows VM に接続します。
- In the Google Cloud console, go to the VM instances page.
-
In the list of virtual machine instances, click SSH in the row of
the instance that you want to connect to.

この VM で
gcloud storageを使用したことがない場合は、gcloud CLI を使用して認証情報を設定します。gcloud init
Cloud Storage スコープを持つサービス アカウントを使用するように VM が構成されている場合はこの手順をスキップできます。
gcloud storageツールを使用してバケットを作成し、データをバケットに書き込み、それらのバケットからデータを読み取ります。特定のバケットに対してデータを読み書きするには、バケットへのアクセス権を取得する必要があります。一般公開されているバケットからデータを読み取ることもできます。必要に応じて、Cloud Storage にデータをストリーミングすることもできます。
クライアント ライブラリ
Cloud Storage スコープを持つサービス アカウントを使用するように VM を構成した場合、Cloud Storage API を使用して Cloud Storage バケットからデータを読み書きできます。
- In the Google Cloud console, go to the VM instances page.
-
In the list of virtual machine instances, click SSH in the row of
the instance that you want to connect to.
使用する言語のクライアント ライブラリをインストールして構成します。
必要に応じて、サンプルコードの挿入手順に沿って VM 上に Cloud Storage バケットを作成します。
サンプルコードの挿入手順でデータの書き込みとデータの読み取りを行い、Cloud Storage バケットとの間でファイルの読み書きを行うコードをアプリに組み込みます。
次のステップ
- VM に Hyperdisk ボリュームを追加する。
- Persistent Disk ボリュームを VM に追加する。
- 同期レプリケートされたディスクを VM に追加する。
- ローカル SSD ディスクを接続した VM を作成する。
- ファイル サーバーまたは分散ファイル システムを作成する。
- ディスクの割り当てを確認する。
- VM で RAM ディスクをマウントする。