Introducción a la API Storage Write de BigQuery
La API Storage Write de BigQuery es una API de ingestión de datos unificada de BigQuery. Combina la ingestión de streaming y la carga por lotes en una sola API de alto rendimiento. Puedes usar la API Storage Write para transmitir registros a BigQuery en tiempo real o para procesar por lotes un número arbitrariamente grande de registros y confirmarlos en una sola operación atómica.
Ventajas de usar la API Storage Write
Semántica de entrega exactamente una vez. La API Storage Write admite la semántica de una sola vez mediante el uso de desplazamientos de flujo. A diferencia del método tabledata.insertAll, la API Storage Write nunca escribe dos mensajes que tengan el mismo desfase en un flujo si el cliente proporciona desfases de flujo al añadir registros.
Transacciones a nivel de flujo. Puedes escribir datos en un flujo y confirmar los datos como una sola transacción. Si la operación de confirmación falla, puedes volver a intentarla sin problemas.
Transacciones en todos los flujos. Varios trabajadores pueden crear sus propios flujos para procesar datos de forma independiente. Cuando todos los trabajadores hayan terminado, puedes confirmar todas las secuencias como una transacción.
Protocolo eficiente. La API Storage Write es más eficiente que el método insertAll antiguo porque usa la transmisión gRPC en lugar de REST a través de HTTP. La API Storage Write también admite el formato binario protocol buffer y el formato columnar Apache Arrow, que son formatos de cable más eficientes que JSON. Las solicitudes de escritura son asíncronas y tienen un orden garantizado.
Detección de actualizaciones de esquemas. Si el esquema de la tabla subyacente cambia mientras el cliente está transmitiendo, la API Storage Write se lo notificará. El cliente puede decidir si quiere volver a conectarse con el esquema actualizado o seguir escribiendo en la conexión actual.
Coste más bajo. La API Storage Write tiene un coste significativamente inferior al de la antigua API de streaming insertAll. Además, puedes ingerir hasta 2 TiB al mes sin coste adicional.
Permisos obligatorios
Para usar la API Storage Write, debes tener permisos de bigquery.tables.updateData.
Los siguientes roles de Gestión de Identidades y Accesos (IAM) predefinidos incluyen los permisos de bigquery.tables.updateData:
bigquery.dataEditorbigquery.dataOwnerbigquery.admin
Para obtener más información sobre los roles y permisos de gestión de identidades y accesos en BigQuery, consulta el artículo sobre roles y permisos predefinidos.
Ámbitos de autenticación
Para usar la API Storage Write, debes tener uno de los siguientes permisos de OAuth:
https://www.googleapis.com/auth/bigqueryhttps://www.googleapis.com/auth/cloud-platformhttps://www.googleapis.com/auth/bigquery.insertdata
Para obtener más información, consulta el artículo Descripción general de la autenticación.
Información general sobre la API Storage Write
La abstracción principal de la API Storage Write es un flujo. Un flujo escribe datos en una tabla de BigQuery. Más de un flujo puede escribir simultáneamente en la misma tabla.
Emisión predeterminada
La API Storage Write proporciona un flujo predeterminado diseñado para situaciones de streaming en las que los datos llegan continuamente. Tiene las siguientes características:
- Los datos escritos en el flujo predeterminado están disponibles inmediatamente para las consultas.
- El flujo predeterminado admite la semántica de al menos una vez.
- No es necesario que cree explícitamente el flujo predeterminado.
Si vas a migrar desde la API antigua tabledata.insertall, te recomendamos que uses el flujo predeterminado. Tiene una semántica de escritura similar, con mayor resiliencia de los datos y menos restricciones de escalado.
Flujo de la API:
AppendRows(bucle)
Para obtener más información y un ejemplo de código, consulta Usar el flujo predeterminado para la semántica de al menos una vez.
Flujos creados por aplicaciones
Puedes crear un flujo explícitamente si necesitas alguna de las siguientes acciones:
- Semántica de escritura exactamente una vez mediante el uso de desplazamientos de flujo.
- Compatibilidad con propiedades ACID adicionales.
En general, las secuencias creadas por aplicaciones ofrecen más control sobre las funciones, pero a costa de una mayor complejidad.
Cuando creas una emisión, debes especificar un tipo. El tipo controla cuándo se pueden leer los datos escritos en el flujo en BigQuery.
Tipo pendiente
En el tipo pendiente, los registros se almacenan en un estado pendiente hasta que confirmas el flujo. Cuando confirmas una transmisión, todos los datos pendientes se pueden leer. La confirmación es una operación atómica. Usa este tipo para cargas de trabajo por lotes, como alternativa a las tareas de carga de BigQuery. Para obtener más información, consulta el artículo Cargar datos por lotes con la API Storage Write.
Flujo de la API:
Tipo de compromiso
En el tipo confirmado, los registros están disponibles para leerse inmediatamente a medida que los escribes en el flujo. Usa este tipo para cargas de trabajo de streaming que necesiten una latencia de lectura mínima. El flujo predeterminado usa un formulario de tipo confirmado al menos una vez. Para obtener más información, consulta Usar el tipo de confirmación para la semántica de entrega única.
Flujo de la API:
CreateWriteStreamAppendRows(bucle)FinalizeWriteStream(opcional)
Tipo almacenado en búfer
El tipo de almacenamiento en búfer es un tipo avanzado que, por lo general, no se debe usar, excepto con el conector de E/S de BigQuery de Apache Beam. Si tienes lotes pequeños que quieres que aparezcan juntos, usa el tipo "committed" y envía cada lote en una solicitud. En este tipo, se proporcionan confirmaciones a nivel de fila y los registros se almacenan en búfer hasta que las filas se confirman vaciando el flujo.
Flujo de la API:
CreateWriteStreamAppendRows⇒FlushRows(bucle)FinalizeWriteStream(opcional)
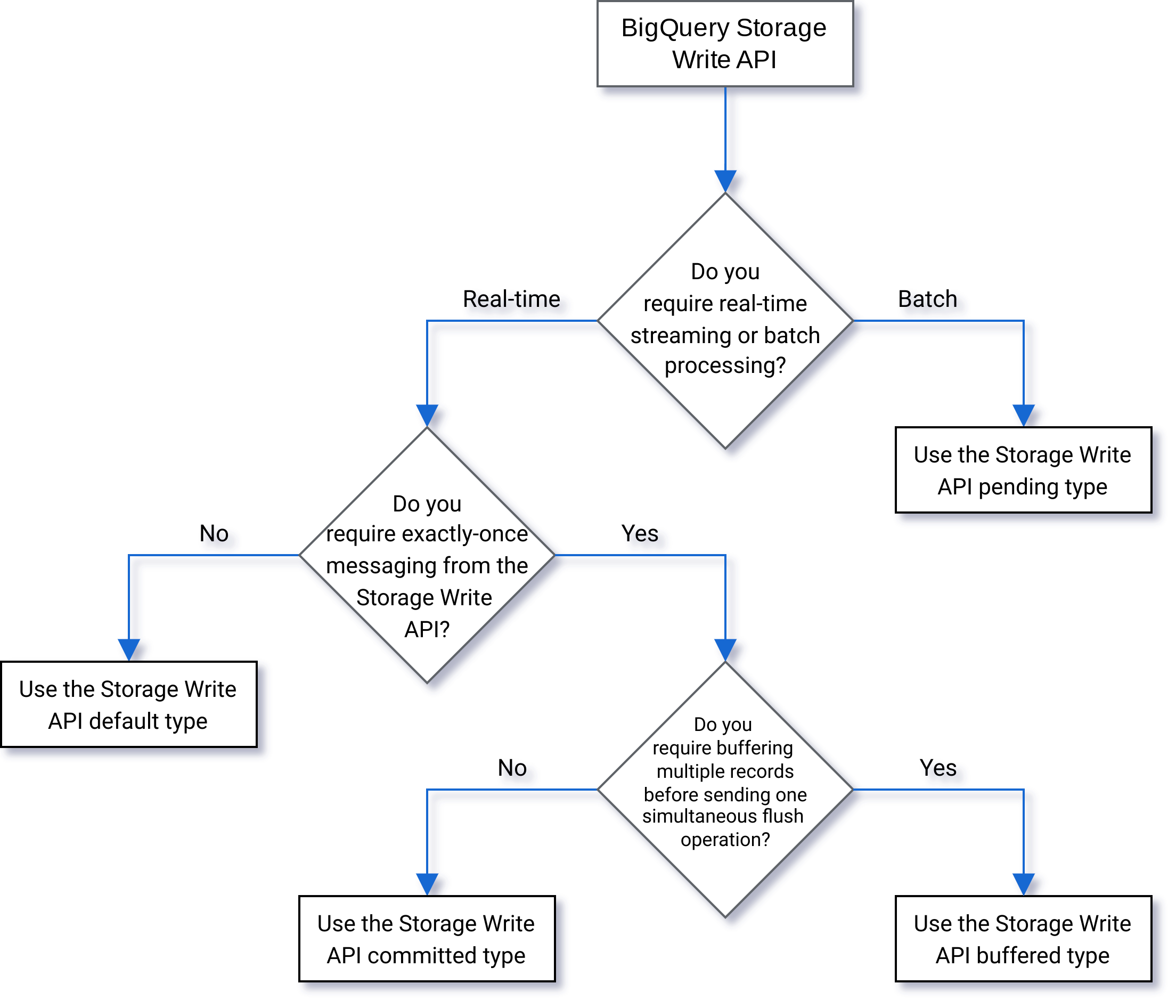
Seleccionar un tipo
Usa el siguiente diagrama de flujo para decidir qué tipo es el más adecuado para tu carga de trabajo:
Detalles de la API
Ten en cuenta lo siguiente cuando uses la API Storage Write:
AppendRows
El método AppendRows añade uno o varios registros al flujo. La primera llamada a AppendRows debe contener un nombre de flujo junto con el esquema de datos, especificado como DescriptorProto. También puede añadir un esquema de flecha serializado en la primera llamada a AppendRows si ingiere datos en formato Apache Arrow. Te recomendamos que envíes un lote de filas en cada llamada AppendRows. No envíe las filas de una en una.
Gestión de búferes de protocolo
Los buffers de protocolo proporcionan un mecanismo extensible, neutral en cuanto a idiomas y plataformas, para serializar datos estructurados de forma compatible con versiones anteriores y posteriores. Ofrecen ventajas, ya que proporcionan un almacenamiento de datos compacto con un análisis rápido y eficiente. Para obtener más información sobre los búferes de protocolo, consulta Introducción a los búferes de protocolo.
Si vas a usar la API directamente con un mensaje de búfer de protocolo predefinido, el mensaje de búfer de protocolo no puede usar un especificador package y todos los tipos anidados o de enumeración deben definirse en el mensaje raíz de nivel superior.
No se permiten referencias a mensajes externos. Para ver un ejemplo, consulta sample_data.proto.
Los clientes de Java y Go admiten búferes de protocolo arbitrarios, ya que la biblioteca de clientes normaliza el esquema del búfer de protocolo.
Gestión de Apache Arrow
Para enviar comentarios o solicitar asistencia sobre esta función, ponte en contacto con bq-write-api-feedback@google.com.
Apache Arrow es un formato de columnas universal y un conjunto de herramientas multilingüe para el procesamiento de datos. Apache Arrow proporciona un formato de memoria orientado a columnas independiente del lenguaje para datos planos y jerárquicos, organizado para realizar operaciones analíticas eficientes en hardware moderno. Para obtener más información sobre Apache Arrow, consulte Apache Arrow.
La API Storage Write admite la ingestión de Arrow mediante el esquema y los datos de Arrow serializados en la clase AppendRowsRequest.
La biblioteca de cliente de Python incluye compatibilidad integrada con la ingestión de Apache Arrow. En otros idiomas, es posible que tengas que llamar a la API AppendRows sin procesar para ingerir datos en formato Apache Arrow.
FinalizeWriteStream
El método FinalizeWriteStream finaliza el flujo para que no se puedan añadir datos nuevos. Este método es obligatorio en el tipo Pending y opcional en los tipos Committed y Buffered. El flujo predeterminado no admite este método.
Gestión de errores
Si se produce un error, el elemento google.rpc.Status devuelto puede incluir un StorageError en los detalles del error. Consulta la StorageErrorCode para encontrar el tipo de error específico. Para obtener más información sobre el modelo de errores de la API de Google, consulta la sección Errores.
Conexiones
La API Storage Write es una API gRPC que usa conexiones bidireccionales. El método AppendRows crea una conexión a un flujo. Puedes abrir varias conexiones en el flujo predeterminado. Estas anexiones son asíncronas, lo que te permite enviar una serie de escrituras simultáneamente. Los mensajes de respuesta de cada conexión bidireccional llegan en el mismo orden en que se enviaron las solicitudes.
Las secuencias creadas por aplicaciones solo pueden tener una conexión activa. Como práctica recomendada, limita el número de conexiones activas y usa una conexión para escribir tantos datos como sea posible. Cuando se usa el flujo predeterminado en Java o Go, se puede usar la multiplexación de la API Storage Write para escribir en varias tablas de destino con conexiones compartidas.
Por lo general, una sola conexión admite al menos 1 MBps de rendimiento. El límite superior depende de varios factores, como el ancho de banda de la red, el esquema de los datos y la carga del servidor. Cuando una conexión alcanza el límite de rendimiento, es posible que se rechacen o se pongan en cola las solicitudes entrantes hasta que disminuya el número de solicitudes en curso. Si necesitas más capacidad de procesamiento, crea más conexiones.
BigQuery cierra la conexión gRPC si permanece inactiva durante demasiado tiempo. Si esto ocurre, el código de respuesta es HTTP 409. La conexión gRPC también se puede cerrar si se reinicia el servidor o por otros motivos. Si se produce un error de conexión, crea una nueva. Las bibliotecas de cliente de Java y Go se vuelven a conectar automáticamente si se cierra la conexión.
Asistencia para bibliotecas de cliente
Las bibliotecas de cliente de la API Storage Write están disponibles en varios lenguajes de programación y exponen las estructuras de la API subyacente basada en gRPC. Esta API aprovecha funciones avanzadas, como el streaming bidireccional, que pueden requerir un trabajo de desarrollo adicional para poder usarse. Para ello, hay disponible una serie de abstracciones de nivel superior para esta API que simplifican esas interacciones y reducen las preocupaciones de los desarrolladores. Te recomendamos que utilices estas otras abstracciones de la biblioteca siempre que sea posible.
En esta sección se proporciona información adicional sobre los lenguajes y las bibliotecas en los que se han ofrecido a los desarrolladores funciones adicionales más allá de la API generada.
Para ver ejemplos de código relacionados con la API Storage Write, consulta Todos los ejemplos de código de BigQuery.
Cliente Java
La biblioteca de cliente de Java proporciona dos objetos de escritura:
StreamWriter: acepta datos en formato de búfer de protocolo.JsonStreamWriter: acepta datos en formato JSON y los convierte en búferes de protocolo antes de enviarlos a través de la red. LaJsonStreamWritertambién admite actualizaciones automáticas del esquema. Si cambia el esquema de la tabla, el escritor se vuelve a conectar automáticamente con el nuevo esquema, lo que permite al cliente enviar datos con el nuevo esquema.
El modelo de programación es similar para ambos escritores. La principal diferencia es la forma en que se da formato a la carga útil.
El objeto writer gestiona una conexión de la API Storage Write. El objeto writer limpia automáticamente las solicitudes, añade los encabezados de enrutamiento regional a las solicitudes y vuelve a conectarse después de que se produzcan errores de conexión. Si usas la API gRPC directamente, debes encargarte de estos detalles.
Cliente de Go
El cliente de Go usa una arquitectura cliente-servidor para codificar mensajes en formato de búfer de protocolo mediante proto2. Consulta la documentación de Go para obtener información sobre cómo usar el cliente de Go, con código de ejemplo.
Cliente Python
El cliente de Python es un cliente de nivel inferior que encapsula la API gRPC. Para usar este cliente, debe enviar los datos como búferes de protocolo, siguiendo el flujo de la API del tipo especificado.
Evita usar la generación dinámica de mensajes proto en Python, ya que el rendimiento de esa biblioteca es inferior al estándar.
Para obtener más información sobre cómo usar los búferes de protocolo con Python, consulta el tutorial sobre los conceptos básicos de los búferes de protocolo en Python.
También puede usar el formato de ingestión Apache Arrow como protocolo alternativo para ingerir datos con la API Storage Write. Para obtener más información, consulta Usar el formato Apache Arrow para ingerir datos.
Cliente de NodeJS
La biblioteca de cliente de NodeJS acepta entradas JSON y ofrece compatibilidad con la reconexión automática. Consulta la documentación para obtener información sobre cómo usar el cliente.
Gestionar la no disponibilidad
Si vuelves a intentar la operación con un tiempo de espera exponencial, puedes mitigar los errores aleatorios y los breves periodos de falta de disponibilidad del servicio, pero para evitar que se eliminen filas durante periodos prolongados de falta de disponibilidad, debes pensártelo mejor. En concreto, si un cliente no puede insertar una fila de forma persistente, ¿qué debe hacer?
La respuesta depende de tus requisitos. Por ejemplo, si BigQuery se usa para analíticas operativas en las que se pueden aceptar algunas filas que faltan, el cliente puede renunciar después de varios reintentos y descartar los datos. Si, por el contrario, cada fila es fundamental para la empresa (por ejemplo, en el caso de los datos financieros), debes tener una estrategia para conservar los datos hasta que se puedan insertar más adelante.
Una forma habitual de gestionar los errores persistentes es publicar las filas en un tema de Pub/Sub para evaluarlas más adelante y, si es posible, insertarlas. Otro método habitual es conservar los datos de forma temporal en el cliente. Ambos métodos pueden mantener a los clientes desbloqueados y, al mismo tiempo, asegurarse de que todas las filas se puedan insertar una vez que se restaure la disponibilidad.
Insertar datos en tablas con particiones
La API Storage Write admite la transmisión de datos a tablas particionadas.
Cuando los datos se transmiten, se colocan inicialmente en la partición __UNPARTITIONED__. Una vez que se han recogido suficientes datos sin particionar, BigQuery vuelve a particionarlos y los coloca en la partición adecuada.
Sin embargo, no hay ningún acuerdo de nivel de servicio que defina cuánto tiempo puede tardar en salir de la partición __UNPARTITIONED__.
En las tablas con particiones creadas en el momento de la ingestión y con particiones creadas en columnas de unidades de tiempo, se pueden excluir los datos sin particiones de una consulta filtrando los valores de NULL de la partición __UNPARTITIONED__ mediante una de las pseudocolumnas (_PARTITIONTIME o _PARTITIONDATE, según el tipo de datos que prefiera).
Partición por hora de ingestión
Cuando se transmite a una tabla con particiones por hora de ingestión, la API Storage Write deduce la partición de destino a partir de la hora UTC del sistema.
Si estás transmitiendo datos a una tabla con particiones diarias, puedes anular la inferencia de la fecha proporcionando un decorador de partición como parte de la solicitud.
Incluye el decorador en el parámetro tableID. Por ejemplo, puedes transmitir a la partición correspondiente al 1 de junio del 2025 de la tabla table1 mediante el decorador de partición table1$20250601.
Cuando se transmite con un decorador de partición, puedes transmitir a particiones desde 31 días anteriores hasta 16 días posteriores. Para escribir en particiones de fechas que estén fuera de estos límites, utiliza una tarea de carga o de consulta, tal como se describe en el artículo Escribir datos en una partición específica.
El streaming con un decorador de partición solo se admite en tablas con particiones diarias con flujos predeterminados, no en tablas con particiones por horas, mensuales o anuales, ni en flujos creados por aplicaciones.
Partición por columnas de unidades de tiempo
Cuando transmite datos a una tabla con particiones por columna de unidad de tiempo, BigQuery coloca automáticamente los datos en la partición correcta en función de los valores de la columna de partición DATE, DATETIME o TIMESTAMP predefinida de la tabla. Puedes transmitir datos a una tabla particionada por una columna de unidad de tiempo si los datos a los que hace referencia la columna de partición están comprendidos entre los 10 años anteriores y el año posterior a la fecha actual.
Particiones de rangos de números enteros
Cuando transmites datos a una tabla con particiones por intervalo de números enteros, BigQuery coloca automáticamente los datos en la partición correcta en función de los valores de la columna de INTEGERparticiónINTEGER predefinida de la tabla.
Plugin de salida de la API Storage Write de Fluent Bit
El complemento de salida de la API Storage Write de Fluent Bit automatiza el proceso de ingestión de registros JSON en BigQuery, por lo que no es necesario que escribas código. Con este complemento, solo tienes que configurar un complemento de entrada compatible y crear un archivo de configuración para empezar a transmitir datos. Fluent Bit es un procesador y reenviador de registros de código abierto y multiplataforma que usa complementos de entrada y salida para gestionar diferentes tipos de fuentes y receptores de datos.
Este complemento admite lo siguiente:
- Semántica de al menos una vez con el tipo predeterminado.
- Semántica de entrega exactamente una vez con el tipo confirmado.
- Escalado dinámico de los flujos predeterminados cuando se indica contrapresión.
Métricas de proyectos de la API Storage Write
Para consultar las métricas que monitorizan la ingestión de datos con la API Storage Write, usa la vista INFORMATION_SCHEMA.WRITE_API_TIMELINE o consulta las Google Cloud métricas.
Usar el lenguaje de manipulación de datos (DML) con datos transmitidos recientemente
Puede usar el lenguaje de manipulación de datos (DML), como las instrucciones UPDATE, DELETE o MERGE, para modificar las filas que se hayan escrito recientemente en una tabla de BigQuery mediante la API Storage Write de BigQuery. Las escrituras recientes son las que se han producido en los últimos 30 minutos.
Para obtener más información sobre cómo usar DML para modificar los datos transmitidos, consulta el artículo Usar el lenguaje de manipulación de datos.
Limitaciones
- No se pueden ejecutar instrucciones de DML de mutación en datos transmitidos recientemente con la API de streaming insertAll.
- No se admite la ejecución de instrucciones de DML mutadoras en una transacción con varias instrucciones en datos transmitidos recientemente.
Cuotas de la API Storage Write
Para obtener información sobre las cuotas y los límites de la API Storage Write, consulta Cuotas y límites de la API Storage Write de BigQuery.
Puedes monitorizar el uso de la cuota de conexiones simultáneas y de rendimiento en la página Cuotas de laGoogle Cloud consola.
Calcular el rendimiento
Supongamos que tu objetivo es recoger registros de 100 millones de endpoints
creando 1500 registros de registro por minuto. A continuación, puede estimar el rendimiento como
100 million * 1,500 / 60 seconds = 2.5 GB per second.
Debes asegurarte de que tienes suficiente cuota para ofrecer este rendimiento.
Precios de la API Storage Write
Para obtener información sobre los precios, consulta la página Precios de la ingestión de datos.
Caso práctico de ejemplo
Supongamos que hay una canalización que procesa datos de eventos de registros de endpoints. Los eventos se generan continuamente y deben estar disponibles para las consultas en BigQuery lo antes posible. Como la actualidad de los datos es fundamental en este caso práctico, la API Storage Write es la mejor opción para ingerir datos en BigQuery. Una arquitectura recomendada para mantener estos endpoints ligeros es enviar eventos a Pub/Sub, desde donde los consume un flujo de procesamiento de Dataflow que transmite directamente a BigQuery.
Una de las principales preocupaciones sobre la fiabilidad de esta arquitectura es cómo gestionar los errores al insertar un registro en BigQuery. Si cada registro es importante y no se puede perder, los datos deben almacenarse en un búfer antes de intentar insertarlos. En la arquitectura recomendada anterior, Pub/Sub puede actuar como un búfer con sus funciones de conservación de mensajes. La canalización de Dataflow debe configurarse para reintentar las inserciones de streaming de BigQuery con retroceso exponencial truncado. Cuando se agota la capacidad de Pub/Sub como búfer (por ejemplo, en caso de que BigQuery no esté disponible durante un periodo prolongado o se produzca un fallo en la red), los datos deben conservarse en el cliente y este debe tener un mecanismo para reanudar la inserción de los registros conservados una vez que se haya restaurado la disponibilidad. Para obtener más información sobre cómo gestionar esta situación, consulta la entrada del blog Guía de fiabilidad de Google Pub/Sub.
Otro caso de fallo que se debe gestionar es el de un registro no válido. Un registro tóxico es un registro que BigQuery rechaza porque no se puede insertar con un error no reintentable o un registro que no se ha insertado correctamente después del número máximo de reintentos. Ambos tipos de registros deben almacenarse en una cola de mensajes fallidos mediante la canalización de Dataflow para investigar más a fondo.
Si se requiere una semántica de exactamente una vez, crea un flujo de escritura de tipo confirmado, con los desplazamientos de los registros proporcionados por el cliente. De esta forma, se evitan los duplicados, ya que la operación de escritura solo se realiza si el valor de desplazamiento coincide con el siguiente desplazamiento de anexión. Si no se proporciona un desplazamiento, los registros se añadirán al final de la secuencia y, si se vuelve a intentar añadir un registro que no se ha podido añadir, es posible que aparezca más de una vez en la secuencia.
Si no se requieren garantías de entrega única, escribir en el flujo predeterminado permite un mayor rendimiento y no se tiene en cuenta para el límite de cuota de creación de flujos de escritura.
Estima el rendimiento de tu red y asegúrate de que tienes suficiente cuota para ofrecer ese rendimiento.
Si tu carga de trabajo genera o procesa datos a un ritmo muy irregular, intenta suavizar los picos de carga en el cliente y transmitir a BigQuery con un rendimiento constante. Esto puede simplificar la planificación de la capacidad. Si no es posible, asegúrate de que estás preparado para gestionar los errores 429 (recursos agotados) si tu capacidad supera la cuota durante picos breves.
Para ver un ejemplo detallado de cómo usar la API Storage Write, consulta Transmitir datos con la API Storage Write.
Siguientes pasos
- Transmitir datos con la API Storage Write
- Cargar datos por lotes con la API Storage Write
- Tipos de datos de búfer de protocolo y Arrow admitidos
- Prácticas recomendadas de la API Storage Write