Mit Zeitreihendaten arbeiten
In diesem Dokument wird beschrieben, wie Sie mit SQL-Funktionen die Zeitreihenanalyse unterstützen.
Einführung
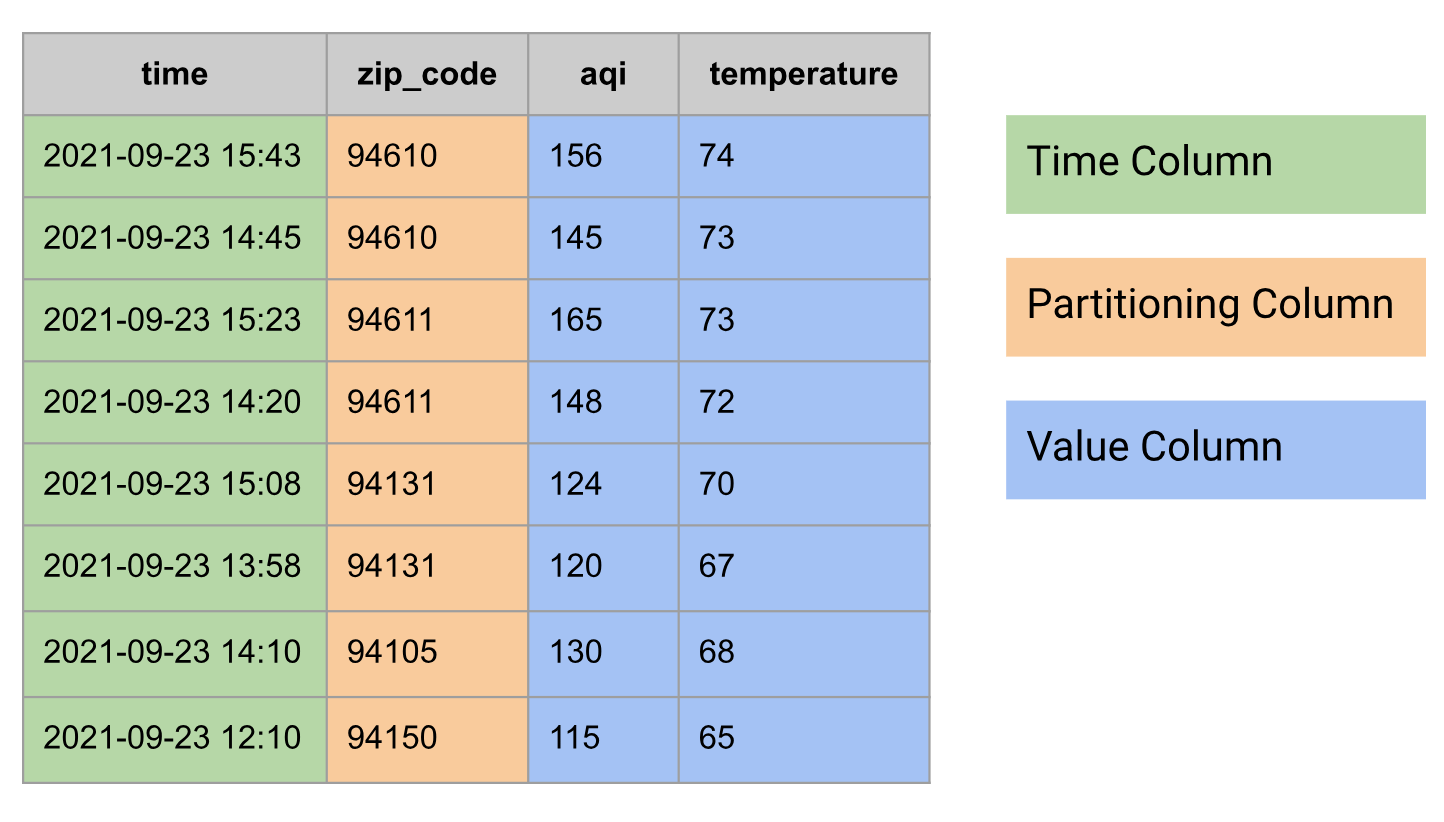
Eine Zeitreihe ist eine Folge von Datenpunkten, die jeweils aus einer Zeit und einem mit dieser Zeit verknüpften Wert bestehen. Normalerweise hat eine Zeitreihe auch eine Kennung, die die Zeitreihe eindeutig benennt.
In relationalen Datenbanken wird eine Zeitreihe als Tabelle mit den folgenden Spaltengruppen modelliert:
- Zeitspalte
- Kann Partitionierungsspalten haben, z. B. Postleitzahl
- Eine oder mehrere Wertspalten oder ein
STRUCT-Typ, der mehrere Werte kombiniert, z. B. Temperatur und AQI
Das folgende Beispiel zeigt Zeitreihendaten, die als Tabelle modelliert werden:
Zeitreihe zusammenfassen
Bei der Zeitreihenanalyse ist die Zeitaggregation eine Aggregation, die entlang der Zeitreihe ausgeführt wird.
Sie können in BigQuery mithilfe von Zeit-Bucketing-Funktionen eine Zeitaggregation durchführen (TIMESTAMP_BUCKET ,DATE_BUCKET und DATETIME_BUCKET). Zeit-Bucketing-Funktionen ordnen Eingabezeitwerte dem Bucket zu, zu dem sie gehören.
In der Regel wird die Zeitaggregation verwendet, um mehrere Datenpunkte in einem Zeitfenster zu einem einzigen Datenpunkt zu kombinieren. Dazu wird eine Aggregationsfunktion wie z. B. AVG, MIN, MAX, COUNT ode rSUM verwendet. Zum Beispiel eine durchschnittliche Anfragelatenz von 15 Minuten, tägliche Mindest- und Höchsttemperaturen und tägliche Anzahl von Taxifahrten.
Erstellen Sie für die Abfragen in diesem Abschnitt eine Tabelle mit dem Namen mydataset.environmental_data_hourly:
CREATE OR REPLACE TABLE mydataset.environmental_data_hourly AS
SELECT * FROM UNNEST(
ARRAY<STRUCT<zip_code INT64, time TIMESTAMP, aqi INT64, temperature INT64>>[
STRUCT(60606, TIMESTAMP '2020-09-08 00:30:51', 22, 66),
STRUCT(60606, TIMESTAMP '2020-09-08 01:32:10', 23, 63),
STRUCT(60606, TIMESTAMP '2020-09-08 02:30:35', 22, 60),
STRUCT(60606, TIMESTAMP '2020-09-08 03:29:39', 21, 58),
STRUCT(60606, TIMESTAMP '2020-09-08 04:33:05', 21, 59),
STRUCT(60606, TIMESTAMP '2020-09-08 05:32:01', 21, 57),
STRUCT(60606, TIMESTAMP '2020-09-08 06:31:14', 22, 56),
STRUCT(60606, TIMESTAMP '2020-09-08 07:31:06', 28, 55),
STRUCT(60606, TIMESTAMP '2020-09-08 08:29:59', 30, 55),
STRUCT(60606, TIMESTAMP '2020-09-08 09:29:34', 31, 55),
STRUCT(60606, TIMESTAMP '2020-09-08 10:31:24', 38, 56),
STRUCT(60606, TIMESTAMP '2020-09-08 11:31:24', 38, 56),
STRUCT(60606, TIMESTAMP '2020-09-08 12:32:38', 38, 57),
STRUCT(60606, TIMESTAMP '2020-09-08 13:29:59', 38, 56),
STRUCT(60606, TIMESTAMP '2020-09-08 14:31:22', 43, 59),
STRUCT(60606, TIMESTAMP '2020-09-08 15:31:38', 42, 63),
STRUCT(60606, TIMESTAMP '2020-09-08 16:34:22', 43, 65),
STRUCT(60606, TIMESTAMP '2020-09-08 17:33:23', 42, 68),
STRUCT(60606, TIMESTAMP '2020-09-08 18:28:47', 36, 69),
STRUCT(60606, TIMESTAMP '2020-09-08 19:30:28', 34, 67),
STRUCT(60606, TIMESTAMP '2020-09-08 20:30:53', 29, 67),
STRUCT(60606, TIMESTAMP '2020-09-08 21:32:28', 27, 67),
STRUCT(60606, TIMESTAMP '2020-09-08 22:31:45', 25, 65),
STRUCT(60606, TIMESTAMP '2020-09-08 23:31:02', 22, 63),
STRUCT(94105, TIMESTAMP '2020-09-08 00:07:11', 60, 74),
STRUCT(94105, TIMESTAMP '2020-09-08 01:07:24', 61, 73),
STRUCT(94105, TIMESTAMP '2020-09-08 02:08:07', 60, 71),
STRUCT(94105, TIMESTAMP '2020-09-08 03:11:05', 69, 69),
STRUCT(94105, TIMESTAMP '2020-09-08 04:07:26', 72, 67),
STRUCT(94105, TIMESTAMP '2020-09-08 05:08:11', 70, 66),
STRUCT(94105, TIMESTAMP '2020-09-08 06:07:30', 68, 65),
STRUCT(94105, TIMESTAMP '2020-09-08 07:07:10', 77, 64),
STRUCT(94105, TIMESTAMP '2020-09-08 08:06:35', 81, 64),
STRUCT(94105, TIMESTAMP '2020-09-08 09:10:18', 82, 63),
STRUCT(94105, TIMESTAMP '2020-09-08 10:08:10', 107, 62),
STRUCT(94105, TIMESTAMP '2020-09-08 11:08:01', 115, 62),
STRUCT(94105, TIMESTAMP '2020-09-08 12:07:39', 120, 62),
STRUCT(94105, TIMESTAMP '2020-09-08 13:06:03', 125, 61),
STRUCT(94105, TIMESTAMP '2020-09-08 14:08:37', 129, 62),
STRUCT(94105, TIMESTAMP '2020-09-08 15:09:19', 150, 62),
STRUCT(94105, TIMESTAMP '2020-09-08 16:06:39', 151, 62),
STRUCT(94105, TIMESTAMP '2020-09-08 17:08:01', 155, 63),
STRUCT(94105, TIMESTAMP '2020-09-08 18:09:23', 154, 64),
STRUCT(94105, TIMESTAMP '2020-09-08 19:08:43', 151, 67),
STRUCT(94105, TIMESTAMP '2020-09-08 20:07:19', 150, 69),
STRUCT(94105, TIMESTAMP '2020-09-08 21:07:37', 148, 72),
STRUCT(94105, TIMESTAMP '2020-09-08 22:08:01', 143, 76),
STRUCT(94105, TIMESTAMP '2020-09-08 23:08:41', 137, 75)
]);
Eine interessante Beobachtung zu den vorhergehenden Daten ist, dass Messungen zu beliebigen Zeiträumen erfolgen, die als nicht ausgerichtete Zeitreihen bezeichnet werden. Die Aggregation ist eine Möglichkeit, eine Zeitreihe auszurichten.
3-Stunden-Durchschnitt abrufen
Die folgende Abfrage berechnet einen durchschnittlichen Luftqualitätsindex (AQI) von 3 Stunden und die Temperatur für jede Postleitzahl. Die Funktion TIMESTAMP_BUCKET führt eine Zeitaggregation durch, indem jeder Zeitwert einem bestimmten Tag zugewiesen wird.
SELECT
TIMESTAMP_BUCKET(time, INTERVAL 3 HOUR) AS time,
zip_code,
CAST(AVG(aqi) AS INT64) AS aqi,
CAST(AVG(temperature) AS INT64) AS temperature
FROM mydataset.environmental_data_hourly
GROUP BY zip_code, time
ORDER BY zip_code, time;
/*---------------------+----------+-----+-------------+
| time | zip_code | aqi | temperature |
+---------------------+----------+-----+-------------+
| 2020-09-08 00:00:00 | 60606 | 22 | 63 |
| 2020-09-08 03:00:00 | 60606 | 21 | 58 |
| 2020-09-08 06:00:00 | 60606 | 27 | 55 |
| 2020-09-08 09:00:00 | 60606 | 36 | 56 |
| 2020-09-08 12:00:00 | 60606 | 40 | 57 |
| 2020-09-08 15:00:00 | 60606 | 42 | 65 |
| 2020-09-08 18:00:00 | 60606 | 33 | 68 |
| 2020-09-08 21:00:00 | 60606 | 25 | 65 |
| 2020-09-08 00:00:00 | 94105 | 60 | 73 |
| 2020-09-08 03:00:00 | 94105 | 70 | 67 |
| 2020-09-08 06:00:00 | 94105 | 75 | 64 |
| 2020-09-08 09:00:00 | 94105 | 101 | 62 |
| 2020-09-08 12:00:00 | 94105 | 125 | 62 |
| 2020-09-08 15:00:00 | 94105 | 152 | 62 |
| 2020-09-08 18:00:00 | 94105 | 152 | 67 |
| 2020-09-08 21:00:00 | 94105 | 143 | 74 |
+---------------------+----------+-----+-------------*/
Mindest- und Höchstwert von 3 Stunden abrufen
In der folgenden Abfrage werden für jede Postleitzahl die Mindest- und Höchsttemperaturen von drei Stunden berechnet:
SELECT
TIMESTAMP_BUCKET(time, INTERVAL 3 HOUR) AS time,
zip_code,
MIN(temperature) AS temperature_min,
MAX(temperature) AS temperature_max,
FROM mydataset.environmental_data_hourly
GROUP BY zip_code, time
ORDER BY zip_code, time;
/*---------------------+----------+-----------------+-----------------+
| time | zip_code | temperature_min | temperature_max |
+---------------------+----------+-----------------+-----------------+
| 2020-09-08 00:00:00 | 60606 | 60 | 66 |
| 2020-09-08 03:00:00 | 60606 | 57 | 59 |
| 2020-09-08 06:00:00 | 60606 | 55 | 56 |
| 2020-09-08 09:00:00 | 60606 | 55 | 56 |
| 2020-09-08 12:00:00 | 60606 | 56 | 59 |
| 2020-09-08 15:00:00 | 60606 | 63 | 68 |
| 2020-09-08 18:00:00 | 60606 | 67 | 69 |
| 2020-09-08 21:00:00 | 60606 | 63 | 67 |
| 2020-09-08 00:00:00 | 94105 | 71 | 74 |
| 2020-09-08 03:00:00 | 94105 | 66 | 69 |
| 2020-09-08 06:00:00 | 94105 | 64 | 65 |
| 2020-09-08 09:00:00 | 94105 | 62 | 63 |
| 2020-09-08 12:00:00 | 94105 | 61 | 62 |
| 2020-09-08 15:00:00 | 94105 | 62 | 63 |
| 2020-09-08 18:00:00 | 94105 | 64 | 69 |
| 2020-09-08 21:00:00 | 94105 | 72 | 76 |
+---------------------+----------+-----------------+-----------------*/
3-Stunden-Durchschnitt mit benutzerdefinierter Ausrichtung erhalten
Wenn Sie eine Zeitreihenaggregation durchführen, verwenden Sie eine bestimmte Ausrichtung für Zeitreihenfenster, entweder implizit oder explizit. Die vorherigen Abfragen verwendeten die implizite Ausrichtung, die Buckets erzeugte, die zu Zeiten wie 00:00:00, 03:00:00 und 06:00:00 gestartet wurden. Um diese Ausrichtung explizit in der Funktion TIMESTAMP_BUCKET festzulegen, übergeben Sie ein optionales Argument, das den Ursprung angibt.
In der folgenden Abfrage wird der Ursprung als 2020-01-01 02:00:00 festgelegt. Dadurch wird die Ausrichtung geändert und Buckets erstellt, die zu Zeiten wie 02:00:00, 05:00:00 und 08:00:00 beginnen:
SELECT
TIMESTAMP_BUCKET(time, INTERVAL 3 HOUR, TIMESTAMP '2020-01-01 02:00:00') AS time,
zip_code,
CAST(AVG(aqi) AS INT64) AS aqi,
CAST(AVG(temperature) AS INT64) AS temperature
FROM mydataset.environmental_data_hourly
GROUP BY zip_code, time
ORDER BY zip_code, time;
/*---------------------+----------+-----+-------------+
| time | zip_code | aqi | temperature |
+---------------------+----------+-----+-------------+
| 2020-09-07 23:00:00 | 60606 | 23 | 65 |
| 2020-09-08 02:00:00 | 60606 | 21 | 59 |
| 2020-09-08 05:00:00 | 60606 | 24 | 56 |
| 2020-09-08 08:00:00 | 60606 | 33 | 55 |
| 2020-09-08 11:00:00 | 60606 | 38 | 56 |
| 2020-09-08 14:00:00 | 60606 | 43 | 62 |
| 2020-09-08 17:00:00 | 60606 | 37 | 68 |
| 2020-09-08 20:00:00 | 60606 | 27 | 66 |
| 2020-09-08 23:00:00 | 60606 | 22 | 63 |
| 2020-09-07 23:00:00 | 94105 | 61 | 74 |
| 2020-09-08 02:00:00 | 94105 | 67 | 69 |
| 2020-09-08 05:00:00 | 94105 | 72 | 65 |
| 2020-09-08 08:00:00 | 94105 | 90 | 63 |
| 2020-09-08 11:00:00 | 94105 | 120 | 62 |
| 2020-09-08 14:00:00 | 94105 | 143 | 62 |
| 2020-09-08 17:00:00 | 94105 | 153 | 65 |
| 2020-09-08 20:00:00 | 94105 | 147 | 72 |
| 2020-09-08 23:00:00 | 94105 | 137 | 75 |
+---------------------+----------+-----+-------------*/
Zeitreihen mit Lückenfüllung aggregieren
Manchmal treten in den Daten nach dem Aggregieren Lücken auf, die zur weiteren Analyse oder Darstellung der Daten mit Werten gefüllt werden müssen.
Die Technik, mit der diese Lücken geschlossen werden, wird als Lückenfüllung bezeichnet. In BigQuery können Sie die Tabellenfunktion GAP_FILL verwenden, um Lücken in Zeitreihendaten mithilfe einer der bereitgestellten Methoden zur Lückenfüllung zu füllen:
- NULL, auch als Konstante bezeichnet
- LOCF, letzte Beobachtung
- Lineare, lineare Interpolation zwischen den beiden benachbarten Datenpunkten
Erstellen Sie für die Abfragen in diesem Abschnitt eine Tabelle mit dem Namen mydataset.environmental_data_hourly_with_gaps, die auf den im vorherigen Abschnitt verwendeten Daten basiert, jedoch mit Lücken enthält. In der Praxis können den Daten aufgrund einer kurzfristigen Fehlfunktion der Wetterstation Datenpunkte fehlen.
CREATE OR REPLACE TABLE mydataset.environmental_data_hourly_with_gaps AS
SELECT * FROM UNNEST(
ARRAY<STRUCT<zip_code INT64, time TIMESTAMP, aqi INT64, temperature INT64>>[
STRUCT(60606, TIMESTAMP '2020-09-08 00:30:51', 22, 66),
STRUCT(60606, TIMESTAMP '2020-09-08 01:32:10', 23, 63),
STRUCT(60606, TIMESTAMP '2020-09-08 02:30:35', 22, 60),
STRUCT(60606, TIMESTAMP '2020-09-08 03:29:39', 21, 58),
STRUCT(60606, TIMESTAMP '2020-09-08 04:33:05', 21, 59),
STRUCT(60606, TIMESTAMP '2020-09-08 05:32:01', 21, 57),
STRUCT(60606, TIMESTAMP '2020-09-08 06:31:14', 22, 56),
STRUCT(60606, TIMESTAMP '2020-09-08 07:31:06', 28, 55),
STRUCT(60606, TIMESTAMP '2020-09-08 08:29:59', 30, 55),
STRUCT(60606, TIMESTAMP '2020-09-08 09:29:34', 31, 55),
STRUCT(60606, TIMESTAMP '2020-09-08 10:31:24', 38, 56),
STRUCT(60606, TIMESTAMP '2020-09-08 11:31:24', 38, 56),
-- No data points between hours 12 and 15.
STRUCT(60606, TIMESTAMP '2020-09-08 16:34:22', 43, 65),
STRUCT(60606, TIMESTAMP '2020-09-08 17:33:23', 42, 68),
STRUCT(60606, TIMESTAMP '2020-09-08 18:28:47', 36, 69),
STRUCT(60606, TIMESTAMP '2020-09-08 19:30:28', 34, 67),
STRUCT(60606, TIMESTAMP '2020-09-08 20:30:53', 29, 67),
STRUCT(60606, TIMESTAMP '2020-09-08 21:32:28', 27, 67),
STRUCT(60606, TIMESTAMP '2020-09-08 22:31:45', 25, 65),
STRUCT(60606, TIMESTAMP '2020-09-08 23:31:02', 22, 63),
STRUCT(94105, TIMESTAMP '2020-09-08 00:07:11', 60, 74),
STRUCT(94105, TIMESTAMP '2020-09-08 01:07:24', 61, 73),
STRUCT(94105, TIMESTAMP '2020-09-08 02:08:07', 60, 71),
STRUCT(94105, TIMESTAMP '2020-09-08 03:11:05', 69, 69),
STRUCT(94105, TIMESTAMP '2020-09-08 04:07:26', 72, 67),
STRUCT(94105, TIMESTAMP '2020-09-08 05:08:11', 70, 66),
STRUCT(94105, TIMESTAMP '2020-09-08 06:07:30', 68, 65),
STRUCT(94105, TIMESTAMP '2020-09-08 07:07:10', 77, 64),
STRUCT(94105, TIMESTAMP '2020-09-08 08:06:35', 81, 64),
STRUCT(94105, TIMESTAMP '2020-09-08 09:10:18', 82, 63),
STRUCT(94105, TIMESTAMP '2020-09-08 10:08:10', 107, 62),
STRUCT(94105, TIMESTAMP '2020-09-08 11:08:01', 115, 62),
STRUCT(94105, TIMESTAMP '2020-09-08 12:07:39', 120, 62),
STRUCT(94105, TIMESTAMP '2020-09-08 13:06:03', 125, 61),
STRUCT(94105, TIMESTAMP '2020-09-08 14:08:37', 129, 62),
-- No data points between hours 15 and 18.
STRUCT(94105, TIMESTAMP '2020-09-08 19:08:43', 151, 67),
STRUCT(94105, TIMESTAMP '2020-09-08 20:07:19', 150, 69),
STRUCT(94105, TIMESTAMP '2020-09-08 21:07:37', 148, 72),
STRUCT(94105, TIMESTAMP '2020-09-08 22:08:01', 143, 76),
STRUCT(94105, TIMESTAMP '2020-09-08 23:08:41', 137, 75)
]);
3-Stunden-Durchschnitt abrufen (mit Lücken)
Die folgende Abfrage berechnet für jede Postleitzahl einen durchschnittlichen AQI-Wert und eine Temperatur von 3 Stunden:
SELECT
TIMESTAMP_BUCKET(time, INTERVAL 3 HOUR) AS time,
zip_code,
CAST(AVG(aqi) AS INT64) AS aqi,
CAST(AVG(temperature) AS INT64) AS temperature
FROM mydataset.environmental_data_hourly_with_gaps
GROUP BY zip_code, time
ORDER BY zip_code, time;
/*---------------------+----------+-----+-------------+
| time | zip_code | aqi | temperature |
+---------------------+----------+-----+-------------+
| 2020-09-08 00:00:00 | 60606 | 22 | 63 |
| 2020-09-08 03:00:00 | 60606 | 21 | 58 |
| 2020-09-08 06:00:00 | 60606 | 27 | 55 |
| 2020-09-08 09:00:00 | 60606 | 36 | 56 |
| 2020-09-08 15:00:00 | 60606 | 43 | 67 |
| 2020-09-08 18:00:00 | 60606 | 33 | 68 |
| 2020-09-08 21:00:00 | 60606 | 25 | 65 |
| 2020-09-08 00:00:00 | 94105 | 60 | 73 |
| 2020-09-08 03:00:00 | 94105 | 70 | 67 |
| 2020-09-08 06:00:00 | 94105 | 75 | 64 |
| 2020-09-08 09:00:00 | 94105 | 101 | 62 |
| 2020-09-08 12:00:00 | 94105 | 125 | 62 |
| 2020-09-08 18:00:00 | 94105 | 151 | 68 |
| 2020-09-08 21:00:00 | 94105 | 143 | 74 |
+---------------------+----------+-----+-------------*/
Beachten Sie, wie die Ausgabe in bestimmten Zeitintervallen Lücken aufweist. Beispiel: Die Zeitreihe für die Postleitzahl 60606 hat keinen Datenpunkt bei 2020-09-08 12:00:00 und die Zeitreihe für die Postleitzahl 94105 keinen Datenpunkt. bei 2020-09-08 15:00:00.
3-Stunden-Durchschnitt abrufen (Lücken auffüllen)
Verwenden Sie die Abfrage aus dem vorherigen Abschnitt und fügen Sie die Funktion GAP_FILL hinzu, um die Lücken zu schließen:
WITH aggregated_3_hr AS (
SELECT
TIMESTAMP_BUCKET(time, INTERVAL 3 HOUR) AS time,
zip_code,
CAST(AVG(aqi) AS INT64) AS aqi,
CAST(AVG(temperature) AS INT64) AS temperature
FROM mydataset.environmental_data_hourly_with_gaps
GROUP BY zip_code, time)
SELECT *
FROM GAP_FILL(
TABLE aggregated_3_hr,
ts_column => 'time',
bucket_width => INTERVAL 3 HOUR,
partitioning_columns => ['zip_code']
)
ORDER BY zip_code, time;
/*---------------------+----------+------+-------------+
| time | zip_code | aqi | temperature |
+---------------------+----------+------+-------------+
| 2020-09-08 00:00:00 | 60606 | 22 | 63 |
| 2020-09-08 03:00:00 | 60606 | 21 | 58 |
| 2020-09-08 06:00:00 | 60606 | 27 | 55 |
| 2020-09-08 09:00:00 | 60606 | 36 | 56 |
| 2020-09-08 12:00:00 | 60606 | NULL | NULL |
| 2020-09-08 15:00:00 | 60606 | 43 | 67 |
| 2020-09-08 18:00:00 | 60606 | 33 | 68 |
| 2020-09-08 21:00:00 | 60606 | 25 | 65 |
| 2020-09-08 00:00:00 | 94105 | 60 | 73 |
| 2020-09-08 03:00:00 | 94105 | 70 | 67 |
| 2020-09-08 06:00:00 | 94105 | 75 | 64 |
| 2020-09-08 09:00:00 | 94105 | 101 | 62 |
| 2020-09-08 12:00:00 | 94105 | 125 | 62 |
| 2020-09-08 15:00:00 | 94105 | NULL | NULL |
| 2020-09-08 18:00:00 | 94105 | 151 | 68 |
| 2020-09-08 21:00:00 | 94105 | 143 | 74 |
+---------------------+----------+------+-------------*/
Die Ausgabetabelle enthält nun eine fehlende Zeile unter 2020-09-08 12:00:00 für die Postleitzahl 60606 und unter 2020-09-08 15:00:00 für die Postleitzahl 94105, mit NULL-Werten in den entsprechenden Messwert-Spalten. Da Sie keine Methode zur Lückenfüllung angegeben haben, hat GAP_FILL die Standardmethode NULL verwendet.
Lücken mit linearer und LOCF-Lückenfüllung auffüllen
In der folgenden Abfrage wird die GAP_FILL-Funktion mit der LOCF-Gap-Füllungsmethode für die Spalte aqi und der linearen Interpolation für die Spalte temperature verwendet:
WITH aggregated_3_hr AS (
SELECT
TIMESTAMP_BUCKET(time, INTERVAL 3 HOUR) AS time,
zip_code,
CAST(AVG(aqi) AS INT64) AS aqi,
CAST(AVG(temperature) AS INT64) AS temperature
FROM mydataset.environmental_data_hourly_with_gaps
GROUP BY zip_code, time)
SELECT *
FROM GAP_FILL(
TABLE aggregated_3_hr,
ts_column => 'time',
bucket_width => INTERVAL 3 HOUR,
partitioning_columns => ['zip_code'],
value_columns => [
('aqi', 'locf'),
('temperature', 'linear')
]
)
ORDER BY zip_code, time;
/*---------------------+----------+-----+-------------+
| time | zip_code | aqi | temperature |
+---------------------+----------+-----+-------------+
| 2020-09-08 00:00:00 | 60606 | 22 | 63 |
| 2020-09-08 03:00:00 | 60606 | 21 | 58 |
| 2020-09-08 06:00:00 | 60606 | 27 | 55 |
| 2020-09-08 09:00:00 | 60606 | 36 | 56 |
| 2020-09-08 12:00:00 | 60606 | 36 | 62 |
| 2020-09-08 15:00:00 | 60606 | 43 | 67 |
| 2020-09-08 18:00:00 | 60606 | 33 | 68 |
| 2020-09-08 21:00:00 | 60606 | 25 | 65 |
| 2020-09-08 00:00:00 | 94105 | 60 | 73 |
| 2020-09-08 03:00:00 | 94105 | 70 | 67 |
| 2020-09-08 06:00:00 | 94105 | 75 | 64 |
| 2020-09-08 09:00:00 | 94105 | 101 | 62 |
| 2020-09-08 12:00:00 | 94105 | 125 | 62 |
| 2020-09-08 15:00:00 | 94105 | 125 | 65 |
| 2020-09-08 18:00:00 | 94105 | 151 | 68 |
| 2020-09-08 21:00:00 | 94105 | 143 | 74 |
+---------------------+----------+-----+-------------*/
In dieser Abfrage hat die erste Zeile mit Lücken den aqi-Wert 36, der aus dem vorherigen Datenpunkt dieser Zeitreihe (Postleitzahl 60606) bei 2020-09-08 09:00:00 stammt. Der temperature-Wert 62 ist das Ergebnis der linearen Interpolation zwischen den Datenpunkten 2020-09-08 09:00:00 und 2020-09-08 15:00:00. Die andere fehlende Zeile wurde auf ähnliche Weise erstellt. Der aqi-Wert 125 wurde vom vorherigen Datenpunkt dieser Zeitreihe (Postleitzahl 94105) übernommen. Und der Temperaturwert 65 ist das Ergebnis der linearen Interpolation zwischen dem vorherigen und den nächsten verfügbaren Datenpunkten.
Zeitreihe mit Lückenfüllung ausrichten
Zeitreihen können ausgerichtet oder nicht ausgerichtet sein. Eine Zeitreihe wird ausgerichtet, wenn Datenpunkte nur in regelmäßigen Abständen auftreten.
In der Praxis sind Zeitreihen zum Zeitpunkt der Erfassung selten ausgerichtet und erfordern in der Regel eine weitere Verarbeitung, um sie auszurichten.
Nehmen wir als Beispiel IoT-Geräte, die ihre Messwerte jede Minute an einen zentralen Collector senden. Es wäre nicht vernünftig zu erwarten, dass die Geräte ihre Messwerte genau zur gleichen Zeit senden. Normalerweise sendet jedes Gerät seine Messwerte mit der gleichen Frequenz (Zeitraum), aber mit einem anderen Zeitversatz (Ausrichtung). Das folgende Diagramm zeigt dieses Beispiel: Sie können sehen, dass jedes Gerät seine Daten im Intervall von einer Minute sendet, wobei einige Instanzen fehlender Daten (Gerät 3 unter 9:36:39 ) und verzögerte Daten (Gerät 1 um 9:37:28) vorliegen.

Sie können die Zeitreihenausrichtung für nicht ausgerichtete Daten mithilfe der Zeitaggregation durchführen. Dies ist hilfreich, wenn Sie den Stichprobenzeitraum der Zeitreihe ändern möchten, z. B. vom ursprünglichen 1-minütigen Stichprobenzeitraum auf 15 Minuten festlegen. Sie können Daten für die weitere Verarbeitung von Zeitreihen, z. B. für das Zusammenführen der Zeitreihendaten, oder für Anzeigezwecke (z. B. grafische Darstellung) ausrichten.
Sie können die Tabellenfunktion GAP_FILL mit LOCF- oder linearen Lücken-Füllungsmethoden verwenden, um eine Zeitreihenausrichtung durchzuführen. Die Idee ist, GAP_FILL mit dem ausgewählten Ausgabezeitraum und der ausgewählten Ausrichtung zu verwenden (gesteuert durch das optionale Ursprungsargument). Das Ergebnis des Vorgangs ist eine Tabelle mit ausgerichteten Zeitreihen, in denen die Werte für jeden Datenpunkt aus der Eingabezeitreihe mit der Methode zur Lückenfüllung abgeleitet werden, die für die jeweilige Wertespalte verwendet wird (LOCF von linear).
Erstellen Sie eine Tabelle mydataset.device_data, die der vorherigen Abbildung ähnelt:
CREATE OR REPLACE TABLE mydataset.device_data AS
SELECT * FROM UNNEST(
ARRAY<STRUCT<device_id INT64, time TIMESTAMP, signal INT64, state STRING>>[
STRUCT(2, TIMESTAMP '2023-11-01 09:35:07', 87, 'ACTIVE'),
STRUCT(1, TIMESTAMP '2023-11-01 09:35:26', 82, 'ACTIVE'),
STRUCT(3, TIMESTAMP '2023-11-01 09:35:39', 74, 'INACTIVE'),
STRUCT(2, TIMESTAMP '2023-11-01 09:36:07', 88, 'ACTIVE'),
STRUCT(1, TIMESTAMP '2023-11-01 09:36:26', 82, 'ACTIVE'),
STRUCT(2, TIMESTAMP '2023-11-01 09:37:07', 88, 'ACTIVE'),
STRUCT(1, TIMESTAMP '2023-11-01 09:37:28', 80, 'ACTIVE'),
STRUCT(3, TIMESTAMP '2023-11-01 09:37:39', 77, 'ACTIVE'),
STRUCT(2, TIMESTAMP '2023-11-01 09:38:07', 86, 'ACTIVE'),
STRUCT(1, TIMESTAMP '2023-11-01 09:38:26', 81, 'ACTIVE'),
STRUCT(3, TIMESTAMP '2023-11-01 09:38:39', 77, 'ACTIVE')
]);
Im Folgenden sehen Sie die tatsächlichen Daten, sortiert nach den Spalten time und device_id:
SELECT * FROM mydataset.device_data ORDER BY time, device_id;
/*-----------+---------------------+--------+----------+
| device_id | time | signal | state |
+-----------+---------------------+--------+----------+
| 2 | 2023-11-01 09:35:07 | 87 | ACTIVE |
| 1 | 2023-11-01 09:35:26 | 82 | ACTIVE |
| 3 | 2023-11-01 09:35:39 | 74 | INACTIVE |
| 2 | 2023-11-01 09:36:07 | 88 | ACTIVE |
| 1 | 2023-11-01 09:36:26 | 82 | ACTIVE |
| 2 | 2023-11-01 09:37:07 | 88 | ACTIVE |
| 1 | 2023-11-01 09:37:28 | 80 | ACTIVE |
| 3 | 2023-11-01 09:37:39 | 77 | ACTIVE |
| 2 | 2023-11-01 09:38:07 | 86 | ACTIVE |
| 1 | 2023-11-01 09:38:26 | 81 | ACTIVE |
| 3 | 2023-11-01 09:38:39 | 77 | ACTIVE |
+-----------+---------------------+--------+----------*/
Die Tabelle enthält die Zeitreihen für jedes Gerät mit zwei Messwertspalten:
signal: Signalstufe, die vom Gerät zum Zeitpunkt der Probenahme beobachtet wird, dargestellt als ganzzahliger Wert zwischen0und100.state: Status des Geräts zum Zeitpunkt der Probenahme, dargestellt als Freitextstring.
In der folgenden Abfrage wird die Funktion GAP_FILL verwendet, um die Zeitreihe in 1-Minuten-Intervallen auszurichten. Beachten Sie, wie zur Berechnung der Werte für die Spalte signal und von LOCF für die Spalte state die lineare Interpolation verwendet wird. In diesen Beispieldaten ist die lineare Interpolation eine geeignete Wahl, um die Ausgabewerte zu berechnen.
SELECT *
FROM GAP_FILL(
TABLE mydataset.device_data,
ts_column => 'time',
bucket_width => INTERVAL 1 MINUTE,
partitioning_columns => ['device_id'],
value_columns => [
('signal', 'linear'),
('state', 'locf')
]
)
ORDER BY time, device_id;
/*---------------------+-----------+--------+----------+
| time | device_id | signal | state |
+---------------------+-----------+--------+----------+
| 2023-11-01 09:36:00 | 1 | 82 | ACTIVE |
| 2023-11-01 09:36:00 | 2 | 88 | ACTIVE |
| 2023-11-01 09:36:00 | 3 | 75 | INACTIVE |
| 2023-11-01 09:37:00 | 1 | 81 | ACTIVE |
| 2023-11-01 09:37:00 | 2 | 88 | ACTIVE |
| 2023-11-01 09:37:00 | 3 | 76 | INACTIVE |
| 2023-11-01 09:38:00 | 1 | 81 | ACTIVE |
| 2023-11-01 09:38:00 | 2 | 86 | ACTIVE |
| 2023-11-01 09:38:00 | 3 | 77 | ACTIVE |
+---------------------+-----------+--------+----------*/
Die Ausgabetabelle enthält eine ausgerichtete Zeitreihe für jede Geräte- und Wertspalte (signal und state), die mit den im Funktionsaufruf angegebenen Methoden zur Lückenfüllung berechnet werden.
Zeitreihendaten verknüpfen
Sie können Zeitreihendaten mit einem Windowed Join oder einem AS OF-Join verknüpfen.
Windowed-Join
Manchmal müssen Sie zwei oder mehr Tabellen mit Zeitreihendaten zusammenführen. Sehen Sie sich die folgenden beiden Tabellen an:
mydataset.sensor_temperaturesenthält Temperaturdaten, die alle 15 Sekunden von jedem Sensor gemeldet werden.mydataset.sensor_fuel_ratesenthält die Kraftstoffverbrauchsrate, die alle 15 Sekunden von jedem Sensor gemessen wird.
Führen Sie die folgenden Abfragen aus, um diese Tabellen zu erstellen:
CREATE OR REPLACE TABLE mydataset.sensor_temperatures AS
SELECT * FROM UNNEST(
ARRAY<STRUCT<sensor_id INT64, ts TIMESTAMP, temp FLOAT64>>[
(1, TIMESTAMP '2020-01-01 12:00:00.063', 37.1),
(1, TIMESTAMP '2020-01-01 12:00:15.024', 37.2),
(1, TIMESTAMP '2020-01-01 12:00:30.032', 37.3),
(2, TIMESTAMP '2020-01-01 12:00:01.001', 38.1),
(2, TIMESTAMP '2020-01-01 12:00:15.082', 38.2),
(2, TIMESTAMP '2020-01-01 12:00:31.009', 38.3)
]);
CREATE OR REPLACE TABLE mydataset.sensor_fuel_rates AS
SELECT * FROM UNNEST(
ARRAY<STRUCT<sensor_id INT64, ts TIMESTAMP, rate FLOAT64>>[
(1, TIMESTAMP '2020-01-01 12:00:11.016', 10.1),
(1, TIMESTAMP '2020-01-01 12:00:26.015', 10.2),
(1, TIMESTAMP '2020-01-01 12:00:41.014', 10.3),
(2, TIMESTAMP '2020-01-01 12:00:08.099', 11.1),
(2, TIMESTAMP '2020-01-01 12:00:23.087', 11.2),
(2, TIMESTAMP '2020-01-01 12:00:38.077', 11.3)
]);
Im Folgenden sind die tatsächlichen Daten aus den Tabellen aufgeführt:
SELECT * FROM mydataset.sensor_temperatures ORDER BY sensor_id, ts;
/*-----------+---------------------+------+
| sensor_id | ts | temp |
+-----------+---------------------+------+
| 1 | 2020-01-01 12:00:00 | 37.1 |
| 1 | 2020-01-01 12:00:15 | 37.2 |
| 1 | 2020-01-01 12:00:30 | 37.3 |
| 2 | 2020-01-01 12:00:01 | 38.1 |
| 2 | 2020-01-01 12:00:15 | 38.2 |
| 2 | 2020-01-01 12:00:31 | 38.3 |
+-----------+---------------------+------*/
SELECT * FROM mydataset.sensor_fuel_rates ORDER BY sensor_id, ts;
/*-----------+---------------------+------+
| sensor_id | ts | rate |
+-----------+---------------------+------+
| 1 | 2020-01-01 12:00:11 | 10.1 |
| 1 | 2020-01-01 12:00:26 | 10.2 |
| 1 | 2020-01-01 12:00:41 | 10.3 |
| 2 | 2020-01-01 12:00:08 | 11.1 |
| 2 | 2020-01-01 12:00:23 | 11.2 |
| 2 | 2020-01-01 12:00:38 | 11.3 |
+-----------+---------------------+------*/
Sie können die beiden Zeitreihen verknüpfen, um die Kraftstoffverbrauchsrate bei der von jedem Sensor gemeldeten Temperatur zu prüfen.
Obwohl die Daten in den beiden Zeitreihen nicht ausgerichtet sind, werden sie im selben Intervall (15 Sekunden) erfasst. Daher sind solche Daten ein guter Kandidat für Windowed Join. Mit den Zeit-Bucketing-Funktionen können Sie Zeitstempel, die als Join-Schlüssel verwendet werden, ausrichten.
Die folgenden Abfragen zeigen, wie jeder Zeitstempel mithilfe der Funktion TIMESTAMP_BUCKET 15-Sekunden-Fenstern zugewiesen werden kann:
SELECT *, TIMESTAMP_BUCKET(ts, INTERVAL 15 SECOND) ts_window
FROM mydataset.sensor_temperatures
ORDER BY sensor_id, ts;
/*-----------+---------------------+------+---------------------+
| sensor_id | ts | temp | ts_window |
+-----------+---------------------+------+---------------------+
| 1 | 2020-01-01 12:00:00 | 37.1 | 2020-01-01 12:00:00 |
| 1 | 2020-01-01 12:00:15 | 37.2 | 2020-01-01 12:00:15 |
| 1 | 2020-01-01 12:00:30 | 37.3 | 2020-01-01 12:00:30 |
| 2 | 2020-01-01 12:00:01 | 38.1 | 2020-01-01 12:00:00 |
| 2 | 2020-01-01 12:00:15 | 38.2 | 2020-01-01 12:00:15 |
| 2 | 2020-01-01 12:00:31 | 38.3 | 2020-01-01 12:00:30 |
+-----------+---------------------+------+---------------------*/
SELECT *, TIMESTAMP_BUCKET(ts, INTERVAL 15 SECOND) ts_window
FROM mydataset.sensor_fuel_rates
ORDER BY sensor_id, ts;
/*-----------+---------------------+------+---------------------+
| sensor_id | ts | rate | ts_window |
+-----------+---------------------+------+---------------------+
| 1 | 2020-01-01 12:00:11 | 10.1 | 2020-01-01 12:00:00 |
| 1 | 2020-01-01 12:00:26 | 10.2 | 2020-01-01 12:00:15 |
| 1 | 2020-01-01 12:00:41 | 10.3 | 2020-01-01 12:00:30 |
| 2 | 2020-01-01 12:00:08 | 11.1 | 2020-01-01 12:00:00 |
| 2 | 2020-01-01 12:00:23 | 11.2 | 2020-01-01 12:00:15 |
| 2 | 2020-01-01 12:00:38 | 11.3 | 2020-01-01 12:00:30 |
+-----------+---------------------+------+---------------------*/
Sie können dieses Konzept verwenden, um die Daten zur Kraftstoffverbrauchsrate mit der von jedem Sensor gemeldeten Temperatur zu verknüpfen:
SELECT
t1.sensor_id AS sensor_id,
t1.ts AS temp_ts,
t1.temp AS temp,
t2.ts AS rate_ts,
t2.rate AS rate
FROM mydataset.sensor_temperatures t1
LEFT JOIN mydataset.sensor_fuel_rates t2
ON TIMESTAMP_BUCKET(t1.ts, INTERVAL 15 SECOND) =
TIMESTAMP_BUCKET(t2.ts, INTERVAL 15 SECOND)
AND t1.sensor_id = t2.sensor_id
ORDER BY sensor_id, temp_ts;
/*-----------+---------------------+------+---------------------+------+
| sensor_id | temp_ts | temp | rate_ts | rate |
+-----------+---------------------+------+---------------------+------+
| 1 | 2020-01-01 12:00:00 | 37.1 | 2020-01-01 12:00:11 | 10.1 |
| 1 | 2020-01-01 12:00:15 | 37.2 | 2020-01-01 12:00:26 | 10.2 |
| 1 | 2020-01-01 12:00:30 | 37.3 | 2020-01-01 12:00:41 | 10.3 |
| 2 | 2020-01-01 12:00:01 | 38.1 | 2020-01-01 12:00:08 | 11.1 |
| 2 | 2020-01-01 12:00:15 | 38.2 | 2020-01-01 12:00:23 | 11.2 |
| 2 | 2020-01-01 12:00:31 | 38.3 | 2020-01-01 12:00:38 | 11.3 |
+-----------+---------------------+------+---------------------+------*/
AS OF zusammenführen
Verwenden Sie für diesen Abschnitt die Tabelle mydataset.sensor_temperatures und erstellen Sie eine neue Tabelle, mydataset.sensor_location.
Die Tabelle mydataset.sensor_temperatures enthält Temperaturdaten von verschiedenen Sensoren, die alle 15 Sekunden gemeldet werden:
SELECT * FROM mydataset.sensor_temperatures ORDER BY sensor_id, ts;
/*-----------+---------------------+------+
| sensor_id | ts | temp |
+-----------+---------------------+------+
| 1 | 2020-01-01 12:00:00 | 37.1 |
| 1 | 2020-01-01 12:00:15 | 37.2 |
| 1 | 2020-01-01 12:00:30 | 37.3 |
| 2 | 2020-01-01 12:00:45 | 38.1 |
| 2 | 2020-01-01 12:01:01 | 38.2 |
| 2 | 2020-01-01 12:01:15 | 38.3 |
+-----------+---------------------+------*/
Führen Sie die folgende Abfrage aus, um mydataset.sensor_location zu erstellen:
CREATE OR REPLACE TABLE mydataset.sensor_locations AS
SELECT * FROM UNNEST(
ARRAY<STRUCT<sensor_id INT64, ts TIMESTAMP, location GEOGRAPHY>>[
(1, TIMESTAMP '2020-01-01 11:59:47.063', ST_GEOGPOINT(-122.022, 37.406)),
(1, TIMESTAMP '2020-01-01 12:00:08.185', ST_GEOGPOINT(-122.021, 37.407)),
(1, TIMESTAMP '2020-01-01 12:00:28.032', ST_GEOGPOINT(-122.020, 37.405)),
(2, TIMESTAMP '2020-01-01 07:28:41.239', ST_GEOGPOINT(-122.390, 37.790))
]);
/*-----------+---------------------+------------------------+
| sensor_id | ts | location |
+-----------+---------------------+------------------------+
| 1 | 2020-01-01 11:59:47 | POINT(-122.022 37.406) |
| 1 | 2020-01-01 12:00:08 | POINT(-122.021 37.407) |
| 1 | 2020-01-01 12:00:28 | POINT(-122.02 37.405) |
| 2 | 2020-01-01 07:28:41 | POINT(-122.39 37.79) |
+-----------+---------------------+------------------------*/
Führen Sie jetzt Daten aus mydataset.sensor_temperatures mit Daten aus mydataset.sensor_location zusammen.
In diesem Szenario können Sie keinen Windowed Join verwenden, da die Temperaturdaten und das Standortdatum nicht im selben Intervall gemeldet werden.
Eine Möglichkeit in BigQuery besteht darin, die Zeitstempeldaten mithilfe des Datentyps RANGE in einen Bereich umzuwandeln. Der Bereich stellt die zeitliche Gültigkeit einer Zeile dar und gibt die Start- und Endzeit an, für die die Zeile gültig ist.
Verwenden Sie die Fensterfunktion LEAD, um den nächsten Datenpunkt in der Zeitreihe relativ zum aktuellen Datenpunkt zu finden, der auch die Endgrenze der zeitlichen Gültigkeit der aktuellen Zeile ist. Das wird in den folgenden Abfragen veranschaulicht, wobei Standortdaten in Gültigkeitsbereiche konvertiert werden:
WITH locations_ranges AS (
SELECT
sensor_id,
RANGE(ts, LEAD(ts) OVER (PARTITION BY sensor_id ORDER BY ts ASC)) AS ts_range,
location
FROM mydataset.sensor_locations
)
SELECT * FROM locations_ranges ORDER BY sensor_id, ts_range;
/*-----------+--------------------------------------------+------------------------+
| sensor_id | ts_range | location |
+-----------+--------------------------------------------+------------------------+
| 1 | [2020-01-01 11:59:47, 2020-01-01 12:00:08) | POINT(-122.022 37.406) |
| 1 | [2020-01-01 12:00:08, 2020-01-01 12:00:28) | POINT(-122.021 37.407) |
| 1 | [2020-01-01 12:00:28, UNBOUNDED) | POINT(-122.02 37.405) |
| 2 | [2020-01-01 07:28:41, UNBOUNDED) | POINT(-122.39 37.79) |
+-----------+--------------------------------------------+------------------------*/
Jetzt können Sie Temperaturdaten (links) mit den Standortdaten (rechts) zusammenführen:
WITH locations_ranges AS (
SELECT
sensor_id,
RANGE(ts, LEAD(ts) OVER (PARTITION BY sensor_id ORDER BY ts ASC)) AS ts_range,
location
FROM mydataset.sensor_locations
)
SELECT
t1.sensor_id AS sensor_id,
t1.ts AS temp_ts,
t1.temp AS temp,
t2.location AS location
FROM mydataset.sensor_temperatures t1
LEFT JOIN locations_ranges t2
ON RANGE_CONTAINS(t2.ts_range, t1.ts)
AND t1.sensor_id = t2.sensor_id
ORDER BY sensor_id, temp_ts;
/*-----------+---------------------+------+------------------------+
| sensor_id | temp_ts | temp | location |
+-----------+---------------------+------+------------------------+
| 1 | 2020-01-01 12:00:00 | 37.1 | POINT(-122.022 37.406) |
| 1 | 2020-01-01 12:00:15 | 37.2 | POINT(-122.021 37.407) |
| 1 | 2020-01-01 12:00:30 | 37.3 | POINT(-122.02 37.405) |
| 2 | 2020-01-01 12:00:01 | 38.1 | POINT(-122.39 37.79) |
| 2 | 2020-01-01 12:00:15 | 38.2 | POINT(-122.39 37.79) |
| 2 | 2020-01-01 12:00:31 | 38.3 | POINT(-122.39 37.79) |
+-----------+---------------------+------+------------------------*/
Bereichsdaten kombinieren und aufteilen
Kombinieren Sie in diesem Abschnitt Bereichsdaten mit sich überschneidenden Bereichen und teilen Sie Bereichsdaten in kleinere Bereiche auf.
Bereichsdaten kombinieren
Tabellen mit Bereichswerten können überlappende Bereiche haben. In der folgenden Abfrage erfassen die Zeiträume den Status der Sensoren in etwa 5-Minuten-Intervallen:
CREATE OR REPLACE TABLE mydataset.sensor_metrics AS
SELECT * FROM UNNEST(
ARRAY<STRUCT<sensor_id INT64, duration RANGE<DATETIME>, flow INT64, spins INT64>>[
(1, RANGE<DATETIME> "[2020-01-01 12:00:01, 2020-01-01 12:05:23)", 10, 1),
(1, RANGE<DATETIME> "[2020-01-01 12:05:12, 2020-01-01 12:10:46)", 10, 20),
(1, RANGE<DATETIME> "[2020-01-01 12:10:27, 2020-01-01 12:15:56)", 11, 4),
(1, RANGE<DATETIME> "[2020-01-01 12:16:00, 2020-01-01 12:20:58)", 11, 9),
(1, RANGE<DATETIME> "[2020-01-01 12:20:33, 2020-01-01 12:25:08)", 11, 8),
(2, RANGE<DATETIME> "[2020-01-01 12:00:19, 2020-01-01 12:05:08)", 21, 31),
(2, RANGE<DATETIME> "[2020-01-01 12:05:08, 2020-01-01 12:10:30)", 21, 2),
(2, RANGE<DATETIME> "[2020-01-01 12:10:22, 2020-01-01 12:15:42)", 21, 10)
]);
Die folgende Abfrage in der Tabelle zeigt mehrere überlappende Bereiche:
SELECT * FROM mydataset.sensor_metrics;
/*-----------+--------------------------------------------+------+-------+
| sensor_id | duration | flow | spins |
+-----------+--------------------------------------------+------+-------+
| 1 | [2020-01-01 12:00:01, 2020-01-01 12:05:23) | 10 | 1 |
| 1 | [2020-01-01 12:05:12, 2020-01-01 12:10:46) | 10 | 20 |
| 1 | [2020-01-01 12:10:27, 2020-01-01 12:15:56) | 11 | 4 |
| 1 | [2020-01-01 12:16:00, 2020-01-01 12:20:58) | 11 | 9 |
| 1 | [2020-01-01 12:20:33, 2020-01-01 12:25:08) | 11 | 8 |
| 2 | [2020-01-01 12:00:19, 2020-01-01 12:05:08) | 21 | 31 |
| 2 | [2020-01-01 12:05:08, 2020-01-01 12:10:30) | 21 | 2 |
| 2 | [2020-01-01 12:10:22, 2020-01-01 12:15:42) | 21 | 10 |
+-----------+--------------------------------------------+------+-------*/
Bei einigen der sich überschneidenden Bereiche ist der Wert in der Spalte flow derselbe.
Zum Beispiel überschneiden sich die Zeilen 1 und 2 und haben auch dieselben flow-Messwerte. Sie können diese beiden Zeilen kombinieren, um die Anzahl der Zeilen in der Tabelle zu reduzieren. Mit der Tabellenfunktion RANGE_SESSIONIZE können Sie Bereiche suchen, die sich mit jeder Zeile überschneiden, und eine zusätzliche session_range-Spalte bereitstellen, die einen Bereich enthält, der die Vereinigung aller überlappenden Bereiche ist. Führen Sie die folgende Abfrage aus, um die Sitzungsbereiche für jede Zeile anzeigen zu lassen:
SELECT sensor_id, session_range, flow
FROM RANGE_SESSIONIZE(
# Input data.
(SELECT sensor_id, duration, flow FROM mydataset.sensor_metrics),
# Range column.
"duration",
# Partitioning columns. Ranges are sessionized only within these partitions.
["sensor_id", "flow"],
# Sessionize mode.
"OVERLAPS")
ORDER BY sensor_id, session_range;
/*-----------+--------------------------------------------+------+
| sensor_id | session_range | flow |
+-----------+--------------------------------------------+------+
| 1 | [2020-01-01 12:00:01, 2020-01-01 12:10:46) | 10 |
| 1 | [2020-01-01 12:00:01, 2020-01-01 12:10:46) | 10 |
| 1 | [2020-01-01 12:10:27, 2020-01-01 12:15:56) | 11 |
| 1 | [2020-01-01 12:16:00, 2020-01-01 12:25:08) | 11 |
| 1 | [2020-01-01 12:16:00, 2020-01-01 12:25:08) | 11 |
| 2 | [2020-01-01 12:00:19, 2020-01-01 12:05:08) | 21 |
| 2 | [2020-01-01 12:05:08, 2020-01-01 12:15:42) | 21 |
| 2 | [2020-01-01 12:05:08, 2020-01-01 12:15:42) | 21 |
+-----------+--------------------------------------------+------*/
Beachten Sie, dass bei sensor_id mit dem Wert 2 die Endgrenze der ersten Zeile denselben Datetime-Wert wie die Startgrenze der zweiten Zeile hat. Da Endgrenzen jedoch exklusiv sind, überschneiden sie sich nicht (nur treffen) und befanden sich daher nicht in denselben Sitzungsbereichen. Wenn Sie diese beiden Zeilen in denselben Sitzungsbereiche platzieren möchten, verwenden Sie den Sitzungsmodus MEETS.
Wenn Sie die Bereiche kombinieren möchten, gruppieren Sie die Ergebnisse nach session_range und den Partitionierungsspalten (sensor_id und flow):
SELECT sensor_id, session_range, flow
FROM RANGE_SESSIONIZE(
(SELECT sensor_id, duration, flow FROM mydataset.sensor_metrics),
"duration",
["sensor_id", "flow"],
"OVERLAPS")
GROUP BY sensor_id, session_range, flow
ORDER BY sensor_id, session_range;
/*-----------+--------------------------------------------+------+
| sensor_id | session_range | flow |
+-----------+--------------------------------------------+------+
| 1 | [2020-01-01 12:00:01, 2020-01-01 12:10:46) | 10 |
| 1 | [2020-01-01 12:10:27, 2020-01-01 12:15:56) | 11 |
| 1 | [2020-01-01 12:16:00, 2020-01-01 12:25:08) | 11 |
| 2 | [2020-01-01 12:00:19, 2020-01-01 12:05:08) | 21 |
| 2 | [2020-01-01 12:05:08, 2020-01-01 12:15:42) | 21 |
+-----------+--------------------------------------------+------*/
Fügen Sie schließlich die Spalte spins den Sitzungsdaten hinzu, indem Sie sie mit SUM aggregieren.
SELECT sensor_id, session_range, flow, SUM(spins) as spins
FROM RANGE_SESSIONIZE(
TABLE mydataset.sensor_metrics,
"duration",
["sensor_id", "flow"],
"OVERLAPS")
GROUP BY sensor_id, session_range, flow
ORDER BY sensor_id, session_range;
/*-----------+--------------------------------------------+------+-------+
| sensor_id | session_range | flow | spins |
+-----------+--------------------------------------------+------+-------+
| 1 | [2020-01-01 12:00:01, 2020-01-01 12:10:46) | 10 | 21 |
| 1 | [2020-01-01 12:10:27, 2020-01-01 12:15:56) | 11 | 4 |
| 1 | [2020-01-01 12:16:00, 2020-01-01 12:25:08) | 11 | 17 |
| 2 | [2020-01-01 12:00:19, 2020-01-01 12:05:08) | 21 | 31 |
| 2 | [2020-01-01 12:05:08, 2020-01-01 12:15:42) | 21 | 12 |
+-----------+--------------------------------------------+------+-------*/
Bereichsdaten aufteilen
Sie können einen Bereich auch in kleinere Bereiche aufteilen. Verwenden Sie für dieses Beispiel die folgende Tabelle mit Bereichsdaten:
/*-----------+--------------------------+------+-------+
| sensor_id | duration | flow | spins |
+-----------+--------------------------+------+-------+
| 1 | [2020-01-01, 2020-12-31) | 10 | 21 |
| 1 | [2021-01-01, 2021-12-31) | 11 | 4 |
| 2 | [2020-04-15, 2021-04-15) | 21 | 31 |
| 2 | [2021-04-15, 2021-04-15) | 21 | 12 |
+-----------+--------------------------+------+-------*/
Teilen Sie nun die ursprünglichen Bereiche in 3-Monats-Intervalle auf:
WITH sensor_data AS (
SELECT * FROM UNNEST(
ARRAY<STRUCT<sensor_id INT64, duration RANGE<DATE>, flow INT64, spins INT64>>[
(1, RANGE<DATE> "[2020-01-01, 2020-12-31)", 10, 21),
(1, RANGE<DATE> "[2021-01-01, 2021-12-31)", 11, 4),
(2, RANGE<DATE> "[2020-04-15, 2021-04-15)", 21, 31),
(2, RANGE<DATE> "[2021-04-15, 2022-04-15)", 21, 12)
])
)
SELECT sensor_id, expanded_range, flow, spins
FROM sensor_data, UNNEST(GENERATE_RANGE_ARRAY(duration, INTERVAL 3 MONTH)) AS expanded_range;
/*-----------+--------------------------+------+-------+
| sensor_id | expanded_range | flow | spins |
+-----------+--------------------------+------+-------+
| 1 | [2020-01-01, 2020-04-01) | 10 | 21 |
| 1 | [2020-04-01, 2020-07-01) | 10 | 21 |
| 1 | [2020-07-01, 2020-10-01) | 10 | 21 |
| 1 | [2020-10-01, 2020-12-31) | 10 | 21 |
| 1 | [2021-01-01, 2021-04-01) | 11 | 4 |
| 1 | [2021-04-01, 2021-07-01) | 11 | 4 |
| 1 | [2021-07-01, 2021-10-01) | 11 | 4 |
| 1 | [2021-10-01, 2021-12-31) | 11 | 4 |
| 2 | [2020-04-15, 2020-07-15) | 21 | 31 |
| 2 | [2020-07-15, 2020-10-15) | 21 | 31 |
| 2 | [2020-10-15, 2021-01-15) | 21 | 31 |
| 2 | [2021-01-15, 2021-04-15) | 21 | 31 |
| 2 | [2021-04-15, 2021-07-15) | 21 | 12 |
| 2 | [2021-07-15, 2021-10-15) | 21 | 12 |
| 2 | [2021-10-15, 2022-01-15) | 21 | 12 |
| 2 | [2022-01-15, 2022-04-15) | 21 | 12 |
+-----------+--------------------------+------+-------*/
In der vorherigen Abfrage wurde jeder ursprüngliche Bereich in kleinere Bereiche unterteilt, wobei die Breite auf INTERVAL 3 MONTH festgelegt wurde. Die 3-Monats-Bereiche sind jedoch nicht auf einen gemeinsamen Ursprung ausgerichtet. Führen Sie die folgende Abfrage aus, um diese Bereiche an einem gemeinsamen Ursprung 2020-01-01 auszurichten:
WITH sensor_data AS (
SELECT * FROM UNNEST(
ARRAY<STRUCT<sensor_id INT64, duration RANGE<DATE>, flow INT64, spins INT64>>[
(1, RANGE<DATE> "[2020-01-01, 2020-12-31)", 10, 21),
(1, RANGE<DATE> "[2021-01-01, 2021-12-31)", 11, 4),
(2, RANGE<DATE> "[2020-04-15, 2021-04-15)", 21, 31),
(2, RANGE<DATE> "[2021-04-15, 2022-04-15)", 21, 12)
])
)
SELECT sensor_id, expanded_range, flow, spins
FROM sensor_data
JOIN UNNEST(GENERATE_RANGE_ARRAY(RANGE<DATE> "[2020-01-01, 2022-12-31)", INTERVAL 3 MONTH)) AS expanded_range
ON RANGE_OVERLAPS(duration, expanded_range);
/*-----------+--------------------------+------+-------+
| sensor_id | expanded_range | flow | spins |
+-----------+--------------------------+------+-------+
| 1 | [2020-01-01, 2020-04-01) | 10 | 21 |
| 1 | [2020-04-01, 2020-07-01) | 10 | 21 |
| 1 | [2020-07-01, 2020-10-01) | 10 | 21 |
| 1 | [2020-10-01, 2021-01-01) | 10 | 21 |
| 1 | [2021-01-01, 2021-04-01) | 11 | 4 |
| 1 | [2021-04-01, 2021-07-01) | 11 | 4 |
| 1 | [2021-07-01, 2021-10-01) | 11 | 4 |
| 1 | [2021-10-01, 2022-01-01) | 11 | 4 |
| 2 | [2020-04-01, 2020-07-01) | 21 | 31 |
| 2 | [2020-07-01, 2020-10-01) | 21 | 31 |
| 2 | [2020-10-01, 2021-01-01) | 21 | 31 |
| 2 | [2021-01-01, 2021-04-01) | 21 | 31 |
| 2 | [2021-04-01, 2021-07-01) | 21 | 31 |
| 2 | [2021-04-01, 2021-07-01) | 21 | 12 |
| 2 | [2021-07-01, 2021-10-01) | 21 | 12 |
| 2 | [2021-10-01, 2022-01-01) | 21 | 12 |
| 2 | [2022-01-01, 2022-04-01) | 21 | 12 |
| 2 | [2022-04-01, 2022-07-01) | 21 | 12 |
+-----------+--------------------------+------+-------*/
In der vorherigen Abfrage wird die Zeile mit dem Bereich [2020-04-15, 2021-04-15) in fünf Bereiche aufgeteilt, beginnend mit dem Bereich [2020-04-01, 2020-07-01). Beachten Sie, dass sich die Startgrenze nun über die ursprüngliche Startgrenze hinaus erstreckt, um eine Ausrichtung auf den gemeinsamen Ursprung vorzunehmen. Wenn Sie nicht möchten, dass die Startgrenze nicht über die ursprüngliche Startgrenze hinausgeht, können Sie die Bedingung JOIN einschränken:
WITH sensor_data AS (
SELECT * FROM UNNEST(
ARRAY<STRUCT<sensor_id INT64, duration RANGE<DATE>, flow INT64, spins INT64>>[
(1, RANGE<DATE> "[2020-01-01, 2020-12-31)", 10, 21),
(1, RANGE<DATE> "[2021-01-01, 2021-12-31)", 11, 4),
(2, RANGE<DATE> "[2020-04-15, 2021-04-15)", 21, 31),
(2, RANGE<DATE> "[2021-04-15, 2022-04-15)", 21, 12)
])
)
SELECT sensor_id, expanded_range, flow, spins
FROM sensor_data
JOIN UNNEST(GENERATE_RANGE_ARRAY(RANGE<DATE> "[2020-01-01, 2022-12-31)", INTERVAL 3 MONTH)) AS expanded_range
ON RANGE_CONTAINS(duration, RANGE_START(expanded_range));
/*-----------+--------------------------+------+-------+
| sensor_id | expanded_range | flow | spins |
+-----------+--------------------------+------+-------+
| 1 | [2020-01-01, 2020-04-01) | 10 | 21 |
| 1 | [2020-04-01, 2020-07-01) | 10 | 21 |
| 1 | [2020-07-01, 2020-10-01) | 10 | 21 |
| 1 | [2020-10-01, 2021-01-01) | 10 | 21 |
| 1 | [2021-01-01, 2021-04-01) | 11 | 4 |
| 1 | [2021-04-01, 2021-07-01) | 11 | 4 |
| 1 | [2021-07-01, 2021-10-01) | 11 | 4 |
| 1 | [2021-10-01, 2022-01-01) | 11 | 4 |
| 2 | [2020-07-01, 2020-10-01) | 21 | 31 |
| 2 | [2020-10-01, 2021-01-01) | 21 | 31 |
| 2 | [2021-01-01, 2021-04-01) | 21 | 31 |
| 2 | [2021-04-01, 2021-07-01) | 21 | 31 |
| 2 | [2021-07-01, 2021-10-01) | 21 | 12 |
| 2 | [2021-10-01, 2022-01-01) | 21 | 12 |
| 2 | [2022-01-01, 2022-04-01) | 21 | 12 |
| 2 | [2022-04-01, 2022-07-01) | 21 | 12 |
+-----------+--------------------------+------+-------*/
Sie sehen jetzt, dass der Bereich [2020-04-15, 2021-04-15) in vier Bereiche aufgeteilt wurde, beginnend mit dem Bereich [2020-07-01, 2020-10-01).
Best Practices zum Speichern von Daten
Beim Speichern von Zeitreihendaten ist es wichtig, die Abfragemuster zu berücksichtigen, die für die Tabellen verwendet werden, in denen die Daten gespeichert sind. Bei der Abfrage von Zeitreihendaten können Sie die Daten in der Regel für einen bestimmten Zeitraum filtern.
Zur Optimierung dieser Nutzungsmuster wird empfohlen, Zeitreihendaten in partitionierten Tabellen zu speichern, wobei die Daten entweder nach der Zeitspalte oder der Aufnahmezeit partitioniert sind. Dies kann die Abfragezeitleistung der Zeitreihendaten erheblich verbessern, da BigQuery so Partitionen bereinigen kann, die keine abgefragten Daten enthalten.
Sie können das Clustering für den Zeitraum, den Bereich oder eine der Partitionierungsspalten aktivieren, um die Leistung der Abfragezeit weiter zu verbessern.