Visão geral do armazenamento do BigQuery
Nesta página, você encontra a descrição do componente de armazenamento do BigQuery.
O armazenamento do BigQuery é otimizado para executar consultas analíticas em grandes conjuntos de dados. Também é compatível com processamento de streaming de alta capacidade e leituras de alta capacidade. Entender o armazenamento do BigQuery ajuda a otimizar suas cargas de trabalho.
Visão geral
Um dos principais recursos da arquitetura do BigQuery é a separação entre armazenamento e computação. Isso permite que o BigQuery faça o escalonamento do armazenamento e da computação de maneira independente, com base na demanda.
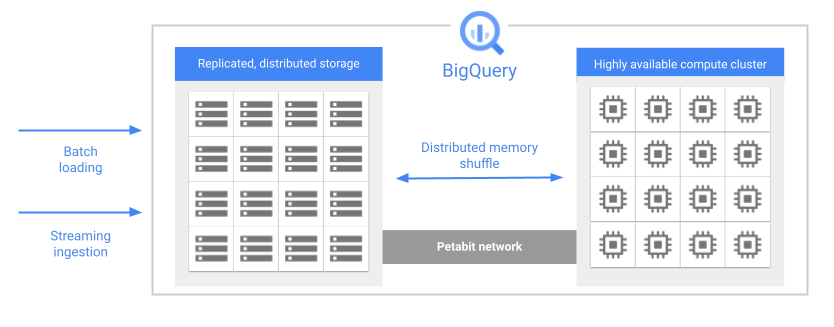
Quando você executa uma consulta, o mecanismo de consulta distribui o trabalho em paralelo para vários workers, que verificam as tabelas relevantes no armazenamento, processam a consulta e coletam os resultados. O BigQuery executa consultas totalmente na memória, usando uma rede de petabits para garantir que os dados se movam com muita rapidez até os nós de trabalho.
Veja alguns dos principais recursos do armazenamento do BigQuery:
Gerenciado. O armazenamento do BigQuery é um serviço totalmente gerenciado. Você não precisa provisionar recursos de armazenamento nem reservar unidades de armazenamento. O BigQuery aloca automaticamente o armazenamento quando você carrega dados no sistema. Você só paga pela quantidade de armazenamento que usar. O modelo de preços do BigQuery cobra pela computação e pelo armazenamento separadamente. Veja detalhes dos preços em Preços do BigQuery.
Durável. O armazenamento do BigQuery foi projetado para oferecer durabilidade anual de 99,999999999% (11 noves). O BigQuery replica seus dados em várias zonas de disponibilidade para proteção contra perda de dados devido a falhas no nível de máquina ou falhas zonais. Para mais informações, consulte Confiabilidade: planejamento de desastres.
Criptografado. Todos os dados do BigQuery são criptografados automaticamente antes de serem gravados no disco. Você pode fornecer sua própria chave de criptografia ou deixar que o Google gerencie essa chave. Veja mais informações em Criptografia em repouso.
Eficiente. O armazenamento do BigQuery usa um formato de codificação eficiente que é otimizado para cargas de trabalho analíticas. Saiba mais sobre o formato de armazenamento do BigQuery na postagem do blog Por dentro do Capacitor, o formato de armazenamento em colunas de última geração do BigQuery (em inglês).
Dados da tabela
A maioria dos dados armazenados no BigQuery são dados de tabelas. Os dados incluem tabelas padrão, clones de tabelas, instantâneos de tabelas e visualizações materializadas. Você é cobrado pelo armazenamento que usar com esses recursos. Para mais informações, consulte preços de armazenamento.
As tabelas padrão contêm dados estruturados. Todas as tabelas têm um esquema, e cada coluna tem um tipo de dados. O BigQuery armazena dados em formato de colunas. Consulte Layout de armazenamento neste documento.
Os clones de tabelas são cópias leves e graváveis de tabelas padrão. O BigQuery só armazena o delta entre um clone de tabela e a tabela base.
Os snapshots de tabelas são cópias pontuais de tabelas. Os snapshots de tabelas são somente leitura, mas é possível restaurar uma tabela a partir de um snapshot de tabela. O BigQuery armazena somente o delta entre um snapshot de tabela e a tabela base.
As visualizações materializadas são visualizações pré-computadas que armazenam em cache os resultados da consulta da visualização periodicamente. Os resultados armazenados em cache são mantidos no armazenamento do BigQuery.
Além disso, os resultados da consulta armazenados em cache são mantidos como tabelas temporárias. Não há cobrança pelos resultados de consulta armazenados em cache armazenados em tabelas temporárias.
As tabelas externas são um tipo especial de tabela, em que os dados residem em um armazenamento de dados externo ao BigQuery, como o Cloud Storage. Uma tabela externa tem um esquema de tabela, assim como uma tabela padrão, mas a definição da tabela aponta para o armazenamento de dados externo. Nesse caso, apenas os metadados da tabela são mantidos no armazenamento do BigQuery. O armazenamento de tabelas externas não é cobrado pelo BigQuery, embora o armazenamento de dados externo possa cobrar pelo armazenamento.
O BigQuery organiza tabelas e outros recursos em contêineres lógicos chamados conjuntos de dados. A maneira como você agrupa os recursos do BigQuery afeta permissões, cotas, faturamento e outros aspectos das cargas de trabalho do BigQuery. Veja mais informações e práticas recomendadas em Como organizar recursos do BigQuery.
A política de retenção de dados usada para uma tabela é determinada pela configuração do conjunto de dados que a contém. Para mais informações, consulte Retenção de dados com tempo de deslocamento e segurança contra falhas.
Metadados
O armazenamento do BigQuery também contém metadados sobre os recursos do BigQuery. O armazenamento de metadados não é cobrado.
Quando você cria uma entidade permanente no BigQuery, como uma função de tabela, visualização ou definida pelo usuário (UDF, na sigla em inglês), o BigQuery armazena metadados sobre a entidade. Isso é válido mesmo para recursos que não contêm dados de tabelas, como UDFs e visualizações lógicas.
Os metadados incluem informações como esquema de tabela, especificações de particionamento e clustering, prazos de validade da tabela, entre outras. Esse tipo de metadados é visível para o usuário e pode ser configurado quando você cria o recurso. Além disso, o BigQuery armazena os metadados usados internamente para otimizar as consultas. Esses metadados não ficam diretamente visíveis aos usuários.
Layout do armazenamento
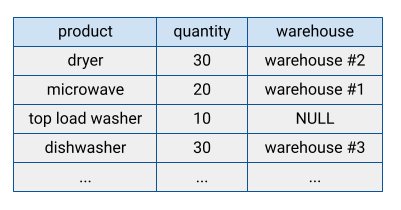
Muitos sistemas de banco de dados tradicionais armazenam os dados no formato orientado por linha, ou seja, as linhas são armazenadas juntas, com os campos de cada linha aparecendo sequencialmente no disco. Os bancos de dados orientados por linha são eficientes na busca de registros individuais. No entanto, eles podem ser menos eficientes na execução de funções analíticas em vários registros, porque o sistema precisa ler todos os campos ao acessar um registro.
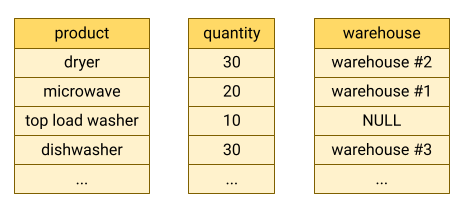
O BigQuery armazena dados de tabelas em formato de colunas, isto é, ele armazena cada coluna separadamente. Os bancos de dados orientados por coluna são especialmente eficientes na verificação de colunas individuais em um conjunto de dados inteiro.
Os bancos de dados orientados por coluna são otimizados para cargas de trabalho analíticas que agregam dados sobre um número muito grande de registros. Muitas vezes, uma consulta analítica precisa apenas ler algumas colunas de uma tabela. Por exemplo, se você quiser calcular a soma de uma coluna em milhões de linhas, o BigQuery pode ler os dados dessa coluna sem ler todos os campos de todas as linhas.
Outra vantagem dos bancos de dados orientados por coluna é que os dados em uma coluna geralmente têm mais redundância do que os dados em uma linha. Essa característica permite uma maior compactação de dados usando técnicas como a codificação de tamanho de execução, que pode melhorar o desempenho da leitura.
Modelos de faturamento do Storage
É possível receber cobranças pelo armazenamento de dados do BigQuery em bytes lógicos ou físicos (compactados) ou uma combinação de ambos. O modelo de faturamento do armazenamento escolhido determina o preço do armazenamento. O modelo de faturamento do armazenamento escolhido não afeta o desempenho do BigQuery. Seja qual for o modelo de faturamento escolhido, seus dados serão armazenados como bytes físicos.
Você define o modelo de faturamento do armazenamento no nível do conjunto de dados. Se você não especificar um modelo de faturamento do armazenamento ao criar um conjunto de dados, o padrão será usar o faturamento do armazenamento lógico. No entanto, é possível alterar o modelo de faturamento do armazenamento de um conjunto de dados depois de criá-lo. Depois de alterar o modelo de faturamento do armazenamento de um conjunto de dados, aguarde 14 dias antes de alterar o modelo de faturamento do armazenamento novamente.
Leva 24 horas para alterar o modelo de faturamento de um conjunto de dados. As tabelas ou partições de tabela no armazenamento de longo prazo não são redefinidas para armazenamento ativo quando você altera o modelo de faturamento de um conjunto de dados. O desempenho e a latência da consulta não são afetados pela alteração do modelo de faturamento de um conjunto de dados.
Os conjuntos de dados usam o armazenamento de viagem no tempo e à prova de falhas para a retenção de dados. Os armazenamentos de viagem no tempo e à prova de falhas são cobrados separadamente de acordo com as taxas de armazenamento ativo quando você usa o faturamento do armazenamento físico, mas estão inclusos na taxa básica cobrada quando você usa o faturamento do armazenamento lógico. É possível modificar a janela de viagem no tempo usada em um conjunto de dados para equilibrar os custos do armazenamento físico com a retenção de dados. Não é possível modificar a janela à prova de falhas. Para mais informações sobre a retenção de dados do conjunto de dados, consulte Retenção de dados com viagem no tempo e à prova de falhas. Para mais informações sobre como prever os custos do armazenamento, consulte Previsão do faturamento do armazenamento.
Não será possível registrar um conjunto de dados no faturamento do armazenamento físico se sua organização tiver algum compromisso de slot de taxa fixa legado localizado na mesma região do conjunto de dados. Isso não se aplica a compromissos comprados com uma edição do BigQuery.
Otimizar o armazenamento
A otimização do armazenamento do BigQuery melhora o desempenho das consultas e controla os custos. Para acessar os metadados de armazenamento de tabelas, consulte as seguintes visualizações INFORMATION_SCHEMA:
Para saber como otimizar o armazenamento, consulte Otimizar o armazenamento no BigQuery.
Carregar dados
Há vários padrões básicos de ingestão de dados no BigQuery.
Carregamento em lote: carregue os dados de origem em uma tabela do BigQuery em uma única operação em lote. Essa operação pode ser única ou pode ser automatizada para ocorrer de acordo com uma programação. Uma operação de carregamento em lote pode criar uma nova tabela ou anexar dados a uma tabela existente.
Streaming: faça streaming contínuo de lotes menores de dados, para que os dados fiquem disponíveis para consultas quase em tempo real.
Dados gerados: use instruções SQL para inserir linhas em uma tabela atual ou gravar os resultados de uma consulta em uma tabela.
Saiba mais sobre quando escolher cada um desses métodos de ingestão em Introdução ao carregamento de dados. Veja informações sobre preços em Preços de ingestão de dados.
Ler dados do armazenamento do BigQuery
Na maioria das vezes, os dados são armazenados no BigQuery para executar consultas analíticas. No entanto, às vezes é melhor ler os registros diretamente em uma tabela. O BigQuery oferece várias maneiras de ler os dados da tabela:
API BigQuery: acesso síncrono paginado com o método
tabledata.list. Os dados são lidos em série, uma página por invocação. Saiba mais em Como navegar pelos dados da tabela.API BigQuery Storage: acesso de alta capacidade de streaming que também oferece suporte à projeção e filtragem de colunas do lado do servidor. As leituras podem ser carregadas em paralelo por vários leitores se forem segmentadas em vários streams separados.
Exportar:cópia assíncrona de alta capacidade de processamento para o Google Cloud Storage, seja com jobs de extração ou a instrução
EXPORT DATA. Se você precisar copiar dados no Cloud Storage, exporte-os com um job de extração ou uma instruçãoEXPORT DATA.Cópia: cópia assíncrona de conjuntos de dados no BigQuery. A cópia é feita de maneira lógica quando os locais de origem e de destino são iguais.
Veja informações sobre preços em Preços de extração de dados.
Com base nos requisitos do aplicativo, é possível ler os dados da tabela:
- Leitura e cópia: se você precisar de uma cópia em repouso no Cloud Storage, exporte os dados com um job de extração ou uma instrução
EXPORT DATA. Se você quiser apenas ler os dados, use a API BigQuery Storage. Se você quiser fazer uma cópia no BigQuery, use um job de cópia. - Escala: a API do BigQuery é o método menos eficiente e não deve ser usada para leituras de alto volume. Se você precisar exportar mais de 50 TB de
dados por dia, use a instrução
EXPORT DATAou a API BigQuery Storage. - Tempo para retornar a primeira linha: a API BigQuery é o método mais rápido para retornar a primeira linha, mas só pode ser usada para ler pequenas quantidades de dados. A API BigQuery Storage é mais lenta para retornar a primeira linha, mas tem uma capacidade de processamento muito maior. As exportações e cópias precisam ser concluídas antes que qualquer linha seja lida. Portanto, o tempo até a primeira linha desses tipos de jobs pode demorar minutos.
Exclusão
Quando você exclui uma tabela, os dados persistem por pelo menos a duração da
janela de viagem no tempo. Depois disso, os dados são limpos
do disco dentro da
linha do tempo de exclusão deGoogle Cloud .
Algumas operações de exclusão, como a
instrução DROP COLUMN,
são apenas operações de metadados. Nesse caso, o armazenamento será liberado na próxima vez que você modificar as linhas afetadas. Se você não modificar a tabela, não haverá
um tempo garantido dentro do qual o armazenamento será liberado. Para mais informações, consulte
Exclusão de dados no Google Cloud.
A seguir
- Saiba mais sobre como trabalhar com tabelas.
- Saiba como otimizar o armazenamento.
- Saiba como consultar dados no BigQuery.
- Saiba mais sobre segurança e governança de dados.