Como organizar os recursos do BigQuery
Assim como outros Google Cloud serviços, os recursos do BigQuery são organizados em uma hierarquia. É possível usar essa hierarquia para gerenciar aspectos das cargas de trabalho do BigQuery, como permissões, cotas, reservas de slot e faturamento.
Hierarquia de recursos
O BigQuery herda a hierarquia de recursos doGoogle Cloud e adiciona outro mecanismo de agrupamento chamado conjuntos de dados, específicos do BigQuery. Esta seção descreve os elementos dessa hierarquia.
Conjuntos de dados
Os conjuntos de dados são contêineres lógicos usados para organizar e controlar o acesso aos recursos do BigQuery. Eles são semelhantes aos esquemas em outros sistemas de banco de dados.
A maioria dos recursos do BigQuery que você cria, incluindo tabelas, visualizações, funções e procedimentos, é criada dentro de um conjunto de dados. Conexões e jobs são exceções. Eles são associados a projetos em vez de conjuntos de dados.
Um conjunto de dados tem um local. Quando você cria uma tabela, os dados dela são armazenados no local do conjunto de dados. Antes de criar tabelas para dados de produção, pense nos requisitos de local. Não é possível alterar o local de um conjunto de dados depois que ele foi criado.
Projetos
Todo conjunto de dados é associado a um projeto. Para usar Google Cloud, é necessário criar pelo menos um projeto. Os projetos formam a base para criar, ativar e usar todos os Google Cloud serviços. Para mais informações, consulte Hierarquia de recursos. Um projeto pode conter vários conjuntos de dados, e conjuntos de dados com locais diferentes podem existir no mesmo projeto.
Ao executar operações nos dados do BigQuery, como executar uma consulta ou ingerir dados em uma tabela, você cria um job. Um job é sempre associado a um projeto, mas não precisa ser executado no mesmo projeto que contém os dados. Na verdade, um job pode se referir a tabelas de conjuntos de dados em vários projetos. Um job de consulta, de carregamento ou de exportação sempre é executado no mesmo local das tabelas referenciadas.
Cada projeto tem uma conta de faturamento do Cloud anexada a ele. Os custos acumulados para um projeto são cobrados nessa conta. Se você usar preços sob demanda, suas consultas serão cobradas do projeto que executa a consulta. Se você usar preços baseados na capacidade, suas reservas de slot serão cobradas no projeto de administração usado para comprar os slots. O armazenamento é cobrado no projeto em que o conjunto de dados está.
Pastas
Um mecanismo de agrupamento extra, além dos projetos, são as pastas. Projetos e pastas dentro de uma pasta herdam automaticamente as políticas de acesso da pasta pai. As pastas podem ser usadas para modelar diferentes pessoas jurídicas, departamentos e equipes em uma empresa.
Organizações
O recurso "Organização" representa uma organização (por exemplo, uma empresa) e é o nó raiz na hierarquia de recursosGoogle Cloud .
Você não precisa de um recurso Organização para começar a usar o BigQuery, mas recomendamos criar um. Com ele, os administradores podem controlar centralmente os recursos do BigQuery, em vez dos usuários individuais que controlam os recursos criados.
O diagrama a seguir mostra um exemplo da hierarquia de recursos. Neste exemplo, a organização tem um projeto dentro de uma pasta. O projeto é associado a uma conta de faturamento e contém três conjuntos de dados.
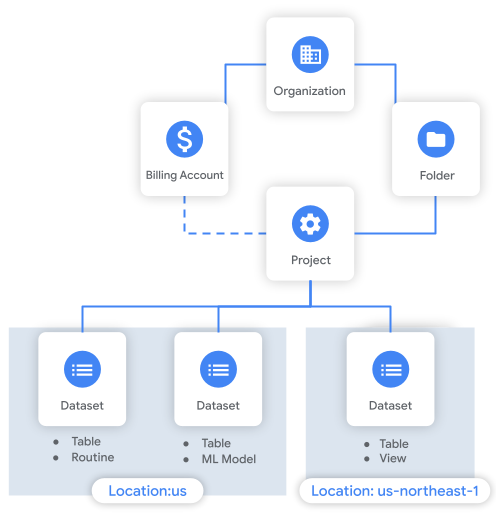
Considerações
Ao escolher como organizar os recursos do BigQuery, considere os seguintes pontos:
- Cotas. Muitas cotas do BigQuery são aplicadas no nível do projeto. Algumas se aplicam no nível do conjunto de dados. As cotas do projeto que envolvem recursos de computação, como consultas e jobs de carregamento, são contabilizadas no projeto que cria o job, e não no projeto de armazenamento.
- Faturamento. Se você quiser que departamentos diferentes da organização usem contas de faturamento do Cloud distintas, crie projetos diferentes para cada equipe. Crie as contas de faturamento do Cloud no nível da organização e associe os projetos a elas.
- Reservas de slots. Os slots reservados têm como escopo o recurso Organização. Depois de adquirir a capacidade de slot reservada, é possível atribuir um pool de slots a qualquer projeto ou pasta dentro da organização ou atribuir slots a todo o recurso Organização. Os projetos herdam reservas de slots da pasta pai ou da organização. Os slots reservados são associados a um projeto de administração, que é usado para gerenciar os slots. Para mais informações, consulte Gerenciamento de carga de trabalho usando as reservas.
Permissões. Analise como sua hierarquia de permissões afeta as pessoas na organização que precisam acessar os dados. Por exemplo, para conceder a uma equipe inteira acesso a dados específicos, esses dados precisam ser armazenados em um único projeto para simplificar o gerenciamento de acesso.
Tabelas e outras entidades herdam as permissões do conjunto de dados pai. Os conjuntos de dados herdam permissões das entidades pai na hierarquia de recursos (projetos, pastas e organizações). Para executar uma operação em um recurso, o usuário precisa das permissões relevantes no recurso e para criar um job do BigQuery. A permissão para criar um job está associada ao projeto usado para esse job.
Padrões
Nesta seção, apresentamos dois padrões comuns para organizar recursos do BigQuery.
Data lake central, data marts de departamentos. A organização cria um projeto de armazenamento unificado para armazenar os dados brutos. Os departamentos da organização criam os próprios projetos de data mart para análise.
Data lakes de departamentos, data warehouse central. Cada departamento cria e gerencia o próprio projeto de armazenamento para armazenar os dados brutos desse departamento. A organização cria um projeto de data warehouse central para análise.
Há vantagens e desvantagens para cada abordagem. Muitas organizações combinam elementos de ambos os padrões.
Data lake central, data marts de departamentos
Nesse padrão, você cria um projeto de armazenamento unificado para armazenar os dados brutos da sua organização. Seu pipeline de ingestão de dados também pode ser executado neste projeto. O projeto de armazenamento unificado atua como um data lake para a organização.
Cada departamento tem o próprio projeto dedicado, que é usado para consultar dados, salvar resultados de consulta e criar visualizações. Esses projetos no nível de departamento atuam como data marts. Eles estão associados à conta de faturamento do departamento.
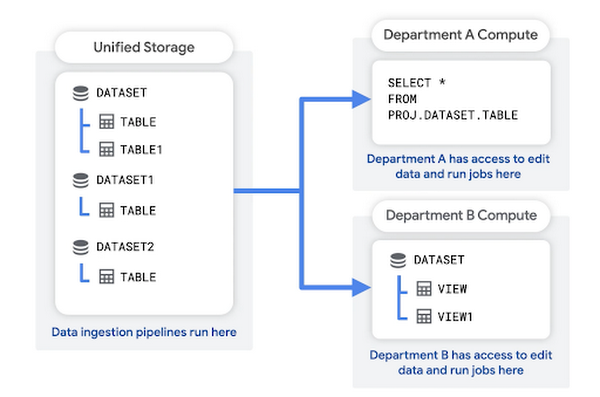
As vantagens dessa estrutura incluem:
- Uma equipe centralizada de engenharia de dados pode gerenciar o pipeline de ingestão em um único lugar.
- Os dados brutos são isolados dos projetos dos departamentos.
- Com os preços sob demanda, o faturamento das consultas em execução é cobrado do departamento que executa a consulta.
- Com preços baseados em capacidade, é possível atribuir slots a cada departamento com base nos requisitos de computação projetados.
- Cada departamento está isolado dos outros em termos de cotas do projeto.
Ao usar essa estrutura, as seguintes permissões são típicas:
- A equipe de engenharia de dados central recebe os papéis de editor de dados do BigQuery e usuário de jobs do BigQuery para o projeto de armazenamento. Esses papéis permitem a ingestão e a edição de dados no projeto de armazenamento.
- Os analistas de departamento recebem o papel de leitor de dados do BigQuery para conjuntos de dados específicos no projeto de data lake central. Isso permite que eles consultem os dados, mas não atualizem ou excluam os dados brutos.
- Os analistas de departamento também recebem o papel de editor de dados do BigQuery e o papel de usuário de jobs para o projeto de data mart do departamento. Isso permite que eles criem e atualizem tabelas no projeto e executem jobs de consulta para transformar e agregar os dados para uso específico do departamento.
Para mais informações, consulte Papéis e permissões básicos.
Data lakes de departamento, armazenamento de dados central
Nesse padrão, cada departamento cria e gerencia o próprio projeto de armazenamento para armazenar os dados brutos do departamento. Um projeto de armazenamento de dados central armazena agregações ou transformações dos dados brutos.
Os analistas podem consultar e ler os dados agregados do projeto de armazenamento de dados. O projeto de armazenamento de dados também oferece uma camada de acesso para as ferramentas de Business Intelligence (BI).
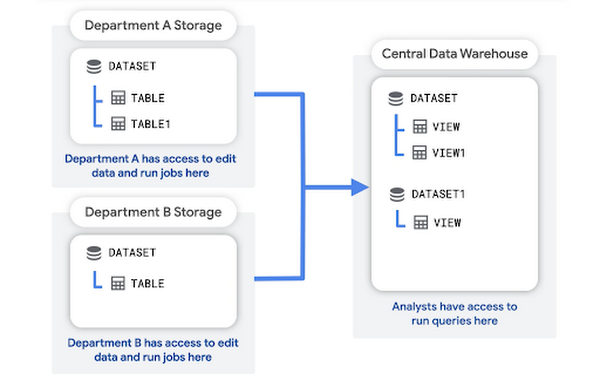
As vantagens dessa estrutura incluem:
- É mais simples gerenciar o acesso a dados no nível do departamento usando projetos separados para cada departamento.
- Uma equipe de análise central tem um único projeto para executar jobs de análise, o que facilita o monitoramento de consultas.
- Os usuários podem acessar dados de uma ferramenta de BI centralizada, que é mantida isolada dos dados brutos.
- É possível atribuir slots ao projeto de armazenamento de dados para processar todas as consultas de analistas e ferramentas externas.
Ao usar essa estrutura, as seguintes permissões são típicas:
- Os engenheiros de dados recebem os papéis de editor de dados do BigQuery e de usuário de jobs do BigQuery no data mart do departamento. Esses papéis permitem a ingestão e transformação de dados no data mart.
- Os analistas recebem os papéis de editor de dados do BigQuery e de usuário de jobs do BigQuery no projeto de data warehouse. Com esses papéis, é possível criar visualizações agregadas no data warehouse e executar jobs de consulta.
- As contas de serviço que conectam o BigQuery às ferramentas de BI recebem o papel de leitor de dados do BigQuery para conjuntos de dados específicos, que podem armazenar dados brutos do data lake ou dados transformados no projeto de data warehouse.
Para mais informações, consulte Papéis e permissões básicos.
Também é possível usar recursos de segurança como visualizações autorizadas e funções definidas pelo usuário (UDFs) para disponibilizar dados agregados a determinados usuários sem conceder a eles permissão para ver os dados brutos nos projetos de data mart.
Essa estrutura de projeto pode resultar em muitas consultas simultâneas no projeto de data warehouse. Como resultado, você pode atingir o limite de consultas simultâneas. Se você adotar essa estrutura, aumente esse limite de cota para o projeto. Considere também o uso do faturamento baseado em capacidade, para que seja possível comprar um pool de slots para executar as consultas.