安排查询
本页面介绍如何在 BigQuery 中安排周期性查询。
您可以计划查询定期运行。计划查询必须使用 GoogleSQL 编写,其中可包括数据定义语言 (DDL) 和数据操纵语言 (DML) 语句。您可以通过参数化查询字符串和目标表来按日期和时间组织查询结果。
创建或更新查询的时间表时,查询的计划时间会从您的本地时间转换为世界协调时间 (UTC)。世界协调时间 (UTC) 不受夏令时的影响。
准备工作
- 计划查询使用 BigQuery Data Transfer Service 的功能。验证您已完成启用 BigQuery Data Transfer Service 中要求的所有操作。
- 授予为用户提供执行本文档中的每个任务所需权限的 Identity and Access Management (IAM) 角色。
- 如果您计划指定客户管理的加密密钥 (CMEK),请确保您的服务账号有权加密和解密,并且您拥有使用 CMEK 所需的 Cloud KMS 密钥资源 ID。如需了解 CMEK 如何与 BigQuery Data Transfer Service 搭配使用,请参阅对计划查询指定加密密钥。
所需权限
如需安排查询,您需要以下 IAM 权限:
如需创建转移作业,您必须拥有
bigquery.transfers.update和bigquery.datasets.get权限,或者拥有bigquery.jobs.create、bigquery.transfers.get和bigquery.datasets.get权限。如需运行计划查询,您必须具有以下权限:
- 针对目标数据集的
bigquery.datasets.get权限 bigquery.jobs.create
- 针对目标数据集的
如需修改或删除预定查询,您必须拥有 bigquery.transfers.update 和 bigquery.transfers.get 权限,或者拥有 bigquery.jobs.create 权限以及预定查询的所有权。
预定义的 BigQuery Admin (roles/bigquery.admin) IAM 角色包含安排或修改查询所需的权限。
如需详细了解 BigQuery 中的 IAM 角色,请参阅预定义的角色和权限。
如需创建或更新服务账号运行的计划查询,您必须拥有该服务账号的访问权限。如需详细了解如何为用户授予服务账号角色,请参阅服务账号用户角色。如需在Google Cloud 控制台的预定查询界面中选择服务账号,您需要以下 IAM 权限:
iam.serviceAccounts.list以列出您的服务账号。iam.serviceAccountUser为预定查询分配服务账号。
配置选项
以下部分介绍了配置选项。
查询字符串
查询字符串必须有效,且必须使用 GoogleSQL 编写。计划查询每次运行时,都会收到以下查询参数。
如需在安排查询之前使用 @run_time 和 @run_date 参数手动测试查询字符串,请使用 bq 命令行工具。
可用参数
| 参数 | GoogleSQL 类型 | 值 |
|---|---|---|
@run_time |
TIMESTAMP |
以世界协调时间 (UTC) 表示。对于定期运行的计划查询,run_time 表示预期执行时间。例如,如果计划查询设置为“每 24 小时”,则连续两次查询之间的 run_time 差值将正好为 24 小时,虽然实际的执行耗时可能略有不同。 |
@run_date |
DATE |
表示逻辑日历日期。 |
示例
以下示例查询名为 hacker_news.stories 的公共数据集,其中 @run_time 参数是查询字符串的一部分。
SELECT @run_time AS time, title, author, text FROM `bigquery-public-data.hacker_news.stories` LIMIT 1000
目标表
在您设置计划查询时,如果结果的目标表不存在,BigQuery 会尝试为您创建表。
如果您使用的是 DDL 或 DML 查询,请在 Google Cloud 控制台中选择处理位置或区域。创建目标表的 DDL 或 DML 查询需要具有处理位置。
如果目标表已存在,并且您使用的是 WRITE_APPEND
写入偏好设置,则 BigQuery 会将数据附加到目标表并尝试映射架构。BigQuery 会自动允许添加字段和重新排序字段,并适应缺失的可选字段。如果表架构在两次运行之间发生了很大变化,以致于 BigQuery 无法自动处理更改,则计划查询会失败。
查询可以引用不同项目和不同数据集中的表。配置计划查询时,无需在表名称中包括目标数据集。您可以单独指定目标数据集。
计划查询的目标数据集和表必须与计划查询位于同一项目中。
写入偏好设置
您选择的写入偏好设置决定了将查询结果写入现有目标表的方式。
WRITE_TRUNCATE:如果相关表已存在,BigQuery 会覆盖表数据。WRITE_APPEND:如果相关表已存在,BigQuery 会向此表附加数据。
如果您使用的是 DDL 或 DML 查询,则无法使用“写入偏好设置”选项。
仅当 BigQuery 能够成功完成查询时,才会创建、截断或附加目标表。作业完成时,创建、截断或附加操作会作为原子更新发生。
聚簇
当使用 DDL CREATE TABLE AS SELECT 语句创建表时,计划查询只能在新表上创建聚簇。请参阅使用数据定义语言语句页面上的基于查询结果创建聚簇表。
分区选项
计划查询可以创建分区或非分区目标表。 Google Cloud 控制台、bq 命令行工具和 API 设置方法提供了分区功能。如果您使用的是带分区功能的 DDL 或 DML 查询,请将目标表分区字段留空。
您可以在 BigQuery 中使用以下类型的表分区:
- 整数范围分区:根据特定
INTEGER列中的值范围对表进行分区。 - 时间单位列分区:根据
TIMESTAMP、DATE或DATETIME列对表进行分区。 - 注入时间分区:按注入时间分区的表。BigQuery 会根据 BigQuery 注入数据时的时间自动将行分配给分区。
如需在Google Cloud 控制台中使用预定查询创建分区表,请使用以下选项:
如需使用整数范围分区,请将目标表分区字段留空。
如需使用时间单位列分区,请在设置计划查询时,在目标表分区字段中指定列名称。
如需使用注入时间分区,请将目标表分区字段留空,并在目标表名称中指明日期分区。例如
mytable${run_date}。如需了解详情,请参阅参数模板语法。
可用参数
设置计划查询时,您可以使用运行时参数指定对目标表进行分区的方式。
| 参数 | 模板类型 | 值 |
|---|---|---|
run_time |
带格式的时间戳 | 采用世界协调时间 (UTC),基于计划。对于定期运行的计划查询,run_time 表示预期执行时间。例如,如果计划查询设置为“每 24 小时”,则连续两次查询之间的 run_time 差值将正好为 24 小时,虽然实际的执行耗时可能略有不同。请参阅 TransferRun.runTime。 |
run_date |
日期字符串 | run_time 参数的日期格式为 %Y-%m-%d,例如 2018-01-01。此格式与提取时间分区表兼容。 |
模板系统
计划查询支持通过模板语法在目标表名称中采用运行时参数。
参数模板语法
模板语法支持基本的字符串模板和时间偏移量设置。您可以采用以下格式来引用参数:
{run_date}{run_time[+\-offset]|"time_format"}
| 参数 | 用途 |
|---|---|
run_date |
此参数将替换成格式为 YYYYMMDD 的日期。 |
run_time |
此参数支持以下属性:
|
- run_time、offset 和 time_format 之间不允许有空格。
- 如需在字符串中包含文本大括号,您可以将其转义为
'\{' and '\}'。 - 如需在 time_format 中包含文本引号或竖线(例如
"YYYY|MM|DD"),您可以在格式字符串中将其转义为'\"'或'\|'。
参数模板示例
以下示例演示了如何使用不同的时间格式指定目标表名称,以及如何设置运行时间的偏移量。| run_time (UTC) | 模板化参数 | 输出目标表名称 |
|---|---|---|
| 2018-02-15 00:00:00 | mytable |
mytable |
| 2018-02-15 00:00:00 | mytable_{run_time|"%Y%m%d"} |
mytable_20180215 |
| 2018-02-15 00:00:00 | mytable_{run_time+25h|"%Y%m%d"} |
mytable_20180216 |
| 2018-02-15 00:00:00 | mytable_{run_time-1h|"%Y%m%d"} |
mytable_20180214 |
| 2018-02-15 00:00:00 | mytable_{run_time+1.5h|"%Y%m%d%H"}
或 mytable_{run_time+90m|"%Y%m%d%H"} |
mytable_2018021501 |
| 2018-02-15 00:00:00 | {run_time+97s|"%Y%m%d"}_mytable_{run_time+97s|"%H%M%S"} |
20180215_mytable_000137 |
使用服务账号
您可以设置计划查询来使用服务账号进行身份验证。服务账号是与您的 Google Cloud 项目关联的特殊账号。服务账号可以使用自己的服务凭据(而不是最终用户的凭据)运行作业(例如计划查询或批处理流水线)。
要详细了解使用服务账号进行身份验证,请阅读身份验证简介。
您可以使用服务账号设置预定查询。如果您使用联合身份登录,则需要有服务账号才能创建转移作业。如果您使用 Google 账号登录,没有服务账号也可以创建转移作业。
您可以通过 bq 命令行工具或 Google Cloud 控制台使用服务账号的凭证更新现有预定查询。如需了解详情,请参阅更新预定查询凭证。
使用预定查询指定加密密钥
您可以指定客户管理的加密密钥 (CMEK) 来加密转移作业运行的数据。您可以使用 CMEK 支持来自计划查询的转移作业。当您使用转移作业指定 CMEK 时,BigQuery Data Transfer Service 会将 CMEK 应用于所注入数据的任何中间磁盘缓存,从而使整个数据转移工作流符合 CMEK 的规定。
如果最初不是使用 CMEK 创建转移作业,则无法更新现有转移作业来添加 CMEK。例如,您无法将最初默认加密的目标表更改为现在使用 CMEK 加密。反之,您也无法将 CMEK 加密的目标表更改为采用其他类型的加密。
如果转移配置最初是使用 CMEK 加密创建的,则可以为转移作业更新 CMEK。当您为转移配置更新 CMEK 时,BigQuery Data Transfer Service 会在下次运行转移作业时将 CMEK 传播到目标表,其中 BigQuery Data Transfer Service 会在转移作业运行期间将所有过时的 CMEK 替换为新的 CMEK。如需了解详情,请参阅更新转移作业。
您也可以使用项目默认密钥。当您使用转移作业指定项目默认密钥时,BigQuery Data Transfer Service 会将项目默认密钥用作任何新转移配置的默认密钥。
设置计划查询
如需了解时间表语法,请参阅设置时间表的格式。
如需详细了解时间表语法,请参阅“资源:TransferConfig”。
控制台
在 Google Cloud 控制台中打开 BigQuery 页面。
运行所需查询。如果您对结果感到满意,请点击安排。
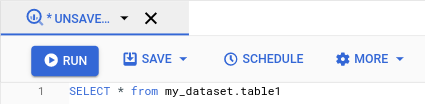
计划查询选项在新建计划查询窗格中打开。
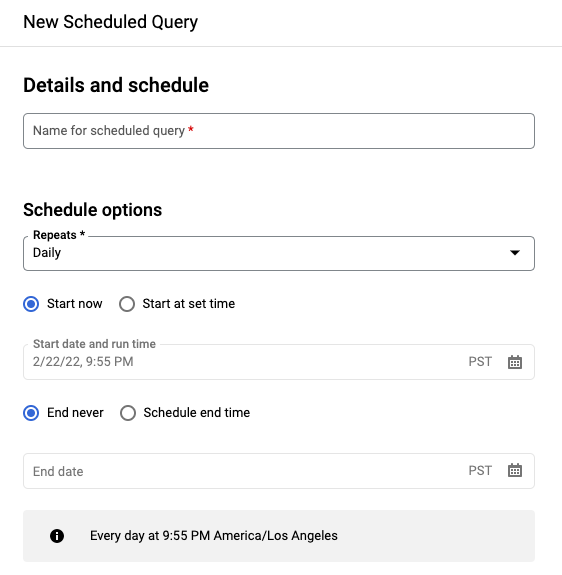
在新建计划查询窗格上:
- 对于计划查询的名称,请输入一个名称,例如
My scheduled query。计划查询的名称可以是您以后在需要修改查询时可识别的任何值。 可选:默认情况下,计划运行每天查询。您可以从重复下拉菜单中选择一个选项,以更改默认时间表:
如需指定自定义频率,请选择自定义,然后在自定义时间表字段中输入类似 Cron 的时间规范;例如
every mon 23:30或every 6 hours。如需详细了解有效时间表(包括自定义间隔时间),请参阅“资源:TransferConfig”下的schedule字段。
如需更改开始时间,请选择从设置的时间开始选项,输入选择的开始日期和时间。
如需指定结束时间,请选择安排结束时间选项,输入选择的结束日期和时间。
如需在没有时间表的情况下保存查询,以便稍后可以按需运行查询,请在重复菜单中选择按需。
- 对于计划查询的名称,请输入一个名称,例如
对于 GoogleSQL
SELECT查询,请选择为查询结果设置目标表选项,并提供目标数据集的以下相关信息。- 在数据集名称部分,选择适当的目标数据集。
- 对于表名称,请输入目标表的名称。
对于目标表的写入偏好设置,请选择附加到表以将数据附加到表中,或选择覆盖表以覆盖目标表。

选择位置类型。
如果您已为查询结果启用目标表,则可以选择自动位置选择,以自动选择目标表所在的位置。
否则,请选择要查询的数据所在的位置。
高级选项:
可选:CMEK 如果您使用客户管理的加密密钥,您可以选择高级选项下的客户管理的密钥。系统会显示一系列可用的 CMEK 供您选择。 如需了解客户管理的加密密钥 (CMEK) 如何与 BigQuery Data Transfer Service 搭配使用,请参阅使用预定查询指定加密密钥。
使用服务账号进行身份验证:如果您有一个或多个服务账号与 Google Cloud 项目关联,则可以将服务账号与预定查询相关联,而不是使用用户凭据。在预定查询凭证下,点击菜单可查看可用服务账号列表。如果您以联合身份登录,则需要服务账号。

其他配置:
点击保存。

bq
方法 1:使用 bq query 命令。
要创建计划查询,请将选项 destination_table(或 target_dataset)、--schedule 和 --display_name 添加到您的 bq query 命令。
bq query \ --display_name=name \ --destination_table=table \ --schedule=interval
替换以下内容:
name。计划查询的显示名称。显示名称可以是您以后在需要修改查询时可识别的任何值。table。查询结果的目标表。- 使用 DDL 和 DML 查询时,您还可以使用
--target_dataset为查询结果命名目标数据集。 - 请使用
--destination_table或--target_dataset,但不要同时使用这两者。
- 使用 DDL 和 DML 查询时,您还可以使用
interval:与bq query一起使用时,可将查询设为周期性计划查询。需要有关查询运行频率的计划。 如需详细了解有效时间表(包括自定义间隔时间),请参阅“资源:TransferConfig”下的schedule字段。示例:--schedule='every 24 hours'--schedule='every 3 hours'--schedule='every monday 09:00'--schedule='1st sunday of sep,oct,nov 00:00'
可选标志:
--project_id是项目 ID。如果未指定--project_id,系统会使用默认项目。--replace会在每次运行预定查询后使用查询结果覆盖目标表。所有现有数据都会清空。对于非分区表,系统也会清除架构。--append_table会将结果附加到目标表。对于 DDL 和 DML 查询,您还可以提供
--location标志以指定要处理的特定区域。如果未指定--location,则使用最近的 Google Cloud 位置。
例如,以下命令会使用查询 SELECT 1 from mydataset.test 创建名为 My Scheduled Query 的预定查询。目标表是数据集 mydataset 中的 mytable。计划查询将在默认项目中创建:
bq query \
--use_legacy_sql=false \
--destination_table=mydataset.mytable \
--display_name='My Scheduled Query' \
--schedule='every 24 hours' \
--replace=true \
'SELECT
1
FROM
mydataset.test'
方法 2:使用 bq mk 命令。
计划查询是一种转移作业。如需计划查询,您可以使用 bq 命令行工具创建转移作业配置。
拟安排的计划查询必须使用 StandardSQL 方言。
输入 bq mk 命令并提供以下必需标志:
--transfer_config--data_source--target_dataset(对于 DDL 和 DML 查询,此标志是可选的)--display_name--params
可选标志:
--project_id是项目 ID。如果未指定--project_id,系统会使用默认项目。--schedule是您希望查询运行的频率。如果未指定--schedule,则默认基于创建时间“每 24 小时运行一次”。对于 DDL 和 DML 查询,您还可以提供
--location标志以指定要处理的特定区域。如果未指定--location,则使用最近的 Google Cloud 位置。--service_account_name用于通过服务账号而不是您的个人用户账号对计划查询进行身份验证。如果您将客户管理的加密密钥 (CMEK) 用于此转移作业,则
--destination_kms_key会指定密钥的密钥资源 ID。如需了解 CMEK 如何与 BigQuery Data Transfer Service 搭配使用,请参阅对计划查询指定加密密钥。
bq mk \ --transfer_config \ --target_dataset=dataset \ --display_name=name \ --params='parameters' \ --data_source=data_source
替换以下内容:
dataset。转移作业配置的目标数据集。- 对于 DDL 和 DML 查询,此参数是可选的。所有其他查询都必须设置此参数。
name。转移作业配置的显示名。显示名称可以是您以后在需要修改查询时可识别的任何值。parameters。包含所创建转移作业配置的参数(采用 JSON 格式),例如:--params='{"param":"param_value"}'。- 对于计划查询,您必须提供
query参数。 destination_table_name_template参数是您的目标表的名称。- 对于 DDL 和 DML 查询,此参数是可选的。所有其他查询都必须设置此参数。
- 对于
write_disposition参数,您可以选择使用WRITE_TRUNCATE截断(覆盖)目标表,或选择使用WRITE_APPEND将查询结果附加到目标表。- 对于 DDL 和 DML 查询,此参数是可选的。所有其他查询都必须设置此参数。
- 对于计划查询,您必须提供
data_source。数据源:scheduled_query。- 可选:
--service_account_name标志用于通过服务账号而不是个人用户账号进行身份验证。 - 可选:
--destination_kms_key用于指定 Cloud KMS 密钥的密钥资源 ID,例如projects/project_name/locations/us/keyRings/key_ring_name/cryptoKeys/key_name。
例如,以下命令会使用查询 SELECT 1
from mydataset.test 创建名为 My Scheduled Query 的预定查询转移作业配置。目标表 mytable 会在每次写入时被截断,而目标数据集为 mydataset。计划查询将在默认项目中创建,并使用服务账号进行身份验证:
bq mk \
--transfer_config \
--target_dataset=mydataset \
--display_name='My Scheduled Query' \
--params='{"query":"SELECT 1 from mydataset.test","destination_table_name_template":"mytable","write_disposition":"WRITE_TRUNCATE"}' \
--data_source=scheduled_query \
--service_account_name=abcdef-test-sa@abcdef-test.iam.gserviceaccount.com
首次运行此命令时,您会收到如下消息:
[URL omitted] Please copy and paste the above URL into your web browser and
follow the instructions to retrieve an authentication code.
请按照该消息中的说明操作,并将身份验证代码粘贴到命令行中。
API
使用 projects.locations.transferConfigs.create 方法并提供一个 TransferConfig 资源实例。
Java
试用此示例之前,请按照 BigQuery 快速入门:使用客户端库中的 Java 设置说明进行操作。 如需了解详情,请参阅 BigQuery Java API 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为客户端库设置身份验证。
Python
试用此示例之前,请按照 BigQuery 快速入门:使用客户端库中的 Python 设置说明进行操作。 如需了解详情,请参阅 BigQuery Python API 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为客户端库设置身份验证。
使用服务账号设置计划查询
Java
试用此示例之前,请按照 BigQuery 快速入门:使用客户端库中的 Java 设置说明进行操作。 如需了解详情,请参阅 BigQuery Java API 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为客户端库设置身份验证。
Python
试用此示例之前,请按照 BigQuery 快速入门:使用客户端库中的 Python 设置说明进行操作。 如需了解详情,请参阅 BigQuery Python API 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为客户端库设置身份验证。
查看计划查询状态
控制台
如需查看预定查询的状态,请在导航菜单中点击安排,然后过滤预定查询。点击预定查询可获取详细信息。
bq
计划查询是一种转移作业。如需显示计划查询的详细信息,您可以先使用 bq 命令行工具列出转移作业配置。
输入 bq ls 命令并提供转移作业标志 --transfer_config。此外,还必须提供以下标志:
--transfer_location
例如:
bq ls \
--transfer_config \
--transfer_location=us
如需显示单个预定查询的详细信息,请输入 bq show 命令并提供该预定查询或转移作业配置的 transfer_path。
例如:
bq show \
--transfer_config \
projects/862514376110/locations/us/transferConfigs/5dd12f26-0000-262f-bc38-089e0820fe38
API
使用 projects.locations.transferConfigs.list 方法并提供一个 TransferConfig 资源实例。
Java
试用此示例之前,请按照 BigQuery 快速入门:使用客户端库中的 Java 设置说明进行操作。 如需了解详情,请参阅 BigQuery Java API 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为客户端库设置身份验证。
Python
试用此示例之前,请按照 BigQuery 快速入门:使用客户端库中的 Python 设置说明进行操作。 如需了解详情,请参阅 BigQuery Python API 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为客户端库设置身份验证。
更新计划查询
控制台
要更新计划查询,请按以下步骤操作:
- 在导航菜单中,点击预定查询或安排。
- 在计划查询列表中,点击要更改的查询的名称。
- 在打开的计划查询详细信息页面上,点击修改。
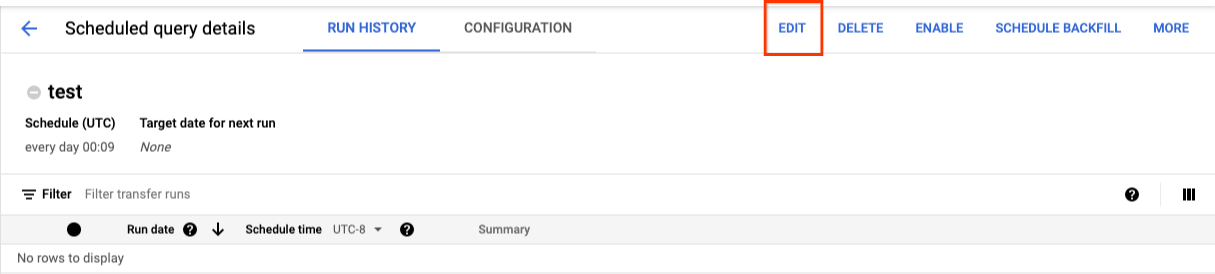
- 可选:更改查询修改窗格中的查询文本。
- 点击计划查询,然后选择更新计划查询。
- 可选:更改查询的任何其他时间安排选项。
- 点击更新。
bq
计划查询是一种转移作业。如需更新计划查询,您可以使用 bq 命令行工具创建转移作业配置。
输入带有所需 --transfer_config 标志的 bq update 命令。
可选标志:
--project_id是项目 ID。如果未指定--project_id,系统会使用默认项目。--schedule是您希望查询运行的频率。如果未指定--schedule,则默认基于创建时间“每 24 小时运行一次”。只有在同时设置
--update_credentials时,--service_account_name才会生效。如需了解详情,请参阅更新预定查询凭证。与 DDL 和 DML 查询搭配使用时,您还可以使用
--target_dataset(对于 DDL 和 DML 查询是可选的)为查询结果命名目标数据集。--display_name是计划查询的名称。--params是所创建转移作业配置的参数(采用 JSON 格式)。例如:--params='{"param":"param_value"}'。如果您将客户管理的加密密钥 (CMEK) 用于此转移作业,则
--destination_kms_key会指定 Cloud KMS 密钥的密钥资源 ID。如需了解客户管理的加密密钥 (CMEK) 如何与 BigQuery Data Transfer Service 搭配使用,请参阅对计划查询指定加密密钥。
bq update \ --target_dataset=dataset \ --display_name=name \ --params='parameters' --transfer_config \ RESOURCE_NAME
替换以下内容:
dataset。转移作业配置的目标数据集。对于 DDL 和 DML 查询,此参数是可选的。所有其他查询都必须设置此参数。name。转移作业配置的显示名。显示名称可以是您以后在需要修改查询时可识别的任何值。parameters。包含所创建转移作业配置的参数(采用 JSON 格式),例如:--params='{"param":"param_value"}'。- 对于计划查询,您必须提供
query参数。 destination_table_name_template参数是您的目标表的名称。 对于 DDL 和 DML 查询,此参数是可选的。 所有其他查询都必须设置此参数。- 对于
write_disposition参数,您可以选择使用WRITE_TRUNCATE截断(覆盖)目标表,或选择使用WRITE_APPEND将查询结果附加到目标表。对于 DDL 和 DML 查询,此参数是可选的。所有其他查询都必须设置此参数。
- 对于计划查询,您必须提供
- 可选:
--destination_kms_key用于指定 Cloud KMS 密钥的密钥资源 ID,例如projects/project_name/locations/us/keyRings/key_ring_name/cryptoKeys/key_name。 RESOURCE_NAME:转移作业的资源名称(也称为转移作业配置)。如果您不知道转移作业的资源名称,您可以通过以下命令查找资源名称:bq ls --transfer_config --transfer_location=location。
例如,以下命令会使用查询 SELECT 1
from mydataset.test 更新名为 My Scheduled Query 的预定查询转移作业配置。目标表 mytable 会在每次写入时被截断,而目标数据集为 mydataset:
bq update \
--target_dataset=mydataset \
--display_name='My Scheduled Query' \
--params='{"query":"SELECT 1 from mydataset.test","destination_table_name_template":"mytable","write_disposition":"WRITE_TRUNCATE"}'
--transfer_config \
projects/myproject/locations/us/transferConfigs/1234a123-1234-1a23-1be9-12ab3c456de7
API
使用 projects.transferConfigs.patch 方法并通过 transferConfig.name 参数提供转移作业的资源名称。如果您不知道转移作业的资源名称,请使用 bq ls --transfer_config --transfer_location=location 命令以列出所有转移作业,或调用 projects.locations.transferConfigs.list 方法并通过 parent 参数提供项目 ID。
Java
试用此示例之前,请按照 BigQuery 快速入门:使用客户端库中的 Java 设置说明进行操作。 如需了解详情,请参阅 BigQuery Java API 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为客户端库设置身份验证。
Python
试用此示例之前,请按照 BigQuery 快速入门:使用客户端库中的 Python 设置说明进行操作。 如需了解详情,请参阅 BigQuery Python API 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为客户端库设置身份验证。
更新具有所有权限制的计划查询
如果您尝试更新您不拥有的计划查询,更新可能会失败,并显示以下错误消息:
Cannot modify restricted parameters without taking ownership of the transfer configuration.
计划查询的所有者是与计划查询关联的用户,或者是可以访问与计划查询关联的服务账号的用户。关联的用户可以在计划查询的配置详细信息中看到。如需了解如何更新计划查询以获取所有权,请参阅更新计划查询凭据。如需向用户授予对服务账号的访问权限,您必须具有服务账号用户角色。
预定查询的所有者受限参数包括:
- 查询文本
- 目标数据集
- 目标表名称模板
更新计划查询凭据
如果您计划的是现有查询,则可能需要更新该查询的用户凭据。对于新的计划查询,凭据会自动更新到最新状态。
以下是可能需要更新凭据的一些其他情况:
- 您想要通过计划查询来查询 Google 云端硬盘数据。
当您尝试计划查询时,收到 INVALID_USER 错误:
Error code 5 : Authentication failure: User Id not found. Error code: INVALID_USERID尝试更新查询时,您会收到以下参数受限错误:
Cannot modify restricted parameters without taking ownership of the transfer configuration.
控制台
如需刷新计划查询的现有凭据,请执行以下操作:
查找并查看计划查询的状态。
点击更多按钮并选择更新凭据。
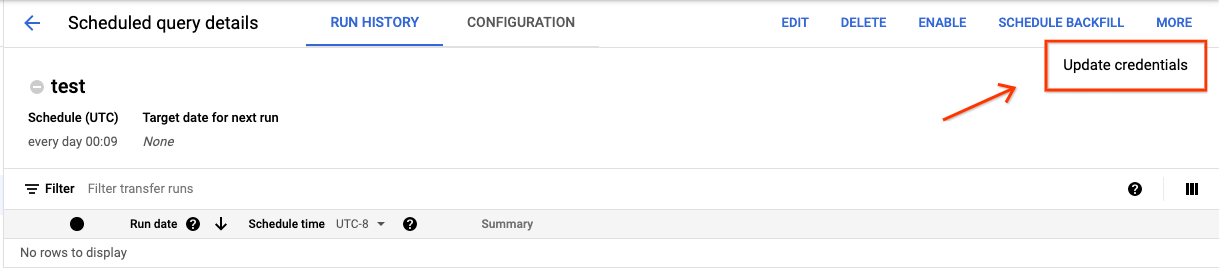
更改需要 10 到 20 分钟的时间才会生效。您可能需要清除浏览器的缓存。
bq
计划查询是一种转移作业。如需更新计划查询的凭据,您可以使用 bq 命令行工具更新转移作业配置。
输入 bq update 命令并提供转移作业标志 --transfer_config。此外,还必须提供以下标志:
--update_credentials
可选标志:
--service_account_name用于通过服务账号而不是您的个人用户账号对计划查询进行身份验证。
例如,下列命令会更新计划查询转移作业配置以使用服务账号进行身份验证:
bq update \
--update_credentials \
--service_account_name=abcdef-test-sa@abcdef-test.iam.gserviceaccount.com \
--transfer_config \
projects/myproject/locations/us/transferConfigs/1234a123-1234-1a23-1be9-12ab3c456de7
Java
试用此示例之前,请按照 BigQuery 快速入门:使用客户端库中的 Java 设置说明进行操作。 如需了解详情,请参阅 BigQuery Java API 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为客户端库设置身份验证。
Python
试用此示例之前,请按照 BigQuery 快速入门:使用客户端库中的 Python 设置说明进行操作。 如需了解详情,请参阅 BigQuery Python API 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为客户端库设置身份验证。
设置历史日期的手动运行
除了计划要在将来运行的查询外,您还可以通过手动触发即刻运行。如果查询使用 run_date 参数,并且在先前的运行期间存在问题,则必须触发即刻运行。
例如,您每天 09:00 查询源表,以查找与当前日期匹配的行。但是,您发现过去三天的数据未添加到源表中。在此情况下,您可以设置对指定日期范围内的历史数据运行查询。运行查询时结合使用 run_date 和 run_time 参数,它们与计划查询中配置的日期相对应。
设置计划查询后,您可以根据以下说明,使用历史日期范围运行查询:
控制台
点击安排保存预定查询后,点击预定查询按钮可查看预定查询的列表。点击任何显示名称可查看查询计划的详细信息。在页面右上角,点击安排回填可指定历史日期范围。
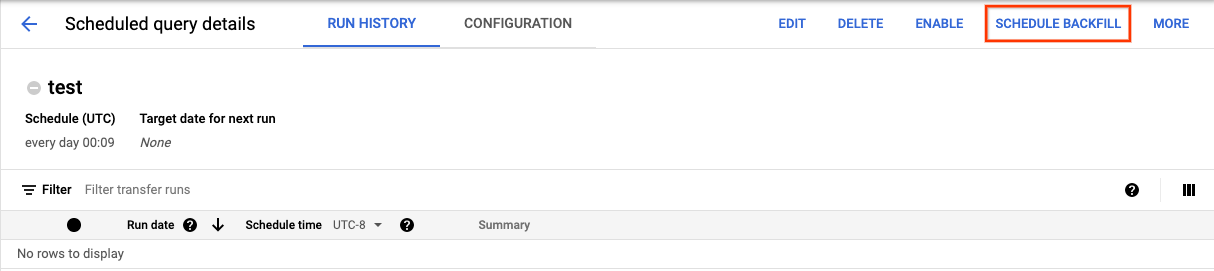
所选的运行时均在您选择的范围内(包括第一个日期,不包括最后一个日期)。
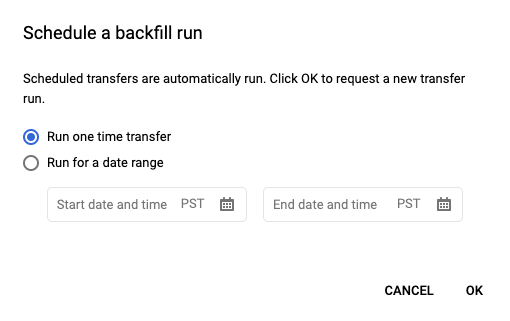
示例 1
您设置了在 every day 09:00(太平洋时间)运行您的计划查询。但是您缺少了 1 月 1 日、1 月 2 日和 1 月 3 日的数据。选择以下历史日期范围:
Start Time = 1/1/19
End Time = 1/4/19
您的查询将使用与以下时间相对应的 run_date 和 run_time 参数运行:
- 19/1/1 09:00 太平洋时间
- 19/1/2 09:00 太平洋时间
- 19/1/3 09:00 太平洋时间
示例 2
您设置了在 every day 23:00(太平洋时间)运行您的计划查询。但是您缺少了 1 月 1 日、1 月 2 日和 1 月 3 日的数据。选择以下历史日期范围(选择较晚的日期,是因为太平洋时间 23:00 已经是 UTC 的次日):
Start Time = 1/2/19
End Time = 1/5/19
您的查询将使用与以下时间相对应的 run_date 和 run_time 参数运行:
- 19/1/2 06:00 UTC,或 2019/1/1 23:00 太平洋时间
- 19/1/3 06:00 UTC,或 2019/1/2 23:00 太平洋时间
- 19/1/4 06:00 UTC,或 2019/1/3 23:00 太平洋时间
设置手动运行后,刷新页面即可在运行列表中查看它们。
bq
如需在历史日期范围内手动运行查询,请执行以下操作:
输入 bq mk 命令并提供转移运行标志 --transfer_run。此外,还必须提供以下标志:
--start_time--end_time
bq mk \ --transfer_run \ --start_time='start_time' \ --end_time='end_time' \ resource_name
替换以下内容:
start_time和end_time。 以 Z 结尾或包含有效时区偏移量的时间戳。示例:- 2017-08-19T12:11:35.00Z
- 2017-05-25T00:00:00+00:00
resource_name。计划查询(或转移作业)的资源名称。资源名称也称为转移作业配置。
例如,以下命令会为计划查询资源(或转移作业配置)安排回填:
projects/myproject/locations/us/transferConfigs/1234a123-1234-1a23-1be9-12ab3c456de7。
bq mk \
--transfer_run \
--start_time 2017-05-25T00:00:00Z \
--end_time 2017-05-25T00:00:00Z \
projects/myproject/locations/us/transferConfigs/1234a123-1234-1a23-1be9-12ab3c456de7
如需了解详情,请参阅 bq mk --transfer_run。
API
使用 projects.locations.transferConfigs.scheduleRun 方法并提供 TransferConfig 资源的路径。
Java
试用此示例之前,请按照 BigQuery 快速入门:使用客户端库中的 Java 设置说明进行操作。 如需了解详情,请参阅 BigQuery Java API 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为客户端库设置身份验证。
Python
试用此示例之前,请按照 BigQuery 快速入门:使用客户端库中的 Python 设置说明进行操作。 如需了解详情,请参阅 BigQuery Python API 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为客户端库设置身份验证。
为预定查询设置提醒
您可以根据行数指标为预定查询配置提醒政策。如需了解详情,请参阅使用预定查询设置提醒。
删除计划查询
控制台
如需在 Google Cloud 控制台的预定查询页面上删除预定查询,请执行以下操作:
- 在导航菜单中,点击预定查询。
- 在预定查询列表中,点击要删除的预定查询的名称。
在预定查询详细信息页面上,点击删除。
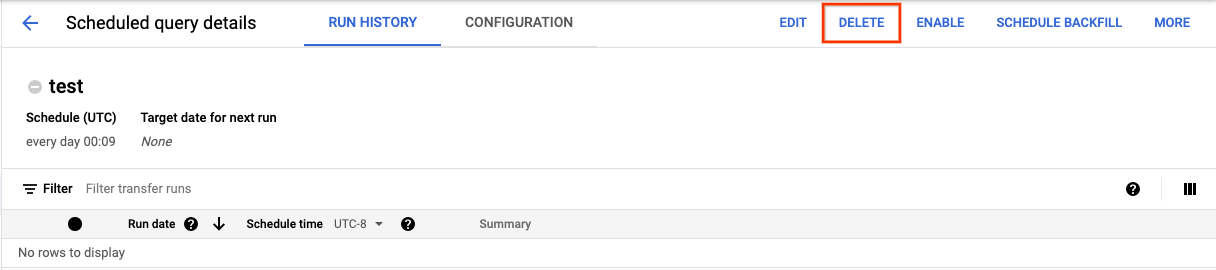
或者,您也可以在 Google Cloud 控制台的安排页面上删除预定查询:
- 在导航菜单中,点击安排。
- 在预定查询列表中,点击要删除的预定查询对应的 操作菜单。
选择删除。

Java
试用此示例之前,请按照 BigQuery 快速入门:使用客户端库中的 Java 设置说明进行操作。 如需了解详情,请参阅 BigQuery Java API 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为客户端库设置身份验证。
Python
试用此示例之前,请按照 BigQuery 快速入门:使用客户端库中的 Python 设置说明进行操作。 如需了解详情,请参阅 BigQuery Python API 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为客户端库设置身份验证。
停用或启用预定查询
如需暂停所选查询的预定运行,而不删除时间表,您可以停用时间表。
如需停用所选查询的时间表,请按照以下步骤操作:
- 在 Google Cloud 控制台的导航菜单中,点击安排。
- 在预定查询列表中,点击要停用的预定查询对应的 操作菜单。
选择 Disable(停用)。

如需启用已停用的预定查询,请点击要启用的预定查询对应的 操作菜单,然后选择启用。
配额
预定查询始终作为批量查询作业运行,并且与手动查询一样受相同的 BigQuery 配额和限制约束。
虽然预定查询使用 BigQuery Data Transfer Service 的功能,但它们不是转移作业,并且不受加载作业配额的约束。
用于执行查询的身份决定了应用的配额。这取决于预定查询的配置:
创建者的凭证(默认):如果您未指定服务账号,则系统会使用创建者的凭证运行预定查询。查询作业的费用将计入创建者的项目,并且受该用户和项目的配额限制。
服务账号凭证:如果您将预定查询配置为使用服务账号,则该查询会使用服务账号的凭证运行。在这种情况下,作业仍会计入包含相应预定查询的项目,但执行会受到指定服务账号的配额限制。
价格
计划查询与手动 BigQuery 查询的价格相同。
支持的区域
以下位置支持计划查询。
区域
下表列出了可使用 BigQuery 的美洲区域。| 区域说明 | 区域名称 | 详细信息 |
|---|---|---|
| 俄亥俄州,哥伦布 | us-east5 |
|
| 达拉斯 | us-south1 |
|
| 艾奥瓦 | us-central1 |
|
| 拉斯维加斯 | us-west4 |
|
| 洛杉矶 | us-west2 |
|
| 墨西哥 | northamerica-south1 |
|
| 蒙特利尔 | northamerica-northeast1 |
|
| 北弗吉尼亚 | us-east4 |
|
| 俄勒冈 | us-west1 |
|
| 盐湖城 | us-west3 |
|
| 圣保罗 | southamerica-east1 |
|
| 圣地亚哥 | southamerica-west1 |
|
| 南卡罗来纳 | us-east1 |
|
| 多伦多 | northamerica-northeast2 |
|
| 区域说明 | 区域名称 | 详细信息 |
|---|---|---|
| 德里 | asia-south2 |
|
| 香港 | asia-east2 |
|
| 雅加达 | asia-southeast2 |
|
| 墨尔本 | australia-southeast2 |
|
| 孟买 | asia-south1 |
|
| 大阪 | asia-northeast2 |
|
| 首尔 | asia-northeast3 |
|
| 新加坡 | asia-southeast1 |
|
| 悉尼 | australia-southeast1 |
|
| 台湾 | asia-east1 |
|
| 东京 | asia-northeast1 |
| 区域说明 | 区域名称 | 详细信息 |
|---|---|---|
| 比利时 | europe-west1 |
|
| 柏林 | europe-west10 |
|
| 芬兰 | europe-north1 |
|
| 法兰克福 | europe-west3 |
|
| 伦敦 | europe-west2 |
|
| 马德里 | europe-southwest1 |
|
| 米兰 | europe-west8 |
|
| 荷兰 | europe-west4 |
|
| 巴黎 | europe-west9 |
|
| 斯德哥尔摩 | europe-north2 |
|
| 都灵 | europe-west12 |
|
| 华沙 | europe-central2 |
|
| 苏黎世 | europe-west6 |
|
| 区域说明 | 区域名称 | 详细信息 |
|---|---|---|
| Dammam | me-central2 |
|
| 多哈 | me-central1 |
|
| 特拉维夫 | me-west1 |
| 区域说明 | 区域名称 | 详细信息 |
|---|---|---|
| 约翰内斯堡 | africa-south1 |
多区域
下表列出了可使用 BigQuery 的多区域。| 多区域说明 | 多区域名称 |
|---|---|
| 欧盟成员国的数据中心1 | EU |
| 美国的数据中心2 | US |
1 位于 EU 多区域的数据仅存储在以下某个位置:europe-west1(比利时)或 europe-west4(荷兰)。存储和处理数据确切位置由 BigQuery 自动确定。
2 位于 US 多区域的数据仅存储在以下某个位置:us-central1(爱荷华)、us-west1(俄勒冈)或 us-central2(俄克拉荷马)。存储和处理数据的确切位置由 BigQuery 自动确定。
后续步骤
- 如需查看使用服务账号并包含
@run_date和@run_time参数的计划查询示例,请参阅使用计划查询创建表快照。