Abfragen planen
Auf dieser Seite wird erläutert, wie wiederkehrende Abfragen in BigQuery geplant werden können.
Sie können Abfragen planen, damit sie automatisch regelmäßig ausgeführt werden. Geplante Abfragen müssen in GoogleSQL geschrieben werden. Dazu können Sie DDL-Anweisungen (Data Definition Language) und DML-Anweisungen (Data Manipulation Language) verwenden. Sie können Abfrageergebnisse nach Datum und Uhrzeit organisieren, indem Sie den Abfragestring und die Zieltabelle parametrisieren.
Wenn Sie den Zeitplan für eine Abfrage erstellen oder aktualisieren, wird die geplante Zeit für die Abfrage von Ihrer Ortszeit in UTC konvertiert. Die Sommerzeit wirkt sich nicht auf UTC aus.
Hinweis
- Geplante Abfragen verwenden Features des BigQuery Data Transfer Service. Prüfen Sie, ob Sie alle erforderlichen Aktionen zum Aktivieren des BigQuery Data Transfer Service ausgeführt haben.
- Weisen Sie IAM-Rollen (Identity and Access Management) zu, die Nutzern die erforderlichen Berechtigungen zum Ausführen der einzelnen Aufgaben in diesem Dokument gewähren.
- Wenn Sie einen vom Kunden verwalteten Verschlüsselungsschlüssel (CMEK) angeben möchten, muss Ihr Dienstkonto über die Berechtigungen zum Verschlüsseln und Entschlüsseln verfügen und Sie müssen die für die Verwendung von CMEK erforderliche Cloud KMS-Schlüsselressourcen-ID haben. Informationen zur Funktionsweise von CMEKs mit BigQuery Data Transfer Service finden Sie unter Verschlüsselungsschlüssel mit geplanten Abfragen angeben.
Erforderliche Berechtigungen
Zum Planen einer Abfrage benötigen Sie die folgenden IAM-Berechtigungen:
Zum Erstellen der Übertragung benötigen Sie entweder die Berechtigungen
bigquery.transfers.updateundbigquery.datasets.getoder die Berechtigungenbigquery.jobs.create,bigquery.transfers.getundbigquery.datasets.get.Zum Ausführen einer geplanten Abfrage benötigen Sie Folgendes:
bigquery.datasets.get-Berechtigungen für das Ziel-Datasetbigquery.jobs.create
Zum Ändern oder Löschen einer geplanten Abfrage benötigen Sie entweder die Berechtigungen bigquery.transfers.update und bigquery.transfers.get oder die Berechtigung bigquery.jobs.create und die Eigentumsrechte für die geplante Abfrage.
Die vordefinierte IAM-Rolle BigQuery-Administrator (roles/bigquery.admin) enthält die Berechtigungen, die Sie zum Planen oder Ändern einer Abfrage benötigen.
Weitere Informationen zu IAM-Rollen in BigQuery finden Sie unter Vordefinierte Rollen und Berechtigungen.
Wenn Sie geplante Abfragen erstellen oder aktualisieren möchten, die von einem Dienstkonto ausgeführt werden, müssen Sie Zugriff auf dieses Dienstkonto haben. Weitere Informationen zum Zuweisen der Dienstkontorolle zu Nutzern finden Sie unter Dienstkontonutzerrolle. Zum Auswählen eines Dienstkontos in der UI für geplante Abfragen derGoogle Cloud -Konsole benötigen Sie die folgenden IAM-Berechtigungen:
iam.serviceAccounts.list, um Ihre Dienstkonten aufzulisten.iam.serviceAccountUser, um einer geplanten Abfrage ein Dienstkonto zuzuweisen.
Konfigurationsoptionen
In den folgenden Abschnitten werden die Konfigurationsoptionen beschrieben.
Abfragestring
Der Abfragestring muss gültig und in GoogleSQL geschrieben sein. Für die Ausführung einer geplanten Abfrage können die im Folgenden aufgeführten Abfrageparameter verwendet werden.
Verwenden Sie das bq-Befehlszeilentool, um einen Abfragestring mit den Parametern @run_time und @run_date manuell zu testen, bevor Sie eine Abfrage planen.
Verfügbare Parameter
| Parameter | GoogleSQL-Typ | Wert |
|---|---|---|
@run_time |
TIMESTAMP |
Wird in UTC-Zeit dargestellt. Bei regelmäßig geplanten Abfragen steht run_time für die beabsichtigte Ausführungszeit. Wenn für die geplante Abfrage beispielsweise "alle 24 Stunden" eingestellt ist, beträgt die run_time-Differenz zwischen zwei aufeinanderfolgenden Abfragen exakt 24 Stunden, auch wenn die jeweilige Ausführungszeit dabei geringfügig variieren kann. |
@run_date |
DATE |
Stellt ein logisches Kalenderdatum dar. |
Beispiel
Der Parameter @run_time ist in diesem Beispiel Teil des Abfragestrings, mit dem ein öffentliches Dataset mit dem Namen hacker_news.stories abgefragt wird.
SELECT @run_time AS time, title, author, text FROM `bigquery-public-data.hacker_news.stories` LIMIT 1000
Zieltabelle
Wenn die Zieltabelle für Ihre Ergebnisse beim Erstellen der geplanten Abfrage nicht vorhanden ist, versucht BigQuery, die Tabelle für Sie zu erstellen.
Wenn Sie eine DDL- oder DML-Abfrage verwenden, wählen Sie in der Google Cloud Console den Verarbeitungsort oder die Region aus. Der Verarbeitungsort ist für DDL- oder DML-Abfragen erforderlich, mit denen die Zieltabelle erstellt wird.
Wenn die Zieltabelle vorhanden ist und Sie die Schreibpräferenz WRITE_APPEND verwenden, hängt BigQuery Daten an die Zieltabelle an und versucht, das Schema zuzuordnen.
In BigQuery können Felder automatisch hinzugefügt und neu angeordnet werden. Außerdem werden fehlende optionale Felder berücksichtigt. Wenn sich das Tabellenschema zwischen den Ausführungen so stark ändert, dass BigQuery die Änderungen nicht automatisch verarbeiten kann, schlägt die geplante Abfrage fehl.
Abfragen können auf Tabellen aus verschiedenen Projekten und unterschiedlichen Datasets verweisen. Bei der Konfiguration der geplanten Abfrage müssen Sie das Ziel-Dataset nicht in den Tabellennamen aufnehmen. Das Ziel-Dataset geben Sie getrennt an.
Das Ziel-Dataset und die Tabelle für eine geplante Abfrage müssen sich im selben Projekt wie die geplante Abfrage befinden.
Schreibeinstellung
Mit der von Ihnen ausgewählten Schreibeinstellung wird festgelegt, wie die Abfrageergebnisse in eine vorhandene Zieltabelle geschrieben werden.
WRITE_TRUNCATE: Wenn die Tabelle vorhanden ist, überschreibt BigQuery die Tabellendaten.WRITE_APPEND: Wenn die Tabelle vorhanden ist, hängt BigQuery die Daten an die Tabelle an.
Wenn Sie eine DDL- bzw. DML-Abfrage verwenden, können Sie die Option „Schreibeinstellung“ nicht verwenden.
Eine Zieltabelle wird nur dann erstellt, gekürzt oder verlängert, wenn BigQuery die Abfrage erfolgreich beenden kann. Die entsprechenden Aktionen werden erst nach Abschluss des Jobs als atomare Aktualisierung ausgeführt.
Clustering
Geplante Abfragen können nur dann Cluster für neue Tabellen erstellen, wenn die Tabelle mit der DDL-Anweisung CREATE TABLE AS SELECT erstellt wurde. Weitere Informationen zu dieser Methode finden Sie auf der Seite Anweisungen der Datendefinitionssprache verwenden unter Geclusterte Tabelle aus dem Ergebnis einer Abfrage erstellen.
Optionen für die Partitionierung
Geplante Abfragen können partitionierte oder nicht partitionierte Zieltabellen erstellen. Die Partitionierung ist in der Google Cloud Console, dem bq-Befehlszeilentool und den API-Einrichtungsmethoden verfügbar. Wenn Sie eine DDL- oder DML-Abfrage mit Partitionierung verwenden, lassen Sie das Partitionierungsfeld für die Zieltabelle leer.
In BigQuery können Sie die folgenden Arten der Tabellenpartitionierung verwenden:
- Ganzzahlbereichspartitionierung: Tabellen, die basierend auf Wertebereichen in einer bestimmten
INTEGER-Spalte partitioniert werden. - Spaltenpartitionierung nach Zeiteinheit: Tabellen, die auf der Grundlage einer
TIMESTAMP-,DATE- oderDATETIME-Spalte partitioniert sind. - Partitionierung nach Aufnahmezeit: Nach Aufnahmezeit partitionierte Tabellen. BigQuery weist den Zeilen automatisch Partitionen zu dem Zeitpunkt zu, an dem BigQuery die Daten aufnimmt.
Zum Erstellen einer partitionierten Tabelle mithilfe einer geplanten Abfrage in derGoogle Cloud -Konsole verwenden Sie die folgenden Optionen:
Wenn Sie die Partitionierung nach Ganzzahlbereich verwenden möchten, lassen Sie das Partitionierungsfeld für die Zieltabelle leer.
Wenn Sie eine Partitionierung nach Zeiteinheitsspalten verwenden möchten, geben Sie den Spaltennamen beim Einrichten einer geplanten Abfrage im Partitionierungsfeld für die Zieltabelle an.
Wenn Sie die Partitionierung nach Aufnahmezeit verwenden möchten, lassen Sie das Partitionierungsfeld für die Zieltabelle leer und geben die Datumspartitionierung im Namen der Zieltabelle an. Beispiel:
mytable${run_date}Weitere Informationen finden Sie unter Parameter der Vorlagensyntax.
Verfügbare Parameter
Bei der Einrichtung der geplanten Abfrage können Sie angeben, wie die Zieltabelle mit Laufzeitparametern partitioniert werden soll.
| Parameter | Vorlagentyp | Wert |
|---|---|---|
run_time |
Formatierter Zeitstempel | Wird in UTC-Zeit per Zeitplan dargestellt. Bei regelmäßig geplanten Abfragen steht run_time für die beabsichtigte Ausführungszeit. Wenn für die geplante Abfrage beispielsweise "alle 24 Stunden" eingestellt ist, beträgt die run_time-Differenz zwischen zwei aufeinanderfolgenden Abfragen exakt 24 Stunden, auch wenn die jeweilige Ausführungszeit dabei geringfügig variieren kann.Siehe hierzu TransferRun.runTime. |
run_date |
Datumsstring | Das Datum des Parameters run_time im Format %Y-%m-%d, zum Beispiel 2018-01-01. Dieses Format ist kompatibel mit nach Aufnahmezeit partitionierten Tabellen. |
Vorlagensystem
Geplante Abfragen unterstützen Laufzeitparameter im Zieltabellennamen mit einer Vorlagensyntax.
Parameter der Vorlagensyntax
Die Vorlagensyntax unterstützt grundlegende Stringvorlagen und Zeitverschiebungen. Die Parameter werden in den folgenden Formaten referenziert:
{run_date}{run_time[+\-offset]|"time_format"}
| Parameter | Zweck |
|---|---|
run_date |
Dieser Parameter wird durch das Datum im Format YYYYMMDD ersetzt. |
run_time |
Dieser Parameter unterstützt folgende Attribute:
|
- Zwischen run_time, offset und time_format ist kein Leerzeichen zulässig.
- Wenn Sie im String geschweifte Klammern für die Anzeige verwenden möchten, maskieren Sie sie:
'\{' and '\}'. - Wenn Sie in "time_format" Anführungszeichen oder senkrechte Striche für die Anzeige verwenden möchten, wie z. B.
"YYYY|MM|DD", maskieren Sie sie im Formatstring:'\"'oder'\|'.
Beispiele für Parametervorlagen
In den folgenden Beispielen wird gezeigt, wie Zieltabellennamen mit unterschiedlichen Zeitformaten angegeben werden und wie die Laufzeit verschoben wird.| run_time (UTC) | Vorlagenparameter | Name der Ausgabezieltabelle |
|---|---|---|
| 2018-02-15 00:00:00 | mytable |
mytable |
| 2018-02-15 00:00:00 | mytable_{run_time|"%Y%m%d"} |
mytable_20180215 |
| 2018-02-15 00:00:00 | mytable_{run_time+25h|"%Y%m%d"} |
mytable_20180216 |
| 2018-02-15 00:00:00 | mytable_{run_time-1h|"%Y%m%d"} |
mytable_20180214 |
| 2018-02-15 00:00:00 | mytable_{run_time+1.5h|"%Y%m%d%H"}
oder mytable_{run_time+90m|"%Y%m%d%H"} |
mytable_2018021501 |
| 2018-02-15 00:00:00 | {run_time+97s|"%Y%m%d"}_mytable_{run_time+97s|"%H%M%S"} |
20180215_mytable_000137 |
Dienstkonto verwenden
Sie können eine geplante Abfrage so einrichten, dass sie für die Authentifizierung ein Dienstkonto verwendet. Ein Dienstkonto ist ein spezielles Konto, das mit Ihrem Google Cloud Projekt verknüpft ist. Das Dienstkonto kann Jobs wie geplante Abfragen oder Batchverarbeitungs-Pipelines mit eigenen Dienstanmeldedaten anstelle der Anmeldedaten eines Endnutzers ausführen.
Weitere Informationen zur Authentifizierung über Dienstkonten finden Sie unter Einführung in Authentifizierung.
Sie können die geplante Abfrage mit einem Dienstkonto einrichten. Wenn Sie sich mit einer föderierten Identität angemeldet haben, ist ein Dienstkonto zum Erstellen einer Übertragung erforderlich. Wenn Sie sich mit einem Google-Konto angemeldet haben, ist ein Dienstkonto für die Übertragung optional.
Sie können eine vorhandene geplante Abfrage mit den Anmeldedaten eines Dienstkontos mit dem bq-Befehlszeilentool oder der Google Cloud -Konsole aktualisieren. Weitere Informationen finden Sie unter Anmeldedaten für geplante Abfragen aktualisieren.
Verschlüsselungsschlüssel mit geplanten Abfragen angeben
Sie können vom Kunden verwaltete Verschlüsselungsschlüssel (CMEKs) angeben, um Daten für eine Übertragungsausführung zu verschlüsseln. Sie können einen CMEK verwenden, um Übertragungen aus geplanten Abfragen zu unterstützen.Wenn Sie einen CMEK mit einer Übertragung angeben, wendet der BigQuery Data Transfer Service den CMEK auf einen zwischengeschalteten Festplatten-Cache von aufgenommenen Daten an, sodass der gesamte Datenübertragungsworkflow CMEK-konform ist.
Sie können eine vorhandene Übertragung nicht aktualisieren, um einen CMEK hinzuzufügen, wenn die Übertragung nicht ursprünglich mit einem CMEK erstellt wurde. Sie können beispielsweise keine Zieltabelle ändern, die ursprünglich standardmäßig verschlüsselt wurde, um jetzt mit CMEK zu verschlüsseln. Umgekehrt können Sie eine CMEK-verschlüsselte Zieltabelle auch nicht auf einen anderen Verschlüsselungstyp ändern.
Sie können einen CMEK für eine Übertragung aktualisieren, wenn die Übertragungskonfiguration ursprünglich mit einer CMEK-Verschlüsselung erstellt wurde. Wenn Sie einen CMEK für eine Übertragungskonfiguration aktualisieren, leitet der BigQuery Data Transfer Service den CMEK bei der nächsten Ausführung der Übertragung an die Zieltabellen weiter, wobei der BigQuery Data Transfer Service während der Übertragungsausführung alle veralteten CMEKs durch den neuen CMEK ersetzt. Weitere Informationen finden Sie unter Übertragung aktualisieren.
Sie können auch Standardschlüssel für Projekte verwenden. Wenn Sie einen Projektstandardschlüssel für eine Übertragung angeben, verwendet BigQuery Data Transfer Service den Standardschlüssel des Projekts als Standardschlüssel für neue Übertragungskonfigurationen.
Geplante Abfragen einrichten
Eine Beschreibung der Zeitplansyntax finden Sie unter Zeitplan formatieren.
Weitere Informationen zur Zeitplansyntax finden Sie unter Ressource: TransferConfig.
Console
Öffnen Sie in der Google Cloud Console die Seite „BigQuery“.
Führen Sie die gewünschte Abfrage aus. Wenn die Ergebnisse Ihren Erwartungen entsprechen, klicken Sie auf Planen.
Die Optionen für die geplante Abfrage werden im Bereich Neue geplante Abfrage angezeigt.
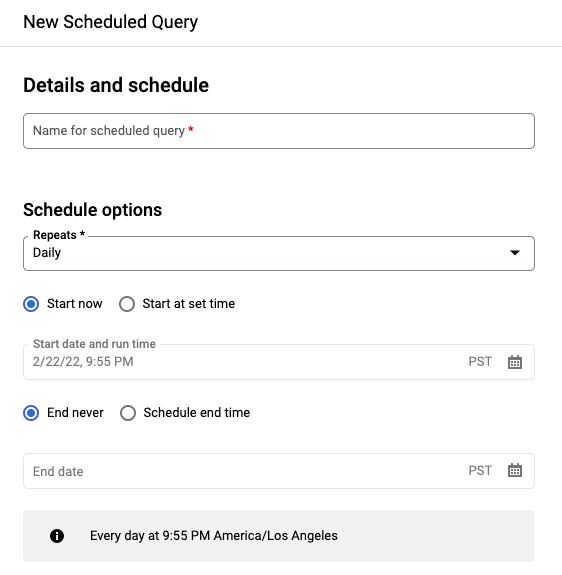
Im Bereich New scheduled query (Neue geplante Abfrage):
- Geben Sie unter Name der geplanten Abfrage einen Namen ein, z. B.
My scheduled query. Der Name der geplanten Abfrage kann ein beliebiger Wert sein, den Sie später identifizieren können, wenn Sie die Abfrage ändern müssen. Optional: Die Abfrage wird standardmäßig täglich ausgeführt. Sie können den Standardzeitplan ändern, indem Sie im Drop-down-Menü Wiederholungen eine Option auswählen:
Wenn Sie eine benutzerdefinierte Häufigkeit angeben möchten, wählen Sie Benutzerdefiniert aus und geben Sie eine Cron-ähnliche Zeitangabe in das Feld Benutzerdefinierter Zeitplan ein. Beispiel:
every mon 23:30oderevery 6 hours. Weitere Informationen zu gültigen Zeitplänen einschließlich benutzerdefinierter Intervalle finden Sie im Feldscheduleunter Ressource:TransferConfig.
Wählen Sie die Option Zum festgelegten Zeitpunkt starten aus, um das Startdatum zu ändern. Geben Sie das gewünschte Startdatum und die gewünschte Uhrzeit ein.
Wählen Sie zum Festlegen des Endes die Option Ende planen aus und geben Sie das gewünschte Enddatum und die gewünschte Uhrzeit ein.
Wenn Sie die Abfrage ohne Zeitplan speichern möchten, um sie später nach Bedarf auszuführen, wählen Sie Bei Bedarf im Menü Wiederholung aus.
- Geben Sie unter Name der geplanten Abfrage einen Namen ein, z. B.
Für eine GoogleSQL-
SELECT-Abfrage wählen Sie die Option Zieltabelle für Abfrageergebnisse festlegen aus und geben die folgenden Informationen zum Ziel-Dataset an.- Wählen Sie für Dataset name (Dataset-Name) das passende Ziel-Dataset aus.
- Geben Sie unter Table name (Tabellenname) den Namen Ihrer Zieltabelle ein.
Wählen Sie für Schreibeinstellung für Zieltabelle entweder An Tabelle anfügen, um Daten an die Tabelle anzuhängen, oder Tabelle überschreiben aus, um die Zieltabelle zu überschreiben.

Wählen Sie den Standorttyp aus.
Wenn Sie die Zieltabelle für Abfrageergebnisse aktiviert haben, können Sie Automatische Standortauswahl auswählen, um den Standort der Zieltabelle automatisch festlegen zu lassen.
Andernfalls wählen Sie den Speicherort der Daten aus, die abgefragt werden.
Erweiterte Optionen:
Optional: CMEK: Wenn Sie vom Kunden verwaltete Verschlüsselungsschlüssel verwenden, können Sie unter Erweiterte Optionen die Option Vom Kunden verwalteter Schlüssel auswählen. Es wird eine Liste Ihrer verfügbaren CMEKs angezeigt, aus denen Sie wählen können. Informationen zur Funktionsweise von vom Kunden verwalteten Verschlüsselungsschlüsseln (CMEKs) mit BigQuery Data Transfer Service finden Sie unter Verschlüsselungsschlüssel mit geplanten Abfragen angeben.
Authentifizierung über ein Dienstkonto Wenn ein oder mehrere Dienstkonten zu Ihrem Google Cloud -Projekt gehören, können Sie statt der Nutzeranmeldedaten ein Dienstkonto mit Ihrer geplanten Abfrage verknüpfen. Klicken Sie unter Anmeldedaten für geplante Abfragen auf das Menü, um eine Liste der verfügbaren Dienstkonten aufzurufen. Ein Dienstkonto ist erforderlich, wenn Sie als föderierte Identität angemeldet sind.

Zusätzliche Konfigurationen:
Optional: Aktivieren Sie E-Mail-Benachrichtigungen senden, um im Falle von Fehlern bei der Übertragungsausführung Benachrichtigungen zu senden.
Optional: Geben Sie unter Cloud Pub/Sub-Thema den Namen Ihres Cloud Pub/Sub-Themas ein, beispielsweise
projects/myproject/topics/mytopic.
Klicken Sie auf Speichern.
bq
Option 1: Verwenden Sie den Befehl bq query.
Fügen Sie zum Erstellen einer geplanten Abfrage dem bq query-Befehl die Optionen destination_table (oder target_dataset), --schedule und --display_name hinzu.
bq query \ --display_name=name \ --destination_table=table \ --schedule=interval
Ersetzen Sie Folgendes:
name. Der angezeigte Name für die geplante Abfrage. Der angezeigte Name kann ein beliebiger Wert sein, den Sie später identifizieren können, wenn Sie die Abfrage ändern müssen.table. Die Zieltabelle für die Abfrageergebnisse.--target_datasetist in DLL- oder DMS-Abfragen eine alternative Möglichkeit, das Ziel-Dataset für die Abfrageergebnisse zu benennen.- Verwenden Sie entweder
--destination_tableoder--target_dataset, aber nicht beides.
interval. Bei Verwendung mitbq querywird eine Abfrage zu einer wiederkehrenden geplanten Abfrage. Hierfür ist ein Zeitplan erforderlich, der angibt, wie häufig die Abfrage ausgeführt werden soll. Weitere Informationen zu gültigen Zeitplänen einschließlich benutzerdefinierter Intervalle finden Sie im Feldscheduleunter Ressource:TransferConfig. Beispiele:--schedule='every 24 hours'--schedule='every 3 hours'--schedule='every monday 09:00'--schedule='1st sunday of sep,oct,nov 00:00'
Optionale Flags:
--project_idist die Projekt-ID. Wenn--project_idnicht angegeben ist, wird das Standardprojekt verwendet.--replaceüberschreibt die Zieltabelle nach jeder Ausführung der geplanten Abfrage mit den Abfrageergebnissen. Alle vorhandenen Daten werden gelöscht. Bei nicht partitionierten Tabellen wird auch das Schema gelöscht.--append_tablehängt Ergebnisse an die Zieltabelle an.Bei DDL- und DML-Abfragen können Sie auch das Flag
--locationübergeben, um eine bestimmte Region für die Verarbeitung anzugeben. Wenn--locationnicht angegeben ist, wird der nächste Google Cloud Standort verwendet.
Mit dem folgenden Befehl wird beispielsweise eine geplante Abfrage namens My Scheduled Query erstellt, die auf der Abfrage SELECT 1 from mydataset.test aufbaut.
Die Zieltabelle ist mytable im Dataset mydataset. Die geplante Abfrage wird im Standardprojekt erstellt:
bq query \
--use_legacy_sql=false \
--destination_table=mydataset.mytable \
--display_name='My Scheduled Query' \
--schedule='every 24 hours' \
--replace=true \
'SELECT
1
FROM
mydataset.test'
Option 2: Verwenden Sie den Befehl bq mk.
Geplante Abfragen sind eine Art der Übertragung. Zum Planen einer Abfrage können Sie mit dem bq-Befehlszeilentool eine Übertragungskonfiguration vornehmen.
Abfragen müssen in Standard-SQL geschrieben werden, um geplant zu werden.
Geben Sie den Befehl bq mk ein und legen Sie die folgenden erforderlichen Flags fest:
--transfer_config--data_source--target_dataset(optional für DDL- und DML-Abfragen)--display_name--params
Optionale Flags:
--project_idist die Projekt-ID. Wenn--project_idnicht angegeben ist, wird das Standardprojekt verwendet.--schedulegibt an, wie oft die Abfrage ausgeführt werden soll. Wenn--schedulenicht angegeben ist, wird als Standardeinstellung "alle 24 Stunden" basierend auf der Erstellungszeit verwendet.Bei DDL- und DML-Abfragen können Sie auch das Flag
--locationübergeben, um eine bestimmte Region für die Verarbeitung anzugeben. Wenn--locationnicht angegeben ist, wird der nächste Google Cloud Standort verwendet.--service_account_namedient zur Authentifizierung der geplanten Abfrage über ein Dienstkonto statt über Ihr eigenes Nutzerkonto.--destination_kms_keygibt die Schlüsselressourcen-ID für den Schlüssel an, wenn Sie für diese Übertragung einen vom Kunden verwalteten Verschlüsselungsschlüssel (CMEK) verwenden. Informationen zur Funktionsweise von CMEKs mit BigQuery Data Transfer Service finden Sie unter Verschlüsselungsschlüssel mit geplanten Abfragen angeben.
bq mk \ --transfer_config \ --target_dataset=dataset \ --display_name=name \ --params='parameters' \ --data_source=data_source
Ersetzen Sie Folgendes:
dataset. Das Ziel-Dataset für die Übertragungskonfiguration.- Dieser Parameter ist für DDL- und DML-Abfragen optional. Er wird für alle anderen Abfragen benötigt.
name. Der angezeigte Name für die Übertragungskonfiguration. Der angezeigte Name kann ein beliebiger Wert sein, den Sie später identifizieren können, wenn Sie die Abfrage ändern müssen.parameters. Enthält die Parameter für die erstellte Übertragungskonfiguration im JSON-Format. Beispiel:--params='{"param":"param_value"}'.- Für eine geplante Abfrage müssen Sie den Parameter
queryangeben. - Der Parameter
destination_table_name_templateist der Name der Zieltabelle.- Dieser Parameter ist für DDL- und DML-Abfragen optional. Er wird für alle anderen Abfragen benötigt.
- Für den Parameter
write_dispositionwählen Sie entwederWRITE_TRUNCATE, um die Zieltabelle zu kürzen (überschreiben), oderWRITE_APPEND, um die Abfrageergebnisse an die Zieltabelle anzuhängen.- Dieser Parameter ist für DDL- und DML-Abfragen optional. Er wird für alle anderen Abfragen benötigt.
- Für eine geplante Abfrage müssen Sie den Parameter
data_source. Die Datenquelle:scheduled_query.- Optional: Das Flag
--service_account_namedient zur Authentifizierung über ein Dienstkonto statt über ein persönliches Nutzerkonto. - Optional:
--destination_kms_keygibt die Schlüsselressourcen-ID für den Cloud KMS-Schlüssel an, z. B.projects/project_name/locations/us/keyRings/key_ring_name/cryptoKeys/key_name.
Mit dem folgenden Befehl wird beispielsweise eine Konfiguration für eine geplante Abfrageübertragung mit der Bezeichnung My Scheduled Query unter Verwendung der Abfrage SELECT 1
from mydataset.test erstellt. Die Zieltabelle mytable wird bei jedem Schreibvorgang gekürzt und das Ziel-Dataset ist mydataset. Die geplante Abfrage wird im Standardprojekt erstellt und mit einem Dienstkonto authentifiziert:
bq mk \
--transfer_config \
--target_dataset=mydataset \
--display_name='My Scheduled Query' \
--params='{"query":"SELECT 1 from mydataset.test","destination_table_name_template":"mytable","write_disposition":"WRITE_TRUNCATE"}' \
--data_source=scheduled_query \
--service_account_name=abcdef-test-sa@abcdef-test.iam.gserviceaccount.com
Wenn Sie den Befehl zum ersten Mal ausführen, erhalten Sie eine Nachricht wie die folgende:
[URL omitted] Please copy and paste the above URL into your web browser and
follow the instructions to retrieve an authentication code.
Richten Sie sich nach der Anleitung in der Nachricht und fügen Sie den Authentifizierungscode in die Befehlszeile ein.
API
Verwenden Sie die Methode projects.locations.transferConfigs.create und geben Sie eine Instanz der Ressource TransferConfig an.
Java
Bevor Sie dieses Beispiel anwenden, folgen Sie den Schritten zur Einrichtung von Java in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery Java API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Python
Bevor Sie dieses Beispiel anwenden, folgen Sie den Schritten zur Einrichtung von Python in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery Python API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Geplante Abfragen mit einem Dienstkonto einrichten
Java
Bevor Sie dieses Beispiel anwenden, folgen Sie den Schritten zur Einrichtung von Java in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery Java API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Python
Bevor Sie dieses Beispiel anwenden, folgen Sie den Schritten zur Einrichtung von Python in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery Python API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Status der geplanten Abfrage ansehen
Console
Wenn Sie den Status Ihrer geplanten Abfragen aufrufen möchten, klicken Sie im Navigationsmenü auf Zeitplanung und filtern Sie nach Geplante Abfrage. Klicken Sie auf eine geplante Abfrage, um weitere Informationen zu erhalten.
bq
Geplante Abfragen sind eine Art der Übertragung. Zum Anzeigen der Details einer geplanten Abfrage können Sie zuerst das bq-Befehlszeilentool verwenden, um die Übertragungskonfigurationen aufzulisten.
Geben Sie den Befehl bq ls mit dem Flag --transfer_config für die Ausführung der Übertragung an. Die folgenden Flags sind ebenfalls erforderlich:
--transfer_location
Beispiel:
bq ls \
--transfer_config \
--transfer_location=us
Wenn Sie die Details einer einzelnen geplanten Abfrage aufrufen möchten, geben Sie den Befehl bq show mit dem transfer_path für diese Konfiguration der geplanten Abfrage oder Übertragung ein.
Beispiel:
bq show \
--transfer_config \
projects/862514376110/locations/us/transferConfigs/5dd12f26-0000-262f-bc38-089e0820fe38
API
Verwenden Sie die Methode projects.locations.transferConfigs.list und geben Sie eine Instanz der Ressource TransferConfig an.
Java
Bevor Sie dieses Beispiel anwenden, folgen Sie den Schritten zur Einrichtung von Java in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery Java API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Python
Bevor Sie dieses Beispiel anwenden, folgen Sie den Schritten zur Einrichtung von Python in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery Python API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Geplante Abfragen aktualisieren
Console
So aktualisieren Sie eine geplante Abfrage:
- Klicken Sie im Navigationsmenü auf Geplante Abfragen oder Planung.
- Klicken Sie in der Liste der geplanten Abfragen auf den Namen der Abfrage, die Sie ändern möchten.
- Die Seite Details der geplanten Abfrage wird geöffnet. Klicken Sie auf Bearbeiten.
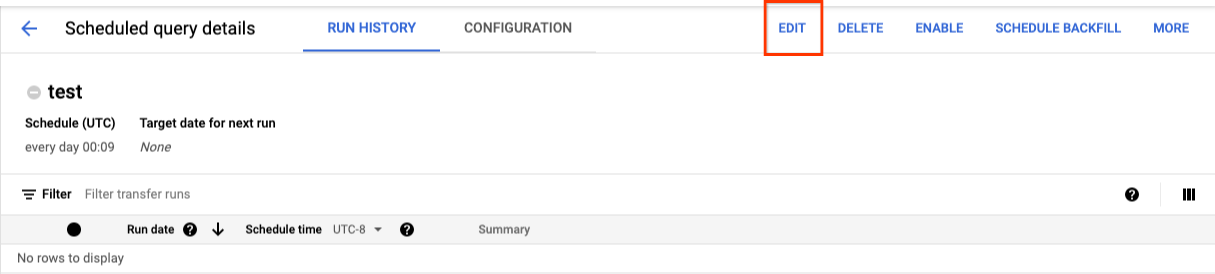
- Optional: Ändern Sie den Abfragetext im Bearbeitungsbereich der Abfrage.
- Klicken Sie auf Abfrage planen () und wählen Sie dann Geplante Abfrage aktualisieren () aus.
- Optional: Ändern Sie anderen Planungsoptionen für die Abfrage.
- Klicken Sie auf Aktualisieren.
bq
Geplante Abfragen sind eine Art der Übertragung. Zum Aktualisieren einer geplanten Abfrage können Sie mit dem bq-Befehlszeilentool eine Übertragungskonfiguration vornehmen.
Geben Sie den Befehl bq update mit dem erforderlichen Flag --transfer_config ein.
Optionale Flags:
--project_idist die Projekt-ID. Wenn--project_idnicht angegeben ist, wird das Standardprojekt verwendet.--schedulegibt an, wie oft die Abfrage ausgeführt werden soll. Wenn--schedulenicht angegeben ist, wird als Standardeinstellung "alle 24 Stunden" basierend auf der Erstellungszeit verwendet.--service_account_namewird nur wirksam, wenn auch--update_credentialsfestgelegt ist. Weitere Informationen finden Sie unter Anmeldedaten für geplante Abfragen aktualisieren.--target_dataset(optional für DDL- und DML-Abfragen) ist eine alternative Möglichkeit, das Ziel-Dataset für die Abfrageergebnisse zu benennen, wenn es mit DDL- und DML-Abfragen verwendet wird.--display_nameist der Name für die geplante Abfrage.--paramsdie Parameter für die erstellte Übertragungskonfiguration im JSON-Format. Beispiel: --params='{"param":"param_value"}'.--destination_kms_keygibt die Schlüsselressourcen-ID für den Cloud KMS-Schlüssel an, wenn Sie für diese Übertragung einen vom Kunden verwalteten Verschlüsselungsschlüssel (CMEK) verwenden. Informationen zur Funktionsweise von vom Kunden verwalteten Verschlüsselungsschlüsseln (CMEKs) mit BigQuery Data Transfer Service finden Sie unter Verschlüsselungsschlüssel mit geplanten Abfragen angeben.
bq update \ --target_dataset=dataset \ --display_name=name \ --params='parameters' --transfer_config \ RESOURCE_NAME
Ersetzen Sie Folgendes:
dataset. Das Ziel-Dataset für die Übertragungskonfiguration. Dieser Parameter ist für DDL- und DML-Abfragen optional. Er wird für alle anderen Abfragen benötigt.name. Der angezeigte Name für die Übertragungskonfiguration. Der angezeigte Name kann ein beliebiger Wert sein, den Sie später identifizieren können, wenn Sie die Abfrage ändern müssen.parameters. Enthält die Parameter für die erstellte Übertragungskonfiguration im JSON-Format. Beispiel:--params='{"param":"param_value"}'.- Für eine geplante Abfrage müssen Sie den Parameter
queryangeben. - Der Parameter
destination_table_name_templateist der Name der Zieltabelle. Dieser Parameter ist für DDL- und DML-Abfragen optional. Er wird für alle anderen Abfragen benötigt. - Für den Parameter
write_dispositionwählen Sie entwederWRITE_TRUNCATE, um die Zieltabelle zu kürzen (überschreiben), oderWRITE_APPEND, um die Abfrageergebnisse an die Zieltabelle anzuhängen. Dieser Parameter ist für DDL- und DML-Abfragen optional. Er wird für alle anderen Abfragen benötigt.
- Für eine geplante Abfrage müssen Sie den Parameter
- Optional:
--destination_kms_keygibt die Schlüsselressourcen-ID für den Cloud KMS-Schlüssel an, z. B.projects/project_name/locations/us/keyRings/key_ring_name/cryptoKeys/key_name. RESOURCE_NAME: Der Ressourcenname der Übertragung (auch als Übertragungskonfiguration bezeichnet). Wenn Sie den Ressourcennamen der Übertragung nicht kennen, suchen Sie den Ressourcennamen mitbq ls --transfer_config --transfer_location=location.
Mit dem folgenden Befehl wird beispielsweise eine Konfiguration für eine geplante Abfrageübertragung mit der Bezeichnung My Scheduled Query unter Verwendung der Abfrage SELECT 1
from mydataset.test aktualisiert. Die Zieltabelle mytable wird bei jedem Schreibvorgang gekürzt und das Ziel-Dataset ist mydataset:
bq update \
--target_dataset=mydataset \
--display_name='My Scheduled Query' \
--params='{"query":"SELECT 1 from mydataset.test","destination_table_name_template":"mytable","write_disposition":"WRITE_TRUNCATE"}'
--transfer_config \
projects/myproject/locations/us/transferConfigs/1234a123-1234-1a23-1be9-12ab3c456de7
API
Verwenden Sie die Methode projects.transferConfigs.patch und geben Sie den Ressourcennamen der Übertragung mithilfe des Parameters transferConfig.name an. Wenn Sie den Ressourcennamen der Übertragung nicht kennen, verwenden Sie den Befehl bq ls --transfer_config --transfer_location=location, um alle Übertragungen aufzulisten, oder rufen Sie die Methode projects.locations.transferConfigs.list auf und geben Sie die Projekt-ID mithilfe des Parameters parent an.
Java
Bevor Sie dieses Beispiel anwenden, folgen Sie den Schritten zur Einrichtung von Java in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery Java API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Python
Bevor Sie dieses Beispiel anwenden, folgen Sie den Schritten zur Einrichtung von Python in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery Python API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Geplante Abfragen mit Inhabereinschränkungen aktualisieren
Wenn Sie eine geplante Abfrage aktualisieren, die Ihnen nicht gehört, kann die Aktualisierung mit der folgenden Fehlermeldung fehlschlagen:
Cannot modify restricted parameters without taking ownership of the transfer configuration.
Der Inhaber der geplanten Abfrage ist der Nutzer, der der geplanten Abfrage zugeordnet ist, oder der Nutzer, der Zugriff auf das Dienstkonto hat, das mit der geplanten Abfrage verknüpft ist. Der zugehörige Nutzer ist in den Konfigurationsdetails der geplanten Abfrage sichtbar. Informationen zum Aktualisieren der geplanten Abfrage, um die Inhaberschaft zu übernehmen, finden Sie unter Anmeldedaten für geplante Abfragen aktualisieren. Sie benötigen die Rolle „Dienstkontonutzer“, um Nutzern Zugriff auf ein Dienstkonto zu gewähren.
Die Parameter mit Inhabereinschränkungen für geplante Abfragen sind:
- Der Abfragetext
- Das Ziel-Dataset
- Vorlage für den Namen der Zieltabelle
Anmeldedaten für geplante Abfragen aktualisieren
Wenn Sie eine vorhandene Abfrage planen, müssen Sie möglicherweise die Nutzeranmeldedaten für die Abfrage aktualisieren. Die Anmeldedaten sind für neue geplante Abfragen automatisch auf dem neuesten Stand.
Andere Situationen, in denen eine Aktualisierung der Anmeldedaten erforderlich sein könnte:
- Sie möchten Google Drive-Daten in einer geplanten Abfrage abfragen.
Sie erhalten die Fehlermeldung INVALID_USER, wenn Sie versuchen, die Abfrage zu planen:
Error code 5 : Authentication failure: User Id not found. Error code: INVALID_USERIDDer folgende eingeschränkte Parameterfehler wird angezeigt, wenn Sie versuchen, die Abfrage zu aktualisieren:
Cannot modify restricted parameters without taking ownership of the transfer configuration.
Console
So aktualisieren Sie die vorhandenen Anmeldedaten für eine geplante Abfrage:
Klicken Sie auf die Schaltfläche MORE (Mehr) und wählen Sie Update credentials (Anmeldedaten aktualisieren) aus.
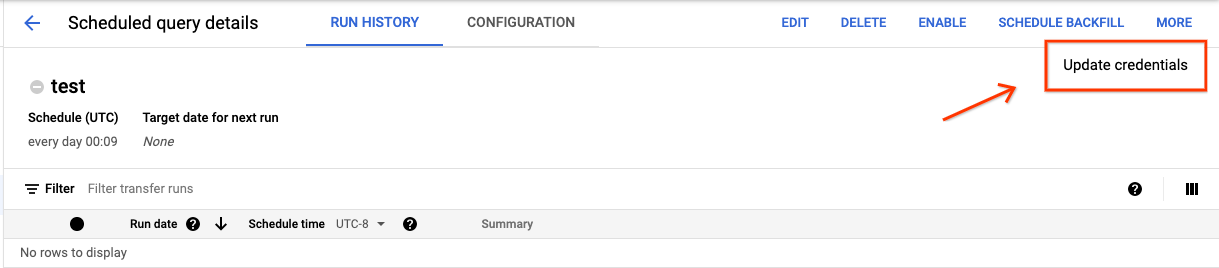
Warten Sie 10 bis 20 Minuten, bis die Änderung wirksam wird. Unter Umständen müssen Sie auch den Cache Ihres Browsers löschen.
bq
Geplante Abfragen sind eine Art der Übertragung. Wenn Sie die Anmeldedaten einer geplanten Abfrage aktualisieren, können Sie das bq-Befehlszeilentool verwenden, um die Übertragungskonfiguration zu aktualisieren.
Geben Sie den Befehl bq update mit dem Flag --transfer_config für die Ausführung der Übertragung an. Die folgenden Flags sind ebenfalls erforderlich:
--update_credentials
Optionales Flag:
--service_account_namedient der Authentifizierung der geplanten Abfrage über ein Dienstkonto statt über Ihr eigenes Nutzerkonto.
Mit dem folgenden Befehl wird beispielsweise die Übertragungskonfiguration einer geplanten Abfrage zur Authentifizierung über ein Dienstkonto aktualisiert.
bq update \
--update_credentials \
--service_account_name=abcdef-test-sa@abcdef-test.iam.gserviceaccount.com \
--transfer_config \
projects/myproject/locations/us/transferConfigs/1234a123-1234-1a23-1be9-12ab3c456de7
Java
Bevor Sie dieses Beispiel anwenden, folgen Sie den Schritten zur Einrichtung von Java in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery Java API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Python
Bevor Sie dieses Beispiel anwenden, folgen Sie den Schritten zur Einrichtung von Python in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery Python API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Ausführung für festen Zeitraum einrichten
Die Ausführung einer Abfrage kann nicht nur zu bestimmten Zeitpunkten geplant werden, sondern auch jederzeit manuell ausgelöst werden. Das Auslösen einer sofortigen Ausführung ist erforderlich, wenn die Abfrage den Parameter run_date verwendet und bei früheren Ausführungen Probleme auftraten.
Sie fragen beispielsweise jeden Tag um 09:00 Uhr eine Quelltabelle nach Zeilen ab, die dem aktuellen Datum entsprechen. Sie stellen jedoch fest, dass in den letzten drei Tagen keine Daten zur Quelltabelle hinzugefügt wurden. In dieser Situation können Sie die Abfrage so einstellen, dass eine unbegrenzte Ausführung zu bestimmten Zeitpunkten ausgeführt wird. Ihre Abfrage wird mit einer Kombination aus run_date- und run_time-Parametern ausgeführt, die den in der geplanten Abfrage konfigurierten Daten entsprechen.
Nach dem Einrichten einer geplanten Abfrage können Sie die Abfrage für einen festen Zeitraum ausführen:
Console
Nachdem Sie auf Planen geklickt haben, um die geplante Abfrage zu speichern, können Sie auf die Schaltfläche Geplante Abfragen klicken, um die Liste der geplanten Abfragen aufzurufen. Sie können die Details zu einer geplanten Abfrage aufrufen, indem Sie auf den zugehörigen Anzeigenamen klicken. Klicken Sie oben rechts auf Schedule backfill (Backfill planen), um einen festen Zeitraum anzugeben.
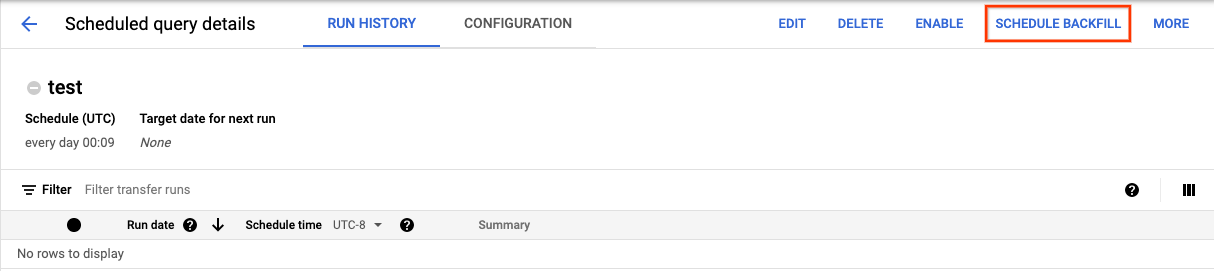
Die ausgewählten Laufzeiten liegen alle innerhalb des ausgewählten Bereichs, wobei das erste Datum enthalten ist, das letzte aber nicht.
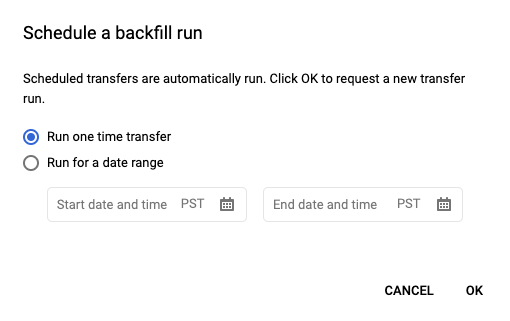
Beispiel 1
Die geplante Abfrage wird so eingestellt, dass sie every day 09:00 in der Zeitzone U.S. Pacific ausgeführt wird. Daten vom 1., 2. und 3. Januar fehlen. Wählen Sie den folgenden festen Zeitraum:
Start Time = 1/1/19
End Time = 1/4/19
Die Abfrage wird mit den Parametern run_date und run_time ausgeführt, die den folgenden Zeiten entsprechen:
- 01.01.19, 09:00 Uhr, Zeitzone U.S. Pacific
- 02.01.19, 09:00 Uhr, Zeitzone U.S. Pacific
- 03.01.19, 09:00 Uhr, Zeitzone U.S. Pacific
Beispiel 2
Die geplante Abfrage wird so eingestellt, dass sie every day 23:00 in der Zeitzone U.S. Pacific ausgeführt wird. Daten vom 1., 2. und 3. Januar fehlen. Wählen Sie die folgenden festen Zeiträume aus (spätere Datumsangaben werden ausgewählt, da die Zeitzone UTC um 23:00 Uhr in der Zeitzone U.S. Pacific ein anderes Datum als diese hat):
Start Time = 1/2/19
End Time = 1/5/19
Die Abfrage wird mit den Parametern run_date und run_time ausgeführt, die den folgenden Zeiten entsprechen:
- 02.01.19, 06:00 Uhr, Zeitzone UTC oder 01.01.2019, 23:00 Uhr, Zeitzone U.S. Pacific
- 02.01.19, 06:00 Uhr, Zeitzone UTC oder 01.01.2019, 23:00 Uhr, Zeitzone U.S. Pacific
- 02.01.19, 06:00 Uhr, Zeitzone UTC oder 01.01.2019, 23:00 Uhr, Zeitzone U.S. Pacific
Aktualisieren Sie nach dem Einrichten der manuellen Ausführung die Seite, um sie in der Liste der Ausführungen anzeigen zu lassen.
bq
So führen Sie die Abfrage manuell in einem festen Zeitraum aus:
Geben Sie den Befehl bq mk mit dem Flag --transfer_run für die Ausführung der Übertragung an. Die folgenden Flags sind ebenfalls erforderlich:
--start_time--end_time
bq mk \ --transfer_run \ --start_time='start_time' \ --end_time='end_time' \ resource_name
Ersetzen Sie Folgendes:
start_timeundend_time. Zeitstempel, die mit Z enden oder einen gültigen Zeitzonenversatz haben. Beispiele:- 2017-08-19T12:11:35.00Z
- 2017-05-25T00:00:00+00:00
resource_name. Der Ressourcenname der geplanten Abfrage (oder der Übertragung). Der Ressourcenname ist auch als Übertragungskonfiguration bekannt.
Mit dem folgenden Befehl können Sie beispielsweise ein Backfill für die geplante Abfrageressource (oder Übertragungskonfiguration) planen: projects/myproject/locations/us/transferConfigs/1234a123-1234-1a23-1be9-12ab3c456de7.
bq mk \
--transfer_run \
--start_time 2017-05-25T00:00:00Z \
--end_time 2017-05-25T00:00:00Z \
projects/myproject/locations/us/transferConfigs/1234a123-1234-1a23-1be9-12ab3c456de7
Weitere Informationen finden Sie unter bq mk --transfer_run.
API
Verwenden Sie die Methode projects.locations.transferConfigs.scheduleRun und geben Sie einen Pfad für die TransferConfig-Ressource an.
Java
Bevor Sie dieses Beispiel anwenden, folgen Sie den Schritten zur Einrichtung von Java in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery Java API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Python
Bevor Sie dieses Beispiel anwenden, folgen Sie den Schritten zur Einrichtung von Python in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery Python API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Benachrichtigungen für geplante Abfragen einrichten
Sie können Benachrichtigungsrichtlinien für geplante Abfragen auf Grundlage von Messwerten für die Zeilenanzahl konfigurieren. Weitere Informationen finden Sie unter Benachrichtigungen mit geplanten Abfragen einrichten.
Geplante Abfragen löschen
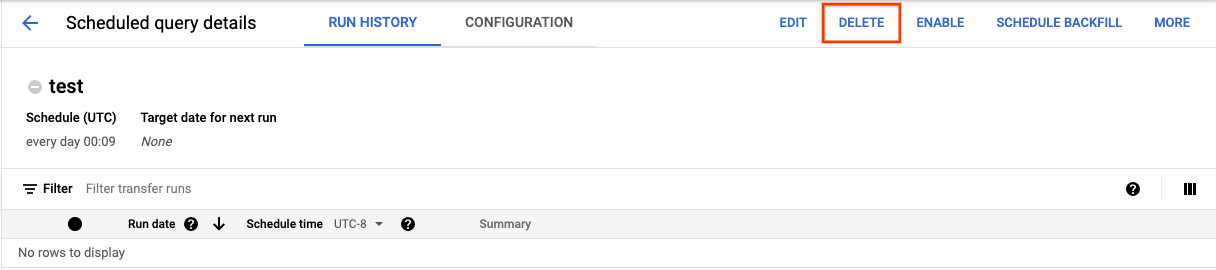
Console
So löschen Sie eine geplante Abfrage auf der Seite Geplante Abfragen der Google Cloud Console:
- Klicken Sie im Navigationsmenü auf Geplante Abfragen.
- Klicken Sie in der Liste der geplanten Abfragen auf den Namen der geplanten Abfrage, die Sie löschen möchten.
Klicken Sie auf der Seite Details der geplanten Abfrage auf Löschen.
Alternativ können Sie eine geplante Abfrage auf der Seite Planung der Google Cloud Console löschen:
- Klicken Sie im Navigationsmenü auf Planung.
- Klicken Sie in der Liste der geplanten Abfragen auf das Menü Aktionen für die geplante Abfrage, die Sie löschen möchten.
Wählen Sie Löschen aus.

Java
Bevor Sie dieses Beispiel anwenden, folgen Sie den Schritten zur Einrichtung von Java in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery Java API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Python
Bevor Sie dieses Beispiel anwenden, folgen Sie den Schritten zur Einrichtung von Python in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery Python API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Geplante Abfragen deaktivieren oder aktivieren
Wenn Sie geplante Ausführungen einer ausgewählten Abfrage pausieren möchten, ohne den Zeitplan zu löschen, können Sie ihn deaktivieren.
So deaktivieren Sie einen Zeitplan für eine ausgewählte Abfrage:
- Klicken Sie im Navigationsmenü der Google Cloud Console auf Planung.
- Klicken Sie in der Liste der geplanten Abfragen auf das Menü Aktionen für die geplante Abfrage, die Sie deaktivieren möchten.
Wählen Sie Disable (Deaktivieren) aus.

Wenn Sie eine deaktivierte geplante Abfrage aktivieren möchten, klicken Sie für die gewünschte geplante Abfrage auf das Menü Aktionen und wählen Sie Aktivieren aus.
Kontingente
Geplante Abfragen werden immer als Batchabfragejobs ausgeführt und unterliegen denselben Kontingenten und Limits für BigQuery wie manuelle Abfragen.
Obwohl geplante Abfragen Features des BigQuery Data Transfer Service verwenden, sind sie keine Übertragungen und unterliegen nicht dem Kontingent für Ladejobs.
Anhand der Identität, die zum Ausführen der Abfrage verwendet wird, wird festgelegt, welche Kontingente angewendet werden. Das hängt von der Konfiguration der geplanten Abfrage ab:
Anmeldedaten des Erstellers (Standard): Wenn Sie kein Dienstkonto angeben, wird die geplante Abfrage mit den Anmeldedaten des Nutzers ausgeführt, der sie erstellt hat. Der Abfragejob wird dem Projekt des Erstellers in Rechnung gestellt und unterliegt den Kontingenten dieses Nutzers und Projekts.
Dienstkonto-Anmeldedaten: Wenn Sie die geplante Abfrage so konfigurieren, dass ein Dienstkonto verwendet wird, wird sie mit den Anmeldedaten des Dienstkontos ausgeführt. In diesem Fall wird der Job weiterhin dem Projekt in Rechnung gestellt, das die geplante Abfrage enthält. Die Ausführung unterliegt jedoch den Kontingenten des angegebenen Dienstkontos.
Preise
Geplante Abfragen kosten genauso viel wie manuelle BigQuery-Abfragen.
Unterstützte Regionen
Geplante Abfragen werden an den folgenden Standorten unterstützt.
Regionen
In der folgenden Tabelle sind die Regionen in Amerika aufgeführt, in denen BigQuery verfügbar ist.| Beschreibung der Region | Name der Region | Details |
|---|---|---|
| Columbus, Ohio | us-east5 |
|
| Dallas | us-south1 |
|
| Iowa | us-central1 |
|
| Las Vegas | us-west4 |
|
| Los Angeles | us-west2 |
|
| Mexiko | northamerica-south1 |
|
| Montreal | northamerica-northeast1 |
|
| Northern Virginia | us-east4 |
|
| Oregon | us-west1 |
|
| Salt Lake City | us-west3 |
|
| São Paulo | southamerica-east1 |
|
| Santiago | southamerica-west1 |
|
| South Carolina | us-east1 |
|
| Toronto | northamerica-northeast2 |
|
| Beschreibung der Region | Name der Region | Details |
|---|---|---|
| Delhi | asia-south2 |
|
| Hongkong | asia-east2 |
|
| Jakarta | asia-southeast2 |
|
| Melbourne | australia-southeast2 |
|
| Mumbai | asia-south1 |
|
| Osaka | asia-northeast2 |
|
| Seoul | asia-northeast3 |
|
| Singapur | asia-southeast1 |
|
| Sydney | australia-southeast1 |
|
| Taiwan | asia-east1 |
|
| Tokio | asia-northeast1 |
| Beschreibung der Region | Name der Region | Details |
|---|---|---|
| Belgien | europe-west1 |
|
| Berlin | europe-west10 |
|
| Finnland | europe-north1 |
|
| Frankfurt | europe-west3 |
|
| London | europe-west2 |
|
| Madrid | europe-southwest1 |
|
| Mailand | europe-west8 |
|
| Niederlande | europe-west4 |
|
| Paris | europe-west9 |
|
| Stockholm | europe-north2 |
|
| Turin | europe-west12 |
|
| Warschau | europe-central2 |
|
| Zürich | europe-west6 |
|
| Beschreibung der Region | Name der Region | Details |
|---|---|---|
| Dammam | me-central2 |
|
| Doha | me-central1 |
|
| Tel Aviv | me-west1 |
| Beschreibung der Region | Name der Region | Details |
|---|---|---|
| Johannesburg | africa-south1 |
Multiregionen
In der folgenden Tabelle sind die Multiregionen aufgeführt, in denen BigQuery verfügbar ist.| Beschreibung des multiregionalen Standorts | Name des multiregionalen Standorts |
|---|---|
| Rechenzentren in Mitgliedsstaaten der Europäischen Union1 | EU |
| Rechenzentren in den USA2 | US |
1 Daten in der Multiregion EU werden nur an einem der folgenden Standorte gespeichert: europe-west1 (Belgien) oder europe-west4 (Niederlande).
Der genaue Speicherort, an dem die Daten gespeichert und verarbeitet werden, wird automatisch von BigQuery bestimmt.
2 Daten in der Multiregion US werden nur an einem der folgenden Standorte gespeichert: us-central1 (Iowa), us-west1 (Oregon) oder us-central2 (Oklahoma). Der genaue Standort, an dem die Daten gespeichert und verarbeitet werden, wird automatisch von BigQuery bestimmt.
Nächste Schritte
- Ein Beispiel für eine geplante Abfrage, die ein Dienstkonto verwendet und die Parameter
@run_dateund@run_timeenthält, finden Sie unter Tabellen-Snapshots mit einer geplanten Abfrage erstellen.