Carregue dados do Amazon S3 para o BigQuery
Pode carregar dados do Amazon S3 para o BigQuery através do conetor do Serviço de transferência de dados do BigQuery para o Amazon S3. Com o Serviço de transferência de dados do BigQuery, pode agendar tarefas de transferência recorrentes que adicionam os seus dados mais recentes do Amazon S3 ao BigQuery.
Antes de começar
Antes de criar uma transferência de dados do Amazon S3:
- Verifique se concluiu todas as ações necessárias para ativar o Serviço de transferência de dados do BigQuery.
- Crie um conjunto de dados do BigQuery para armazenar os seus dados.
- Crie a tabela de destino para a transferência de dados e especifique a definição do esquema. A tabela de destino tem de seguir as regras de nomenclatura de tabelas. Os nomes das tabelas de destino também suportam parâmetros.
- Obtenha o URI do Amazon S3, o ID da chave de acesso e a chave de acesso secreta. Para obter informações sobre como gerir as suas chaves de acesso, consulte a documentação da AWS.
- Se pretender configurar notificações de execução de transferências para o Pub/Sub, tem de ter
pubsub.topics.setIamPolicyautorizações. As autorizações do Pub/Sub não são necessárias se configurar apenas notificações por email. Para mais informações, consulte Notificações de execução do Serviço de transferência de dados do BigQuery.
Limitações
As transferências de dados do Amazon S3 estão sujeitas às seguintes limitações:
- Não é possível parametrizar a parte do contentor do URI do Amazon S3.
- As transferências de dados do Amazon S3 com o parâmetro Write disposition definido como
WRITE_TRUNCATEtransferem todos os ficheiros correspondentes para Google Cloud durante cada execução. Isto pode resultar em custos de transferência de dados de saída adicionais do Amazon S3. Para mais informações sobre os ficheiros transferidos durante uma execução, consulte o artigo Impacto da correspondência de prefixos em comparação com a correspondência de carateres universais. - As transferências de dados das regiões do AWS GovCloud (
us-gov) não são suportadas. - As transferências de dados para localizações do BigQuery Omni não são suportadas.
Consoante o formato dos dados de origem do Amazon S3, podem existir limitações adicionais. Para mais informações, consulte:
O intervalo de tempo mínimo entre transferências de dados recorrentes é de 1 hora. O intervalo predefinido para uma transferência de dados recorrente é de 24 horas.
Autorizações necessárias
Antes de criar uma transferência de dados do Amazon S3:
Certifique-se de que a pessoa que está a criar a transferência de dados tem as seguintes autorizações necessárias no BigQuery:
- Autorizações
bigquery.transfers.updatepara criar a Transferência de dados - Autorizações de
bigquery.datasets.getebigquery.datasets.updateno conjunto de dados de destino
A
bigquery.adminfunção de IAM predefinida inclui as autorizaçõesbigquery.transfers.update,bigquery.datasets.updateebigquery.datasets.get. Para mais informações sobre as funções do IAM no Serviço de transferência de dados do BigQuery, consulte o artigo Controlo de acesso.- Autorizações
Consulte a documentação do Amazon S3 para garantir que configurou todas as autorizações necessárias para ativar a transferência de dados. No mínimo, os dados de origem do Amazon S3 têm de ter a política gerida pela AWS
AmazonS3ReadOnlyAccessaplicada.
Configure uma transferência de dados do Amazon S3
Para criar uma transferência de dados do Amazon S3:
Consola
Aceda à página Transferências de dados na Google Cloud consola.
Clique em Criar transferência.
Na página Criar transferência:
Na secção Tipo de origem, para Origem, escolha Amazon S3.

Na secção Nome da configuração da transferência, em Nome a apresentar, introduza um nome para a transferência, como
My Transfer. O nome da transferência pode ser qualquer valor que lhe permita identificar a transferência se precisar de a modificar mais tarde.
Na secção Opções de programação:
Selecione uma Frequência de repetição. Se selecionar Horas, Dias, Semanas ou Meses, também tem de especificar uma frequência. Também pode selecionar Personalizado para criar uma frequência de repetição mais específica. Se selecionar A pedido, esta transferência de dados só é executada quando aciona manualmente a transferência.
Se aplicável, selecione Começar agora ou Começar à hora definida e indique uma data de início e um tempo de execução.
Na secção Definições de destino, para Conjunto de dados de destino, escolha o conjunto de dados que criou para armazenar os seus dados.
Na secção Detalhes da origem de dados:
- Em Tabela de destino, introduza o nome da tabela que criou para armazenar os dados no BigQuery. Os nomes das tabelas de destino suportam parâmetros.
- Para o URI do Amazon S3, introduza o URI no formato
s3://mybucket/myfolder/.... Os URIs também suportam parâmetros. - Para o ID da chave de acesso, introduza o ID da chave de acesso.
- Para Chave de acesso secreta, introduza a sua chave de acesso secreta.
- Para Formato de ficheiro, escolha o formato de dados (JSON delimitado por nova linha, CSV, Avro, Parquet ou ORC).
- Para Write Disposition, escolha uma das seguintes opções:
WRITE_APPENDpara acrescentar incrementalmente novos dados à tabela de destino existente.WRITE_APPENDé o valor predefinido para a preferência de escrita.WRITE_TRUNCATEpara substituir os dados na tabela de destino durante cada execução da transferência de dados.
Para mais informações sobre como o Serviço de transferência de dados do BigQuery carrega dados através do
WRITE_APPENDou doWRITE_TRUNCATE, consulte o artigo Carregamento de dados para transferências do Amazon S3. Para mais informações sobre o campowriteDisposition, consulteJobConfigurationLoad.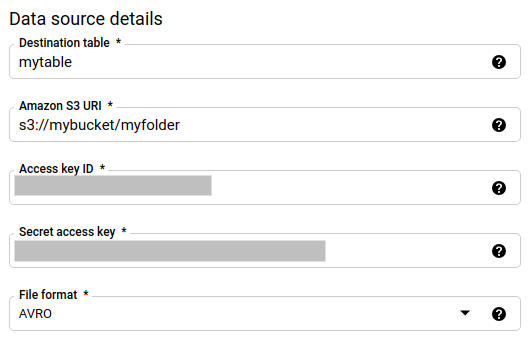
Na secção Opções de transferência – todos os formatos:
- Para Número de erros permitidos, introduza um valor inteiro para o número máximo de registos inválidos que podem ser ignorados.
- (Opcional) Para tipos de destino decimais, introduza uma lista separada por vírgulas dos possíveis tipos de dados SQL para os quais os valores decimais de origem podem ser convertidos. O tipo de dados SQL selecionado para a conversão depende das seguintes condições:
- O tipo de dados selecionado para a conversão será o primeiro tipo de dados na seguinte lista que suporta a precisão e a escala dos dados de origem, por esta ordem: NUMERIC, BIGNUMERIC e STRING.
- Se nenhum dos tipos de dados indicados suportar a precisão e a escala, é selecionado o tipo de dados que suporta o intervalo mais amplo na lista especificada. Se um valor exceder o intervalo suportado ao ler os dados de origem, é apresentado um erro.
- O tipo de dados STRING suporta todos os valores de precisão e escala.
- Se este campo for deixado em branco, o tipo de dados é predefinido como "NUMERIC,STRING" para ORC e "NUMERIC" para os outros formatos de ficheiros.
- Este campo não pode conter tipos de dados duplicados.
- A ordem dos tipos de dados que indica neste campo é ignorada.

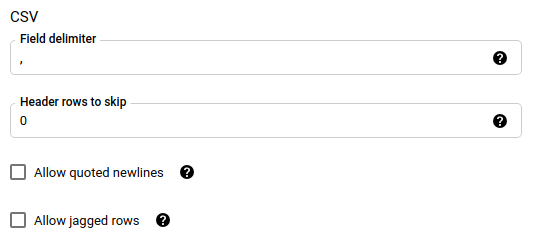
Se escolheu CSV ou JSON como formato de ficheiro, na secção JSON,CSV, selecione Ignorar valores desconhecidos para aceitar linhas que contenham valores que não correspondem ao esquema. Os valores desconhecidos são ignorados. Para ficheiros CSV, esta opção ignora valores adicionais no final de uma linha.

Se escolheu CSV como formato de ficheiro, na secção CSV, introduza quaisquer opções de CSV adicionais para carregar dados.
No menu Conta de serviço, selecione uma conta de serviço das contas de serviço associadas ao seu Google Cloud projeto. Pode associar uma conta de serviço à transferência de dados em vez de usar as suas credenciais de utilizador. Para mais informações sobre a utilização de contas de serviço com transferências de dados, consulte o artigo Utilize contas de serviço.
- Se iniciou sessão com uma identidade federada, é necessária uma conta de serviço para criar uma transferência de dados. Se iniciou sessão com uma Conta Google, uma conta de serviço para a transferência de dados é opcional.
- A conta de serviço tem de ter as autorizações necessárias.
(Opcional) Na secção Opções de notificação:
- Clique no botão para ativar as notificações por email. Quando ativa esta opção, o administrador da transferência recebe uma notificação por email quando uma execução da transferência de dados falha.
- Em Selecionar um tópico do Pub/Sub, escolha o nome do seu tópico ou clique em Criar um tópico para criar um. Esta opção configura notificações executadas pelo Pub/Sub para a transferência de dados.
Clique em Guardar.
bq
Introduza o comando bq mk e forneça a flag de criação de transferência —
--transfer_config.
bq mk \ --transfer_config \ --project_id=project_id \ --data_source=data_source \ --display_name=name \ --target_dataset=dataset \ --service_account_name=service_account \ --params='parameters'
Onde:
- project_id: opcional. O seu Google Cloud ID do projeto.
Se
--project_idnão for fornecido para especificar um projeto em particular, é usado o projeto predefinido. - data_source: obrigatório. A origem de dados:
amazon_s3. - display_name: obrigatório. O nome a apresentar da configuração de transferência de dados. O nome da transferência pode ser qualquer valor que lhe permita identificar a transferência se precisar de a modificar mais tarde.
- dataset: obrigatório. O conjunto de dados de destino para a configuração de transferência de dados.
- service_account: o nome da conta de serviço usado para autenticar a transferência de dados. A conta de serviço deve ser propriedade do mesmo
project_idusado para criar a transferência de dados e deve ter todas as autorizações necessárias. parameters: obrigatório. Os parâmetros da configuração de transferência criada no formato JSON. Por exemplo:
--params='{"param":"param_value"}'. Seguem-se os parâmetros para uma transferência do Amazon S3:- destination_table_name_template: obrigatório. O nome da tabela de destino.
data_path: obrigatório. O URI do Amazon S3, no seguinte formato:
s3://mybucket/myfolder/...Os URIs também suportam parâmetros.
access_key_id: obrigatório. O ID da chave de acesso.
secret_access_key: obrigatório. A sua chave de acesso secreta.
file_format: opcional. Indica o tipo de ficheiros que quer transferir:
CSV,JSON,AVRO,PARQUETouORC. O valor predefinido éCSV.write_disposition: opcional.
WRITE_APPENDtransfere apenas os ficheiros que foram modificados desde a execução bem-sucedida anterior.WRITE_TRUNCATEtransfere todos os ficheiros correspondentes, incluindo os ficheiros que foram transferidos numa execução anterior. A predefinição éWRITE_APPEND.max_bad_records: opcional. O número de registos inválidos permitidos. A predefinição é
0.decimal_target_types: opcional. Uma lista separada por vírgulas de tipos de dados SQL possíveis para os quais os valores decimais de origem podem ser convertidos. Se este campo não for fornecido, o tipo de dados é predefinido como "NUMERIC,STRING" para ORC e "NUMERIC" para os outros formatos de ficheiros.
ignore_unknown_values: opcional e ignorado se file_format não for
JSONnemCSV. Se deve ignorar os valores desconhecidos nos seus dados.field_delimiter: opcional e aplica-se apenas quando
file_formatéCSV. O caráter que separa os campos. O valor predefinido é uma vírgula.skip_leading_rows: opcional e aplica-se apenas quando file_format é
CSV. Indica o número de linhas de cabeçalho que não quer importar. O valor predefinido é0.allow_quoted_newlines: opcional e aplica-se apenas quando file_format é
CSV. Indica se devem ser permitidas novas linhas em campos entre aspas.allow_jagged_rows: opcional e aplica-se apenas quando file_format é
CSV. Indica se devem ser aceitas linhas que não tenham colunas opcionais finais. Os valores em falta são preenchidos com valores nulos.
Por exemplo, o comando seguinte cria uma transferência de dados do Amazon S3 denominada
My Transfer usando um valor data_path de
s3://mybucket/myfile/*.csv, o conjunto de dados de destino mydataset e file_format
CSV. Este exemplo inclui valores não predefinidos para os parâmetros opcionais associados ao CSV file_format.
A transferência de dados é criada no projeto predefinido:
bq mk --transfer_config \
--target_dataset=mydataset \
--display_name='My Transfer' \
--params='{"data_path":"s3://mybucket/myfile/*.csv",
"destination_table_name_template":"MyTable",
"file_format":"CSV",
"write_disposition":"WRITE_APPEND",
"max_bad_records":"1",
"ignore_unknown_values":"true",
"field_delimiter":"|",
"skip_leading_rows":"1",
"allow_quoted_newlines":"true",
"allow_jagged_rows":"false"}' \
--data_source=amazon_s3
Depois de executar o comando, recebe uma mensagem semelhante à seguinte:
[URL omitted] Please copy and paste the above URL into your web browser and
follow the instructions to retrieve an authentication code.
Siga as instruções e cole o código de autenticação na linha de comandos.
API
Use o método projects.locations.transferConfigs.create
e forneça uma instância do recurso TransferConfig.
Java
Antes de experimentar este exemplo, siga as Javainstruções de configuração no início rápido do BigQuery com bibliotecas cliente. Para mais informações, consulte a API Java BigQuery documentação de referência.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para bibliotecas de cliente.
Impacto da correspondência de prefixos em comparação com a correspondência de carateres universais
A API Amazon S3 suporta a correspondência de prefixos, mas não a correspondência de carateres universais. Todos os ficheiros do Amazon S3 que correspondam a um prefixo são transferidos para Google Cloud. No entanto, apenas os que correspondem ao URI do Amazon S3 na configuração de transferência são realmente carregados no BigQuery. Isto pode resultar em custos de transferência de dados de saída do Amazon S3 excessivos para ficheiros que são transferidos, mas não carregados no BigQuery.
Por exemplo, considere este caminho de dados:
s3://bucket/folder/*/subfolder/*.csv
Juntamente com estes ficheiros na localização de origem:
s3://bucket/folder/any/subfolder/file1.csv
s3://bucket/folder/file2.csv
Isto resulta na transferência de todos os ficheiros do Amazon S3 com o prefixo s3://bucket/folder/
para Google Cloud. Neste exemplo, file1.csv e file2.csv vão ser transferidos.
No entanto, apenas os ficheiros correspondentes a s3://bucket/folder/*/subfolder/*.csv são
efetivamente carregados no BigQuery. Neste exemplo, apenas file1.csv
será carregado no BigQuery.
Resolva problemas de configuração da transferência
Se tiver problemas com a configuração da transferência de dados, consulte o artigo Problemas de transferência do Amazon S3.
O que se segue?
- Para uma introdução às transferências de dados do Amazon S3, consulte o artigo Vista geral das transferências do Amazon S3
- Para uma vista geral do Serviço de transferência de dados do BigQuery, consulte o artigo Introdução ao Serviço de transferência de dados do BigQuery.
- Para obter informações sobre a utilização de transferências de dados, incluindo informações sobre uma configuração de transferência, a listagem de configurações de transferência e a visualização do histórico de execução de uma transferência, consulte o artigo Trabalhar com transferências.
- Saiba como carregar dados com operações em várias nuvens.