Especifique colunas aninhadas e repetidas em esquemas de tabelas
Esta página descreve como definir um esquema de tabela com colunas aninhadas e repetidas no BigQuery. Para uma vista geral dos esquemas de tabelas, consulte o artigo Especificar um esquema.
Defina colunas aninhadas e repetidas
Para criar uma coluna com dados aninhados, defina o tipo de dados da coluna como
RECORD no esquema. Pode aceder a um RECORD como um tipo STRUCT no GoogleSQL. Um STRUCT é um contentor de campos ordenados.
Para criar uma coluna com dados repetidos, defina o modo da coluna como REPEATED no esquema.
Pode aceder a um campo repetido como um tipo ARRAY no GoogleSQL.
Uma coluna RECORD pode ter o modo REPEATED, que é representado como uma matriz de tipos STRUCT. Além disso, um campo num registo pode ser repetido, o que é representado como um STRUCT que contém um ARRAY. Uma matriz não pode conter outra matriz diretamente. Para mais informações, consulte o artigo
Declarar um tipo de ARRAY.
Limitações
Os esquemas aninhados e repetidos estão sujeitos às seguintes limitações:
- Um esquema não pode conter mais de 15 níveis de tipos
RECORDaninhados. - As colunas do tipo
RECORDpodem conter tiposRECORDaninhados, também denominados registos secundários. O limite máximo de profundidade de aninhamento é de 15 níveis. Este limite é independente de osRECORDs serem escalares ou baseados em matrizes (repetidos).
O tipo RECORD é incompatível com UNION, INTERSECT, EXCEPT DISTINCT e SELECT DISTINCT.
Esquema de exemplo
O exemplo seguinte mostra dados aninhados e repetidos de exemplo. Esta tabela contém informações sobre pessoas. É composto pelos seguintes campos:
idfirst_namelast_namedob(data de nascimento)addresses(um campo aninhado e repetido)addresses.status(atual ou anterior)addresses.addressaddresses.cityaddresses.stateaddresses.zipaddresses.numberOfYears(anos no endereço)
O ficheiro de dados JSON teria o seguinte aspeto. Repare que a coluna addresses contém uma matriz de valores (indicada por [ ]). Os vários endereços na matriz são os dados repetidos. Os vários campos em cada morada são os dados aninhados.
{"id":"1","first_name":"John","last_name":"Doe","dob":"1968-01-22","addresses":[{"status":"current","address":"123 First Avenue","city":"Seattle","state":"WA","zip":"11111","numberOfYears":"1"},{"status":"previous","address":"456 Main Street","city":"Portland","state":"OR","zip":"22222","numberOfYears":"5"}]}
{"id":"2","first_name":"Jane","last_name":"Doe","dob":"1980-10-16","addresses":[{"status":"current","address":"789 Any Avenue","city":"New York","state":"NY","zip":"33333","numberOfYears":"2"},{"status":"previous","address":"321 Main Street","city":"Hoboken","state":"NJ","zip":"44444","numberOfYears":"3"}]}
O esquema desta tabela tem o seguinte aspeto:
[ { "name": "id", "type": "STRING", "mode": "NULLABLE" }, { "name": "first_name", "type": "STRING", "mode": "NULLABLE" }, { "name": "last_name", "type": "STRING", "mode": "NULLABLE" }, { "name": "dob", "type": "DATE", "mode": "NULLABLE" }, { "name": "addresses", "type": "RECORD", "mode": "REPEATED", "fields": [ { "name": "status", "type": "STRING", "mode": "NULLABLE" }, { "name": "address", "type": "STRING", "mode": "NULLABLE" }, { "name": "city", "type": "STRING", "mode": "NULLABLE" }, { "name": "state", "type": "STRING", "mode": "NULLABLE" }, { "name": "zip", "type": "STRING", "mode": "NULLABLE" }, { "name": "numberOfYears", "type": "STRING", "mode": "NULLABLE" } ] } ]
Especificar as colunas aninhadas e repetidas no exemplo
Para criar uma nova tabela com as colunas aninhadas e repetidas anteriores, selecione uma das seguintes opções:
Consola
Especifique a coluna addresses aninhada e repetida:
Na Google Cloud consola, abra a página do BigQuery.
No painel Explorador, expanda o projeto e selecione um conjunto de dados.
No painel de detalhes, clique em Criar tabela.
Na página Criar tabela, especifique os seguintes detalhes:
- Para Origem, no campo Criar tabela a partir de, selecione Tabela vazia.
Na secção Destino, especifique os seguintes campos:
- Para Conjunto de dados, selecione o conjunto de dados no qual quer criar a tabela.
- Para Tabela, introduza o nome da tabela que quer criar.
Para Esquema, clique em Adicionar campo e introduza o seguinte esquema de tabela:
- Em Nome do campo, introduza
addresses. - Para Tipo, selecione REGISTO.
- Para Modo, escolha REPETIDO.
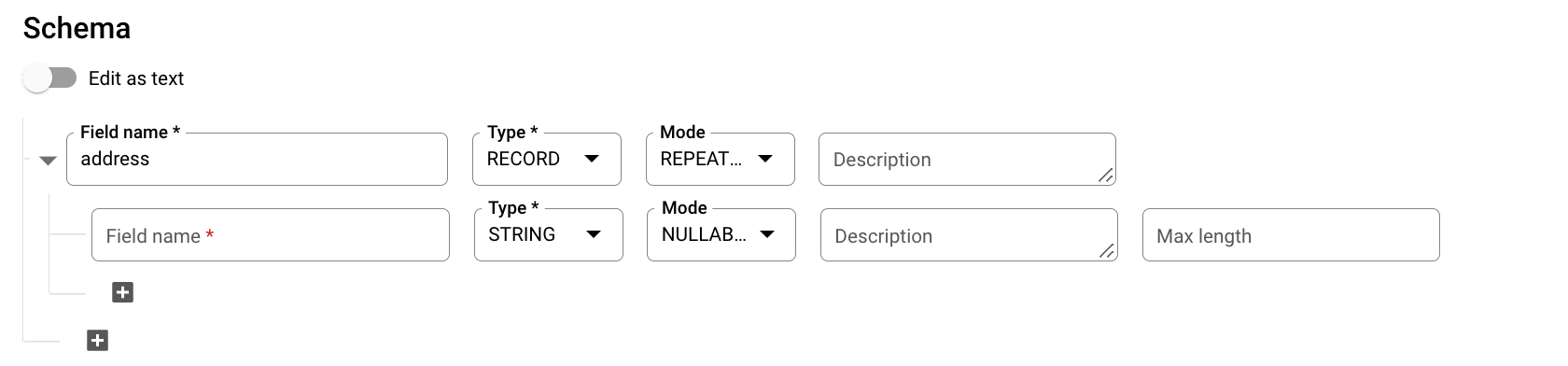
Especifique os seguintes campos para um campo aninhado:
- No campo Nome do campo, introduza
status. - Para Tipo, escolha STRING.
- Para Mode, deixe o valor definido como NULLABLE.
Clique em Adicionar campo para adicionar os seguintes campos:
Nome do campo Tipo Modo addressSTRINGNULLABLEcitySTRINGNULLABLEstateSTRINGNULLABLEzipSTRINGNULLABLEnumberOfYearsSTRINGNULLABLE
Em alternativa, clique em Editar como texto e especifique o esquema como uma matriz JSON.
- No campo Nome do campo, introduza
- Em Nome do campo, introduza
SQL
Use a declaração CREATE TABLE.
Especifique o esquema através da opção coluna:
Na Google Cloud consola, aceda à página BigQuery.
No editor de consultas, introduza a seguinte declaração:
CREATE TABLE IF NOT EXISTS mydataset.mytable ( id STRING, first_name STRING, last_name STRING, dob DATE, addresses ARRAY< STRUCT< status STRING, address STRING, city STRING, state STRING, zip STRING, numberOfYears STRING>> ) OPTIONS ( description = 'Example name and addresses table');
Clique em Executar.
Para mais informações sobre como executar consultas, consulte o artigo Execute uma consulta interativa.
bq
Para especificar a coluna addresses aninhada e repetida num ficheiro de esquema JSON,
use um editor de texto para criar um novo ficheiro. Cole a definição do esquema de exemplo apresentada acima.
Depois de criar o ficheiro de esquema JSON, pode fornecê-lo através da ferramenta de linha de comandos bq. Para mais informações, consulte o artigo Usar um ficheiro de esquema JSON.
Go
Antes de experimentar este exemplo, siga as Goinstruções de configuração no início rápido do BigQuery com bibliotecas cliente. Para mais informações, consulte a API Go BigQuery documentação de referência.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para bibliotecas de cliente.
Java
Antes de experimentar este exemplo, siga as Javainstruções de configuração no início rápido do BigQuery com bibliotecas cliente. Para mais informações, consulte a API Java BigQuery documentação de referência.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para bibliotecas de cliente.
Node.js
Antes de experimentar este exemplo, siga as Node.jsinstruções de configuração no início rápido do BigQuery com bibliotecas cliente. Para mais informações, consulte a API Node.js BigQuery documentação de referência.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para bibliotecas de cliente.
Python
Antes de experimentar este exemplo, siga as Pythoninstruções de configuração no início rápido do BigQuery com bibliotecas cliente. Para mais informações, consulte a API Python BigQuery documentação de referência.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para bibliotecas de cliente.
Insira dados em colunas aninhadas no exemplo
Use as seguintes consultas para inserir registos de dados aninhados em tabelas que tenham colunas do tipo de dados RECORD.
Exemplo 1
INSERT INTO mydataset.mytable (id, first_name, last_name, dob, addresses) values ("1","Johnny","Dawn","1969-01-22", ARRAY< STRUCT< status STRING, address STRING, city STRING, state STRING, zip STRING, numberOfYears STRING>> [("current","123 First Avenue","Seattle","WA","11111","1")])
Exemplo 2
INSERT INTO mydataset.mytable (id, first_name, last_name, dob, addresses) values ("1","Johnny","Dawn","1969-01-22",[("current","123 First Avenue","Seattle","WA","11111","1")])
Consultar colunas aninhadas e repetidas
Para selecionar o valor de um ARRAY numa posição específica, use um operador de subscrição de matriz.
Para aceder a elementos num STRUCT, use o
operador de ponto.
O exemplo seguinte seleciona o nome próprio, o apelido e a primeira morada indicados no campo addresses:
SELECT first_name, last_name, addresses[offset(0)].address FROM mydataset.mytable;
O resultado é o seguinte:
+------------+-----------+------------------+ | first_name | last_name | address | +------------+-----------+------------------+ | John | Doe | 123 First Avenue | | Jane | Doe | 789 Any Avenue | +------------+-----------+------------------+
Para extrair todos os elementos de um ARRAY, use o
operador UNNEST
com um CROSS JOIN.
O exemplo seguinte seleciona o nome próprio, o apelido, a morada e o estado de todas as moradas que não se encontram em Nova Iorque:
SELECT first_name, last_name, a.address, a.state FROM mydataset.mytable CROSS JOIN UNNEST(addresses) AS a WHERE a.state != 'NY';
O resultado é o seguinte:
+------------+-----------+------------------+-------+ | first_name | last_name | address | state | +------------+-----------+------------------+-------+ | John | Doe | 123 First Avenue | WA | | John | Doe | 456 Main Street | OR | | Jane | Doe | 321 Main Street | NJ | +------------+-----------+------------------+-------+
Modifique colunas aninhadas e repetidas
Depois de adicionar uma coluna aninhada ou uma coluna aninhada e repetida à definição do esquema de uma tabela, pode modificar a coluna como faria com qualquer outro tipo de coluna. O BigQuery suporta nativamente várias alterações de esquema, como adicionar um novo campo aninhado a um registo ou flexibilizar o modo de um campo aninhado. Para mais informações, consulte o artigo Modificar esquemas de tabelas.
Quando usar colunas aninhadas e repetidas
O BigQuery tem o melhor desempenho quando os seus dados são desnormalizados. Em vez de preservar um esquema relacional, como um esquema em estrela ou floco de neve, desnormalize os seus dados e tire partido das colunas aninhadas e repetidas. As colunas aninhadas e repetidas podem manter relações sem o impacto no desempenho da preservação de um esquema relacional (normalizado).
Por exemplo, uma base de dados relacional usada para monitorizar livros de bibliotecas provavelmente manteria todas as informações dos autores numa tabela separada. Uma chave como author_id seria usada para associar o livro aos autores.
No BigQuery, pode preservar a relação entre o livro e o autor sem criar uma tabela de autores separada. Em alternativa, cria uma coluna de autor e aninha campos na mesma, como o nome próprio, o apelido, a data de nascimento, etc. do autor. Se um livro tiver vários autores, pode tornar a coluna de autor aninhada repetida.
Suponhamos que tem a seguinte tabela mydataset.books:
+------------------+------------+-----------+ | title | author_ids | num_pages | +------------------+------------+-----------+ | Example Book One | [123, 789] | 487 | | Example Book Two | [456] | 89 | +------------------+------------+-----------+
Também tem a seguinte tabela, mydataset.authors, com informações completas para cada ID de autor:
+-----------+-------------+---------------+ | author_id | author_name | date_of_birth | +-----------+-------------+---------------+ | 123 | Alex | 01-01-1960 | | 456 | Rosario | 01-01-1970 | | 789 | Kim | 01-01-1980 | +-----------+-------------+---------------+
Se as tabelas forem grandes, a junção regular das mesmas pode exigir muitos recursos. Consoante a sua situação, pode ser vantajoso criar uma única tabela que contenha todas as informações:
CREATE TABLE mydataset.denormalized_books( title STRING, authors ARRAY<STRUCT<id INT64, name STRING, date_of_birth STRING>>, num_pages INT64) AS ( SELECT title, ARRAY_AGG(STRUCT(author_id, author_name, date_of_birth)) AS authors, ANY_VALUE(num_pages) FROM mydataset.books, UNNEST(author_ids) id JOIN mydataset.authors ON id = author_id GROUP BY title );
A tabela resultante tem o seguinte aspeto:
+------------------+-------------------------------+-----------+
| title | authors | num_pages |
+------------------+-------------------------------+-----------+
| Example Book One | [{123, Alex, 01-01-1960}, | 487 |
| | {789, Kim, 01-01-1980}] | |
| Example Book Two | [{456, Rosario, 01-01-1970}] | 89 |
+------------------+-------------------------------+-----------+
O BigQuery suporta o carregamento de dados aninhados e repetidos a partir de formatos de origem que suportam esquemas baseados em objetos, como ficheiros JSON, ficheiros Avro, ficheiros de exportação do Firestore e ficheiros de exportação do Datastore.
Remova registos duplicados numa tabela
A seguinte consulta usa a função row_number() para identificar registos duplicados que têm os mesmos valores para last_name e first_name nos exemplos usados e ordena-os por dob:
CREATE OR REPLACE TABLE mydataset.mytable AS ( SELECT * except(row_num) FROM ( SELECT *, row_number() over (partition by last_name, first_name order by dob) row_num FROM mydataset.mytable) temp_table WHERE row_num=1 )
Segurança da mesa
Para controlar o acesso a tabelas no BigQuery, consulte o artigo Controle o acesso a recursos com a IAM.
O que se segue?
- Para inserir e atualizar linhas com colunas aninhadas e repetidas, consulte a sintaxe da linguagem de manipulação de dados.