Organizzare le risorse BigQuery
Come altri servizi Google Cloud , le risorse BigQuery sono organizzate in una gerarchia. Puoi utilizzare questa gerarchia per gestire aspetti dei tuoi carichi di lavoro BigQuery come autorizzazioni, quote, prenotazioni di slot e fatturazione.
Gerarchia delle risorse
BigQuery eredita la Google Cloud gerarchia delle risorse e aggiunge un meccanismo di raggruppamento aggiuntivo chiamato set di dati, che sono specifici per BigQuery. Questa sezione descrive gli elementi di questa gerarchia.
Set di dati
I set di dati sono contenitori logici utilizzati per organizzare e controllare l'accesso alle risorse BigQuery. I set di dati sono simili agli schemi in altri sistemi di database.
La maggior parte delle risorse BigQuery che crei, tra cui tabelle, viste, funzioni e procedure, vengono create all'interno di un set di dati. Le connessioni e i job sono eccezioni; sono associati ai progetti anziché ai set di dati.
Un set di dati ha una posizione. Quando crei una tabella, i dati della tabella vengono archiviati nella posizione del set di dati. Prima di creare tabelle per i dati di produzione, pensa ai tuoi requisiti di località. Non puoi modificare la posizione di un set di dati dopo la creazione.
Progetti
Ogni set di dati è associato a un progetto. Per utilizzare Google Cloud, devi creare almeno un progetto. I progetti sono la base per creare, abilitare e utilizzare tutti i servizi Google Cloud . Per saperne di più, consulta Gerarchia delle risorse. Un progetto può contenere più set di dati e nello stesso progetto possono esistere set di dati con località diverse.
Quando esegui operazioni sui dati BigQuery, ad esempio esegui una query o importi dati in una tabella, crei un job. Un job è sempre associato a un progetto, ma non deve essere eseguito nello stesso progetto che contiene i dati. Infatti, un job potrebbe fare riferimento a tabelle di set di dati in più progetti. Un job di query, un job di caricamento o un job di estrazione viene sempre eseguito nella stessa posizione delle tabelle a cui fa riferimento.
Ogni progetto ha un account di fatturazione Cloud collegato. I costi maturati per un progetto vengono fatturati a questo account. Se utilizzi i prezzi on demand, le query vengono addebitate al progetto che le esegue. Se utilizzi i prezzi basati sulla capacità, le prenotazioni degli slot vengono fatturate al progetto di amministrazione utilizzato per acquistare gli slot. L'archiviazione viene addebitata al progetto in cui si trova il set di dati.
Cartelle
Le cartelle sono un meccanismo di raggruppamento aggiuntivo sopra i progetti. I progetti e le cartelle all'interno di una cartella ereditano automaticamente i criteri di accesso della cartella principale. Le cartelle possono essere utilizzate per modellare diverse persone giuridiche, reparti e team all'interno di un'azienda.
Organizzazioni
La risorsa organizzazione rappresenta un'organizzazione (ad esempio, un'azienda) ed è il nodo radice della gerarchia di risorseGoogle Cloud .
Per iniziare a utilizzare BigQuery non è necessaria una risorsa organizzazione, ma ti consigliamo di crearne una. L'utilizzo di una risorsa Organizzazione consente agli amministratori di controllare centralmente le risorse BigQuery, anziché lasciare che i singoli utenti controllino le risorse che creano.
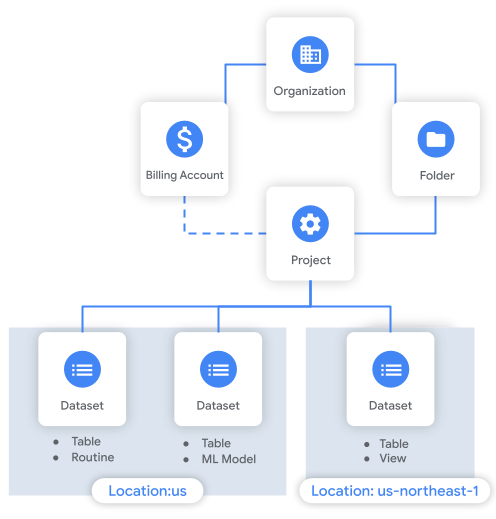
Il seguente diagramma mostra un esempio della gerarchia delle risorse. In questo esempio, l'organizzazione ha un progetto all'interno di una cartella. Il progetto è associato a un account di fatturazione e contiene tre set di dati.
Considerazioni
Quando scegli come organizzare le risorse BigQuery, considera i seguenti punti:
- Quote. Molte quote di BigQuery vengono applicate a livello di progetto. Alcune si applicano a livello di set di dati. Le quote a livello di progetto che coinvolgono risorse di calcolo, come query e job di caricamento, vengono conteggiate in base al progetto che crea il job, anziché al progetto di archiviazione.
- Fatturazione. Se vuoi che reparti diversi della tua organizzazione utilizzino account di fatturazione Cloud diversi, crea progetti diversi per ogni team. Crea gli account di fatturazione Cloud a livello di organizzazione e associa i progetti.
- Prenotazioni di slot. Gli slot riservati sono limitati alla risorsa Organizzazione. Dopo aver acquistato la capacità degli slot riservati, puoi assegnare un pool di slot a qualsiasi progetto o cartella all'interno dell'organizzazione oppure assegnare slot all'intera risorsa organizzazione. I progetti ereditano le prenotazioni di slot dalla cartella o dall'organizzazione padre. Gli slot riservati sono associati a un progetto di amministrazione, che viene utilizzato per gestire gli slot. Per saperne di più, vedi Gestione dei carichi di lavoro utilizzando le prenotazioni.
Autorizzazioni. Valuta in che modo la gerarchia delle autorizzazioni influisce sulle persone della tua organizzazione che devono accedere ai dati. Ad esempio, se vuoi concedere a un intero team l'accesso a dati specifici, puoi archiviarli in un unico progetto per semplificare la gestione dell'accesso.
Tabelle e altre entità ereditano le autorizzazioni del set di dati principale. I set di dati ereditano le autorizzazioni dalle entità principali nella gerarchia delle risorse (progetti, cartelle, organizzazioni). Per eseguire un'operazione su una risorsa, un utente ha bisogno sia delle autorizzazioni pertinenti sulla risorsa sia dell'autorizzazione per creare un job BigQuery. L'autorizzazione a creare un job è associata al progetto utilizzato per il job.
Motivi
Questa sezione presenta due pattern comuni per l'organizzazione delle risorse BigQuery.
Data lake centrale, data mart dei reparti. L'organizzazione crea un progetto di archiviazione unificato per contenere i dati non elaborati. I reparti dell'organizzazione creano i propri progetti di data mart per l'analisi.
Data lake di reparto, data warehouse centrale. Ogni reparto crea e gestisce il proprio progetto di archiviazione per conservare i dati non elaborati del reparto. L'organizzazione crea quindi un progetto di data warehouse centrale per l'analisi.
Ogni approccio presenta vantaggi e svantaggi. Molte organizzazioni combinano elementi di entrambi i modelli.
Data lake centrale, data mart di reparto
In questo pattern, crei un progetto di archiviazione unificato per contenere i dati non elaborati della tua organizzazione. In questo progetto può essere eseguita anche la pipeline di importazione dati. Il progetto di archiviazione unificata funge da data lake per la tua organizzazione.
Ogni reparto ha il proprio progetto dedicato, che utilizza per eseguire query sui dati, salvare i risultati delle query e creare visualizzazioni. Questi progetti a livello di reparto fungono da data mart. Sono associati all'account di fatturazione del reparto.
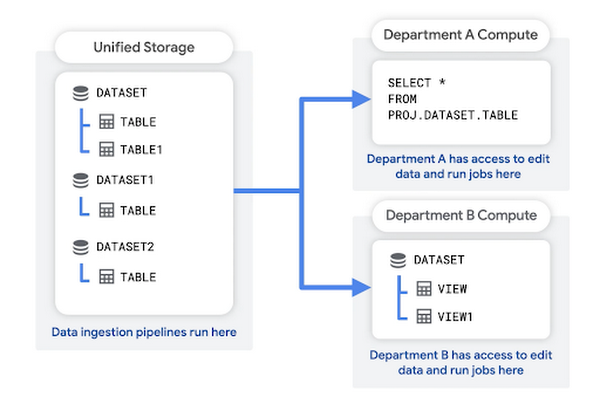
I vantaggi di questa struttura includono:
- Un team di data engineering centralizzato può gestire la pipeline di importazione in un'unica posizione.
- I dati non elaborati sono isolati dai progetti a livello di reparto.
- Con i prezzi on demand, la fatturazione per l'esecuzione delle query viene addebitata al dipartimento che esegue la query.
- Con i prezzi basati sulla capacità, puoi assegnare slot a ogni reparto in base ai requisiti di calcolo previsti.
- Ogni reparto è isolato dagli altri in termini di quote a livello di progetto.
Quando utilizzi questa struttura, le seguenti autorizzazioni sono tipiche:
- Al team centrale di data engineering vengono concessi i ruoli Editor dati BigQuery e Utente job BigQuery per il progetto di archiviazione. Questi consentono di importare e modificare i dati nel progetto di archiviazione.
- Agli analisti del reparto viene concesso il ruolo Visualizzatore dati BigQuery per set di dati specifici nel progetto del data lake centrale. In questo modo possono interrogare i dati, ma non aggiornare o eliminare i dati non elaborati.
- Agli analisti del reparto vengono concessi anche i ruoli Editor dati BigQuery e Utente job per il progetto data mart del reparto. Ciò consente loro di creare e aggiornare tabelle nel progetto ed eseguire job di query, al fine di trasformare e aggregare i dati per l'utilizzo specifico del reparto.
Per ulteriori informazioni, consulta Ruoli e autorizzazioni di base.
Data lake di reparto, data warehouse centrale
In questo pattern, ogni reparto crea e gestisce il proprio progetto di archiviazione, che contiene i dati non elaborati del reparto. Un progetto data warehouse centrale memorizza aggregazioni o trasformazioni dei dati non elaborati.
Gli analisti possono eseguire query e leggere i dati aggregati dal progetto data warehouse. Il progetto data warehouse fornisce anche un livello di accesso per gli strumenti di business intelligence (BI).
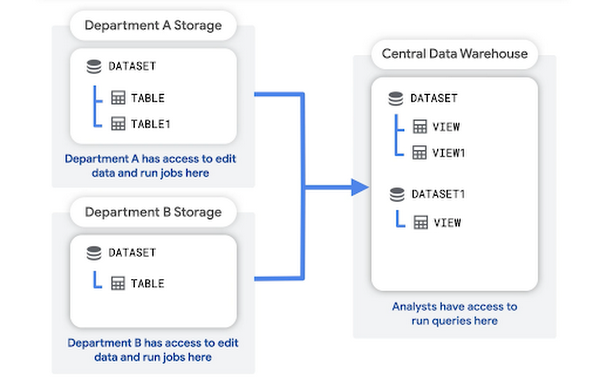
I vantaggi di questa struttura includono:
- È più semplice gestire l'accesso ai dati a livello di reparto utilizzando progetti separati per ogni reparto.
- Un team di analisi centrale ha un unico progetto per l'esecuzione dei job di analisi, il che semplifica il monitoraggio delle query.
- Gli utenti possono accedere ai dati da uno strumento BI centralizzato, che viene mantenuto isolato dai dati non elaborati.
- Gli slot possono essere assegnati al progetto data warehouse per gestire tutte le query di analisti e strumenti esterni.
Quando utilizzi questa struttura, le seguenti autorizzazioni sono tipiche:
- Ai data engineer vengono concessi i ruoli Editor dati BigQuery e Utente job BigQuery nel data mart del loro reparto. Questi ruoli consentono di importare e trasformare i dati nel data mart.
- Agli analisti vengono concessi i ruoli Editor dati BigQuery e Utente job BigQuery nel progetto data warehouse. Questi ruoli consentono di creare viste aggregate nel data warehouse ed eseguire job di query.
- Agli service account che collegano BigQuery agli strumenti di BI viene concesso il ruolo Visualizzatore dati BigQuery per set di dati specifici, che possono contenere dati non elaborati del data lake o dati trasformati nel progetto data warehouse.
Per ulteriori informazioni, consulta Ruoli e autorizzazioni di base.
Puoi anche utilizzare funzionalità di sicurezza come viste autorizzate e funzioni definite dall'utente autorizzate (UDF) per rendere disponibili i dati aggregati a determinati utenti senza concedere loro l'autorizzazione a visualizzare i dati non elaborati nei progetti data mart.
Questa struttura del progetto può generare molte query simultanee nel progetto data warehouse. Di conseguenza, potresti raggiungere il limite di query simultanee. Se adotti questa struttura, valuta la possibilità di aumentare questo limite di quota per il progetto. Valuta anche l'utilizzo della fatturazione basata sulla capacità, in modo da poter acquistare un pool di slot per eseguire le query.