Introdução a tabelas particionadas
Uma tabela particionada é dividida em segmentos, chamados partições, que facilitam o gerenciamento e a consulta dos dados. Ao dividir uma tabela grande em partições menores, você melhora o desempenho das consultas e controla os custos, reduzindo o número de bytes lidos por consulta. Para particionar tabelas, especifique uma coluna de partição usada para segmentar a tabela.
Se uma consulta usar um filtro qualificado no valor da coluna de particionamento, o BigQuery poderá verificar as partições que correspondem ao filtro e pular as partições restantes. Esse processo é chamado de remoção.
Em uma tabela particionada, os dados são armazenados em blocos físicos, cada um contendo uma partição de dados. Cada tabela particionada mantém vários metadados sobre as propriedades de classificação em todas as operações que a modificam. Com os metadados, o BigQuery faz uma estimativa mais precisa dos custos de consulta antes de executá-la.
Quando usar o particionamento
Considere o particionamento de uma tabela nos seguintes cenários:
- Você quer melhorar o desempenho da consulta verificando apenas uma parte de uma tabela.
- A operação da tabela excede uma cota de tabela padrão, e é possível definir o escopo das operações da tabela para valores específicos da coluna de partição, permitindo cotas de tabela particionadas mais altas.
- Você quer determinar os custos de consulta antes de executar uma consulta. O BigQuery fornece estimativas de custo antes que a consulta seja executada em uma tabela particionada. Para calcular uma estimativa de custo da consulta, remova uma tabela particionada e execute uma simulação de execução de consulta para estimar os custos.
- Você quer um dos seguintes recursos de gerenciamento no nível da partição:
- Defina um prazo de validade da partição para excluir automaticamente partições inteiras após um período especificado.
- Grave dados em uma partição específica usando jobs de carregamento sem afetar outras partições na tabela.
- Excluir partições específicas sem verificar a tabela inteira.
Considere agrupar uma tabela em vez de particioná-la nas seguintes circunstâncias:
- Você precisa de mais granularidade do que o particionamento permite.
- As consultas geralmente usam filtros ou agregação em várias colunas.
- A cardinalidade do número de valores em uma coluna ou grupo de colunas é grande.
- Você não precisa de estimativas de custo rígidas antes da execução da consulta.
- O particionamento resulta em uma pequena quantidade de dados por particionamento (aproximadamente menos de 10 GB). Criar muitas partições pequenas aumenta os metadados da tabela e pode afetar os tempos de acesso aos metadados ao consultar a tabela.
- O particionamento resulta em um grande número de particionamentos, excedendo os limites nas tabelas particionadas.
- As operações DML modificam com frequência a maioria das partições na tabela, por exemplo, a cada poucos minutos.
Nesses casos, o clustering de tabelas permite acelerar consultas agrupando dados em colunas específicas com base nas propriedades de classificação definidas pelo usuário.
Também é possível combinar o clustering e o particionamento de tabela para alcançar uma classificação mais detalhada. Para mais informações sobre essa abordagem, consulte Como combinar tabelas particionadas e em cluster.
Tipos de particionamento
Nesta seção, descrevemos as diferentes maneiras de particionar uma tabela.
Particionamento por intervalo de números inteiros
É possível particionar uma tabela com base em intervalos de valores em uma coluna INTEGER
específica. Para criar uma tabela particionada por intervalo de números inteiros, forneça:
- A coluna de particionamento.
- O valor inicial do particionamento de intervalo (inclusive).
- O valor final do particionamento de intervalo (exclusivo).
- O intervalo de cada intervalo dentro da partição.
Por exemplo, suponha que você crie uma partição por intervalo de números inteiros com a seguinte especificação:
| Argumento | Valor |
|---|---|
| column name | customer_id |
| start | 0 |
| end | 100 |
| interval | 10 |
A tabela é particionada na coluna customer_id em intervalos de 10.
Os valores de 0 a 9 vão para uma partição, os valores de 10 a 19 vão para a próxima
partição, etc., até 99. Valores fora desse intervalo vão para uma partição
chamada __UNPARTITIONED__. Todas as linhas em que customer_id é NULL entram em uma partição chamada __NULL__.
Para mais informações sobre tabelas particionadas por intervalo de números inteiros, consulte Criar uma tabela particionada por intervalo de números inteiros.
Particionamento de colunas por unidade de tempo
É possível particionar uma tabela em uma coluna DATE, TIMESTAMP ou DATETIME na
tabela. Quando você grava dados na tabela, o BigQuery os coloca
automaticamente na partição correta, com base nos valores da coluna.
Para as colunas TIMESTAMP e DATETIME, as partições podem ter granularidade
por hora diária, mensal ou anual. Para as colunas DATE, as partições podem
ter granularidade diária, mensal ou anual. Os limites de partições são baseados no
horário UTC.
Por exemplo, se você particionar uma tabela em uma coluna DATETIME com
particionamento mensal. Se você inserir os seguintes valores na tabela, as
linhas serão gravadas nas seguintes partições:
| Valor da coluna | Partição (mensal) |
|---|---|
DATETIME("2019-01-01") |
201901 |
DATETIME("2019-01-15") |
201901 |
DATETIME("2019-04-30") |
201904 |
Além disso, duas partições especiais são criadas:
__NULL__: contém linhas com valoresNULLna coluna de particionamento.__UNPARTITIONED__: contém linhas em que o valor da coluna de particionamento é anterior a 01/01/1960 ou posterior a 31/12/2159.
Para informações sobre tabelas particionadas por coluna de unidade de tempo, consulte Criar uma tabela particionada por coluna de unidade de tempo.
Particionamento por tempo de processamento
Quando você cria uma tabela particionada por tempo de processamento, o BigQuery atribui automaticamente linhas às partições com base na hora em que o BigQuery processa os dados. É possível escolher granularidade por hora, diária, mensal ou anual para as partições. Os limites de partições são baseados no horário UTC.
Se os dados puderem alcançar o número máximo de partições por tabela ao usar uma granularidade de tempo mais fina, use uma granularidade mais aproximada. Por exemplo, é possível particionar por mês em vez de dia para reduzir o número de partições. Também é possível agrupar a coluna de partição para melhorar ainda mais o desempenho.
Uma tabela particionada por tempo de processamento tem uma pseudocoluna chamada _PARTITIONTIME.
O valor dessa coluna é o tempo de processamento de cada linha, truncado para o
limite de partição (como por hora ou dia). Por exemplo, suponha que você
crie uma tabela particionada por tempo de processamento com particionamento por hora e envie
dados nos seguintes horários:
| Tempo de ingestão | _PARTITIONTIME |
Partição (por hora) |
|---|---|---|
| 05/07/2021 17:22:00 | 05/07/2021 17:00:00 | 2021050717 |
| 05/07/2021 17:40:00 | 05/07/2021 17:00:00 | 2021050717 |
| 05/07/2021 18:31:00 | 05/07/2021 18:00:00 | 2021050718 |
Como a tabela neste exemplo usa particionamento por hora, o valor de
_PARTITIONTIME é truncado para um limite de hora. O BigQuery
usa esse valor para determinar a partição correta para os dados.
Também é possível gravar dados em uma partição específica. Por exemplo, talvez você queira carregar dados históricos ou ajustar os fusos horários. É possível usar qualquer data válida entre 01/01/0001 e 31/12/9999. No entanto, as instruções DML não podem referenciar datas anteriores a 01/01/1970 ou posteriores a 31/12/2159. Para mais informações, consulte Gravar dados em uma partição específica.
Em vez de usar _PARTITIONTIME, você também pode usar
_PARTITIONDATE.
A pseudocoluna _PARTITIONDATE contém a data em UTC correspondente ao valor
na pseudocoluna _PARTITIONTIME.
Escolher o particionamento diário, por hora, mensal ou anual.
Ao particionar uma tabela por coluna de unidade de tempo ou tempo de processamento, você escolhe se as partições têm granularidade diária, por hora, mensal ou anual.
Particionamento diário é o tipo de particionamento padrão. O particionamento diário é uma boa opção quando os dados são distribuídos por um grande intervalo de datas ou se os dados são adicionados continuamente ao longo do tempo.
Opte pelo particionamento por hora se as tabelas tiverem um grande volume de dados que abranja um intervalo curto (geralmente menos de seis meses de valores de carimbo de data/hora). Se você optar pelo particionamento por hora, verifique se a contagem de partições permanece dentro dos limites de partição.
Escolha o particionamento mensal ou anual se suas tabelas tiverem uma quantidade de dados relativamente pequena para cada dia, mas abrangerem um período amplo. Essa opção de particionamento também é recomendada se seu fluxo de trabalho exigir atualização frequente ou adição de linhas que abrangem um período amplo (por exemplo, mais de 500 datas). Nesses cenários, use o particionamento mensal ou anual, além do clustering na coluna de particionamento para obter um melhor desempenho. Para mais informações, consulte Como combinar tabelas particionadas e em cluster neste documento.
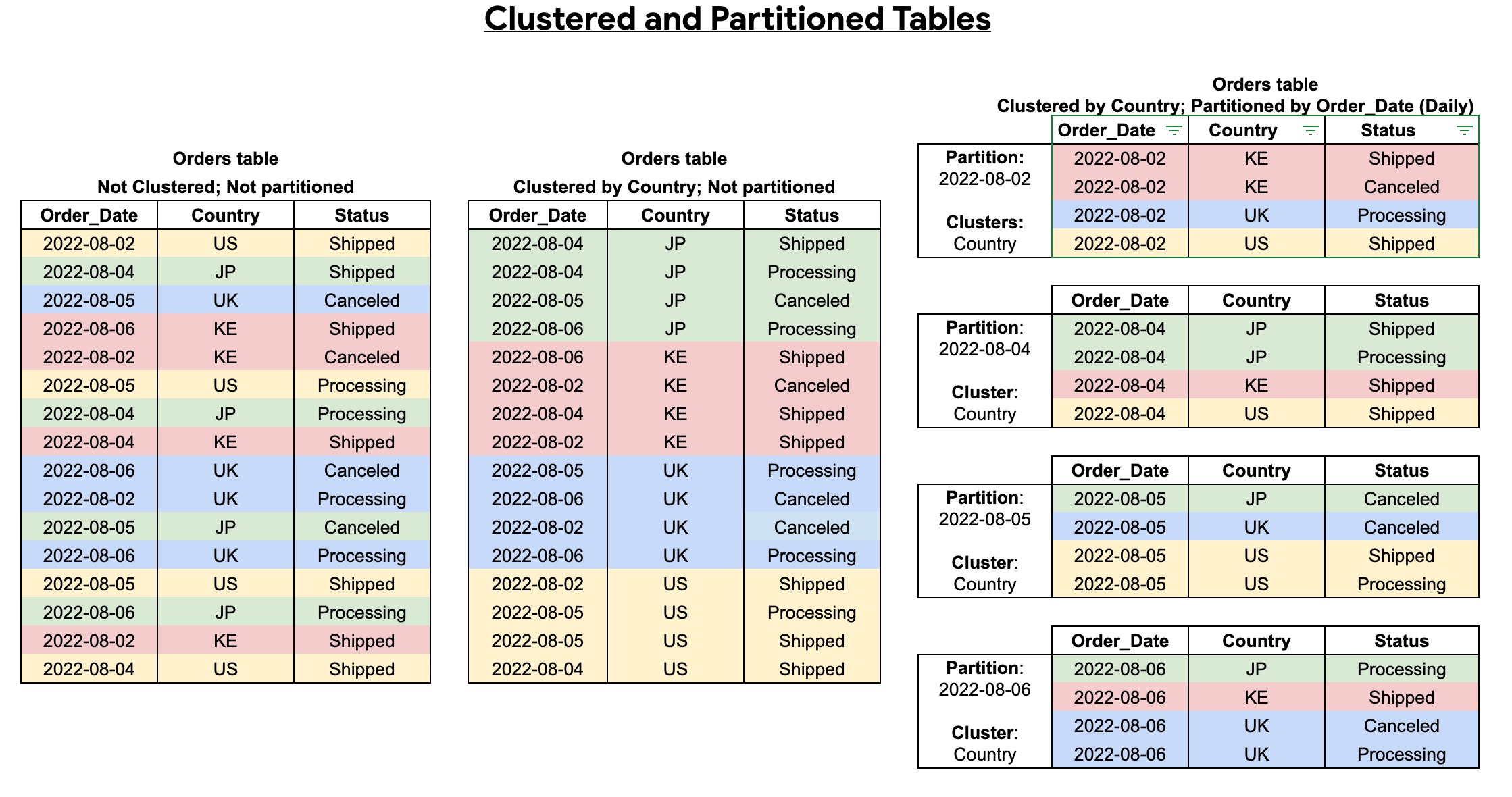
Como combinar tabelas particionadas e em cluster
É possível combinar o particionamento de tabela com o clustering de tabelas para garantir uma classificação detalhada e otimizar ainda mais a consulta.
Uma tabela em cluster contém colunas em cluster que classificam os dados com base nas propriedades de classificação definidas pelo usuário. Os dados dentro dessas colunas em cluster são classificados em blocos de armazenamento, que são dimensionados de forma adaptável com base no tamanho da tabela. Quando você executa uma consulta que filtra pela coluna em cluster, o BigQuery verifica apenas os blocos relevantes com base nessas colunas, e não em toda a tabela ou partição. Em uma abordagem combinada usando particionamento e clustering de tabelas, primeiro você segmenta os dados da tabela em partições e, em seguida, agrupa os dados em cada partição pelas colunas em cluster.
Ao criar uma tabela em cluster e particionada, é possível alcançar uma classificação mais refinada, como mostra o diagrama a seguir:
Particionamento x fragmentação
A fragmentação de tabelas é a prática de armazenar dados em várias tabelas, usando um
prefixo de nome como [PREFIX]_YYYYMMDD.
O particionamento é recomendado em vez da fragmentação da tabela porque as tabelas particionadas têm um desempenho melhor. Com tabelas fragmentadas, o BigQuery precisa manter uma cópia do esquema e dos metadados de cada tabela. O BigQuery também pode precisar verificar as permissões para cada tabela consultada. Essa prática também sobrecarrega a consulta e afeta o desempenho dela.
Se você criou tabelas fragmentadas por data anteriormente, é possível convertê-las em uma tabela particionada por tempo de processamento. Para mais informações, consulte Converter tabelas fragmentadas por data em tabelas particionadas por tempo de processamento.
Decoradores de partição
Os decoradores de partição permitem que você faça referência a uma partição em uma tabela. Por exemplo, é possível usá-las para gravar dados em uma partição específica.
Um decorador de partição tem o formato table_name$partition_id em que o formato do segmento partition_id depende do tipo de particionamento:
| Tipo de particionamento | Formato | Exemplo |
|---|---|---|
| Por hora | yyyymmddhh |
my_table$2021071205 |
| Diariamente | yyyymmdd |
my_table$20210712 |
| Mensalmente | yyyymm |
my_table$202107 |
| Anualmente | yyyy |
my_table$2021 |
| Intervalo de números inteiros | range_start |
my_table$40 |
Procurar os dados em uma partição
Para procurar os dados em uma partição especificada, use o comando bq head com um decorador de partição.
Por exemplo, o comando a seguir lista todos os campos nas primeiras 10 linhas de my_dataset.my_table na partição 2018-02-24:
bq head --max_rows=10 'my_dataset.my_table$20180224'
exportar dados da tabela
Exportar todos os dados de uma tabela particionada é o mesmo processo que exportar dados de uma tabela não particionada. Para mais informações, consulte Como exportar dados de tabelas.
Para exportar dados de uma partição individual, use o comando bq extract e anexe o decorador de partição ao nome da tabela. Por exemplo, my_table$20160201. Também é possível exportar os dados das partições __NULL__ e __UNPARTITIONED__anexando os nomes das partições ao nome da tabela. Por exemplo, my_table$__NULL__ ou my_table$__UNPARTITIONED__.
Limitações
As tabelas particionadas têm as seguintes limitações:
Não é possível usar SQL legado para consultar tabelas particionadas ou gravar resultados de consulta nesse tipo de tabela.
O BigQuery não oferece suporte ao particionamento por várias colunas. Só é possível usar uma coluna para particionar uma tabela.
Não é possível converter diretamente uma tabela não particionada em uma tabela particionada. A estratégia de particionamento é definida quando a tabela é criada. Em vez disso, use a instrução
CREATE TABLEpara criar uma tabela particionada consultando os dados na tabela atual.As tabelas particionadas por coluna de unidade de tempo estão sujeitas às seguintes limitações:
- A coluna de particionamento precisa ser
DATE,TIMESTAMPouDATETIME. O modo da coluna pode serREQUIREDouNULLABLE, mas não pode serREPEATED(baseado em matriz). - A coluna de particionamento precisa ser um campo de nível superior. Não é possível usar um campo de folha
de um
RECORD(STRUCT) como a coluna de particionamento.
Para informações sobre tabelas particionadas por coluna de unidade de tempo, consulte Criar uma tabela particionada por coluna de unidade de tempo.
- A coluna de particionamento precisa ser
As tabelas particionadas por variação em números inteiros estão sujeitas às seguintes limitações:
- A coluna de particionamento precisa ser uma coluna
INTEGER. O modo da coluna pode serREQUIREDouNULLABLE, mas não pode serREPEATED(baseado em matriz). - A coluna de particionamento precisa ser um campo de nível superior. Não é possível usar um campo de folha
de um
RECORD(STRUCT) como a coluna de particionamento.
Para mais informações sobre tabelas particionadas por intervalo de números inteiros, consulte Criar uma tabela particionada por intervalo de números inteiros.
- A coluna de particionamento precisa ser uma coluna
Cotas e limites
Tabelas particionadas definiram limites no BigQuery.
Cotas e limites também se aplicam aos diferentes tipos de jobs executados em tabelas particionadas, incluindo:
- Carregamento de dados (jobs de carregamento)
- Exportação de dados (jobs de extração)
- Consulta de dados (jobs de consulta)
- Cópia de tabelas (jobs de cópia)
Para mais informações sobre todas as cotas e limites, consulte Cotas e limites.
Preços da tabela
Ao criar e usar tabelas particionadas no BigQuery, as cobranças são baseadas na quantidade de dados armazenados nas partições e nas consultas de dados executadas:
- Para saber mais sobre preços de armazenamento, consulte esta página.
- Para saber mais sobre preços de consulta, consulte esta página.
Muitas operações de tabelas particionadas são gratuitas, incluindo carregamento de dados em partições, cópias de partições e exportação de dados de partições. Essas operações são gratuitas, mas estão sujeitas a cotas e limites do BigQuery. Consulte Operações gratuitas na página de preços para mais informações sobre esse assunto.
Para práticas recomendadas sobre como controlar de custos no BigQuery, consulte Como controlar custos no BigQuery.
Segurança de tabelas
O controle de acesso para tabelas particionadas é o mesmo que o das tabelas padrão. Saiba mais em Introdução aos controles de acesso à tabela.
A seguir
- Para saber como criar tabelas particionadas, consulte Como criar tabelas particionadas.
- Para saber como gerenciar e atualizar tabelas particionadas, consulte esta página.
- Para mais informações sobre como buscar tabelas particionadas, consulte esta página.