Especificar colunas aninhadas e repetidas em esquemas de tabelas
Nesta página, você verá como definir um esquema de tabela com colunas aninhadas e repetidas no BigQuery. Para ter uma visão geral dos esquemas de tabelas, consulte Como especificar um esquema.
Definir colunas aninhadas e repetidas
Para criar uma coluna com dados aninhados, defina o tipo de dados da coluna como
RECORD no esquema. Um RECORD pode ser acessado como um
tipo STRUCT
no GoogleSQL. Um STRUCT é um contêiner de campos ordenados.
Para criar uma coluna com dados repetidos, defina o
modo da coluna como REPEATED no esquema.
Um campo repetido pode ser acessado como um
tipo ARRAY no
GoogleSQL.
Uma coluna RECORD pode ter o modo REPEATED, que é representado como uma matriz de
tipos STRUCT. Além disso, um campo dentro de um registro pode ser repetido, que é
representado como um STRUCT que contém um ARRAY. Uma matriz não pode conter
outra matriz diretamente. Para mais informações, consulte
Como declarar um tipo ARRAY.
Limitações
Os esquemas aninhados e repetidos estão sujeitos às seguintes limitações:
- Um esquema não pode conter mais de 15 níveis de tipos de
RECORDaninhados. - Colunas do tipo
RECORDpodem conter tiposRECORDaninhados, também chamados de registros filhos. O limite máximo de profundidade aninhado é de 15 níveis. Esse limite não depende do fato que osRECORDs sejam escalares ou baseados em matrizes (repetidos).
O tipo de RECORD é incompatível com UNION, INTERSECT, EXCEPT DISTINCT e SELECT DISTINCT.
Esquema de exemplo
O exemplo a seguir exibe dados aninhados e repetidos de amostra. A tabela contém informações sobre pessoas. Ela consiste nos campos abaixo:
idfirst_namelast_namedob(data de nascimento)addresses(um campo aninhado e repetido)addresses.status(atual ou anterior)addresses.addressaddresses.cityaddresses.stateaddresses.zipaddresses.numberOfYears(anos no endereço)
O arquivo de dados JSON se parece com o seguinte exemplo. Observe que a coluna de endereços contém uma matriz de valores (indicada por [ ]). Os vários endereços na matriz são os dados repetidos. Os vários campos dentro de cada endereço são os dados aninhados.
{"id":"1","first_name":"John","last_name":"Doe","dob":"1968-01-22","addresses":[{"status":"current","address":"123 First Avenue","city":"Seattle","state":"WA","zip":"11111","numberOfYears":"1"},{"status":"previous","address":"456 Main Street","city":"Portland","state":"OR","zip":"22222","numberOfYears":"5"}]}
{"id":"2","first_name":"Jane","last_name":"Doe","dob":"1980-10-16","addresses":[{"status":"current","address":"789 Any Avenue","city":"New York","state":"NY","zip":"33333","numberOfYears":"2"},{"status":"previous","address":"321 Main Street","city":"Hoboken","state":"NJ","zip":"44444","numberOfYears":"3"}]}
O esquema dessa tabela se parece com o seguinte:
[ { "name": "id", "type": "STRING", "mode": "NULLABLE" }, { "name": "first_name", "type": "STRING", "mode": "NULLABLE" }, { "name": "last_name", "type": "STRING", "mode": "NULLABLE" }, { "name": "dob", "type": "DATE", "mode": "NULLABLE" }, { "name": "addresses", "type": "RECORD", "mode": "REPEATED", "fields": [ { "name": "status", "type": "STRING", "mode": "NULLABLE" }, { "name": "address", "type": "STRING", "mode": "NULLABLE" }, { "name": "city", "type": "STRING", "mode": "NULLABLE" }, { "name": "state", "type": "STRING", "mode": "NULLABLE" }, { "name": "zip", "type": "STRING", "mode": "NULLABLE" }, { "name": "numberOfYears", "type": "STRING", "mode": "NULLABLE" } ] } ]
Como especificar colunas aninhadas e repetidas no exemplo
Para criar uma nova tabela com as colunas aninhadas e repetidas anteriores, selecione uma das seguintes opções:
Console
Especifique a coluna addresses aninhada e repetida:
No console do Google Cloud , abra a página do BigQuery.
No painel Explorer, expanda o projeto e selecione um conjunto de dados.
No painel de detalhes, clique em Criar tabela.
Na página Criar tabela, especifique os seguintes detalhes:
- Em Origem, no campo Criar tabela de, selecione Tabela vazia.
Na seção Destino, especifique os seguintes campos:
- Em Conjunto de dados, selecione o conjunto de dados em que você quer criar a tabela.
- Em Tabela, insira o nome da tabela que você quer criar.
Em Esquema, clique em Adicionar campo e insira o seguinte esquema de tabela:
- Em Nome do campo, insira
addresses. - Em Tipo, selecione RECORD.
- Em Modo, escolha REPEATED.
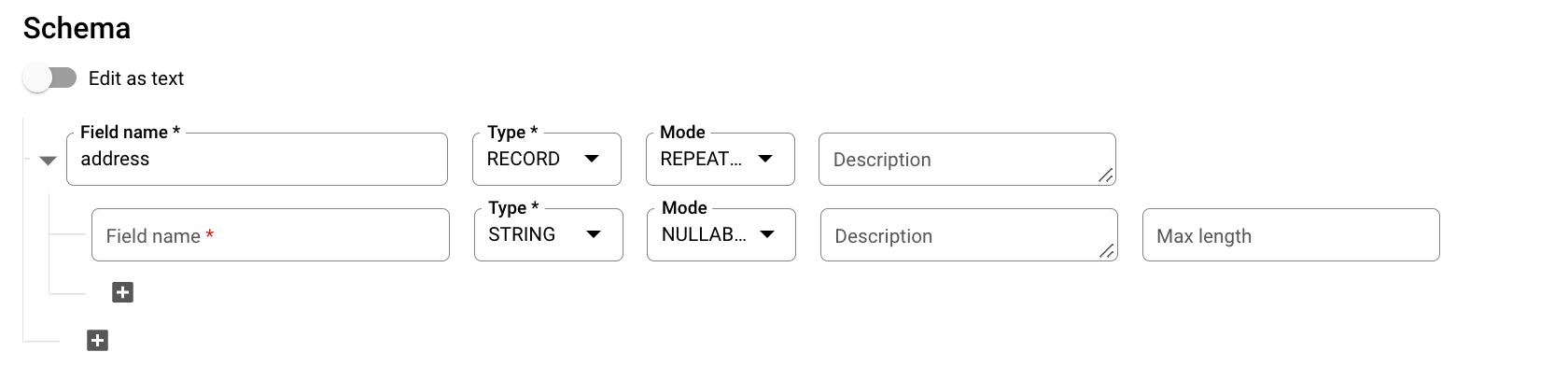
Especifique os seguintes campos para um campo aninhado:
- No campo Nome do campo, insira
status. - Em Tipo, escolha STRING.
- Em Modo, configure o valor como NULLABLE.
Clique em Adicionar campo para adicionar os seguintes campos:
Nome do campo Tipo Modo addressSTRINGNULLABLEcitySTRINGNULLABLEstateSTRINGNULLABLEzipSTRINGNULLABLEnumberOfYearsSTRINGNULLABLE
Se preferir, clique em Editar como texto e especifique o esquema como uma matriz JSON.
- No campo Nome do campo, insira
- Em Nome do campo, insira
SQL
Use a instrução CREATE TABLE.
Especifique o esquema usando a opção coluna.
No console Google Cloud , acesse a página BigQuery.
No editor de consultas, digite a seguinte instrução:
CREATE TABLE IF NOT EXISTS mydataset.mytable ( id STRING, first_name STRING, last_name STRING, dob DATE, addresses ARRAY< STRUCT< status STRING, address STRING, city STRING, state STRING, zip STRING, numberOfYears STRING>> ) OPTIONS ( description = 'Example name and addresses table');
Clique em Executar.
Para mais informações sobre como executar consultas, acesse Executar uma consulta interativa.
bq
Para especificar a coluna addresses aninhada e repetida em um arquivo de esquema JSON,
use um editor de texto para criar um novo arquivo. Cole a definição de esquema de
exemplo mostrada acima.
Depois de criar o arquivo de esquema JSON, forneça-o pela ferramenta de linha de comando bq. Para mais informações, consulte Como usar um arquivo de esquema JSON.
Go
Antes de testar esta amostra, siga as instruções de configuração do Go no Guia de início rápido do BigQuery: como usar bibliotecas de cliente. Para mais informações, consulte a documentação de referência da API BigQuery em Go.
Para autenticar no BigQuery, configure o Application Default Credentials. Para mais informações, acesse Configurar a autenticação para bibliotecas de cliente.
Java
Antes de testar esta amostra, siga as instruções de configuração do Java no Guia de início rápido do BigQuery: como usar bibliotecas de cliente. Para mais informações, consulte a documentação de referência da API BigQuery em Java.
Para autenticar no BigQuery, configure o Application Default Credentials. Para mais informações, acesse Configurar a autenticação para bibliotecas de cliente.
Node.js
Antes de testar esta amostra, siga as instruções de configuração do Node.js no Guia de início rápido do BigQuery: como usar bibliotecas de cliente. Para mais informações, consulte a documentação de referência da API BigQuery em Node.js.
Para autenticar no BigQuery, configure o Application Default Credentials. Para mais informações, acesse Configurar a autenticação para bibliotecas de cliente.
Python
Antes de testar esta amostra, siga as instruções de configuração do Python no Guia de início rápido do BigQuery: como usar bibliotecas de cliente. Para mais informações, consulte a documentação de referência da API BigQuery em Python.
Para autenticar no BigQuery, configure o Application Default Credentials. Para mais informações, acesse Configurar a autenticação para bibliotecas de cliente.
Inserir dados em colunas aninhadas no exemplo
Use as consultas a seguir para inserir registros de dados aninhados em tabelas que tenham colunas com tipo de dados RECORD.
Exemplo 1
INSERT INTO mydataset.mytable (id, first_name, last_name, dob, addresses) values ("1","Johnny","Dawn","1969-01-22", ARRAY< STRUCT< status STRING, address STRING, city STRING, state STRING, zip STRING, numberOfYears STRING>> [("current","123 First Avenue","Seattle","WA","11111","1")])
Exemplo 2
INSERT INTO mydataset.mytable (id, first_name, last_name, dob, addresses) values ("1","Johnny","Dawn","1969-01-22",[("current","123 First Avenue","Seattle","WA","11111","1")])
Consultar colunas aninhadas e repetidas
Para selecionar o valor de uma ARRAY em uma posição específica, use um operador de
subscrito da matriz.
Para acessar elementos em um STRUCT, use o
operador de ponto.
O exemplo a seguir seleciona o nome, o sobrenome e o primeiro endereço listados no campo addresses:
SELECT first_name, last_name, addresses[offset(0)].address FROM mydataset.mytable;
O resultado é o seguinte:
+------------+-----------+------------------+ | first_name | last_name | address | +------------+-----------+------------------+ | John | Doe | 123 First Avenue | | Jane | Doe | 789 Any Avenue | +------------+-----------+------------------+
Para extrair todos os elementos de um ARRAY, use o
operador UNNEST
com um CROSS JOIN.
O exemplo a seguir seleciona o nome, o sobrenome, o endereço e o estado de todos os endereços não localizados em Nova York:
SELECT first_name, last_name, a.address, a.state FROM mydataset.mytable CROSS JOIN UNNEST(addresses) AS a WHERE a.state != 'NY';
O resultado é o seguinte:
+------------+-----------+------------------+-------+ | first_name | last_name | address | state | +------------+-----------+------------------+-------+ | John | Doe | 123 First Avenue | WA | | John | Doe | 456 Main Street | OR | | Jane | Doe | 321 Main Street | NJ | +------------+-----------+------------------+-------+
Modificar colunas aninhadas e repetidas
Depois de adicionar uma coluna aninhada ou uma aninhada e repetida à definição de esquema de uma tabela, é possível modificá-la como qualquer outro tipo de coluna. O BigQuery é compatível nativamente com várias alterações de esquema, como adicionar um novo campo aninhado a um registro ou relaxar o modo de um campo aninhado. Para saber mais, consulte Como modificar os esquemas das tabelas.
Quando usar colunas aninhadas e repetidas
O BigQuery funciona melhor quando os dados são desnormalizados. Em vez de preservar um esquema relacional, como em estrela ou em floco de neve, desnormalize os dados e aproveite as colunas aninhadas e repetidas. Elas se relacionam sem o impacto sobre o desempenho da preservação de um esquema relacional ou normalizado.
Por exemplo, é provável que um banco de dados relacional usado para rastrear os livros de uma biblioteca mantenha todas as informações do autor em uma tabela separada. Uma chave como author_id seria usada para vincular o livro aos autores.
No BigQuery, é possível preservar a relação entre o livro e o autor sem criar uma tabela de autor separada. Na verdade, você cria uma coluna de autor e aninha os campos dentro dela como nome, sobrenome, data de nascimento e assim por diante. Se um livro tiver vários autores, será possível repetir essa coluna.
Suponha que você tenha a tabela mydataset.books a seguir:
+------------------+------------+-----------+ | title | author_ids | num_pages | +------------------+------------+-----------+ | Example Book One | [123, 789] | 487 | | Example Book Two | [456] | 89 | +------------------+------------+-----------+
Você também tem a tabela a seguir, mydataset.authors, com informações completas de cada ID de autor:
+-----------+-------------+---------------+ | author_id | author_name | date_of_birth | +-----------+-------------+---------------+ | 123 | Alex | 01-01-1960 | | 456 | Rosario | 01-01-1970 | | 789 | Kim | 01-01-1980 | +-----------+-------------+---------------+
Quando as tabelas são grandes, elas podem consumir muitos recursos regularmente. Dependendo da situação, pode ser vantajoso criar uma única tabela com todas as informações:
CREATE TABLE mydataset.denormalized_books( title STRING, authors ARRAY<STRUCT<id INT64, name STRING, date_of_birth STRING>>, num_pages INT64) AS ( SELECT title, ARRAY_AGG(STRUCT(author_id, author_name, date_of_birth)) AS authors, ANY_VALUE(num_pages) FROM mydataset.books, UNNEST(author_ids) id JOIN mydataset.authors ON id = author_id GROUP BY title );
A tabela terá esta aparência:
+------------------+-------------------------------+-----------+
| title | authors | num_pages |
+------------------+-------------------------------+-----------+
| Example Book One | [{123, Alex, 01-01-1960}, | 487 |
| | {789, Kim, 01-01-1980}] | |
| Example Book Two | [{456, Rosario, 01-01-1970}] | 89 |
+------------------+-------------------------------+-----------+
O BigQuery permite o carregamento de dados aninhados e repetidos a partir de formatos de origem que permitem esquemas baseados em objeto, como arquivos JSON, arquivos Avro e arquivos de exportação do Firestore e do Datastore.
Eliminar a duplicação de registros duplicados em uma tabela
A consulta a seguir usa a função row_number()
para identificar registros duplicados que têm os mesmos valores para
last_name e first_name nos exemplos usados e os classifica por dob:
CREATE OR REPLACE TABLE mydataset.mytable AS ( SELECT * except(row_num) FROM ( SELECT *, row_number() over (partition by last_name, first_name order by dob) row_num FROM mydataset.mytable) temp_table WHERE row_num=1 )
Segurança de tabelas
Para controlar o acesso a tabelas no BigQuery, consulte Controlar o acesso a recursos com o IAM.
A seguir
- Para inserir e atualizar linhas com colunas aninhadas e repetidas, consulte Sintaxe da linguagem de manipulação de dados.