Migrazione da Snowflake a BigQuery: panoramica
Questo documento mostra come eseguire la migrazione dei dati da Snowflake a BigQuery.
Per un framework generale per la migrazione da altri data warehouse a BigQuery, consulta Panoramica: eseguire la migrazione dei data warehouse in BigQuery.
Panoramica della migrazione da Snowflake a BigQuery
Per una migrazione Snowflake, ti consigliamo di configurare un'architettura di migrazione che influisca in modo minimo sulle operazioni esistenti. L'esempio seguente mostra un'architettura in cui puoi riutilizzare gli strumenti e i processi esistenti scaricando altri carichi di lavoro in BigQuery.
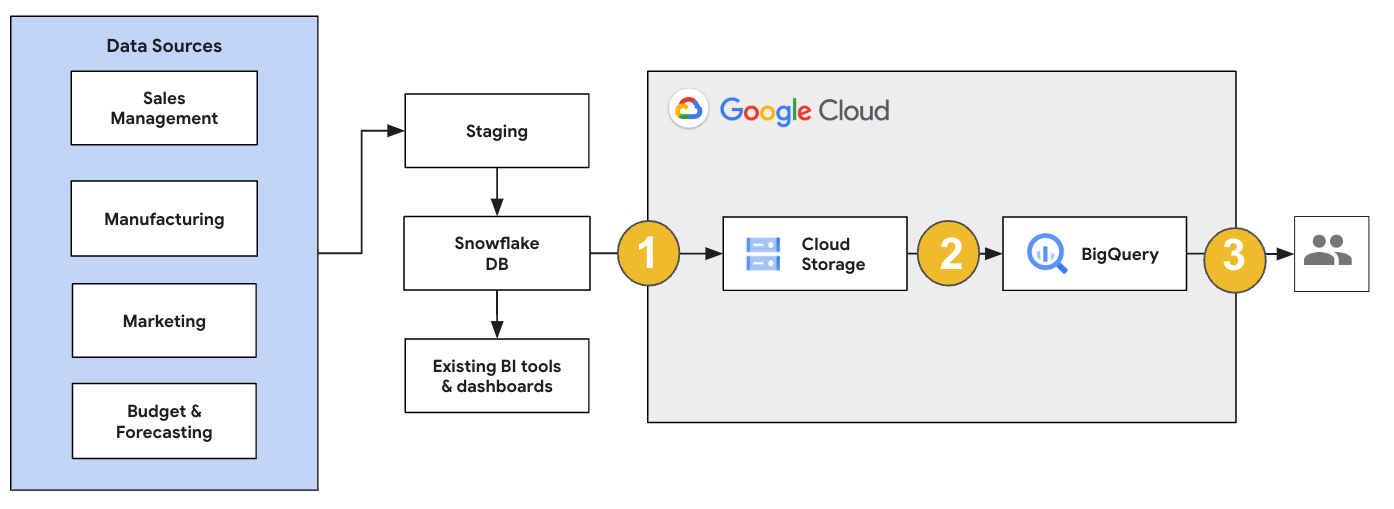
Puoi anche convalidare report e dashboard rispetto alle versioni precedenti. Per ulteriori informazioni, consulta Migrazione dei data warehouse a BigQuery: verifica e convalida.
Eseguire la migrazione di singoli carichi di lavoro
Quando pianifichi la migrazione di Snowflake, ti consigliamo di eseguire la migrazione dei seguenti workload singolarmente nel seguente ordine:
Migrazione dello schema
Inizia replicando gli schemi necessari dall'ambiente Snowflake in BigQuery. Ti consigliamo di utilizzare BigQuery Migration Service per eseguire la migrazione dello schema. BigQuery Migration Service supporta un'ampia gamma di pattern di progettazione di modello dei dati, come lo schema a stella o lo schema a fiocco di neve, il che elimina la necessità di aggiornare le pipeline di dati upstream per un nuovo schema. BigQuery Migration Service offre anche la migrazione automatica dello schema, incluse le funzionalità di estrazione e traduzione dello schema, per semplificare il processo di migrazione.
Esegui la migrazione delle query SQL
Per eseguire la migrazione delle query SQL, BigQuery Migration Service offre varie funzionalità di traduzione SQL per automatizzare la conversione delle query SQL Snowflake in SQL GoogleSQL, ad esempio il traduttore SQL batch per tradurre le query in blocco, il traduttore SQL interattivo per tradurre le singole query e l'API di traduzione SQL. Questi servizi di traduzione includono anche funzionalità avanzate di Gemini per semplificare ulteriormente il processo di migrazione delle query SQL.
Quando traduci le query SQL, esamina attentamente le query tradotte per verificare che i tipi di dati e le strutture delle tabelle siano gestiti correttamente. A questo scopo, ti consigliamo di creare un'ampia gamma di scenari di test con dati diversi. Poi esegui questi scenari di test su BigQuery per confrontare i risultati con quelli originali di Snowflake. Se ci sono differenze, analizza e correggi le query convertite.
Migrazione dei dati
Esistono diversi modi per configurare la pipeline di migrazione dei dati per trasferirli a BigQuery. In genere, queste pipeline seguono lo stesso pattern:
Estrai i dati dall'origine:copia i file estratti dall'origine nell'area di staging nell'ambiente on-premise. Per ulteriori informazioni, consulta Migrazione dei data warehouse a BigQuery: estrazione dei dati di origine.
Trasferisci i dati a un bucket Cloud Storage gestione temporanea: dopo aver terminato l'estrazione dei dati dall'origine, trasferiscili a un bucket gestione temporanea in Cloud Storage. A seconda della quantità di dati che stai trasferendo e della larghezza di banda di rete disponibile, hai diverse opzioni.
È importante verificare che la posizione del set di dati BigQuery e dell'origine dati esterna o del bucket Cloud Storage si trovino nella stessa regione.
Carica i dati dal bucket Cloud Storage in BigQuery: i dati si trovano ora in un bucket Cloud Storage. Esistono diverse opzioni per caricare i dati in BigQuery. Queste opzioni dipendono dalla quantità di trasformazione necessaria per i dati. In alternativa, puoi trasformare i dati in BigQuery seguendo l'approccio ELT.
Quando importi i dati in blocco da un file JSON, un file Avro o un file CSV, BigQuery rileva automaticamente lo schema, quindi non devi predefinirlo. Per una panoramica dettagliata del processo di migrazione dello schema per i workload EDW, consulta Processo di migrazione di schema e dati.
Per un elenco degli strumenti che supportano la migrazione dei dati Snowflake, vedi Strumenti di migrazione.
Per esempi end-to-end di configurazione di una pipeline di migrazione dei dati Snowflake, consulta Esempi di pipeline di migrazione Snowflake.
Ottimizzare lo schema e le query
Dopo la migrazione dello schema, puoi testare il rendimento e apportare ottimizzazioni in base ai risultati. Ad esempio, puoi introdurre il partizionamento per rendere più efficiente la gestione e l'esecuzione di query sui tuoi dati. Il partizionamento delle tabelle ti consente di migliorare le prestazioni delle query e il controllo dei costi eseguendo il partizionamento in base all'ora di importazione, al timestamp o all'intervallo di numeri interi. Per ulteriori informazioni, consulta Introduzione alle tabelle partizionate.
Le tabelle in cluster sono un'altra ottimizzazione dello schema. Puoi raggruppare le tabelle per organizzare i dati della tabella in base ai contenuti dello schema della tabella, migliorando le prestazioni delle query che utilizzano clausole di filtro o che aggregano dati. Per ulteriori informazioni, consulta Introduzione alle tabelle in cluster.
Tipi di dati, proprietà e formati di file supportati
Snowflake e BigQuery supportano la maggior parte degli stessi tipi di dati, anche se a volte utilizzano nomi diversi. Per un elenco completo dei tipi di dati supportati in Snowflake e BigQuery, consulta Tipi di dati. Puoi anche utilizzare strumenti di traduzione SQL, come il traduttore SQL interattivo, l'API di traduzione SQL o il traduttore SQL batch, per tradurre diversi dialetti SQL in GoogleSQL.
Per ulteriori informazioni sui tipi di dati supportati in BigQuery, consulta la pagina Tipi di dati GoogleSQL.
Snowflake può esportare i dati nei seguenti formati di file. Puoi caricare i seguenti formati direttamente in BigQuery:
- Caricamento dei dati CSV da Cloud Storage.
- Caricamento dei dati Parquet da Cloud Storage.
- Caricamento dei dati JSON da Cloud Storage.
- Esegui query sui dati da Apache Iceberg.
Strumenti di migrazione
Il seguente elenco descrive gli strumenti che puoi utilizzare per eseguire la migrazione dei dati da Snowflake a BigQuery. Per esempi di come questi strumenti possono essere utilizzati insieme in una pipeline di migrazione Snowflake, consulta Esempi di pipeline di migrazione Snowflake.
- Comando
COPY INTO <location>: utilizza questo comando in Snowflake per estrarre i dati da una tabella Snowflake direttamente in un bucket Cloud Storage specificato. Per un esempio end-to-end, consulta Snowflake to BigQuery (snowflake2bq) su GitHub. - Apache Sqoop: Per estrarre i dati da Snowflake in HDFS o Cloud Storage, invia job Hadoop con il driver JDBC da Sqoop e Snowflake. Sqoop viene eseguito in un ambiente Dataproc.
- Snowflake JDBC: Utilizza questo driver con la maggior parte degli strumenti o delle applicazioni client che supportano JDBC.
Puoi utilizzare i seguenti strumenti generici per eseguire la migrazione dei dati da Snowflake a BigQuery:
- Connettore BigQuery Data Transfer Service per Snowflake Anteprima: esegui un trasferimento batch automatizzato dei dati di Cloud Storage in BigQuery.
- Google Cloud CLI:copia i file Snowflake scaricati in Cloud Storage con questo strumento a riga di comando.
- Strumento a riga di comando bq: interagisci con BigQuery utilizzando questo strumento a riga di comando. I casi d'uso comuni includono la creazione di schemi di tabelle BigQuery, il caricamento di dati Cloud Storage nelle tabelle e l'esecuzione di query.
- Librerie client di Cloud Storage: copia i file Snowflake scaricati in Cloud Storage con uno strumento personalizzato che utilizza le librerie client di Cloud Storage.
- Librerie client di BigQuery: interagisci con BigQuery con uno strumento personalizzato basato sulla libreria client di BigQuery.
- Utilità di pianificazione delle query BigQuery: pianifica query SQL ricorrenti con questa funzionalità integrata di BigQuery.
- Cloud Composer: utilizza questo ambiente Apache Airflow completamente gestito per orchestrare i job di caricamento e le trasformazioni BigQuery.
Per ulteriori informazioni sul caricamento dei dati in BigQuery, vedi Caricamento di dati in BigQuery.
Esempi di pipeline di migrazione Snowflake
Le sezioni seguenti mostrano esempi di come eseguire la migrazione dei dati da Snowflake a BigQuery utilizzando tre processi diversi: ELT, ETL e strumenti partner.
Estrai, carica e trasforma
Puoi configurare un processo di estrazione, caricamento e trasformazione (ELT) con due metodi:
- Utilizza una pipeline per estrarre i dati da Snowflake e caricarli in BigQuery
- Estrai i dati da Snowflake utilizzando altri Google Cloud prodotti.
Utilizzare una pipeline per estrarre i dati da Snowflake
Per estrarre i dati da Snowflake e caricarli direttamente in Cloud Storage, utilizza lo strumento snowflake2bq.
Puoi quindi caricare i dati da Cloud Storage a BigQuery utilizzando uno dei seguenti strumenti:
- Il connettore BigQuery Data Transfer Service per Cloud Storage
- Il comando
LOADutilizzando lo strumento a riga di comando bq - Librerie client API BigQuery
Altri strumenti per estrarre dati da Snowflake
Puoi anche utilizzare i seguenti strumenti per estrarre i dati da Snowflake:
- Dataflow
- Cloud Data Fusion
- Dataproc
- Connettore BigQuery Apache Spark
- Connettore Snowflake per Apache Spark
- Connettore Hadoop BigQuery
- Il driver JDBC di Snowflake e Sqoop per estrarre i dati da Snowflake in Cloud Storage:
Altri strumenti per caricare dati in BigQuery
Puoi anche utilizzare i seguenti strumenti per caricare i dati in BigQuery:
- Dataflow
- Cloud Data Fusion
- Dataproc
- Dataprep di Trifacta
Estrazione, trasformazione e caricamento
Se vuoi trasformare i dati prima di caricarli in BigQuery, prendi in considerazione i seguenti strumenti:
- Dataflow
- Clona il codice del modello JDBC to BigQuery e modificalo per aggiungere trasformazioni Apache Beam.
- Cloud Data Fusion
- Crea una pipeline riutilizzabile e trasforma i dati utilizzando i plug-in CDAP.
- Dataproc
- Trasforma i dati utilizzando Spark SQL o codice personalizzato in uno dei linguaggi Spark supportati, come Scala, Java, Python o R.
Strumenti dei partner per la migrazione
Esistono più fornitori specializzati nello spazio di migrazione EDW. Per un elenco dei partner principali e delle soluzioni fornite, consulta Partner BigQuery.
Tutorial sull'esportazione di Snowflake
Il seguente tutorial mostra un'esportazione di dati di esempio da Snowflake a BigQuery che utilizza il comando COPY INTO <location> Snowflake.
Per una procedura dettagliata passo passo che include esempi di codice, consulta
lo strumento di servizi professionali per la migrazione da Snowflake a BigQuery.Google Cloud
Prepararsi per l'esportazione
Puoi preparare i dati Snowflake per l'esportazione estraendoli in un bucket Cloud Storage o Amazon Simple Storage Service (Amazon S3) seguendo questi passaggi:
Cloud Storage
Questo tutorial prepara il file in formato PARQUET.
Utilizza le istruzioni SQL di Snowflake per creare una specifica del formato di file denominato.
create or replace file format NAMED_FILE_FORMAT type = 'PARQUET'
Sostituisci
NAMED_FILE_FORMATcon un nome per il formato del file. Ad esempio,my_parquet_unload_format.Crea un'integrazione con il comando
CREATE STORAGE INTEGRATION.create storage integration INTEGRATION_NAME type = external_stage storage_provider = gcs enabled = true storage_allowed_locations = ('BUCKET_NAME')
Sostituisci quanto segue:
INTEGRATION_NAME: un nome per l'integrazione dell'archiviazione. Ad esempio,gcs_intBUCKET_NAME: il percorso del bucket Cloud Storage. Ad esempio,gcs://mybucket/extract/
Recupera il account di servizio Cloud Storage per Snowflake con il comando
DESCRIBE INTEGRATION.desc storage integration INTEGRATION_NAME;
L'output è simile al seguente:
+-----------------------------+---------------+-----------------------------------------------------------------------------+------------------+ | property | property_type | property_value | property_default | +-----------------------------+---------------+-----------------------------------------------------------------------------+------------------| | ENABLED | Boolean | true | false | | STORAGE_ALLOWED_LOCATIONS | List | gcs://mybucket1/path1/,gcs://mybucket2/path2/ | [] | | STORAGE_BLOCKED_LOCATIONS | List | gcs://mybucket1/path1/sensitivedata/,gcs://mybucket2/path2/sensitivedata/ | [] | | STORAGE_GCP_SERVICE_ACCOUNT | String | service-account-id@iam.gserviceaccount.com | | +-----------------------------+---------------+-----------------------------------------------------------------------------+------------------+
Concedi all'account di servizio elencato come
STORAGE_GCP_SERVICE_ACCOUNTl'accesso in lettura e scrittura al bucket specificato nel comando di integrazione dell'archiviazione. In questo esempio, concedi all'account di servizioservice-account-id@l'accesso in lettura e scrittura al bucket<var>UNLOAD_BUCKET</var>.Crea uno stage Cloud Storage esterno che faccia riferimento all'integrazione che hai creato in precedenza.
create or replace stage STAGE_NAME url='UNLOAD_BUCKET' storage_integration = INTEGRATION_NAME file_format = NAMED_FILE_FORMAT;
Sostituisci quanto segue:
STAGE_NAME: un nome per l'oggetto di staging Cloud Storage. Ad esempio,my_ext_unload_stage
Amazon S3
L'esempio seguente mostra come spostare i dati da una tabella Snowflake a un bucket Amazon S3:
In Snowflake, configura un oggetto di integrazione dell'archiviazione per consentire a Snowflake di scrivere in un bucket Amazon S3 a cui viene fatto riferimento in una fase Cloud Storage esterna.
Questo passaggio prevede la configurazione delle autorizzazioni di accesso al bucket Amazon S3, creazione del ruolo AWS IAM e la creazione di un'integrazione di archiviazione in Snowflake con il comando
CREATE STORAGE INTEGRATION:create storage integration INTEGRATION_NAME type = external_stage storage_provider = s3 enabled = true storage_aws_role_arn = 'arn:aws:iam::001234567890:role/myrole' storage_allowed_locations = ('BUCKET_NAME')
Sostituisci quanto segue:
INTEGRATION_NAME: un nome per l'integrazione dell'archiviazione. Ad esempio,s3_intBUCKET_NAME: il percorso del bucket Amazon S3 in cui caricare i file. Ad esempio,s3://unload/files/
Recupera l'utente IAM AWS con il comando
DESCRIBE INTEGRATION.desc integration INTEGRATION_NAME;
L'output è simile al seguente:
+---------------------------+---------------+================================================================================+------------------+ | property | property_type | property_value | property_default | +---------------------------+---------------+================================================================================+------------------| | ENABLED | Boolean | true | false | | STORAGE_ALLOWED_LOCATIONS | List | s3://mybucket1/mypath1/,s3://mybucket2/mypath2/ | [] | | STORAGE_BLOCKED_LOCATIONS | List | s3://mybucket1/mypath1/sensitivedata/,s3://mybucket2/mypath2/sensitivedata/ | [] | | STORAGE_AWS_IAM_USER_ARN | String | arn:aws:iam::123456789001:user/abc1-b-self1234 | | | STORAGE_AWS_ROLE_ARN | String | arn:aws:iam::001234567890:role/myrole | | | STORAGE_AWS_EXTERNAL_ID | String | MYACCOUNT_SFCRole=
| | +---------------------------+---------------+================================================================================+------------------+ Crea un ruolo con il privilegio
CREATE STAGEper lo schema e il privilegioUSAGEper l'integrazione dell'archiviazione:CREATE role ROLE_NAME; GRANT CREATE STAGE ON SCHEMA public TO ROLE ROLE_NAME; GRANT USAGE ON INTEGRATION s3_int TO ROLE ROLE_NAME;
Sostituisci
ROLE_NAMEcon un nome per il ruolo. Ad esempio,myrole.Concedi all'utente IAM AWS le autorizzazioni per accedere al bucket Amazon S3 e crea uno stage esterno con il comando
CREATE STAGE:USE SCHEMA mydb.public; create or replace stage STAGE_NAME url='BUCKET_NAME' storage_integration = INTEGRATION_NAMEt file_format = NAMED_FILE_FORMAT;
Sostituisci quanto segue:
STAGE_NAME: un nome per l'oggetto di staging Cloud Storage. Ad esempio,my_ext_unload_stage
Esportare i dati di Snowflake
Dopo aver preparato i dati, puoi spostarli su Google Cloud.
Utilizza il comando COPY INTO per copiare i dati dalla tabella del database Snowflake in un bucket Cloud Storage o Amazon S3 specificando l'oggetto di staging esterno, STAGE_NAME.
copy into @STAGE_NAME/d1 from TABLE_NAME;
Sostituisci TABLE_NAME con il nome della tabella del database Snowflake.
Come risultato di questo comando, i dati della tabella vengono copiati nell'oggetto di staging, che è collegato al bucket Cloud Storage o Amazon S3. Il file include il prefisso d1.
Altri metodi di esportazione
Per utilizzare Azure Blob Storage per le esportazioni di dati, segui i passaggi descritti in Scaricamento in Microsoft Azure. Poi, trasferisci i file esportati in Cloud Storage utilizzando Storage Transfer Service.
Prezzi
Quando pianifichi la migrazione di Snowflake, considera il costo del trasferimento dei dati, dell'archiviazione dei dati e dell'utilizzo dei servizi in BigQuery. Per ulteriori informazioni, vedi Prezzi.
Potrebbero essere addebitati costi per il traffico in uscita per lo spostamento dei dati da Snowflake o AWS. Potrebbero essere previsti costi aggiuntivi anche per il trasferimento di dati tra regioni o tra diversi cloud provider.
Passaggi successivi
- Rendimento e ottimizzazione post-migrazione.