Introduzione alle tabelle partizionate
Una tabella partizionata è divisa in segmenti, denominati partizioni, che semplificano la gestione e l'interrogazione dei dati. Dividendo una tabella grande in partizioni più piccole, puoi migliorare le prestazioni delle query e controllare i costi riducendo il numero di byte letti da una query. Per partizionare le tabelle, specifica una colonna di partizionamento utilizzata per segmentare la tabella.
Se una query utilizza un filtro idoneo sul valore della colonna di partizionamento, BigQuery può analizzare le partizioni che corrispondono al filtro e saltare quelle rimanenti. Questo processo è chiamato potatura.
In una tabella partizionata, i dati vengono archiviati in blocchi fisici, ognuno dei quali contiene una partizione di dati. Ogni tabella partizionata mantiene vari metadati sulle proprietà di ordinamento in tutte le operazioni che la modificano. I metadati consentono a BigQuery di stimare con maggiore precisione il costo di una query prima che venga eseguita.
Quando utilizzare il partizionamento
Valuta la possibilità di partizionare una tabella nei seguenti scenari:
- Vuoi migliorare le prestazioni delle query eseguendo la scansione solo di una parte di una tabella.
- L'operazione sulla tabella supera una quota di tabella standard e puoi limitare le operazioni sulla tabella a valori specifici della colonna di partizione, consentendo quote di tabella partizionata più elevate.
- Vuoi determinare i costi delle query prima che vengano eseguite. BigQuery fornisce stime dei costi delle query prima che vengano eseguite su una tabella partizionata. Calcola una stima del costo di una query eliminando una tabella partizionata, quindi esegui un test dry run della query per stimare i costi della query.
- Vuoi una delle seguenti funzionalità di gestione a livello di partizione:
- Imposta una durata di scadenza della partizione per eliminare automaticamente intere partizioni dopo un periodo di tempo specificato.
- Scrivi dati in una partizione specifica utilizzando i job di caricamento senza influire sulle altre partizioni della tabella.
- Elimina partizioni specifiche senza scansionare l'intera tabella.
Valuta la possibilità di raggruppare una tabella anziché partizionarla nelle seguenti circostanze:
- Hai bisogno di una granularità maggiore di quella consentita dal partizionamento.
- Le tue query utilizzano spesso filtri o aggregazioni su più colonne.
- La cardinalità del numero di valori in una colonna o in un gruppo di colonne è elevata.
- Non hai bisogno di stime dei costi rigorose prima dell'esecuzione della query.
- Il partizionamento genera una piccola quantità di dati per partizione (circa meno di 10 GB). La creazione di molte piccole partizioni aumenta i metadati della tabella e può influire sui tempi di accesso ai metadati durante l'esecuzione di query sulla tabella.
- La partizionamento genera un numero elevato di partizioni, superando i limiti per le tabelle partizionate.
- Le operazioni DML modificano spesso (ad esempio, ogni pochi minuti) la maggior parte delle partizioni della tabella.
In questi casi, il clustering delle tabelle consente di accelerare le query raggruppando i dati in colonne specifiche in base alle proprietà di ordinamento definite dall'utente.
Puoi anche combinare il clustering e il partizionamento delle tabelle per ottenere un ordinamento più granulare. Per saperne di più su questo approccio, consulta Combinazione di tabelle in cluster e partizionate.
Tipi di partizionamento
Questa sezione descrive i diversi modi per partizionare una tabella.
Partizionamento per intervalli di numeri interi
Puoi partizionare una tabella in base a intervalli di valori in una colonna INTEGER specifica. Per creare una tabella partizionata con intervallo di numeri interi, devi fornire:
- La colonna di partizionamento.
- Il valore iniziale per il partizionamento degli intervalli (incluso).
- Il valore finale per il partizionamento degli intervalli (esclusivo).
- L'intervallo di ogni intervallo all'interno della partizione.
Ad esempio, supponi di creare una partizione di intervallo di numeri interi con la seguente specifica:
| Argomento | Valore |
|---|---|
| nome colonna | customer_id |
| start | 0 |
| end | 100 |
| intervallo | 10 |
La tabella è partizionata in base alla colonna customer_id in intervalli di 10.
I valori da 0 a 9 vanno in una partizione, i valori da 10 a 19 vanno nella partizione successiva e così via fino a 99. I valori che non rientrano in questo intervallo vengono inseriti in una partizione
denominata __UNPARTITIONED__. Tutte le righe in cui customer_id è NULL vengono inserite in una
partizione denominata __NULL__.
Per informazioni sulle tabelle partizionate con intervallo di numeri interi, vedi Creare una tabella partizionata con intervallo di numeri interi.
Partizionamento delle colonne di unità di tempo
Puoi partizionare una tabella in base a una colonna DATE,TIMESTAMP o DATETIME nella
tabella. Quando scrivi i dati nella tabella, BigQuery li inserisce automaticamente nella partizione corretta, in base ai valori della colonna.
Per le colonne TIMESTAMP e DATETIME, le partizioni possono avere una granularità oraria,
giornaliera, mensile o annuale. Per le colonne DATE, le partizioni possono
avere granularità giornaliera, mensile o annuale. I limiti delle partizioni si basano sull'ora UTC.
Ad esempio, supponiamo di partizionare una tabella in base a una colonna DATETIME con
partizionamento mensile. Se inserisci i seguenti valori nella tabella, le righe vengono scritte nelle seguenti partizioni:
| Valore colonna | Partizione (mensile) |
|---|---|
DATETIME("2019-01-01") |
201901 |
DATETIME("2019-01-15") |
201901 |
DATETIME("2019-04-30") |
201904 |
Inoltre, vengono create due partizioni speciali:
__NULL__: contiene righe con valoriNULLnella colonna di partizionamento.__UNPARTITIONED__: contiene righe in cui il valore della colonna di partizionamento è precedente al 01/01/1960 o successivo al 31/12/2159.
Per informazioni sulle tabelle partizionate per colonne di unità di tempo, vedi Creare una tabella partizionata per colonne di unità di tempo.
Partizionamento per tempo di importazione
Quando crei una tabella partizionata per data di importazione, BigQuery assegna automaticamente le righe alle partizioni in base all'ora in cui BigQuery importa i dati. Puoi scegliere una granularità oraria, giornaliera, mensile o annuale per le partizioni. I limiti delle partizioni si basano sull'ora UTC.
Se i tuoi dati potrebbero raggiungere il numero massimo di partizioni per tabella quando utilizzi una granularità temporale più precisa, utilizza una granularità più grossolana. Ad esempio, puoi partizionare per mese anziché per giorno per ridurre il numero di partizioni. Puoi anche raggruppare la colonna della partizione per migliorare ulteriormente il rendimento.
Una tabella partizionata per data di importazione ha una pseudocolonna denominata _PARTITIONTIME.
Il valore di questa colonna è l'ora di importazione per ogni riga, troncata al
limite della partizione (ad esempio orario o giornaliero). Ad esempio, supponiamo di
creare una tabella partizionata per data di importazione con partizionamento orario e di inviare
i dati nei seguenti orari:
| Data di importazione | _PARTITIONTIME |
Partizione (oraria) |
|---|---|---|
| 2021-05-07 17:22:00 | 2021-05-07 17:00:00 | 2021050717 |
| 2021-05-07 17:40:00 | 2021-05-07 17:00:00 | 2021050717 |
| 2021-05-07 18:31:00 | 2021-05-07 18:00:00 | 2021050718 |
Poiché la tabella in questo esempio utilizza il partizionamento orario, il valore di
_PARTITIONTIME viene troncato a un limite orario. BigQuery
utilizza questo valore per determinare la partizione corretta per i dati.
Puoi anche scrivere dati in una partizione specifica. Ad esempio, potresti voler caricare dati storici o apportare modifiche per i fusi orari. Puoi utilizzare qualsiasi data valida compresa tra il 01/01/0001 e il 31/12/9999. Tuttavia, le istruzioni DML non possono fare riferimento a date precedenti al 1° gennaio 1970 o successive al 31 dicembre 2159. Per saperne di più, consulta Scrivere dati in una partizione specifica.
Anziché utilizzare _PARTITIONTIME, puoi anche utilizzare
_PARTITIONDATE.
La pseudo-colonna _PARTITIONDATE contiene la data UTC corrispondente al valore
nella pseudo-colonna _PARTITIONTIME.
Seleziona il partizionamento giornaliero, orario, mensile o annuale
Quando partizioni una tabella in base alla colonna dell'unità di tempo o all'ora di importazione, scegli se le partizioni hanno una granularità giornaliera, oraria, mensile o annuale.
Il partizionamento giornaliero è il tipo di partizionamento predefinito. Il partizionamento giornaliero è una buona scelta quando i dati sono distribuiti su un ampio intervallo di date o se vengono aggiunti continuamente nel tempo.
Scegli la partizione oraria se le tue tabelle contengono un volume elevato di dati che coprono un breve intervallo di date, in genere meno di sei mesi di valori timestamp. Se scegli il partizionamento orario, assicurati che il conteggio delle partizioni rientri nei limiti di partizionamento.
Scegli la partizionamento mensile o annuale se le tue tabelle contengono una quantità di dati relativamente ridotta per ogni giorno, ma coprono un ampio intervallo di date. Questa opzione è consigliata anche se il tuo flusso di lavoro richiede l'aggiornamento o l'aggiunta frequente di righe che coprono un ampio intervallo di date (ad esempio più di 500 date). In questi scenari, utilizza il partizionamento mensile o annuale insieme al clustering nella colonna di partizionamento per ottenere il rendimento migliore. Per ulteriori informazioni, consulta Combinazione di tabelle in cluster e partizionate in questo documento.
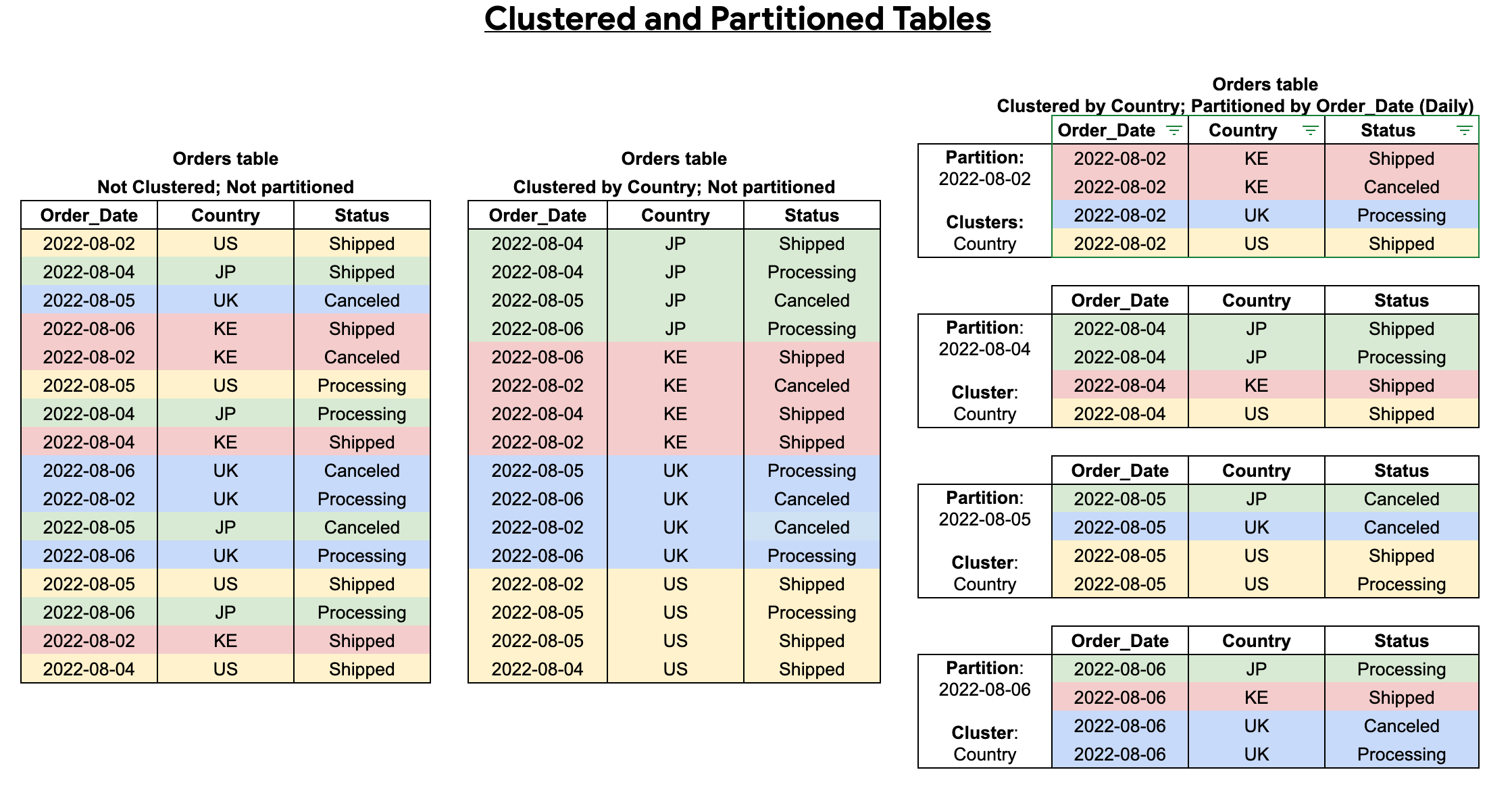
Combinare tabelle in cluster e partizionate
Puoi combinare il partizionamento delle tabelle con il clustering delle tabelle per ottenere un ordinamento granulare per un'ulteriore ottimizzazione delle query.
Una tabella in cluster contiene colonne in cluster che ordinano i dati in base alle proprietà di ordinamento definite dall'utente. I dati all'interno di queste colonne in cluster vengono ordinati in blocchi di archiviazione di dimensioni adattive in base alle dimensioni della tabella. Quando esegui una query che filtra in base alla colonna in cluster, BigQuery analizza solo i blocchi pertinenti in base alle colonne in cluster anziché l'intera tabella o partizione di tabella. In un approccio combinato che utilizza sia il partizionamento che il clustering delle tabelle, segmenti innanzitutto i dati della tabella in partizioni, poi raggruppi in cluster i dati all'interno di ogni partizione in base alle colonne di clustering.
Quando crei una tabella sottoposta a clustering e partizionamento, puoi ottenere un ordinamento più granulare, come mostrato nel seguente diagramma:
Partizionamento e sharding
Lo sharding delle tabelle è la pratica di archiviare i dati in più tabelle utilizzando un
prefisso di denominazione come [PREFIX]_YYYYMMDD.
Il partizionamento è consigliato rispetto allo sharding delle tabelle perché le tabelle partizionate hanno un rendimento migliore. Con le tabelle suddivise, BigQuery deve mantenere una copia dello schema e dei metadati per ogni tabella. BigQuery potrebbe anche dover verificare le autorizzazioni per ogni tabella sottoposta a query. Questa pratica aumenta anche l'overhead delle query e influisce sulle prestazioni delle query.
Se in precedenza hai creato tabelle con partizionamento per data, puoi convertirle in una tabella partizionata per data di importazione. Per ulteriori informazioni, consulta Convertire le tabelle suddivise per data in tabelle partizionate in base all'ora di importazione.
Decorator per partizioni
I decoratori di partizione ti consentono di fare riferimento a una partizione in una tabella. Ad esempio, puoi utilizzarli per scrivere dati in una partizione specifica.
Un decoratore di partizione ha la forma table_name$partition_id, dove il formato
del segmento partition_id dipende dal tipo di partizionamento:
| Tipo di partizionamento | Formato | Esempio |
|---|---|---|
| Ogni ora | yyyymmddhh |
my_table$2021071205 |
| Ogni giorno | yyyymmdd |
my_table$20210712 |
| Mensile | yyyymm |
my_table$202107 |
| Annuale | yyyy |
my_table$2021 |
| Intervallo di numeri interi | range_start |
my_table$40 |
Sfogliare i dati in una partizione
Per sfogliare i dati in una partizione specificata, utilizza il
comando bq head con un
decoratore di partizione.
Ad esempio, il seguente comando elenca tutti i campi nelle prime 10 righe di
my_dataset.my_table nella partizione 2018-02-24:
bq head --max_rows=10 'my_dataset.my_table$20180224'
Esportare i dati delle tabelle
L'esportazione di tutti i dati da una tabella partizionata è la stessa procedura di esportazione dei dati da una tabella non partizionata. Per ulteriori informazioni, vedi Esportazione dei dati delle tabelle.
Per esportare i dati da una singola partizione, utilizza il comando bq extract e aggiungi il decoratore della partizione al nome della tabella. Ad esempio, my_table$20160201. Puoi anche esportare i dati dalle partizioni
__NULL__ e __UNPARTITIONED__
aggiungendo i nomi delle partizioni al nome della tabella. Ad esempio,
my_table$__NULL__ o my_table$__UNPARTITIONED__.
Limitazioni
Le tabelle partizionate presentano le seguenti limitazioni:
Non puoi utilizzare SQL precedente per eseguire query sulle tabelle partizionate o per scrivere i risultati delle query nelle tabelle partizionate.
BigQuery non supporta il partizionamento in base a più colonne. È possibile utilizzare una sola colonna per partizionare una tabella.
Non puoi convertire direttamente una tabella non partizionata esistente in una tabella partizionata. La strategia di partizionamento viene definita al momento della creazione della tabella. Utilizza invece l'istruzione
CREATE TABLEper creare una nuova tabella partizionata eseguendo query sui dati nella tabella esistente.Le tabelle partizionate per colonne di unità di tempo sono soggette alle seguenti limitazioni:
- La colonna di partizionamento deve essere una colonna scalare
DATE,TIMESTAMPoDATETIME. La modalità della colonna può essereREQUIREDoNULLABLE, ma non può essereREPEATED(basata su array). - La colonna di partizionamento deve essere un campo di primo livello. Non puoi utilizzare un campo foglia
di un
RECORD(STRUCT) come colonna di partizionamento.
Per informazioni sulle tabelle partizionate per colonne di unità di tempo, vedi Creare una tabella partizionata per colonne di unità di tempo.
- La colonna di partizionamento deve essere una colonna scalare
Le tabelle partizionate in base all'intervallo di numeri interi sono soggette alle seguenti limitazioni:
- La colonna di partizionamento deve essere una colonna
INTEGER. Anche se la modalità della colonna può essereREQUIREDoNULLABLE, non può essereREPEATED(basata su array). - La colonna di partizionamento deve essere un campo di primo livello. Non puoi utilizzare un campo foglia
di un
RECORD(STRUCT) come colonna di partizionamento.
Per informazioni sulle tabelle partizionate con intervallo di numeri interi, vedi Creare una tabella partizionata con intervallo di numeri interi.
- La colonna di partizionamento deve essere una colonna
Quote e limiti
Le tabelle partizionate hanno limiti definiti in BigQuery.
Quote e limiti si applicano anche ai diversi tipi di job che puoi eseguire sulle tabelle partizionate, tra cui:
- Caricamento dei dati (caricamento dei job)
- Esportazione dei dati (job di esportazione)
- Esecuzione di query sui dati (job di query)
- Copia delle tabelle (job di copia)
Per ulteriori informazioni su tutte le quote e i limiti, consulta Quote e limiti.
Prezzi delle tabelle
Quando crei e utilizzi tabelle partizionate in BigQuery, i tuoi addebiti dipendono dalla quantità di dati archiviati nelle partizioni e dalle query eseguite sui dati:
- Per informazioni sui prezzi di archiviazione, vedi Prezzi di archiviazione.
- Per informazioni sui prezzi delle query, consulta la sezione Prezzi delle query.
Molte operazioni tabella partizionata sono gratuite, tra cui il caricamento dei dati nelle partizioni, la copia delle partizioni e l'esportazione dei dati dalle partizioni. Sebbene gratuite, queste operazioni sono soggette a quote e limiti di BigQuery. Per informazioni su tutte le operazioni gratuite, consulta la sezione Operazioni gratuite nella pagina dei prezzi.
Per le best practice per il controllo dei costi in BigQuery, consulta Controllo dei costi in BigQuery.
Sicurezza delle tabelle
Il controllo dell'accesso per le tabelle partizionate è lo stesso di quello per le tabelle standard. Per ulteriori informazioni, consulta Introduzione ai controlli dell'accesso alle tabelle.
Passaggi successivi
- Per scoprire come creare tabelle partizionate, consulta Creazione delle tabelle partizionate.
- Per scoprire come gestire e aggiornare le tabelle partizionate, consulta la sezione Gestione delle tabelle partizionate.
- Per informazioni sull'esecuzione di query sulle tabelle partizionate, consulta Esecuzione di query sulle tabelle partizionate.