Migrazione da Amazon Redshift a BigQuery: panoramica
Questo documento fornisce indicazioni sulla migrazione da Amazon Redshift a BigQuery, concentrandosi sui seguenti argomenti:
- Strategie di migrazione
- Best practice per l'ottimizzazione delle query e la modellazione dei dati
- Suggerimenti per la risoluzione dei problemi
- Indicazioni per l'adozione da parte degli utenti
Gli obiettivi di questo documento sono i seguenti:
- Fornisci indicazioni di alto livello per le organizzazioni che eseguono la migrazione da Amazon Redshift a BigQuery, aiutandoti a ripensare le pipeline di dati esistenti per ottenere il massimo da BigQuery.
- Aiutarti a confrontare le architetture di BigQuery e Amazon Redshift in modo da determinare come implementare le funzionalità esistenti durante la migrazione. L'obiettivo è mostrarti le nuove funzionalità disponibili per la tua organizzazione tramite BigQuery, non mappare le funzionalità uno a uno con Amazon Redshift.
Questo documento è destinato ad architetti aziendali, amministratori di database, sviluppatori di applicazioni e specialisti della sicurezza IT. Si presume che tu abbia familiarità con Amazon Redshift.
Puoi anche utilizzare la traduzione SQL batch per eseguire la migrazione degli script SQL in blocco o la traduzione SQL interattiva per tradurre query ad hoc. Amazon Redshift SQL è completamente supportato da entrambi i servizi di traduzione SQL.
Attività pre-migrazione
Per garantire una migrazione del data warehouse riuscita, inizia a pianificare la tua strategia di migrazione all'inizio della cronologia del progetto. Questo approccio ti consente di valutare le funzionalità più adatte alle tue esigenze. Google Cloud
Pianificazione della capacità
BigQuery utilizza gli slot per misurare la velocità effettiva delle analisi. Uno slot BigQuery è un'unità proprietaria di Google di capacità di calcolo richiesta per eseguire le query SQL. BigQuery calcola continuamente il numero di slot richiesti dalle query durante l'esecuzione, ma alloca gli slot alle query in base a uno scheduler equo.
Quando pianifichi la capacità per gli slot BigQuery, puoi scegliere tra i seguenti modelli di determinazione dei prezzi:
- Prezzi on demand: Con i prezzi on demand, BigQuery addebita i costi in base al numero di byte elaborati (dimensioni dei dati), quindi paghi solo per le query che esegui. Per ulteriori informazioni su come BigQuery determina le dimensioni dei dati, vedi Calcolo delle dimensioni dei dati. Poiché gli slot determinano la capacità di calcolo sottostante, puoi pagare l'utilizzo di BigQuery in base al numero di slot di cui avrai bisogno (anziché in base ai byte elaborati). Per impostazione predefinita, tutti i progettiGoogle Cloud sono limitati a un massimo di 2000 slot. BigQuery potrebbe consentire il bursting oltre questo limite per accelerare le query, ma il bursting non è garantito.
- Prezzi basati sulla capacità: Con i prezzi basati sulla capacità, acquisti prenotazioni di slot BigQuery (un minimo di 100) anziché pagare per i byte elaborati dalle query che esegui. Consigliamo i prezzi basati sulla capacità per i workload di data warehouse aziendale, che in genere vedono molte query di report e di estrazione, caricamento e trasformazione (ELT) simultanee con un consumo prevedibile.
Per facilitare la stima degli slot, ti consigliamo di configurare il monitoraggio di BigQuery tramite Cloud Monitoring e di analizzare gli audit log utilizzando BigQuery. Puoi utilizzare Looker Studio (ecco un esempio open source di una dashboard di Looker Studio) o Looker per visualizzare i dati dei log di controllo di BigQuery, in particolare per l'utilizzo degli slot in query e progetti. Puoi anche utilizzare i dati delle tabelle di sistema di BigQuery per monitorare l'utilizzo degli slot in job e prenotazioni (qui trovi un esempio open source di una dashboard di Looker Studio). Il monitoraggio e l'analisi regolari dell'utilizzo degli slot ti aiutano a stimare il numero totale di slot necessari alla tua organizzazione man mano che cresci su Google Cloud.
Ad esempio, supponiamo di prenotare inizialmente 4000 slot BigQuery per eseguire 100 query di media complessità contemporaneamente. Se noti tempi di attesa elevati nei piani di esecuzione delle query e le dashboard mostrano un utilizzo elevato degli slot, ciò potrebbe indicare che hai bisogno di slot BigQuery aggiuntivi per supportare i tuoi carichi di lavoro. Se vuoi acquistare slot autonomamente tramite impegni annuali o triennali, puoi iniziare a utilizzare le prenotazioni BigQuery utilizzando la consoleGoogle Cloud o lo strumento a riga di comando bq. Per ulteriori dettagli sulla gestione dei workload, sull'esecuzione delle query e sull'architettura di BigQuery, consulta Migrazione a Google Cloud: una visione approfondita.
Sicurezza a Google Cloud
Le sezioni seguenti descrivono i controlli di sicurezza comuni di Amazon Redshift e come puoi contribuire a garantire che il tuo data warehouse rimanga protetto in un ambienteGoogle Cloud .
Gestione di identità e accessi
La configurazione dei controlli dell'accesso in Amazon Redshift prevede la scrittura di policy delle autorizzazioni API Amazon Redshift e il loro collegamento alle identità Identity and Access Management (IAM). Le autorizzazioni API Amazon Redshift forniscono l'accesso a livello di cluster, ma non forniscono livelli di accesso più granulari del cluster. Se vuoi un accesso più granulare a risorse come tabelle o viste, puoi utilizzare gli account utente nel database Amazon Redshift.
BigQuery utilizza IAM per gestire l'accesso alle risorse a un livello più granulare. I tipi di risorse disponibili in BigQuery sono organizzazioni, progetti, set di dati, tabelle, colonne e viste. Nella gerarchia dei criteri IAM, i set di dati sono risorse secondarie dei progetti. Una tabella eredita le autorizzazioni dal set di dati che la contiene.
Per concedere l'accesso a una risorsa, assegna uno o più ruoli IAM a un utente, a un gruppo o a un account di servizio. I ruoli dell'organizzazione e del progetto influiscono sulla capacità di eseguire job o gestire il progetto, mentre i ruoli del set di dati influiscono sulla capacità di accedere o modificare i dati all'interno di un progetto.
IAM fornisce i seguenti tipi di ruoli:
- Ruoli predefiniti, che hanno lo scopo di supportare casi d'uso comuni e modelli di controllo dell'accesso.
- Ruoli personalizzati, che forniscono un accesso granulare in base a un elenco di autorizzazioni specificato dall'utente.
In IAM, BigQuery fornisce il controllo dell'accesso a livello di tabella. Le autorizzazioni a livello di tabella determinano gli utenti, i gruppi e i service account che possono accedere a una tabella o a una visualizzazione. Puoi concedere a un utente l'accesso a tabelle o viste specifiche senza concedere l'accesso al set di dati completo. Per un accesso più granulare, puoi anche valutare l'implementazione di uno o più dei seguenti meccanismi di sicurezza:
- Controllo dell'accesso a livello di colonna, che fornisce un accesso granulare alle colonne sensibili utilizzando i tag di criteri o la classificazione dei dati basata sui tipi.
- Mascheramento dinamico dei dati a livello di colonna, che consente di oscurare selettivamente i dati della colonna per gruppi di utenti, consentendo comunque l'accesso alla colonna.
- Sicurezza a livello di riga, che consente di filtrare i dati e di accedere a righe specifiche di una tabella in base alle condizioni utente qualificanti.
Crittografia completa del disco
Oltre alla gestione di identità e accessi, la crittografia dei dati aggiunge un ulteriore livello di difesa per la protezione dei dati. In caso di esposizione dei dati, i dati criptati non sono leggibili.
Su Amazon Redshift, la crittografia per i dati inattivi e in transito non è attivata per impostazione predefinita. La crittografia dei dati at-rest deve essere abilitata esplicitamente quando viene avviato un cluster o modificando un cluster esistente per utilizzare la crittografia di AWS Key Management Service. Anche la crittografia dei dati in transito deve essere abilitata esplicitamente.
BigQuery cripta tutti i dati at-rest e in transito per impostazione predefinita, indipendentemente dall'origine o da qualsiasi altra condizione, e questa funzionalità non può essere disattivata. BigQuery supporta anche le chiavi di crittografia gestite dal cliente (CMEK) se vuoi controllare e gestire le chiavi di crittografia delle chiavi in Cloud Key Management Service.
Per ulteriori informazioni sulla crittografia in Google Cloud, consulta i white paper sulla crittografia dei dati at-rest e sulla crittografia dei dati in transito.
Per i dati in transito su Google Cloud, i dati vengono criptati e autenticati quando si spostano al di fuori dei confini fisici controllati da Google o per conto di Google. All'interno di questi confini, i dati in transito sono generalmente autenticati, ma non necessariamente criptati.
Prevenzione della perdita di dati
I requisiti di conformità potrebbero limitare i dati che possono essere archiviati su Google Cloud. Puoi utilizzare Sensitive Data Protection per analizzare le tabelle BigQuery per rilevare e classificare i dati sensibili. Se vengono rilevati dati sensibili, le trasformazioni di anonimizzazione di Sensitive Data Protection possono mascherare, eliminare o nascondere in altro modo i dati.
Migrazione a Google Cloud: nozioni di base
Utilizza questa sezione per scoprire di più sull'utilizzo di strumenti e pipeline per facilitare la migrazione.
Strumenti di migrazione
BigQuery Data Transfer Service fornisce uno strumento automatizzato per eseguire la migrazione direttamente di schema e dati da Amazon Redshift a BigQuery. La tabella seguente elenca strumenti aggiuntivi per facilitare la migrazione da Amazon Redshift a BigQuery:
| Strumento | Purpose |
|---|---|
| BigQuery Data Transfer Service | Esegui un trasferimento batch automatizzato dei dati Amazon Redshift a BigQuery utilizzando questo servizio completamente gestito. |
| Storage Transfer Service | Importa rapidamente i dati di Amazon S3 in Cloud Storage e configura un programma ripetuto per il trasferimento dei dati utilizzando questo servizio completamente gestito. |
gcloud |
Copia i file Amazon S3 in Cloud Storage utilizzando questo strumento a riga di comando. |
| Strumento a riga di comando bq | Interagisci con BigQuery utilizzando questo strumento a riga di comando. Le interazioni comuni includono la creazione di schemi di tabelle BigQuery, il caricamento di dati Cloud Storage nelle tabelle e l'esecuzione di query. |
| Librerie client di Cloud Storage | Copia i file Amazon S3 in Cloud Storage utilizzando lo strumento personalizzato, creato sulla base della libreria client di Cloud Storage. |
| Librerie client di BigQuery | Interagisci con BigQuery utilizzando lo strumento personalizzato, creato sulla base della libreria client BigQuery. |
| Pianificatore di query BigQuery | Pianifica query SQL ricorrenti utilizzando questa funzionalità integrata di BigQuery. |
| Cloud Composer | Orchestra le trasformazioni e i job di caricamento di BigQuery utilizzando questo ambiente Apache Airflow completamente gestito. |
| Apache Sqoop | Invia i job Hadoop utilizzando Sqoop e il driver JDBC di Amazon Redshift per estrarre i dati da Amazon Redshift in HDFS o Cloud Storage. Sqoop viene eseguito in un ambiente Dataproc. |
Per saperne di più sull'utilizzo di BigQuery Data Transfer Service, consulta Eseguire la migrazione di schema e dati da Amazon Redshift.
Migrazione tramite pipeline
La migrazione dei dati da Amazon Redshift a BigQuery può seguire percorsi diversi in base agli strumenti di migrazione disponibili. Sebbene l'elenco in questa sezione non sia esaustivo, fornisce un'idea dei diversi pattern della pipeline di dati disponibili quando sposti i dati.
Per informazioni più generali sulla migrazione dei dati a BigQuery utilizzando le pipeline, consulta Eseguire la migrazione delle pipeline di dati.
Estrai e carica (EL)
Puoi automatizzare completamente una pipeline EL utilizzando BigQuery Data Transfer Service, che può copiare automaticamente gli schemi e i dati delle tabelle dal cluster Amazon Redshift a BigQuery. Se vuoi un maggiore controllo sui passaggi della pipeline di dati, puoi creare una pipeline utilizzando le opzioni descritte nelle sezioni seguenti.
Utilizzare le estrazioni di file Amazon Redshift
- Esporta i dati di Amazon Redshift in Amazon S3.
Copia i dati da Amazon S3 a Cloud Storage utilizzando una delle seguenti opzioni:
- Storage Transfer Service (opzione consigliata)
- gcloud CLI
- Librerie client di Cloud Storage
Carica i dati di Cloud Storage in BigQuery utilizzando una delle seguenti opzioni:
Utilizzare una connessione JDBC di Amazon Redshift
Utilizza uno dei seguenti prodotti Google Cloud per esportare i dati di Amazon Redshift utilizzando il driver JDBC di Amazon Redshift:
-
- Modello fornito da Google: JDBC to BigQuery
-
Connettiti ad Amazon Redshift tramite JDBC utilizzando Apache Spark
Utilizza Sqoop e il driver JDBC di Amazon Redshift per estrarre i dati da Amazon Redshift in Cloud Storage
Estrazione, trasformazione e caricamento (ETL)
Se vuoi trasformare alcuni dati prima di caricarli in BigQuery, segui gli stessi consigli per la pipeline descritti nella sezione Estrai e carica (EL), aggiungendo un passaggio aggiuntivo per trasformare i dati prima di caricarli in BigQuery.
Utilizzare le estrazioni di file Amazon Redshift
Copia i dati da Amazon S3 a Cloud Storage utilizzando una delle seguenti opzioni:
- Storage Transfer Service (opzione consigliata)
- gcloud CLI
- Librerie client di Cloud Storage
Trasforma e poi carica i dati in BigQuery utilizzando una delle seguenti opzioni:
-
- Leggere da Cloud Storage
- Scrivi in BigQuery
- Modello fornito da Google: Testo Cloud Storage a BigQuery
Utilizzare una connessione JDBC di Amazon Redshift
Utilizza uno qualsiasi dei prodotti descritti nella sezione Estrai e carica (EL), aggiungendo un passaggio aggiuntivo per trasformare i dati prima del caricamento in BigQuery. Modifica la pipeline per introdurre uno o più passaggi per trasformare i dati prima di scriverli in BigQuery.
-
- Clona il codice del modello JDBC to BigQuery e modificalo per aggiungere trasformazioni Apache Beam.
-
- Trasforma i dati utilizzando uno dei plug-in CDAP.
Estrazione, caricamento e trasformazione (ELT)
Puoi trasformare i dati utilizzando BigQuery stesso, utilizzando una delle opzioni di estrazione e caricamento (EL) per caricare i dati in una tabella di staging. Quindi, trasforma i dati in questa tabella di staging utilizzando query SQL che scrivono il loro output nella tabella di produzione finale.
Change Data Capture (CDC)
Change Data Capture (CDC) è uno dei diversi pattern di progettazione del software utilizzati per monitorare le modifiche ai dati. Viene spesso utilizzato nel data warehousing perché il data warehouse viene utilizzato per raccogliere e monitorare i dati e le relative modifiche provenienti da vari sistemi di origine nel tempo.
Strumenti dei partner per la migrazione dei dati
Esistono diversi fornitori nel campo dell'estrazione, trasformazione e caricamento (ETL). Consulta il sito web dei partner BigQuery per un elenco dei partner chiave e delle soluzioni che forniscono.
Migrazione a Google Cloud: una visione approfondita
Utilizza questa sezione per scoprire di più su come l'architettura, lo schema e il dialetto SQL del data warehouse influiscono sulla migrazione.
Confronto tra architetture
Sia BigQuery che Amazon Redshift si basano su un'architettura di elaborazione massicciamente parallela (MPP). Le query vengono distribuite su più server per accelerarne l'esecuzione. Per quanto riguarda l'architettura di sistema, Amazon Redshift e BigQuery differiscono principalmente per il modo in cui i dati vengono archiviati e per l'esecuzione delle query. In BigQuery, l'hardware e le configurazioni sottostanti vengono astratti; l'archiviazione e il calcolo consentono al data warehouse di crescere senza alcun intervento da parte tua.
Calcolo, memoria e spazio di archiviazione
In Amazon Redshift, CPU, memoria e spazio di archiviazione su disco sono collegati tramite nodi di calcolo, come illustrato in questo diagramma della documentazione di Amazon Redshift. Le prestazioni del cluster e la capacità di archiviazione sono determinate dal tipo e dalla quantità di nodi di calcolo, entrambi da configurare. Per modificare il calcolo o lo spazio di archiviazione, devi ridimensionare il cluster tramite una procedura (nell'arco di un paio d'ore o fino a due giorni o più) che crea un nuovo cluster e copia i dati. Amazon Redshift offre anche nodi RA3 con spazio di archiviazione gestito che aiutano a separare le risorse di calcolo da quelle di archiviazione. Il nodo più grande della categoria RA3 ha un limite di 64 TB di spazio di archiviazione gestito per ogni nodo.
Fin dall'inizio, BigQuery non lega insieme computing, memoria e spazio di archiviazione, ma li tratta separatamente.
Il computing BigQuery è definito dagli slot, un'unità di capacità di calcolo richiesta per eseguire le query. Google gestisce l'intera infrastruttura che un slot racchiude, eliminando tutto tranne l'attività di scelta della quantità di slot appropriata per i carichi di lavoro BigQuery. Consulta la pianificazione della capacità per decidere quanti slot acquistare per il tuo data warehouse. La memoria BigQuery è fornita da un servizio distribuito remoto, collegato agli slot di calcolo dalla rete petabit di Google, il tutto gestito da Google.
BigQuery e Amazon Redshift utilizzano entrambi l'archiviazione colonnare, ma BigQuery utilizza variazioni e miglioramenti dell'archiviazione colonnare. Durante la codifica delle colonne, vengono mantenute varie statistiche sui dati che vengono utilizzate in un secondo momento durante l'esecuzione delle query per compilare piani ottimali e scegliere l'algoritmo di runtime più efficiente. BigQuery memorizza i dati nel file system distribuito di Google, dove vengono compressi, criptati, replicati e distribuiti automaticamente. Tutto questo viene eseguito senza influire sulla potenza di calcolo disponibile per le tue query. La separazione dell'archiviazione dal calcolo consente di scalare fino a decine di petabyte di spazio di archiviazione senza problemi, senza richiedere risorse di calcolo aggiuntive costose. Esistono anche una serie di altri vantaggi della separazione di calcolo e archiviazione.
Scale up o scale down
Quando lo spazio di archiviazione o il calcolo diventano limitati, i cluster Amazon Redshift devono essere ridimensionati modificando la quantità o i tipi di nodi nel cluster.
Quando ridimensioni un cluster Amazon Redshift, esistono due approcci:
- Ridimensionamento classico: Amazon Redshift crea un cluster in cui vengono copiati i dati, un processo che può richiedere un paio d'ore o fino a due giorni o più per grandi quantità di dati.
- Ridimensionamento elastico: se modifichi solo il numero di nodi, le query vengono temporaneamente sospese e le connessioni vengono mantenute aperte, se possibile. Durante l'operazione di ridimensionamento, il cluster è di sola lettura. Il ridimensionamento elastico in genere richiede 10-15 minuti, ma potrebbe non essere disponibile per tutte le configurazioni.
Poiché BigQuery è una piattaforma come servizio (PaaS), devi preoccuparti solo del numero di slot BigQuery che vuoi prenotare per la tua organizzazione. Prenoti gli slot BigQuery nelle prenotazioni e poi assegni i progetti a queste prenotazioni. Per scoprire come configurare queste prenotazioni, vedi Pianificazione della capacità.
Esecuzione delle query
Il motore di esecuzione di BigQuery è simile a quello di Amazon Redshift in quanto entrambi orchestrano la query suddividendola in passaggi (un piano di query), eseguendo i passaggi (contemporaneamente, se possibile) e poi riassemblano i risultati. Amazon Redshift genera un piano di query statico, mentre BigQuery no perché ottimizza dinamicamente i piani di query durante l'esecuzione della query. BigQuery esegue lo shuffle dei dati utilizzando il servizio di memoria remota, mentre Amazon Redshift esegue lo shuffle dei dati utilizzando la memoria dei nodi di calcolo locali. Per ulteriori informazioni sull'archiviazione dei dati intermedi di BigQuery dalle varie fasi del piano di query, consulta Esecuzione in memoria delle query in Google BigQuery.
Gestione dei carichi di lavoro in BigQuery
BigQuery offre i seguenti controlli per la gestione dei carichi di lavoro (WLM):
- Query interattive, che vengono eseguite il prima possibile (questa è l'impostazione predefinita).
- Query batch, che vengono accodate per tuo conto e avviate non appena le risorse inattive sono disponibili nel pool di risorse condivise di BigQuery.
Prenotazioni di slot tramite prezzi basati sulla capacità. Anziché pagare le query on demand, puoi creare e gestire dinamicamente bucket di slot chiamati prenotazioni e assegnare progetti, cartelle o organizzazioni a queste prenotazioni. Puoi acquistare impegni slot BigQuery (a partire da un minimo di 100) con impegni flessibili, mensili o annuali per ridurre al minimo i costi. Per impostazione predefinita, le query eseguite in una prenotazione utilizzano automaticamente gli slot di altre prenotazioni.
Come illustrato nel seguente diagramma, supponiamo che tu abbia acquistato una capacità di impegno totale di 1000 slot da condividere tra tre tipi di carichi di lavoro: data science, ELT e business intelligence (BI). Per supportare questi carichi di lavoro, puoi creare le seguenti prenotazioni:
- Puoi creare la prenotazione ds con 500 slot e assegnare tutti i progetti di data science a questa prenotazione.Google Cloud
- Puoi creare la prenotazione elt con 300 slot e assegnare a questa prenotazione i progetti che utilizzi per i carichi di lavoro ELT.
- Puoi creare la prenotazione BI con 200 slot e assegnare a questa prenotazione i progetti connessi ai tuoi strumenti BI.
Questa configurazione è mostrata nella seguente immagine:
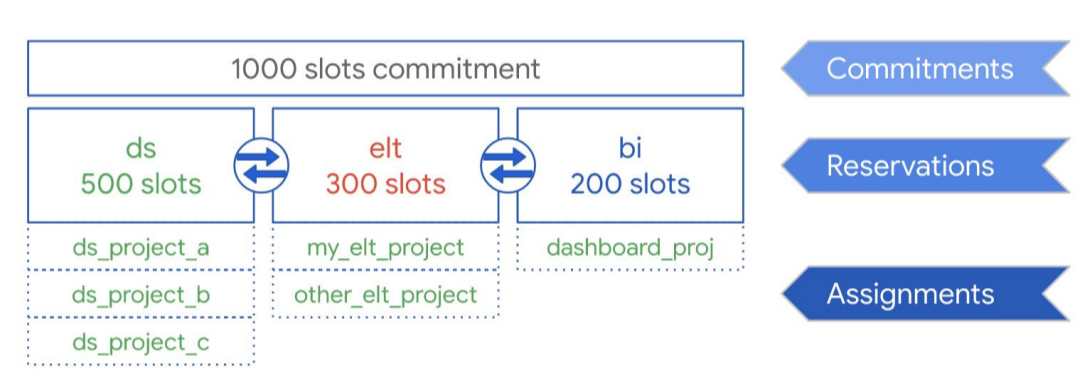
Invece di distribuire le prenotazioni ai carichi di lavoro della tua organizzazione, ad esempio a produzione e test, potresti scegliere di assegnarle a singoli team o reparti, a seconda del tuo caso d'uso.
Per saperne di più, vedi Gestione dei carichi di lavoro utilizzando le prenotazioni.
Gestione del carico di lavoro in Amazon Redshift
Amazon Redshift offre due tipi di gestione dei carichi di lavoro (WLM):
- Automatico: Con WLM automatico, Amazon Redshift gestisce la concorrenza delle query e l'allocazione della memoria. Vengono create fino a otto code con gli identificatori della classe di servizio 100-107. WLM automatico determina la quantità di risorse necessarie per le query e regola la concorrenza in base al carico di lavoro. Per maggiori informazioni, consulta Priorità delle query.
- Manuale: Al contrario, la gestione manuale del carico di lavoro richiede di specificare i valori per la concorrenza delle query e l'allocazione della memoria. Il valore predefinito per WLM manuale è la concorrenza di cinque query e la memoria è suddivisa equamente tra tutte e cinque.
Quando la scalabilità della concorrenza è abilitata, Amazon Redshift aggiunge automaticamente capacità del cluster aggiuntiva quando è necessario elaborare un aumento delle query di lettura simultanee. Lo scaling della concorrenza presenta alcune considerazioni relative alle query e alle regioni. Per ulteriori informazioni, consulta Candidati per lo scaling della concorrenza.
Configurazioni di set di dati e tabelle
BigQuery offre diversi modi per configurare i dati e le tabelle, ad esempio partizionamento, clustering e località dei dati. Queste configurazioni possono contribuire a gestire tabelle di grandi dimensioni e a ridurre il carico complessivo dei dati e il tempo di risposta delle query, aumentando così l'efficienza operativa dei carichi di lavoro dei dati.
Partizionamento
Una tabella partizionata è una tabella divisa in segmenti, denominati partizioni, che semplificano la gestione e l'esecuzione di query sui dati. In genere gli utenti dividono le tabelle di grandi dimensioni in molte partizioni più piccole, ognuna delle quali contiene i dati di un giorno. La gestione delle partizioni è un fattore determinante per le prestazioni e i costi di BigQuery quando esegui query su un intervallo di date specifico, perché aiuta BigQuery a scansionare meno dati per query.
In BigQuery esistono tre tipi di partizionamento delle tabelle:
- Tabelle partizionate per data di importazione: Le tabelle vengono partizionate in base alla data di importazione dei dati.
- Tabelle partizionate per colonna:
Le tabelle sono partizionate in base a una colonna
TIMESTAMPoDATE. - Tabelle partizionate per intervallo di numeri interi: Le tabelle sono partizionate in base a una colonna di numeri interi.
Una tabella partizionata in base al tempo e alle colonne elimina la necessità di gestire la consapevolezza della partizione indipendentemente dal filtro dei dati esistente nella colonna associata. I dati scritti in una tabella partizionata in base al tempo e alle colonne vengono inviati automaticamente alla partizione appropriata in base al valore dei dati. Allo stesso modo, le query che esprimono filtri sulla colonna di partizionamento possono ridurre la quantità complessiva di dati scansionati, il che può migliorare le prestazioni e ridurre il costo delle query on demand.
Il partizionamento basato su colonne di BigQuery è simile a quello di Amazon Redshift, ma con una motivazione leggermente diversa. Amazon Redshift utilizza la distribuzione delle chiavi basata su colonne per cercare di mantenere i dati correlati archiviati insieme all'interno dello stesso nodo di calcolo, riducendo al minimo lo data shuffling che si verifica durante i join e le aggregazioni. BigQuery separa l'archiviazione dal calcolo, quindi sfrutta il partizionamento basato su colonne per ridurre al minimo la quantità di dati che gli slot leggono dal disco.
Una volta che i worker slot leggono i dati dal disco, BigQuery può determinare automaticamente una suddivisione più ottimale dei dati e ripartizionarli rapidamente utilizzando il servizio di shuffling in memoria di BigQuery.
Per ulteriori informazioni, consulta Introduzione alle tabelle partizionate.
Chiavi di clustering e ordinamento
Amazon Redshift supporta la specifica delle colonne della tabella come chiavi di ordinamento composte o interleaved. In BigQuery, puoi specificare chiavi di ordinamento composte mediante il clustering della tabella. Le tabelle in cluster BigQuery migliorano le prestazioni delle query perché i dati della tabella vengono ordinati automaticamente in base ai contenuti di un massimo di quattro colonne specificate nello schema della tabella. Queste colonne vengono utilizzate per collocare vicini i dati correlati. L'ordine delle colonne di clustering che specifichi è importante perché determina l'ordinamento dei dati.
Il clustering può migliorare le prestazioni di determinati tipi di query, ad esempio quelle che usano clausole di filtro e quelle che aggregano dati. Quando i dati vengono scritti in una tabella in cluster da un job di query o da un job di caricamento, BigQuery ordina automaticamente i dati usando i valori delle colonne di clustering. Questi valori vengono utilizzati per organizzare i dati in più blocchi nello spazio di archiviazione BigQuery. Quando invii una query che contiene una clausola che filtra i dati in base alle colonne di clustering, BigQuery usa blocchi ordinati per evitare analisi dei dati non necessarie.
Allo stesso modo, quando invii una query che aggrega i dati in base ai valori delle colonne di clustering, le prestazioni migliorano perché i blocchi ordinati avvicinano tra loro le righe con valori simili.
Utilizza il clustering nelle seguenti circostanze:
- Le chiavi di ordinamento composte sono configurate nelle tabelle Amazon Redshift.
- Il filtro o l'aggregazione è configurato su colonne specifiche nelle tue query.
Quando usi insieme il clustering e il partizionamento, i dati possono essere partizionati per colonna di data, timestamp o numeri interi e poi raggruppati in cluster in un diverso insieme di colonne (fino a un massimo di quattro colonne raggruppate in cluster). In questo caso, i dati in ciascuna partizione vengono raggruppati in cluster in base ai valori delle colonne di clustering.
Quando specifichi le chiavi di ordinamento nelle tabelle di Amazon Redshift, a seconda del carico
sul sistema, Amazon Redshift avvia automaticamente l'ordinamento utilizzando la capacità di calcolo del tuo
cluster. Potresti persino dover eseguire manualmente il comando
VACUUM
se vuoi ordinare completamente i dati della tabella il prima possibile, ad esempio dopo un caricamento di grandi quantità di dati. BigQuery
gestisce automaticamente
questo ordinamento per te e non utilizza gli slot BigQuery allocati, pertanto non influisce sul rendimento di nessuna delle tue query.
Per saperne di più sull'utilizzo delle tabelle in cluster, consulta la Introduzione alle tabelle in cluster.
Chiavi di distribuzione
Amazon Redshift utilizza le chiavi di distribuzione per ottimizzare la posizione dei blocchi di dati per eseguire le query. BigQuery non utilizza le chiavi di distribuzione perché determina e aggiunge automaticamente le fasi in un piano di query (durante l'esecuzione della query) per migliorare la distribuzione dei dati tra i worker di query.
Sorgenti esterne
Se utilizzi Amazon Redshift Spectrum per eseguire query sui dati in Amazon S3, puoi utilizzare in modo simile la funzionalità di origine dati esterna di BigQuery per eseguire query sui dati direttamente dai file in Cloud Storage.
Oltre a eseguire query sui dati in Cloud Storage, BigQuery offre funzioni di query federata per eseguire query direttamente dai seguenti prodotti:
- Cloud SQL (MySQL o PostgreSQL completamente gestito)
- Bigtable (NoSQL completamente gestito)
- Google Drive (CSV, JSON, Avro, Fogli)
Località dei dati
Puoi creare i set di dati BigQuery in località sia regionali che multiregionali, mentre Amazon Redshift offre solo località regionali. BigQuery determina la località in cui eseguire i job di caricamento, query o estrazione in base ai set di dati a cui viene fatto riferimento nella richiesta. Consulta le considerazioni sulla località BigQuery per suggerimenti sull'utilizzo di set di dati regionali e multiregionali.
Mappatura dei tipi di dati in BigQuery
I tipi di dati di Amazon Redshift sono diversi da quelli di BigQuery. Per maggiori dettagli sui tipi di dati di BigQuery, consulta la documentazione ufficiale.
BigQuery supporta anche i seguenti tipi di dati, che non hanno un analogo diretto in Amazon Redshift:
Confronto SQL
GoogleSQL supporta la conformità allo standard SQL 2011 e dispone di estensioni che supportano l'interrogazione di dati nidificati e ripetuti. Amazon Redshift SQL si basa su PostgreSQL, ma presenta diverse differenze descritte in dettaglio nella documentazione di Amazon Redshift. Per un confronto dettagliato tra la sintassi e le funzioni di Amazon Redshift e GoogleSQL, consulta la guida alla traduzione di Amazon Redshift SQL.
Puoi utilizzare il traduttore SQL batch per convertire script e altro codice SQL dalla tua piattaforma attuale a BigQuery.
Post-migrazione
Poiché hai eseguito la migrazione di script che non sono stati progettati pensando a BigQuery, puoi scegliere di implementare tecniche per ottimizzare le prestazioni delle query in BigQuery. Per maggiori informazioni, vedi Introduzione all'ottimizzazione del rendimento delle query.
Passaggi successivi
- Ricevi istruzioni passo passo per eseguire la migrazione dello schema e dei dati da Amazon Redshift.
- Ricevi istruzioni passo passo per eseguire la migrazione di Amazon Redshift a BigQuery con VPC.