移行評価
BigQuery 移行評価を使用すると、既存のデータ ウェアハウスの BigQuery への移行を計画して確認できます。BigQuery 移行評価を実行してレポートを生成できます。これにより、BigQuery にデータを保存する費用を評価し、BigQuery でコスト削減のために既存のワークロードをどのように最適化できるかを確認し、移行計画を準備できます。この移行計画には、データ ウェアハウスの BigQuery への移行に必要な時間と労力の概要を記載します。
このドキュメントでは、BigQuery 移行評価の使用方法と、評価結果を確認するさまざまな方法について説明します。このドキュメントは、Google Cloud コンソールとバッチ SQL トランスレータに精通しているユーザーを対象としています。
始める前に
BigQuery 移行評価を準備して実行する手順は次のとおりです。
dwh-migration-dumperツールを使用して、データ ウェアハウスからメタデータとクエリのログを抽出します。Cloud Storage バケットにメタデータとクエリログをアップロードします。
省略可: 評価結果をクエリして、詳細または具体的な評価情報を確認します。
データ ウェアハウスからメタデータとクエリログを抽出する
推奨事項を使用して評価を準備するには、メタデータとクエリログの両方が必要です。
評価の実行に必要なメタデータとクエリログを抽出するには、データ ウェアハウスを選択します。
Teradata
要件
- 移行元の Teradata データ ウェアハウスに接続されているマシン(Teradata 15 以降をサポート)
- データの保存先となる Cloud Storage バケットがある Google Cloud アカウント
- 結果を保存する空の BigQuery データセット
- 結果を表示するためのデータセットに対する読み取り権限
- 推奨: 抽出ツールを使用してシステム テーブルにアクセスする場合のソース データベースに対する管理者レベルのアクセス権
要件: ロギングを有効にする
dwh-migration-dumper ツールは、クエリログ、ユーティリティ ログ、リソース使用ログの 3 種類のログを抽出します。より完全な分析情報を表示するには、次の種類のログの記録を有効にする必要があります。
- クエリログ: ビュー
dbc.QryLogVとテーブルdbc.DBQLSqlTblから抽出されます。ロギングを有効にするには、WITH SQLオプションを指定してます。 - ユーティリティ ログ: テーブル
dbc.DBQLUtilityTblから抽出されます。ロギングを有効にするには、WITH UTILITYINFOオプションを指定してます。 - リソース使用ログ: テーブル
dbc.ResUsageScpuとdbc.ResUsageSpmaから抽出されます。これら 2 つのテーブルの RSS ロギングを有効化します。
dwh-migration-dumper ツールを実行する
dwh-migration-dumper ツールをダウンロードします。
SHA256SUMS.txt ファイルをダウンロードし、次のコマンドを実行して zip ファイルに問題がないことを確認します。
Bash
sha256sum --check SHA256SUMS.txt
Windows PowerShell
(Get-FileHash RELEASE_ZIP_FILENAME).Hash -eq ((Get-Content SHA256SUMS.txt) -Split " ")[0]
RELEASE_ZIP_FILENAME は、dwh-migration-dumper コマンドライン抽出ツールリリースのダウンロード済み zip ファイル名に置き換えます(例: dwh-migration-tools-v1.0.52.zip)。
True という結果は、チェックサムの検証が成功したことを示します。
False の結果は、検証エラーを示します。チェックサム ファイルと ZIP ファイルが同じリリース バージョンからダウンロードされ、同じディレクトリに配置されていることを確認します。
抽出ツールを設定して使用する方法については、変換と評価のためのメタデータを生成するをご覧ください。
抽出ツールを使用して、Teradata データ ウェアハウスからログとメタデータを 2 つの ZIP ファイルとして抽出します。移行元のデータ ウェアハウスへのアクセス権があるマシン上で次のコマンドを実行して、ファイルを生成します。
メタデータ ZIP ファイルを生成します。
dwh-migration-dumper \ --connector teradata \ --database DATABASES \ --driver path/terajdbc4.jar \ --host HOST \ --assessment \ --user USER \ --password PASSWORD
注: teradata コネクタでは、--database フラグは省略可能です。省略した場合、すべてのデータベースのメタデータが抽出されます。このフラグは teradata コネクタでのみ有効です。teradata-logs との併用はできません。
クエリログを含む ZIP ファイルを生成します。
dwh-migration-dumper \ --connector teradata-logs \ --driver path/terajdbc4.jar \ --host HOST \ --assessment \ --user USER \ --password PASSWORD
注: teradata-logs コネクタでクエリログを抽出する場合は、--database フラグを使用しません。クエリログは、常にすべてのデータベースに対して抽出されます。
次のように置き換えます。
PATH: この接続に使用するドライバ JAR ファイルの絶対パスまたは相対パスVERSION: ドライバのバージョンHOST: ホストアドレスUSER: データベース接続に使用するユーザー名DATABASES:(省略可)抽出するデータベース名のカンマ区切りリスト。省略した場合、すべてのデータベースが抽出されます。PASSWORD:(省略可)データベース接続に使用するパスワード。空白のままにすると、パスワードの入力を求められます。
デフォルトでは、クエリログは dbc.QryLogV ビューと dbc.DBQLSqlTbl テーブルから抽出されます。クエリログを代わりの場所から抽出する必要がある場合は、-Dteradata-logs.query-logs-table フラグと -Dteradata-logs.sql-logs-table フラグを使用してテーブルまたはビューの名前を指定できます。
デフォルトでは、ユーティリティ ログは dbc.DBQLUtilityTbl テーブルから抽出されます。ユーティリティ ログを別の場所から抽出する必要がある場合は、-Dteradata-logs.utility-logs-table フラグを使用してテーブルの名前を指定できます。
デフォルトでは、リソース使用状況ログは dbc.ResUsageScpu テーブルと dbc.ResUsageSpma テーブルから抽出されます。リソース使用状況ログを別の場所から抽出する必要がある場合は、-Dteradata-logs.res-usage-scpu-table フラグと -Dteradata-logs.res-usage-spma-table フラグを使用してテーブルの名前を指定できます。
例:
Bash
dwh-migration-dumper \ --connector teradata-logs \ --driver path/terajdbc4.jar \ --host HOST \ --assessment \ --user USER \ --password PASSWORD \ -Dteradata-logs.query-logs-table=pdcrdata.QryLogV_hst \ -Dteradata-logs.sql-logs-table=pdcrdata.DBQLSqlTbl_hst \ -Dteradata-logs.log-date-column=LogDate \ -Dteradata-logs.utility-logs-table=pdcrdata.DBQLUtilityTbl_hst \ -Dteradata-logs.res-usage-scpu-table=pdcrdata.ResUsageScpu_hst \ -Dteradata-logs.res-usage-spma-table=pdcrdata.ResUsageSpma_hst
Windows PowerShell
dwh-migration-dumper ` --connector teradata-logs ` --driver path\terajdbc4.jar ` --host HOST ` --assessment ` --user USER ` --password PASSWORD ` "-Dteradata-logs.query-logs-table=pdcrdata.QryLogV_hst" ` "-Dteradata-logs.sql-logs-table=pdcrdata.DBQLSqlTbl_hst" ` "-Dteradata-logs.log-date-column=LogDate" ` "-Dteradata-logs.utility-logs-table=pdcrdata.DBQLUtilityTbl_hst" ` "-Dteradata-logs.res-usage-scpu-table=pdcrdata.ResUsageScpu_hst" ` "-Dteradata-logs.res-usage-spma-table=pdcrdata.ResUsageSpma_hst"
デフォルトでは、dwh-migration-dumper ツールは過去 7 日間のクエリログを抽出します。より完全な分析情報を表示できるように、少なくとも 2 週間のクエリログを用意することをおすすめします。--query-log-start フラグと --query-log-end フラグを使用して、カスタム期間を指定できます。例:
dwh-migration-dumper \ --connector teradata-logs \ --driver path/terajdbc4.jar \ --host HOST \ --assessment \ --user USER \ --password PASSWORD \ --query-log-start "2023-01-01 00:00:00" \ --query-log-end "2023-01-15 00:00:00"
また、さまざまな期間を対象とするクエリログを含む ZIP ファイルを複数生成し、そのすべてを評価のために提供することもできます。
Redshift
要件
- 移行元の Amazon Redshift データ ウェアハウスに接続されているマシン
- データを保存する Cloud Storage バケットがある Google Cloud アカウント
- 結果を保存する空の BigQuery データセット
- 結果を表示するためのデータセットに対する読み取り権限
- 推奨: 抽出ツールを使用してシステム テーブルにアクセスする際のデータベースへのスーパー ユーザー アクセス
dwh-migration-dumper ツールを実行する
dwh-migration-dumper コマンドライン抽出ツールをダウンロードします。
SHA256SUMS.txt ファイルをダウンロードし、次のコマンドを実行して zip ファイルに問題がないことを確認します。
Bash
sha256sum --check SHA256SUMS.txt
Windows PowerShell
(Get-FileHash RELEASE_ZIP_FILENAME).Hash -eq ((Get-Content SHA256SUMS.txt) -Split " ")[0]
RELEASE_ZIP_FILENAME は、dwh-migration-dumper コマンドライン抽出ツールリリースのダウンロード済み zip ファイル名に置き換えます(例: dwh-migration-tools-v1.0.52.zip)。
True という結果は、チェックサムの検証が成功したことを示します。
False の結果は、検証エラーを示します。チェックサム ファイルと ZIP ファイルが同じリリース バージョンからダウンロードされ、同じディレクトリに配置されていることを確認します。
dwh-migration-dumper ツールの使用方法について詳しくは、メタデータの生成ページをご覧ください。
dwh-migration-dumper ツールを使用して、Amazon Redshift データ ウェアハウスからログとメタデータを 2 つの ZIP ファイルとして抽出します。移行元のデータ ウェアハウスへのアクセス権があるマシン上で次のコマンドを実行して、ファイルを生成します。
メタデータ ZIP ファイルを生成します。
dwh-migration-dumper \ --connector redshift \ --database DATABASE \ --driver PATH/redshift-jdbc42-VERSION.jar \ --host host.region.redshift.amazonaws.com \ --assessment \ --user USER \ --iam-profile IAM_PROFILE_NAME
クエリログを含む ZIP ファイルを生成します。
dwh-migration-dumper \ --connector redshift-raw-logs \ --database DATABASE \ --driver PATH/redshift-jdbc42-VERSION.jar \ --host host.region.redshift.amazonaws.com \ --assessment \ --user USER \ --iam-profile IAM_PROFILE_NAME
次のように置き換えます。
DATABASE: 接続先のデータベースの名前。PATH: この接続に使用するドライバ JAR ファイルの絶対パスまたは相対パスVERSION: ドライバのバージョンUSER: データベース接続に使用するユーザー名IAM_PROFILE_NAME: Amazon Redshift IAM プロファイル名。Amazon Redshift の認証と AWS API アクセスに必要です。Amazon Redshift クラスタの説明を取得するには、AWS API を使用します。
デフォルトでは、Amazon Redshift は 3~5 日間のクエリログを保存します。
デフォルトでは、dwh-migration-dumper ツールは過去 7 日間のクエリログを抽出します。
より完全な分析情報を表示できるように、少なくとも 2 週間のクエリログを用意することをおすすめします。最適な結果を得るには、抽出ツールを 2 週間の間に数回実行する必要がある場合があります。--query-log-start フラグと --query-log-end フラグを使用して、カスタム範囲を指定できます。例:
dwh-migration-dumper \ --connector redshift-raw-logs \ --database DATABASE \ --driver PATH/redshift-jdbc42-VERSION.jar \ --host host.region.redshift.amazonaws.com \ --assessment \ --user USER \ --iam-profile IAM_PROFILE_NAME \ --query-log-start "2023-01-01 00:00:00" \ --query-log-end "2023-01-02 00:00:00"
また、さまざまな期間を対象とするクエリログを含む ZIP ファイルを複数生成し、そのすべてを評価のために提供することもできます。
Redshift Serverless
要件
- 移行元の Amazon Redshift Serverless データ ウェアハウスに接続されているマシン
- データの保存先となる Cloud Storage バケットがある Google Cloud アカウント
- 結果を保存する空の BigQuery データセット
- 結果を表示するためのデータセットに対する読み取り権限
- 推奨: 抽出ツールを使用してシステム テーブルにアクセスする際のデータベースへのスーパー ユーザー アクセス
dwh-migration-dumper ツールを実行する
dwh-migration-dumper コマンドライン抽出ツールをダウンロードします。
dwh-migration-dumper ツールの使用方法について詳しくは、メタデータを生成するをご覧ください。
dwh-migration-dumper ツールを使用して、Amazon Redshift Serverless 名前空間から使用状況ログとメタデータを 2 つの ZIP ファイルとして抽出します。移行元のデータ ウェアハウスにアクセスできるマシン上で次のコマンドを実行し、ファイルを生成します。
メタデータ ZIP ファイルを生成します。
dwh-migration-dumper \ --connector redshift \ --database DATABASE \ --driver PATH/redshift-jdbc42-VERSION.jar \ --host host.region.redshift-serverless.amazonaws.com \ --assessment \ --user USER \ --iam-profile IAM_PROFILE_NAME
クエリログを含む ZIP ファイルを生成します。
dwh-migration-dumper \ --connector redshift-serverless-logs \ --database DATABASE \ --driver PATH/redshift-jdbc42-VERSION.jar \ --host host.region.redshift-serverless.amazonaws.com \ --assessment \ --user USER \ --iam-profile IAM_PROFILE_NAME
次のように置き換えます。
DATABASE: 接続先のデータベースの名前。PATH: この接続に使用するドライバ JAR ファイルの絶対パスまたは相対パスVERSION: ドライバのバージョンUSER: データベース接続に使用するユーザー名IAM_PROFILE_NAME: Amazon Redshift IAM プロファイル名。Amazon Redshift の認証と AWS API アクセスに必要です。Amazon Redshift クラスタの説明を取得するには、AWS API を使用します。
Amazon Redshift Serverless は、使用状況ログを 7 日間保存します。より広い範囲が必要な場合は、より長い期間データを複数回抽出することをおすすめします。
Snowflake
要件
Snowflake からメタデータとクエリログを抽出するには、次の要件を満たす必要があります。
- Snowflake インスタンスに接続できるマシン。
- データを保存する Cloud Storage バケットがある Google Cloud アカウント。
- 結果を保存する空の BigQuery データセット。BigQuery データセットは、 Google Cloud コンソール UI で評価ジョブを作成するときに作成することもできます。
- データベース
Snowflakeに対するIMPORTED PRIVILEGESアクセス権のある Snowflake ユーザー。鍵ペアベースの認証を使用するSERVICEユーザーの作成をおすすめします。これにより、MFA トークンを生成することなく Snowflake データ プラットフォームにアクセスするための安全な方法が提供されます。- 新しいサービス ユーザーを作成するには、Snowflake の公式ガイドをご覧ください。RSA 鍵ペアを生成し、Snowflake ユーザーに公開鍵を割り当てる必要があります。
- サービス ユーザーには
ACCOUNTADMINロールが付与されているか、アカウント管理者からデータベースSnowflakeに対するIMPORTED PRIVILEGES権限を含むロールが付与されている必要があります。 - 鍵ペア認証の代わりに、パスワード ベースの認証を使用することもできます。ただし、2025 年 8 月以降、Snowflake はパスワードベースのすべてのユーザーに MFA を適用します。これにより、抽出ツールの使用時に MFA プッシュ通知の承認が必要になります。
dwh-migration-dumper ツールを実行する
dwh-migration-dumper コマンドライン抽出ツールをダウンロードします。
SHA256SUMS.txt ファイルをダウンロードし、次のコマンドを実行して zip ファイルに問題がないことを確認します。
Bash
sha256sum --check SHA256SUMS.txt
Windows PowerShell
(Get-FileHash RELEASE_ZIP_FILENAME).Hash -eq ((Get-Content SHA256SUMS.txt) -Split " ")[0]
RELEASE_ZIP_FILENAME は、dwh-migration-dumper コマンドライン抽出ツールリリースのダウンロード済み zip ファイル名に置き換えます(例: dwh-migration-tools-v1.0.52.zip)。
True という結果は、チェックサムの検証が成功したことを示します。
False の結果は、検証エラーを示します。チェックサム ファイルと ZIP ファイルが同じリリース バージョンからダウンロードされ、同じディレクトリに配置されていることを確認します。
dwh-migration-dumper ツールの使用方法について詳しくは、メタデータの生成ページをご覧ください。
dwh-migration-dumper ツールを使用して、Snowflake データ ウェアハウスからログとメタデータを 2 つの ZIP ファイルとして抽出します。移行元のデータ ウェアハウスにアクセスできるマシン上で次のコマンドを実行し、ファイルを生成します。
メタデータ ZIP ファイルを生成します。
dwh-migration-dumper \ --connector snowflake \ --host HOST_NAME \ --user USER_NAME \ --role ROLE_NAME \ --warehouse WAREHOUSE \ --assessment \ --private-key-file PRIVATE_KEY_PATH \ --private-key-password PRIVATE_KEY_PASSWORD
クエリログを含む ZIP ファイルを生成します。
dwh-migration-dumper \ --connector snowflake-logs \ --host HOST_NAME \ --user USER_NAME \ --role ROLE_NAME \ --warehouse WAREHOUSE \ --query-log-start STARTING_DATE \ --query-log-end ENDING_DATE \ --assessment \ --private-key-file PRIVATE_KEY_PATH \ --private-key-password PRIVATE_KEY_PASSWORD
次のように置き換えます。
HOST_NAME: Snowflake インスタンスのホスト名。USER_NAME: データベース接続に使用するユーザー名。このユーザーには、要件で説明されているアクセス権が必要です。PRIVATE_KEY_PATH: 認証に使用される RSA 秘密鍵のパス。PRIVATE_KEY_PASSWORD:(省略可)RSA 秘密鍵の作成時に使用されたパスワード。秘密鍵が暗号化されている場合にのみ必要です。ROLE_NAME:(省略可)dwh-migration-dumperツールを実行するときのユーザーロール(例:ACCOUNTADMIN)。WAREHOUSE: ダンプ オペレーションの実行に使用されるウェアハウス。複数の仮想ウェアハウスがある場合は、このクエリを実行する任意のウェアハウスを指定できます。要件のセクションで詳述されているアクセス権限を使用してこのクエリを実行すると、このアカウント内のすべてのウェアハウスのアーティファクトが抽出されます。STARTING_DATE:(省略可)クエリログの期間の開始日を示すために使用します。YYYY-MM-DDの形式で記述します。ENDING_DATE:(省略可)クエリログの期間の終了日を示すために使用します。YYYY-MM-DDの形式で記述します。
また、重複しない期間を対象とするクエリログを含む ZIP ファイルを複数生成し、そのすべてを評価のために提出することもできます。
Oracle
この機能に関するフィードバックやサポートをご希望の場合は、bq-edw-migration-support@google.com 宛てにメールをお送りください。
要件
Oracle からメタデータとクエリログを抽出するには、次の要件を満たす必要があります。
- バージョン 11g R1 以降の Oracle データベース。
- Oracle インスタンスに接続できるマシン。
- Java 8 以上。
- データを保存する Cloud Storage バケットがある Google Cloud アカウント。
- 結果を保存する空の BigQuery データセット。BigQuery データセットは、 Google Cloud コンソール UI で評価ジョブを作成するときに作成することもできます。
- SYSDBA 権限を持つ Oracle 共通ユーザー。
dwh-migration-dumper ツールを実行する
dwh-migration-dumper コマンドライン抽出ツールをダウンロードします。
SHA256SUMS.txt ファイルをダウンロードし、次のコマンドを実行して ZIP ファイルに問題がないことを確認します。
sha256sum --check SHA256SUMS.txt
dwh-migration-dumper ツールの使用方法について詳しくは、メタデータの生成ページをご覧ください。
dwh-migration-dumper ツールを使用して、メタデータとパフォーマンス統計情報を ZIP ファイルに抽出します。デフォルトでは、Oracle Tuning Pack と Oracle Diagnostics Pack を必要とする Oracle AWR から統計情報が抽出されます。このデータが利用できない場合、dwh-migration-dumper は、代わりに STATSPACK を使用します。
マルチテナント データベースの場合、dwh-migration-dumper ツールはルートコンテナで実行する必要があります。プラガブル データベースのいずれかで実行すると、他のプラガブル データベースに関するパフォーマンス統計情報とメタデータが失われます。
メタデータ ZIP ファイルを生成します。
dwh-migration-dumper \ --connector oracle-stats \ --host HOST_NAME \ --port PORT \ --oracle-service SERVICE_NAME \ --assessment \ --driver JDBC_DRIVER_PATH \ --user USER_NAME \ --password
次のように置き換えます。
HOST_NAME: Oracle インスタンスのホスト名。PORT: 接続ポート番号。デフォルト値は 1521 です。SERVICE_NAME: 接続に使用する Oracle サービス名。JDBC_DRIVER_PATH: ドライバ JAR ファイルの絶対パスまたは相対パス。このファイルは、Oracle JDBC ドライバのダウンロード ページからダウンロードできます。データベース バージョンと互換性のあるドライバ バージョンを選択する必要があります。USER_NAME: Oracle インスタンスへの接続に使用するユーザーの名前。このユーザーには、要件で説明されているアクセス権が必要です。
Hadoop / Cloudera
この機能に関するフィードバックやサポートをご希望の場合は、bq-edw-migration-support@google.com 宛てにメールをお送りください。
要件
Cloudera からメタデータを抽出するには、次のものが必要です。
- Cloudera Manager API に接続できるマシン。
- データの保存先となる Cloud Storage バケットがある Google Cloud アカウント。
- 結果を保存する空の BigQuery データセット。BigQuery データセットは、評価ジョブを作成するときに作成することもできます。
dwh-migration-dumper ツールを実行する
dwh-migration-dumperコマンドライン抽出ツールをダウンロードします。SHA256SUMS.txtファイルをダウンロードします。コマンドライン環境で、ZIP ファイルに問題がないことを確認します。
sha256sum --check SHA256SUMS.txt
dwh-migration-dumperツールの使用方法について詳しくは、変換と評価用のメタデータを生成するをご覧ください。dwh-migration-dumperツールを使用して、メタデータとパフォーマンス統計情報を ZIP ファイルに抽出します。dwh-migration-dumper \ --connector cloudera-manager \ --user USER_NAME \ --password PASSWORD \ --url URL_PATH \ --yarn-application-types "APP_TYPES" \ --pagination-page-size PAGE_SIZE \ --start-date START_DATE \ --end-date END_DATE \ --assessment
次のように置き換えます。
USER_NAME: Cloudera Manager インスタンスへの接続に使用するユーザーの名前。PASSWORD: Cloudera Manager インスタンスのパスワード。URL_PATH: Cloudera Manager API の URL パス(例:https://localhost:7183/api/v55/)。APP_TYPES(省略可): クラスタからダンプされる YARN アプリケーション タイプのカンマ区切りリスト。デフォルト値はMAPREDUCE,SPARK,Oozie Launcherです。PAGE_SIZE(省略可): Cloudera レスポンスあたりのレコード数。デフォルト値は1000です。START_DATE(省略可): 履歴ダンプの開始日。ISO 8601 形式で指定します(例:2025-05-29)。デフォルト値は現在の日付の 90 日前です。END_DATE(省略可): 履歴ダンプの終了日。ISO 8601 形式で指定します(例:2025-05-30)。デフォルト値は現在の日付です。
Cloudera クラスタで Oozie を使用する
Cloudera クラスタで Oozie を使用している場合は、Oozie コネクタを使用して Oozie ジョブ履歴をダンプできます。Oozie は、Kerberos 認証または基本認証で使用できます。
Kerberos 認証の場合は、次のコマンドを実行します。
kinit dwh-migration-dumper \ --connector oozie \ --url URL_PATH \ --assessment
次のように置き換えます。
URL_PATH(省略可): Oozie サーバーの URL パス。URL パスを省略すると、OOZIE_URL環境変数からパスが取得されます。
基本認証の場合は、次のコマンドを実行します。
dwh-migration-dumper \ --connector oozie \ --user USER_NAME \ --password PASSWORD \ --url URL_PATH \ --assessment
次のように置き換えます。
USER_NAME: Oozie ユーザーの名前。PASSWORD: ユーザーのパスワード。URL_PATH(省略可): Oozie サーバーの URL パス。URL パスを省略すると、OOZIE_URL環境変数からパスが取得されます。
Cloudera クラスタで Airflow を使用する
Cloudera クラスタで Airflow を使用している場合は、Airflow コネクタを使用して DAG の履歴をダンプできます。
dwh-migration-dumper \ --connector airflow \ --user USER_NAME \ --password PASSWORD \ --url URL \ --driver "DRIVER_PATH" \ --start-date START_DATE \ --end-date END_DATE \ --assessment
次のように置き換えます。
USER_NAME: Airflow ユーザーの名前PASSWORD: ユーザーのパスワードURL: Airflow データベースの JDBC 文字列DRIVER_PATH: JDBC ドライバのパスSTART_DATE(省略可): 履歴ダンプの開始日(ISO 8601 形式)END_DATE(省略可): 履歴ダンプの終了日(ISO 8601 形式)
Cloudera クラスタで Hive を使用する
Hive コネクタを使用するには、Apache Hive タブをご覧ください。
Apache Hive
要件
- 移行元の Apache Hive データ ウェアハウスに接続されているマシン(BigQuery の移行評価は Hive on Tez と MapReduce をサポートしており、Apache Hive バージョン 2.2~3.1 をサポートしています)
- データを保存する Cloud Storage バケットがある Google Cloud アカウント
- 結果を保存する空の BigQuery データセット
- 結果を表示するためのデータセットに対する読み取り権限
- クエリログの抽出を構成するための移行元 Apache Hive データ ウェアハウスへのアクセス権
- テーブル、パーティション、列に関する最新の統計情報
BigQuery 移行評価では、テーブル、パーティション、列の統計情報を使用して、Apache Hive データ ウェアハウスについて理解を深め、詳細な分析情報を提供します。ソースの Apache Hive データ ウェアハウスで hive.stats.autogather 構成が false に設定されている場合は、dwh-migration-dumper ツールを実行する前に、それを有効にするか、統計情報を手動で更新することをおすすめします。
dwh-migration-dumper ツールを実行する
dwh-migration-dumper コマンドライン抽出ツールをダウンロードします。
SHA256SUMS.txt ファイルをダウンロードし、次のコマンドを実行して zip ファイルに問題がないことを確認します。
Bash
sha256sum --check SHA256SUMS.txt
Windows PowerShell
(Get-FileHash RELEASE_ZIP_FILENAME).Hash -eq ((Get-Content SHA256SUMS.txt) -Split " ")[0]
RELEASE_ZIP_FILENAME は、dwh-migration-dumper コマンドライン抽出ツールリリースのダウンロード済み zip ファイル名に置き換えます(例: dwh-migration-tools-v1.0.52.zip)。
True という結果は、チェックサムの検証が成功したことを示します。
False の結果は、検証エラーを示します。チェックサム ファイルと ZIP ファイルが同じリリース バージョンからダウンロードされ、同じディレクトリに配置されていることを確認します。
dwh-migration-dumper ツールの使用方法について詳しくは、変換と評価用のメタデータを生成するをご覧ください。
dwh-migration-dumper ツールを使用して、Hive データ ウェアハウスからメタデータを ZIP ファイルとして生成します。
認証なし
メタデータ ZIP ファイルを生成するには、移行元のデータ ウェアハウスにアクセスできるマシンで次のコマンドを実行します。
dwh-migration-dumper \ --connector hiveql \ --database DATABASES \ --host hive.cluster.host \ --port 9083 \ --assessment
Kerberos 認証を使用
メタストアに対する認証を行うには、Apache Hive メタストアにアクセスできるユーザーとしてログインし、Kerberos チケットを生成します。次に、以下のコマンドを使用してメタデータの zip ファイルを生成します。
JAVA_OPTS="-Djavax.security.auth.useSubjectCredsOnly=false" \ dwh-migration-dumper \ --connector hiveql \ --database DATABASES \ --host hive.cluster.host \ --port 9083 \ --hive-kerberos-url PRINCIPAL/HOST \ -Dhiveql.rpc.protection=hadoop.rpc.protection \ --assessment
次のように置き換えます。
DATABASES: 抽出するデータベース名のカンマ区切りリスト。省略した場合、すべてのデータベースが抽出されます。PRINCIPAL: チケットの発行先 kerberos プリンシパルHOST: チケットの発行先 kerberos ホスト名hadoop.rpc.protection: Simple Authentication and Security Layer(SASL)構成レベルの保護の質(QOP)。/etc/hadoop/conf/core-site.xmlファイル内のhadoop.rpc.protectionパラメータの値と等しく、次のいずれかの値を指定します。authenticationintegrityprivacy
hadoop-migration-assessment ロギングフックを使用してクエリログを抽出する
クエリログを抽出する手順は次のとおりです。
hadoop-migration-assessment ロギングフックをアップロードする
Hive ロギングフックの JAR ファイルを含む
hadoop-migration-assessmentクエリログ抽出ロギングフックをダウンロードします。JAR ファイルを抽出します。
ツールがコンプライアンス要件を満たしていることを監査する必要がある場合は、
hadoop-migration-assessmentロギングフック GitHub リポジトリからソースコードを確認し、独自のバイナリをコンパイルします。クエリロギングを有効にするすべてのクラスタの補助ライブラリ フォルダに JAR ファイルをコピーします。ベンダーによっては、クラスタ設定で補助ライブラリ フォルダを見つけて、JAR ファイルを Hive クラスタの補助ライブラリ フォルダに転送する必要があります。
hadoop-migration-assessmentロギングフックの構成プロパティを設定します。Hadoop ベンダーによっては、UI コンソールでクラスタの設定を編集する必要があります。/etc/hive/conf/hive-site.xmlファイルを変更するか、構成マネージャーを使用して構成を適用します。
プロパティを構成する
次の構成キーに他の値がすでにある場合は、カンマ(,)を使用して設定を追加します。hadoop-migration-assessment ロギングフックを設定するには、次の構成設定が必要です。
hive.exec.failure.hooks:com.google.cloud.bigquery.dwhassessment.hooks.MigrationAssessmentLoggingHookhive.exec.post.hooks:com.google.cloud.bigquery.dwhassessment.hooks.MigrationAssessmentLoggingHookhive.exec.pre.hooks:com.google.cloud.bigquery.dwhassessment.hooks.MigrationAssessmentLoggingHookhive.aux.jars.path: ロギングフックの JAR ファイルのパスを含めます(例:file://)。/HiveMigrationAssessmentQueryLogsHooks_deploy.jar dwhassessment.hook.base-directory: クエリログ出力フォルダのパス。例:hdfs://tmp/logs/次のオプションの構成を設定することもできます。
dwhassessment.hook.queue.capacity: クエリイベント ロギング スレッドのキュー容量。デフォルト値は64です。dwhassessment.hook.rollover-interval: ファイル ロールオーバーの実行頻度。例:600sデフォルト値は 3,600 秒(1 時間)です。dwhassessment.hook.rollover-eligibility-check-interval: ファイル ロールオーバーの適格性チェックがバックグラウンドでトリガーされる頻度。例:600s。デフォルト値は 600 秒(10 分)です。
ロギングフックを検証する
hive-server2 プロセスを再起動したら、テストクエリを実行してデバッグログを分析します。次のメッセージが表示されます。
Logger successfully started, waiting for query events. Log directory is '[dwhassessment.hook.base-directory value]'; rollover interval is '60' minutes; rollover eligibility check is '10' minutes
ロギングフックは、構成されたフォルダに日付分割サブフォルダを作成します。クエリイベントを含む Avro ファイルは、dwhassessment.hook.rollover-interval 間隔または hive-server2 プロセスが終了すると、そのフォルダに作成されます。デバッグログで同様のメッセージを探すことで、ロールオーバー オペレーションのステータスを確認できます。
Updated rollover time for logger ID 'my_logger_id' to '2023-12-25T10:15:30'
Performed rollover check for logger ID 'my_logger_id'. Expected rollover time is '2023-12-25T10:15:30'
ロールオーバーは、指定した間隔または日付が変更されたときに行われます。日付が変更されると、ロギングフックによってその日付の新しいサブフォルダも作成されます。
より完全な分析情報を表示できるように、少なくとも 2 週間のクエリログを用意することをおすすめします。
異なる Hive クラスタのクエリログを含むフォルダを生成し、そのすべてを 1 回の評価のために提出することもできます。
メタデータとクエリログを Cloud Storage にアップロードする
データ ウェアハウスからメタデータとクエリログを抽出したら、ファイルを Cloud Storage バケットにアップロードして移行評価に進むことができます。
Teradata
メタデータと、クエリログを含む 1 つ以上の ZIP ファイルを Cloud Storage バケットにアップロードします。バケットの作成と Cloud Storage へのファイルのアップロードの詳細については、バケットの作成とファイル システムからオブジェクトのアップロードをご覧ください。メタデータ ZIP ファイルに含まれているすべてのファイルの非圧縮サイズの合計の上限は 50 GB です。
クエリログが含まれている ZIP ファイルのエントリは、次のように分割されます。
query_history_接頭辞のあるクエリ履歴ファイルutility_logs_、dbc.ResUsageScpu_、dbc.ResUsageSpma_接頭辞のある時系列ファイル。
すべてのクエリ履歴ファイルの非圧縮サイズの合計の上限は 5 TB です。すべての時系列ファイルの非圧縮サイズの合計の上限は 1 TB です。
クエリログが別のデータベースにアーカイブされている場合は、このセクションで前述した -Dteradata-logs.query-logs-table フラグと -Dteradata-logs.sql-logs-table フラグの説明をご覧ください。そこでクエリログの代わりの場所を指定する方法を説明しています。
Redshift
メタデータと、クエリログを含む 1 つ以上の ZIP ファイルを Cloud Storage バケットにアップロードします。バケットの作成と Cloud Storage へのファイルのアップロードの詳細については、バケットの作成とファイル システムからオブジェクトのアップロードをご覧ください。メタデータ ZIP ファイルに含まれているすべてのファイルの非圧縮サイズの合計の上限は 50 GB です。
クエリログが含まれている ZIP ファイルのエントリは、次のように分割されます。
querytext_接頭辞とddltext_接頭辞を持つクエリ履歴ファイルquery_queue_info_、wlm_query_、querymetrics_接頭辞のある時系列ファイル。
すべてのクエリ履歴ファイルの非圧縮サイズの合計の上限は 5 TB です。すべての時系列ファイルの非圧縮サイズの合計の上限は 1 TB です。
Redshift Serverless
メタデータと、クエリログを含む 1 つ以上の ZIP ファイルを Cloud Storage バケットにアップロードします。バケットの作成と Cloud Storage へのファイルのアップロードの詳細については、バケットの作成とファイル システムからオブジェクトのアップロードをご覧ください。
Snowflake
メタデータと、クエリログと使用状況履歴を含む ZIP ファイルを Cloud Storage バケットにアップロードします。これらのファイルを Cloud Storage にアップロードする場合は、次の要件を満たす必要があります。
- メタデータ ZIP ファイル内のすべてのファイルの非圧縮サイズの合計は 50 GB 未満にする必要があります。
- メタデータ ZIP ファイルとクエリログを含む ZIP ファイルは、Cloud Storage フォルダにアップロードする必要があります。重複しないクエリログを含む ZIP ファイルが複数ある場合は、そのすべてをアップロードできます。
- すべてのファイルを同じ Cloud Storage フォルダにアップロードする必要があります。
- メタデータとクエリログの ZIP ファイルはすべて、
dwh-migration-dumperツールで出力されたとおりにアップロードする必要があります。抽出、結合、またはその他の変更は行わないでください。 - すべてのクエリ履歴ファイルの非圧縮サイズの合計は 5 TB 未満でなければなりません。
バケットの作成と Cloud Storage へのファイルのアップロードの詳細については、バケットを作成するとファイル システムからオブジェクトをアップロードするをご覧ください。
Oracle
この機能に関するフィードバックやサポートをご希望の場合は、bq-edw-migration-support@google.com 宛てにメールをお送りください。
メタデータとパフォーマンス統計情報を含む ZIP ファイルを Cloud Storage バケットにアップロードします。デフォルトでは、ZIP ファイルのファイル名は dwh-migration-oracle-stats.zip ですが、--output フラグで指定することでこの名前をカスタマイズできます。ZIP ファイルに含まれているすべてのファイルの非圧縮サイズの合計の上限は 50 GB です。
バケットの作成と Cloud Storage へのファイルのアップロードの詳細については、バケットの作成とファイル システムからオブジェクトのアップロードをご覧ください。
Hadoop / Cloudera
この機能に関するフィードバックやサポートをご希望の場合は、bq-edw-migration-support@google.com 宛てにメールをお送りください。
メタデータとパフォーマンス統計情報を含む ZIP ファイルを Cloud Storage バケットにアップロードします。デフォルトでは、ZIP ファイルのファイル名は dwh-migration-cloudera-manager-RUN_DATE.zip(dwh-migration-cloudera-manager-20250312T145808.zip など)ですが、--output フラグでカスタマイズできます。ZIP ファイルに含まれているすべてのファイルの非圧縮サイズの合計の上限は 50 GB です。
バケットの作成と Cloud Storage へのファイルのアップロードの詳細については、バケットを作成するとファイル システムからオブジェクトをアップロードするをご覧ください。
Apache Hive
1 つまたは複数の Hive クラスタから、クエリログを含むメタデータとフォルダを Cloud Storage バケットにアップロードします。バケットの作成と Cloud Storage へのファイルのアップロードの詳細については、バケットの作成とファイル システムからオブジェクトのアップロードをご覧ください。
メタデータ ZIP ファイルに含まれているすべてのファイルの非圧縮サイズの合計の上限は 50 GB です。
Cloud Storage コネクタを使用すると、クエリログを Cloud Storage フォルダに直接コピーできます。クエリログを含むサブフォルダを含むフォルダは、メタデータ ZIP ファイルがアップロードされるのと同じ Cloud Storage フォルダにアップロードする必要があります。
クエリログ フォルダには、dwhassessment_ という接頭辞が付いたクエリ履歴ファイルがあります。すべてのクエリ履歴ファイルの非圧縮サイズの合計の上限は 5 TB です。
BigQuery 移行評価を実行する
BigQuery 移行評価を実行する手順は次のとおりです。この手順は、前のセクションで説明したとおり、メタデータ ファイルを Cloud Storage バケットにアップロード済みであることを前提としています。
必要な権限
BigQuery Migration Service を有効にするには、次の Identity and Access Management(IAM)権限が必要です。
resourcemanager.projects.getresourcemanager.projects.updateserviceusage.services.enableserviceusage.services.get
BigQuery Migration Service にアクセスして使用するには、プロジェクトに対して次の権限が必要です。
bigquerymigration.workflows.createbigquerymigration.workflows.getbigquerymigration.workflows.listbigquerymigration.workflows.deletebigquerymigration.subtasks.getbigquerymigration.subtasks.list
BigQuery Migration Service を実行するには、次に示す追加の権限が必要です。
入出力ファイル用の Cloud Storage バケットにアクセスするための権限:
- ソース Cloud Storage バケットに対する
storage.objects.get。 - ソース Cloud Storage バケットに対する
storage.objects.list。 - 転送先の Cloud Storage バケットに対する
storage.objects.create。 - 転送先の Cloud Storage バケットに対する
storage.objects.delete。 - 転送先の Cloud Storage バケットに対する
storage.objects.update。 storage.buckets.getstorage.buckets.list
- ソース Cloud Storage バケットに対する
BigQuery Migration Service が結果を書き込む BigQuery データセットを読み取り、更新するための権限:
bigquery.datasets.updatebigquery.datasets.getbigquery.datasets.createbigquery.datasets.deletebigquery.jobs.createbigquery.jobs.deletebigquery.jobs.listbigquery.jobs.updatebigquery.tables.createbigquery.tables.getbigquery.tables.getDatabigquery.tables.listbigquery.tables.updateData
Looker Studio レポートをユーザーと共有するには、次のロールを付与する必要があります。
roles/bigquery.dataViewerroles/bigquery.jobUser
このドキュメントをカスタマイズして、コマンドで独自のプロジェクトとユーザーを使用するには、変数 PROJECT、USER_EMAIL を編集します。
BigQuery 移行評価を使用するために必要な権限を含むカスタムロールを作成します。
gcloud iam roles create BQMSrole \ --project=PROJECT \ --title=BQMSrole \ --permissions=bigquerymigration.subtasks.get,bigquerymigration.subtasks.list,bigquerymigration.workflows.create,bigquerymigration.workflows.get,bigquerymigration.workflows.list,bigquerymigration.workflows.delete,resourcemanager.projects.update,resourcemanager.projects.get,serviceusage.services.enable,serviceusage.services.get,storage.objects.get,storage.objects.list,storage.objects.create,storage.objects.delete,storage.objects.update,bigquery.datasets.get,bigquery.datasets.update,bigquery.datasets.create,bigquery.datasets.delete,bigquery.tables.get,bigquery.tables.create,bigquery.tables.updateData,bigquery.tables.getData,bigquery.tables.list,bigquery.jobs.create,bigquery.jobs.update,bigquery.jobs.list,bigquery.jobs.delete,storage.buckets.list,storage.buckets.get
カスタムロール BQMSrole をユーザーに付与します。
gcloud projects add-iam-policy-binding \ PROJECT \ --member=user:USER_EMAIL \ --role=projects/PROJECT/roles/BQMSrole
レポートを共有するユーザーに対して、必要なロールを付与します。
gcloud projects add-iam-policy-binding \ PROJECT \ --member=user:USER_EMAIL \ --role=roles/bigquery.dataViewer gcloud projects add-iam-policy-binding \ PROJECT \ --member=user:USER_EMAIL \ --role=roles/bigquery.jobUser
サポートされているロケーション
BigQuery 移行評価機能は、次の 2 種類のロケーションでサポートされています。
リージョンは、ロンドンなどの特定の地理的な場所です。
マルチリージョンは、2 つ以上のリージョンを含む広い地理的なエリアです(たとえば米国)。マルチリージョン ロケーションでは、単一のリージョンよりも大きな割り当てを提供できます。
リージョンとゾーンの詳細については、地域とリージョンをご覧ください。
リージョン
次の表に、BigQuery 移行評価を利用できる南北アメリカのリージョンを示します。| リージョンの説明 | リージョン名 | 詳細 |
|---|---|---|
| コロンバス(オハイオ州) | us-east5 |
|
| ダラス | us-south1 |
|
| アイオワ | us-central1 |
|
| サウス カロライナ | us-east1 |
|
| 北バージニア | us-east4 |
|
| オレゴン | us-west1 |
|
| ロサンゼルス | us-west2 |
|
| ソルトレイクシティ | us-west3 |
| リージョンの説明 | リージョン名 | 詳細 |
|---|---|---|
| シンガポール | asia-southeast1 |
|
| 東京 | asia-northeast1 |
| リージョンの説明 | リージョン名 | 詳細 |
|---|---|---|
| ベルギー | europe-west1 |
|
| フィンランド | europe-north1 |
|
| フランクフルト | europe-west3 |
|
| ロンドン | europe-west2 |
|
| マドリード | europe-southwest1 |
|
| オランダ | europe-west4 |
|
| パリ | europe-west9 |
|
| トリノ | europe-west12 |
|
| ワルシャワ | europe-central2 |
|
| チューリッヒ | europe-west6 |
|
マルチリージョン
次の表に、BigQuery 移行評価を利用できるマルチリージョンを示します。| マルチリージョンの説明 | マルチリージョン名 |
|---|---|
| 欧州連合の加盟国内のデータセンター | EU |
| 米国内のデータセンター | US |
始める前に
評価を実行する前に、BigQuery Migration API を有効にして、評価の結果を保存する BigQuery データセットを作成する必要があります。
BigQuery Migration API を有効にする
次のように BigQuery Migration API を有効にします。
Google Cloud コンソールで、BigQuery Migration API のページに移動します。
[有効にする] をクリックします。
評価結果のデータセットを作成する
BigQuery 移行評価では、評価結果が BigQuery のテーブルに書き込まれます。始める前に、これらのテーブルを保持するデータセットを作成します。Looker Studio レポートを共有する場合は、このデータセットを読み取る権限をユーザーに付与する必要があります。詳細については、ユーザーがレポートを利用できるようにするをご覧ください。
移行評価を実行する
コンソール
Google Cloud コンソールで、[BigQuery] ページに移動します。
ナビゲーション メニューで [評価] をクリックします。
[評価を開始] をクリックします。
[評価の設定] ダイアログに入力します。
- [表示名] に名前を入力します。名前には、文字、数字、アンダースコアを使用できます。この名前は表示専用なので、一意である必要はありません。
データのロケーションのリストで、評価ジョブのロケーションを選択します。評価ジョブは、抽出されたファイルの入力 Cloud Storage バケットと出力 BigQuery データセットと同じ場所に配置する必要があります。ただし、Cloud Storage バケットまたは BigQuery データセットがマルチリージョンにある場合、評価ジョブはこのマルチリージョン内の任意のリージョンに存在する必要があります。
評価のロケーションが
USまたはEUマルチリージョンの場合、Cloud Storage バケットのロケーションと BigQuery データセットのロケーションは、同じマルチリージョンまたはこのマルチリージョン内のロケーションに存在する必要があります。ロケーション制約の詳細については、BigQuery データ読み込みのロケーションに関する考慮事項をご覧ください。[評価データソース] で、データ ウェアハウスを選択します。
[入力ファイルのパス] に、抽出したファイルが含まれる Cloud Storage バケットへのパスを入力します。
評価結果の保存方法を選択するには、次のいずれかを行います。
- BigQuery データセットを自動的に作成するには、[新しい BigQuery データセットを自動的に作成する] チェックボックスをオンのままにします。データセットの名前は自動的に生成されます。
- [新しい BigQuery データセットを自動的に作成する] チェックボックスをオフにして、
projectId.datasetId形式を使用して既存の空の BigQuery データセットを選択するか、新しいデータセット名を作成します。このオプションでは、BigQuery データセット名を選択できます。
オプション 1 - BigQuery データセットの自動生成(デフォルト)
![[評価の設定] ダイアログ。](https://cloud.google.com/static/bigquery/images/assessment-config.png?authuser=8&hl=ja)
オプション 2 - BigQuery データセットの手動作成:
![データセットを手動で作成する [評価の設定] ダイアログ。](https://cloud.google.com/static/bigquery/images/assessment-config-manual.png?authuser=8&hl=ja)
[作成] をクリックします。ジョブのステータスは評価ジョブリストに表示されます。
評価の実行中は、ステータス アイコンのツールチップで進行状況と完了までの推定時間を確認できます。
評価の実行中に、評価ジョブのリストにある [レポートを表示] リンクをクリックすると、Looker Studio で一部のデータを含む評価レポートを表示できます。評価の実行中は、[レポートを表示] リンクが表示されるまでに時間がかかることがあります。新しいタブでレポートが開きます。
レポートは、処理されるたびに新しいデータで更新されます。レポートが開いているタブを更新するか、[レポートを表示] をもう一度クリックして、更新されたレポートを表示します。
評価が完了したら、[レポートを表示] をクリックして、Looker Studio で完全な評価レポートを表示します。新しいタブでレポートが開きます。
API
定義済みのワークフローを使用して create メソッドを呼び出します。
次に、start メソッドを呼び出して、評価ワークフローを開始します。
評価では、前に作成した BigQuery データセットにテーブルが作成されます。これらのテーブルに対してクエリを実行すると、既存データ ウェアハウスで使用されているテーブルとクエリに関する情報を照会できます。変換の出力ファイルについては、バッチ SQL トランスレータをご覧ください。
共有可能な集計された評価結果
Amazon Redshift、Teradata、Snowflake の評価では、以前に作成した BigQuery データセットに加えて、同じ名前と _shareableRedactedAggregate 接尾辞を持つ別の軽量データセットが作成されます。このデータセットには、出力データセットから派生した高度に集約されたデータが含まれており、個人を特定できる情報(PII)は含まれていません。
データセットを検索、検査、他のユーザーと安全に共有するには、移行評価の出力テーブルに対してクエリを実行するをご覧ください。
この機能はデフォルトでオンになっていますが、公開 API を使用して無効にできます。
評価の詳細
評価の詳細ページを表示するには、評価ジョブのリストで表示名をクリックします。

評価の詳細ページには、評価ジョブの詳細を表示できる [構成] タブと、評価処理中に発生したエラーを確認できる [エラー] タブがあります。
[構成] タブで、評価のプロパティを確認します。
![評価の詳細ページ - [構成] タブ。](https://cloud.google.com/static/bigquery/images/assessment-details.png?authuser=8&hl=ja)
[エラー] タブで、評価処理中に発生したエラーを確認します。
![評価の詳細ページ - [エラー] タブ。](https://cloud.google.com/static/bigquery/images/assessment-details-errors.png?authuser=8&hl=ja)
Looker Studio レポートを確認して共有する
評価タスクが完了すると、結果の Looker Studio レポートを作成して共有できます。
レポートを確認する
個々の評価タスクの横に表示されている [レポートを表示] リンクをクリックします。Looker Studio レポートが新しいタブでプレビュー モードで開きます。プレビュー モードを使用すると、レポートの内容を確認してから共有できます。
レポートは次のスクリーンショットのようになります。
レポートに含まれるビューを確認するには、使用するデータ ウェアハウスを選択します。
Teradata
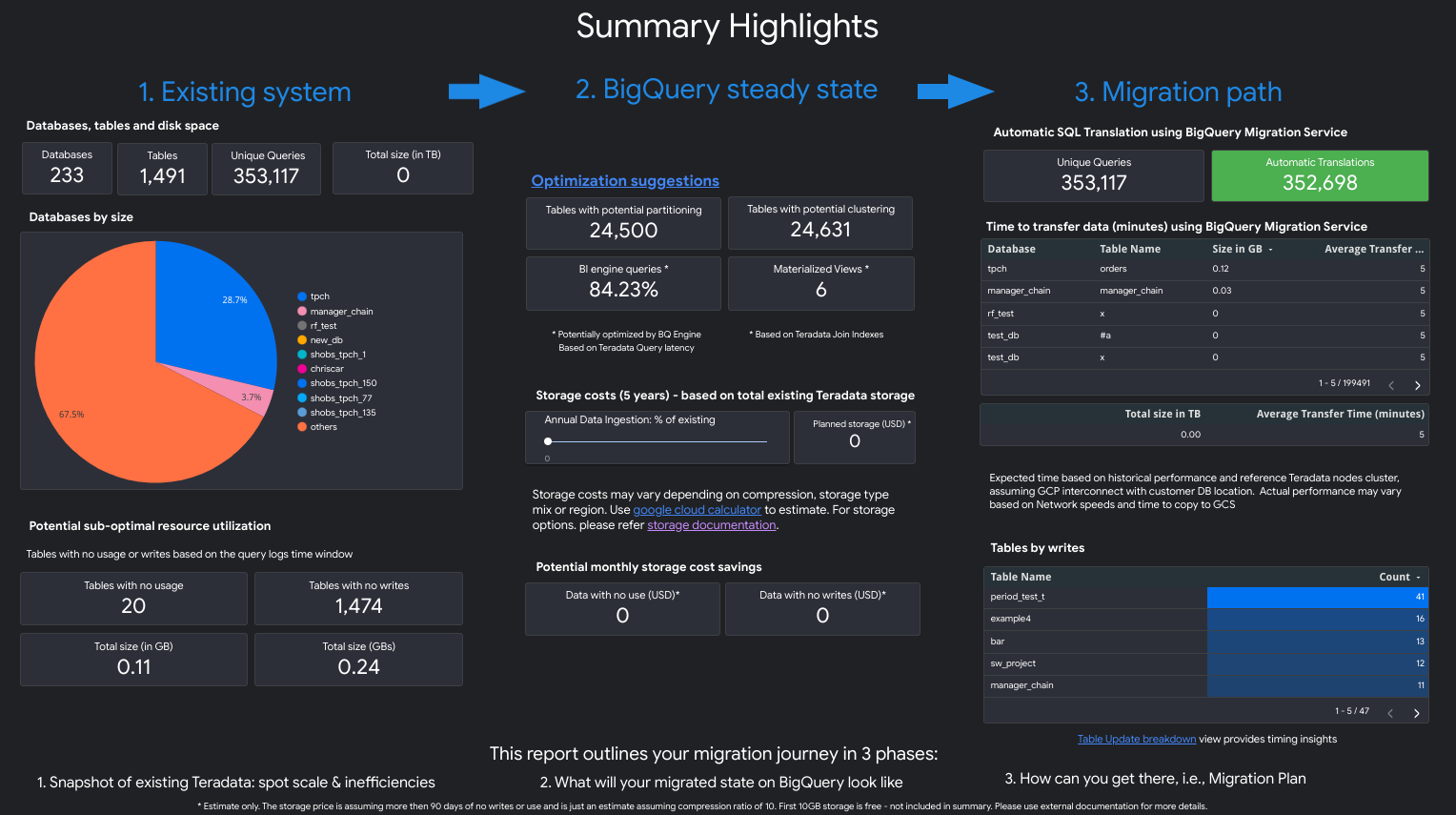
レポートは、概要ハイライトのページで始まる 3 部構成になっています。このページは以下のセクションで構成されています。
- Existing system。このセクションは、データベース、スキーマ、テーブル、合計サイズ(TB 単位)の数を含む、既存の Teradata システムと使用状況のスナップショットです。また、スキーマをサイズ別にリストし、潜在的に最適ではないリソース使用率(書き込みがまったくない、または読み取りがほとんどないテーブル)を示します。
- BigQuery steady state transformations (suggestions)。このセクションでは、移行後の BigQuery でシステムがどう表示されるかを示します。これには BigQuery のワークロードの最適化(と無駄の回避)に関する提案が含まれます。
- Migration plan。このセクションでは、移行作業自体(たとえば、既存のシステムから BigQuery の定常状態への移行)に関する情報を提供します。このセクションには、自動的に変換されたクエリの数と、各テーブルを BigQuery に移行する予想時間が含まれています。
各セクションの詳細には次の情報が含まれます。
Existing system
- コンピューティングとクエリ
- CPU 使用率:
- 1 時間あたりの平均 CPU 使用率のヒートマップ(システム リソース全体の使用率のビュー)
- CPU 使用率による時間別と日別のクエリ
- CPU 使用率を使用した種類(読み取り/書き込み)別のクエリ
- CPU 使用率があるアプリケーション
- 1 時間あたりの平均 CPU 使用率の、平均の時間ごとのクエリのパフォーマンスと平均の時間ごとのアプリケーションのパフォーマンスとの重ね合わせ
- 種類とクエリ期間別のクエリのヒストグラム
- アプリケーションの詳細ビュー(アプリ、ユーザー、一意のクエリ、レポートと ETL の内訳)
- CPU 使用率:
- ストレージの概要
- データベース(ボリューム、ビュー、アクセス率別)
- ユーザー、クエリ、書き込み、一時テーブルの作成別のアクセス率を含むテーブル
- アプリケーション: アクセスレートと IP アドレス
BigQuery steady state transformations (suggestions)
- マテリアライズド ビューに変換された結合インデックス
- メタデータと使用状況に基づくクラスタリングとパーティショニングの候補
- BigQuery BI Engine の候補として特定された低レイテンシ クエリ
- 列の説明機能を使用してデフォルト値を格納する、デフォルト値で構成された列
- (テーブル内で一意でない鍵を持つ行を防止する)Teradata の一意のインデックスは、ステージング テーブルと
MERGEステートメントを使用して、ターゲット テーブルに一意のレコードのみを挿入してから、重複を破棄します。 - そのまま変換された残りのクエリとスキーマ
Migration plan
- 自動変換されたクエリを含む詳細ビュー
- ユーザー、アプリケーション、影響を受けるテーブル、クエリされたテーブル、クエリタイプ別でフィルタリングできるクエリの合計数
- 類似パターンのクエリがグループ化され、まとめて表示されるバケット。これによりユーザーは、クエリタイプ別に変換の概念を確認できます。
- 人間による介入を必要とするクエリ
- BigQuery の語彙構造違反のあるクエリ
- ユーザー定義関数とプロシージャ
- BigQuery の予約済みキーワード
- 書き込みと読み取り別のテーブル一覧(移動用にグループ化)
- BigQuery Data Transfer Service を使用したデータ移行: テーブル別の移行の推定所要時間
[Existing System] セクションには次のビューが表示されます。
- System Overview
- [System Overview] ビューでは、特定の期間における既存のシステムの主要コンポーネントのボリューム指標の概要を確認できます。評価されるタイムラインは、BigQuery 移行評価で分析されたログによって異なります。このビューでは、移行計画に使用できる移行元のデータ ウェアハウスの使用率をすばやく分析した情報を提供します。
- Table Volume
- [Table Volume] ビューには、BigQuery 移行評価で見つかった最大のテーブルとデータベースに関する統計情報が表示されます。大規模なテーブルはソースデータ ウェアハウス システムからの抽出に時間がかかることがあるため、移行の計画と順序付けにはこのビューが役立ちます。
- Table Usage
- [Table Usage] ビューには、ソースデータ ウェアハウス システム内で頻繁に使用されるテーブルに関する統計情報が表示されます。頻繁に使用するテーブルは、依存関係が多い可能性のあるテーブルを把握し、移行プロセス中に追加の計画を必要とする場合に役立ちます。
- アプリケーション
- [Applications Usage] ビューと [Applications Patterns] ビューには、ログの処理中に見いだされたアプリケーションの統計情報が表示されます。これらのビューにより、ユーザーは特定のアプリケーションの使用状況の推移と、リソース使用量への影響を把握できます。移行する際は、データの取り込みと消費を可視化して、データ ウェアハウスの依存関係をよく理解し、さまざまな依存アプリケーションの一緒の移行による影響を分析することが重要です。IP アドレス テーブルは、JDBC 接続でデータ ウェアハウスを使用しているアプリケーションを正確に特定するために役立ちます。
- Queries
- [Queries] ビューには、実行された SQL ステートメントの種類の内訳と使用状況の統計情報が表示されます。クエリタイプと時間のヒストグラムを使用すると、システム使用率の低い期間やデータ転送に最適な時間帯を特定できます。このビューを使用して、頻繁に実行されるクエリと、その実行を呼び出したユーザーを特定することもできます。
- Databases
- [Databases] ビューには、ソースデータ ウェアハウス システムで定義されたサイズ、テーブル、ビュー、プロシージャの指標が表示されます。このビューでは、移行する必要があるオブジェクトのボリュームに関する分析情報が得られます。
- Database Coupling
- [Database Coupling] ビューには、単一のクエリでまとめてアクセスされるデータベースとテーブルの概要が表示されます。このビューでは、頻繁に参照されるテーブルとデータベース、また移行計画に使用できるテーブルとデータベースが示されます。
[BigQuery steady state] セクションには、次のビューが含まれます。
- Tables With No Usage
- [Tables With No Usage] ビューには、分析対象のログの期間中に BigQuery 移行評価で使用量が検出されなかったテーブルが表示されます。使用量がないことは、移行中にそのテーブルを BigQuery に転送する必要がないか、BigQuery にデータを保存する費用を削減できることを示す場合があります。未使用のテーブルのリストを検証する必要があります。これは、3 か月または 6 か月に 1 回だけ使用されるテーブルなど、ログ期間外での使用状況がある可能性があるためです。
- Tables With No Writes
- [Tables With No Writes] ビューには、分析対象のログの期間中に BigQuery 移行評価で更新が検出されなかったテーブルが表示されます。書き込みがないことは、BigQuery でストレージ コストを削減できる場所を示している可能性があります。
- Low-Latency Queries
- [Low-Latency Queries] ビューには、分析したログデータに基づくクエリ ランタイムの分布が表示されます。クエリ実行時間の分布グラフに、実行時間が 1 秒未満の多数のクエリが表示される場合は、BigQuery BI Engine が BI やその他の低レイテンシ ワークロードを高速化できるようにすることを検討してください。
- マテリアライズド ビュー
- マテリアライズド ビューは、BigQuery のパフォーマンス向上のさらなる最適化提案を提供します。
- Clustering and Partitioning
[Clustering and Partitioning] ビューには、パーティショニング、クラスタリング、またはその両方に役立つテーブルが表示されます。
メタデータの提案は、ソースデータ ウェアハウスのスキーマ(ソーステーブルのパーティショニングと主キーなど)を分析し、同様の最適化特性を実現するために最も近い BigQuery の同等物を見つけることによって実現されます。
ワークロードの提案は、ソースクエリのログの分析によって実現します。推奨事項は、ワークロード(特に分析対象のクエリログの
WHERE句またはJOIN句)の分析によって決定されます。- Clustering Recommendation
[Partitioning] ビューには、パーティショニング制約の定義に基づいて、パーティションが 10,000 を超える可能性のあるテーブルが表示されます。こうしたテーブルは、きめ細かいテーブル パーティションを可能にする BigQuery のクラスタリングに適しています。
- Unique Constraints
[Unique Constraints] ビューには、ソースデータ ウェアハウス内で定義された
SETテーブルと一意のインデックスの両方が表示されます。BigQuery では、ステージング テーブルとMERGEステートメントを使用して、ターゲット テーブルに一意のレコードのみを挿入することをおすすめします。このビューのコンテンツは、移行中に ETL の調整が必要なテーブルを確認するのに役立ちます。- Default Values / Check Constraints
このビューには、チェック制約を使用してデフォルトの列値を設定するテーブルが表示されます。BigQuery で、デフォルトの列の値を指定するをご覧ください。
レポートの [Migration path] セクションには、次のビューが含まれています。
- SQL Translation
- [SQL Translation] ビューには、BigQuery 移行評価によって自動的に変換され、手動での操作が不要なクエリの数と詳細が表示されます。メタデータが提供されている場合は通常、自動 SQL 変換で高い変換率が実現されます。このビューはインタラクティブであり、一般的なクエリとその変換方法を分析できます。
- Offline Effort
- [Offline Effort] ビューには、特定の UDF と、テーブルまたは列の潜在的な語彙の構造と構文の違反など、手動での操作が必要な領域のキャプチャが表示されます。
- BigQuery Reserved Keywords
- [BigQuery Reserved Keywords] ビューには、GoogleSQL 言語で特殊な意味を持ち、識別子として使用するにはバッククォート(
`)文字で囲む必要があるキーワードに関して検出された使用状況が表示されます。 - Table Updates Schedule
- [Table Updates Schedule] ビューには、テーブルの更新のタイミングと頻度が表示されます。これは、テーブルの移動方法とタイミングを決定するのに役立ちます。
- Data Migration to BigQuery
- [Data Migration to BigQuery] ビューには、BigQuery Data Transfer Service を使用したデータの移行に予想される時間とその移行パスが示されます。詳細については、Teradata 用 BigQuery Data Transfer Service ガイドをご覧ください。
[Appendix] セクションには次のビューがあります。
- Case Sensitivity
- [Case Sensitivity] ビューには、大文字と小文字を区別しない比較を実行するように構成されたソースデータ ウェアハウス内のテーブルが表示されます。 デフォルトでは、BigQuery の文字列比較では大文字と小文字が区別されます。詳細については、照合順序をご覧ください。
Redshift
- Migration Highlights
- [Migration Highlights] ビューには、レポートの 3 つのセクションの概要が表示されます。
- [Existing System] パネルには、データベース、スキーマ、テーブルの数、および既存の Redshift システムの合計サイズに関する情報が表示されます。また、スキーマをサイズ別に一覧表示し、潜在的に最適ではないリソース使用率も示します。テーブルを削除、パーティショニング、クラスタリングするときにこの情報を使用できます。
- [BigQuery Steady State] パネルに、BigQuery でデータが移行後にどのようになるかに関する情報(BigQuery 移行サービスを使用して自動的に変換できるクエリの数など)が表示されます。また、このセクションには、年間データ取り込み率に基づいてデータを BigQuery に保存するのにかかる費用とともに、テーブル、プロビジョニング、スペースの最適化に関する提案も表示されます。
- [Migration Path] パネルには、移行処理自体に関する情報が表示されます。テーブルごとに、予想される移行時間、テーブル内の行数、サイズが表示されます。
[Existing System] セクションには次のビューが表示されます。
- Queries by Type and Schedule
- [Queries by Type and Schedule] ビューでは、クエリが ETL/書き込みとレポート/集計に分類されます。クエリの組み合わせを時系列で確認すると、既存の使用パターンを把握し、コストとパフォーマンスに影響する可能性のあるバースト性とオーバープロビジョニングを特定するのに役立ちます。
- Query Queuing
- [Query Queuing] ビューには、クエリの量、組み合わせ、キューイングによるパフォーマンスへの影響(リソースの不足など)など、システム負荷に関する追加の詳細が表示されます。
- Queries and WLM Scaling
- [Queries and WLM Scaling] ビューでは、同時実行スケーリングは、追加のコストと複雑な構成が必要であるものと識別されます。Redshift では、指定したルールに基づいてクエリがどのようにルーティングされるか、キューイング、同時実行のスケーリング、強制排除されたクエリによるパフォーマンスへの影響が示されます。
- Queuing and Waiting
- [Queuing and Waiting] ビューでは、時間の経過に伴うキューと待機時間の詳細を確認できます。
- WLM Classes and Performance
- [WLM Classes and Performance] ビューでは、ルールを BigQuery にマッピングできます。ただし、BigQuery にクエリを自動的にルーティングさせるようにすることをおすすめします。
- Query & Table volume insights
- [Query & Table volume insights] ビューには、クエリがサイズ、頻度、上位ユーザーに基づいて一覧表示されます。これにより、システムに対する負荷の原因を分類し、ワークロードの移行方法を計画できます。
- Databases and Schemas
- [Databases and Schemas] ビューには、ソースデータ ウェアハウス システムで定義されているサイズ、テーブル、ビュー、プロシージャの指標が表示されます。これにより、移行する必要があるオブジェクトの量に関する分析情報が得られます。
- Table Volume
- [Table Volume] ビューには、最も大きなテーブルとデータベースに関する統計情報と、これらのテーブルとデータベースへのアクセス方法が表示されます。大規模なテーブルはソースデータ ウェアハウス システムからの抽出に時間がかかることがあるため、移行の計画と順序付けの際にこのビューが役立ちます。
- Table Usage
- [Table Usage] ビューには、ソースデータ ウェアハウス システム内で頻繁に使用されるテーブルに関する統計情報が表示されます。頻繁に使用されるテーブルから、多くの依存関係を持つ可能性があるテーブルを把握し、移行プロセス中に追加の計画を立てることができます。
- Importers & Exporters
- [Importers & Exporters] ビューには、データ インポート(
COPYクエリを使用)とデータ エクスポート(UNLOADクエリを使用)に関与するデータとユーザーに関する情報が表示されます。このビューは、取り込みとエクスポートに関連するステージング レイヤとプロセスを特定するのに役立ちます。 - クラスタの使用率
- [クラスタの使用率] ビューには、使用可能なすべてのクラスタに関する全般情報が提供され、各クラスタの CPU 使用率が表示されます。このビューは、システムの容量の予約を把握するのに役立ちます。
[BigQuery steady state] セクションには、次のビューが含まれます。
- Clustering & Partitioning
[Clustering and Partitioning] ビューには、パーティショニング、クラスタリング、またはその両方に役立つテーブルが表示されます。
メタデータの提案は、ソースデータ ウェアハウスのスキーマ(ソーステーブルのソートキーと Dist キーなど)を分析し、同様の最適化特性を実現するために最も近い BigQuery の同等物を見つけることによって実現されます。
ワークロードの提案は、ソースクエリのログの分析によって実現します。推奨事項は、ワークロード(特に分析対象のクエリログの
WHERE句またはJOIN句)の分析によって決定されます。ページの下部には、すべての最適化が適用された変換済み create テーブル ステートメントが表示されます。変換されたすべての DDL ステートメントは、データセットから抽出することもできます。変換された DDL ステートメントは、
SchemaConversionテーブルのCreateTableDDL列に格納されます。レポートの推奨事項は、1 GB を超えるテーブルに対してのみ提供されます。小さなテーブルでは、クラスタリングとパーティショニングのメリットが得られないためです。ただし、すべてのテーブル(1 GB 未満のテーブルを含む)の DDL を
SchemaConversionテーブルで使用できます。- Tables With No Usage
[Tables With No Usage] ビューには、分析対象のログの期間中に BigQuery 移行評価で使用が検出されなかったテーブルが表示されます。使用量がないことは、移行中にそのテーブルを BigQuery に転送する必要がないか、BigQuery にデータを保存する費用を削減できることを示す場合があります(長期保存ストレージとして請求されます)。未使用のテーブルのリストを検証することをおすすめします。これは、3 か月または 6 か月に 1 回だけ使用されるテーブルなど、ログ期間外での使用状況がある可能性があるためです。
- Tables With No Writes
[Tables With No Writes] ビューには、分析対象のログの期間中に BigQuery 移行評価で更新が検出されなかったテーブルが表示されます。書き込みがないことは、BigQuery でストレージ コストを削減できる場所を示している可能性があります(長期保存として請求されます)。
- BigQuery BI Engine and Materialized Views
[BigQuery BI Engine and Materialized Views] には、BigQuery のパフォーマンスを向上させるための最適化に関するその他の推奨事項が示されます。
[Migration path] セクションには、次のビューが表示されます。
- SQL Translation
- [SQL Translation] ビューには、BigQuery 移行評価によって自動的に変換され、手動での操作が不要なクエリの数と詳細が表示されます。メタデータが提供されている場合は通常、自動 SQL 変換で高い変換率が実現されます。
- SQL Translation Offline Effort
- [SQL Translation Offline Effort] ビューでは、特定の UDF や変換のあいまいさがあるクエリなど、手動での操作が必要な領域が表示されます。
- Alter Table Append Support
- [Alter Table Append Support] ビューには、BigQuery に直接対応していない一般的な Redshift SQL コンストラクトの詳細が表示されます。
- Copy Command Support
- [Copy Command Support] ビューには、BigQuery に直接対応していない一般的な Redshift SQL コンストラクトの詳細が表示されます。
- SQL Warnings
- [SQL Warnings] ビューには、正常に変換されたものの、レビューが必要な領域が表示されます。
- Lexical Structure & Syntax Violations
- [Lexical Structure & Syntax Violations] ビューには、BigQuery の構文に違反している列、テーブル、関数、プロシージャの名前が表示されます。
- BigQuery Reserved Keywords
- [BigQuery Reserved Keywords] ビューには、GoogleSQL 言語で特殊な意味を持ち、識別子として使用するにはバッククォート(
`)文字で囲む必要があるキーワードに関して検出された使用状況が表示されます。 - Schema Coupling
- [Schema Coupling] ビューには、単一のクエリでまとめてアクセスされるデータベース、スキーマ、テーブルの概要が表示されます。このビューでは、頻繁に参照されるテーブル、スキーマ、データベース、また移行計画に使用できるテーブルとデータベースが示されます。
- Table Updates Schedule
- [Table Updates Schedule] ビューには、テーブルの更新のタイミングと頻度が表示されます。これは、テーブルの移動方法とタイミングを決定するのに役立ちます。
- Table Scale
- [Table Scale] ビューには、列が最も多いテーブルが一覧表示されます。
- Data Migration to BigQuery
- [Data Migration to BigQuery] ビューには、BigQuery Data Transfer Service を使用したデータの移行に予想される時間とその移行パスが示されます。詳細については、Redshift 用 BigQuery Data Transfer Service ガイドをご覧ください。
- 評価の実行の概要
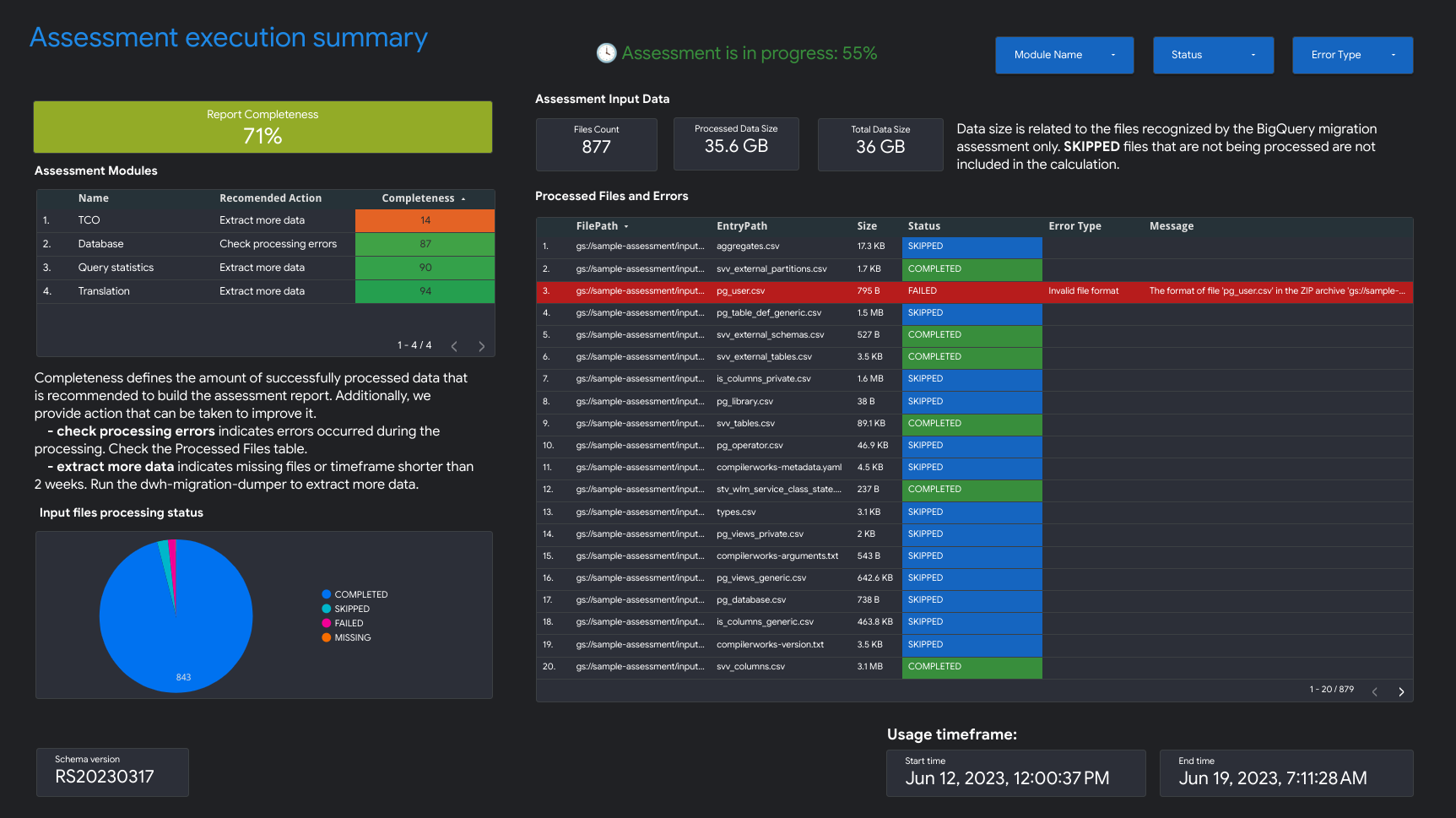
評価の実行の概要には、レポートの完全性、進行中の評価の進捗状況、処理されたファイルとエラーのステータスが含まれます。
レポートの完全性は、評価レポートに有用な分析情報を表示するために推奨される、正常に処理されたデータの割合を表します。レポートの特定のセクションのデータが欠落している場合、この情報は [Assessment Modules] の表の [Report Completeness] インジケーターに表示されます。
進行状況の指標は、これまでに処理されたデータの割合と、すべてのデータが処理されるまでのおおよその時間を示します。処理が完了すると、進行状況の指標は表示されなくなります。
Redshift Serverless
- Migration Highlights
- このレポートページには、既存の Amazon Redshift Serverless データベースの概要(サイズやテーブル数など)が表示されます。また、年間契約額(ACV)(BigQuery のコンピューティングとストレージの費用)の見積もりも表示されます。[Migration Highlights] ビューには、レポートの 3 つのセクションの概要が表示されます。
[Existing System] セクションには次のビューが表示されます。
- Databases and Schemas
- 各データベース、スキーマ、テーブルの合計ストレージ サイズ(GB 単位)の内訳が表示されます。
- External Databases and Schemas
- 各外部データベース、スキーマ、テーブルの合計ストレージ サイズ(GB 単位)の内訳が表示されます。
- System Utilization
- 過去のシステム使用率に関する全般的な情報が表示されます。このビューには、過去の RPU(Amazon Redshift Processing Units)の使用量と 1 日あたりのストレージ消費量が表示されます。このビューは、システムの容量の予約を把握する際に役立ちます。
[BigQuery Steady State] セクションには、BigQuery でデータが移行後にどのようになるかに関する情報(BigQuery 移行サービスを使用して自動的に変換できるクエリの数など)が表示されます。また、このセクションには、年間データ取り込み率に基づいてデータを BigQuery に保存するのにかかる費用とともに、テーブル、プロビジョニング、スペースの最適化に関する提案も表示されます。[Steady State] セクションには、次のビューがあります。
- Amazon Redshift Serverless versus BigQuery pricing
- Amazon Redshift Serverless と BigQuery の料金モデルの比較が表示されます。BigQuery への移行後のメリットと削減可能な費用を把握できます。
- BigQuery Compute Cost(TCO)
- BigQuery のコンピューティング費用を見積もることができます。計算ツールには、手動で入力する項目として、BigQuery エディション、リージョン、コミット期間、ベースラインの 4 つがあります。デフォルトでは、計算ツールは最適で費用対効果の高いベースライン コミットメントを提供します。このコミットメントは手動でオーバーライドできます。
- Total Cost of Ownership
- 年間契約額(ACV)(BigQuery のコンピューティングとストレージの費用)を見積もることができます。この計算ツールでは、ストレージ費用も計算できます。ストレージ費用は、分析対象期間のテーブルの変更に応じて、アクティブ ストレージと長期保存ストレージで異なります。詳細については、ストレージの料金をご覧ください。
[Appendix] セクションには、次のビューが表示されます。
- Assessment Execution Summary
- 処理されたファイルのリスト、エラー、レポートの完全性など、評価の実行に関する詳細が表示されます。このページでは、レポートに欠落しているデータを調査し、レポートの完全性を把握することができます。
Snowflake
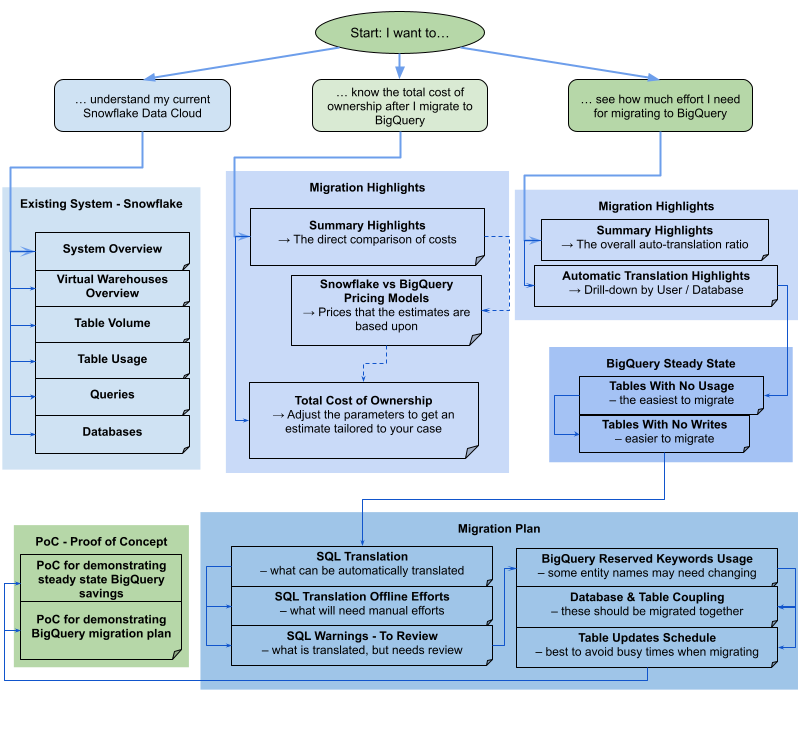
レポートは、個別または一緒に使用できるさまざまなセクションで構成されています。移行ニーズの評価に役立つように、次の図ではこれらのセクションを 3 つの一般的なユーザーの目的に分類しています。
Migration Highlights ビュー
[Migration Highlights] セクションには、次のビューが含まれています。
- Snowflake versus BigQuery Pricing Models
- 階層 / エディション別の料金リストです。また、Snowflake と比較して BigQuery の自動スケーリングの方が費用を節約できることを示す図も含まれています。
- Total Cost of Ownership
- BigQuery エディション、コミットメント、ベースライン スロット コミットメント、アクティブ ストレージの割合、読み込みまたは変更されたデータの割合をユーザーが定義できるインタラクティブなテーブルです。カスタムケースの費用をより正確に見積もるのに役立ちます。
- Automatic Translation Highlights
- ユーザーまたはデータベースごとにグループ化された、昇順または降順の変換率の集計。失敗した自動変換についての最も多いエラー メッセージも含まれます。
Existing System ビュー
[Existing System] セクションには次のビューが表示されます。
- System Overview
- [System Overview] ビューでは、特定の期間における既存のシステムの主要コンポーネントのボリューム指標の概要を確認できます。評価されるタイムラインは、BigQuery 移行評価で分析されたログによって異なります。このビューでは、移行計画に使用できるソースデータ ウェアハウスの使用率をすばやく分析した情報を提供します。
- Virtual Warehouses Overview
- ウェアハウスごとの Snowflake の費用と、期間中に行われたノードベースの再スケーリングが表示されます。
- Table Volume
- [Table Volume] ビューには、BigQuery 移行評価で見つかった最大のテーブルとデータベースに関する統計情報が表示されます。大規模なテーブルはソースデータ ウェアハウス システムからの抽出に時間がかかることがあるため、移行の計画と順序付けにはこのビューが役立ちます。
- Table Usage
- [Table Usage] ビューには、ソースデータ ウェアハウス システム内で頻繁に使用されるテーブルに関する統計情報が表示されます。頻繁に使用するテーブルは、依存関係が多い可能性のあるテーブルを把握し、移行プロセス中に追加の計画を必要とする場合に役立ちます。
- Queries
- [Queries] ビューには、実行された SQL ステートメントの種類の内訳と使用状況の統計情報が表示されます。クエリタイプと時間のヒストグラムを使用すると、システム使用率の低い期間やデータ転送に最適な時間帯を特定できます。このビューを使用して、頻繁に実行されるクエリと、その実行を呼び出したユーザーを特定することもできます。
- Databases
- [Databases] ビューには、ソースデータ ウェアハウス システムで定義されたサイズ、テーブル、ビュー、プロシージャの指標が表示されます。このビューでは、移行する必要があるオブジェクトのボリュームに関する分析情報が得られます。
BigQuery steady state ビュー
[BigQuery steady state] セクションには、次のビューが含まれます。
- Tables With No Usage
- [Tables With No Usage] ビューには、分析対象のログの期間中に BigQuery 移行評価で使用量が検出されなかったテーブルが表示されます。これは、移行中に BigQuery に転送する必要がないテーブルや、BigQuery にデータを保存する費用を削減できることを示している可能性があります。未使用のテーブルは、分析されたログ期間外に使用されている可能性があるため、未使用のテーブルのリストを検証する必要があります。たとえば、四半期または半期に 1 回だけ使用されるテーブルなどが該当します。
- Tables With No Writes
- [Tables With No Writes] ビューには、分析対象のログの期間中に BigQuery 移行評価で更新が検出されなかったテーブルが表示されます。これは、BigQuery にデータを保存するコストを削減できる可能性があることを示しています。
Migration Plan ビュー
レポートの [Migration path] セクションには、次のビューが含まれています。
- SQL Translation
- [SQL Translation] ビューには、BigQuery 移行評価によって自動的に変換され、手動での操作が不要なクエリの数と詳細が表示されます。メタデータが提供されている場合は通常、自動 SQL 変換で高い変換率が実現されます。このビューはインタラクティブであり、一般的なクエリとその変換方法を分析できます。
- SQL Translation Offline Effort
- [Offline Effort] ビューには、特定の UDF と、テーブルまたは列の潜在的な語彙の構造と構文の違反など、手動での操作が必要な領域のキャプチャが表示されます。
- SQL Warnings - To Review
- [Warnings To Review] ビューには、大部分が変換されているものの、人間による検査が必要な領域が表示されます。
- BigQuery Reserved Keywords
- [BigQuery Reserved Keywords] ビューには、GoogleSQL 言語で特殊な意味を持ち、識別子として使用するにはバッククォート(
`)文字で囲む必要があるキーワードに関して検出された使用状況が表示されます。 - Database and Table Coupling
- [Database Coupling] ビューには、単一のクエリでまとめてアクセスされるデータベースとテーブルの概要が表示されます。このビューでは、頻繁に参照されるテーブルとデータベース、および移行計画に使用できるテーブルとデータベースを確認できます。
- Table Updates Schedule
- [Table Updates Schedule] ビューには、テーブルの更新のタイミングと頻度が表示されます。これは、テーブルの移動方法とタイミングを決定するのに役立ちます。
Proof of Concept ビュー
[PoC](概念実証)セクションには、次のビューが表示されます。
- PoC for demonstrating steady state BigQuery savings
- 最も頻繁に発生するクエリ、最も多くのデータを読み取るクエリ、最も遅いクエリ、これらのクエリの影響を受けるテーブルが含まれます。
- PoC for demonstrating BigQuery migration plan
- BigQuery が、最も複雑なクエリと、そのクエリが影響を与えるテーブルをどのように変換するかを説明します。
Oracle
この機能に関するフィードバックやサポートをご希望の場合は、bq-edw-migration-support@google.com 宛てにメールをお送りください。
Migration Highlights
[Migration Highlights] セクションには、次のビューが含まれています。
- [Existing system]: データベース、スキーマ、テーブルの数、合計サイズ(GB 単位)など、既存の Oracle システムと使用状況のスナップショット。また、各データベースのワークロード分類の概要も提供されるため、BigQuery が適切な移行ターゲットかどうかを判断できます。
- [Compatibility]: 移行作業自体に関する情報を提供します。分析されたデータベースごとに、移行の予想所要時間と、Google 提供のツールで自動的に移行できるデータベース オブジェクトの数が表示されます。
- [BigQuery steady state]: BigQuery への移行後にデータがどのような状態になるかに関する情報(年間データ取り込み率に基づく BigQuery へのデータの保存費用とコンピューティング費用の見積もりなど)が含まれます。また、使用率の低いテーブルに関する分析情報も提供されます。
Existing System
[Existing System] セクションには次のビューが表示されます。
- [Workloads Characteristic]: 分析されたパフォーマンス指標に基づいて、各データベースのワークロード タイプを示します。各データベースは、OLAP、混在、OLTP に分類されます。この情報は、BigQuery に移行できるデータベースを決定する際に役立ちます。
- Databases and Schemas: 各データベース、スキーマ、テーブルの合計ストレージ サイズ(GB 単位)の内訳が表示されます。また、このビューを使用して、マテリアライズド ビューと外部テーブルを特定することもできます。
- Database Features and Links: データベースで使用されている Oracle 機能のリストと、移行後に使用できる BigQuery の同等の機能またはサービスが表示されます。また、データベース リンクを調べて、データベース間の接続を詳しく把握することもできます。
- Database Connections: ユーザーまたはアプリケーションによって開始されたデータベース セッションに関する分析情報が表示されます。このデータを分析すると、移行時に追加の作業が必要になる可能性のある外部アプリケーションを特定できます。
- Query Types: 実行された SQL ステートメントの種類の内訳と使用状況の統計情報が表示されます。クエリの実行数またはクエリの CPU 時間を示す 1 時間ごとのヒストグラムを使用して、システム使用率の低い期間やデータ転送に最適な時間帯を特定できます。
- PL/SQL Source Code: PL/SQL オブジェクト(関数、プロシージャなど)や、各データベースとスキーマのサイズに関する分析情報が表示されます。また、1 時間ごとの実行ヒストグラムを使用して、PL/SQL の実行が集中するピーク時間を特定することもできます。
- [System Utilization]: 過去のシステム使用状況に関する全般的な情報を提供します。このビューには、1 時間あたりの CPU 使用量と 1 日あたりのストレージ消費量が表示されます。このビューは、システムの容量の予約を把握するのに役立ちます。
BigQuery Steady State
[BigQuery steady state] セクションには、次のビューが含まれます。
- Exadata vs BigQuery pricing: Exadata と BigQuery の料金モデルの一般的な比較が表示されます。BigQuery への移行後のメリットと削減可能な費用を把握できます。
- BigQuery Database Read/Writes: データベースの物理ディスク オペレーションに関する分析情報が表示されます。このデータを分析すると、Oracle から BigQuery へのデータ移行を実施するのに最適なタイミングを特定できます。
- BigQuery Compute Cost: BigQuery のコンピューティング費用を見積もることができます。計算ツールには、手動で入力する項目として、BigQuery エディション、リージョン、コミット期間、ベースラインの 4 つがあります。デフォルトでは、計算ツールは最適で費用対効果の高いベースライン コミットメントを提供します。このコミットメントは手動でオーバーライドできます。[Annual Autoscaling Slot Hours] の値は、コミットメントの外で使用されるスロット時間数を示します。この値はシステム使用率を使用して計算されます。ベースライン、自動スケーリング、使用率の関係を視覚的に示した図がページの最後にあります。それぞれの推定について、確率が高い数と推定範囲が示されます。
- [Total Cost of Ownership (TCO)]: 年間契約額(ACV)(BigQuery のコンピューティングとストレージの費用)を見積もることができます。この計算ツールでは、ストレージ費用も計算できます。この計算ツールでは、ストレージ費用も計算できます。ストレージ費用は、分析対象期間のテーブルの変更に応じて、アクティブ ストレージと長期保存ストレージで異なります。ストレージの料金については、ストレージの料金をご覧ください。
- [Underutilized Tables]: 分析対象期間の使用状況の指標に基づいて、未使用のテーブルと読み取り専用のテーブルに関する情報を提供します。使用量がないことは、移行中にそのテーブルを BigQuery に転送する必要がないか、BigQuery にデータを保存する費用を削減できることを示す場合があります(長期保存ストレージとして請求されます)。未使用のテーブルが分析対象期間外に使用されている可能性があるため、未使用のテーブルのリストを検証することをおすすめします。
Migration Hints
[Migration Hints] セクションには、次のビューが表示されます。
- [Database Objects Compatibility]: Google 提供のツールで自動的に移行できるオブジェクトの数や、手動による対策が必要なオブジェクトの数など、BigQuery とデータベース オブジェクトの互換性の概要を提供します。この情報は、データベース、スキーマ、データベース オブジェクト タイプごとに表示されます。
- [Database Objects Migration Effort]: データベース、スキーマ、データベース オブジェクト タイプごとに、移行作業の見積もりを時間単位で示します。また、移行作業に基づいて、小さいオブジェクト、中くらいのオブジェクト、大きいオブジェクトの割合も表示されます。
- [Database Schema Migration Effort]: 検出されたすべてのデータベース オブジェクト タイプ、その数、BigQuery との互換性、移行作業の推定時間(時間単位)のリストを提供します。
- [Database Schema Migration Effort Detailed]: データベース スキーマの移行作業に関する詳細な分析情報を提供します。個々のオブジェクトに関する情報も含まれます。
Proof of Concept views
[Proof of Concept views] セクションには、次のビューが表示されます。
- Proof of concept migration: 移行作業が最も少なく、初期移行の有力な候補として推奨されるデータベースのリストが表示されます。また、概念実証を通じて時間と費用の節約や、BigQuery の価値を示す際に役立つ上位のクエリも表示されます。
付録
[Appendix] セクションには、次のビューが表示されます。
- [Assessment Execution Summar]: 処理されたファイルのリスト、エラー、レポートの完全性など、評価の実行に関する詳細を提供します。このページを使用して、レポートに欠落しているデータを調査し、レポート全体の完全性を詳しく把握できます。
Apache Hive
3 部構成のレポートの最初に、次のセクションを含む概要ページがあります。
Existing System - Apache Hive。このセクションは、既存の Apache Hive システムのスナップショットと、データベースとテーブルの数、それらの合計サイズ(GB 単位)、処理されたクエリログの数などを含む使用状況で構成されています。このセクションでは、データベースをサイズ別に一覧表示し、最適ではない可能性があるリソース使用率(書き込みがないか、読み取りがほとんどないテーブル)とプロビジョニングを示します。このセクションの詳細は次のとおりです。
- コンピューティングとクエリ
- CPU 使用率:
- CPU 使用率による時間別と日別のクエリ
- タイプ(読み取り/書き込み)別のクエリ
- キューとアプリケーション
- 1 時間あたりの平均 CPU 使用率の、平均の時間ごとのクエリのパフォーマンスと平均の時間ごとのアプリケーションのパフォーマンスとの重ね合わせ
- 種類とクエリ期間別のクエリのヒストグラム
- キューと待機ページ
- キューの詳細ビュー(キュー、ユーザー、一意のクエリ、レポートと ETL の内訳、指標別)
- CPU 使用率:
- ストレージの概要
- データベース(ボリューム、ビュー、アクセス率別)
- ユーザー、クエリ、書き込み、一時テーブルの作成別のアクセス率を含むテーブル
- キューとアプリケーション: アクセスレートとクライアント IP アドレス
- コンピューティングとクエリ
BigQuery Steady State。 このセクションでは、移行後の BigQuery でシステムがどう表示されるかを示します。これには BigQuery のワークロードの最適化(と無駄の回避)に関する提案が含まれます。このセクションの詳細は次のとおりです。
- マテリアライズド ビューの候補として識別されたテーブル。
- メタデータと使用状況に基づくクラスタリングとパーティショニングの候補。
- BigQuery BI Engine の候補として特定された低レイテンシ クエリ。
- 読み取りまたは書き込みがないテーブル。
- データスキューのあるパーティション分割テーブル。
Migration Plan。このセクションでは、移行作業自体について説明します。たとえば、既存のシステムから BigQuery の定常状態への移行などです。このセクションには、各テーブルで識別されたストレージ ターゲット、移行に重要と識別されたテーブル、自動的に変換されたクエリの数が含まれます。このセクションの詳細は次のとおりです。
- 自動変換されたクエリを含む詳細ビュー
- ユーザー、アプリケーション、影響を受けるテーブル、クエリされたテーブル、クエリタイプ別でフィルタリングできるクエリの合計数。
- 類似パターンがグループ化されたクエリバケット。これにより、ユーザーはクエリタイプごとに変換の概念を確認できます。
- 人間による介入を必要とするクエリ
- BigQuery の語彙構造違反のあるクエリ
- ユーザー定義関数とプロシージャ
- BigQuery の予約済みキーワード
- レビューが必要なクエリ
- 書き込みと読み取り別のテーブル一覧(移動用にグループ化)
- 外部テーブルおよびマネージド テーブルのための特定されたストレージ ターゲット
- 自動変換されたクエリを含む詳細ビュー
[Existing System - Hive] セクションには次のビューが表示されます。
- System Overview
- このビューでは、特定の期間における既存のシステムの主要コンポーネントのボリューム指標の概要を確認できます。評価されるタイムラインは、BigQuery 移行評価で分析されたログによって異なります。このビューでは、移行計画に使用できる移行元のデータ ウェアハウスの使用率をすばやく分析した情報を提供します。
- Table Volume
- このビューには、BigQuery 移行評価で検出された最大のテーブルとデータベースに関する統計情報が表示されます。大規模なテーブルはソースデータ ウェアハウス システムからの抽出に時間がかかることがあるため、移行の計画と順序付けにはこのビューが役立ちます。
- Table Usage
- このビューには、ソースデータ ウェアハウス システム内で頻繁に使用されるテーブルに関する統計情報が表示されます。頻繁に使用するテーブルは、依存関係が多い可能性のあるテーブルを把握し、移行プロセス中に追加の計画を必要とする場合に役立ちます。
- Queues Utilization
- このビューには、ログの処理中に見つかった YARN キューの使用状況に関する統計情報が表示されます。これらのビューにより、ユーザーは特定のキューとアプリケーションの使用状況の推移と、リソース使用量への影響を把握できます。これらのビューは、移行するワークロードを特定して優先順位を付ける際にも役立ちます。移行する際は、データの取り込みと消費を可視化して、データ ウェアハウスの依存関係をよく理解し、さまざまな依存アプリケーションの一緒の移行による影響を分析することが重要です。IP アドレス テーブルは、JDBC 接続でデータ ウェアハウスを使用しているアプリケーションを正確に特定するために役立ちます。
- Queues Metrics
- このビューには、ログの処理中に見つかった YARN キューのさまざまな指標の内訳が表示されます。このビューでは、特定のキューでの使用状況のパターンと移行への影響を把握できます。このビューを使用して、クエリでアクセスされたテーブルと、クエリが実行されたキューとの間の接続を特定することもできます。
- Queuing and Waiting
- このビューは、ソースデータ ウェアハウス内のクエリキュー時間に関する分析情報を提供します。キュー時間は、プロビジョニング不足によるパフォーマンスの低下を意味しており、追加のプロビジョニングによってハードウェアとメンテナンスのコストが増大します。
- Queries
- このビューには、実行された SQL ステートメントの種類の内訳と使用状況の統計情報が表示されます。クエリタイプと時間のヒストグラムを使用すると、システム使用率の低い期間やデータ転送に最適な時間帯を特定できます。このビューを使用して、最も使用されている Hive 実行エンジンと頻繁に実行されているクエリを、ユーザーの詳細とともに特定することもできます。
- Databases
- このビューには、ソースデータ ウェアハウス システムで定義されているサイズ、テーブル、ビュー、プロシージャの指標が表示されます。このビューでは、移行する必要があるオブジェクトのボリュームに関する分析情報が得られます。
- Database & Table Coupling
- このビューには、単一のクエリでまとめてアクセスされるデータベースとテーブルの概要が表示されます。このビューでは、頻繁に参照されるテーブルとデータベース、また移行計画に使用できるテーブルとデータベースが示されます。
[BigQuery Steady State] セクションには、次のビューが含まれます。
- Tables With No Usage
- [Tables With No Usage] ビューには、分析対象のログの期間中に BigQuery 移行評価で使用量が検出されなかったテーブルが表示されます。使用量がないことは、移行中にそのテーブルを BigQuery に転送する必要がないか、BigQuery にデータを保存する費用を削減できることを示す場合があります。未使用のテーブルのリストを検証する必要があります。これは、3 か月または 6 か月に 1 回だけ使用されるテーブルなど、ログ期間外での使用状況がある可能性があるためです。
- Tables With No Writes
- [Tables With No Writes] ビューには、分析対象のログの期間中に BigQuery 移行評価で更新が検出されなかったテーブルが表示されます。書き込みがないことは、BigQuery でストレージ コストを削減できる場所を示している可能性があります。
- Clustering and Partitioning Recommendations
このビューには、パーティショニング、クラスタリング、またはその両方に役立つテーブルが表示されます。
メタデータの提案は、ソースデータ ウェアハウスのスキーマ(ソーステーブルのパーティショニングと主キーなど)を分析し、同様の最適化特性を実現するために最も近い BigQuery の同等物を見つけることによって実現されます。
ワークロードの提案は、ソースクエリのログの分析によって実現します。推奨事項は、ワークロード(特に分析対象のクエリログの
WHERE句またはJOIN句)の分析によって決定されます。- Partitions converted to Clusters
このビューには、パーティショニング制約の定義に基づいて、パーティションが 10,000 を超えるテーブルが表示されます。こうしたテーブルは、きめ細かいテーブル パーティションを可能にする BigQuery のクラスタリングに適しています。
- Skewed partitions
[Skewed Partitions] ビューには、メタデータ分析に基づいていて、1 つ以上のパーティションにデータスキューがあるテーブルが表示されます。偏りのあるパーティションに対するクエリはうまく機能しない可能性があるため、これらのテーブルはスキーマの変更を検討する必要があります。
- BI Engine and Materialized Views
[Low-Latency Queries and Materialized Views] ビューには、分析されたログデータに基づくクエリ ランタイムの分布と、BigQuery のパフォーマンスを向上させるためのさらなる最適化の提案が表示されます。クエリ実行時間の分布グラフに、実行時間が 1 秒未満の多数のクエリが表示される場合は、BI Engine が BI やその他の低レイテンシ ワークロードを高速化できるようにすることを検討してください。
レポートの [Migration path] セクションには、次のビューが含まれています。
- SQL Translation
- [SQL Translation] ビューには、BigQuery 移行評価によって自動的に変換され、手動での操作が不要なクエリの数と詳細が表示されます。メタデータが提供されている場合は通常、自動 SQL 変換で高い変換率が実現されます。このビューはインタラクティブであり、一般的なクエリとその変換方法を分析できます。
- SQL Translation Offline Effort
- [Offline Effort] ビューには、特定の UDF と、テーブルまたは列の潜在的な語彙の構造と構文の違反など、手動での操作が必要な領域のキャプチャが表示されます。
- SQL Warnings
- [SQL Warnings] ビューには、正常に変換されたものの、レビューが必要な領域が表示されます。
- BigQuery Reserved Keywords
- [BigQuery Reserved Keyword] ビューには、GoogleSQL 言語で特別な意味を持つキーワードに関して検出された使用状況が表示されます。これらのキーワードは、バッククォート(
`)文字で囲まない限り、識別子として使用できません。 - Table Updates Schedule
- [Table Updates Schedule] ビューには、テーブルの更新のタイミングと頻度が表示されます。これは、テーブルの移動方法とタイミングを決定するのに役立ちます。
- BigLake External Tables
- [BigLake External Tables] ビューには、BigQuery ではなく BigLake への移行ターゲットとして識別されたテーブルの概要が表示されます。
レポートの [推奨事項] セクションには、次のビューが表示されます。
- Detailed SQL Translation Offline Effort Analysis
- [Detailed Offline Effort Analysis] ビューには、手動操作が必要な SQL 領域に関する追加の分析情報が表示されます。
- Detailed SQL Warnings Analysis
- [Detailed Warnings Analysis] ビューには、正常に変換されたものの、レビューが必要な SQL 領域に関する追加の分析情報が表示されます。
レポートを共有する
Looker Studio レポートは、移行評価のためのフロントエンド ダッシュボードです。基になるデータセットのアクセス権限に依存しています。レポートを共有するには、受取人に Looker Studio レポート自体へのアクセス権と、評価結果を含む BigQuery データセットへのアクセス権の両方が必要です。
Google Cloud コンソールからレポートを開くと、レポートがプレビュー モードで表示されます。レポートを作成して他のユーザーと共有する手順は、次のとおりです。
- [Edit and share] をクリックします。新しく作成した Looker Studio コネクタを新しいレポートに接続するように求められます。
- [レポートに追加] をクリックします。レポートには、個別のレポート ID が付与され、この ID を使用してレポートにアクセスできます。
- Looker Studio レポートを他のユーザーと共有するには、閲覧者または編集者とレポートを共有するの手順を実施します。
- 評価タスクの実行に使用した BigQuery データセットを表示する権限をユーザーに付与します。詳細については、データセットへのアクセス権の付与をご覧ください。
移行評価の出力テーブルに対してクエリを実行する
Looker Studio レポートは評価結果を確認できる最も便利な手段ですが、BigQuery データセットの基となるデータを表示してクエリすることもできます。
クエリ例
次の例では、一意のクエリの総数、変換に失敗したクエリの数、変換に失敗した一意のクエリの割合を取得します。
SELECT QueryCount.v AS QueryCount, ErrorCount.v as ErrorCount, (ErrorCount.v * 100) / QueryCount.v AS FailurePercentage FROM ( SELECT COUNT(*) AS v FROM `your_project.your_dataset.TranslationErrors` WHERE Severity = "ERROR" ) AS ErrorCount, ( SELECT COUNT(DISTINCT(QueryHash)) AS v FROM `your_project.your_dataset.Queries` ) AS QueryCount;
他のプロジェクトのユーザーとデータセットを共有する
データセットを検査した後、プロジェクトに参加していないユーザーと共有する場合は、BigQuery Sharing(旧称 Analytics Hub)のパブリッシャー ワークフローを使用します。
Google Cloud コンソールで、[BigQuery] ページに移動します。
データセットをクリックすると詳細が表示されます。
[共有] > [リスティングとして公開] をクリックします。
表示されたダイアログで、指示に沿ってリスティングを作成します。
データ エクスチェンジがすでにある場合は、手順 5 をスキップします。
データ エクスチェンジを作成して権限を設定します。このエクスチェンジでユーザーがリスティングを表示できるようにするには、ユーザーを [サブスクライバー] リストに追加します。
リスティングの詳細を入力します。
[表示名] は、このリスティングの名前で、必須です。他のフィールドは省略可能です。
[公開] をクリックします。
非公開リスティングが作成されます。
リスティングの [操作] で [その他の操作] を選択します。
[共有リンクをコピー] をクリックします。
エクスチェンジまたはリスティングへのサブスクリプション アクセス権を持つユーザーとリンクを共有できます。
評価テーブルのスキーマ
BigQuery 移行評価により BigQuery に書き込まれるテーブルとそのスキーマを確認するには、使用しているデータ ウェアハウスを選択します。
Teradata
AllRIChildren
このテーブルは、テーブルの子の参照整合性情報を提供します。
| 列 | 型 | 説明 |
|---|---|---|
IndexId |
INTEGER |
参照インデックス番号。 |
IndexName |
STRING |
インデックスの名前。 |
ChildDB |
STRING |
小文字に変換された参照データベースの名前。 |
ChildDBOriginal |
STRING |
大文字と小文字が区別される参照データベースの名前。 |
ChildTable |
STRING |
小文字に変換された参照テーブルの名前。 |
ChildTableOriginal |
STRING |
大文字と小文字が保持された参照テーブルの名前。 |
ChildKeyColumn |
STRING |
小文字に変換された参照キーの列の名前。 |
ChildKeyColumnOriginal |
STRING |
大文字と小文字が保持された参照キー内の列の名前。 |
ParentDB |
STRING |
小文字に変換された参照データベースの名前。 |
ParentDBOriginal |
STRING |
大文字と小文字が保持された参照データベースの名前。 |
ParentTable |
STRING |
小文字に変換された参照先テーブルの名前。 |
ParentTableOriginal |
STRING |
大文字と小文字が保持された参照先テーブルの名前。 |
ParentKeyColumn |
STRING |
小文字に変換された参照先キー内の列の名前。 |
ParentKeyColumnOriginal |
STRING |
大文字と小文字が保持された参照先キーの列の名前。 |
AllRIParents
このテーブルは、テーブルの親の参照整合性情報を提供します。
| 列 | 型 | 説明 |
|---|---|---|
IndexId |
INTEGER |
参照インデックス番号。 |
IndexName |
STRING |
インデックスの名前。 |
ChildDB |
STRING |
小文字に変換された参照データベースの名前。 |
ChildDBOriginal |
STRING |
大文字と小文字が区別される参照データベースの名前。 |
ChildTable |
STRING |
小文字に変換された参照テーブルの名前。 |
ChildTableOriginal |
STRING |
大文字と小文字が保持された参照テーブルの名前。 |
ChildKeyColumn |
STRING |
小文字に変換された参照キーの列の名前。 |
ChildKeyColumnOriginal |
STRING |
大文字と小文字が保持された参照キー内の列の名前。 |
ParentDB |
STRING |
小文字に変換された参照データベースの名前。 |
ParentDBOriginal |
STRING |
大文字と小文字が保持された参照データベースの名前。 |
ParentTable |
STRING |
小文字に変換された参照先テーブルの名前。 |
ParentTableOriginal |
STRING |
大文字と小文字が保持された参照先テーブルの名前。 |
ParentKeyColumn |
STRING |
小文字に変換された参照先キー内の列の名前。 |
ParentKeyColumnOriginal |
STRING |
大文字と小文字が保持された参照先キーの列の名前。 |
Columns
このテーブルは、列に関する情報を提供します。
| 列 | 型 | 説明 |
|---|---|---|
DatabaseName |
STRING |
小文字に変換されたデータベースの名前。 |
DatabaseNameOriginal |
STRING |
大文字と小文字が保持されたデータベースの名前。 |
TableName |
STRING |
小文字に変換されたテーブルの名前。 |
TableNameOriginal |
STRING |
大文字と小文字が保持されたテーブルの名前。 |
ColumnName |
STRING |
小文字に変換された列の名前。 |
ColumnNameOriginal |
STRING |
大文字と小文字が保持された列の名前。 |
ColumnType |
STRING |
列の BigQuery の型(STRING など)。 |
OriginalColumnType |
STRING |
列の元の型(VARCHAR など)。 |
ColumnLength |
INTEGER |
列の最大バイト数(VARCHAR(30) の場合は 30 など)。 |
DefaultValue |
STRING |
デフォルト値(存在する場合)。 |
Nullable |
BOOLEAN |
列が null 値を許容するかどうか。 |
DiskSpace
このテーブルは、データベースごとのディスク使用量に関する情報を提供します。
| 列 | 型 | 説明 |
|---|---|---|
DatabaseName |
STRING |
小文字に変換されたデータベースの名前。 |
DatabaseNameOriginal |
STRING |
大文字と小文字が保持されたデータベースの名前。 |
MaxPerm |
INTEGER |
永続領域に割り当てられる最大バイト数。 |
MaxSpool |
INTEGER |
スプール領域に割り当てられる最大バイト数。 |
MaxTemp |
INTEGER |
一時領域に割り当てられる最大バイト数。 |
CurrentPerm |
INTEGER |
永続領域に割り当てられるバイト数。 |
CurrentSpool |
INTEGER |
スプール領域に割り当てられるバイト数。 |
CurrentTemp |
INTEGER |
一時領域に割り当てられるバイト数。 |
PeakPerm |
INTEGER |
永続領域の最後のリセット以降に使用されたピークバイト数。 |
PeakSpool |
INTEGER |
スプール領域の最後のリセット以降に使用されたピークバイト数。 |
PeakPersistentSpool |
INTEGER |
永続領域の最後のリセット以降に使用されたピークバイト数。 |
PeakTemp |
INTEGER |
一時領域の最後のリセット以降に使用されたピークバイト数。 |
MaxProfileSpool |
INTEGER |
ユーザーのスプール領域の上限。 |
MaxProfileTemp |
INTEGER |
ユーザーの一時領域の上限。 |
AllocatedPerm |
INTEGER |
永続領域の現在の割り当て。 |
AllocatedSpool |
INTEGER |
スプール領域の現在の割り当て。 |
AllocatedTemp |
INTEGER |
一時領域の現在の割り当て。 |
Functions
このテーブルは、関数に関する情報を提供します。
| 列 | 型 | 説明 |
|---|---|---|
DatabaseName |
STRING |
小文字に変換されたデータベースの名前。 |
DatabaseNameOriginal |
STRING |
大文字と小文字が保持されたデータベースの名前。 |
FunctionName |
STRING |
関数名。 |
LanguageName |
STRING |
言語の名前。 |
Indices
このテーブルは、インデックスに関する情報を提供します。
| 列 | 型 | 説明 |
|---|---|---|
DatabaseName |
STRING |
小文字に変換されたデータベースの名前。 |
DatabaseNameOriginal |
STRING |
大文字と小文字が保持されたデータベースの名前。 |
TableName |
STRING |
小文字に変換されたテーブルの名前。 |
TableNameOriginal |
STRING |
大文字と小文字が保持されたテーブルの名前。 |
IndexName |
STRING |
インデックスの名前。 |
ColumnName |
STRING |
小文字に変換された列の名前。 |
ColumnNameOriginal |
STRING |
大文字と小文字が保持された列の名前。 |
OrdinalPosition |
INTEGER |
列の位置。 |
UniqueFlag |
BOOLEAN |
インデックスで一意性が適用されるかどうかを示します。 |
Queries
このテーブルは、抽出されたクエリに関する情報を提供します。
| 列 | 型 | 説明 |
|---|---|---|
QueryHash |
STRING |
クエリのハッシュ。 |
QueryText |
STRING |
クエリのテキスト。 |
QueryLogs
このテーブルは、抽出されたクエリに関する実行統計情報を提供します。
| 列 | 型 | 説明 |
|---|---|---|
QueryText |
STRING |
クエリのテキスト。 |
QueryHash |
STRING |
クエリのハッシュ。 |
QueryId |
STRING |
クエリの ID。 |
QueryType |
STRING |
クエリのタイプ(Query または DDL)。 |
UserId |
BYTES |
クエリを実行したユーザーの ID。 |
UserName |
STRING |
クエリを実行したユーザーの名前。 |
StartTime |
TIMESTAMP |
クエリ送信時のタイムスタンプ。 |
Duration |
STRING |
クエリの所要時間(ミリ秒単位)。 |
AppId |
STRING |
クエリを実行したアプリケーションの ID。 |
ProxyUser |
STRING |
中間階層で使用される場合のプロキシ ユーザー。 |
ProxyRole |
STRING |
中間階層で使用される場合のプロキシロール。 |
QueryTypeStatistics
このテーブルは、クエリのタイプに関する統計情報を提供します。
| 列 | 型 | 説明 |
|---|---|---|
QueryHash |
STRING |
クエリのハッシュ。 |
QueryType |
STRING |
クエリのタイプ。 |
UpdatedTable |
STRING |
クエリによって更新されたテーブル(存在する場合)。 |
QueriedTables |
ARRAY<STRING> |
クエリされたテーブルのリスト。 |
ResUsageScpu
このテーブルは、CPU リソースの使用状況に関する情報を提供します。
| 列 | 型 | 説明 |
|---|---|---|
EventTime |
TIMESTAMP |
イベントの時刻。 |
NodeId |
INTEGER |
ノード ID |
CabinetId |
INTEGER |
ノードの物理キャビネット番号。 |
ModuleId |
INTEGER |
ノードの物理モジュール番号。 |
NodeType |
STRING |
ノードの種類。 |
CpuId |
INTEGER |
このノード内の CPU の ID。 |
MeasurementPeriod |
INTEGER |
センチ秒で表された測定期間。 |
SummaryFlag |
STRING |
S - 概要行、N - 非概要行 |
CpuFrequency |
FLOAT |
CPU 周波数(MHz)。 |
CpuIdle |
FLOAT |
CPU がアイドル状態である時間(センチ秒)。 |
CpuIoWait |
FLOAT |
CPU が I/O を待機している時間(センチ秒)。 |
CpuUServ |
FLOAT |
CPU がユーザーコードを実行している時間(センチ秒)。 |
CpuUExec |
FLOAT |
CPU がサービスコードを実行している時間(センチ秒)。 |
Roles
このテーブルは、ロールに関する情報を提供します。
| 列 | 型 | 説明 |
|---|---|---|
RoleName |
STRING |
ロールの名前。 |
Grantor |
STRING |
ロールを付与したデータベースの名前。 |
Grantee |
STRING |
ロールが付与されたユーザー。 |
WhenGranted |
TIMESTAMP |
ロールの付与日時。 |
WithAdmin |
BOOLEAN |
付与されたロールに管理者オプションが設定されているかどうか。 |
SchemaConversion
このテーブルは、クラスタリングとパーティショニングに関連するスキーマ変換の情報を提供します。
| 列名 | 列の型 | 説明 |
|---|---|---|
DatabaseName |
STRING |
提案が行われたソース データベースの名前。 データベースは BigQuery のデータセットにマッピングされます。 |
TableName |
STRING |
提案が行われたテーブルの名前。 |
PartitioningColumnName |
STRING |
BigQuery で提案されるパーティショニング列の名前。 |
ClusteringColumnNames |
ARRAY |
BigQuery で提案されるクラスタリング列の名前。 |
CreateTableDDL |
STRING |
BigQuery にテーブルを作成するための CREATE TABLE statement。 |
TableInfo
このテーブルは、テーブルに関する情報を提供します。
| 列 | 型 | 説明 |
|---|---|---|
DatabaseName |
STRING |
小文字に変換されたデータベースの名前。 |
DatabaseNameOriginal |
STRING |
大文字と小文字が保持されたデータベースの名前。 |
TableName |
STRING |
小文字に変換されたテーブルの名前。 |
TableNameOriginal |
STRING |
大文字と小文字が保持されたテーブルの名前。 |
LastAccessTimestamp |
TIMESTAMP |
テーブルが最後にアクセスされた時刻。 |
LastAlterTimestamp |
TIMESTAMP |
テーブルが最後に変更された時刻。 |
TableKind |
STRING |
テーブルのタイプ。 |
TableRelations
このテーブルは、テーブルに関する情報を提供します。
| 列 | 型 | 説明 |
|---|---|---|
QueryHash |
STRING |
関係を確立したクエリのハッシュ。 |
DatabaseName1 |
STRING |
最初のデータベースの名前。 |
TableName1 |
STRING |
最初のテーブルの名前。 |
DatabaseName2 |
STRING |
2 番目のデータベースの名前。 |
TableName2 |
STRING |
2 番目のテーブルの名前。 |
Relation |
STRING |
2 つのテーブル間の結合の種類。 |
TableSizes
このテーブルは、テーブルのサイズに関する情報を提供します。
| 列 | 型 | 説明 |
|---|---|---|
DatabaseName |
STRING |
小文字に変換されたデータベースの名前。 |
DatabaseNameOriginal |
STRING |
大文字と小文字が保持されたデータベースの名前。 |
TableName |
STRING |
小文字に変換されたテーブルの名前。 |
TableNameOriginal |
STRING |
大文字と小文字が保持されたテーブルの名前。 |
TableSizeInBytes |
INTEGER |
テーブルのサイズ(バイト単位)。 |
Users
このテーブルは、ユーザーに関する情報を提供します。
| 列 | 型 | 説明 |
|---|---|---|
UserName |
STRING |
ユーザーの名前。 |
CreatorName |
STRING |
このユーザーを作成したエンティティの名前。 |
CreateTimestamp |
TIMESTAMP |
このユーザーが作成されたときのタイムスタンプ。 |
LastAccessTimestamp |
TIMESTAMP |
このユーザーがデータベースに最後にアクセスしたときのタイムスタンプ。 |
Redshift
Columns
Columns テーブルは、SVV_COLUMNS、INFORMATION_SCHEMA.COLUMNS または PG_TABLE_DEF のいずれかのテーブルから、優先度の高いものから順に取得されます。このツールは、優先度が最も高いテーブルからデータの読み込みを試みます。失敗した場合は、次に優先度が高いテーブルからデータの読み込みを試みます。スキーマと使用方法の詳細については、Amazon Redshift と PostgreSQL のドキュメントをご覧ください。
| 列 | 型 | 説明 |
|---|---|---|
DatabaseName |
STRING |
データベースの名前。 |
SchemaName |
STRING |
スキーマ名。 |
TableName |
STRING |
テーブルの名前。 |
ColumnName |
STRING |
列の名前。 |
DefaultValue |
STRING |
デフォルト値(使用可能な場合)。 |
Nullable |
BOOLEAN |
列に null 値を含めることができるかどうか。 |
ColumnType |
STRING |
列の型(VARCHAR など)。 |
ColumnLength |
INTEGER |
列のサイズ(VARCHAR(30) の場合は 30 など)。 |
CreateAndDropStatistic
このテーブルは、テーブルの作成と削除に関する情報を提供します。
| 列 | 型 | 説明 |
|---|---|---|
QueryHash |
STRING |
クエリのハッシュ。 |
DefaultDatabase |
STRING |
デフォルトのデータベース。 |
EntityType |
STRING |
エンティティのタイプ。TABLE など。 |
EntityName |
STRING |
エンティティの名前。 |
Operation |
STRING |
オペレーション: CREATE または DROP。 |
Databases
このテーブルは、Amazon Redshift の PG_DATABASE_INFO テーブルから直接取得されます。PG テーブルの元のフィールド名が説明に含まれています。スキーマと使用方法の詳細については、Amazon Redshift と PostgreSQL のドキュメントをご覧ください。
| 列 | 型 | 説明 |
|---|---|---|
DatabaseName |
STRING |
データベースの名前。ソース名: datname |
Owner |
STRING |
データベースのオーナー。データベースを作成したユーザーなど。ソース名: datdba |
ExternalColumns
このテーブルには、Amazon Redshift の SVV_EXTERNAL_COLUMNS テーブルからの直接の情報が含まれています。スキーマと使用方法の詳細については、Amazon Redshift のドキュメントをご覧ください。
| 列 | 型 | 説明 |
|---|---|---|
SchemaName |
STRING |
外部スキーマ名。 |
TableName |
STRING |
外部テーブル名。 |
ColumnName |
STRING |
外部列名。 |
ColumnType |
STRING |
列の型。 |
Nullable |
BOOLEAN |
列に null 値を含めることができるかどうか。 |
ExternalDatabases
このテーブルには、Amazon Redshift の SVV_EXTERNAL_DATABASES テーブルからの直接の情報が含まれています。スキーマと使用方法の詳細については、Amazon Redshift のドキュメントをご覧ください。
| 列 | 型 | 説明 |
|---|---|---|
DatabaseName |
STRING |
外部データベース名。 |
Location |
STRING |
データベースのロケーション。 |
ExternalPartitions
このテーブルには、Amazon Redshift の SVV_EXTERNAL_PARTITIONS テーブルからの直接の情報が含まれています。スキーマと使用方法の詳細については、Amazon Redshift のドキュメントをご覧ください。
| 列 | 型 | 説明 |
|---|---|---|
SchemaName |
STRING |
外部スキーマ名。 |
TableName |
STRING |
外部テーブル名。 |
Location |
STRING |
パーティションのロケーション。列のサイズは 128 文字に制限されています。それより長い値は切り捨てられます。 |
ExternalSchemas
このテーブルには、Amazon Redshift の SVV_EXTERNAL_SCHEMAS テーブルからの直接の情報が含まれています。スキーマと使用方法の詳細については、Amazon Redshift のドキュメントをご覧ください。
| 列 | 型 | 説明 |
|---|---|---|
SchemaName |
STRING |
外部スキーマ名。 |
DatabaseName |
STRING |
外部データベース名。 |
ExternalTables
このテーブルには、Amazon Redshift の SVV_EXTERNAL_TABLES テーブルからの直接の情報が含まれています。スキーマと使用方法の詳細については、Amazon Redshift のドキュメントをご覧ください。
| 列 | 型 | 説明 |
|---|---|---|
SchemaName |
STRING |
外部スキーマ名。 |
TableName |
STRING |
外部テーブル名。 |
Functions
このテーブルには、Amazon Redshift の PG_PROC テーブルからの直接の情報が含まれています。スキーマと使用方法の詳細については、Amazon Redshift と PostgreSQL のドキュメントをご覧ください。
| 列 | 型 | 説明 |
|---|---|---|
SchemaName |
STRING |
スキーマ名。 |
FunctionName |
STRING |
関数名。 |
LanguageName |
STRING |
この関数の実装言語または呼び出しインターフェース。 |
Queries
このテーブルは、QueryLogs テーブルの情報を使用して生成されます。QueryLogs テーブルとは異なり、Queries テーブルのすべての行に QueryText 列に保存されるクエリ ステートメントは 1 つのみ含まれます。このテーブルは、統計テーブルと変換出力を生成するためのソースデータを提供します。
| 列 | 型 | 説明 |
|---|---|---|
QueryText |
STRING |
クエリのテキスト。 |
QueryHash |
STRING |
クエリのハッシュ。 |
QueryLogs
このテーブルは、クエリの実行に関する情報を提供します。
| 列 | 型 | 説明 |
|---|---|---|
QueryText |
STRING |
クエリのテキスト。 |
QueryHash |
STRING |
クエリのハッシュ。 |
QueryID |
STRING |
クエリの ID。 |
UserID |
STRING |
ユーザーの ID。 |
StartTime |
TIMESTAMP |
開始時間。 |
Duration |
INTEGER |
実行時間(ミリ秒)。 |
QueryTypeStatistics
| 列 | 型 | 説明 |
|---|---|---|
QueryHash |
STRING |
クエリのハッシュ。 |
DefaultDatabase |
STRING |
デフォルトのデータベース。 |
QueryType |
STRING |
クエリのタイプ。 |
UpdatedTable |
STRING |
更新されたテーブル。 |
QueriedTables |
ARRAY<STRING> |
クエリされたテーブル。 |
TableInfo
このテーブルには、Amazon Redshift の SVV_TABLE_INFO テーブルから抽出された情報が含まれています。
| 列 | 型 | 説明 |
|---|---|---|
DatabaseName |
STRING |
データベースの名前。 |
SchemaName |
STRING |
スキーマ名。 |
TableId |
INTEGER |
テーブル ID。 |
TableName |
STRING |
テーブルの名前。 |
SortKey1 |
STRING |
並べ替えキーの最初の列。 |
SortKeyNum |
INTEGER |
並べ替えキーとして定義された列の数。 |
MaxVarchar |
INTEGER |
VARCHAR データ型を使用する最大の列のサイズ。 |
Size |
INTEGER |
テーブルのサイズ(1 MB データブロック単位)。 |
TblRows |
INTEGER |
テーブル内の総行数。 |
TableRelations
| 列 | 型 | 説明 |
|---|---|---|
QueryHash |
STRING |
関係を確立したクエリのハッシュ(JOIN クエリなど)。 |
DefaultDatabase |
STRING |
デフォルトのデータベース。 |
TableName1 |
STRING |
関係の最初のテーブル。 |
TableName2 |
STRING |
関係の 2 番目のテーブル。 |
Relation |
STRING |
関係の種類。次のいずれかの値を取ります。COMMA_JOIN、CROSS_JOIN、FULL_OUTER_JOIN、INNER_JOIN、LEFT_OUTER_JOIN、RIGHT_OUTER_JOIN、CREATED_FROM、INSERT_INTO。 |
Count |
INTEGER |
この関係が観察された頻度。 |
TableSizes
このテーブルはテーブルサイズに関する情報を提供します。
| 列 | 型 | 説明 |
|---|---|---|
DatabaseName |
STRING |
データベースの名前。 |
SchemaName |
STRING |
スキーマ名。 |
TableName |
STRING |
テーブルの名前。 |
TableSizeInBytes |
INTEGER |
テーブルのサイズ(バイト単位)。 |
Tables
このテーブルには、Amazon Redshift の SVV_TABLES テーブルから抽出された情報が含まれています。スキーマと使用方法の詳細については、Amazon Redshift のドキュメントをご覧ください。
| 列 | 型 | 説明 |
|---|---|---|
DatabaseName |
STRING |
データベースの名前。 |
SchemaName |
STRING |
スキーマ名。 |
TableName |
STRING |
テーブルの名前。 |
TableType |
STRING |
テーブルのタイプ。 |
TranslatedQueries
このテーブルは、クエリ変換を提供します。
| 列 | 型 | 説明 |
|---|---|---|
QueryHash |
STRING |
クエリのハッシュ。 |
TranslatedQueryText |
STRING |
ソース言語から GoogleSQL への変換の結果。 |
TranslationErrors
このテーブルは、クエリ変換のエラーに関する情報を提供します。
| 列 | 型 | 説明 |
|---|---|---|
QueryHash |
STRING |
クエリのハッシュ。 |
Severity |
STRING |
エラーの重大度(ERROR など)。 |
Category |
STRING |
エラーのカテゴリ(AttributeNotFound など)。 |
Message |
STRING |
エラーの詳細を含むメッセージ。 |
LocationOffset |
INTEGER |
エラーの位置を示す文字位置。 |
LocationLine |
INTEGER |
エラーの行番号。 |
LocationColumn |
INTEGER |
エラーの列番号。 |
LocationLength |
INTEGER |
エラーの位置の文字長。 |
UserTableRelations
| 列 | 型 | 説明 |
|---|---|---|
UserID |
STRING |
ユーザー ID。 |
TableName |
STRING |
テーブルの名前。 |
Relation |
STRING |
関係。 |
Count |
INTEGER |
数。 |
Users
このテーブルには、Amazon Redshift の PG_USER テーブルから抽出された情報が含まれています。スキーマと使用方法の詳細については、PostgreSQL のドキュメントをご覧ください。
| 列 | 型 | 説明 | |
|---|---|---|---|
UserName |
STRING |
ユーザーの名前。 | |
UserId |
STRING |
ユーザー ID。 |
Snowflake
Warehouses
| 列 | 型 | 説明 | プレゼンス |
|---|---|---|---|
WarehouseName |
STRING |
ウェアハウスの名前。 | 常時 |
State |
STRING |
ウェアハウスの状態。指定できる値: STARTED、SUSPENDED、RESIZING。 |
常時 |
Type |
STRING |
ウェアハウスのタイプ。指定できる値: STANDARD、SNOWPARK-OPTIMIZED。 |
常時 |
Size |
STRING |
ウェアハウスのサイズ。指定できる値: X-Small、Small、Medium、Large、X-Large、2X-Large ... 6X-Large。 |
常時 |
Databases
| 列 | 型 | 説明 | プレゼンス |
|---|---|---|---|
DatabaseNameOriginal |
STRING |
大文字と小文字が保持されたデータベースの名前。 | 常時 |
DatabaseName |
STRING |
小文字に変換されたデータベースの名前。 | 常時 |
Schemata
| 列 | 型 | 説明 | プレゼンス |
|---|---|---|---|
DatabaseNameOriginal |
STRING |
大文字と小文字が保持された、スキーマが属するデータベースの名前。 | 常時 |
DatabaseName |
STRING |
小文字に変換された、スキーマが属するデータベースの名前。 | 常時 |
SchemaNameOriginal |
STRING |
大文字と小文字が保持されたスキーマの名前。 | 常時 |
SchemaName |
STRING |
小文字に変換されたスキーマの名前。 | 常時 |
Tables
| 列 | 型 | 説明 | プレゼンス |
|---|---|---|---|
DatabaseNameOriginal |
STRING |
大文字と小文字が保持された、テーブルが属するデータベースの名前。 | 常時 |
DatabaseName |
STRING |
小文字に変換された、テーブルが属するデータベースの名前。 | 常時 |
SchemaNameOriginal |
STRING |
大文字と小文字が保持された、テーブルが属するスキーマの名前。 | 常時 |
SchemaName |
STRING |
小文字に変換された、テーブルが属するスキーマの名前。 | 常時 |
TableNameOriginal |
STRING |
大文字と小文字が保持されたテーブルの名前。 | 常時 |
TableName |
STRING |
小文字に変換されたテーブルの名前。 | 常時 |
TableType |
STRING |
テーブルのタイプ(ビュー / マテリアライズド ビュー / ベーステーブル)。 | 常時 |
RowCount |
BIGNUMERIC |
テーブル内の行数。 | 常時 |
Columns
| 列 | 型 | 説明 | プレゼンス |
|---|---|---|---|
DatabaseName |
STRING |
小文字に変換されたデータベースの名前。 | 常時 |
DatabaseNameOriginal |
STRING |
大文字と小文字が保持されたデータベースの名前。 | 常時 |
SchemaName |
STRING |
小文字に変換されたスキーマの名前。 | 常時 |
SchemaNameOriginal |
STRING |
大文字と小文字が保持されたスキーマの名前。 | 常時 |
TableName |
STRING |
小文字に変換されたテーブルの名前。 | 常時 |
TableNameOriginal |
STRING |
大文字と小文字が保持されたテーブルの名前。 | 常時 |
ColumnName |
STRING |
小文字に変換された列の名前。 | 常時 |
ColumnNameOriginal |
STRING |
大文字と小文字が保持された列の名前。 | 常時 |
ColumnType |
STRING |
列の型。 | 常時 |
CreateAndDropStatistics
| 列 | 型 | 説明 | プレゼンス |
|---|---|---|---|
QueryHash |
STRING |
クエリのハッシュ。 | 常時 |
DefaultDatabase |
STRING |
デフォルトのデータベース。 | 常時 |
EntityType |
STRING |
エンティティのタイプ(例: TABLE)。 |
常時 |
EntityName |
STRING |
エンティティの名前。 | 常時 |
Operation |
STRING |
オペレーション: CREATE または DROP。 |
常時 |
Queries
| 列 | 型 | 説明 | プレゼンス |
|---|---|---|---|
QueryText |
STRING |
クエリのテキスト。 | 常時 |
QueryHash |
STRING |
クエリのハッシュ。 | 常時 |
QueryLogs
| 列 | 型 | 説明 | プレゼンス |
|---|---|---|---|
QueryText |
STRING |
クエリのテキスト。 | 常時 |
QueryHash |
STRING |
クエリのハッシュ。 | 常時 |
QueryID |
STRING |
クエリの ID。 | 常時 |
UserID |
STRING |
ユーザーの ID。 | 常時 |
StartTime |
TIMESTAMP |
開始時間。 | 常時 |
Duration |
INTEGER |
実行時間(ミリ秒)。 | 常時 |
QueryTypeStatistics
| 列 | 型 | 説明 | プレゼンス |
|---|---|---|---|
QueryHash |
STRING |
クエリのハッシュ。 | 常時 |
DefaultDatabase |
STRING |
デフォルトのデータベース。 | 常時 |
QueryType |
STRING |
クエリのタイプ。 | 常時 |
UpdatedTable |
STRING |
更新されたテーブル。 | 常時 |
QueriedTables |
REPEATED STRING |
クエリされたテーブル。 | 常時 |
TableRelations
| 列 | 型 | 説明 | プレゼンス |
|---|---|---|---|
QueryHash |
STRING |
関係を確立したクエリのハッシュ(例: JOIN クエリ)。 |
常時 |
DefaultDatabase |
STRING |
デフォルトのデータベース。 | 常時 |
TableName1 |
STRING |
関係の最初のテーブル。 | 常時 |
TableName2 |
STRING |
関係の 2 番目のテーブル。 | 常時 |
Relation |
STRING |
関係の種類。 | 常時 |
Count |
INTEGER |
この関係が観察された頻度。 | 常時 |
TranslatedQueries
| 列 | 型 | 説明 | プレゼンス |
|---|---|---|---|
QueryHash |
STRING |
クエリのハッシュ。 | 常時 |
TranslatedQueryText |
STRING |
ソース言語から BigQuery SQL への変換の結果。 | 常時 |
TranslationErrors
| 列 | 型 | 説明 | プレゼンス |
|---|---|---|---|
QueryHash |
STRING |
クエリのハッシュ。 | 常時 |
Severity |
STRING |
エラーの重大度(例: ERROR)。 |
常時 |
Category |
STRING |
エラーのカテゴリ(例: AttributeNotFound)。 |
常時 |
Message |
STRING |
エラーの詳細を含むメッセージ。 | 常時 |
LocationOffset |
INTEGER |
エラーの位置を示す文字位置。 | 常時 |
LocationLine |
INTEGER |
エラーの行番号。 | 常時 |
LocationColumn |
INTEGER |
エラーの列番号。 | 常時 |
LocationLength |
INTEGER |
エラーの位置の文字長。 | 常時 |
UserTableRelations
| 列 | 型 | 説明 | プレゼンス |
|---|---|---|---|
UserID |
STRING |
ユーザー ID。 | 常時 |
TableName |
STRING |
テーブルの名前。 | 常時 |
Relation |
STRING |
関係。 | 常時 |
Count |
INTEGER |
数。 | 常時 |
Apache Hive
Columns
このテーブルは、列に関する情報を提供します。
| 列 | 型 | 説明 |
|---|---|---|
DatabaseName |
STRING |
大文字と小文字が保持されたデータベースの名前。 |
TableName |
STRING |
大文字と小文字が保持されたテーブルの名前。 |
ColumnName |
STRING |
大文字と小文字が保持された列の名前。 |
ColumnType |
STRING |
列の BigQuery の型(STRING など)。 |
OriginalColumnType |
STRING |
列の元の型(VARCHAR など)。 |
CreateAndDropStatistic
このテーブルは、テーブルの作成と削除に関する情報を提供します。
| 列 | 型 | 説明 |
|---|---|---|
QueryHash |
STRING |
クエリのハッシュ。 |
DefaultDatabase |
STRING |
デフォルトのデータベース。 |
EntityType |
STRING |
エンティティのタイプ(例: TABLE)。 |
EntityName |
STRING |
エンティティの名前。 |
Operation |
STRING |
テーブルに対して実行されたオペレーション(CREATE または DROP)。 |
Databases
このテーブルは、データベースに関する情報を提供します。
| 列 | 型 | 説明 |
|---|---|---|
DatabaseName |
STRING |
大文字と小文字が保持されたデータベースの名前。 |
Owner |
STRING |
データベースのオーナー。データベースを作成したユーザーなど。 |
Location |
STRING |
ファイル システム内のデータベースの場所。 |
Functions
このテーブルは、関数に関する情報を提供します。
| 列 | 型 | 説明 |
|---|---|---|
DatabaseName |
STRING |
大文字と小文字が保持されたデータベースの名前。 |
FunctionName |
STRING |
関数名。 |
LanguageName |
STRING |
言語の名前。 |
ClassName |
STRING |
関数のクラス名。 |
ObjectReferences
このテーブルは、クエリで参照されるオブジェクトに関する情報を提供します。
| 列 | 型 | 説明 |
|---|---|---|
QueryHash |
STRING |
クエリのハッシュ。 |
DefaultDatabase |
STRING |
デフォルトのデータベース。 |
Clause |
STRING |
オブジェクトが表示される句。例: SELECT。 |
ObjectName |
STRING |
オブジェクトの名前です。 |
Type |
STRING |
オブジェクトの型。 |
Subtype |
STRING |
オブジェクトのサブタイプ。 |
ParititionKeys
このテーブルは、パーティション キーに関する情報を提供します。
| 列 | 型 | 説明 |
|---|---|---|
DatabaseName |
STRING |
大文字と小文字が保持されたデータベースの名前。 |
TableName |
STRING |
大文字と小文字が保持されたテーブルの名前。 |
ColumnName |
STRING |
大文字と小文字が保持された列の名前。 |
ColumnType |
STRING |
列の BigQuery の型(STRING など)。 |
Parititions
このテーブルは、テーブルのパーティションに関する情報を提供します。
| 列 | 型 | 説明 |
|---|---|---|
DatabaseName |
STRING |
大文字と小文字が保持されたデータベースの名前。 |
TableName |
STRING |
大文字と小文字が保持されたテーブルの名前。 |
PartitionName |
STRING |
パーティションの名前。 |
CreateTimestamp |
TIMESTAMP |
このパーティションが作成されたときのタイムスタンプ。 |
LastAccessTimestamp |
TIMESTAMP |
このパーティションが最後にアクセスされたときのタイムスタンプ。 |
LastDdlTimestamp |
TIMESTAMP |
このパーティションが最後に変更されたときのタイムスタンプ。 |
TotalSize |
INTEGER |
パーティションの圧縮サイズ(バイト単位)。 |
Queries
このテーブルは、QueryLogs テーブルの情報を使用して生成されます。QueryLogs テーブルとは異なり、Queries テーブルのすべての行に QueryText 列に保存されたクエリ ステートメントが 1 つのみ含まれます。このテーブルは、統計テーブルと変換出力を生成するためのソースデータを提供します。
| 列 | 型 | 説明 |
|---|---|---|
QueryHash |
STRING |
クエリのハッシュ。 |
QueryText |
STRING |
クエリのテキスト。 |
QueryLogs
このテーブルは、抽出されたクエリに関する実行統計情報を提供します。
| 列 | 型 | 説明 |
|---|---|---|
QueryText |
STRING |
クエリのテキスト。 |
QueryHash |
STRING |
クエリのハッシュ。 |
QueryId |
STRING |
クエリの ID。 |
QueryType |
STRING |
クエリのタイプ(Query または DDL)。 |
UserName |
STRING |
クエリを実行したユーザーの名前。 |
StartTime |
TIMESTAMP |
クエリ送信時のタイムスタンプ。 |
Duration |
STRING |
クエリの所要時間(ミリ秒単位)。 |
QueryTypeStatistics
このテーブルは、クエリのタイプに関する統計情報を提供します。
| 列 | 型 | 説明 |
|---|---|---|
QueryHash |
STRING |
クエリのハッシュ。 |
QueryType |
STRING |
クエリのタイプ。 |
UpdatedTable |
STRING |
クエリによって更新されたテーブル(存在する場合)。 |
QueriedTables |
ARRAY<STRING> |
クエリされたテーブルのリスト。 |
QueryTypes
このテーブルは、クエリのタイプに関する統計情報を提供します。
| 列 | 型 | 説明 |
|---|---|---|
QueryHash |
STRING |
クエリのハッシュ。 |
Category |
STRING |
クエリのカテゴリ。 |
Type |
STRING |
クエリのタイプ。 |
Subtype |
STRING |
クエリのサブタイプ。 |
SchemaConversion
このテーブルは、クラスタリングとパーティショニングに関連するスキーマ変換の情報を提供します。
| 列名 | 列の型 | 説明 |
|---|---|---|
DatabaseName |
STRING |
提案が行われたソース データベースの名前。 データベースは BigQuery のデータセットにマッピングされます。 |
TableName |
STRING |
提案が行われたテーブルの名前。 |
PartitioningColumnName |
STRING |
BigQuery で提案されるパーティショニング列の名前。 |
ClusteringColumnNames |
ARRAY |
BigQuery で提案されるクラスタリング列の名前。 |
CreateTableDDL |
STRING |
BigQuery にテーブルを作成するための CREATE TABLE statement。 |
TableRelations
このテーブルは、テーブルに関する情報を提供します。
| 列 | 型 | 説明 |
|---|---|---|
QueryHash |
STRING |
関係を確立したクエリのハッシュ。 |
DatabaseName1 |
STRING |
最初のデータベースの名前。 |
TableName1 |
STRING |
最初のテーブルの名前。 |
DatabaseName2 |
STRING |
2 番目のデータベースの名前。 |
TableName2 |
STRING |
2 番目のテーブルの名前。 |
Relation |
STRING |
2 つのテーブル間の結合の種類。 |
TableSizes
このテーブルは、テーブルのサイズに関する情報を提供します。
| 列 | 型 | 説明 |
|---|---|---|
DatabaseName |
STRING |
大文字と小文字が保持されたデータベースの名前。 |
TableName |
STRING |
大文字と小文字が保持されたテーブルの名前。 |
TotalSize |
INTEGER |
テーブルのサイズ(バイト単位)。 |
Tables
このテーブルは、テーブルに関する情報を提供します。
| 列 | 型 | 説明 |
|---|---|---|
DatabaseName |
STRING |
大文字と小文字が保持されたデータベースの名前。 |
TableName |
STRING |
大文字と小文字が保持されたテーブルの名前。 |
Type |
STRING |
テーブルのタイプ。 |
TranslatedQueries
このテーブルは、クエリ変換を提供します。
| 列 | 型 | 説明 |
|---|---|---|
QueryHash |
STRING |
クエリのハッシュ。 |
TranslatedQueryText |
STRING |
ソース言語から GoogleSQL への変換の結果。 |
TranslationErrors
このテーブルは、クエリ変換のエラーに関する情報を提供します。
| 列 | 型 | 説明 |
|---|---|---|
QueryHash |
STRING |
クエリのハッシュ。 |
Severity |
STRING |
エラーの重大度(ERROR など)。 |
Category |
STRING |
エラーのカテゴリ(AttributeNotFound など)。 |
Message |
STRING |
エラーの詳細を含むメッセージ。 |
LocationOffset |
INTEGER |
エラーの位置を示す文字位置。 |
LocationLine |
INTEGER |
エラーの行番号。 |
LocationColumn |
INTEGER |
エラーの列番号。 |
LocationLength |
INTEGER |
エラーの位置の文字長。 |
UserTableRelations
| 列 | 型 | 説明 |
|---|---|---|
UserID |
STRING |
ユーザー ID。 |
TableName |
STRING |
テーブルの名前。 |
Relation |
STRING |
関係。 |
Count |
INTEGER |
数。 |
トラブルシューティング
このセクションでは、データ ウェアハウスを BigQuery に移行する際の一般的な問題とトラブルシューティング方法について説明します。
dwh-migration-dumper ツールのエラー
メタデータまたはクエリログの抽出中に発生した dwh-migration-dumper ツールのターミナルに出力されるエラーと警告のトラブルシューティングについては、メタデータの生成に関するトラブルシューティングをご覧ください。
Hive 移行のエラー
このセクションでは、データ ウェアハウスを Hive から BigQuery に移行する際に発生する可能性のある一般的な問題について説明します。
ロギングフックは、デバッグ ログメッセージを hive-server2 ログに書き込みます。問題が発生した場合は、MigrationAssessmentLoggingHook という文字列が含まれる、ロギングフックのデバッグログを確認します。
ClassNotFoundException エラーの処理
このエラーは、ロギングフック JAR ファイルの配置ミスが原因で発生している可能性があります。JAR ファイルを Hive クラスタの auxlib フォルダに追加したことを確認します。hive.aux.jars.path プロパティで JAR ファイルへのフルパスを指定することもできます(例: file://)。
構成したフォルダにサブフォルダが表示されない
この問題は、構成ミスやロギングフックの初期化中の問題が原因で発生する可能性があります。
hive-server2 デバッグログで、次のロギングフック メッセージを検索します。
Unable to initialize logger, logging disabled
Log dir configuration key 'dwhassessment.hook.base-directory' is not set, logging disabled.
Error while trying to set permission
問題の詳細を確認し、問題を解決するために修正が必要な点があるかどうかを確認します。
ファイルがフォルダに表示されない
この問題は、イベント処理中またはファイルへの書き込み中に発生した問題が原因で発生する可能性があります。
hive-server2 デバッグログで、次のロギングフック メッセージを検索します。
Failed to close writer for file
Got exception while processing event
Error writing record for query
問題の詳細を確認し、問題を解決するために修正が必要な点があるかどうかを確認します。
一部のクエリイベントが欠落している
この問題は、ロギングフックのスレッドキューのオーバーフローが原因で発生する可能性があります。
hive-server2 デバッグログで、次のロギングフック メッセージを検索します。
Writer queue is full. Ignoring event
このようなメッセージがある場合は、dwhassessment.hook.queue.capacity パラメータを増やすことを検討してください。
次のステップ
dwh-migration-dumper ツールの詳細については、dwh-migration-tools をご覧ください。
データ ウェアハウス移行の次の手順についても詳細をご覧いただけます。