Migrationsbewertung
Mit der BigQuery-Migrationsbewertung können Sie die Migration Ihres vorhandenen Data Warehouse zu BigQuery planen und prüfen. Sie können die BigQuery-Migrationsbewertung ausführen, um einen Bericht zu erstellen, in dem Sie die Kosten für die Speicherung Ihrer Daten in BigQuery ermitteln, um zu sehen, wie BigQuery Ihre bestehende Arbeitslast im Hinblick auf Kosteneinsparungen optimieren kann, und um einen Migrationsplan zu erstellen, der den Zeit- und Arbeitsaufwand für die Migration Ihres Data Warehouse zu BigQuery beschreibt.
In diesem Dokument wird beschrieben, wie Sie die BigQuery-Migrationsbewertung verwenden und wie Sie die Bewertungsergebnisse auf verschiedene Arten prüfen können. Dieses Dokument richtet sich an Nutzer, die mit der Google Cloud -Konsole und dem Batch-SQL-Übersetzer vertraut sind.
Hinweise
So bereiten Sie eine BigQuery-Migrationsbewertung vor und führen sie aus:
Extrahieren Sie Metadaten und Abfragelogs aus Ihrem Data Warehouse mit dem Tool
dwh-migration-dumper.Metadaten und Abfragelogs in Ihren Cloud Storage-Bucket hochladen.
Optional: Fragen Sie die Bewertungsergebnisse ab, um detaillierte oder spezifische Bewertungsinformationen zu erhalten.
Metadaten und Abfragelogs aus Ihrem Data Warehouse extrahieren
Sowohl Metadaten als auch Abfragelogs sind erforderlich, um die Bewertung mit Empfehlungen vorzubereiten.
Wählen Sie Ihr Data Warehouse aus, um die Metadaten und Abfragelogs zu extrahieren, die zum Ausführen der Analyse erforderlich sind:
Teradata
Voraussetzungen
- Eine Maschine, die mit dem Teradata-Quell-Data-Warehouse verbunden ist (Teradata 15 und höher wird unterstützt).
- Ein Google Cloud -Konto mit einem Cloud Storage-Bucket zum Speichern der Daten
- Ein leeres BigQuery-Dataset zum Speichern der Ergebnisse
- Leseberechtigungen für das Dataset, um die Ergebnisse aufzurufen
- Empfohlen: Zugriffsrechte auf Administratorebene für die Quelldatenbank, wenn das Extraktionstool für den Zugriff auf Systemtabellen verwendet wird
Anforderung: Logging aktivieren
Das dwh-migration-dumper-Tool extrahiert drei Arten von Logs: Abfragelogs, Hilfslogs und Logs zur Ressourcennutzung. Sie müssen das Logging für die folgenden Logtypen aktivieren, um umfangreichere Informationen zu erhalten:
- Abfragelogs: Aus der Ansicht
dbc.QryLogVund der Tabelledbc.DBQLSqlTblextrahiert. Aktivieren Sie das Logging, indem Sie die OptionWITH SQLangeben. - Hilfslogs: Aus der Tabelle
dbc.DBQLUtilityTblextrahiert. Aktivieren Sie die Protokollierung, indem Sie die OptionWITH UTILITYINFOangeben. - Logs zur Ressourcennutzung: Aus den Tabellen
dbc.ResUsageScpuunddbc.ResUsageSpmaextrahiert. Aktivieren Sie das RSS-Logging für diese beiden Tabellen.
dwh-migration-dumper-Tool ausführen
Laden Sie das dwh-migration-dumper-Tool herunter.
Laden Sie die Datei SHA256SUMS.txt herunter und führen Sie den folgenden Befehl aus, um die Richtigkeit der ZIP-Datei zu prüfen:
Bash
sha256sum --check SHA256SUMS.txt
Windows PowerShell
(Get-FileHash RELEASE_ZIP_FILENAME).Hash -eq ((Get-Content SHA256SUMS.txt) -Split " ")[0]
Ersetzen Sie RELEASE_ZIP_FILENAME durch den heruntergeladenen ZIP-Dateinamen des dwh-migration-dumper-Befehlszeilen-Extraktionstools, z. B. dwh-migration-tools-v1.0.52.zip.
Das Ergebnis True bestätigt die erfolgreiche Prüfsummenverifizierung.
Das Ergebnis False weist auf einen Überprüfungsfehler hin. Achten Sie darauf, dass die Prüfsumme und die ZIP-Dateien aus derselben Releaseversion heruntergeladen und im selben Verzeichnis gespeichert werden.
Weitere Informationen zum Einrichten und Verwenden des Extraktionstools finden Sie unter Metadaten für Übersetzung und Bewertung generieren.
Verwenden Sie das Extraktionstool, um Logs und Metadaten aus Ihrem Teradata-Data-Warehouse als zwei ZIP-Dateien zu extrahieren. Führen Sie die folgenden Befehle auf einem Computer mit Zugriff auf das Quell-Data-Warehouse aus, um die Dateien zu generieren.
Generieren Sie die Metadaten-ZIP-Datei:
dwh-migration-dumper \ --connector teradata \ --database DATABASES \ --driver path/terajdbc4.jar \ --host HOST \ --assessment \ --user USER \ --password PASSWORD
Hinweis:Das Flag --database ist für den teradata-Connector optional. Wenn nicht angegeben, werden die Metadaten für alle Datenbanken extrahiert. Dieses Flag ist nur für den teradata-Connector gültig und kann nicht mit teradata-logs verwendet werden.
Generieren Sie die ZIP-Datei mit den Abfragelogs:
dwh-migration-dumper \ --connector teradata-logs \ --driver path/terajdbc4.jar \ --host HOST \ --assessment \ --user USER \ --password PASSWORD
Hinweis:Das Flag --database wird nicht verwendet, wenn Abfragelogs mit dem Connector teradata-logs extrahiert werden. Abfragelogs werden immer für alle Datenbanken extrahiert.
Ersetzen Sie Folgendes:
PATH: Der absolute oder relative Pfad zur JAR-Datei des Treibers, die für diese Verbindung verwendet werden soll.VERSION: Die Version Ihres Treibers.HOST: Die Hostadresse.USER: Der Nutzername für die Datenbankverbindung.DATABASES: (Optional) Die durch Kommas getrennte Liste der Namen der zu extrahierenden Datenbank. Wenn nicht angegeben, werden alle Datenbanken extrahiert.PASSWORD: (Optional) Das Passwort für die Datenbankverbindung. Wenn dieses Feld leer bleibt, wird der Nutzer zur Eingabe seines Passworts aufgefordert.
Standardmäßig werden die Abfragelogs aus der Ansicht dbc.QryLogV und aus der Tabelle dbc.DBQLSqlTbl extrahiert. Wenn Sie die Abfragelogs aus einem alternativen Speicherort extrahieren möchten, können Sie die Namen der Tabellen oder Ansichten mit den Flags -Dteradata-logs.query-logs-table und -Dteradata-logs.sql-logs-table angeben.
Die Dienstprogrammlogs werden standardmäßig aus der Tabelle dbc.DBQLUtilityTbl extrahiert. Wenn Sie die Dienstprogrammlogs aus einem alternativen Speicherort extrahieren müssen, können Sie den Namen der Tabelle mit dem Flag -Dteradata-logs.utility-logs-table angeben.
Die Logs zur Ressourcennutzung werden standardmäßig aus den Tabellen dbc.ResUsageScpu und dbc.ResUsageSpma extrahiert. Wenn Sie die Logs zur Ressourcennutzung aus einem alternativen Speicherort extrahieren müssen, können Sie die Namen der Tabellen mit den Flags -Dteradata-logs.res-usage-scpu-table und -Dteradata-logs.res-usage-spma-table angeben.
Beispiel:
Bash
dwh-migration-dumper \ --connector teradata-logs \ --driver path/terajdbc4.jar \ --host HOST \ --assessment \ --user USER \ --password PASSWORD \ -Dteradata-logs.query-logs-table=pdcrdata.QryLogV_hst \ -Dteradata-logs.sql-logs-table=pdcrdata.DBQLSqlTbl_hst \ -Dteradata-logs.log-date-column=LogDate \ -Dteradata-logs.utility-logs-table=pdcrdata.DBQLUtilityTbl_hst \ -Dteradata-logs.res-usage-scpu-table=pdcrdata.ResUsageScpu_hst \ -Dteradata-logs.res-usage-spma-table=pdcrdata.ResUsageSpma_hst
Windows PowerShell
dwh-migration-dumper ` --connector teradata-logs ` --driver path\terajdbc4.jar ` --host HOST ` --assessment ` --user USER ` --password PASSWORD ` "-Dteradata-logs.query-logs-table=pdcrdata.QryLogV_hst" ` "-Dteradata-logs.sql-logs-table=pdcrdata.DBQLSqlTbl_hst" ` "-Dteradata-logs.log-date-column=LogDate" ` "-Dteradata-logs.utility-logs-table=pdcrdata.DBQLUtilityTbl_hst" ` "-Dteradata-logs.res-usage-scpu-table=pdcrdata.ResUsageScpu_hst" ` "-Dteradata-logs.res-usage-spma-table=pdcrdata.ResUsageSpma_hst"
Standardmäßig extrahiert das dwh-migration-dumper-Tool die Abfragelogs der letzten sieben Tage.
Google empfiehlt, Abfragelogs über mindestens zwei Wochen bereitzustellen, um umfangreichere Informationen zu erhalten. Mit den Flags --query-log-start und --query-log-end können Sie einen benutzerdefinierten Zeitraum festlegen. Beispiel:
dwh-migration-dumper \ --connector teradata-logs \ --driver path/terajdbc4.jar \ --host HOST \ --assessment \ --user USER \ --password PASSWORD \ --query-log-start "2023-01-01 00:00:00" \ --query-log-end "2023-01-15 00:00:00"
Sie können auch mehrere ZIP-Dateien mit Abfragelogs generieren, die verschiedene Zeiträume abdecken, und alle zur Bewertung bereitstellen.
Redshift
Voraussetzungen
- Eine Maschine, die mit Ihrem Amazon-Redshift-Quell-Data-Warehouse verbunden ist
- Ein Google Cloud -Konto mit einem Cloud Storage-Bucket zum Speichern der Daten
- Ein leeres BigQuery-Dataset zum Speichern der Ergebnisse
- Leseberechtigungen für das Dataset, um die Ergebnisse aufzurufen
- Empfohlen: Superuser-Zugriff auf die Datenbank, wenn das Extraktionstool für den Zugriff auf Systemtabellen verwendet wird
dwh-migration-dumper-Tool ausführen
Laden Sie das dwh-migration-dumper-Befehlszeilentool zur Extraktion herunter.
Laden Sie die Datei SHA256SUMS.txt herunter und führen Sie den folgenden Befehl aus, um die Richtigkeit der ZIP-Datei zu prüfen:
Bash
sha256sum --check SHA256SUMS.txt
Windows PowerShell
(Get-FileHash RELEASE_ZIP_FILENAME).Hash -eq ((Get-Content SHA256SUMS.txt) -Split " ")[0]
Ersetzen Sie RELEASE_ZIP_FILENAME durch den heruntergeladenen ZIP-Dateinamen des dwh-migration-dumper-Befehlszeilen-Extraktionstools, z. B. dwh-migration-tools-v1.0.52.zip.
Das Ergebnis True bestätigt die erfolgreiche Prüfsummenverifizierung.
Das Ergebnis False weist auf einen Überprüfungsfehler hin. Achten Sie darauf, dass die Prüfsumme und die ZIP-Dateien aus derselben Releaseversion heruntergeladen und im selben Verzeichnis gespeichert werden.
Weitere Informationen zur Verwendung des dwh-migration-dumper-Tools finden Sie auf der Seite Metadaten generieren.
Verwenden Sie das dwh-migration-dumper-Tool, um Logs und Metadaten aus Ihrem Amazon Redshift-Data-Warehouse als zwei ZIP-Dateien zu extrahieren.
Führen Sie die folgenden Befehle auf einem Computer mit Zugriff auf das Quell-Data-Warehouse aus, um die Dateien zu generieren.
Generieren Sie die Metadaten-ZIP-Datei:
dwh-migration-dumper \ --connector redshift \ --database DATABASE \ --driver PATH/redshift-jdbc42-VERSION.jar \ --host host.region.redshift.amazonaws.com \ --assessment \ --user USER \ --iam-profile IAM_PROFILE_NAME
Generieren Sie die ZIP-Datei mit den Abfragelogs:
dwh-migration-dumper \ --connector redshift-raw-logs \ --database DATABASE \ --driver PATH/redshift-jdbc42-VERSION.jar \ --host host.region.redshift.amazonaws.com \ --assessment \ --user USER \ --iam-profile IAM_PROFILE_NAME
Ersetzen Sie Folgendes:
DATABASE: Der Name der Datenbank, zu der eine Verbindung hergestellt werden soll.PATH: Der absolute oder relative Pfad zur JAR-Datei des Treibers, die für diese Verbindung verwendet werden soll.VERSION: Die Version Ihres Treibers.USER: Der Nutzername für die Datenbankverbindung.IAM_PROFILE_NAME: der Name des Amazon Redshift-IAM-Profils. Für die Amazon Redshift-Authentifizierung und den AWS-API-Zugriff erforderlich. Verwenden Sie die AWS API, um die Beschreibung von Amazon Redshift-Clustern abzurufen.
Standardmäßig speichert Amazon Redshift Abfragelogs für drei bis fünf Tage.
Standardmäßig extrahiert das dwh-migration-dumper-Tool Abfragelogs der letzten sieben Tage.
Google empfiehlt, Abfragelogs über mindestens zwei Wochen bereitzustellen, um umfangreichere Informationen zu erhalten. Möglicherweise müssen Sie das Extraktionstool mehrmals innerhalb von zwei Wochen ausführen, um die besten Ergebnisse zu erzielen. Mit den Flags --query-log-start und --query-log-end können Sie einen benutzerdefinierten Bereich festlegen.
Beispiel:
dwh-migration-dumper \ --connector redshift-raw-logs \ --database DATABASE \ --driver PATH/redshift-jdbc42-VERSION.jar \ --host host.region.redshift.amazonaws.com \ --assessment \ --user USER \ --iam-profile IAM_PROFILE_NAME \ --query-log-start "2023-01-01 00:00:00" \ --query-log-end "2023-01-02 00:00:00"
Sie können auch mehrere ZIP-Dateien mit Abfragelogs generieren, die verschiedene Zeiträume abdecken, und alle zur Bewertung bereitstellen.
Redshift Serverless
Voraussetzungen
- Eine Maschine, die mit Ihrem Amazon Redshift Serverless-Quell-Data Warehouse verbunden ist
- Ein Google Cloud -Konto mit einem Cloud Storage-Bucket zum Speichern der Daten
- Ein leeres BigQuery-Dataset zum Speichern der Ergebnisse
- Leseberechtigungen für das Dataset, um die Ergebnisse aufzurufen
- Empfohlen: Superuser-Zugriff auf die Datenbank, wenn das Extraktionstool für den Zugriff auf Systemtabellen verwendet wird
dwh-migration-dumper-Tool ausführen
Laden Sie das dwh-migration-dumper-Befehlszeilentool zur Extraktion herunter.
Weitere Informationen zur Verwendung des dwh-migration-dumper-Tools finden Sie auf der Seite Metadaten generieren.
Verwenden Sie das dwh-migration-dumper-Tool, um Nutzungslogs und Metadaten aus Ihrem Amazon Redshift Serverless-Namespace als zwei ZIP-Dateien zu extrahieren. Führen Sie die folgenden Befehle auf einem Computer mit Zugriff auf das Quell-Data-Warehouse aus, um die Dateien zu generieren.
Generieren Sie die Metadaten-ZIP-Datei:
dwh-migration-dumper \ --connector redshift \ --database DATABASE \ --driver PATH/redshift-jdbc42-VERSION.jar \ --host host.region.redshift-serverless.amazonaws.com \ --assessment \ --user USER \ --iam-profile IAM_PROFILE_NAME
Generieren Sie die ZIP-Datei mit den Abfragelogs:
dwh-migration-dumper \ --connector redshift-serverless-logs \ --database DATABASE \ --driver PATH/redshift-jdbc42-VERSION.jar \ --host host.region.redshift-serverless.amazonaws.com \ --assessment \ --user USER \ --iam-profile IAM_PROFILE_NAME
Ersetzen Sie Folgendes:
DATABASE: Der Name der Datenbank, zu der eine Verbindung hergestellt werden soll.PATH: Der absolute oder relative Pfad zur JAR-Datei des Treibers, die für diese Verbindung verwendet werden soll.VERSION: Die Version Ihres Treibers.USER: Der Nutzername für die Datenbankverbindung.IAM_PROFILE_NAME: der Name des Amazon Redshift-IAM-Profils. Für die Amazon Redshift-Authentifizierung und den AWS-API-Zugriff erforderlich. Verwenden Sie die AWS API, um die Beschreibung von Amazon Redshift-Clustern abzurufen.
In Amazon Redshift Serverless werden Nutzungsprotokolle sieben Tage lang gespeichert. Wenn ein größerer Bereich erforderlich ist, empfiehlt Google, Daten mehrmals über einen längeren Zeitraum hinweg zu extrahieren.
Snowflake
Voraussetzungen
Sie müssen die folgenden Anforderungen erfüllen, um Metadaten und Abfragelogs aus Snowflake zu extrahieren:
- Eine Maschine, die eine Verbindung zu Ihrer Snowflake-Instanz herstellen kann.
- Ein Google Cloud -Konto mit einem Cloud Storage-Bucket zum Speichern der Daten.
- Ein leeres BigQuery-Dataset zum Speichern der Ergebnisse. Alternativ können Sie ein BigQuery-Dataset erstellen, wenn Sie den Bewertungsjob über die Google Cloud Console-UI erstellen.
- Snowflake-Nutzer mit
IMPORTED PRIVILEGES-Zugriff auf die DatenbankSnowflake. Wir empfehlen, einenSERVICE-Nutzer mit einer auf Schlüsselpaaren basierenden Authentifizierung zu erstellen. Dies ist die sichere Methode für den Zugriff auf die Snowflake-Datenplattform, ohne dass MFA-Tokens generiert werden müssen.- Folgen Sie der offiziellen Snowflake-Anleitung, um einen neuen Dienstnutzer zu erstellen. Sie müssen das RSA-Schlüsselpaar generieren und dem Snowflake-Nutzer den öffentlichen Schlüssel zuweisen.
- Der Dienstnutzer sollte die Rolle
ACCOUNTADMINhaben oder von einem Kontoadministrator eine Rolle mit denIMPORTED PRIVILEGES-Berechtigungen für die DatenbankSnowflakeerhalten haben. - Alternativ zur Schlüsselpaar-Authentifizierung können Sie die passwortbasierte Authentifizierung verwenden. Ab August 2025 erzwingt Snowflake jedoch die MFA für alle passwortbasierten Nutzer. Dazu müssen Sie die MFA-Push-Benachrichtigung genehmigen, wenn Sie unser Extraktionstool verwenden.
dwh-migration-dumper-Tool ausführen
Laden Sie das dwh-migration-dumper-Befehlszeilentool zur Extraktion herunter.
Laden Sie die Datei SHA256SUMS.txt herunter und führen Sie den folgenden Befehl aus, um die Richtigkeit der ZIP-Datei zu prüfen:
Bash
sha256sum --check SHA256SUMS.txt
Windows PowerShell
(Get-FileHash RELEASE_ZIP_FILENAME).Hash -eq ((Get-Content SHA256SUMS.txt) -Split " ")[0]
Ersetzen Sie RELEASE_ZIP_FILENAME durch den heruntergeladenen ZIP-Dateinamen des dwh-migration-dumper-Befehlszeilen-Extraktionstools, z. B. dwh-migration-tools-v1.0.52.zip.
Das Ergebnis True bestätigt die erfolgreiche Prüfsummenverifizierung.
Das Ergebnis False weist auf einen Überprüfungsfehler hin. Achten Sie darauf, dass die Prüfsumme und die ZIP-Dateien aus derselben Releaseversion heruntergeladen und im selben Verzeichnis gespeichert werden.
Weitere Informationen zur Verwendung des dwh-migration-dumper-Tools finden Sie auf der Seite Metadaten generieren.
Verwenden Sie das dwh-migration-dumper-Tool, um Logs und Metadaten aus Ihrem Snowflake-Data-Warehouse als zwei ZIP-Dateien zu extrahieren. Führen Sie die folgenden Befehle auf einem Computer mit Zugriff auf das Quell-Data-Warehouse aus, um die Dateien zu generieren.
Generieren Sie die Metadaten-ZIP-Datei:
dwh-migration-dumper \ --connector snowflake \ --host HOST_NAME \ --user USER_NAME \ --role ROLE_NAME \ --warehouse WAREHOUSE \ --assessment \ --private-key-file PRIVATE_KEY_PATH \ --private-key-password PRIVATE_KEY_PASSWORD
Generieren Sie die ZIP-Datei mit den Abfragelogs:
dwh-migration-dumper \ --connector snowflake-logs \ --host HOST_NAME \ --user USER_NAME \ --role ROLE_NAME \ --warehouse WAREHOUSE \ --query-log-start STARTING_DATE \ --query-log-end ENDING_DATE \ --assessment \ --private-key-file PRIVATE_KEY_PATH \ --private-key-password PRIVATE_KEY_PASSWORD
Ersetzen Sie Folgendes:
HOST_NAME: der Hostname Ihrer Snowflake-Instanz.USER_NAME: der Nutzername für die Datenbankverbindung, wobei der Nutzer die Zugriffsberechtigungen haben muss, die im Abschnitt Anforderungen beschrieben sind.PRIVATE_KEY_PATH: Der Pfad zum privaten RSA-Schlüssel, der für die Authentifizierung verwendet wird.PRIVATE_KEY_PASSWORD: (Optional) Das Passwort, das beim Erstellen des privaten RSA-Schlüssels verwendet wurde. Nur erforderlich, wenn der private Schlüssel verschlüsselt ist.ROLE_NAME: (Optional) die Nutzerrolle beim Ausführen desdwh-migration-dumper-Tools, z. B.ACCOUNTADMIN.WAREHOUSE: das Warehouse zum Ausführen der Verschiebevorgänge. Wenn Sie mehrere virtuelle Warehouses haben, können Sie ein beliebiges Warehouse angeben, um diese Abfrage auszuführen. Wenn Sie diese Abfrage mit den im Abschnitt Anforderungen beschriebenen Zugriffsberechtigungen ausführen, werden alle Warehouse-Artefakte in diesem Konto extrahiert.STARTING_DATE: (Optional) wird verwendet, um das Startdatum in einem Zeitraum von Abfragelogs im FormatYYYY-MM-DDanzugeben.ENDING_DATE: (Optional) wird verwendet, um das Enddatum in einem Zeitraum von Abfragelogs im FormatYYYY-MM-DDanzugeben.
Sie können auch mehrere ZIP-Dateien mit Abfragelogs generieren, die nicht-überlappende Zeiträume abdecken, und alle zur Bewertung bereitstellen.
Oracle
Wenn Sie Feedback oder Unterstützung für dieses Feature benötigen, senden Sie eine E-Mail an bq-edw-migration-support@google.com.
Voraussetzungen
Sie müssen die folgenden Anforderungen erfüllen, um Metadaten und Abfragelogs aus Oracle zu extrahieren:
- Ihre Oracle-Datenbank muss Version 11g R1 oder höher sein.
- Eine Maschine, die eine Verbindung zu Ihrer Oracle-Instanz herstellen kann.
- Java 8 oder höher.
- Ein Google Cloud -Konto mit einem Cloud Storage-Bucket zum Speichern der Daten.
- Ein leeres BigQuery-Dataset zum Speichern der Ergebnisse. Alternativ können Sie ein BigQuery-Dataset erstellen, wenn Sie den Bewertungsjob über die Google Cloud Console-UI erstellen.
- Ein allgemeiner Oracle-Nutzer mit SYSDBA-Berechtigungen.
dwh-migration-dumper-Tool ausführen
Laden Sie das dwh-migration-dumper-Befehlszeilentool zur Extraktion herunter.
Laden Sie die Datei SHA256SUMS.txt herunter und führen Sie den folgenden Befehl aus, um die Richtigkeit der ZIP-Datei zu prüfen:
sha256sum --check SHA256SUMS.txt
Weitere Informationen zur Verwendung des dwh-migration-dumper-Tools finden Sie auf der Seite Metadaten generieren.
Verwenden Sie das dwh-migration-dumper-Tool, um Metadaten und Leistungsstatistiken in die ZIP-Datei zu extrahieren. Standardmäßig werden Statistiken aus dem Oracle AWR extrahiert, für das das Oracle Tuning and Diagnostics Pack erforderlich ist. Wenn diese Daten nicht verfügbar sind, verwendet dwh-migration-dumper stattdessen STATSPACK.
Bei Mandantendatenbanken muss das dwh-migration-dumper-Tool im Root-Container ausgeführt werden. Wenn Sie sie in einer der einsteckbaren Datenbanken ausführen, fehlen Leistungsstatistiken und Metadaten zu anderen einsteckbaren Datenbanken.
Generieren Sie die Metadaten-ZIP-Datei:
dwh-migration-dumper \ --connector oracle-stats \ --host HOST_NAME \ --port PORT \ --oracle-service SERVICE_NAME \ --assessment \ --driver JDBC_DRIVER_PATH \ --user USER_NAME \ --password
Ersetzen Sie Folgendes:
HOST_NAME: Der Hostname Ihrer Oracle-Instanz.PORT: die Portnummer der Verbindung. Der Standardwert ist 1521.SERVICE_NAME: Der Oracle-Dienstname, der für die Verbindung verwendet werden soll.JDBC_DRIVER_PATH: Der absolute oder relative Pfad zur JAR-Datei des Treibers. Sie können diese Datei von der Seite Oracle JDBC-Treiber herunterladen herunterladen. Sie sollten die Treiberversion auswählen, die mit Ihrer Datenbankversion kompatibel ist.USER_NAME: Name des Nutzers, der für die Verbindung zu Ihrer Oracle-Instanz verwendet wird. Der Nutzer muss die im Abschnitt zu den Anforderungen beschriebenen Zugriffsberechtigungen haben.
Hadoop / Cloudera
Wenn Sie Feedback oder Unterstützung für dieses Feature benötigen, senden Sie eine E-Mail an bq-edw-migration-support@google.com.
Voraussetzungen
Sie benötigen Folgendes, um Metadaten aus Cloudera zu extrahieren:
- Eine Maschine, die eine Verbindung zur Cloudera Manager API herstellen kann.
- Ein Google Cloud -Konto mit einem Cloud Storage-Bucket zum Speichern der Daten.
- Ein leeres BigQuery-Dataset zum Speichern der Ergebnisse. Alternativ können Sie ein BigQuery-Dataset erstellen, wenn Sie den Bewertungsjob erstellen.
dwh-migration-dumper-Tool ausführen
Laden Sie das
dwh-migration-dumper-Befehlszeilentool zur Extraktion herunter.Laden Sie die
SHA256SUMS.txt-Datei herunter.Prüfen Sie in Ihrer Befehlszeilenumgebung, ob die ZIP-Datei korrekt ist:
sha256sum --check SHA256SUMS.txt
Weitere Informationen zur Verwendung des
dwh-migration-dumper-Tools finden Sie unter Metadaten für Übersetzung und Bewertung generieren.Verwenden Sie das
dwh-migration-dumper-Tool, um Metadaten und Leistungsstatistiken in die ZIP-Datei zu extrahieren:dwh-migration-dumper \ --connector cloudera-manager \ --user USER_NAME \ --password PASSWORD \ --url URL_PATH \ --yarn-application-types "APP_TYPES" \ --pagination-page-size PAGE_SIZE \ --start-date START_DATE \ --end-date END_DATE \ --assessment
Ersetzen Sie Folgendes:
USER_NAME: Der Name des Nutzers, der eine Verbindung zu Ihrer Cloudera Manager-Instanz herstellen soll.PASSWORD: Das Passwort für Ihre Cloudera Manager-Instanz.URL_PATH: Der URL-Pfad zur Cloudera Manager API, z. B.https://localhost:7183/api/v55/.APP_TYPES(optional): Die durch Kommas getrennten YARN-Anwendungstypen, die aus dem Cluster exportiert werden. Der Standardwert istMAPREDUCE,SPARK,Oozie Launcher.PAGE_SIZE(optional): Die Anzahl der Datensätze pro Cloudera-Antwort. Der Standardwert ist1000.START_DATE(optional): Das Startdatum für Ihren Verlaufsexport im ISO 8601-Format, z. B.2025-05-29. Der Standardwert ist 90 Tage vor dem aktuellen Datum.END_DATE(optional): Das Enddatum für Ihren Verlaufsexport im ISO 8601-Format, z. B.2025-05-30. Der Standardwert ist das aktuelle Datum.
Oozie in Ihrem Cloudera-Cluster verwenden
Wenn Sie Oozie in Ihrem Cloudera-Cluster verwenden, können Sie den Oozie-Jobverlauf mit dem Oozie-Connector exportieren. Sie können Oozie mit Kerberos-Authentifizierung oder einfacher Authentifizierung verwenden.
Führen Sie für die Kerberos-Authentifizierung Folgendes aus:
kinit dwh-migration-dumper \ --connector oozie \ --url URL_PATH \ --assessment
Ersetzen Sie Folgendes:
URL_PATH(optional): Der Oozie-Server-URL-Pfad. Wenn Sie den URL-Pfad nicht angeben, wird er aus der UmgebungsvariableOOZIE_URLübernommen.
Führen Sie für die Basisauthentifizierung Folgendes aus:
dwh-migration-dumper \ --connector oozie \ --user USER_NAME \ --password PASSWORD \ --url URL_PATH \ --assessment
Ersetzen Sie Folgendes:
USER_NAME: Der Name des Oozie-Nutzers.PASSWORD: das Nutzerpasswort.URL_PATH(optional): Der Oozie-Server-URL-Pfad. Wenn Sie den URL-Pfad nicht angeben, wird er aus der UmgebungsvariableOOZIE_URLübernommen.
Airflow in Ihrem Cloudera-Cluster verwenden
Wenn Sie Airflow in Ihrem Cloudera-Cluster verwenden, können Sie den DAG-Verlauf mit dem Airflow-Connector exportieren:
dwh-migration-dumper \ --connector airflow \ --user USER_NAME \ --password PASSWORD \ --url URL \ --driver "DRIVER_PATH" \ --start-date START_DATE \ --end-date END_DATE \ --assessment
Ersetzen Sie Folgendes:
USER_NAME: Der Name des Airflow-Nutzers.PASSWORD: das NutzerpasswortURL: der JDBC-String für die Airflow-DatenbankDRIVER_PATH: der Pfad zum JDBC-TreiberSTART_DATE(optional): Das Startdatum für Ihren Verlaufsexport im ISO 8601-FormatEND_DATE(optional): Das Enddatum für Ihren Verlaufsexport im ISO 8601-Format
Hive in Ihrem Cloudera-Cluster verwenden
Informationen zur Verwendung des Hive-Connectors finden Sie auf dem Tab „Apache Hive“.
Apache Hive
Voraussetzungen
- Maschine, die mit Ihrem Apache Hive-Data-Warehouse der Quelle verbunden ist (die BigQuery-Migrationsbewertung unterstützt Hive auf Tez und MapReduce und Apache Hive-Versionen zwischen 2.2 und 3.1 (einschließlich))
- Ein Google Cloud -Konto mit einem Cloud Storage-Bucket zum Speichern der Daten
- Ein leeres BigQuery-Dataset zum Speichern der Ergebnisse
- Leseberechtigungen für das Dataset, um die Ergebnisse aufzurufen
- Zugriff auf Ihr Apache Hive-Quell-Data-Warehouse zum Konfigurieren der Extraktion von Abfragelogs
- Aktuelle Tabellen-, Partitions- und Spaltenstatistiken
Die BigQuery-Migrationsbewertung verwendet Tabellen-, Partitions- und Spaltenstatistiken, um Ihr Apache Hive-Data-Warehouse besser zu verstehen und umfassende Informationen zu liefern. Wenn die Konfigurationseinstellung hive.stats.autogather in Ihrem Apache Hive-Quell-Data-Warehouse auf false gesetzt ist, empfiehlt Google, sie zu aktivieren oder Statistiken manuell zu aktualisieren, bevor Sie das dwh-migration-dumper-Tool ausführen.
dwh-migration-dumper-Tool ausführen
Laden Sie das dwh-migration-dumper-Befehlszeilentool zur Extraktion herunter.
Laden Sie die Datei SHA256SUMS.txt herunter und führen Sie den folgenden Befehl aus, um die Richtigkeit der ZIP-Datei zu prüfen:
Bash
sha256sum --check SHA256SUMS.txt
Windows PowerShell
(Get-FileHash RELEASE_ZIP_FILENAME).Hash -eq ((Get-Content SHA256SUMS.txt) -Split " ")[0]
Ersetzen Sie RELEASE_ZIP_FILENAME durch den heruntergeladenen ZIP-Dateinamen des dwh-migration-dumper-Befehlszeilen-Extraktionstools, z. B. dwh-migration-tools-v1.0.52.zip.
Das Ergebnis True bestätigt die erfolgreiche Prüfsummenverifizierung.
Das Ergebnis False weist auf einen Überprüfungsfehler hin. Achten Sie darauf, dass die Prüfsumme und die ZIP-Dateien aus derselben Releaseversion heruntergeladen und im selben Verzeichnis gespeichert werden.
Weitere Informationen zur Verwendung des dwh-migration-dumper-Tools finden Sie unter Metadaten für Übersetzung und Bewertung generieren.
Verwenden Sie das dwh-migration-dumper-Tool, um Metadaten aus Ihrem Hive-Data-Warehouse als ZIP-Datei zu generieren.
Ohne Authentifizierung
Führen Sie zum Generieren der Metadaten-ZIP-Datei den folgenden Befehl auf einem Computer aus, der Zugriff auf das Quell-Data-Warehouse hat:
dwh-migration-dumper \ --connector hiveql \ --database DATABASES \ --host hive.cluster.host \ --port 9083 \ --assessment
Mit Kerberos-Authentifizierung
Melden Sie sich als Nutzer mit Zugriff auf den Apache Hive-Metastore an und generieren Sie ein Kerberos-Ticket, um sich beim Metastore zu authentifizieren. Generieren Sie dann die Metadaten-ZIP-Datei mit dem folgenden Befehl:
JAVA_OPTS="-Djavax.security.auth.useSubjectCredsOnly=false" \ dwh-migration-dumper \ --connector hiveql \ --database DATABASES \ --host hive.cluster.host \ --port 9083 \ --hive-kerberos-url PRINCIPAL/HOST \ -Dhiveql.rpc.protection=hadoop.rpc.protection \ --assessment
Ersetzen Sie Folgendes:
DATABASES: eine durch Kommas getrennte Liste der Namen der zu extrahierenden Datenbank. Wenn nicht angegeben, werden alle Datenbanken extrahiert.PRINCIPAL: das Kerberos-Hauptkonto für das das Ticket ausgestellt wirdHOST: der Kerberos-Hostname, für den das Ticket ausgestellt wirdhadoop.rpc.protection: die Qualität des Schutzes (QOP) der SASL-Konfigurationsebene (Simple Authentication and Security Layer), entspricht dem Wert des Parametershadoop.rpc.protectionin der/etc/hadoop/conf/core-site.xml-Datei mit einem der folgenden Werte:authenticationintegrityprivacy
Abfragelogs mit dem Logging-Hook hadoop-migration-assessment extrahieren
So extrahieren Sie Abfragelogs:
- Laden Sie den Logging-Hook
hadoop-migration-assessmenthoch. - Konfigurieren Sie die Logging-Hook-Attribute.
- Überprüfen Sie den Logging-Hook.
Logging-Hook hadoop-migration-assessment hochladen
Laden Sie den Logging-Hook
hadoop-migration-assessmentfür die Abfragelog-Extraktion herunter, der die Hive-Logging-Hook-Datei enthält.Extrahieren Sie die JAR-Datei.
Wenn Sie prüfen müssen, ob das Tool die Compliance-Anforderungen erfüllt, überprüfen Sie den Quellcode aus dem GitHub-Repository für den Logging-Hook
hadoop-migration-assessmentund kompilieren Sie Ihre eigene Binärdatei.Kopieren Sie die JAR-Datei in den Hilfsbibliotheksordner in allen Clustern, in denen Sie das Abfrage-Logging aktivieren möchten. Je nach Anbieter müssen Sie den Hilfsbibliotheksordner in den Clustereinstellungen suchen und die JAR-Datei in den Hilfsbibliotheksordner im Hive-Cluster übertragen.
Richten Sie Konfigurationsattribute für den Logging-Hook
hadoop-migration-assessmentein. Je nach Hadoop-Anbieter müssen Sie die Clustereinstellungen über die UI-Konsole bearbeiten. Ändern Sie die Datei/etc/hive/conf/hive-site.xmloder wenden Sie die Konfiguration mit dem Konfigurationsmanager an.
Attribute konfigurieren
Wenn Sie bereits andere Werte für die folgenden Konfigurationsschlüssel haben, hängen Sie die Einstellungen mit einem Komma an (,). Zum Einrichten des hadoop-migration-assessment-Logging-Hooks sind folgende Konfigurationseinstellungen erforderlich:
hive.exec.failure.hooks:com.google.cloud.bigquery.dwhassessment.hooks.MigrationAssessmentLoggingHookhive.exec.post.hooks:com.google.cloud.bigquery.dwhassessment.hooks.MigrationAssessmentLoggingHookhive.exec.pre.hooks:com.google.cloud.bigquery.dwhassessment.hooks.MigrationAssessmentLoggingHookhive.aux.jars.path: Fügen Sie den Pfad zur JAR-Datei für den Logging-Hook hinzu, z. B.file://./HiveMigrationAssessmentQueryLogsHooks_deploy.jar dwhassessment.hook.base-directory: der Pfad zum Ausgabeordner der Abfragelogs. Beispiel:hdfs://tmp/logs/.Sie können auch die folgenden optionalen Konfigurationen festlegen:
dwhassessment.hook.queue.capacity: die Warteschlangenkapazität für die Logging-Threads für Abfrageereignisse. Der Standardwert ist64.dwhassessment.hook.rollover-interval: die Häufigkeit, mit der die Datei-Übertragung ausgeführt werden soll. Beispiel:600s. Der Standardwert beträgt 3.600 Sekunden (1 Stunde).dwhassessment.hook.rollover-eligibility-check-interval: die Häufigkeit, mit der die Berechtigungsprüfung der Datei-Übertragung im Hintergrund ausgelöst wird. Beispiel:600s. Der Standardwert beträgt 600 Sekunden (10 Minuten).
Logging-Hook überprüfen
Nachdem Sie den Prozess hive-server2 neu gestartet haben, führen Sie eine Testabfrage aus und analysieren Ihre Debugging-Logs. Die folgende Meldung wird angezeigt:
Logger successfully started, waiting for query events. Log directory is '[dwhassessment.hook.base-directory value]'; rollover interval is '60' minutes; rollover eligibility check is '10' minutes
Der Logging-Hook erstellt einen datumspartitionierten Unterordner im konfigurierten Ordner. Die Avro-Datei mit Abfrageereignissen wird nach der Beendigung des Prozesses dwhassessment.hook.rollover-interval oder des Prozesses hive-server2 in diesem Ordner angezeigt. Sie können in Ihren Debugging-Logs nach ähnlichen Einträgen suchen, um den Status der Übertragung zu sehen:
Updated rollover time for logger ID 'my_logger_id' to '2023-12-25T10:15:30'
Performed rollover check for logger ID 'my_logger_id'. Expected rollover time is '2023-12-25T10:15:30'
Die Übertragung erfolgt in den angegebenen Intervallen oder wenn sich der Tag ändert. Wenn sich das Datum ändert, erstellt der Logging-Hook auch einen neuen Unterordner für dieses Datum.
Google empfiehlt, Abfragelogs über mindestens zwei Wochen bereitzustellen, um umfangreichere Informationen zu erhalten.
Sie können auch Ordner mit Abfragelogs aus verschiedenen Hive-Clustern generieren und alle für eine einzelne Bewertung bereitstellen.
Informatica
Wenn Sie Feedback oder Unterstützung für dieses Feature benötigen, senden Sie eine E-Mail an bq-edw-migration-support@google.com.
Voraussetzungen
- Zugriff auf den Informatica PowerCenter Repository Manager-Client
- Ein Google Cloud -Konto mit einem Cloud Storage-Bucket zum Speichern der Daten.
- Ein leeres BigQuery-Dataset zum Speichern der Ergebnisse. Alternativ können Sie ein BigQuery-Dataset erstellen, wenn Sie den Bewertungsjob über die Google Cloud Konsole erstellen.
Anforderung: Objektdateien exportieren
Sie können die GUI des Informatica PowerCenter Repository Manager verwenden, um Ihre Objektdateien zu exportieren. Weitere Informationen finden Sie unter Objekte exportieren.
Alternativ können Sie auch den pmrep-Befehl ausführen, um Ihre Objektdateien zu exportieren. Gehen Sie dazu so vor:
- Führen Sie den Befehl
pmrep connectaus, um eine Verbindung zum Repository herzustellen:
pmrep connect -r `REPOSITORY_NAME` -d `DOMAIN_NAME` -n `USERNAME` -x `PASSWORD`
Ersetzen Sie Folgendes:
REPOSITORY_NAME: Name des Repositorys, mit dem Sie eine Verbindung herstellen möchtenDOMAIN_NAME: Name der Domain für das RepositoryUSERNAME: Nutzername für die Verbindung zum RepositoryPASSWORD: Passwort des Nutzernamens
- Nachdem Sie eine Verbindung zum Repository hergestellt haben, verwenden Sie den Befehl
pmrep objectexport, um die erforderlichen Objekte zu exportieren:
pmrep objectexport -n `OBJECT_NAME` -o `OBJECT_TYPE` -f `FOLDER_NAME` -u `OUTPUT_FILE_NAME.xml`
Ersetzen Sie Folgendes:
OBJECT_NAME: Name eines bestimmten Objekts, das exportiert werden sollOBJECT_TYPE: Objekttyp des angegebenen ObjektsFOLDER_NAME: Name des Ordners, der das zu exportierende Objekt enthältOUTPUT_FILE_NAME: Name der XML-Datei, die die Objektinformationen enthalten soll
Metadaten und Abfragelogs in Cloud Storage hochladen
Nachdem Sie die Metadaten und Abfragelogs aus Ihrem Data Warehouse extrahiert haben, können Sie die Dateien in einen Cloud Storage-Bucket hochladen, um mit der Migrationsbewertung fortzufahren.
Teradata
Laden Sie die Metadaten und eine oder mehrere ZIP-Dateien mit Abfragelogs in Ihren Cloud Storage-Bucket hoch. Weitere Informationen zum Erstellen von Buckets und zum Hochladen von Dateien in Cloud Storage erhalten Sie unter Buckets erstellen und Objekte aus einem Dateisystem hochladen. Das Limit für die unkomprimierte Gesamtgröße aller Dateien in der Metadaten-Zip-Datei beträgt 50 GB.
Die Einträge in allen ZIP-Dateien, die Abfragelogs enthalten, sind so unterteilt:
- Abfrageverlaufsdateien mit dem Präfix
query_history_. - Zeitachsendateien mit den Präfixen
utility_logs_,dbc.ResUsageScpu_unddbc.ResUsageSpma_.
Das Limit für die unkomprimierte Gesamtgröße aller Abfrageverlaufsdateien beträgt 5 TB. Das Limit für die unkomprimierte Gesamtgröße aller Zeitachsendateien beträgt 1 TB.
Wenn die Abfragelogs in einer anderen Datenbank archiviert werden, lesen Sie die Beschreibung des Flags -Dteradata-logs.query-logs-table und -Dteradata-logs.sql-logs-table weiter oben in diesem Abschnitt, in dem erläutert wird, wie Sie einen alternativen Speicherort für die Abfragelogs angeben.
Redshift
Laden Sie die Metadaten und eine oder mehrere ZIP-Dateien mit Abfragelogs in Ihren Cloud Storage-Bucket hoch. Weitere Informationen zum Erstellen von Buckets und zum Hochladen von Dateien in Cloud Storage erhalten Sie unter Buckets erstellen und Objekte aus einem Dateisystem hochladen. Das Limit für die unkomprimierte Gesamtgröße aller Dateien in der Metadaten-Zip-Datei beträgt 50 GB.
Die Einträge in allen ZIP-Dateien, die Abfragelogs enthalten, sind so unterteilt:
- Abfrageverlaufsdateien mit den Präfixen
querytext_undddltext_. - Zeitachsendateien mit den Präfixen
query_queue_info_,wlm_query_undquerymetrics_.
Das Limit für die unkomprimierte Gesamtgröße aller Abfrageverlaufsdateien beträgt 5 TB. Das Limit für die unkomprimierte Gesamtgröße aller Zeitachsendateien beträgt 1 TB.
Redshift Serverless
Laden Sie die Metadaten und eine oder mehrere ZIP-Dateien mit Abfragelogs in Ihren Cloud Storage-Bucket hoch. Weitere Informationen zum Erstellen von Buckets und zum Hochladen von Dateien in Cloud Storage erhalten Sie unter Buckets erstellen und Objekte aus einem Dateisystem hochladen.
Snowflake
Laden Sie die Metadaten und die ZIP-Datei(en) mit Abfragelogs und Nutzungsverlauf in den Cloud Storage-Bucket hoch. Beim Hochladen dieser Dateien in Cloud Storage müssen die folgenden Anforderungen erfüllt sein:
- Die unkomprimierte Gesamtgröße aller Dateien in der Metadaten-ZIP-Datei darf maximal 50 GB betragen.
- Die Metadaten-ZIP-Datei und die ZIP-Datei mit Abfragelogs müssen in einen Cloud Storage-Ordner hochgeladen werden. Wenn Sie mehrere ZIP-Dateien mit nicht überlappenden Abfragelogs haben, können Sie alle hochladen.
- Sie müssen alle Dateien in denselben Cloud Storage-Ordner hochladen.
- Sie müssen alle ZIP-Dateien mit Metadaten und Abfragelogs genau so hochladen, wie sie vom
dwh-migration-dumper-Tool ausgegeben werden. Extrahieren, kombinieren oder ändern Sie sie nicht. - Die unkomprimierte Gesamtgröße aller Abfrageverlaufsdateien muss kleiner als 5 TB sein.
Weitere Informationen zum Erstellen von Buckets und zum Hochladen von Dateien in Cloud Storage erhalten Sie unter Buckets erstellen und Objekte aus einem Dateisystem hochladen.
Oracle
Wenn Sie Feedback oder Unterstützung für dieses Feature benötigen, senden Sie eine E-Mail an bq-edw-migration-support@google.com.
Laden Sie die ZIP-Datei mit Metadaten und Leistungsstatistiken in einen Cloud Storage-Bucket hoch. Der Dateiname der ZIP-Datei ist standardmäßig dwh-migration-oracle-stats.zip. Sie können ihn jedoch anpassen, indem Sie ihn im Flag --output angeben. Das Limit für die unkomprimierte Gesamtgröße aller Dateien in der ZIP-Datei beträgt 50 GB.
Weitere Informationen zum Erstellen von Buckets und zum Hochladen von Dateien in Cloud Storage erhalten Sie unter Buckets erstellen und Objekte aus einem Dateisystem hochladen.
Hadoop / Cloudera
Wenn Sie Feedback oder Unterstützung für dieses Feature benötigen, senden Sie eine E-Mail an bq-edw-migration-support@google.com.
Laden Sie die ZIP-Datei mit Metadaten und Leistungsstatistiken in einen Cloud Storage-Bucket hoch. Der Dateiname der ZIP-Datei ist standardmäßig dwh-migration-cloudera-manager-RUN_DATE.zip (z. B. dwh-migration-cloudera-manager-20250312T145808.zip). Sie können ihn aber mit dem Flag --output anpassen. Das Limit für die unkomprimierte Gesamtgröße aller Dateien in der ZIP-Datei beträgt 50 GB.
Weitere Informationen zum Erstellen von Buckets und zum Hochladen von Dateien in Cloud Storage finden Sie unter Bucket erstellen und Objekte aus einem Dateisystem hochladen.
Apache Hive
Laden Sie die Metadaten und Ordner mit Abfragelogs aus einem oder mehreren Hive-Clustern in Ihren Cloud Storage-Bucket hoch. Weitere Informationen zum Erstellen von Buckets und zum Hochladen von Dateien in Cloud Storage erhalten Sie unter Buckets erstellen und Objekte aus einem Dateisystem hochladen.
Das Limit für die unkomprimierte Gesamtgröße aller Dateien in der Metadaten-Zip-Datei beträgt 50 GB.
Mit dem Cloud Storage-Connector können Sie Abfrage-Logs direkt in den Cloud Storage-Ordner kopieren. Die Ordner mit Unterordnern mit Abfragelogs müssen in denselben Cloud Storage-Ordner hochgeladen werden, in den auch die Metadaten-ZIP-Datei hochgeladen wird.
Abfragelog-Ordner haben Abfrageverlaufsdateien mit dem Präfix dwhassessment_. Das Limit für die unkomprimierte Gesamtgröße aller Abfrageverlaufsdateien beträgt 5 TB.
Informatica
Wenn Sie Feedback oder Unterstützung für dieses Feature benötigen, senden Sie eine E-Mail an bq-edw-migration-support@google.com.
Laden Sie eine ZIP-Datei mit Ihren Informatica XML-Repository-Objekten in einen Cloud Storage-Bucket hoch. Diese ZIP-Datei muss auch eine compilerworks-metadata.yaml-Datei mit Folgendem enthalten:
product: arguments: "ConnectorArguments{connector=informatica, assessment=true}"
Das Limit für die unkomprimierte Gesamtgröße aller Dateien in der ZIP-Datei beträgt 50 GB.
Weitere Informationen zum Erstellen von Buckets und zum Hochladen von Dateien in Cloud Storage erhalten Sie unter Buckets erstellen und Objekte aus einem Dateisystem hochladen.
BigQuery-Migrationsbewertung ausführen
Führen Sie die folgenden Schritte aus, um die BigQuery-Migrationsbewertung auszuführen. Bei diesen Schritten wird davon ausgegangen, dass Sie die Metadatendateien in einen Cloud Storage-Bucket hochgeladen haben, wie im vorherigen Abschnitt beschrieben.
Erforderliche Berechtigungen
Zum Aktivieren des BigQuery Migration Service benötigen Sie die folgenden IAM-Berechtigungen (Identity and Access Management):
resourcemanager.projects.getresourcemanager.projects.updateserviceusage.services.enableserviceusage.services.get
Für den Zugriff auf den BigQuery Migration Service und dessen Verwendung benötigen Sie die folgenden Berechtigungen für das Projekt:
bigquerymigration.workflows.createbigquerymigration.workflows.getbigquerymigration.workflows.listbigquerymigration.workflows.deletebigquerymigration.subtasks.getbigquerymigration.subtasks.list
Zum Ausführen von BigQuery Migration Service benötigen Sie außerdem die folgenden Berechtigungen.
Berechtigungen zum Zugreifen auf die Cloud Storage-Buckets für Eingabe- und Ausgabedateien:
storage.objects.getfür den Cloud Storage-Quell-Bucketstorage.objects.listfür den Cloud Storage-Quell-Bucketstorage.objects.createfür den Cloud Storage-Ziel-Bucketstorage.objects.deletefür den Cloud Storage-Ziel-Bucketstorage.objects.updatefür den Cloud Storage-Ziel-Bucketstorage.buckets.getstorage.buckets.list
Berechtigung zum Lesen und Aktualisieren des BigQuery-Datasets, in das der BigQuery-Migrationsdienst die Ergebnisse schreibt:
bigquery.datasets.updatebigquery.datasets.getbigquery.datasets.createbigquery.datasets.deletebigquery.jobs.createbigquery.jobs.deletebigquery.jobs.listbigquery.jobs.updatebigquery.tables.createbigquery.tables.getbigquery.tables.getDatabigquery.tables.listbigquery.tables.updateData
Um einen Looker Studio-Bericht für einen Nutzer freizugeben, müssen Sie die folgenden Rollen zuweisen:
roles/bigquery.dataViewerroles/bigquery.jobUser
Wenn Sie dieses Dokument anpassen möchten, um Ihr eigenes Projekt und Ihren eigenen Nutzer in den Befehlen zu verwenden, bearbeiten Sie diese Variablen: PROJECT, USER_EMAIL.
Erstellen Sie eine benutzerdefinierte Rolle mit den Berechtigungen, die zum Verwenden der BigQuery-Migrationsbewertung erforderlich sind:
gcloud iam roles create BQMSrole \ --project=PROJECT \ --title=BQMSrole \ --permissions=bigquerymigration.subtasks.get,bigquerymigration.subtasks.list,bigquerymigration.workflows.create,bigquerymigration.workflows.get,bigquerymigration.workflows.list,bigquerymigration.workflows.delete,resourcemanager.projects.update,resourcemanager.projects.get,serviceusage.services.enable,serviceusage.services.get,storage.objects.get,storage.objects.list,storage.objects.create,storage.objects.delete,storage.objects.update,bigquery.datasets.get,bigquery.datasets.update,bigquery.datasets.create,bigquery.datasets.delete,bigquery.tables.get,bigquery.tables.create,bigquery.tables.updateData,bigquery.tables.getData,bigquery.tables.list,bigquery.jobs.create,bigquery.jobs.update,bigquery.jobs.list,bigquery.jobs.delete,storage.buckets.list,storage.buckets.get
Benutzerdefinierte Rolle BQMSrole einem Nutzer erteilen:
gcloud projects add-iam-policy-binding \ PROJECT \ --member=user:USER_EMAIL \ --role=projects/PROJECT/roles/BQMSrole
Weisen Sie einem Nutzer, für den Sie den Bericht freigeben möchten, die erforderlichen Rollen zu:
gcloud projects add-iam-policy-binding \ PROJECT \ --member=user:USER_EMAIL \ --role=roles/bigquery.dataViewer gcloud projects add-iam-policy-binding \ PROJECT \ --member=user:USER_EMAIL \ --role=roles/bigquery.jobUser
Unterstützte Standorte
Das Feature zur Migrationsbewertung von BigQuery wird an zwei Arten von Standorten unterstützt:
Eine Region ist ein bestimmter geografischer Ort, wie z. B. London.
Eine Multiregion ist ein großes geografisches Gebiet (beispielsweise die USA), das mindestens zwei geografische Regionen enthält. Standorte mit mehreren Regionen können größere Kontingente als einzelne Regionen bieten.
Weitere Informationen zu Regionen und Zonen finden Sie unter Geografie und Regionen.
Regionen
In der folgenden Tabelle sind die Regionen in Amerika aufgeführt, in denen die BigQuery-Migrationsanalyse verfügbar ist.| Beschreibung der Region | Name der Region | Details |
|---|---|---|
| Columbus, Ohio | us-east5 |
|
| Dallas | us-south1 |
|
| Iowa | us-central1 |
|
| South Carolina | us-east1 |
|
| Northern Virginia | us-east4 |
|
| Oregon | us-west1 |
|
| Los Angeles | us-west2 |
|
| Salt Lake City | us-west3 |
| Beschreibung der Region | Name der Region | Details |
|---|---|---|
| Singapur | asia-southeast1 |
|
| Tokio | asia-northeast1 |
| Beschreibung der Region | Name der Region | Details |
|---|---|---|
| Belgien | europe-west1 |
|
| Finnland | europe-north1 |
|
| Frankfurt | europe-west3 |
|
| London | europe-west2 |
|
| Madrid | europe-southwest1 |
|
| Niederlande | europe-west4 |
|
| Paris | europe-west9 |
|
| Turin | europe-west12 |
|
| Warschau | europe-central2 |
|
| Zürich | europe-west6 |
|
Multiregionen
In der folgenden Tabelle sind die Multiregionen aufgeführt, in denen die BigQuery-Migrationsbewertung verfügbar ist.| Beschreibung des multiregionalen Standorts | Name des multiregionalen Standorts |
|---|---|
| Rechenzentren in Mitgliedsstaaten der Europäischen Union | EU |
| Rechenzentren in den USA | US |
Hinweise
Bevor Sie die Bewertung ausführen, müssen Sie die BigQuery Migration API aktivieren und ein BigQuery-Dataset erstellen, um die Ergebnisse der Bewertung zu speichern.
BigQuery Migration API aktivieren
Aktivieren Sie die BigQuery Migration API wie im Folgenden dargestellt:
Rufen Sie in der Google Cloud Console die Seite BigQuery Migration API auf.
Klicken Sie auf Aktivieren.
Dataset für die Bewertungsergebnisse erstellen
Die BigQuery-Migrationsbewertung schreibt die Bewertungsergebnisse in Tabellen in BigQuery. Erstellen Sie zuerst ein Dataset, in dem die Tabellen gespeichert werden. Wenn Sie den Looker Studio-Bericht freigeben, müssen Sie Nutzern auch die Berechtigung zum Lesen dieses Datasets erteilen. Weitere Informationen finden Sie unter Bericht für Nutzer bereitstellen.
Migrationsbewertung ausführen
Console
Öffnen Sie in der Google Cloud Console die Seite BigQuery.
Klicken Sie im Navigationsmenü auf Bewertung.
Klicken Sie auf Bewertung starten.
Füllen Sie das Dialogfeld für die Bewertungskonfiguration aus.
- Geben Sie als Anzeigename einen Namen ein. Er darf Buchstaben, Ziffern oder Unterstriche enthalten. Dieser Name dient nur Anzeigezwecken und muss nicht eindeutig sein.
Wählen Sie in der Liste Datenspeicherort einen Speicherort für den Bewertungsjob aus. Der Bewertungsjob muss sich am selben Speicherort wie der Cloud Storage-Bucket mit den extrahierten Dateien und das BigQuery-Ausgabedataset befinden. Wenn sich der Cloud Storage-Bucket oder das BigQuery-Dataset jedoch in einer Multiregion befindet, muss sich der Bewertungsjob in einer der Regionen innerhalb dieser Multiregion befinden.
Wenn sich der Bewertungsstandort in einer Multi-Region
USoderEUbefindet, müssen sich der Cloud Storage-Bucket und das BigQuery-Dataset am selben Standort oder an einem Standort in derselben Multi-Region befinden. Weitere Informationen zu Standortbeschränkungen finden Sie unter Überlegungen zum Standort für das Laden von Daten in BigQuery.Wählen Sie für Datenquelle für Bewertung Ihr Data Warehouse aus.
Geben Sie unter Pfad zu Eingabedateien den Pfad zu dem Cloud Storage-Bucket ein, der Ihre extrahierten Dateien enthält.
Führen Sie eine der folgenden Optionen aus, um auszuwählen, wie die Bewertungsergebnisse gespeichert werden:
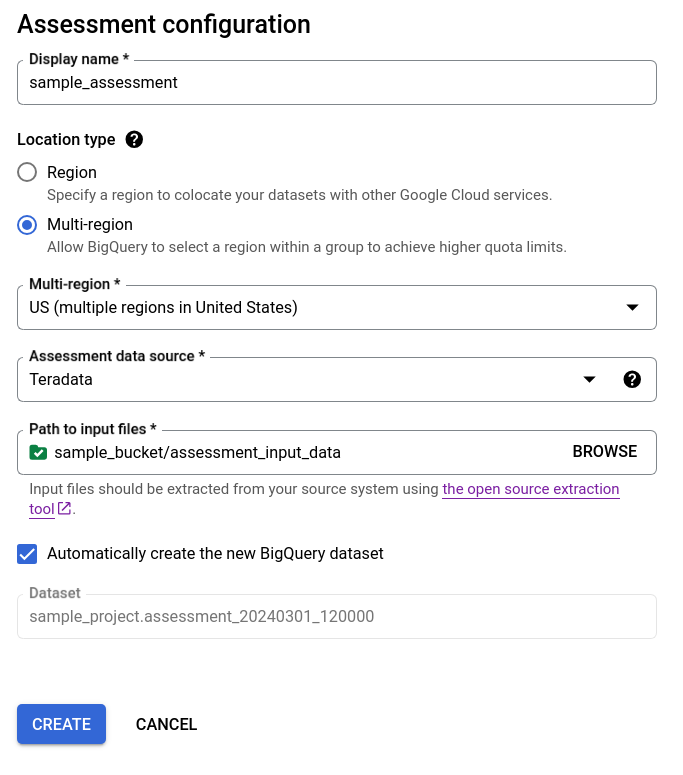
- Lassen Sie das Kästchen Neues BigQuery-Dataset automatisch erstellen angeklickt, damit das BigQuery-Dataset automatisch erstellt wird. Der Name des Datasets wird automatisch generiert.
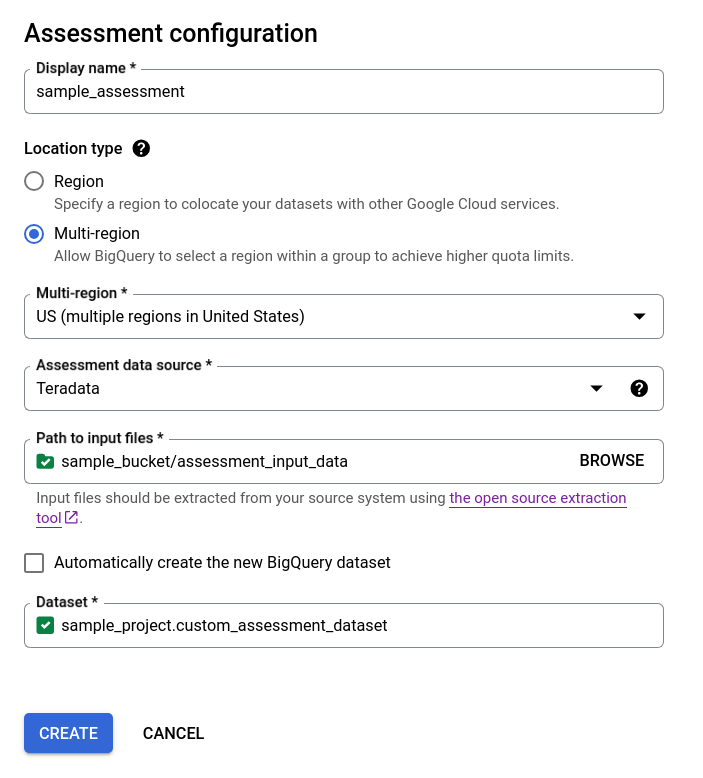
- Entfernen Sie das Häkchen aus dem Kästchen Neues BigQuery-Dataset automatisch erstellen und wählen Sie entweder das vorhandene leere BigQuery-Dataset im Format
projectId.datasetIdaus oder erstellen Sie einen neuen Dataset-Namen. In dieser Option können Sie den Namen des BigQuery-Datasets auswählen.
Option 1: Automatische BigQuery-Dataset-Generierung (Standard)
Option 2: BigQuery-Dataset manuell erstellen:
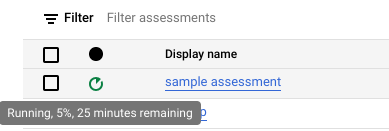
Klicken Sie auf Erstellen. Der Status des Jobs wird in der Liste der Bewertungsjobs angezeigt.
Während die Bewertung ausgeführt wird, können Sie den Fortschritt und die geschätzte Zeit bis zum Abschluss in der Kurzinfo des Statussymbols prüfen.
Während die Bewertung ausgeführt wird, können Sie in der Liste der Bewertungsjobs auf den Link Bericht ansehen klicken, um den Bewertungsbericht mit unvollständigen Daten in Looker Studio aufzurufen. Es kann einige Zeit dauern, bis der Link Bericht aufrufen angezeigt wird, während die Bewertung ausgeführt wird. Der Bericht wird in einem neuen Tab geöffnet.
Der Bericht wird während der Verarbeitung mit neuen Daten aktualisiert. Aktualisieren Sie den Tab mit dem Bericht oder klicken Sie noch einmal auf Bericht aufrufen, um den aktualisierten Bericht aufzurufen.
Klicken Sie nach Abschluss der Bewertung auf Bericht ansehen, um den vollständigen Bewertungsbericht in Looker Studio aufzurufen. Der Bericht wird in einem neuen Tab geöffnet.
API
Rufen Sie die Methode create mit einem definierten Workflow auf.
Rufen Sie dann die Methode start auf, um den Bewertungs-Workflow zu starten.
Die Bewertung erstellt Tabellen im BigQuery-Dataset, das Sie zuvor erstellt haben. Sie können diese Informationen zu den Tabellen und Abfragen abfragen, die in Ihrem vorhandenen Data Warehouse verwendet werden. Informationen zu den Ausgabedateien der Übersetzung finden Sie unter Batch SQL-Übersetzer.
Teilbares aggregiertes Bewertungsergebnis
Für Amazon Redshift-, Teradata- und Snowflake-Bewertungen erstellt der Workflow neben dem zuvor erstellten BigQuery-Dataset ein weiteres einfaches Dataset mit demselben Namen sowie dem Suffix _shareableRedactedAggregate. Dieses Dataset enthält stark aggregierte Daten, die aus dem Ausgabedataset abgeleitet werden, und keine personenidentifizierbaren Informationen.
Informationen dazu, wie Sie das Dataset finden, prüfen und sicher für andere Nutzer freigeben, finden Sie unter Ausgabetabellen der Migrationsbewertung abfragen.
Die Funktion ist standardmäßig aktiviert, kann aber über die öffentliche API deaktiviert werden.
Informationen zur Prüfung
Klicken Sie zum Aufrufen der Seite mit den Bewertungsdetails auf den Anzeigenamen in der Liste der Bewertungsjobs.

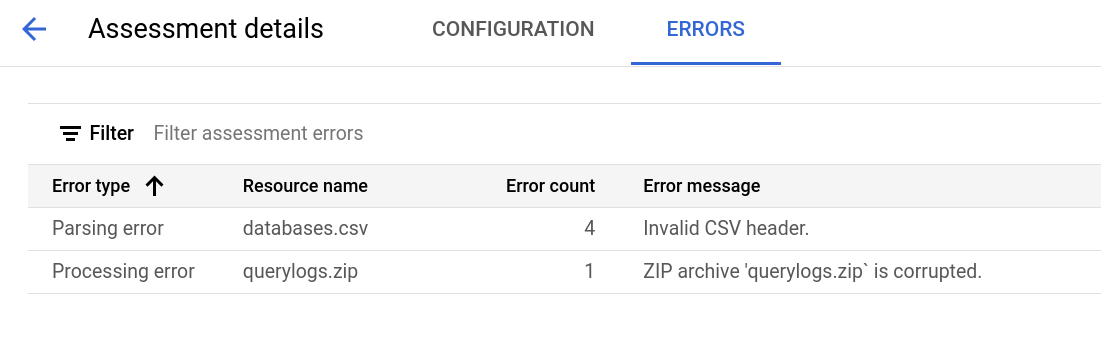
Die Seite mit den Bewertungsdetails enthält den Tab Konfiguration, auf dem Sie weitere Informationen zu einem Bewertungsjob aufrufen können, und den Tab Fehler, auf dem Sie alle Fehler, die während der Bewertungsverarbeitung aufgetreten sind.
Rufen Sie den Tab Konfiguration auf, um die Attribute der Bewertung aufzurufen.
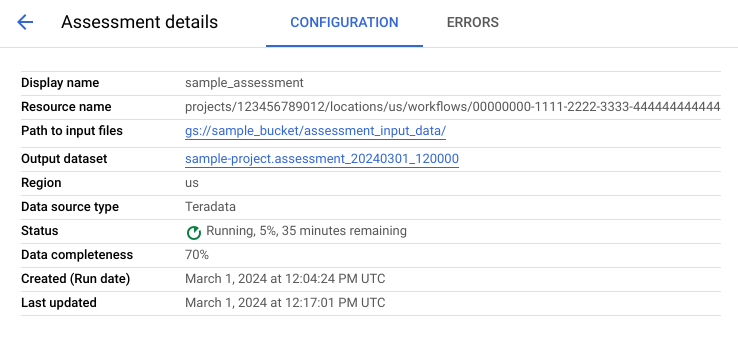
Rufen Sie den Tab Fehler auf, um die Fehler anzuzeigen, die während der Bewertungsverarbeitung aufgetreten sind.
Looker Studio-Bericht erstellen und freigeben
Nach Abschluss der Bewertungsaufgaben können Sie einen Looker Studio-Bericht mit den Ergebnissen erstellen und freigeben.
Bericht ansehen
Klicken Sie neben der jeweiligen Bewertungsaufgabe auf den Link Bericht ansehen. Der Looker Studio-Bericht wird in einem neuen Tab im Vorschaumodus geöffnet. Sie können den Vorschaumodus verwenden, um den Inhalt des Berichts zu prüfen, bevor Sie ihn weiter freigeben.
Der Bericht sieht ungefähr so aus:
Wenn Sie sehen möchten, welche Ansichten im Bericht enthalten sind, wählen Sie Ihr Data Warehouse aus:
Teradata
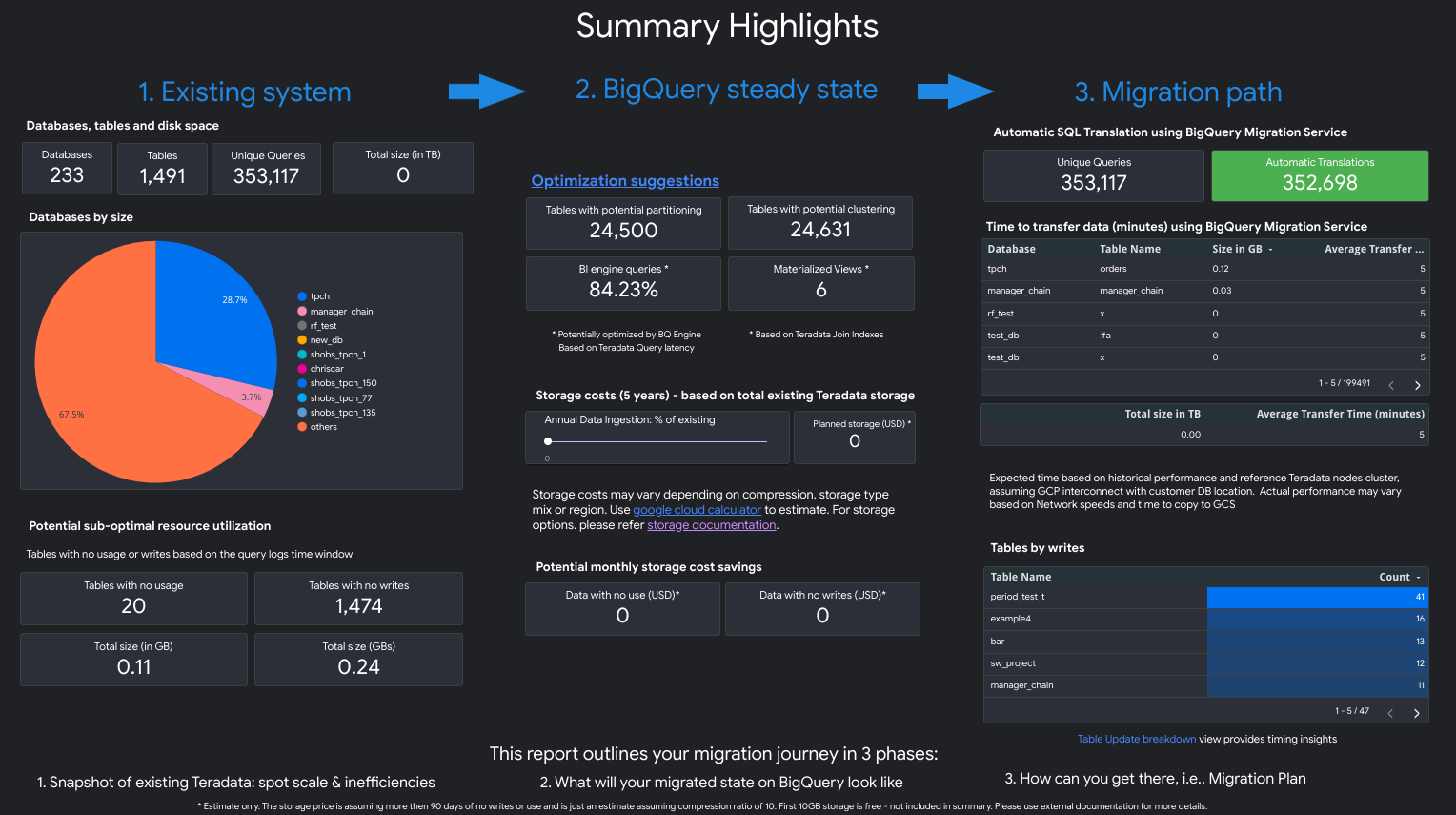
Der Bericht besteht aus drei Teilen, dem eine Seite mit einer Übersicht der Highlights vorangestellt ist. Diese Seite enthält die folgenden Abschnitte:
- Vorhandenes System. Dieser Abschnitt ist ein Snapshot des vorhandenen Teradata-Systems und der vorhandenen Nutzung, einschließlich der Anzahl der Datenbanken, Schemas, Tabellen und der Gesamtgröße in TB. Außerdem werden die Schemas nach Größe aufgelistet und es wird auf eine potenzielle suboptimale Ressourcennutzung (Tabellen ohne Schreibvorgänge oder mit wenigen Lesevorgängen) verwiesen.
- BigQuery stabiler Zustand – Transformationen (Vorschläge). Dieser Abschnitt zeigt, wie das System nach der Migration in BigQuery aussieht. Er enthält Vorschläge zur Optimierung von Arbeitslasten in BigQuery (und Vermeidung von unnötiger Inanspruchnahme).
- Migrationsplan. Dieser Abschnitt enthält Informationen zum Migrationsaufwand selbst, z. B. zum Wechsel vom vorhandenen System zum stabilen Zustand von BigQuery. In diesem Abschnitt werden die Anzahl der automatisch übersetzten Abfragen und die erwartete Zeit zum Verschieben der einzelnen Tabellen in BigQuery angegeben.
Die Details der einzelnen Abschnitte umfassen Folgendes:
Vorhandenes System.
- Berechnungen und Abfragen
- CPU-Auslastung:
- Heatmap der stündlichen durchschnittlichen CPU-Auslastung (Gesamtsystemressourcenauslastung)
- Abfragen nach Stunde und Tag mit CPU-Auslastung
- Abfragen nach Typ (Lesen/Schreiben) mit CPU-Auslastung
- Anwendungen mit CPU-Auslastung
- Overlay der stündlichen CPU-Auslastung mit durchschnittlicher stündlicher Abfrageleistung und durchschnittlicher stündlicher Anwendungsleistung
- Abfragehistogramm nach Typ und Abfragedauer
- Detailansicht der Anwendungen (App, Nutzer, eindeutige Abfragen, Aufschlüsselung nach Berichterstellung und ETL)
- CPU-Auslastung:
- Speicherübersicht
- Datenbanken nach Volumen, Ansichten und Zugriffsraten
- Tabellen mit Zugriffsraten nach Nutzern, Abfragen, Schreibvorgängen und dem Erstellen temporärer Tabellen
- Anwendungen: Zugriffsraten und IP-Adressen
BigQuery stabiler Zustand – Transformationen (Vorschläge)
- Join-Indizes, die in materialisierte Ansichten konvertiert wurden
- Clustering und Partitionierung von Kandidaten nach Metadaten und Nutzung
- Abfragen mit niedriger Latenz, die als Kandidaten für BigQuery BI Engine identifiziert wurden
- Mit Standardwerten konfigurierte Spalten, die das Feature zur Spaltenbeschreibung zum Speichern von Standardwerten verwenden
- Eindeutige Indexe in Teradata (um Zeilen mit nicht eindeutigen Schlüsseln in einer Tabelle zu verhindern) verwenden Staging-Tabellen und eine
MERGE-Anweisung, um nur eindeutige Einträge in die Zieltabellen einzufügen und dann Duplikate zu verwerfen. - Verbleibende Abfragen und Schema werden unverändert übersetzt
Migrationsplan
- Detaillierte Ansicht mit automatisch übersetzten Abfragen
- Gesamtzahl der Abfragen mit Filterung nach Nutzer, Anwendung, betroffenen Tabellen, abgefragten Tabellen und Abfragetyp
- Buckets von Abfragen mit ähnlichen Mustern, die gruppiert und zusammen angezeigt werden, sodass der Nutzer die Übersetzungsphilosophie nach Abfragetyp sehen kann
- Abfragen, die menschliches Eingreifen erfordern
- Abfragen mit Verstößen gegen die lexikalische BigQuery-Struktur
- Benutzerdefinierte Funktionen und Verfahren
- Reservierte BigQuery-Keywords
- Tabellen werden nach Schreib- und Lesevorgängen gruppiert, um sie zum Verschieben zu gruppieren.
- Datenmigration mit dem BigQuery Data Transfer Service: Geschätzte Migrationszeit nach Tabelle
Der Abschnitt Vorhandenes System enthält die folgenden Ansichten:
- Systemübersicht
- Die Systemübersicht bietet eine allgemeine Übersicht über die Volume-Messwerte der Schlüsselkomponenten im vorhandenen System für einen bestimmten Zeitraum. Die auszuwertende Zeitachse hängt von den Logs ab, die von der BigQuery-Migrationsbewertung analysiert wurden. In dieser Ansicht erhalten Sie einen schnellen Einblick in die Nutzung des Quell-Data-Warehouse, das für die Migrationsplanung verwendet werden kann.
- Tabellen-Volumen
- Die Ansicht „Tabellen-Volume“ enthält Statistiken zu den größten Tabellen und Datenbanken, die von der BigQuery-Migrationsbewertung gefunden wurden. Da das Extrahieren großer Tabellen aus dem Quell-Data-Warehouse-System länger dauern kann, kann diese Ansicht bei der Migrationsplanung und -sequenzierung hilfreich sein.
- Tabellennutzung
- Die Ansicht „Tabellennutzung“ enthält Statistiken zu den Tabellen, die im Quell-Data-Warehouse-System stark genutzt werden. Anhand der Statistiken zu stark genutzten Tabellen können Sie verstehen, welche Tabellen möglicherweise viele Abhängigkeiten haben und eine zusätzliche Planung während des Migrationsprozesses erfordern.
- Anwendungen
- Die Ansichten "Anwendungsnutzung" und "Anwendungsmuster" enthalten Statistiken zu Anwendungen, die während der Verarbeitung von Logs gefunden wurden. Diese Ansichten ermöglichen Nutzern, die Nutzung bestimmter Anwendungen im Zeitverlauf sowie die Auswirkungen auf die Ressourcennutzung zu verstehen. Während einer Migration ist es wichtig, die Aufnahme und Nutzung von Daten zu visualisieren, um die Abhängigkeiten des Data Warehouse besser zu verstehen und die Auswirkungen der gemeinsamen Migration verschiedener abhängiger Anwendungen zu analysieren. Die IP-Adresstabelle kann nützlich sein, um die genaue Anwendung mit dem Data Warehouse über JDBC-Verbindungen zu bestimmen.
- Abfragen
- Die Abfrageansicht enthält eine Aufschlüsselung der ausgeführten SQL-Anweisungen und Statistiken zu deren Nutzung. Sie können das Histogramm für Abfragetyp und -zeit verwenden, um niedrige Zeiträume der Systemauslastung und optimale Tageszeiten für die Datenübertragung zu ermitteln. Sie können diese Ansicht auch verwenden, um häufig ausgeführte Abfragen und die Nutzer zu bestimmen, die diese Ausführungen aufrufen.
- Datenbanken
- Die Ansicht der Datenbanken enthält Messwerte zur Größe, Tabellen, Ansichten und im Quell-Data-Warehouse definierte Verfahren. Diese Ansicht bietet Einblick in das Volumen der zu migrierenden Objekte.
- Datenbankkopplung
- Die Ansicht "Datenbankkopplung" bietet eine allgemeine Ansicht der Datenbanken und Tabellen, auf die in einer einzigen Abfrage zugegriffen wird. Diese Ansicht kann zeigen, auf welche Tabellen und Datenbanken häufig verwiesen wird und was Sie für die Migrationsplanung verwenden können.
Der Abschnitt BigQuery stabiler Zustand enthält die folgenden Ansichten:
- Tabellen ohne Nutzung
- In der Ansicht „Tabellen ohne Nutzung“ werden Tabellen angezeigt, in denen die BigQuery-Migrationsbewertung während des analysierten Logzeitraums keine Nutzung finden konnte. Eine mangelnde Nutzung kann darauf hinweisen, dass Sie diese Tabelle während der Migration nicht zu BigQuery übertragen müssen oder dass die Kosten für die Speicherung von Daten in BigQuery niedriger sein können. Sie sollten die Liste der nicht verwendeten Tabellen validieren, da sie außerhalb des Logzeitraums verwendet werden könnten, z. B. eine Tabelle, die nur alle drei oder sechs Monate verwendet wird.
- Tabellen ohne Schreibvorgänge
- In der Ansicht „Tabellen ohne Schreibvorgänge“ werden Tabellen angezeigt, in denen die BigQuery-Migrationsbewertung während des Analysezeitraums keine Aktualisierungen finden konnte. Fehlende Schreibvorgänge können darauf hinweisen, dass Sie die Speicherkosten in BigQuery senken können.
- Abfragen mit niedriger Latenz
- In der Ansicht „Abfragen mit niedriger Latenz“ wird eine Verteilung der Abfragelaufzeiten basierend auf den analysierten Logdaten angezeigt. Wenn das Diagramm zur Verteilung der Abfragedauer eine große Anzahl von Abfragen mit weniger als 1 Sekunde anzeigt, sollten Sie BigQuery BI Engine aktivieren, um BI- und andere Arbeitslasten mit niedriger Latenz zu beschleunigen.
- Materialisierte Ansichten
- Die materialisierte Ansicht liefert weitere Optimierungsvorschläge, um die Leistung in BigQuery zu verbessern.
- Clustering und Partitionierung
Die Ansicht "Partitionierung und Clustering" enthält Tabellen, die von Partitionierung, Clustering oder beidem profitieren würden.
Die Metadatenvorschläge werden dadurch erreicht, dass das Schema des Quelldatenspeichers (Partitionierung und Primärschlüssel in der Quelltabelle) analysiert und das nächstgelegene BigQuery-Äquivalent ermittelt wird, um ähnliche Optimierungsmerkmale zu erreichen.
Die Arbeitslastvorschläge werden durch die Analyse der Quellabfragelogs generiert. Die Empfehlung wird durch die Analyse der Arbeitslasten ermittelt, insbesondere durch die Klauseln
WHEREoderJOINin den analysierten Abfragelogs.- Empfehlung für Clustering
Die Partitionierungsansicht zeigt Tabellen an, die je nach ihrer Definition zur Partitionierungseinschränkung mehr als 10.000 Partitionen haben können. Diese Tabellen sind in der Regel gute Kandidaten für BigQuery-Clustering, das eine detaillierte Tabellenpartitionierung ermöglicht.
- Eindeutige Einschränkungen
In der Ansicht „Eindeutige Einschränkungen“ werden sowohl die
SET-Tabellen als auch die eindeutigen Indexe im Quell-Data-Warehouse angezeigt. In BigQuery wird empfohlen, Staging-Tabellen und eineMERGE-Anweisung zu verwenden, um nur eindeutige Einträge in eine Zieltabelle einzufügen. Verwenden Sie den Inhalt dieser Ansicht, um festzustellen, für welche Tabellen Sie während der Migration möglicherweise die ETL anpassen müssen.- Standardwerte/Diagnoseeinschränkungen
Diese Ansicht zeigt Tabellen, in denen Diagnoseeinschränkungen zum Festlegen von Standardspaltenwerten verwendet werden. Standardspaltenwerte angeben
Der Abschnitt Migrationspfad des Berichts enthält die folgenden Ansichten:
- SQL-Übersetzung
- In der SQL-Übersetzungsansicht werden die Anzahl und Details der Abfragen aufgelistet, die von der BigQuery-Migrationsbewertung automatisch konvertiert wurden und keinen manuellen Eingriff erfordern. Die automatische SQL-Übersetzung erreicht in der Regel hohe Übersetzungsraten, wenn Metadaten bereitgestellt werden. Diese Ansicht ist interaktiv und ermöglicht die Analyse gängiger Abfragen und wie diese übersetzt werden.
- Offline-Aufwand
- Die Ansicht „Offline-Aufwand“ erfasst die Bereiche, die manuell erforderlich sind, einschließlich bestimmter UDFs und potenzieller lexikalischer Struktur- und Syntaxverstöße für Tabellen oder Spalten.
- Reservierte BigQuery-Keywords
- Die Ansicht "Reservierte BigQuery-Keywords" zeigt die erkannte Nutzung von Keywords an, die in der GoogleSQL-Sprache eine besondere Bedeutung haben. Sie können nur als Kennungen verwendet werden, wenn sie in Backticks
`) eingeschlossen sind. - Zeitplan für Tabellenaktualisierungen
- In der Ansicht „Zeitplan für die Tabellenaktualisierung“ sehen Sie, wann und wie häufig Tabellen aktualisiert werden, damit Sie planen können, wie und wann Sie sie migrieren.
- Datenmigration zu BigQuery
- In der Ansicht „Datenmigration zu BigQuery“ wird der Migrationspfad mit der erwarteten Zeit für die Migration Ihrer Daten mit dem Data Transfer Service von BigQuery Data Transfer Service dargestellt. Weitere Informationen finden Sie in der Anleitung zu BigQuery Data Transfer Service für Teradata.
Der Abschnitt „Anhang“ enthält die folgenden Ansichten.
- Berücksichtigung der Groß-/Kleinschreibung
- Die Ansicht „Groß-/Kleinschreibung beachten“ zeigt Tabellen im Quell-Data Warehouse an, die für Vergleiche konfiguriert sind, bei denen die Groß- und Kleinschreibung nicht berücksichtigt wird. Standardmäßig wird bei Stringvergleichen in BigQuery die Groß-/Kleinschreibung beachtet. Weitere Informationen finden Sie unter Sortierung.
Redshift
- Migrations-Highlights
- Die Ansicht „Highlights der Migration“ enthält eine Zusammenfassung der drei Abschnitte des Berichts:
- Der Bereich Vorhandenes System enthält Informationen zur Anzahl der Datenbanken, Schemas, Tabellen und der Gesamtgröße des vorhandenen Redshift-Systems. Außerdem werden die Schemas nach Größe und potenzieller suboptimaler Ressourcennutzung aufgeführt. Anhand dieser Informationen können Sie Ihre Daten optimieren- Entfernen, partitionieren oder gruppieren Sie dazu die Tabellen.
- Der Bereich BigQuery stabiler Zustand enthält Informationen dazu, wie Ihre Daten nach der Migration in BigQuery aussehen, einschließlich der Anzahl der Abfragen, die automatisch mit dem BigQuery Migration Service übersetzt werden können. In diesem Abschnitt werden auch die Kosten für das Speichern Ihrer Daten in BigQuery auf der Grundlage der jährlichen Datenaufnahmerate angezeigt. Außerdem werden Optimierungsvorschläge für Tabellen, Bereitstellung und Speicherplatz angezeigt.
- Im Bereich Migrationspfad finden Sie Informationen zur Migration selbst. Für jede Tabelle werden die voraussichtliche Migrationszeit, die Anzahl der Zeilen in der Tabelle und ihre Größe angezeigt.
Der Abschnitt Vorhandenes System enthält die folgenden Ansichten:
- Abfragen nach Typ und Zeitplan
- In der Ansicht „Abfragen nach Typ“ und „Zeitplan“ werden Ihre Abfragen in ETL/Write und Reporting/Aggregation kategorisiert. Wenn Sie Ihre Abfrage im Laufe der Zeit sehen, können Sie Ihre vorhandenen Nutzungsmuster verstehen sowie Burstiness und potenzielle Überdimensionierungen erkennen, die sich auf Kosten und Leistung auswirken können.
- Abfrage in die Warteschlange stellen
- Die Ansicht „Abfragewarteschlange“ enthält zusätzliche Details zur Systemlast, einschließlich Abfragevolumen, Mixing und Leistungseinbußen aufgrund von Warteschlangen, z. B. unzureichende Ressourcen.
- Abfragen und WLM-Skalierung
- Die Ansicht „Abfragen“ und „WLM-Skalierung“ identifiziert die Gleichzeitigkeitsskalierung als zusätzliche Kosten und Konfigurationskomplexität. Sie zeigt, wie Ihr Redshift-System Abfragen auf der Grundlage der von Ihnen festgelegten Regeln weiterleitet und wie sich Warteschlangen, Gleichzeitigkeitsskalierung und verworfene Abfragen auf die Leistung auswirken.
- In Warteschlange stellen und warten
- Die Ansicht für „Warteschlangen“ und „Wartezeiten“ bietet einen detaillierteren Einblick in Warteschlangen- und Wartezeiten für Abfragen im Laufe der Zeit.
- WLM-Klassen und Leistung
- Die Ansicht „WLM-Klassen“ und „Leistung“ bietet eine optionale Möglichkeit, Ihre Regeln BigQuery zuzuordnen. Wir empfehlen jedoch, dass BigQuery Ihre Anfragen automatisch weiterleitet.
- Informationen zum Abfrage- und Tabellen-Volume
- In der Statistikansicht zu Abfrage- und Tabellen-Volume werden Abfragen nach Größe, Häufigkeit und Top-Nutzern aufgelistet. So können Sie die Quellen der Systemlast kategorisieren und die Migration Ihrer Arbeitslasten planen.
- Datenbanken und Schemas
- Die Ansicht der Datenbanken enthält Messwerte zur Größe, Tabellen, Ansichten und im Quell-Data-Warehouse definierte Verfahren. Diese Ansicht bietet Einblick in die Menge der zu migrierenden Objekte.
- Tabellen-Volumen
- Die Ansicht „Tabellen-Volumen“ liefert Statistiken über die größten Tabellen und Datenbanken und zeigt, wie auf sie zugegriffen wird. Da das Extrahieren großer Tabellen aus dem Quell-Data-Warehouse-System länger dauern kann, kann diese Ansicht bei der Migrationsplanung und -sequenzierung hilfreich sein.
- Tabellennutzung
- Die Ansicht „Tabellennutzung“ enthält Statistiken zu den Tabellen, die im Quell-Data-Warehouse-System stark genutzt werden. Anhand der Statistiken zu stark genutzten Tabellen können Sie verstehen, welche Tabellen möglicherweise viele Abhängigkeiten haben und eine zusätzliche Planung während des Migrationsprozesses erfordern.
- Importer und Exporter
- Die Ansicht „Importer und Exporter“ enthält Informationen zu Daten und Nutzern, die am Datenimport (mit
COPY-Abfragen) und Datenexport (mitUNLOAD-Abfragen) beteiligt sind. Mithilfe dieser Ansicht lassen sich die Staging-Ebene und die Prozesse im Zusammenhang mit Datenaufnahme und Exporten identifizieren. - Clusterauslastung
- Die Ansicht „Cluster Utilization“ (Cluster-Auslastung) enthält allgemeine Informationen zu allen verfügbaren Clustern und zeigt die CPU-Auslastung für jeden Cluster an. Mit dieser Ansicht können Sie die Kapazitätsreserve des Systems besser nachvollziehen.
Der Abschnitt BigQuery stabiler Zustand enthält die folgenden Ansichten:
- Clustering und Partitionierung
Die Ansicht "Partitionierung und Clustering" enthält Tabellen, die von Partitionierung, Clustering oder beidem profitieren würden.
Die Metadatenvorschläge werden dadurch erreicht, dass das Schema des Quelldatenspeichers (wie Sort Key und Dist Key in der Quelltabelle) analysiert und das nächstgelegene BigQuery-Äquivalent ermittelt wird, um ähnliche Optimierungsmerkmale zu erreichen.
Die Vorschläge für Arbeitslasten werden durch die Analyse der Quellabfragelogs generiert. Die Empfehlung wird durch die Analyse der Arbeitslasten ermittelt, insbesondere durch die Klauseln
WHEREoderJOINin den analysierten Abfragelogs.Unten auf der Seite finden Sie eine übersetzte CREATE TABLE-Anweisung mit allen Optimierungen. Alle übersetzten DDL-Anweisungen können auch aus dem Dataset extrahiert werden. Übersetzte DDL-Anweisungen werden gespeichert in Tabelle „
SchemaConversion“ in Spalte „CreateTableDDL“.Die Empfehlungen im Bericht gelten nur für Tabellen, die größer sind als 1 GB, da kleine Tabellen nicht von Clustering und Partitionierung profitieren. DDL für alle Tabellen (auch für Tabellen, die kleiner als 1 GB sind) sind jedoch in der Tabelle
SchemaConversionverfügbar.- Tabellen ohne Nutzung
In der Ansicht „Tabellen ohne Nutzung“ werden Tabellen angezeigt, in denen BigQuery-Migrationsbewertung keine Nutzung während der analysierten Logzeiträume festgestellt hat. Mangelnde Nutzung kann darauf hindeuten, dass Sie diese Tabelle nicht während der Migration zu BigQuery übertragen müssen, oder dass die Kosten für die Datenspeicherung BigQuery (in Rechnung gestellt als Langzeitspeicherung) niedriger sein könnten. Wir empfehlen, dass Sie die Liste der nicht verwendeten Tabellen validieren, da sie außerhalb des Logzeitraums verwendet werden könnten, z. B. eine Tabelle, die nur alle drei oder sechs Monate verwendet wird.
- Tabellen ohne Schreibvorgänge
In der Ansicht „Tabellen ohne Schreibvorgänge“ werden Tabellen angezeigt, in denen die BigQuery-Migrationsbewertung während der analysierten Logzeiträume keine Aktualisierungen identifiziert hat. Ein Mangel an Schreibvorgängen kann darauf hindeuten, dass die Ihre Speicherkosten in BigQuery (in Rechnung gestellt als Langzeitspeicherung) niedriger sein könnten.
- BigQuery BI Engine und materialisierte Ansichten
Die BigQuery BI Engine und die materialisierten Ansichten liefern weitere Optimierungsvorschläge, um die Leistung auf BigQuery zu verbessern.
Der Abschnitt Migrationspfad enthält die folgenden Ansichten:
- SQL-Übersetzung
- In der SQL-Übersetzungsansicht werden die Anzahl und Details der Abfragen aufgelistet, die von der BigQuery-Migrationsbewertung automatisch konvertiert wurden und keinen manuellen Eingriff erfordern. Die automatische SQL-Übersetzung erreicht in der Regel hohe Übersetzungsraten, wenn Metadaten bereitgestellt werden.
- Offline-Aufwand der SQL-Übersetzung
- Die Ansicht „Offline-Aufwand der SQL-Übersetzung“ erfasst die Bereiche, die manuelle Eingriffe erfordern, einschließlich bestimmter UDFs und Abfragen mit potenziellen Unklarheiten der Übersetzung.
- Unterstützung für Änderung von Tabellenanhängen
- Die Ansicht „Unterstützung für Änderung von Tabellenanhängen“ enthält Details zu gängigen Redshift-SQL-Konstrukten, die kein direktes BigQuery-Gegenstück haben.
- Unterstützung für den Kopierbefehl
- Die Ansicht „Unterstützung für den Kopierbefehl“ enthält Details zu häufig verwendeten Redshift-SQL-Konstrukten, die kein direktes BigQuery-Gegenstück haben.
- SQL-Warnungen
- In der Ansicht „SQL-Warnungen“ werden Bereiche erfasst, die erfolgreich übersetzt wurden, aber eine Überprüfung erfordern.
- Lexikalische Struktur und Syntaxverstöße
- In der Ansicht „Lexikalische Struktur und Syntaxverstöße“ werden Namen von Spalten, Tabellen, Funktionen und Verfahren angezeigt, die gegen die BigQuery-Syntax verstoßen.
- Reservierte BigQuery-Keywords
- Die Ansicht "Reservierte BigQuery-Keywords" zeigt die erkannte Nutzung von Keywords an, die in der GoogleSQL-Sprache eine besondere Bedeutung haben. Sie können nur als Kennungen verwendet werden, wenn sie in Backticks
`) eingeschlossen sind. - Schemakupplung
- Die Ansicht „Schema-Kopplung“ bietet eine allgemeine Ansicht der Datenbanken, Schemas und Tabellen, auf die in einer einzigen Abfrage zugegriffen wird. Diese Ansicht kann zeigen, auf welche Tabellen, Schemas und Datenbanken häufig verwiesen wird und was Sie für die Migrationsplanung verwenden können.
- Zeitplan für Tabellenaktualisierungen
- In der Ansicht „Zeitplan für die Tabellenaktualisierung“ sehen Sie, wann und wie häufig Tabellen aktualisiert werden, damit Sie planen können, wie und wann Sie sie migrieren.
- Tabellenskalierung
- In der Ansicht „Tabellenskalierung“ werden die Tabellen mit den meisten Spalten aufgelistet.
- Datenmigration zu BigQuery
- In der Ansicht „Datenmigration zu BigQuery“ wird der Migrationspfad mit der erwarteten Zeit für die Migration Ihrer Daten mit dem Data Transfer Service von BigQuery Migration Service dargestellt. Weitere Informationen finden Sie in der Anleitung zu BigQuery Data Transfer Service für Redshift.
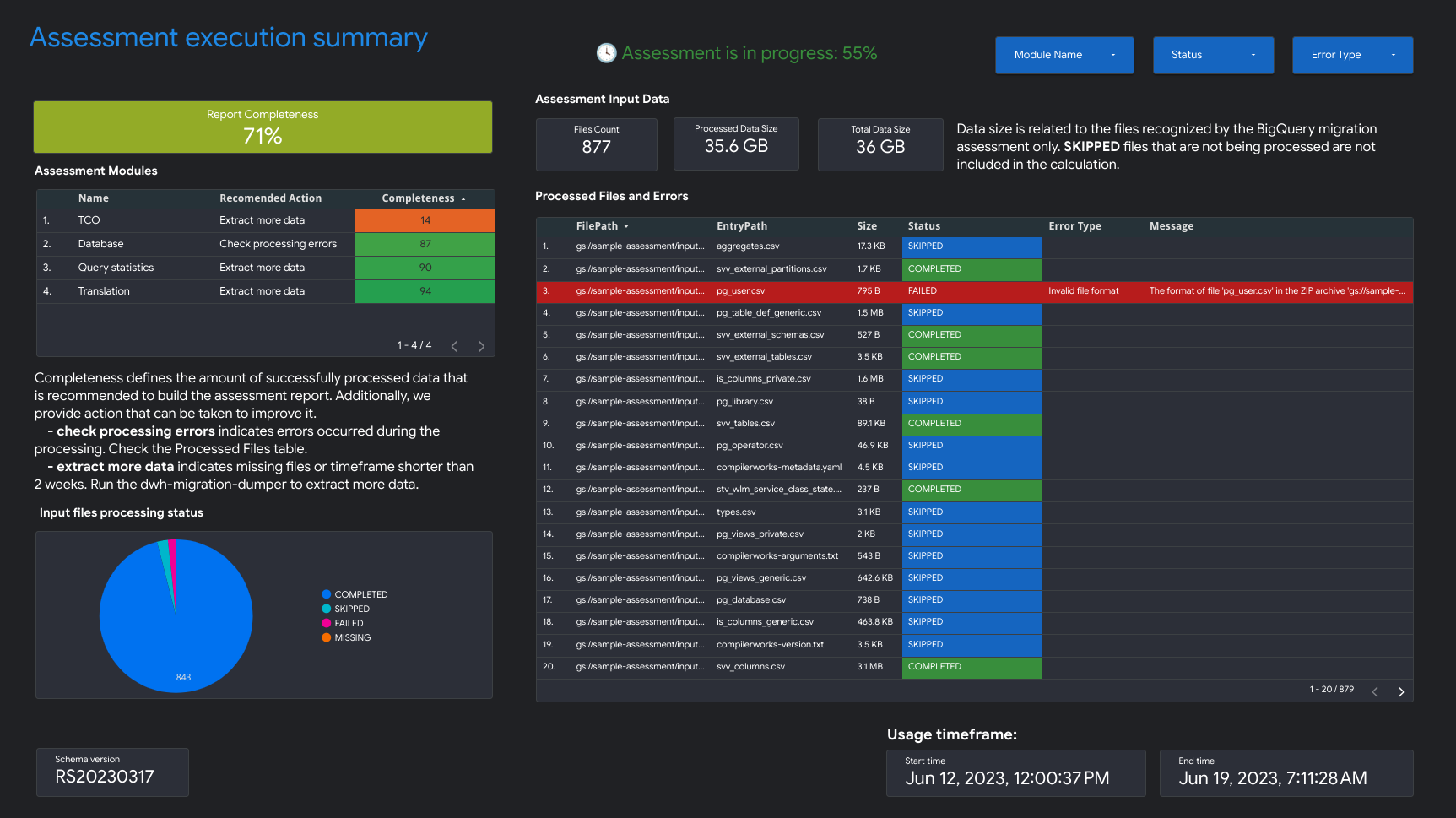
- Zusammenfassung der Bewertungsausführung
Die Zusammenfassung der Ausführung der Analyse enthält Informationen zur Vollständigkeit des Berichts, zum Fortschritt der laufenden Analyse sowie zum Status der verarbeiteten Dateien und zu Fehlern.
Die Vollständigkeit des Berichts gibt den Prozentsatz der erfolgreich verarbeiteten Daten an, die für aussagekräftige Statistiken im Bewertungsbericht empfohlen werden. Wenn die Daten für einen bestimmten Abschnitt des Berichts fehlen, werden diese Informationen in der Tabelle Bewertungsmodule unter dem Indikator Vollständigkeit des Berichts aufgeführt.
Der Messwert Fortschritt gibt den Prozentsatz der bisher verarbeiteten Daten sowie die geschätzte verbleibende Zeit für die Verarbeitung aller Daten an. Nach Abschluss der Verarbeitung wird der Fortschrittsmesswert nicht mehr angezeigt.
Redshift Serverless
- Migrations-Highlights
- Auf dieser Berichtsseite sehen Sie die Zusammenfassung der vorhandenen Amazon Redshift Serverless-Datenbanken, einschließlich der Größe und Anzahl der Tabellen. Außerdem wird eine Schätzung des jährlichen Vertragswerts (Annual Contract Value, ACV) bereitgestellt, d. h. der Kosten für Computing und Speicher in BigQuery. Die Ansicht „Highlights der Migration“ enthält eine Zusammenfassung der drei Abschnitte des Berichts.
Der Abschnitt Vorhandenes System enthält die folgenden Ansichten:
- Datenbanken und Schemas
- Hier wird die Gesamtspeichergröße in GB für jede Datenbank, jedes Schema oder jede Tabelle aufgeschlüsselt.
- Externe Datenbanken und Schemas
- Hier wird die Gesamtspeichergröße in GB für jede externe Datenbank, jedes externe Schema oder jede externe Tabelle aufgeschlüsselt.
- Systemauslastung
- Allgemeine Informationen zur bisherigen Systemauslastung. In dieser Ansicht wird die bisherige Nutzung von RPU (Amazon Redshift Processing Units) und der tägliche Speicherverbrauch angezeigt. Mit dieser Ansicht können Sie die Kapazitätsreserve des Systems besser nachvollziehen.
Der Bereich BigQuery Steady State enthält Informationen dazu, wie Ihre Daten nach der Migration in BigQuery aussehen, einschließlich der Anzahl der Abfragen, die automatisch mit dem BigQuery Migration Service übersetzt werden können. In diesem Abschnitt werden auch die Kosten für das Speichern Ihrer Daten in BigQuery auf der Grundlage der jährlichen Datenaufnahmerate angezeigt. Außerdem werden Optimierungsvorschläge für Tabellen, Bereitstellung und Speicherplatz angezeigt. Der Abschnitt „Stabiler Zustand“ enthält die folgenden Ansichten:
- Amazon Redshift Serverless im Vergleich zu BigQuery-Preisen
- Vergleich der Preismodelle von Amazon Redshift Serverless und BigQuery, damit Sie die Vorteile und potenziellen Kosteneinsparungen nach der Migration zu BigQuery besser nachvollziehen können.
- BigQuery-Computing-Kosten (Gesamtbetriebskosten)
- Ermöglicht Ihnen, die Kosten für die Rechenleistung in BigQuery zu schätzen. Der Rechner erfordert vier manuelle Eingaben: BigQuery-Version, Region, Mindestlaufzeit und Baseline. Standardmäßig bietet der Rechner optimale, kostengünstige Baseline-Zusicherungen, die Sie manuell überschreiben können.
- Gesamtbetriebskosten
- Ermöglicht Ihnen, den jährlichen Vertragswert (Annual Contract Value, ACV) zu schätzen – die Kosten für Computing und Speicher in BigQuery. Mit dem Rechner können Sie auch die Speicherkosten berechnen, die je nach aktivem Speicher und Langzeitspeicher variieren. Das hängt von den Tabellenänderungen im analysierten Zeitraum ab. Weitere Informationen finden Sie unter Speicherpreise.
Der Abschnitt Anhang enthält die folgende Ansicht:
- Zusammenfassung der Ausführung der Bewertung
- Enthält Details zur Ausführung der Analyse, einschließlich der Liste der verarbeiteten Dateien, Fehler und der Vollständigkeit des Berichts. Auf dieser Seite können Sie fehlende Daten im Bericht untersuchen und besser nachvollziehen, wie vollständig der Bericht ist.
Snowflake
Der Bericht besteht aus verschiedenen Abschnitten, die entweder separat oder zusammen verwendet werden können. Das folgende Diagramm organisiert diese Abschnitte in drei allgemeine Nutzerziele, um Ihnen bei der Bewertung Ihrer Migrationsanforderungen zu helfen:
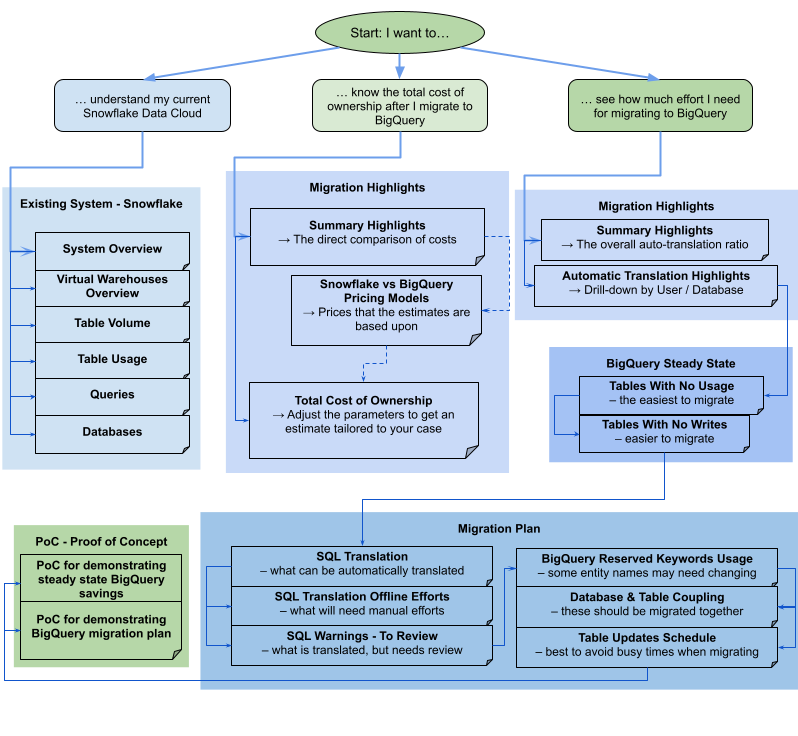
Ansichten unter „Migrations-Highlights“
Der Abschnitt Migrations-Highlights enthält die folgenden Ansichten:
- Vergleich von Snowflake- und BigQuery-Preismodellen
- Liste der Preise mit verschiedenen Stufen/Versionen. Enthält auch eine Abbildung dazu, wie Sie mit BigQuery-Autoscaling Kosten im Vergleich zu denen von Snowflake sparen können.
- Gesamtbetriebskosten
- Interaktive Tabelle, in der der Nutzer Folgendes definieren kann: BigQuery-Edition, Zusicherung, Referenz-Slot-Zusicherung, Prozentsatz des aktiven Speichers und Prozentsatz der geladenen oder geänderten Daten. Damit können die Kosten für benutzerdefinierte Fälle besser geschätzt werden.
- Highlights der automatischen Übersetzung
- Aggregiertes Übersetzungsverhältnis, gruppiert nach Nutzer oder Datenbank, aufsteigend oder absteigend sortiert. Enthält auch die häufigste Fehlermeldung für eine fehlgeschlagene automatische Übersetzung.
Ansichten unter „Vorhandenes System“
Der Abschnitt Vorhandenes System enthält die folgenden Ansichten:
- Systemübersicht
- Die Systemübersicht zeigt die allgemeinen Volume-Messwerte der Schlüsselkomponenten im vorhandenen System für einen bestimmten Zeitraum. Die auszuwertende Zeitachse hängt von den Logs ab, die von der BigQuery-Migrationsbewertung analysiert wurden. In dieser Ansicht erhalten Sie einen schnellen Einblick in die Nutzung des Quell-Data-Warehouse, das für die Migrationsplanung verwendet werden kann.
- Übersicht über virtuelle Warehouses
- Zeigt die Snowflake-Kosten nach Warehouse sowie die knotenbasierte Neuskalierung im jeweiligen Zeitraum an.
- Tabellen-Volumen
- Die Ansicht „Tabellen-Volume“ enthält Statistiken zu den größten Tabellen und Datenbanken, die von der BigQuery-Migrationsbewertung gefunden wurden. Da das Extrahieren großer Tabellen aus dem Quell-Data-Warehouse-System länger dauern kann, kann diese Ansicht bei der Migrationsplanung und -sequenzierung hilfreich sein.
- Tabellennutzung
- Die Ansicht „Tabellennutzung“ enthält Statistiken zu den Tabellen, die im Quell-Data-Warehouse-System stark genutzt werden. Anhand der Statistiken zu stark genutzten Tabellen können Sie verstehen, welche Tabellen möglicherweise viele Abhängigkeiten haben und eine zusätzliche Planung während des Migrationsprozesses erfordern.
- Abfragen
- Die Abfrageansicht enthält eine Aufschlüsselung der ausgeführten SQL-Anweisungen und Statistiken zu deren Nutzung. Sie können das Histogramm für Abfragetyp und -zeit verwenden, um niedrige Zeiträume der Systemauslastung und optimale Tageszeiten für die Datenübertragung zu ermitteln. Sie können diese Ansicht auch verwenden, um häufig ausgeführte Abfragen und die Nutzer zu bestimmen, die diese Ausführungen aufrufen.
- Datenbanken
- Die Ansicht der Datenbanken enthält Messwerte zur Größe, Tabellen, Ansichten sowie im Quell-Data-Warehouse definierte Verfahren. Diese Ansicht bietet Einblick in das Volumen der zu migrierenden Objekte.
Ansichten unter „BigQuery stabiler Zustand“
Der Abschnitt BigQuery stabiler Zustand enthält die folgenden Ansichten:
- Tabellen ohne Nutzung
- In der Ansicht „Tabellen ohne Nutzung“ werden Tabellen angezeigt, in denen die BigQuery-Migrationsbewertung während der Analyse des Logzeitraums keine Nutzung finden konnte. Dies kann darauf hinweisen, welche Tabellen während der Migration möglicherweise nicht an BigQuery übertragen werden müssen oder dass die Kosten für die Speicherung von Daten in BigQuery niedriger sein könnten. Sie müssen die Liste der nicht verwendeten Tabellen überprüfen, da sie außerhalb des analysierten Logging-Zeitraums verwendet werden könnten, z. B. eine Tabelle, die nur einmal pro Quartal oder Halbjahr verwendet wird.
- Tabellen ohne Schreibvorgänge
- In der Ansicht „Tabellen ohne Schreibvorgänge“ werden Tabellen angezeigt, in denen die BigQuery-Migrationsbewertung während des Analysezeitraums keine Aktualisierungen finden konnte. Dies kann darauf hinweisen, dass die Kosten für die Speicherung von Daten in BigQuery niedriger sein könnten.
Ansichten unter „Migrationsplan“
Der Abschnitt Migrationsplan des Berichts enthält die folgenden Ansichten:
- SQL-Übersetzung
- In der SQL-Übersetzungsansicht werden die Anzahl und Details der Abfragen aufgelistet, die von der BigQuery-Migrationsbewertung automatisch konvertiert wurden und keinen manuellen Eingriff erfordern. Die automatische SQL-Übersetzung erreicht in der Regel hohe Übersetzungsraten, wenn Metadaten bereitgestellt werden. Diese Ansicht ist interaktiv und ermöglicht die Analyse gängiger Abfragen und wie diese übersetzt werden.
- Offline-Aufwand der SQL-Übersetzung
- Die Ansicht „Offline-Aufwand“ erfasst die Bereiche, die manuell erforderlich sind, einschließlich bestimmter UDFs und potenzieller lexikalischer Struktur- und Syntaxverstöße für Tabellen oder Spalten.
- SQL-Warnungen – Zur Überprüfung
- In der Ansicht „Warnungen zur Überprüfung“ werden die Bereiche erfasst, die hauptsächlich übersetzt werden, aber einige manuelle Prüfungen erfordern.
- Reservierte BigQuery-Keywords
- Die Ansicht "Reservierte BigQuery-Keywords" zeigt die erkannte Nutzung von Keywords an, die in der GoogleSQL-Sprache eine besondere Bedeutung haben. Sie können nur als Kennungen verwendet werden, wenn sie in Backticks
`) eingeschlossen sind. - Datenbank- und Tabellenkopplung
- Die Ansicht "Datenbankkopplung" bietet eine allgemeine Ansicht der Datenbanken und Tabellen, auf die in einer einzigen Abfrage zugegriffen wird. Diese Ansicht kann zeigen, auf welche Tabellen und Datenbanken häufig verwiesen wird und was für die Migrationsplanung verwendet werden kann.
- Zeitplan für Tabellenaktualisierungen
- In der Ansicht „Zeitplan für die Tabellenaktualisierungen“ sehen Sie, wann und wie häufig Tabellen aktualisiert werden, damit Sie planen können, wie und wann Sie sie migrieren.
Ansichten unter „PoC“
Der Abschnitt PoC (Proof of Concept) enthält die folgenden Ansichten:
- PoC für die Demonstration von Einsparungen für BigQuery im stabilen Zustand
- Dies umfasst die häufigsten Abfragen, die Abfragen, die die meisten Daten lesen, die langsamsten Abfragen und die Tabellen, die von den eben genannten Abfragen betroffen sind.
- PoC für die Demonstration des BigQuery-Migrationsplans
- Hier sehen Sie, wie BigQuery die komplexesten Abfragen und die betroffenen Tabellen übersetzt.
Oracle
Wenn Sie Feedback oder Unterstützung für dieses Feature benötigen, senden Sie eine E-Mail an bq-edw-migration-support@google.com.
Migrations-Highlights
Der Abschnitt Migrations-Highlights enthält die folgenden Ansichten:
- Vorhandenes System: ein Snapshot des vorhandenen Oracle-Systems und der vorhandenen Nutzung, einschließlich der Anzahl der Datenbanken, Schemas, Tabellen und der Gesamtgröße in GB. Außerdem enthält es die Zusammenfassung der Arbeitslastklassifizierung für jede Datenbank, damit Sie entscheiden können, ob BigQuery das richtige Migrationsziel ist.
- Kompatibilität: Enthält Informationen zur Migration selbst. Für jede analysierte Datenbank wird die voraussichtliche Migrationszeit und die Anzahl der Datenbankobjekte angezeigt, die automatisch mit von Google bereitgestellten Tools migriert werden können.
- BigQuery-Steady-State: Enthält Informationen dazu, wie Ihre Daten nach der Migration in BigQuery aussehen, einschließlich der Kosten für das Speichern Ihrer Daten in BigQuery basierend auf Ihrer jährlichen Datenaufnahmerate und der Schätzung der Rechenkosten. Außerdem erhalten Sie Informationen zu Tabellen, die nicht ausreichend genutzt werden.
Vorhandenes System
Der Abschnitt Vorhandenes System enthält die folgenden Ansichten:
- „Workloads Characteristic“ (Arbeitslastmerkmal): Beschreibt den Arbeitslasttyp für jede Datenbank basierend auf den analysierten Leistungsmesswerten. Jede Datenbank wird als OLAP, gemischt oder OLTP klassifiziert. Anhand dieser Informationen können Sie entscheiden, welche Datenbanken zu BigQuery migriert werden können.
- Datenbanken und Schemas: Hier wird die Gesamtspeichergröße in GB für jede Datenbank, jedes Schema oder jede Tabelle aufgeschlüsselt. Außerdem können Sie in dieser Ansicht materialisierte Ansichten und externe Tabellen identifizieren.
- „Database Features and Links“ (Datenbankfunktionen und Links): Hier wird die Liste der in Ihrer Datenbank verwendeten Oracle-Funktionen zusammen mit den entsprechenden BigQuery-Funktionen oder -Diensten angezeigt, die nach der Migration verwendet werden können. Außerdem können Sie die Datenbanklinks aufrufen, um die Verbindungen zwischen den Datenbanken besser zu verstehen.
- „Datenbankverbindungen“: Hier erhalten Sie Informationen zu den Datenbankverbindungen, die vom Nutzer oder der Anwendung gestartet wurden. Wenn Sie diese Daten analysieren, können Sie externe Anwendungen ermitteln, die während der Migration möglicherweise zusätzlichen Aufwand erfordern.
- Abfragetypen: Hier finden Sie eine Aufschlüsselung der ausgeführten SQL-Anweisungen und Statistiken zu deren Nutzung. Sie können das stündliche Histogramm für die Ausführung von Abfragen oder die CPU-Zeit von Abfragen verwenden, um niedrige Zeiträume der Systemauslastung und optimale Tageszeiten für die Datenübertragung zu ermitteln.
- PL/SQL-Quellcode: Bietet Einblick in die PL/SQL-Objekte wie Funktionen oder Prozeduren und deren Größe für jede Datenbank und jedes Schema. Außerdem kann das Histogramm für stündliche Ausführungen verwendet werden, um Spitzenzeiten mit den meisten PL/SQL-Ausführungen zu ermitteln.
- Systemauslastung: Hier finden Sie allgemeine Informationen zur bisherigen Systemauslastung. In dieser Ansicht wird die stündliche CPU-Nutzung und der tägliche Speicherverbrauch angezeigt. Mit dieser Ansicht können Sie die Kapazitätsreserve des Systems besser nachvollziehen.
BigQuery-Steady State
Der Abschnitt BigQuery stabiler Zustand enthält die folgenden Ansichten:
- Exadata- und BigQuery-Preise: Hier finden Sie einen allgemeinen Vergleich der Preismodelle von Exadata und BigQuery, damit Sie die Vorteile und potenziellen Kosteneinsparungen nach der Migration zu BigQuery besser nachvollziehen können.
- BigQuery Database Read/Writes: Bietet Informationen zu den physischen Festplattenvorgängen der Datenbank. Wenn Sie diese Daten analysieren, können Sie den besten Zeitpunkt für die Datenmigration von Oracle zu BigQuery ermitteln.
- BigQuery-Compute-Kosten: Damit können Sie die Kosten für Compute in BigQuery schätzen. Der Rechner erfordert vier manuelle Eingaben: BigQuery-Version, Region, Laufzeit des Vertrags und Baseline. Standardmäßig wird im Rechner die optimale, kostengünstige Baseline-Zusicherung angegeben, die Sie manuell überschreiben können. Der Wert Jährliche Autoscaling-Slotstunden gibt die Anzahl der Slotstunden an, die außerhalb der Zusicherung verwendet wurden. Dieser Wert wird anhand der Systemauslastung berechnet. Eine visuelle Erklärung der Beziehungen zwischen Baseline, Autoscaling und Nutzung finden Sie am Ende der Seite. Jede Schätzung enthält die wahrscheinliche Anzahl und einen Schätzbereich.
- Gesamtbetriebskosten (Total Cost of Ownership, TCO): Mit dieser Option können Sie den jährlichen Vertragswert (Annual Contract Value, ACV) schätzen – die Kosten für Compute und Speicher in BigQuery. Mit dem Rechner können Sie auch die Speicherkosten berechnen. Mit dem Rechner können Sie auch die Speicherkosten berechnen, die je nach Tabellenänderungen im analysierten Zeitraum für aktiven Speicherplatz und langfristigen Speicherplatz variieren. Weitere Informationen zu den Preisen für Speicher finden Sie unter Speicherpreise.
- Nicht ausreichend genutzte Tabellen: Hier finden Sie Informationen zu nicht verwendeten und schreibgeschützten Tabellen basierend auf den Nutzungsmesswerten aus dem analysierten Zeitraum. Eine mangelnde Nutzung kann darauf hinweisen, dass Sie die Tabelle während einer Migration nicht zu BigQuery übertragen müssen oder dass die Kosten für die Speicherung von Daten in BigQuery niedriger sein können (in Rechnung gestellt als Langzeitspeicherung). Wir empfehlen, die Liste der nicht verwendeten Tabellen zu prüfen, da sie möglicherweise außerhalb des analysierten Zeitraums verwendet werden.
Hinweise zur Migration
Der Abschnitt Hinweise zur Migration enthält die folgenden Ansichten:
- „Kompatibilität von Datenbankobjekten“: Bietet einen Überblick über die Kompatibilität von Datenbankobjekten mit BigQuery, einschließlich der Anzahl der Objekte, die automatisch mit von Google bereitgestellten Tools migriert werden können oder manuelle Maßnahmen erfordern. Diese Informationen werden für jede Datenbank, jedes Schema und jeden Datenbankobjekttyp angezeigt.
- „Aufwand für die Migration von Datenbankobjekten“: Hier wird der geschätzte Aufwand für die Migration in Stunden für jede Datenbank, jedes Schema oder jeden Datenbankobjekttyp angezeigt. Außerdem wird der Prozentsatz kleiner, mittelgroßer und großer Objekte basierend auf dem Migrationsaufwand angezeigt.
- „Aufwand für die Migration des Datenbankschemas“: Hier finden Sie die Liste aller erkannten Datenbankobjekttypen, ihre Anzahl, die Kompatibilität mit BigQuery und den geschätzten Migrationsaufwand in Stunden.
- „Database Schema Migration Effort Detailed“ (Detaillierter Aufwand für die Migration von Datenbankschemas): Bietet detailliertere Informationen zum Aufwand für die Migration von Datenbankschemas, einschließlich der Informationen für jedes einzelne Objekt.
Ansichten unter „PoC“
Der Abschnitt Ansichten für den Proof of Concept enthält die folgenden Ansichten:
- Proof-of-Concept-Migration: Hier wird die vorgeschlagene Liste von Datenbanken mit dem geringsten Migrationsaufwand angezeigt, die sich gut für die erste Migration eignen. Außerdem werden die wichtigsten Abfragen aufgeführt, mit denen sich die Zeit- und Kostenersparnisse sowie der Wert von BigQuery anhand eines Proof of Concept demonstrieren lassen.
Anhang
Der Abschnitt Anhang enthält die folgenden Ansichten:
- Zusammenfassung der Analyseausführung: Enthält die Details zur Analyseausführung, einschließlich der Liste der verarbeiteten Dateien, Fehler und der Vollständigkeit des Berichts. Auf dieser Seite können Sie fehlende Daten im Bericht untersuchen und die Vollständigkeit des Berichts besser nachvollziehen.
Apache Hive
Dem Bericht mit einer dreiteiligen Beschreibung wird eine Übersichtsseite mit den folgenden Abschnitten vorangestellt:
Vorhandenes System – Apache Hive. Dieser Abschnitt besteht aus einem Snapshot des vorhandenen Apache Hive-Systems und der vorhandenen Nutzung, einschließlich der Anzahl der Datenbanken, Tabellen, ihrer Gesamtgröße in GB und der Anzahl der verarbeiteten Abfragelogs. In diesem Abschnitt werden auch die Datenbanken nach Größe aufgelistet und es wird auf eine potenzielle suboptimale Ressourcennutzung (Tabellen ohne Schreibvorgänge oder mit wenigen Lesevorgängen) und -bereitstellung verwiesen. Dieser Abschnitt enthält folgende Details:
- Computing und Abfragen
- CPU-Auslastung:
- Abfragen nach Stunde und Tag mit CPU-Auslastung
- Abfragen nach Typ (Lesen/Schreiben)
- Warteschlangen und Anwendungen
- Overlay der stündlichen CPU-Auslastung mit durchschnittlicher stündlicher Abfrageleistung und durchschnittlicher stündlicher Anwendungsleistung
- Abfragehistogramm nach Typ und Abfragedauer
- Warteschlangen- und Warteseite
- Detailansicht der Warteschlangen (Warteschlange, Nutzer, eindeutige Abfragen, Aufschlüsselung nach Berichterstellung im Vergleich zu ETL, nach Messwerten)
- CPU-Auslastung:
- Speicherübersicht
- Datenbanken nach Volumen, Ansichten und Zugriffsraten
- Tabellen mit Zugriffsraten nach Nutzern, Abfragen, Schreibvorgängen und dem Erstellen temporärer Tabellen
- Warteschlangen und Anwendungen: Zugriffsraten und Client-IP-Adressen
- Computing und Abfragen
BigQuery stabiler Zustand. Dieser Abschnitt zeigt, wie das System nach der Migration in BigQuery aussieht. Er enthält Vorschläge zur Optimierung von Arbeitslasten in BigQuery (und Vermeidung von unnötiger Inanspruchnahme). Dieser Abschnitt enthält folgende Details:
- Tabellen, die als Kandidaten für materialisierte Ansichten identifiziert wurden.
- Clustering und Partitionierung von Kandidaten nach Metadaten und Nutzung
- Abfragen mit niedriger Latenz, die als Kandidaten für BigQuery BI Engine identifiziert wurden.
- Tabellen ohne Lese- oder Schreibnutzung.
- Partitionierte Tabellen mit Datenverzerrung
Migrationsplan. Dieser Abschnitt enthält Informationen zur Migration selbst. Zum Beispiel zur Überführung des vorhandenen Systems in einen stabilen BigQuery-Zustand. Dieser Abschnitt enthält die angegebenen Speicherziele für jede Tabelle, die für die Migration als wichtig eingestuften Tabellen und die Anzahl der automatisch übersetzten Abfragen. Dieser Abschnitt enthält folgende Details:
- Detaillierte Ansicht mit automatisch übersetzten Abfragen
- Gesamtzahl der Abfragen mit Filterung nach Nutzer, Anwendung, betroffenen Tabellen, abgefragten Tabellen und Abfragetyp.
- Abfrage-Buckets, die nach ähnlichen Mustern gruppiert sind, sodass Nutzer die Übersetzungsphilosophie nach Abfragetyp sehen können.
- Abfragen, die menschliches Eingreifen erfordern
- Abfragen mit Verstößen gegen die lexikalische BigQuery-Struktur
- Benutzerdefinierte Funktionen und Verfahren
- Reservierte BigQuery-Keywords
- Abfragen, die eine Überprüfung erfordern
- Tabellen werden nach Schreib- und Lesevorgängen gruppiert, um sie zum Verschieben zu gruppieren.
- Identifiziertes Speicherziel für externe und verwaltete Tabellen
- Detaillierte Ansicht mit automatisch übersetzten Abfragen
Der Abschnitt Vorhandenes System – Hive enthält die folgenden Ansichten:
- Systemübersicht
- Diese Ansicht bietet eine allgemeine Übersicht über die Volume-Messwerte der Schlüsselkomponenten im vorhandenen System für einen bestimmten Zeitraum. Die auszuwertende Zeitachse hängt von den Logs ab, die von der BigQuery-Migrationsbewertung analysiert wurden. In dieser Ansicht erhalten Sie einen schnellen Einblick in die Nutzung des Quell-Data-Warehouse, das für die Migrationsplanung verwendet werden kann.
- Tabellen-Volumen
- Diese Ansicht enthält Statistiken zu den größten Tabellen und Datenbanken, die bei der BigQuery-Migrationsbewertung gefunden wurden. Da das Extrahieren großer Tabellen aus dem Quell-Data-Warehouse-System länger dauern kann, kann diese Ansicht bei der Migrationsplanung und -sequenzierung hilfreich sein.
- Tabellennutzung
- Diese Ansicht enthält Statistiken zu den Tabellen, die im Quell-Data-Warehouse-System stark genutzt werden. Anhand der Statistiken zu stark genutzten Tabellen können Sie verstehen, welche Tabellen möglicherweise viele Abhängigkeiten haben und eine zusätzliche Planung während des Migrationsprozesses erfordern.
- Warteschlangenauslastung
- Diese Ansicht enthält Statistiken zur Nutzung der YARN-Warteschlangen bei der Verarbeitung von Logs. Diese Ansichten ermöglichen Nutzern, die Nutzung bestimmter Warteschlangen und Anwendungen im Zeitverlauf sowie die Auswirkungen auf die Ressourcennutzung zu verstehen. Anhand dieser Ansichten können Sie Arbeitslasten für die Migration identifizieren und priorisieren. Während einer Migration ist es wichtig, die Aufnahme und Nutzung von Daten zu visualisieren, um die Abhängigkeiten des Data Warehouse besser zu verstehen und die Auswirkungen der gemeinsamen Migration verschiedener abhängiger Anwendungen zu analysieren. Die IP-Adresstabelle kann nützlich sein, um die genaue Anwendung mit dem Data Warehouse über JDBC-Verbindungen zu bestimmen.
- Warteschlangenmesswerte
- Diese Ansicht enthält eine Aufschlüsselung der verschiedenen Messwerte zu YARN-Warteschlangen, die während der Verarbeitung von Logs gefunden wurden. Anhand dieser Ansicht lassen sich Nutzungsmuster in bestimmten Warteschlangen und die Auswirkungen auf die Migration nachvollziehen. Sie können diese Ansicht auch verwenden, um Verbindungen zwischen Tabellen, auf die in Abfragen zugegriffen wird, sowie die Warteschlangen, in denen die Abfrage ausgeführt wurde, zu identifizieren.
- In Warteschlange stellen und warten
- Diese Ansicht bietet einen Einblick in die Warteschlangen-Verweildauer von Abfragen im Quell-Data-Warehouse. Die Warteschlangen-Verweildauer kann auf eine Leistungsverschlechterung aufgrund von unzureichender Ressourcenbereitstellung hinweisen und zusätzliche Ressourcen beinhalten höhere Hardware- und Wartungskosten.
- Abfragen
- Diese Ansicht enthält eine Aufschlüsselung der ausgeführten SQL-Anweisungen und Statistiken zu deren Nutzung. Sie können das Histogramm für Abfragetyp und -zeit verwenden, um niedrige Zeiträume der Systemauslastung und optimale Tageszeiten für die Datenübertragung zu ermitteln. Sie können diese Ansicht auch verwenden, um die am häufigsten verwendeten Hive-Ausführungs-Engines und häufig ausgeführte Abfragen zusammen mit den Nutzerdetails zu identifizieren.
- Datenbanken
- Diese Ansicht enthält Messwerte zur Größe, zu Tabellen und Ansichten sowie zu im Quell-Data-Warehouse definierten Verfahren. Diese Ansicht bietet Einblick in das Volumen der zu migrierenden Objekte.
- Datenbank- und Tabellenkopplung
- Diese Ansicht bietet eine allgemeine Ansicht der Datenbanken und Tabellen, auf die in einer einzigen Abfrage zugegriffen wird. Diese Ansicht kann zeigen, auf welche Tabellen und Datenbanken häufig verwiesen wird und was Sie für die Migrationsplanung verwenden können.
Der Abschnitt BigQuery stabiler Zustand enthält die folgenden Ansichten:
- Tabellen ohne Nutzung
- In der Ansicht „Tabellen ohne Nutzung“ werden Tabellen angezeigt, in denen die BigQuery-Migrationsbewertung während des analysierten Logzeitraums keine Nutzung finden konnte. Eine mangelnde Nutzung kann darauf hinweisen, dass Sie diese Tabelle während der Migration nicht zu BigQuery übertragen müssen oder dass die Kosten für die Speicherung von Daten in BigQuery niedriger sein können. Sie müssen die Liste der nicht verwendeten Tabellen validieren, da sie außerhalb des Logzeitraums verwendet werden könnten, z. B. eine Tabelle, die nur alle drei oder sechs Monate verwendet wird.
- Tabellen ohne Schreibvorgänge
- In der Ansicht „Tabellen ohne Schreibvorgänge“ werden Tabellen angezeigt, in denen die BigQuery-Migrationsbewertung während des Analysezeitraums keine Aktualisierungen finden konnte. Fehlende Schreibvorgänge können darauf hinweisen, dass Sie die Speicherkosten in BigQuery senken können.
- Empfehlungen zum Clustering und zur Partitionierung
Diese Ansicht zeigt Tabellen, die von Partitionierung, Clustering oder beidem profitieren würden.
Die Metadatenvorschläge werden dadurch erreicht, dass das Schema des Quelldatenspeichers (Partitionierung und Primärschlüssel in der Quelltabelle) analysiert und das nächstgelegene BigQuery-Äquivalent ermittelt wird, um ähnliche Optimierungsmerkmale zu erreichen.
Die Arbeitslastvorschläge werden durch die Analyse der Quellabfragelogs generiert. Die Empfehlung wird durch die Analyse der Arbeitslasten ermittelt, insbesondere durch die Klauseln
WHEREoderJOINin den analysierten Abfragelogs.- In Cluster konvertierte Partitionen
In dieser Ansicht werden Tabellen mit mehr als 10.000 Partitionen basierend auf ihrer Definition zur Partitionierungseinschränkung angezeigt. Diese Tabellen sind in der Regel gute Kandidaten für BigQuery-Clustering, das eine detaillierte Tabellenpartitionierung ermöglicht.
- Verzerrte Partitionen
In der Ansicht „Verzerrte Partitionen“ werden Tabellen angezeigt, die auf der Metadatenanalyse basieren und in einer oder mehreren Partitionen eine Datenverzerrung aufweisen. Diese Tabellen sind gute Kandidaten für Schemaänderungen, da Abfragen auf verzerrten Partitionen möglicherweise nicht gut funktionieren.
- BI Engine und materialisierte Ansichten
In der Ansicht „Abfragen mit niedriger Latenz und materialisierte Ansichten“ werden eine Verteilung der Abfragelaufzeiten basierend auf den analysierten Logdaten sowie weitere Optimierungsvorschläge zur Verbesserung der Leistung in BigQuery angezeigt. Wenn das Diagramm zur Verteilung der Abfragedauer eine große Anzahl von Abfragen mit Laufzeiten von weniger als einer Sekunde anzeigt, sollten Sie eventuell BI Engine aktivieren, um BI- und andere Arbeitslasten mit niedriger Latenz zu beschleunigen.
Der Abschnitt Migrationsplan des Berichts enthält die folgenden Ansichten:
- SQL-Übersetzung
- In der SQL-Übersetzungsansicht werden die Anzahl und Details der Abfragen aufgelistet, die von der BigQuery-Migrationsbewertung automatisch konvertiert wurden und keinen manuellen Eingriff erfordern. Die automatische SQL-Übersetzung erreicht in der Regel hohe Übersetzungsraten, wenn Metadaten bereitgestellt werden. Diese Ansicht ist interaktiv und ermöglicht die Analyse gängiger Abfragen und wie diese übersetzt werden.
- Offline-Aufwand der SQL-Übersetzung
- Die Ansicht „Offline-Aufwand“ erfasst die Bereiche, die manuell erforderlich sind, einschließlich bestimmter UDFs und potenzieller lexikalischer Struktur- und Syntaxverstöße für Tabellen oder Spalten.
- SQL-Warnungen
- In der Ansicht „SQL-Warnungen“ werden Bereiche erfasst, die erfolgreich übersetzt wurden, aber eine Überprüfung erfordern.
- Reservierte BigQuery-Keywords
- Die Ansicht „Reservierte BigQuery-Keywords“ zeigt die erkannte Nutzung von Keywords an, die in der GoogleSQL-Sprache eine besondere Bedeutung haben.
Diese Keywords können nur dann als Kennungen verwendet werden, wenn sie in Backticks (
`) eingeschlossen sind. - Zeitplan für Tabellenaktualisierungen
- In der Ansicht „Zeitplan für die Tabellenaktualisierung“ sehen Sie, wann und wie häufig Tabellen aktualisiert werden, damit Sie planen können, wie und wann Sie sie migrieren.
- Externe BigLake-Tabellen
- Die Ansicht „Externe BigLake-Tabellen“ beschreibt Tabellen, die als Ziele für die Migration zu BigLake anstelle von BigQuery identifiziert wurden.
Der Abschnitt Anhang des Berichts enthält die folgenden Ansichten.
- Detaillierte Analyse des Offline-Aufwands der SQL-Übersetzung
- Die Ansicht „Detaillierte Analyse des Offline-Aufwands“ bietet einen zusätzlichen Einblick in die SQL-Bereiche, die einen manuellen Eingriff erfordern.
- Detaillierte SQL-Warnungsanalyse
- Die Ansicht „Detaillierte Warnungsanalyse“ bietet einen zusätzlichen Einblick in die SQL-Bereiche, die erfolgreich übersetzt wurden, aber eine Überprüfung erfordern.
Bericht freigeben
Der Looker Studio-Bericht ist ein Frontend-Dashboard für die Migrationsbewertung. Es basiert auf den zugrunde liegenden Dataset-Zugriffsberechtigungen. Zum Freigeben des Berichts muss der Empfänger Zugriff auf den Looker Studio-Bericht selbst und auf das BigQuery-Dataset haben, das die Bewertungsergebnisse enthält.
Wenn Sie den Bericht über die Google Cloud Console öffnen, sehen Sie den Bericht im Vorschaumodus. Führen Sie die folgenden Schritte aus, um den Bericht zu erstellen und für andere Nutzer freizugeben:
- Klicken Sie auf Bearbeiten und freigeben. Looker Studio fordert Sie auf, neu erstellte Looker Studio-Connectors an den neuen Bericht anzuhängen.
- Klicken Sie auf Zum Bericht hinzufügen. Der Bericht erhält eine einzelne Berichts-ID, mit der Sie auf den Bericht zugreifen können.
- Um den Looker Studio-Bericht für andere Nutzer freizugeben, führen Sie die Schritte unter Berichte für Betrachter und Bearbeiter freigeben aus.
- Gewähren Sie den Nutzern die Berechtigung zum Aufrufen des BigQuery-Datasets, mit dem die Bewertungsaufgabe ausgeführt wurde. Weitere Informationen finden Sie unter Zugriff auf ein Dataset gewähren.
Ausgabetabellen der Migrationsbewertung abfragen
Looker Studio ist die einfachste Möglichkeit zum Aufrufen der Bewertungsergebnisse. Sie können aber auch die zugrunde liegenden Daten im BigQuery-Dataset aufrufen und abfragen.
Beispielabfrage
Im folgenden Beispiel wird die Gesamtzahl der eindeutigen Abfragen, die Anzahl der Abfragen mit fehlgeschlagener Übersetzung und der Prozentsatz der eindeutigen Abfragen zurückgegeben, deren Übersetzung fehlgeschlagen ist.
SELECT QueryCount.v AS QueryCount, ErrorCount.v as ErrorCount, (ErrorCount.v * 100) / QueryCount.v AS FailurePercentage FROM ( SELECT COUNT(*) AS v FROM `your_project.your_dataset.TranslationErrors` WHERE Severity = "ERROR" ) AS ErrorCount, ( SELECT COUNT(DISTINCT(QueryHash)) AS v FROM `your_project.your_dataset.Queries` ) AS QueryCount;
Dataset für Nutzer in anderen Projekten freigeben
Wenn Sie das Dataset nach der Überprüfung für einen Nutzer freigeben möchten, der nicht zu Ihrem Projekt gehört, können Sie dazu den Publisher-Workflow von BigQuery Sharing (früher Analytics Hub) verwenden.
Öffnen Sie in der Google Cloud Console die Seite BigQuery.
Klicken Sie auf das Dataset, um die Details aufzurufen.
Klicken Sie auf Freigabe > Als Eintrag veröffentlichen.
Erstellen Sie im daraufhin geöffneten Dialogfeld ein Unternehmensprofil, wie Sie dazu aufgefordert werden.
Wenn Sie bereits einen Datenpool haben, überspringen Sie Schritt 5.
Datenaustausch erstellen und Berechtigungen festlegen Damit ein Nutzer Ihre Einträge in dieser Pool ansehen kann, fügen Sie ihn der Liste Abonnenten hinzu.
Geben Sie die Eintragsdetails ein.
Anzeigename ist der Name dieses Eintrags und ist erforderlich. andere Felder sind optional.
Klicken Sie auf Veröffentlichen.
Ein privater Eintrag wird erstellt.
Wählen Sie für Ihren Eintrag unter Aktionen die Option Weitere Aktionen aus.
Klicken Sie auf Link zur Freigabe kopieren.
Sie können den Link für Nutzer freigeben, die Abozugriff auf Ihren Pool oder Ihren Eintrag haben.
Bewertungstabellenschemas
Wenn Sie die Tabellen und zugehörigen Schemas sehen möchten, die die BigQuery-Migrationsbewertung in BigQuery schreibt, wählen Sie Ihr Data Warehouse aus:
Teradata
AllRIChildren
Diese Tabelle enthält Informationen zur referenziellen Integrität der untergeordneten Tabellen.
| Spalte | Typ | Beschreibung |
|---|---|---|
IndexId |
INTEGER |
Die Referenzindexnummer. |
IndexName |
STRING |
Der Name des Index. |
ChildDB |
STRING |
Der Name der referenzierenden Datenbank, in Kleinbuchstaben umgewandelt. |
ChildDBOriginal |
STRING |
Der Name der referenzierenden Datenbank mit beibehaltener Groß-/Kleinschreibung. |
ChildTable |
STRING |
Der Name der referenzierenden Tabelle, in Kleinbuchstaben umgewandelt. |
ChildTableOriginal |
STRING |
Der Name der referenzierenden Tabelle mit beibehaltener Groß-/Kleinschreibung. |
ChildKeyColumn |
STRING |
Der Name einer Spalte im referenzierenden Schlüssel, in Kleinbuchstaben umgewandelt. |
ChildKeyColumnOriginal |
STRING |
Der Name einer Spalte im referenzierenden Schlüssel mit beibehaltener Groß-/Kleinschreibung. |
ParentDB |
STRING |
Der Name der referenzierten Datenbank, in Kleinbuchstaben umgewandelt. |
ParentDBOriginal |
STRING |
Der Name der referenzierten Datenbank mit beibehaltener Groß-/Kleinschreibung. |
ParentTable |
STRING |
Der Name der referenzierten Tabelle, in Kleinbuchstaben umgewandelt. |
ParentTableOriginal |
STRING |
Der Name der referenzierten Tabelle mit beibehaltener Groß-/Kleinschreibung. |
ParentKeyColumn |
STRING |
Der Name der Spalte in einem referenzierten Schlüssel, in Kleinbuchstaben umgewandelt. |
ParentKeyColumnOriginal |
STRING |
Der Name der Spalte in einem referenzierten Schlüssel mit beibehaltener Groß-/Kleinschreibung. |
AllRIParents
Diese Tabelle enthält die Informationen zur referenziellen Integrität der übergeordneten Tabellen.
| Spalte | Typ | Beschreibung |
|---|---|---|
IndexId |
INTEGER |
Die Referenzindexnummer. |
IndexName |
STRING |
Der Name des Index. |
ChildDB |
STRING |
Der Name der referenzierenden Datenbank, in Kleinbuchstaben umgewandelt. |
ChildDBOriginal |
STRING |
Der Name der referenzierenden Datenbank mit beibehaltener Groß-/Kleinschreibung. |
ChildTable |
STRING |
Der Name der referenzierenden Tabelle, in Kleinbuchstaben umgewandelt. |
ChildTableOriginal |
STRING |
Der Name der referenzierenden Tabelle mit beibehaltener Groß-/Kleinschreibung. |
ChildKeyColumn |
STRING |
Der Name einer Spalte im referenzierenden Schlüssel, in Kleinbuchstaben umgewandelt. |
ChildKeyColumnOriginal |
STRING |
Der Name einer Spalte im referenzierenden Schlüssel mit beibehaltener Groß-/Kleinschreibung. |
ParentDB |
STRING |
Der Name der referenzierten Datenbank, in Kleinbuchstaben umgewandelt. |
ParentDBOriginal |
STRING |
Der Name der referenzierten Datenbank mit beibehaltener Groß-/Kleinschreibung. |
ParentTable |
STRING |
Der Name der referenzierten Tabelle, in Kleinbuchstaben umgewandelt. |
ParentTableOriginal |
STRING |
Der Name der referenzierten Tabelle mit beibehaltener Groß-/Kleinschreibung. |
ParentKeyColumn |
STRING |
Der Name der Spalte in einem referenzierten Schlüssel, in Kleinbuchstaben umgewandelt. |
ParentKeyColumnOriginal |
STRING |
Der Name der Spalte in einem referenzierten Schlüssel mit beibehaltener Groß-/Kleinschreibung. |
Columns
Diese Tabelle enthält Informationen zu den Spalten.
| Spalte | Typ | Beschreibung |
|---|---|---|
DatabaseName |
STRING |
Der Name der Datenbank, in Kleinbuchstaben umgewandelt. |
DatabaseNameOriginal |
STRING |
Der Name der Datenbank mit beibehaltener Groß-/Kleinschreibung. |
TableName |
STRING |
Der Name der Tabelle, in Kleinbuchstaben umgewandelt. |
TableNameOriginal |
STRING |
Der Name der Tabelle mit beibehaltener Groß-/Kleinschreibung. |
ColumnName |
STRING |
Der Name der Spalte, in Kleinbuchstaben umgewandelt. |
ColumnNameOriginal |
STRING |
Der Name der Spalte mit beibehaltener Groß-/Kleinschreibung. |
ColumnType |
STRING |
Der BigQuery-Typ der Spalte, z. B. STRING. |
OriginalColumnType |
STRING |
Der ursprüngliche Typ der Spalte, z. B. VARCHAR. |
ColumnLength |
INTEGER |
Die maximale Anzahl von Byte der Spalte, z. B. 30 für VARCHAR(30). |
DefaultValue |
STRING |
Der Standardwert, falls vorhanden. |
Nullable |
BOOLEAN |
Gibt an, ob die Spalte Nullwerte enthalten kann. |
DiskSpace
Die folgende Tabelle enthält Informationen zur Speicherplatzbelegung für jede Datenbank.
| Spalte | Typ | Beschreibung |
|---|---|---|
DatabaseName |
STRING |
Der Name der Datenbank, in Kleinbuchstaben umgewandelt. |
DatabaseNameOriginal |
STRING |
Der Name der Datenbank mit beibehaltener Groß-/Kleinschreibung. |
MaxPerm |
INTEGER |
Die maximale Anzahl der Byte, die dem permanenten Speicherplatz zugeordnet sind. |
MaxSpool |
INTEGER |
Die maximale Anzahl der Byte, die dem Spool-Bereich zugeordnet sind. |
MaxTemp |
INTEGER |
Die maximale Anzahl der Byte, die dem temporären Speicherplatz zugeordnet sind. |
CurrentPerm |
INTEGER |
Die Anzahl der Byte, die dem permanenten Speicherplatz zugeordnet sind. |
CurrentSpool |
INTEGER |
Die Anzahl der Byte, die dem Spool-Bereich zugeordnet sind. |
CurrentTemp |
INTEGER |
Die Anzahl der Byte, die dem temporären Speicherplatz zugeordnet sind. |
PeakPerm |
INTEGER |
Die Höchstzahl der Byte, die seit dem letzten Zurücksetzen für den permanenten Speicherplatz verwendet wurden. |
PeakSpool |
INTEGER |
Die Höchstzahl der Byte, die seit dem letzten Zurücksetzen für den Spool-Bereich verwendet wurden. |
PeakPersistentSpool |
INTEGER |
Die Höchstzahl der Byte, die seit dem letzten Zurücksetzen für den nichtflüchtigen Speicherplatz verwendet wurden. |
PeakTemp |
INTEGER |
Die Höchstzahl der Byte, die seit dem letzten Zurücksetzen für den temporären Speicherplatz verwendet wurden. |
MaxProfileSpool |
INTEGER |
Das Limit für den Spool-Bereich für den Nutzer. |
MaxProfileTemp |
INTEGER |
Das Limit für den temporären Speicherplatz für den Nutzer. |
AllocatedPerm |
INTEGER |
Aktuelle Zuordnung des permanenten Speicherplatzes. |
AllocatedSpool |
INTEGER |
Aktuelle Zuordnung des Spool-Bereichs. |
AllocatedTemp |
INTEGER |
Aktuelle Zuordnung des temporären Speicherplatzes. |
Functions
Diese Tabelle enthält Informationen zu den Funktionen.
| Spalte | Typ | Beschreibung |
|---|---|---|
DatabaseName |
STRING |
Der Name der Datenbank, in Kleinbuchstaben umgewandelt. |
DatabaseNameOriginal |
STRING |
Der Name der Datenbank mit beibehaltener Groß-/Kleinschreibung. |
FunctionName |
STRING |
Der Name der Funktion. |
LanguageName |
STRING |
Der Name der Sprache. |
Indices
Diese Tabelle enthält Informationen zu den Indexen.
| Spalte | Typ | Beschreibung |
|---|---|---|
DatabaseName |
STRING |
Der Name der Datenbank, in Kleinbuchstaben umgewandelt. |
DatabaseNameOriginal |
STRING |
Der Name der Datenbank mit beibehaltener Groß-/Kleinschreibung. |
TableName |
STRING |
Der Name der Tabelle, in Kleinbuchstaben umgewandelt. |
TableNameOriginal |
STRING |
Der Name der Tabelle mit beibehaltener Groß-/Kleinschreibung. |
IndexName |
STRING |
Der Name des Index. |
ColumnName |
STRING |
Der Name der Spalte, in Kleinbuchstaben umgewandelt. |
ColumnNameOriginal |
STRING |
Der Name der Spalte mit beibehaltener Groß-/Kleinschreibung. |
OrdinalPosition |
INTEGER |
Die Position der Spalte. |
UniqueFlag |
BOOLEAN |
Gibt an, ob der Index Eindeutigkeit erzwingt. |
Queries
Diese Tabelle enthält Informationen zu den extrahierten Abfragen.
| Spalte | Typ | Beschreibung |
|---|---|---|
QueryHash |
STRING |
Der Hash der Abfrage. |
QueryText |
STRING |
Der Text der Abfrage. |
QueryLogs
Diese Tabelle enthält einige Ausführungsstatistiken zu den extrahierten Abfragen.
| Spalte | Typ | Beschreibung |
|---|---|---|
QueryText |
STRING |
Der Text der Abfrage. |
QueryHash |
STRING |
Der Hash der Abfrage. |
QueryId |
STRING |
Die ID der Abfrage. |
QueryType |
STRING |
Der Typ der Abfrage, entweder Abfrage oder DDL. |
UserId |
BYTES |
Die ID des Nutzers, der die Abfrage ausgeführt hat. |
UserName |
STRING |
Der Name des Nutzers, der die Abfrage ausgeführt hat. |
StartTime |
TIMESTAMP |
Zeitstempel für das Senden der Abfrage. |
Duration |
STRING |
Dauer der Abfrage in Millisekunden. |
AppId |
STRING |
Die ID der Anwendung, die die Abfrage ausgeführt hat. |
ProxyUser |
STRING |
Der Proxy-Nutzer, wenn über eine Mittelstufe verwendet. |
ProxyRole |
STRING |
Die Proxy-Rolle, wenn über eine Mittelstufe verwendet. |
QueryTypeStatistics
Diese Tabelle enthält Statistiken zu Abfragetypen.
| Spalte | Typ | Beschreibung |
|---|---|---|
QueryHash |
STRING |
Der Hash der Abfrage. |
QueryType |
STRING |
Der Typ der Abfrage. |
UpdatedTable |
STRING |
Die gegebenenfalls von der Abfrage aktualisierte Tabelle. |
QueriedTables |
ARRAY<STRING> |
Eine Liste der abgefragten Tabellen. |
ResUsageScpu
Diese Tabelle enthält Informationen zur CPU-Ressourcennutzung.
| Spalte | Typ | Beschreibung |
|---|---|---|
EventTime |
TIMESTAMP |
Die Uhrzeit des Ereignisses. |
NodeId |
INTEGER |
Knoten-ID |
CabinetId |
INTEGER |
Die physische Schranknummer des Knotens. |
ModuleId |
INTEGER |
Die physische Modulnummer des Knotens. |
NodeType |
STRING |
Knotentyp. |
CpuId |
INTEGER |
ID der CPU in diesem Knoten. |
MeasurementPeriod |
INTEGER |
Der Zeitraum der Messung, ausgedrückt in Hundertstelsekunden. |
SummaryFlag |
STRING |
S: Zeile mit Zusammenfassung (Summary), N – Zeile ohne Zusammenfassung (Non-summary) |
CpuFrequency |
FLOAT |
CPU-Frequenz in MHz. |
CpuIdle |
FLOAT |
Die Inaktivitätszeit der CPU, ausgedrückt in Hundertstelsekunden. |
CpuIoWait |
FLOAT |
Die Zeit, die die CPU auf die E/A wartet, ausgedrückt in Hundertstelsekunden. |
CpuUServ |
FLOAT |
Die Zeit, in der die CPU den Nutzercode ausführt, ausgedrückt in Hundertstelsekunden. |
CpuUExec |
FLOAT |
Die Zeit, in der die CPU den Dienstcode ausführt, ausgedrückt in Hunderstelsekunden. |
Roles
Diese Tabelle enthält Informationen zu Rollen.
| Spalte | Typ | Beschreibung |
|---|---|---|
RoleName |
STRING |
Der Name der Rolle. |
Grantor |
STRING |
Der Datenbankname, der die Rolle zugewiesen hat. |
Grantee |
STRING |
Der Nutzer, dem die Rolle zugewiesen wurde. |
WhenGranted |
TIMESTAMP |
Wann die Rolle gewährt wurde. |
WithAdmin |
BOOLEAN |
Ist die Option „Administrator“ für die zugewiesene Rolle festgelegt. |
SchemaConversion
Die folgende Tabelle enthält Informationen zu Schemakonvertierungen im Zusammenhang mit Clustering und Partitionierung.
| Spaltenname | Spaltentyp | Beschreibung |
|---|---|---|
DatabaseName |
STRING |
Der Name der Quelldatenbank, für die der Vorschlag gemacht wird. Eine Datenbank ist einem Dataset in BigQuery zugeordnet. |
TableName |
STRING |
Der Name der Tabelle, für die der Vorschlag gemacht wird. |
PartitioningColumnName |
STRING |
Der Name der vorgeschlagenen Partitionierungsspalte in BigQuery. |
ClusteringColumnNames |
ARRAY |
Die Namen der vorgeschlagenen Clustering-Spalten in BigQuery. |
CreateTableDDL |
STRING |
Die CREATE TABLE statement zum Erstellen der Tabelle in BigQuery. |
TableInfo
Diese Tabelle enthält Informationen zu Tabellen.
| Spalte | Typ | Beschreibung |
|---|---|---|
DatabaseName |
STRING |
Der Name der Datenbank, in Kleinbuchstaben umgewandelt. |
DatabaseNameOriginal |
STRING |
Der Name der Datenbank mit beibehaltener Groß-/Kleinschreibung. |
TableName |
STRING |
Der Name der Tabelle, in Kleinbuchstaben umgewandelt. |
TableNameOriginal |
STRING |
Der Name der Tabelle mit beibehaltener Groß-/Kleinschreibung. |
LastAccessTimestamp |
TIMESTAMP |
Der Zeitpunkt des letzten Zugriffs auf die Tabelle. |
LastAlterTimestamp |
TIMESTAMP |
Der Zeitpunkt der letzten Änderung der Tabelle. |
TableKind |
STRING |
Der Typ der Tabelle. |
TableRelations
Diese Tabelle enthält Informationen zu Tabellen.
| Spalte | Typ | Beschreibung |
|---|---|---|
QueryHash |
STRING |
Der Hash der Abfrage, die die Beziehung hergestellt hat. |
DatabaseName1 |
STRING |
Der Name der ersten Datenbank. |
TableName1 |
STRING |
Der Name der ersten Tabelle. |
DatabaseName2 |
STRING |
Der Name der zweiten Datenbank. |
TableName2 |
STRING |
Der Name der zweiten Tabelle. |
Relation |
STRING |
Die Art der Beziehung zwischen den beiden Tabellen. |
TableSizes
Diese Tabelle enthält Informationen zu Tabellengrößen.
| Spalte | Typ | Beschreibung |
|---|---|---|
DatabaseName |
STRING |
Der Name der Datenbank, in Kleinbuchstaben umgewandelt. |
DatabaseNameOriginal |
STRING |
Der Name der Datenbank mit beibehaltener Groß-/Kleinschreibung. |
TableName |
STRING |
Der Name der Tabelle, in Kleinbuchstaben umgewandelt. |
TableNameOriginal |
STRING |
Der Name der Tabelle mit beibehaltener Groß-/Kleinschreibung. |
TableSizeInBytes |
INTEGER |
Die Größe der Tabelle in Byte. |
Users
Diese Tabelle enthält Informationen zu Nutzern.
| Spalte | Typ | Beschreibung |
|---|---|---|
UserName |
STRING |
Der Nutzername. |
CreatorName |
STRING |
Der Name der Entität, die diesen Nutzer erstellt hat. |
CreateTimestamp |
TIMESTAMP |
Der Zeitstempel für die Erstellung des Nutzers. |
LastAccessTimestamp |
TIMESTAMP |
Der Zeitstempel, zu dem dieser Nutzer zuletzt auf eine Datenbank zugegriffen hat. |
Redshift
Columns
Die Tabelle Columns stammt aus einer der folgenden Tabellen: SVV_COLUMNS, INFORMATION_SCHEMA.COLUMNS oder PG_TABLE_DEF, geordnet nach Priorität. Das Tool versucht zuerst, Daten aus der Tabelle mit der höchsten Priorität zu laden. Wenn dies fehlschlägt, wird versucht, die Daten aus der Tabelle mit der zweithöchsten Priorität zu laden. Weitere Informationen zum Schema und zur Verwendung finden Sie in der Dokumentation zu Amazon Redshift und PostgreSQL.
| Spalte | Typ | Beschreibung |
|---|---|---|
DatabaseName |
STRING |
Der Name der Instanz. |
SchemaName |
STRING |
Der Name des Schemas. |
TableName |
STRING |
Der Name der Tabelle. |
ColumnName |
STRING |
Der Name der Spalte. |
DefaultValue |
STRING |
Der Standardwert, falls verfügbar. |
Nullable |
BOOLEAN |
Gibt an, ob eine Spalte einen Nullwert haben darf. |
ColumnType |
STRING |
Der Typ der Spalte, z. B. VARCHAR. |
ColumnLength |
INTEGER |
Die Größe der Spalte, z. B. 30 für VARCHAR(30). |
CreateAndDropStatistic
Die folgende Tabelle enthält Informationen zum Erstellen und Löschen von Tabellen.
| Spalte | Typ | Beschreibung |
|---|---|---|
QueryHash |
STRING |
Der Hash der Abfrage. |
DefaultDatabase |
STRING |
Die Standarddatenbank. |
EntityType |
STRING |
Der Typ der Entität, z. B. TABLE. |
EntityName |
STRING |
Der Name der Entität. |
Operation |
STRING |
Der Vorgang: entweder CREATE oder DROP. |
Databases
Diese Tabelle stammt direkt aus der Tabelle PG_DATABASE_INFO von Amazon Redshift. Die ursprünglichen Feldnamen aus der PG-Tabelle sind in den Beschreibungen enthalten. Weitere Informationen zum Schema und zur Verwendung finden Sie in der Dokumentation zu Amazon Redshift und PostgreSQL.
| Spalte | Typ | Beschreibung |
|---|---|---|
DatabaseName |
STRING |
Der Name der Instanz. Quellname: datname |
Owner |
STRING |
Der Inhaber der Datenbank. Beispiel: der Nutzer, der die Datenbank erstellt hat. Quellname: datdba |
ExternalColumns
Diese Tabelle enthält Informationen, die direkt aus der Tabelle SVV_EXTERNAL_COLUMNS in Amazon Redshift stammen. Weitere Informationen zum Schema und zur Nutzung finden Sie in der Dokumentation zu Amazon Redshift.
| Spalte | Typ | Beschreibung |
|---|---|---|
SchemaName |
STRING |
Der Name des externen Schemas. |
TableName |
STRING |
Der Name der externen Tabelle. |
ColumnName |
STRING |
Der Name der externen Spalte. |
ColumnType |
STRING |
Der Typ der Spalte. |
Nullable |
BOOLEAN |
Gibt an, ob eine Spalte einen Nullwert haben darf. |
ExternalDatabases
Diese Tabelle enthält Informationen, die direkt aus der Tabelle SVV_EXTERNAL_DATABASES in Amazon Redshift stammen. Weitere Informationen zum Schema und zur Nutzung finden Sie in der Dokumentation zu Amazon Redshift.
| Spalte | Typ | Beschreibung |
|---|---|---|
DatabaseName |
STRING |
Der Name der externen Datenbank. |
Location |
STRING |
Der Speicherort der Datenbank. |
ExternalPartitions
Diese Tabelle enthält Informationen direkt aus der Tabelle SVV_EXTERNAL_PARTITIONS in Amazon Redshift. Weitere Informationen zum Schema und zur Nutzung finden Sie in der Dokumentation zu Amazon Redshift.
| Spalte | Typ | Beschreibung |
|---|---|---|
SchemaName |
STRING |
Der Name des externen Schemas. |
TableName |
STRING |
Der Name der externen Tabelle. |
Location |
STRING |
Der Speicherort der Partition. Die Spaltengröße ist auf 128 Zeichen beschränkt. Längere Werte werden abgeschnitten. |
ExternalSchemas
Diese Tabelle enthält Informationen, die direkt aus der Tabelle SVV_EXTERNAL_SCHEMAS in Amazon Redshift stammen. Weitere Informationen zum Schema und zur Nutzung finden Sie in der Dokumentation zu Amazon Redshift.
| Spalte | Typ | Beschreibung |
|---|---|---|
SchemaName |
STRING |
Der Name des externen Schemas. |
DatabaseName |
STRING |
Der Name der externen Datenbank. |
ExternalTables
Diese Tabelle enthält Informationen direkt aus der Tabelle SVV_EXTERNAL_TABLES von Amazon Redshift. Weitere Informationen zum Schema und zur Nutzung finden Sie in der Dokumentation zu Amazon Redshift.
| Spalte | Typ | Beschreibung |
|---|---|---|
SchemaName |
STRING |
Der Name des externen Schemas. |
TableName |
STRING |
Der Name der externen Tabelle. |
Functions
Diese Tabelle enthält Informationen direkt aus der Tabelle PG_PROC von Amazon Redshift. Weitere Informationen zum Schema und zur Verwendung finden Sie in der Dokumentation zu Amazon Redshift und PostgreSQL.
| Spalte | Typ | Beschreibung |
|---|---|---|
SchemaName |
STRING |
Der Name des Schemas. |
FunctionName |
STRING |
Der Name der Funktion. |
LanguageName |
STRING |
Die Implementierungssprache oder die Aufrufschnittstelle dieser Funktion. |
Queries
Diese Tabelle wird mit den Informationen aus der Tabelle QueryLogs generiert. Im Gegensatz zur Tabelle QueryLogs enthält jede Zeile in der Tabelle „Queries“ nur eine einzige Abfrageanweisung, die in der Spalte „QueryText“ gespeichert ist. Diese Tabelle enthält die Quelldaten zum Generieren der Statistiktabellen und Übersetzungsausgaben.
| Spalte | Typ | Beschreibung |
|---|---|---|
QueryText |
STRING |
Der Text der Abfrage. |
QueryHash |
STRING |
Der Hash der Abfrage. |
QueryLogs
Diese Tabelle enthält Informationen zur Abfrageausführung.
| Spalte | Typ | Beschreibung |
|---|---|---|
QueryText |
STRING |
Der Text der Abfrage. |
QueryHash |
STRING |
Der Hash der Abfrage. |
QueryID |
STRING |
Die ID der Abfrage. |
UserID |
STRING |
Die ID des Nutzers. |
StartTime |
TIMESTAMP |
Die Startzeit. |
Duration |
INTEGER |
Dauer in Millisekunden. |
QueryTypeStatistics
| Spalte | Typ | Beschreibung |
|---|---|---|
QueryHash |
STRING |
Der Hash der Abfrage. |
DefaultDatabase |
STRING |
Die Standarddatenbank. |
QueryType |
STRING |
Der Typ der Abfrage. |
UpdatedTable |
STRING |
Die aktualisierte Tabelle. |
QueriedTables |
ARRAY<STRING> |
Die abgefragten Tabellen. |
TableInfo
Diese Tabelle enthält Informationen, die aus der Tabelle SVV_TABLE_INFO in Amazon Redshift extrahiert wurden.
| Spalte | Typ | Beschreibung |
|---|---|---|
DatabaseName |
STRING |
Der Name der Instanz. |
SchemaName |
STRING |
Der Name des Schemas. |
TableId |
INTEGER |
Die Tabellen-ID. |
TableName |
STRING |
Der Name der Tabelle. |
SortKey1 |
STRING |
Erste Spalte im Sortierschlüssel. |
SortKeyNum |
INTEGER |
Anzahl der als Sortierschlüssel definierten Spalten. |
MaxVarchar |
INTEGER |
Größe der größten Spalte mit dem Datentyp VARCHAR. |
Size |
INTEGER |
Größe der Tabelle in 1 MB großen Datenblöcken. |
TblRows |
INTEGER |
Anzahl der Zeilen in der Tabelle. |
TableRelations
| Spalte | Typ | Beschreibung |
|---|---|---|
QueryHash |
STRING |
Der Hash der Abfrage, die die Beziehung hergestellt hat (z. B. eine JOIN-Abfrage). |
DefaultDatabase |
STRING |
Die Standarddatenbank. |
TableName1 |
STRING |
Die erste Tabelle der Beziehung. |
TableName2 |
STRING |
Die zweite Tabelle der Beziehung. |
Relation |
STRING |
Die Art der Beziehung. Nimmt einen der folgenden Werte:
COMMA_JOIN, CROSS_JOIN,
FULL_OUTER_JOIN, INNER_JOIN,
LEFT_OUTER_JOIN,
RIGHT_OUTER_JOIN, CREATED_FROM, oder
INSERT_INTO. |
Count |
INTEGER |
Wie oft diese Beziehung beobachtet wurde. |
TableSizes
Diese Tabelle enthält Informationen zu Tabellengrößen.
| Spalte | Typ | Beschreibung |
|---|---|---|
DatabaseName |
STRING |
Der Name der Instanz. |
SchemaName |
STRING |
Der Name des Schemas. |
TableName |
STRING |
Der Name der Tabelle. |
TableSizeInBytes |
INTEGER |
Die Größe der Tabelle in Byte. |
Tables
Diese Tabelle enthält Informationen, die aus der Tabelle SVV_TABLES in Amazon Redshift extrahiert wurden. Weitere Informationen zum Schema und zur Nutzung finden Sie in der Dokumentation zu Amazon Redshift.
| Spalte | Typ | Beschreibung |
|---|---|---|
DatabaseName |
STRING |
Der Name der Instanz. |
SchemaName |
STRING |
Der Name des Schemas. |
TableName |
STRING |
Der Name der Tabelle. |
TableType |
STRING |
Der Typ der Tabelle. |
TranslatedQueries
Diese Tabelle enthält Abfrageübersetzungen.
| Spalte | Typ | Beschreibung |
|---|---|---|
QueryHash |
STRING |
Der Hash der Abfrage. |
TranslatedQueryText |
STRING |
Ergebnis der Übersetzung vom Quelldialekt zu GoogleSQL. |
TranslationErrors
Diese Tabelle enthält Informationen zu Fehlern bei der Abfrageübersetzung.
| Spalte | Typ | Beschreibung |
|---|---|---|
QueryHash |
STRING |
Der Hash der Abfrage. |
Severity |
STRING |
Die Schwere des Fehlers, z. B. ERROR. |
Category |
STRING |
Die Kategorie des Fehlers, z. B. AttributeNotFound. |
Message |
STRING |
Die Nachricht mit den Fehlerdetails. |
LocationOffset |
INTEGER |
Die Zeichenposition des Fehlerorts. |
LocationLine |
INTEGER |
Die Zeilennummer des Fehlers. |
LocationColumn |
INTEGER |
Die Spaltennummer des Fehlers. |
LocationLength |
INTEGER |
Die Zeichenlänge der Position des Fehlers. |
UserTableRelations
| Spalte | Typ | Beschreibung |
|---|---|---|
UserID |
STRING |
Die Nutzer-ID. |
TableName |
STRING |
Der Name der Tabelle. |
Relation |
STRING |
Die Beziehung. |
Count |
INTEGER |
Die Anzahl. |
Users
Diese Tabelle enthält Informationen, die aus der Tabelle PG_USER in Amazon Redshift extrahiert wurden. Weitere Informationen zum Schema und zur Verwendung finden Sie in der PostgreSQL-Dokumentation.
| Spalte | Typ | Beschreibung | |
|---|---|---|---|
UserName |
STRING |
Der Nutzername. | |
UserId |
STRING |
Die Nutzer-ID. |
Snowflake
Warehouses
| Spalte | Typ | Beschreibung | Präsenz |
|---|---|---|---|
WarehouseName |
STRING |
Der Name des Warehouse. | Immer |
State |
STRING |
Der Status des Warehouse. Mögliche Werte: STARTED, SUSPENDED, RESIZING. |
Immer |
Type |
STRING |
Warehouse-Typ. Mögliche Werte: STANDARD, SNOWPARK-OPTIMIZED. |
Immer |
Size |
STRING |
Größe des Warehouse. Mögliche Werte: X-Small, Small, Medium, Large, X-Large, 2X-Large ... 6X-Large. |
Immer |
Databases
| Spalte | Typ | Beschreibung | Präsenz |
|---|---|---|---|
DatabaseNameOriginal |
STRING |
Der Name der Datenbank mit beibehaltener Groß-/Kleinschreibung. | Immer |
DatabaseName |
STRING |
Der Name der Datenbank, in Kleinbuchstaben umgewandelt. | Immer |
Schemata
| Spalte | Typ | Beschreibung | Präsenz |
|---|---|---|---|
DatabaseNameOriginal |
STRING |
Der Name der Datenbank, zu der das Schema gehört, wobei die Groß-/Kleinschreibung beibehalten wird. | Immer |
DatabaseName |
STRING |
Der Name der Datenbank, zu der das Schema gehört, in Kleinbuchstaben umgewandelt. | Immer |
SchemaNameOriginal |
STRING |
Der Name des Schemas, wobei die Groß-/Kleinschreibung beibehalten wird. | Immer |
SchemaName |
STRING |
Der Name des Schemas, in Kleinbuchstaben umgewandelt. | Immer |
Tables
| Spalte | Typ | Beschreibung | Präsenz |
|---|---|---|---|
DatabaseNameOriginal |
STRING |
Der Name der Datenbank, zu der die Tabelle gehört, wobei die Groß-/Kleinschreibung beibehalten wird. | Immer |
DatabaseName |
STRING |
Der Name der Datenbank, zu der die Tabelle gehört, in Kleinbuchstaben umgewandelt. | Immer |
SchemaNameOriginal |
STRING |
Der Name des Schemas, zu dem die Tabelle gehört, wobei die Groß-/Kleinschreibung beibehalten wird. | Immer |
SchemaName |
STRING |
Der Name des Schemas, zu dem die Tabelle gehört, in Kleinbuchstaben umgewandelt. | Immer |
TableNameOriginal |
STRING |
Der Name der Tabelle mit beibehaltener Groß-/Kleinschreibung. | Immer |
TableName |
STRING |
Der Name der Tabelle, in Kleinbuchstaben umgewandelt. | Immer |
TableType |
STRING |
Typ der Tabelle (Ansicht / Materialisierte Ansicht / Basistabelle). | Immer |
RowCount |
BIGNUMERIC |
Anzahl der Zeilen in der Tabelle. | Immer |
Columns
| Spalte | Typ | Beschreibung | Präsenz |
|---|---|---|---|
DatabaseName |
STRING |
Der Name der Datenbank, in Kleinbuchstaben umgewandelt. | Immer |
DatabaseNameOriginal |
STRING |
Der Name der Datenbank mit beibehaltener Groß-/Kleinschreibung. | Immer |
SchemaName |
STRING |
Der Name des Schemas, in Kleinbuchstaben umgewandelt. | Immer |
SchemaNameOriginal |
STRING |
Der Name des Schemas, wobei die Groß-/Kleinschreibung beibehalten wird. | Immer |
TableName |
STRING |
Der Name der Tabelle, in Kleinbuchstaben umgewandelt. | Immer |
TableNameOriginal |
STRING |
Der Name der Tabelle mit beibehaltener Groß-/Kleinschreibung. | Immer |
ColumnName |
STRING |
Der Name der Spalte, in Kleinbuchstaben umgewandelt. | Immer |
ColumnNameOriginal |
STRING |
Der Name der Spalte mit beibehaltener Groß-/Kleinschreibung. | Immer |
ColumnType |
STRING |
Der Typ der Spalte. | Immer |
CreateAndDropStatistics
| Spalte | Typ | Beschreibung | Präsenz |
|---|---|---|---|
QueryHash |
STRING |
Der Hash der Abfrage. | Immer |
DefaultDatabase |
STRING |
Die Standarddatenbank. | Immer |
EntityType |
STRING |
Der Typ der Entität, z. B. TABLE. |
Immer |
EntityName |
STRING |
Der Name der Entität. | Immer |
Operation |
STRING |
Der Vorgang: entweder CREATE oder DROP. |
Immer |
Queries
| Spalte | Typ | Beschreibung | Präsenz |
|---|---|---|---|
QueryText |
STRING |
Der Text der Abfrage. | Immer |
QueryHash |
STRING |
Der Hash der Abfrage. | Immer |
QueryLogs
| Spalte | Typ | Beschreibung | Präsenz |
|---|---|---|---|
QueryText |
STRING |
Der Text der Abfrage. | Immer |
QueryHash |
STRING |
Der Hash der Abfrage. | Immer |
QueryID |
STRING |
Die ID der Abfrage. | Immer |
UserID |
STRING |
Die ID des Nutzers. | Immer |
StartTime |
TIMESTAMP |
Die Startzeit. | Immer |
Duration |
INTEGER |
Dauer in Millisekunden. | Immer |
QueryTypeStatistics
| Spalte | Typ | Beschreibung | Präsenz |
|---|---|---|---|
QueryHash |
STRING |
Der Hash der Abfrage. | Immer |
DefaultDatabase |
STRING |
Die Standarddatenbank. | Immer |
QueryType |
STRING |
Der Typ der Abfrage. | Immer |
UpdatedTable |
STRING |
Die aktualisierte Tabelle. | Immer |
QueriedTables |
REPEATED STRING |
Die abgefragten Tabellen. | Immer |
TableRelations
| Spalte | Typ | Beschreibung | Präsenz |
|---|---|---|---|
QueryHash |
STRING |
Der Hash der Abfrage, die die Beziehung hergestellt hat (z. B. eine JOIN-Abfrage). |
Immer |
DefaultDatabase |
STRING |
Die Standarddatenbank. | Immer |
TableName1 |
STRING |
Die erste Tabelle der Beziehung. | Immer |
TableName2 |
STRING |
Die zweite Tabelle der Beziehung. | Immer |
Relation |
STRING |
Die Art der Beziehung. | Immer |
Count |
INTEGER |
Wie oft diese Beziehung beobachtet wurde. | Immer |
TranslatedQueries
| Spalte | Typ | Beschreibung | Präsenz |
|---|---|---|---|
QueryHash |
STRING |
Der Hash der Abfrage. | Immer |
TranslatedQueryText |
STRING |
Ergebnis der Übersetzung vom Quelldialekt in BigQuery SQL. | Immer |
TranslationErrors
| Spalte | Typ | Beschreibung | Präsenz |
|---|---|---|---|
QueryHash |
STRING |
Der Hash der Abfrage. | Immer |
Severity |
STRING |
Der Schweregrad des Fehlers, z. B. ERROR. |
Immer |
Category |
STRING |
Die Kategorie des Fehlers, z. B. AttributeNotFound. |
Immer |
Message |
STRING |
Die Nachricht mit den Fehlerdetails. | Immer |
LocationOffset |
INTEGER |
Die Zeichenposition des Fehlerorts. | Immer |
LocationLine |
INTEGER |
Die Zeilennummer des Fehlers. | Immer |
LocationColumn |
INTEGER |
Die Spaltennummer des Fehlers. | Immer |
LocationLength |
INTEGER |
Die Zeichenlänge der Position des Fehlers. | Immer |
UserTableRelations
| Spalte | Typ | Beschreibung | Präsenz |
|---|---|---|---|
UserID |
STRING |
Nutzer-ID | Immer |
TableName |
STRING |
Der Name der Tabelle. | Immer |
Relation |
STRING |
Die Beziehung. | Immer |
Count |
INTEGER |
Die Anzahl. | Immer |
Apache Hive
Columns
Diese Tabelle enthält Informationen zu den Spalten:
| Spalte | Typ | Beschreibung |
|---|---|---|
DatabaseName |
STRING |
Der Name der Datenbank mit beibehaltener Groß-/Kleinschreibung. |
TableName |
STRING |
Der Name der Tabelle mit beibehaltener Groß-/Kleinschreibung. |
ColumnName |
STRING |
Der Name der Spalte mit beibehaltener Groß-/Kleinschreibung. |
ColumnType |
STRING |
Der BigQuery-Typ der Spalte, z. B. STRING. |
OriginalColumnType |
STRING |
Der ursprüngliche Typ der Spalte, z. B. VARCHAR. |
CreateAndDropStatistic
Die folgende Tabelle enthält Informationen zum Erstellen und Löschen von Tabellen:
| Spalte | Typ | Beschreibung |
|---|---|---|
QueryHash |
STRING |
Der Hash der Abfrage. |
DefaultDatabase |
STRING |
Die Standarddatenbank. |
EntityType |
STRING |
Der Typ der Entität, z. B. TABLE. |
EntityName |
STRING |
Der Name der Entität. |
Operation |
STRING |
Der Vorgang, der für die Tabelle ausgeführt wird (CREATE oder DROP). |
Databases
Diese Tabelle enthält Informationen zu den Datenbanken:
| Spalte | Typ | Beschreibung |
|---|---|---|
DatabaseName |
STRING |
Der Name der Datenbank mit beibehaltener Groß-/Kleinschreibung. |
Owner |
STRING |
Der Inhaber der Datenbank. Beispiel: der Nutzer, der die Datenbank erstellt hat. |
Location |
STRING |
Speicherort der Datenbank im Dateisystem. |
Functions
Diese Tabelle enthält Informationen zu den Funktionen:
| Spalte | Typ | Beschreibung |
|---|---|---|
DatabaseName |
STRING |
Der Name der Datenbank mit beibehaltener Groß-/Kleinschreibung. |
FunctionName |
STRING |
Der Name der Funktion. |
LanguageName |
STRING |
Der Name der Sprache. |
ClassName |
STRING |
Der Klassenname der Funktion. |
ObjectReferences
Diese Tabelle enthält Informationen zu den Objekten, auf die in Abfragen verwiesen wird:
| Spalte | Typ | Beschreibung |
|---|---|---|
QueryHash |
STRING |
Der Hash der Abfrage. |
DefaultDatabase |
STRING |
Die Standarddatenbank. |
Clause |
STRING |
Die Klausel, in der das Objekt vorkommt. Beispiel: SELECT. |
ObjectName |
STRING |
Der Name des Objekts. |
Type |
STRING |
Der Typ des Objekts. |
Subtype |
STRING |
Der Untertyp des Objekts. |
PartitionKeys
Die folgende Tabelle enthält Informationen zu den Partitionsschlüsseln:
| Spalte | Typ | Beschreibung |
|---|---|---|
DatabaseName |
STRING |
Der Name der Datenbank mit beibehaltener Groß-/Kleinschreibung. |
TableName |
STRING |
Der Name der Tabelle mit beibehaltener Groß-/Kleinschreibung. |
ColumnName |
STRING |
Der Name der Spalte mit beibehaltener Groß-/Kleinschreibung. |
ColumnType |
STRING |
Der BigQuery-Typ der Spalte, z. B. STRING. |
Partitions
Diese Tabelle enthält Informationen zu den Tabellenpartitionen:
| Spalte | Typ | Beschreibung |
|---|---|---|
DatabaseName |
STRING |
Der Name der Datenbank mit beibehaltener Groß-/Kleinschreibung. |
TableName |
STRING |
Der Name der Tabelle mit beibehaltener Groß-/Kleinschreibung. |
PartitionName |
STRING |
Der Name der Partition. |
CreateTimestamp |
TIMESTAMP |
Der Zeitstempel der Erstellung dieser Partition. |
LastAccessTimestamp |
TIMESTAMP |
Der Zeitstempel des letzten Zugriffs auf diese Partition. |
LastDdlTimestamp |
TIMESTAMP |
Der Zeitstempel der letzten Änderung dieser Partition. |
TotalSize |
INTEGER |
Die komprimierte Größe der Partition in Byte. |
Queries
Diese Tabelle wird mit den Informationen aus der Tabelle QueryLogs generiert. Im Gegensatz zur Tabelle QueryLogs enthält jede Zeile in der Tabelle „Queries“ nur eine einzige Abfrageanweisung, die in der Spalte QueryText gespeichert ist. Diese Tabelle enthält die Quelldaten zum Generieren der Statistiktabellen und Übersetzungsausgaben:
| Spalte | Typ | Beschreibung |
|---|---|---|
QueryHash |
STRING |
Der Hash der Abfrage. |
QueryText |
STRING |
Der Text der Abfrage. |
QueryLogs
Diese Tabelle enthält einige Ausführungsstatistiken zu den extrahierten Abfragen:
| Spalte | Typ | Beschreibung |
|---|---|---|
QueryText |
STRING |
Der Text der Abfrage. |
QueryHash |
STRING |
Der Hash der Abfrage. |
QueryId |
STRING |
Die ID der Abfrage. |
QueryType |
STRING |
Der Typ der Abfrage, entweder Query oder DDL. |
UserName |
STRING |
Der Name des Nutzers, der die Abfrage ausgeführt hat. |
StartTime |
TIMESTAMP |
Der Zeitstempel für das Senden der Abfrage. |
Duration |
STRING |
Die Dauer der Abfrage in Millisekunden. |
QueryTypeStatistics
Diese Tabelle enthält Statistiken zu Abfragetypen:
| Spalte | Typ | Beschreibung |
|---|---|---|
QueryHash |
STRING |
Der Hash der Abfrage. |
QueryType |
STRING |
Der Typ der Abfrage. |
UpdatedTable |
STRING |
Gegebenenfalls die von der Abfrage aktualisierte Tabelle. |
QueriedTables |
ARRAY<STRING> |
Eine Liste der abgefragten Tabellen. |
QueryTypes
Diese Tabelle enthält Statistiken zu Abfragetypen:
| Spalte | Typ | Beschreibung |
|---|---|---|
QueryHash |
STRING |
Der Hash der Abfrage. |
Category |
STRING |
Die Kategorie der Abfrage. |
Type |
STRING |
Der Typ der Abfrage. |
Subtype |
STRING |
Der Untertyp der Abfrage. |
SchemaConversion
Die folgende Tabelle enthält Informationen zu Schemakonvertierungen im Zusammenhang mit Clustering und Partitionierung:
| Spaltenname | Spaltentyp | Beschreibung |
|---|---|---|
DatabaseName |
STRING |
Der Name der Quelldatenbank, für die der Vorschlag gemacht wird. Eine Datenbank ist einem Dataset in BigQuery zugeordnet. |
TableName |
STRING |
Der Name der Tabelle, für die der Vorschlag gemacht wird. |
PartitioningColumnName |
STRING |
Der Name der vorgeschlagenen Partitionierungsspalte in BigQuery. |
ClusteringColumnNames |
ARRAY |
Die Namen der vorgeschlagenen Clustering-Spalten in BigQuery. |
CreateTableDDL |
STRING |
Die CREATE TABLE statement zum Erstellen der Tabelle in BigQuery. |
TableRelations
Diese Tabelle enthält Informationen zu Tabellen:
| Spalte | Typ | Beschreibung |
|---|---|---|
QueryHash |
STRING |
Der Hash der Abfrage, die die Beziehung hergestellt hat. |
DatabaseName1 |
STRING |
Der Name der ersten Datenbank. |
TableName1 |
STRING |
Der Name der ersten Tabelle. |
DatabaseName2 |
STRING |
Der Name der zweiten Datenbank. |
TableName2 |
STRING |
Der Name der zweiten Tabelle. |
Relation |
STRING |
Die Art der Beziehung zwischen den beiden Tabellen. |
TableSizes
Diese Tabelle enthält Informationen zu Tabellengrößen:
| Spalte | Typ | Beschreibung |
|---|---|---|
DatabaseName |
STRING |
Der Name der Datenbank mit beibehaltener Groß-/Kleinschreibung. |
TableName |
STRING |
Der Name der Tabelle mit beibehaltener Groß-/Kleinschreibung. |
TotalSize |
INTEGER |
Die Größe der Tabelle in Byte. |
Tables
Diese Tabelle enthält Informationen zu Tabellen:
| Spalte | Typ | Beschreibung |
|---|---|---|
DatabaseName |
STRING |
Der Name der Datenbank mit beibehaltener Groß-/Kleinschreibung. |
TableName |
STRING |
Der Name der Tabelle mit beibehaltener Groß-/Kleinschreibung. |
Type |
STRING |
Der Typ der Tabelle. |
TranslatedQueries
Diese Tabelle enthält Abfrageübersetzungen:
| Spalte | Typ | Beschreibung |
|---|---|---|
QueryHash |
STRING |
Der Hash der Abfrage. |
TranslatedQueryText |
STRING |
Das Ergebnis der Übersetzung vom Quelldialekt in GoogleSQL. |
TranslationErrors
Diese Tabelle enthält Informationen zu Fehlern bei der Abfrageübersetzung:
| Spalte | Typ | Beschreibung |
|---|---|---|
QueryHash |
STRING |
Der Hash der Abfrage. |
Severity |
STRING |
Die Schwere des Fehlers, z. B. ERROR. |
Category |
STRING |
Die Kategorie des Fehlers, z. B. AttributeNotFound. |
Message |
STRING |
Die Nachricht mit den Fehlerdetails. |
LocationOffset |
INTEGER |
Die Zeichenposition des Fehlerorts. |
LocationLine |
INTEGER |
Die Zeilennummer des Fehlers. |
LocationColumn |
INTEGER |
Die Spaltennummer des Fehlers. |
LocationLength |
INTEGER |
Die Zeichenlänge der Position des Fehlers. |
UserTableRelations
| Spalte | Typ | Beschreibung |
|---|---|---|
UserID |
STRING |
Die Nutzer-ID. |
TableName |
STRING |
Der Name der Tabelle. |
Relation |
STRING |
Die Beziehung. |
Count |
INTEGER |
Die Anzahl. |
Fehlerbehebung
In diesem Abschnitt werden einige häufige Probleme und Techniken zur Fehlerbehebung für die Migration Ihres Data Warehouse zu BigQuery erläutert.
dwh-migration-dumper-Toolfehler
Informationen zur Fehlerbehebung bei Fehlern und Warnungen in der Terminalausgabe des dwh-migration-dumper-Tools, die beim Extrahieren von Metadaten oder Abfragelogs aufgetreten sind, finden Sie unter Fehlerbehebung beim Generieren von Metadaten.
Fehler bei der Hive-Migration
In diesem Abschnitt werden häufige Probleme beschrieben, die bei der Migration Ihres Data Warehouse von Hive zu BigQuery auftreten können.
Der Logging-Hook schreibt Debugging-Logeinträge in Ihre hive-server2-Logs. Überprüfen Sie bei Problemen die Logging-Hook-Debugging-Logs, die den String MigrationAssessmentLoggingHook enthalten.
Fehler ClassNotFoundException verarbeiten
Der Fehler kann dadurch verursacht werden, dass die Logging-Hook-JAR-Datei am falschen Ort gespeichert wurde. Prüfen Sie, ob Sie die JAR-Datei dem Ordner „auxlib“ im Hive-Cluster hinzugefügt haben. Alternativ können Sie den vollständigen Pfad zur JAR-Datei im Attribut hive.aux.jars.path angeben, z. B. file://.
Unterordner werden nicht im konfigurierten Ordner angezeigt
Dieses Problem kann durch eine fehlerhafte Konfiguration oder Probleme bei der Logging-Hook-Initialisierung verursacht werden.
Suchen Sie in den hive-server2-Debugging-Logs nach den folgenden Logging-Hook-Einträgen:
Unable to initialize logger, logging disabled
Log dir configuration key 'dwhassessment.hook.base-directory' is not set, logging disabled.
Error while trying to set permission
Sehen Sie sich die Problemdetails an und prüfen Sie, ob Sie etwas korrigieren müssen, um das Problem zu beheben.
Dateien werden nicht im Ordner angezeigt
Dieses Problem kann durch Probleme verursacht werden, die während einer Ereignisverarbeitung oder beim Schreiben in eine Datei aufgetreten sind.
Suchen Sie in den hive-server2-Debugging-Logs nach den folgenden Logging-Hook-Einträgen:
Failed to close writer for file
Got exception while processing event
Error writing record for query
Sehen Sie sich die Problemdetails an und prüfen Sie, ob Sie etwas korrigieren müssen, um das Problem zu beheben.
Einige Abfrageereignisse fehlen
Dieses Problem kann durch einen Überlauf der Logging-Hook-Thread-Warteschlange verursacht werden.
Suchen Sie in den hive-server2-Debugging-Logs nach dem folgenden Logging-Hook-Eintrag:
Writer queue is full. Ignoring event
Wenn solche Einträge vorhanden sind, sollten Sie den Parameter dwhassessment.hook.queue.capacity erhöhen.
Nächste Schritte
Weitere Informationen zum dwh-migration-dumper-Tool finden Sie unter dwh-migration-tools.
Weitere Informationen zu den folgenden Schritten bei der Data-Warehouse-Migration:
- Übersicht über die Migration
- Schema- und Datenübertragung
- Datenpipelines
- Batch-SQL-Übersetzung
- Interaktive SQL-Übersetzung
- Datensicherheit und Governance
- Datenvalidierungstool