Gestione dei tag di criteri in varie località
Questo documento descrive come gestire i tag di criteri tra località regionali per sicurezza a livello di colonna e mascheramento dinamico dei dati in BigQuery.
BigQuery offre un controllo dell'accesso granulare e il mascheramento dinamico dei dati colonne di tabelle sensibili tramite tag di criteri, con supporto delle per la classificazione dei dati.
Dopo aver creato una tassonomia di classificazione dei dati e aver applicato i tag di criteri puoi gestire ulteriormente i tag di criteri nelle varie località.
Considerazioni sulla località
Le tassonomie sono risorse di regione, come i set di dati BigQuery tabelle. Quando crei una tassonomia, specifichi la regione, o località, per la tassonomia.
Puoi creare una tassonomia e applicare tag di criteri alle tabelle in tutte le regioni in cui è disponibile BigQuery. Tuttavia, per applicare i tag di criteri da una tassonomia a una colonna della tabella, la tassonomia e la tabella devono esistere nella stessa località regionale.
Sebbene non sia possibile applicare un tag di criteri a una colonna della tabella esistente in un località diversa, puoi copiare la tassonomia in un'altra posizione esplicitamente replicandolo lì.
Utilizzo di tassonomie tra località
Puoi copiare (o replicare) esplicitamente un tassonomia e delle relative definizioni dei tag di criteri in altre località senza di creare manualmente una nuova tassonomia in ogni località. Quando replichi tassonomie, puoi usare gli stessi tag di criteri per la sicurezza a livello di colonna più sedi, semplificandone la gestione.
Quando li replichi, la tassonomia e i tag di criteri conservano gli stessi ID in ogni località.
I tag della tassonomia e dei criteri possono essere sincronizzati di nuovo, per mantenerli unificati in più località. La replica esplicita di una tassonomia è eseguita da una chiamata API Data Catalog. Sincronizzazioni future del replicato tassonomia usano lo stesso comando API, che sovrascrive la tassonomia precedente.
Per facilitare la sincronizzazione della tassonomia, è possibile utilizzare Cloud Scheduler per eseguire periodicamente una sincronizzazione dei tassonomia tra regioni, in base a una programmazione prestabilita o alla pressione manuale dei pulsanti. Per utilizzare Cloud Scheduler, devi configurare un account di servizio.
Replica di una tassonomia in una nuova località
Autorizzazioni obbligatorie
Le credenziali utente o l'account di servizio che replica la tassonomia devono avere Ruolo Amministratore tag di criteri di Data Catalog.
Scopri di più sulla concessione del ruolo Amministratore tag di criteri in Limitazione dell'accesso con la sicurezza a livello di colonna di BigQuery.
Per ulteriori informazioni su ruoli e autorizzazioni IAM in BigQuery, vedi Autorizzazioni e ruoli predefiniti.
Per replicare una tassonomia tra località:
API
Chiama il
projects.locations.taxonomies.import
dell'API Data Catalog, fornendo una richiesta POST e
il nome del progetto di destinazione e la posizione nella stringa HTTP.
POST https://datacatalog.googleapis.com/{parent}/taxonomies:import
Il parametro del percorso parent corrisponde al progetto e alla località di destinazione
in cui vuoi copiare la tassonomia. Esempio:
projects/MyProject/locations/eu
Sincronizzazione di una tassonomia replicata
Per sincronizzare una tassonomia già replicata tra località, ripeti il comando Chiamata all'API Data Catalog come descritto in Replica di una tassonomia in una nuova località.
In alternativa, puoi utilizzare un account di servizio e Cloud Scheduler per sincronizzare tassonomia in base a una pianificazione specificata. La configurazione di un account di servizio in Cloud Scheduler consente inoltre di attivare una sincronizzazione on demand (non pianificata) tramite la pagina Cloud Scheduler nella console Google Cloud oppure con Google Cloud CLI.
Sincronizzazione di una tassonomia replicata con Cloud Scheduler
Per sincronizzare una tassonomia replicata tra località con Cloud Scheduler, è necessario un account di servizio.
Account di servizio
Puoi concedere le autorizzazioni per la sincronizzazione della replica a un servizio esistente un account di servizio, oppure puoi crearne uno nuovo.
Per creare un nuovo account di servizio, consulta Crea gli account di servizio.
Autorizzazioni obbligatorie
L'account di servizio che esegue la sincronizzazione della tassonomia deve avere il valore Ruolo Amministratore tag di criteri di Data Catalog. Per ulteriori informazioni, vedi Concedi il ruolo Amministratore tag di criteri.
Configurazione di una sincronizzazione della tassonomia con Cloud Scheduler
Per sincronizzare una tassonomia replicata tra località con Cloud Scheduler:
Console
Innanzitutto, crea il job di sincronizzazione e la relativa pianificazione.
Segui le istruzioni per Crea un job in Cloud Scheduler.
In Frequenza, inserisci l'intervallo che preferisci tra le offerte automatiche viene sincronizzato.
Per Target, vedi le istruzioni alla pagina Creazione di un job scheduler con autenticazione.
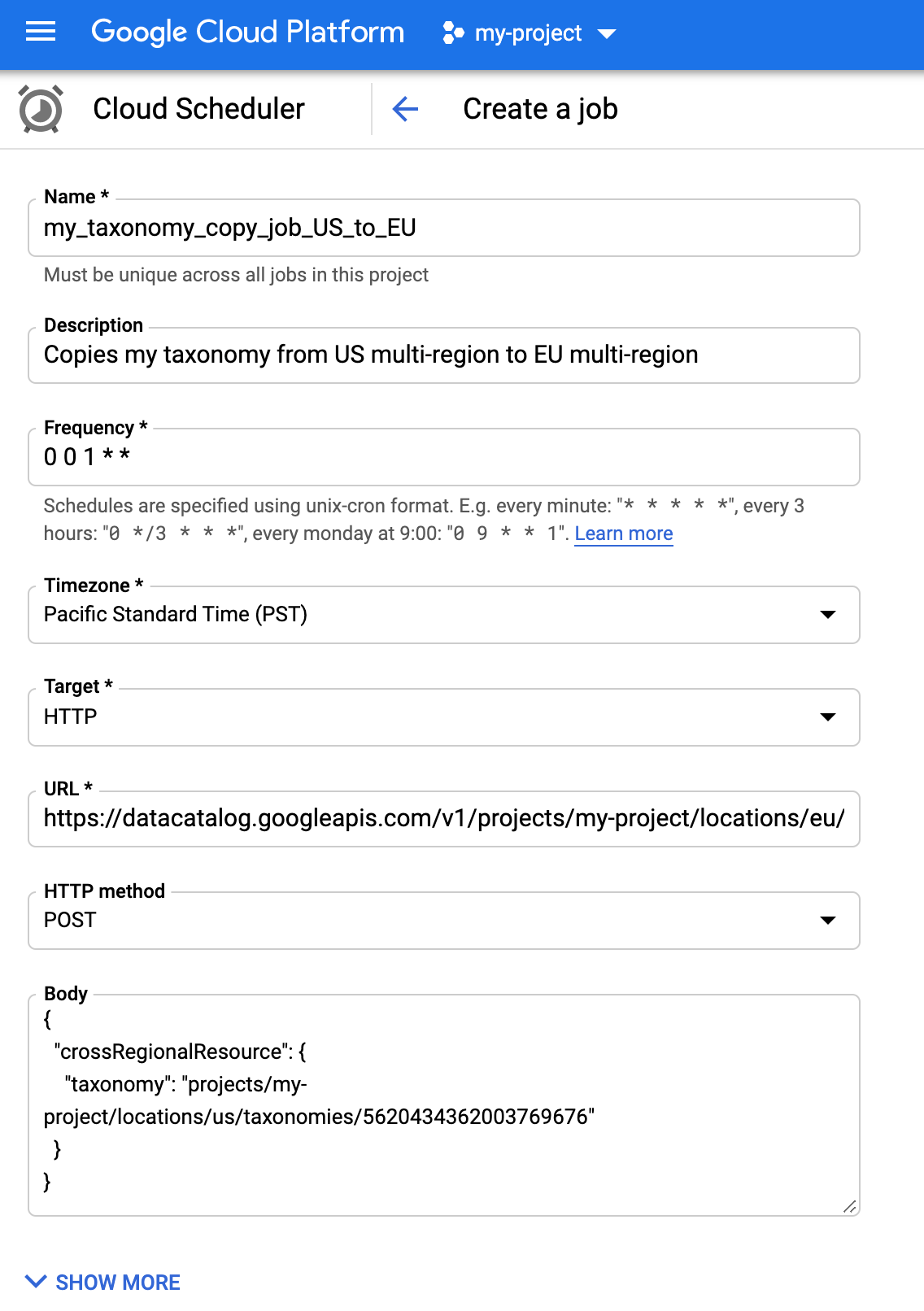
Quindi, aggiungi l'autenticazione necessaria per la sincronizzazione pianificata.
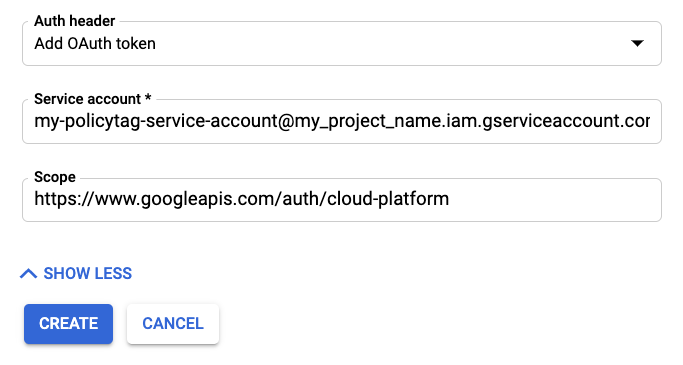
Fai clic su MOSTRA ALTRO per visualizzare i campi di autenticazione.
Per Intestazione autorizzazione, seleziona "Aggiungi token OAuth".
Aggiungi le informazioni dell'account di servizio.
Per Ambito, inserisci "https://www.googleapis.com/auth/cloud-platform".
Fai clic su Crea per salvare la sincronizzazione pianificata.
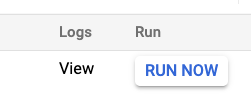
Ora verifica che il job sia configurato correttamente.
Dopo aver creato il job, fai clic su Esegui ora per testare il job. sia configurato correttamente. Successivamente, Cloud Scheduler attiva la richiesta HTTP in base alla pianificazione specificata.
gcloud
Sintassi:
gcloud scheduler jobs create http "JOB_ID" --schedule="FREQUENCY" --uri="URI" --oath-service-account-email="CLIENT_SERVICE_ACCOUNT_EMAIL" --time-zone="TIME_ZONE" --message-body-from-file="MESSAGE_BODY"
Sostituisci quanto segue:
${JOB_ID}è un nome per il job. Deve essere univoco nel progetto. Tieni presente che non puoi riutilizzare un nome job in un progetto anche se elimini al job associato.${FREQUENCY}è la pianificazione, chiamata anche intervallo job, della frequenza dovrebbe essere eseguito il job. Ad esempio, "ogni 3 ore". La stringa che fornisci qui può essere qualsiasi stringa compatibile con crontab. In alternativa, gli sviluppatori che hanno familiarità con la versione precedente di cron di App Engine Utilizzare App Engine Cron a riga di comando.${URI}è l'URL completo dell'endpoint.--oauth-service-account-emaildefinisce il tipo di token. Tieni presente che Le API di Google ospitate su*.googleapis.comprevedono un protocollo OAuth di accesso.${CLIENT_SERVICE_ACCOUNT_EMAIL}è l'email del cliente l'account di servizio.${MESSAGE_BODY}è il percorso del file che contiene il POST corpo della richiesta.
Sono disponibili altri parametri di opzione, descritti nel Riferimento per Google Cloud CLI.
Esempio:
gcloud scheduler jobs create http cross_regional_copy_to_eu_scheduler --schedule="0 0 1 * *" --uri="https://datacatalog.googleapis.com/v1/projects/my-project/locations/eu/taxonomies:import" --oauth-service-account-email="policytag-manager-service-acou@my-project.iam.gserviceaccount.com" --time-zone="America/Los_Angeles" --message-body-from-file=request_body.json
Passaggi successivi
- Per una panoramica della sicurezza a livello di colonna con i tag di criteri, consulta Introduzione alla sicurezza a livello di colonna di BigQuery.
- Per ulteriori informazioni sulla creazione e l'applicazione di tag di criteri, consulta Limitazione dell'accesso con la sicurezza a livello di colonna di BigQuery
- per scoprire l'impatto sulle scritture quando utilizzi BigQuery sicurezza a livello di colonna, consulta Impatto sulle scritture con la sicurezza a livello di colonna di BigQuery.
- Per informazioni sulle best practice per l'utilizzo dei tag di criteri, consulta Utilizzo dei tag di criteri in BigQuery.