Manage partition and cluster recommendations
This document describes how the partition and cluster recommender works, how to view your recommendations and insights, and how can apply partition and cluster recommendations.
How the recommender works
The BigQuery partitioning and clustering recommender generates partition or cluster recommendations to optimize your BigQuery tables. The recommender analyzes workflows on your BigQuery tables and offers recommendations to better optimize your workflows and query costs using either table partitioning or table clustering.
For more information about the Recommender service, see the Recommender overview.
The partitioning and clustering recommender uses the project's workload execution data from the past 30 days to analyze each BigQuery table for suboptimal partitioning and clustering configurations. The recommender also uses machine learning to predict how much the workload execution could be optimized with different partitioning or clustering configurations. If the recommender finds that partitioning or clustering a table yields significant savings, the recommender generates a recommendation. The partitioning and clustering recommender generates the following types of recommendations:
| Existing table type | Recommendation subtype | Recommendation example |
|---|---|---|
| Non-partitioned, non-clustered | Partition | "Save about 64 slot hours per month by partitioning on column_C by DAY" |
| Non-partitioned, non-clustered | Cluster | "Save about 64 slot hours per month by clustering on column_C" |
| Partitioned, non-clustered | Cluster | "Save about 64 slot hours per month by clustering on column_C" |
Each recommendation consists of three parts:
- Guidance to either partition or cluster a specific table
- The specific column in a table to partition or cluster
- Estimated monthly savings for applying the recommendation
To calculate potential workload savings, the recommender assumes that the historical execution workload data from the past 30 days represents the future workload.
The recommender API also returns table workload information in the form of insights. Insights are findings that help you understand your project's workload, providing more context on how a partition or cluster recommendation might improve workload costs.
Limitations
The partitioning and clustering recommender does not support BigQuery tables with legacy SQL. When generating a recommendation, the recommender excludes any legacy SQL queries in its analysis. Additionally, applying partition recommendations on BigQuery tables with legacy SQL breaks any legacy SQL workflows in that table.
Before you apply partition recommendations, migrate your legacy SQL workflows into GoogleSQL.
BigQuery does not support changing the partitioning scheme of a table in place. You can only change the partitioning of a table on a copy of the table. For more information, see Apply partition recommendations.
Locations
The partitioning and clustering recommender is available in the following processing locations:
| Region description | Region name | Details | |
|---|---|---|---|
| Asia Pacific | |||
| Delhi | asia-south2 |
||
| Hong Kong | asia-east2 |
||
| Jakarta | asia-southeast2 |
||
| Mumbai | asia-south1 |
||
| Osaka | asia-northeast2 |
||
| Seoul | asia-northeast3 |
||
| Singapore | asia-southeast1 |
||
| Sydney | australia-southeast1 |
||
| Taiwan | asia-east1 |
||
| Tokyo | asia-northeast1 |
||
| Europe | |||
| Belgium | europe-west1 |
|
|
| Berlin | europe-west10 |
||
| EU multi-region | eu |
||
| Frankfurt | europe-west3 |
||
| London | europe-west2 |
|
|
| Netherlands | europe-west4 |
|
|
| Zürich | europe-west6 |
|
|
| Americas | |||
| Iowa | us-central1 |
|
|
| Las Vegas | us-west4 |
||
| Los Angeles | us-west2 |
||
| Montréal | northamerica-northeast1 |
|
|
| Northern Virginia | us-east4 |
||
| Oregon | us-west1 |
|
|
| Salt Lake City | us-west3 |
||
| São Paulo | southamerica-east1 |
|
|
| Toronto | northamerica-northeast2 |
|
|
| US multi-region | us |
||
Before you begin
- Ensure that Gemini in BigQuery is enabled for your Google Cloud project.
- Enable the Recommender API.
Required permissions
To get the permissions that
you need to access partition and cluster recommendations,
ask your administrator to grant you the
BigQuery Partitioning Clustering Recommender Viewer (roles/recommender.bigqueryPartitionClusterViewer)
IAM role.
For more information about granting roles, see Manage access to projects, folders, and organizations.
This predefined role contains the permissions required to access partition and cluster recommendations. To see the exact permissions that are required, expand the Required permissions section:
Required permissions
The following permissions are required to access partition and cluster recommendations:
-
recommender.bigqueryPartitionClusterRecommendations.get -
recommender.bigqueryPartitionClusterRecommendations.list
You might also be able to get these permissions with custom roles or other predefined roles.
For more information about IAM roles and permissions in BigQuery, see Introduction to IAM.
View recommendations
This section describes how to view partition and cluster recommendations and insights using the Google Cloud console, the Google Cloud CLI, or the Recommender API.
Select one of the following options:
Console
In the Google Cloud console, go to the BigQuery page.
In the navigation menu, click Recommendations.
The recommendations tab lists all recommendations available to your project.
In the Optimize BigQuery workload cost panel, click View all.
The cost recommendation table lists all recommendations generated for the current project. For example, the following screenshot shows that the recommender analyzed the
example_tabletable, and then recommended clustering theexample_columncolumn to save an approximate amount of bytes and slots.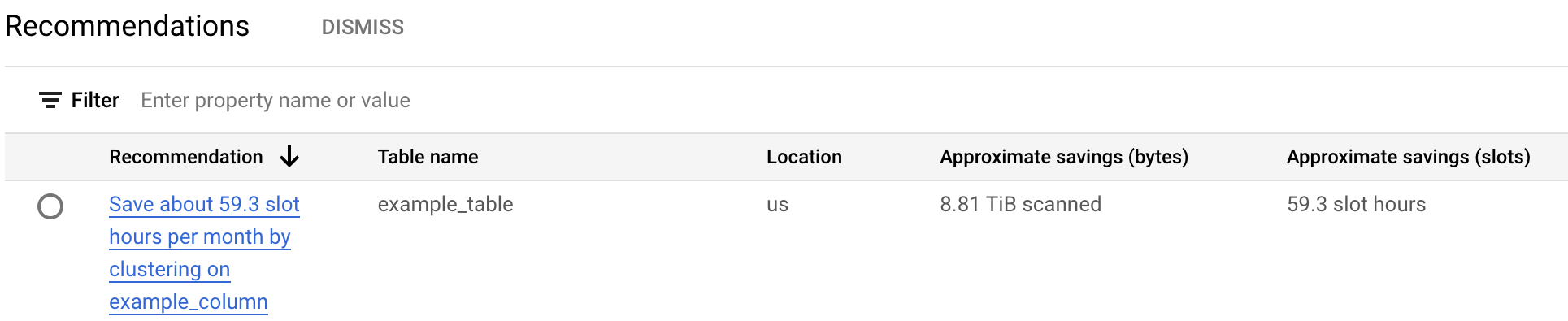
To see more information about the table insight and recommendation, click a recommendation.
gcloud
To view partition or cluster recommendations for a specific project, use
the gcloud recommender recommendations list command:
gcloud recommender recommendations list \
--project=PROJECT_NAME \
--location=REGION_NAME \
--recommender=google.bigquery.table.PartitionClusterRecommender \
--format=FORMAT_TYPE \
Replace the following:
PROJECT_NAME: the name of the project that contains your BigQuery tableREGION_NAME: the region that your project is inFORMAT_TYPE: a supported gcloud CLI output format—for example, JSON
| Property | Relevant for subtype | Description |
|---|---|---|
recommenderSubtype |
Partition or cluster | Indicates the type of recommendation. |
content.overview.partitionColumn |
Partition | Recommended partitioning column name. |
content.overview.partitionTimeUnit |
Partition | Recommended partitioning time unit. For example, DAY means the
recommendation is to have daily partitions on the recommended column. |
content.overview.clusterColumns |
Cluster | Recommended clustering column names. |
- For more information about other fields in the recommender response, see REST Resource:
projects.locations.recommendersrecommendation. - For more information about using the Recommender API, see Using the API - Recommendations.
To view table insights using the gcloud CLI, use the
gcloud recommender insights list command:
gcloud recommender insights list \
--project=PROJECT_NAME \
--location=REGION_NAME \
--insight-type=google.bigquery.table.StatsInsight \
--format=FORMAT_TYPE \
Replace the following:
PROJECT_NAME: the name of the project that contains your BigQuery tableREGION_NAME: the region that your project is inFORMAT_TYPE: a supported gcloud CLI output format—for example, JSON
| Property | Relevant for subtype | Description |
|---|---|---|
content.existingPartitionColumn |
Cluster | Existing partitioning column, if any |
content.tableSizeTb |
All | Size of the table in terabytes |
content.bytesReadMonthly |
All | Monthly bytes read from the table |
content.slotMsConsumedMonthly |
All | Monthly slot milliseconds consumed by the workload running on the table |
content.queryJobsCountMonthly |
All | Monthly count of jobs running on the table |
- For more information about other fields in the insights response, see REST Resource:
projects.locations.insightTypes.insights. - For more information about using insights, see Using the API - Insights.
REST API
To view partition or cluster recommendations for a specific project, use the REST API. With each command, you must provide an authentication token, which you can get using the gcloud CLI. For more information about getting an authentication token, see Methods for getting an ID token.
You can use the curl list request to view all recommendations for a
specific project:
curl
-H "Authorization: Bearer $GCLOUD_AUTH_TOKEN"
-H "x-goog-user-project: PROJECT_NAME" https://recommender.googleapis.com/v1/projects/my-project/locations/us/recommenders/google.bigquery.table.PartitionClusterRecommender/recommendations
Replace the following:
GCLOUD_AUTH_TOKEN: the name of a valid gcloud CLI access tokenPROJECT_NAME: the name of the project containing your BigQuery table
| Property | Relevant for subtype | Description |
|---|---|---|
recommenderSubtype |
Partition or cluster | Indicates the type of recommendation. |
content.overview.partitionColumn |
Partition | Recommended partitioning column name. |
content.overview.partitionTimeUnit |
Partition | Recommended partitioning time unit. For example, DAY means the
recommendation is to have daily partitions on the recommended column. |
content.overview.clusterColumns |
Cluster | Recommended clustering column names. |
- For more information about other fields in the recommender response, see REST Resource:
projects.locations.recommendersrecommendation. - For more information about using the Recommender API, see Using the API - Recommendations.
To view table insights using the REST API, run the following command:
curl -H "Authorization: Bearer $GCLOUD_AUTH_TOKEN" -H "x-goog-user-project: PROJECT_NAME" https://recommender.googleapis.com/v1/projects/my-project/locations/us/insightTypes/google.bigquery.table.StatsInsight/insights
Replace the following:
GCLOUD_AUTH_TOKEN: the name of a valid gcloud CLI access tokenPROJECT_NAME: the name of the project containing your BigQuery table
| Property | Relevant for subtype | Description |
|---|---|---|
content.existingPartitionColumn |
Cluster | Existing partitioning column, if any |
content.tableSizeTb |
All | Size of the table in terabytes |
content.bytesReadMonthly |
All | Monthly bytes read from the table |
content.slotMsConsumedMonthly |
All | Monthly slot milliseconds consumed by the workload running on the table |
content.queryJobsCountMonthly |
All | Monthly count of jobs running on the table |
- For more information about other fields in the insights response, see REST Resource:
projects.locations.insightTypes.insights. - For more information about using insights, see Using the API - Insights.
View recommendations with INFORMATION_SCHEMA
You can also view your recommendations and insights using INFORMATION_SCHEMA
views. For example, you can use the INFORMATION_SCHEMA.RECOMMENDATIONS view to
view your top three recommendations based on slots savings, as seen in the
following example:
SELECT
recommender,
target_resources,
LAX_INT64(additional_details.overview.bytesSavedMonthly) / POW(1024, 3) as est_gb_saved_monthly,
LAX_INT64(additional_details.overview.slotMsSavedMonthly) / (1000 * 3600) as slot_hours_saved_monthly,
last_updated_time
FROM
`region-us`.INFORMATION_SCHEMA.RECOMMENDATIONS
WHERE
primary_impact.category = 'COST'
AND
state = 'ACTIVE'
ORDER by
slot_hours_saved_monthly DESC
LIMIT 3;
The result is similar to the following:
+---------------------------------------------------+--------------------------------------------------------------------------------------------------+ | recommender | target_resources | est_gb_saved_monthly | slot_hours_saved_monthly | last_updated_time +---------------------------------------------------+--------------------------------------------------------------------------------------------------+ | google.bigquery.materializedview.Recommender | ["project_resource"] | 140805.38289248943 | 9613.139166666666 | 2024-07-01 13:00:00 | google.bigquery.table.PartitionClusterRecommender | ["table_resource_1"] | 4393.7416711859405 | 56.61476777777777 | 2024-07-01 13:00:00 | google.bigquery.table.PartitionClusterRecommender | ["table_resource_2"] | 3934.07264107652 | 10.499466666666667 | 2024-07-01 13:00:00 +---------------------------------------------------+--------------------------------------------------------------------------------------------------+
For more information, see the following resources:
INFORMATION_SCHEMA.RECOMMENDATIONSviewINFORMATION_SCHEMA.RECOMMENDATIONS_BY_ORGANIZATIONviewINFORMATION_SCHEMA.INSIGHTSview
Apply cluster recommendations
To apply cluster recommendations, do one of the following:
- Apply clusters directly to the original table
- Apply clusters to a copied table
- Apply clusters in a materialized view
Apply clusters directly to the original table
You can apply cluster recommendations directly to an existing BigQuery table. This method is quicker than applying recommendations to a copied table, but it does not preserve a backup table.
Follow these steps to apply a new clustering specification to unpartitioned or partitioned tables.
In the bq tool, update the clustering specification of your table to match the new clustering:
bq update --clustering_fields=CLUSTER_COLUMN DATASET.ORIGINAL_TABLE
Replace the following:
CLUSTER_COLUMN: the column you are clustering on—for example,mycolumnDATASET: the name of the dataset containing the table—for example,mydatasetORIGINAL_TABLE: the name of your original table—for example,mytable
You can also call the
tables.updateortables.patchAPI method to modify the clustering specification.To cluster all rows according to the new clustering specification, run the following
UPDATEstatement:UPDATE DATASET.ORIGINAL_TABLE SET CLUSTER_COLUMN=CLUSTER_COLUMN WHERE true
Apply clusters to a copied table
When you apply cluster recommendations to a BigQuery table, you can first copy the original table and then apply the recommendation to the copied table. This method ensures that your original data is preserved if you need to roll back the change to the clustering configuration.
You can use this method to apply cluster recommendations to both unpartitioned and partitioned tables.
In the Google Cloud console, go to the BigQuery page.
In the query editor, create an empty table with the same metadata (including the clustering specifications) of the original table by using the
LIKEoperator:CREATE TABLE DATASET.COPIED_TABLE LIKE DATASET.ORIGINAL_TABLE
Replace the following:
DATASET: the name of the dataset containing the table—for example,mydatasetCOPIED_TABLE: a name for your copied table—for example,copy_mytableORIGINAL_TABLE: the name of your original table—for example,mytable
In the Google Cloud console, open the Cloud Shell Editor.
In the Cloud Shell Editor, update the clustering specification of the copied table to match the recommended clustering by using the
bq updatecommand:bq update --clustering_fields=CLUSTER_COLUMN DATASET.COPIED_TABLE
Replace
CLUSTER_COLUMNwith the column you are clustering on—for example,mycolumn.You can also call the
tables.updateortables.patchAPI method to modify the clustering specification.In the query editor, retrieve the table schema with the partitioning and clustering configuration of the original table, if any partitioning or clustering exists. You can retrieve the schema by viewing the
INFORMATION_SCHEMA.TABLESview of the original table:SELECT ddl FROM DATASET.INFORMATION_SCHEMA.TABLES WHERE table_name = 'DATASET.ORIGINAL_TABLE;'
The output is the full data definition language (DDL) statement of ORIGINAL_TABLE, including the
PARTITION BYclause. For more information about the arguments in your DDL output, seeCREATE TABLEstatement.The DDL output indicates the type of partitioning in the original table:
Partitioning type Output example Not partitioned The PARTITION BYclause is absent.Partitioned by table column PARTITION BY c0PARTITION BY DATE(c0)PARTITION BY DATETIME_TRUNC(c0, MONTH)Partitioned by ingestion time PARTITION BY _PARTITIONDATEPARTITION BY DATETIME_TRUNC(_PARTITIONTIME, MONTH)Ingest data into the copied table. The process that you use is based on the partition type.
- If the original table is non-partitioned or partitioned by a table column,
ingest the data from the original table to the copied table:
INSERT INTO DATASET.COPIED_TABLE SELECT * FROM DATASET.ORIGINAL_TABLE
If the original table is partitioned by ingestion time, follow these steps:
Retrieve the list of columns to form the data ingestion expression by using the
INFORMATION_SCHEMA.COLUMNSview:SELECT ARRAY_TO_STRING(( SELECT ARRAY( SELECT column_name FROM DATASET.INFORMATION_SCHEMA.COLUMNS WHERE table_name = 'ORIGINAL_TABLE')), ", ")
The output is a comma-separated list of column names.
Ingest the data from the original table to the copied table:
INSERT DATASET.COPIED_TABLE (COLUMN_NAMES, _PARTITIONTIME) SELECT *, _PARTITIONTIME FROM DATASET.ORIGINAL_TABLE
Replace
COLUMN_NAMESwith the list of columns that was the output in the preceding step, separated by commas—for example,col1, col2, col3.
You now have a clustered copied table with the same data as the original table. In the next steps, you replace your original table with a newly clustered table.
- If the original table is non-partitioned or partitioned by a table column,
ingest the data from the original table to the copied table:
Rename the original table to a backup table:
ALTER TABLE DATASET.ORIGINAL_TABLE RENAME TO DATASET.BACKUP_TABLE
Replace
BACKUP_TABLEwith a name for your backup table—for example,backup_mytable.Rename the copied table to the original table:
ALTER TABLE DATASET.COPIED_TABLE RENAME TO DATASET.ORIGINAL_TABLE
Your original table is now clustered according to the cluster recommendation.
- Access and permissions, such as IAM permissions, row-level access, or column-level access.
- Table artifacts such as table clones, table snapshots, or search indexes.
- The status of any ongoing table processes, such as any materialized views or any jobs that ran when you copied the table.
- The ability to access historical table data using time travel.
- Any metadata associated with the original table—for example,
table_option_listorcolumn_option_list. For more information, see Data definition language statements.
If any issues arise, you must manually migrate the affected artifacts to the new table.
After reviewing the clustered table, you can optionally delete the backup table with the following command:DROP TABLE DATASET.BACKUP_TABLE
Apply clusters in a materialized view
You can create a materialized view of the table to store data from the original table with the recommendation applied. Using materialized views to apply recommendations ensures that the clustered data is kept up to date using automatic refreshes. There are pricing considerations when you query, maintain, and store materialized views. To learn how to create a clustered materialized view, see Clustered materialized views.Apply partition recommendations
To apply partition recommendations, you must apply it to a copy of the original table. BigQuery does not support the changing of a partitioning scheme of a table in place, such as changing an unpartitioned table to a partitioned table, changing the partitioning scheme of a table, or creating a materialized view with a different partitioning scheme from the base table. You can only change the partitioning of a table on a copy of the table.
Apply partition recommendations to a copied table
When you apply partition recommendations to a BigQuery table, you must first copy the original table and then apply the recommendation to the copied table. This approach ensures that your original data is preserved if you need to roll back a partition.
The following procedure uses an example recommendation to partition a table by
the partition time unit DAY.
Create a copied table using the partition recommendations:
CREATE TABLE DATASET.COPIED_TABLE PARTITION BY DATE_TRUNC(PARTITION_COLUMN, DAY) AS SELECT * FROM DATASET.ORIGINAL_TABLE
Replace the following:
DATASET: the name of the dataset containing the table—for example,mydatasetCOPIED_TABLE: a name for your copied table—for example,copy_mytablePARTITION_COLUMN: the column you are partitioning on—for example,mycolumn
For more information about creating partitioned tables, see Creating partitioned tables.
Rename the original table to a backup table:
ALTER TABLE DATASET.ORIGINAL_TABLE RENAME TO DATASET.BACKUP_TABLE
Replace
BACKUP_TABLEwith a name for your backup table—for example,backup_mytable.Rename the copied table to the original table:
ALTER TABLE DATASET.COPIED_TABLE RENAME TO DATASET.ORIGINAL_TABLE
Your original table is now partitioned according to the partition recommendation.
- Access and permissions, such as IAM permissions, row-level access, or column-level access.
- Table artifacts such as table clones, table snapshots, or search indexes.
- The status of any ongoing table processes, such as any materialized views or any jobs that ran when you copied the table.
- The ability to access historical table data using time travel.
- Any metadata associated with the original table—for example,
table_option_listorcolumn_option_list. For more information, see Data definition language statements. - Ability to use legacy SQL to write query results into partitioned tables. The use of legacy SQL is not fully supported in partitioned tables. One solution is to migrate your legacy SQL workflows into GoogleSQL before applying a partition recommendation.
If any issues arise, you must manually migrate the affected artifacts to the new table.
After reviewing the partitioned table, you can optionally delete the backup table with the following command:DROP TABLE DATASET.BACKUP_TABLE
Pricing
When you apply a recommendation to a table, you can incur the following costs:
- Processing costs. When you apply a recommendation, you execute a data definition language (DDL) or data manipulation language (DML) query to your BigQuery project.
- Storage costs. If you use the method of copying a table, you use extra storage for the copied (or backup) table.
Standard processing and storage charges apply depending on the billing account that's associated with the project. For more information, see BigQuery pricing.
Troubleshooting
Issue: No recommendations appear for a specific table.
Partition recommendations might not appear for tables that meet these criteria:
- The table is less than 100GB.
- The table is already partitioned or clustered.
Cluster recommendations might not appear for tables that meet these criteria:
- The table is less than 10GB.
- The table is already clustered.
Both partition and cluster recommendations might be suppressed when:
- The table has a high write cost from data manipulation language (DML) operations.
- The table was not read in the past 30 days.
- The estimated monthly savings is too insignificant (less than 1 slot hour of savings).