Faça a gestão das recomendações de partições e clusters
Este documento descreve como funciona o recomendador de partições e clusters, como ver as suas recomendações e estatísticas, e como pode aplicar recomendações de partições e clusters.
Como funciona o motor de recomendações
O recomendador de particionamento e clustering do BigQuery gera recomendações de partição ou cluster para otimizar as tabelas do BigQuery. O recomendador analisa os fluxos de trabalho nas suas tabelas do BigQuery e oferece recomendações para otimizar melhor os fluxos de trabalho e os custos das consultas através da partição de tabelas ou da agrupamento de tabelas.
Para mais informações sobre o serviço Recommender, consulte a vista geral do Recommender.
O recomendador de particionamento e agrupamento usa os dados de execução da carga de trabalho do projeto dos últimos 30 dias para analisar cada tabela do BigQuery em busca de configurações de particionamento e agrupamento subótimas. O recomendador também usa a aprendizagem automática para prever o quanto a execução da carga de trabalho pode ser otimizada com diferentes configurações de particionamento ou agrupamento. Se o recomendador determinar que a partição ou a agrupamento de uma tabela gera poupanças significativas, o recomendador gera uma recomendação. O recomendador de particionamento e agrupamento gera os seguintes tipos de recomendações:
| Tipo de tabela existente | Subtipo de recomendação | Exemplo de recomendação |
|---|---|---|
| Não particionada, não agrupada | Partição | "Poupe cerca de 64 horas de disponibilidade por mês ao fazer a partição na coluna_C por DIA" |
| Não particionada, não agrupada | Cluster | "Poupe cerca de 64 horas de disponibilidade por mês agrupando por column_C" |
| Particionada, não agrupada | Cluster | "Poupe cerca de 64 horas de disponibilidade por mês agrupando por column_C" |
Cada recomendação é composta por três partes:
- Orientações para particionar ou agrupar uma tabela específica
- A coluna específica numa tabela para particionar ou agrupar
- Poupanças mensais estimadas com a aplicação da recomendação
Para calcular a potencial poupança de carga de trabalho, o recomendador pressupõe que os dados do histórico da carga de trabalho de execução dos últimos 30 dias representam a carga de trabalho futura.
A API Recommender também devolve informações sobre a carga de trabalho da tabela sob a forma de estatísticas. As estatísticas são conclusões que ajudam a compreender a carga de trabalho do seu projeto, fornecendo mais contexto sobre como uma partição ou uma recomendação de cluster pode melhorar os custos da carga de trabalho.
Limitações
O recomendador de particionamento e clustering não suporta tabelas do BigQuery com SQL antigo. Quando gera uma recomendação, o motor de recomendações exclui todas as consultas SQL antigas na respetiva análise. Além disso, a aplicação de recomendações de partições em tabelas do BigQuery com SQL antigo interrompe todos os fluxos de trabalho de SQL antigo nessa tabela.
Antes de aplicar recomendações de partições, migre os fluxos de trabalho SQL antigos para o GoogleSQL.
O BigQuery não suporta a alteração do esquema de particionamento de uma tabela no local. Só pode alterar a partição de uma tabela numa cópia da tabela. Para mais informações, consulte o artigo Aplique recomendações de partição.
Localizações
O recomendador de particionamento e agrupamento está disponível nas seguintes localizações de processamento:
| Descrição da região | Nome da região | Detalhes | |
|---|---|---|---|
| Ásia-Pacífico | |||
| Deli | asia-south2 |
||
| Hong Kong | asia-east2 |
||
| Jacarta | asia-southeast2 |
||
| Mumbai | asia-south1 |
||
| Osaca | asia-northeast2 |
||
| Seul | asia-northeast3 |
||
| Singapura | asia-southeast1 |
||
| Sydney | australia-southeast1 |
||
| Taiwan | asia-east1 |
||
| Tóquio | asia-northeast1 |
||
| Europa | |||
| Bélgica | europe-west1 |
|
|
| Berlim | europe-west10 |
||
| Multirregional da UE | eu |
||
| Frankfurt | europe-west3 |
||
| Londres | europe-west2 |
|
|
| Países Baixos | europe-west4 |
|
|
| Zurique | europe-west6 |
|
|
| Americas | |||
| Iowa | us-central1 |
|
|
| Las Vegas | us-west4 |
||
| Los Angeles | us-west2 |
||
| Montréal | northamerica-northeast1 |
|
|
| Virgínia do Norte | us-east4 |
||
| Oregon | us-west1 |
|
|
| Salt Lake City | us-west3 |
||
| São Paulo | southamerica-east1 |
|
|
| Toronto | northamerica-northeast2 |
|
|
| Multirregião dos EUA | us |
||
Antes de começar
- Certifique-se de que o Gemini no BigQuery está ativado para o seu projeto. Google Cloud
- Ative a API Recommender.
Autorizações necessárias
Para receber as autorizações de que
precisa para aceder às recomendações de partições e clusters,
peça ao seu administrador para lhe conceder a função de IAM
Visualizador do recomendador de clustering e particionamento do BigQuery (roles/recommender.bigqueryPartitionClusterViewer).
Para mais informações sobre a atribuição de funções, consulte o artigo Faça a gestão do acesso a projetos, pastas e organizações.
Esta função predefinida contém as autorizações necessárias para aceder às recomendações de partições e clusters. Para ver as autorizações exatas que são necessárias, expanda a secção Autorizações necessárias:
Autorizações necessárias
São necessárias as seguintes autorizações para aceder às recomendações de partições e clusters:
-
recommender.bigqueryPartitionClusterRecommendations.get -
recommender.bigqueryPartitionClusterRecommendations.list
Também pode conseguir estas autorizações com funções personalizadas ou outras funções predefinidas.
Para mais informações acerca das funções e autorizações do IAM no BigQuery, consulte o artigo Introdução ao IAM.
Ver recomendações
Esta secção descreve como ver as recomendações de partições e clusters, bem como as estatísticas, através da Google Cloud consola, da Google Cloud CLI ou da API Recommender.
Selecione uma das seguintes opções:
Consola
Na Google Cloud consola, aceda à página BigQuery.
No menu de navegação, clique em Recomendações.
O separador Recomendações apresenta todas as recomendações disponíveis para o seu projeto.
No painel Otimize o custo da carga de trabalho do BigQuery, clique em Ver tudo.
A tabela de recomendações de custos apresenta todas as recomendações geradas para o projeto atual. Por exemplo, a captura de ecrã seguinte mostra que o recomendador analisou a tabela
example_tablee, em seguida, recomendou o agrupamento da colunaexample_columnpara guardar uma quantidade aproximada de bytes e espaços.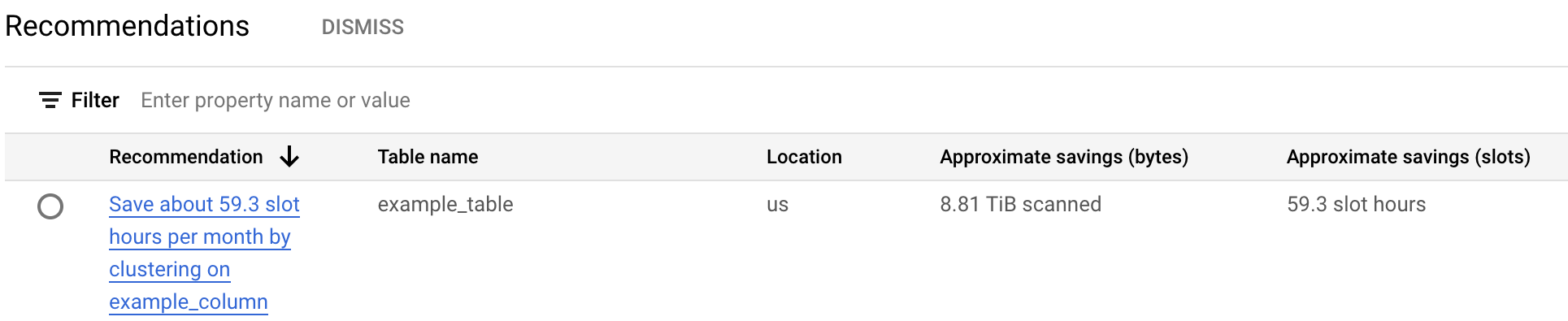
Para ver mais informações sobre a estatística e a recomendação da tabela, clique numa recomendação.
gcloud
Para ver recomendações de partições ou clusters para um projeto específico, use o comando gcloud recommender recommendations list:
gcloud recommender recommendations list \
--project=PROJECT_NAME \
--location=REGION_NAME \
--recommender=google.bigquery.table.PartitionClusterRecommender \
--format=FORMAT_TYPE \
Substitua o seguinte:
PROJECT_NAME: o nome do projeto que contém a sua tabela do BigQueryREGION_NAME: a região em que o seu projeto se encontraFORMAT_TYPE: um formato de saída da CLI gcloud suportado, por exemplo, JSON
| Propriedade | Relevante para o subtipo | Descrição |
|---|---|---|
recommenderSubtype |
Particione ou agrupe | Indica o tipo de recomendação. |
content.overview.partitionColumn |
Partição | Nome da coluna de partição recomendado. |
content.overview.partitionTimeUnit |
Partição | Unidade de tempo de partição recomendada. Por exemplo, DAY significa que a recomendação é ter partições diárias na coluna recomendada. |
content.overview.clusterColumns |
Cluster | Nomes de colunas de agrupamento recomendados. |
- Para mais informações sobre outros campos na resposta do recomendador, consulte o recurso REST:
projects.locations.recommendersrecommendation. - Para mais informações sobre a utilização da API Recommender, consulte o artigo Usar a API – Recomendações.
Para ver as estatísticas das tabelas através da CLI gcloud, use o comando gcloud recommender insights list:
gcloud recommender insights list \
--project=PROJECT_NAME \
--location=REGION_NAME \
--insight-type=google.bigquery.table.StatsInsight \
--format=FORMAT_TYPE \
Substitua o seguinte:
PROJECT_NAME: o nome do projeto que contém a sua tabela do BigQueryREGION_NAME: a região em que o seu projeto se encontraFORMAT_TYPE: um formato de saída da CLI gcloud suportado, por exemplo, JSON
| Propriedade | Relevante para o subtipo | Descrição |
|---|---|---|
content.existingPartitionColumn |
Cluster | Coluna de partição existente, se existir |
content.tableSizeTb |
Tudo | Tamanho da tabela em terabytes |
content.bytesReadMonthly |
Tudo | Bytes lidos mensalmente da tabela |
content.slotMsConsumedMonthly |
Tudo | Milissegundos de espaço mensal consumidos pela carga de trabalho em execução na tabela |
content.queryJobsCountMonthly |
Tudo | Contagem mensal de tarefas em execução na tabela |
- Para mais informações sobre outros campos na resposta de estatísticas, consulte o recurso REST:
projects.locations.insightTypes.insights. - Para mais informações sobre a utilização de estatísticas, consulte o artigo Utilizar a API – Estatísticas.
API REST
Para ver recomendações de partições ou clusters para um projeto específico, use a API REST. Com cada comando, tem de fornecer um token de autenticação, que pode obter através da CLI gcloud. Para mais informações sobre como obter um token de autenticação, consulte Métodos para obter um token de ID.
Pode usar o pedido curl list para ver todas as recomendações de um projeto específico:
curl
-H "Authorization: Bearer $GCLOUD_AUTH_TOKEN"
-H "x-goog-user-project: PROJECT_NAME" https://recommender.googleapis.com/v1/projects/my-project/locations/us/recommenders/google.bigquery.table.PartitionClusterRecommender/recommendations
Substitua o seguinte:
GCLOUD_AUTH_TOKEN: o nome de um token de acesso da CLI gcloud válidoPROJECT_NAME: o nome do projeto que contém a sua tabela do BigQuery
| Propriedade | Relevante para o subtipo | Descrição |
|---|---|---|
recommenderSubtype |
Particione ou agrupe | Indica o tipo de recomendação. |
content.overview.partitionColumn |
Partição | Nome da coluna de partição recomendado. |
content.overview.partitionTimeUnit |
Partição | Unidade de tempo de partição recomendada. Por exemplo, DAY significa que a recomendação é ter partições diárias na coluna recomendada. |
content.overview.clusterColumns |
Cluster | Nomes de colunas de agrupamento recomendados. |
- Para mais informações sobre outros campos na resposta do recomendador, consulte o recurso REST:
projects.locations.recommendersrecommendation. - Para mais informações sobre a utilização da API Recommender, consulte o artigo Usar a API – Recomendações.
Para ver as estatísticas das tabelas através da API REST, execute o seguinte comando:
curl -H "Authorization: Bearer $GCLOUD_AUTH_TOKEN" -H "x-goog-user-project: PROJECT_NAME" https://recommender.googleapis.com/v1/projects/my-project/locations/us/insightTypes/google.bigquery.table.StatsInsight/insights
Substitua o seguinte:
GCLOUD_AUTH_TOKEN: o nome de um token de acesso da CLI gcloud válidoPROJECT_NAME: o nome do projeto que contém a sua tabela do BigQuery
| Propriedade | Relevante para o subtipo | Descrição |
|---|---|---|
content.existingPartitionColumn |
Cluster | Coluna de partição existente, se existir |
content.tableSizeTb |
Tudo | Tamanho da tabela em terabytes |
content.bytesReadMonthly |
Tudo | Bytes lidos mensalmente da tabela |
content.slotMsConsumedMonthly |
Tudo | Milissegundos de espaço mensal consumidos pela carga de trabalho em execução na tabela |
content.queryJobsCountMonthly |
Tudo | Contagem mensal de tarefas em execução na tabela |
- Para mais informações sobre outros campos na resposta de estatísticas, consulte o recurso REST:
projects.locations.insightTypes.insights. - Para mais informações sobre a utilização de estatísticas, consulte o artigo Utilizar a API – Estatísticas.
Ver recomendações com INFORMATION_SCHEMA
Também pode ver as suas recomendações e estatísticas através de INFORMATION_SCHEMAvistas. Por exemplo, pode usar a vista INFORMATION_SCHEMA.RECOMMENDATIONS para ver as três principais recomendações com base nas poupanças de posições, conforme mostrado no exemplo seguinte:
SELECT
recommender,
target_resources,
LAX_INT64(additional_details.overview.bytesSavedMonthly) / POW(1024, 3) as est_gb_saved_monthly,
LAX_INT64(additional_details.overview.slotMsSavedMonthly) / (1000 * 3600) as slot_hours_saved_monthly,
last_updated_time
FROM
`region-us`.INFORMATION_SCHEMA.RECOMMENDATIONS
WHERE
primary_impact.category = 'COST'
AND
state = 'ACTIVE'
ORDER by
slot_hours_saved_monthly DESC
LIMIT 3;
O resultado é semelhante ao seguinte:
+---------------------------------------------------+--------------------------------------------------------------------------------------------------+ | recommender | target_resources | est_gb_saved_monthly | slot_hours_saved_monthly | last_updated_time +---------------------------------------------------+--------------------------------------------------------------------------------------------------+ | google.bigquery.materializedview.Recommender | ["project_resource"] | 140805.38289248943 | 9613.139166666666 | 2024-07-01 13:00:00 | google.bigquery.table.PartitionClusterRecommender | ["table_resource_1"] | 4393.7416711859405 | 56.61476777777777 | 2024-07-01 13:00:00 | google.bigquery.table.PartitionClusterRecommender | ["table_resource_2"] | 3934.07264107652 | 10.499466666666667 | 2024-07-01 13:00:00 +---------------------------------------------------+--------------------------------------------------------------------------------------------------+
Para obter mais informações, consulte os seguintes recursos:
INFORMATION_SCHEMA.RECOMMENDATIONSverINFORMATION_SCHEMA.RECOMMENDATIONS_BY_ORGANIZATIONverINFORMATION_SCHEMA.INSIGHTSver
Aplique recomendações de clusters
Para aplicar recomendações de agrupamentos, efetue uma das seguintes ações:
- Aplique clusters diretamente à tabela original
- Aplique clusters a uma tabela copiada
- Aplique clusters numa vista materializada
Aplique clusters diretamente à tabela original
Pode aplicar recomendações de clusters diretamente a uma tabela do BigQuery existente. Este método é mais rápido do que aplicar recomendações a uma tabela copiada, mas não preserva uma tabela de cópia de segurança.
Siga estes passos para aplicar uma nova especificação de agrupamento a tabelas não particionadas ou particionadas.
Na ferramenta bq, atualize a especificação de clustering da sua tabela para corresponder ao novo clustering:
bq update --clustering_fields=CLUSTER_COLUMN DATASET.ORIGINAL_TABLE
Substitua o seguinte:
CLUSTER_COLUMN: a coluna na qual está a fazer o agrupamento, por exemplo,mycolumnDATASET: o nome do conjunto de dados que contém a tabela, por exemplo,mydatasetORIGINAL_TABLE: o nome da tabela original, por exemplo,mytable
Também pode chamar o método da API
tables.updateoutables.patchpara modificar a especificação de agrupamento.Para agrupar todas as linhas de acordo com a nova especificação de clustering, execute a seguinte declaração
UPDATE:UPDATE DATASET.ORIGINAL_TABLE SET CLUSTER_COLUMN=CLUSTER_COLUMN WHERE true
Aplique clusters a uma tabela copiada
Quando aplica recomendações de clusters a uma tabela do BigQuery, pode primeiro copiar a tabela original e, em seguida, aplicar a recomendação à tabela copiada. Este método garante que os dados originais são preservados se precisar de reverter a alteração à configuração de agrupamento.
Pode usar este método para aplicar recomendações de clusters a tabelas não particionadas e particionadas.
Na Google Cloud consola, aceda à página do BigQuery.
No editor de consultas, crie uma tabela vazia com os mesmos metadados (incluindo as especificações de clustering) da tabela original através do operador
LIKE:CREATE TABLE DATASET.COPIED_TABLE LIKE DATASET.ORIGINAL_TABLE
Substitua o seguinte:
DATASET: o nome do conjunto de dados que contém a tabela, por exemplo,mydatasetCOPIED_TABLE: um nome para a tabela copiada, por exemplo,copy_mytableORIGINAL_TABLE: o nome da tabela original, por exemplo,mytable
Na Google Cloud consola, abra o editor do Cloud Shell.
No editor da Cloud Shell, atualize a especificação de clustering da tabela copiada para corresponder ao clustering recomendado através do comando
bq update:bq update --clustering_fields=CLUSTER_COLUMN DATASET.COPIED_TABLE
Substitua
CLUSTER_COLUMNpela coluna na qual está a fazer o agrupamento, por exemplo,mycolumn.Também pode chamar o método da API
tables.updateoutables.patchpara modificar a especificação de agrupamento.No editor de consultas, obtenha o esquema da tabela com a configuração de particionamento e agrupamento da tabela original, se existir algum particionamento ou agrupamento. Pode obter o esquema através da vista
INFORMATION_SCHEMA.TABLESda tabela original:SELECT ddl FROM DATASET.INFORMATION_SCHEMA.TABLES WHERE table_name = 'DATASET.ORIGINAL_TABLE;'
O resultado é a declaração completa da linguagem de definição de dados (LDD) de ORIGINAL_TABLE, incluindo a cláusula
PARTITION BY. Para mais informações sobre os argumentos na saída DDL, consulte a declaraçãoCREATE TABLE.A saída DDL indica o tipo de particionamento na tabela original:
Tipo de partição Exemplo de saída Não particionada A cláusula PARTITION BYestá ausente.Particionada por coluna da tabela PARTITION BY c0PARTITION BY DATE(c0)PARTITION BY DATETIME_TRUNC(c0, MONTH)Particionada por tempo de ingestão PARTITION BY _PARTITIONDATEPARTITION BY DATETIME_TRUNC(_PARTITIONTIME, MONTH)Carregue dados para a tabela copiada. O processo que usa baseia-se no tipo de partição.
- Se a tabela original não estiver particionada ou estiver particionada por uma coluna da tabela,
carregue os dados da tabela original para a tabela copiada:
INSERT INTO DATASET.COPIED_TABLE SELECT * FROM DATASET.ORIGINAL_TABLE
Se a tabela original estiver particionada por tempo de ingestão, siga estes passos:
Recupere a lista de colunas para formar a expressão de carregamento de dados através da
INFORMATION_SCHEMA.COLUMNSvista:SELECT ARRAY_TO_STRING(( SELECT ARRAY( SELECT column_name FROM DATASET.INFORMATION_SCHEMA.COLUMNS WHERE table_name = 'ORIGINAL_TABLE')), ", ")
O resultado é uma lista de nomes de colunas separados por vírgulas.
Introduza os dados da tabela original na tabela copiada:
INSERT DATASET.COPIED_TABLE (COLUMN_NAMES, _PARTITIONTIME) SELECT *, _PARTITIONTIME FROM DATASET.ORIGINAL_TABLE
Substitua
COLUMN_NAMESpela lista de colunas que foi o resultado no passo anterior, separadas por vírgulas. Por exemplo,col1, col2, col3.
Agora, tem uma tabela copiada agrupada com os mesmos dados da tabela original. Nos passos seguintes, substitui a tabela original por uma tabela recém-agrupada.
- Se a tabela original não estiver particionada ou estiver particionada por uma coluna da tabela,
carregue os dados da tabela original para a tabela copiada:
Mude o nome da tabela original para uma tabela de cópia de segurança:
ALTER TABLE DATASET.ORIGINAL_TABLE RENAME TO DATASET.BACKUP_TABLE
Substitua
BACKUP_TABLEpor um nome para a tabela de cópia de segurança, por exemplo,backup_mytable.Mude o nome da tabela copiada para o nome da tabela original:
ALTER TABLE DATASET.COPIED_TABLE RENAME TO DATASET.ORIGINAL_TABLE
A sua tabela original está agora agrupada de acordo com a recomendação de agrupamento.
- Acesso e autorizações, como autorizações da IAM, acesso ao nível da linha ou acesso ao nível da coluna.
- Artefactos de tabelas, como clones de tabelas, capturas instantâneas de tabelas ou índices de pesquisa.
- O estado de todos os processos de tabelas em curso, como vistas materializadas ou tarefas executadas quando copiou a tabela.
- A capacidade de aceder aos dados do histórico das tabelas através da viagem no tempo.
- Quaisquer metadados associados à tabela original, por exemplo,
table_option_listoucolumn_option_list. Para mais informações, consulte o artigo Declarações de linguagem de definição de dados.
Se surgirem problemas, tem de migrar manualmente os artefactos afetados para a nova tabela.
Depois de rever a tabela agrupada, pode eliminar opcionalmente a tabela de cópia de segurança com o seguinte comando:DROP TABLE DATASET.BACKUP_TABLE
Aplique clusters numa vista materializada
Pode criar uma vista materializada da tabela para armazenar dados da tabela original com a recomendação aplicada. A utilização de vistas materializadas para aplicar recomendações garante que os dados agrupados são mantidos atualizados através de atualizações automáticas. Existem considerações de preços quando consulta, mantém e armazena vistas materializadas. Para saber como criar uma vista materializada agrupada, consulte o artigo Vistas materializadas agrupadas.Aplique recomendações de partições
Para aplicar recomendações de partições, tem de as aplicar a uma cópia da tabela original. O BigQuery não suporta a alteração de um esquema de partição de uma tabela no local, como alterar uma tabela não particionada para uma tabela particionada, alterar o esquema de partição de uma tabela ou criar uma vista materializada com um esquema de partição diferente da tabela base. Só pode alterar a partição de uma tabela numa cópia da tabela.
Aplique recomendações de partições a uma tabela copiada
Quando aplica recomendações de partições a uma tabela do BigQuery, tem de copiar primeiro a tabela original e, em seguida, aplicar a recomendação à tabela copiada. Esta abordagem garante que os dados originais são preservados se precisar de reverter uma partição.
O procedimento seguinte usa uma recomendação de exemplo para particionar uma tabela pela unidade de tempo de partição DAY.
Crie uma tabela copiada com as recomendações de partições:
CREATE TABLE DATASET.COPIED_TABLE PARTITION BY DATE_TRUNC(PARTITION_COLUMN, DAY) AS SELECT * FROM DATASET.ORIGINAL_TABLE
Substitua o seguinte:
DATASET: o nome do conjunto de dados que contém a tabela, por exemplo,mydatasetCOPIED_TABLE: um nome para a tabela copiada, por exemplo,copy_mytablePARTITION_COLUMN: a coluna na qual está a fazer a partição, por exemplo,mycolumn
Para mais informações sobre a criação de tabelas particionadas, consulte o artigo Criar tabelas particionadas.
Mude o nome da tabela original para uma tabela de cópia de segurança:
ALTER TABLE DATASET.ORIGINAL_TABLE RENAME TO DATASET.BACKUP_TABLE
Substitua
BACKUP_TABLEpor um nome para a tabela de cópia de segurança, por exemplo,backup_mytable.Mude o nome da tabela copiada para o nome da tabela original:
ALTER TABLE DATASET.COPIED_TABLE RENAME TO DATASET.ORIGINAL_TABLE
A sua tabela original está agora particionada de acordo com a recomendação de partição.
- Acesso e autorizações, como autorizações da IAM, acesso ao nível da linha ou acesso ao nível da coluna.
- Artefactos de tabelas, como clones de tabelas, capturas instantâneas de tabelas ou índices de pesquisa.
- O estado de todos os processos de tabelas em curso, como vistas materializadas ou tarefas executadas quando copiou a tabela.
- A capacidade de aceder aos dados do histórico das tabelas através da viagem no tempo.
- Quaisquer metadados associados à tabela original, por exemplo,
table_option_listoucolumn_option_list. Para mais informações, consulte o artigo Declarações de linguagem de definição de dados. - Capacidade de usar o SQL antigo para escrever resultados de consultas em tabelas particionadas. A utilização de SQL antigo não é totalmente suportada em tabelas particionadas. Uma solução é migrar os fluxos de trabalho SQL antigos para o GoogleSQL antes de aplicar uma recomendação de partição.
Se surgirem problemas, tem de migrar manualmente os artefactos afetados para a nova tabela.
Depois de rever a tabela particionada, pode eliminar opcionalmente a tabela de cópia de segurança com o seguinte comando:DROP TABLE DATASET.BACKUP_TABLE
Preços
Quando aplica uma recomendação a uma tabela, pode incorrer nos seguintes custos:
- Custos de processamento. Quando aplica uma recomendação, executa uma consulta de linguagem de definição de dados (LDD) ou linguagem de manipulação de dados (LMD) no seu projeto do BigQuery.
- Custos de armazenamento. Se usar o método de copiar uma tabela, usa armazenamento adicional para a tabela copiada (ou de cópia de segurança).
Aplicam-se as taxas de processamento e armazenamento padrão, consoante a conta de faturação associada ao projeto. Para mais informações, consulte os preços do BigQuery.
Resolução de problemas
Problema: não são apresentadas recomendações para uma tabela específica.
As recomendações de partições podem não aparecer para tabelas que cumpram estes critérios:
- A tabela tem menos de 100 GB.
- A tabela já está particionada ou agrupada.
As recomendações de clusters podem não aparecer para tabelas que cumpram estes critérios:
- A tabela tem menos de 10 GB.
- A tabela já está agrupada.
As recomendações de partição e cluster podem ser suprimidas quando:
- A tabela tem um custo de gravação elevado devido a operações da linguagem de manipulação de dados (DML).
- A tabela não foi lida nos últimos 30 dias.
- As poupanças mensais estimadas são demasiado insignificantes (menos de 1 hora de poupanças).