이 튜토리얼에서는 TensorFlow 모델을 BigQuery ML 데이터 세트로 가져옵니다. 그런 다음 SQL 쿼리를 사용하여 가져온 모델에서 예측을 실행합니다.
데이터 세트 만들기
ML 모델을 저장할 BigQuery 데이터 세트를 만듭니다.
콘솔
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
탐색기 창에서 프로젝트 이름을 클릭합니다.
작업 보기 > 데이터 세트 만들기를 클릭합니다.
데이터 세트 만들기 페이지에서 다음을 수행합니다.
데이터 세트 ID에
bqml_tutorial를 입력합니다.위치 유형에 대해 멀티 리전을 선택한 다음 US(미국 내 여러 리전)를 선택합니다.
나머지 기본 설정은 그대로 두고 데이터 세트 만들기를 클릭합니다.
bq
새 데이터 세트를 만들려면 --location 플래그와 함께 bq mk 명령어를 실행합니다. 사용할 수 있는 전체 파라미터 목록은 bq mk --dataset 명령어 참조를 확인하세요.
데이터 위치가
US로 설정되고 설명이BigQuery ML tutorial dataset인bqml_tutorial데이터 세트를 만듭니다.bq --location=US mk -d \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
--dataset플래그를 사용하는 대신 이 명령어는-d단축키를 사용합니다.-d와--dataset를 생략하면 이 명령어는 기본적으로 데이터 세트를 만듭니다.데이터 세트가 생성되었는지 확인합니다.
bq ls
API
데이터 세트 리소스가 정의된 datasets.insert 메서드를 호출합니다.
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
BigQuery DataFrames
이 샘플을 사용해 보기 전에 BigQuery DataFrames를 사용하여 BigQuery 빠른 시작의 BigQuery DataFrames 설정 안내를 따르세요. 자세한 내용은 BigQuery DataFrames 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 ADC 설정을 참조하세요.
TensorFlow 모델 가져오기
다음 단계에서는 Cloud Storage에서 모델을 가져오는 방법을 보여줍니다.
모델의 경로는 gs://cloud-training-demos/txtclass/export/exporter/1549825580/*입니다. 가져온 모델 이름은 imported_tf_model입니다.
Cloud Storage URI는 와일드 카드 문자(*)로 끝납니다. 이 문자는 BigQuery ML이 모델과 연결된 모든 애셋을 가져와야 함을 나타냅니다.
가져온 모델은 지정된 문서 제목을 게시한 웹사이트를 예측하는 TensorFlow 텍스트 분류 모델입니다.
TensorFlow 모델을 데이터 세트로 가져오려면 다음 단계를 따르세요.
콘솔
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
새로 만들기에서 SQL 쿼리를 클릭합니다.
쿼리 편집기에서 이
CREATE MODEL문을 입력한 후 실행을 클릭합니다.CREATE OR REPLACE MODEL `bqml_tutorial.imported_tf_model` OPTIONS (MODEL_TYPE='TENSORFLOW', MODEL_PATH='gs://cloud-training-demos/txtclass/export/exporter/1549825580/*')
작업이 완료되면
Successfully created model named imported_tf_model과 같은 메시지가 표시됩니다.새 모델이 리소스 패널에 표시됩니다. 모델은 모델 아이콘(
 )으로 표시됩니다.
)으로 표시됩니다.리소스 패널에서 새 모델을 선택하면 모델에 대한 정보가 쿼리 편집기 아래에 표시됩니다.
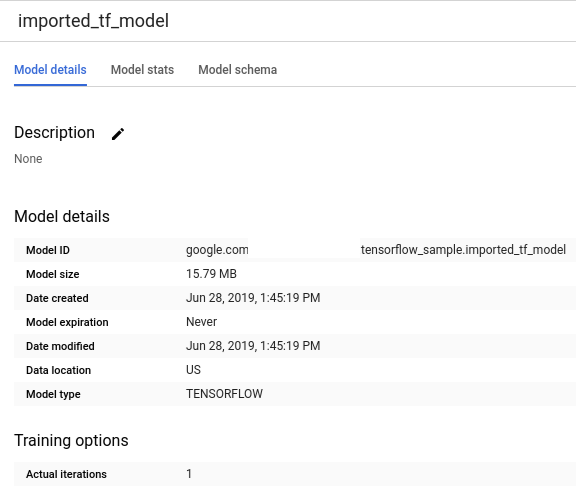
bq
다음
CREATE MODEL문을 입력하여 Cloud Storage에서 TensorFlow 모델을 가져옵니다.bq query --use_legacy_sql=false \ "CREATE OR REPLACE MODEL `bqml_tutorial.imported_tf_model` OPTIONS (MODEL_TYPE='TENSORFLOW', MODEL_PATH='gs://cloud-training-demos/txtclass/export/exporter/1549825580/*')"
모델을 가져온 후 모델이 데이터 세트에 표시되는지 확인합니다.
bq ls -m bqml_tutorial
출력은 다음과 비슷합니다.
tableId Type ------------------- ------- imported_tf_model MODEL
API
새 작업을 삽입하고 jobs#configuration.query 속성을 요청 본문과 같이 입력합니다.
{ "query": "CREATE MODEL `PROJECT_ID:bqml_tutorial.imported_tf_model` OPTIONS(MODEL_TYPE='TENSORFLOW' MODEL_PATH='gs://cloud-training-demos/txtclass/export/exporter/1549825580/*')" }
PROJECT_ID를 프로젝트 및 데이터 세트의 이름으로 바꿉니다.
BigQuery DataFrames
이 샘플을 사용해 보기 전에 BigQuery DataFrames를 사용하여 BigQuery 빠른 시작의 BigQuery DataFrames 설정 안내를 따르세요. 자세한 내용은 BigQuery DataFrames 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 ADC 설정을 참조하세요.
TensorFlowModel 객체를 사용하여 모델을 가져옵니다.
형식 및 스토리지 요구사항을 포함하여 TensorFlow 모델을 BigQuery ML로 가져오는 방법에 대한 자세한 내용은 TensorFlow 모델 가져오기에 사용되는 CREATE MODEL 문을 참조하세요.
가져온 TensorFlow 모델로 예측 수행
TensorFlow 모델을 가져온 후 ML.PREDICT 함수를 사용하여 모델로 예측합니다.
다음 쿼리는 imported_tf_model을 사용하여 공개 데이터 세트 hacker_news의 full 테이블에 있는 입력 데이터를 사용하여 예측합니다. 쿼리에서 TensorFlow 모델의 serving_input_fn 함수는 모델이 input이라는 단일 입력 문자열을 예상하도록 지정합니다. 서브 쿼리는 서브 쿼리의 SELECT 문에 있는 title 열에 별칭 input을 할당합니다.
가져온 TensorFlow 모델로 예측을 수행하려면 다음 단계를 따르세요.
콘솔
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
새로 만들기에서 SQL 쿼리를 클릭합니다.
쿼리 편집기에서
ML.PREDICT함수를 사용하는 쿼리를 입력합니다.SELECT * FROM ML.PREDICT(MODEL `bqml_tutorial.imported_tf_model`, ( SELECT title AS input FROM bigquery-public-data.hacker_news.full ) )
쿼리 결과는 다음과 같습니다.
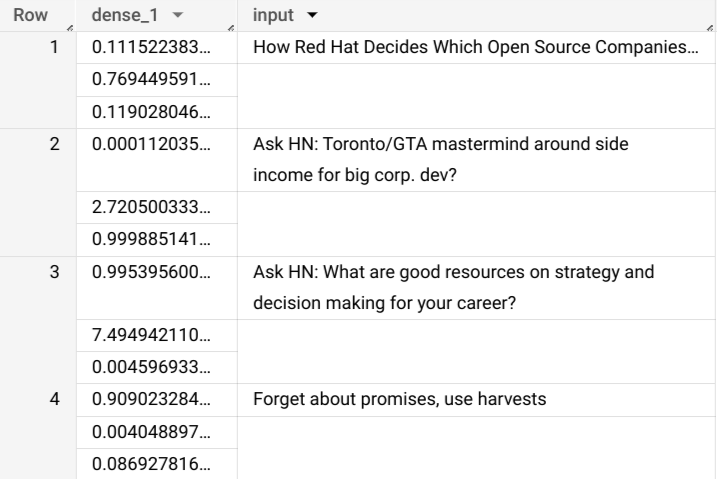
bq
다음 명령어를 입력하여 ML.PREDICT를 사용하는 쿼리를 실행합니다.
bq query \ --use_legacy_sql=false \ 'SELECT * FROM ML.PREDICT( MODEL `bqml_tutorial.imported_tf_model`, (SELECT title AS input FROM `bigquery-public-data.hacker_news.full`))'
다음과 같은 결과가 표시됩니다.
+------------------------------------------------------------------------+----------------------------------------------------------------------------------+ | dense_1 | input | +------------------------------------------------------------------------+----------------------------------------------------------------------------------+ | ["0.6251608729362488","0.2989124357700348","0.07592673599720001"] | How Red Hat Decides Which Open Source Companies t... | | ["0.014276246540248394","0.972910463809967","0.01281337533146143"] | Ask HN: Toronto/GTA mastermind around side income for big corp. dev? | | ["0.9821603298187256","1.8601855117594823E-5","0.01782100833952427"] | Ask HN: What are good resources on strategy and decision making for your career? | | ["0.8611106276512146","0.06648492068052292","0.07240450382232666"] | Forget about promises, use harvests | +------------------------------------------------------------------------+----------------------------------------------------------------------------------+
API
새 작업을 삽입하고 jobs#configuration.query 속성을 요청 본문과 같이 입력합니다. project_id를 프로젝트 이름으로 바꿉니다.
{ "query": "SELECT * FROM ML.PREDICT(MODEL `project_id.bqml_tutorial.imported_tf_model`, (SELECT * FROM input_data))" }
BigQuery DataFrames
이 샘플을 사용해 보기 전에 BigQuery DataFrames를 사용하여 BigQuery 빠른 시작의 BigQuery DataFrames 설정 안내를 따르세요. 자세한 내용은 BigQuery DataFrames 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 ADC 설정을 참조하세요.
predict 함수를 사용하여 TensorFlow 모델을 실행합니다.
다음과 같은 결과가 표시됩니다.
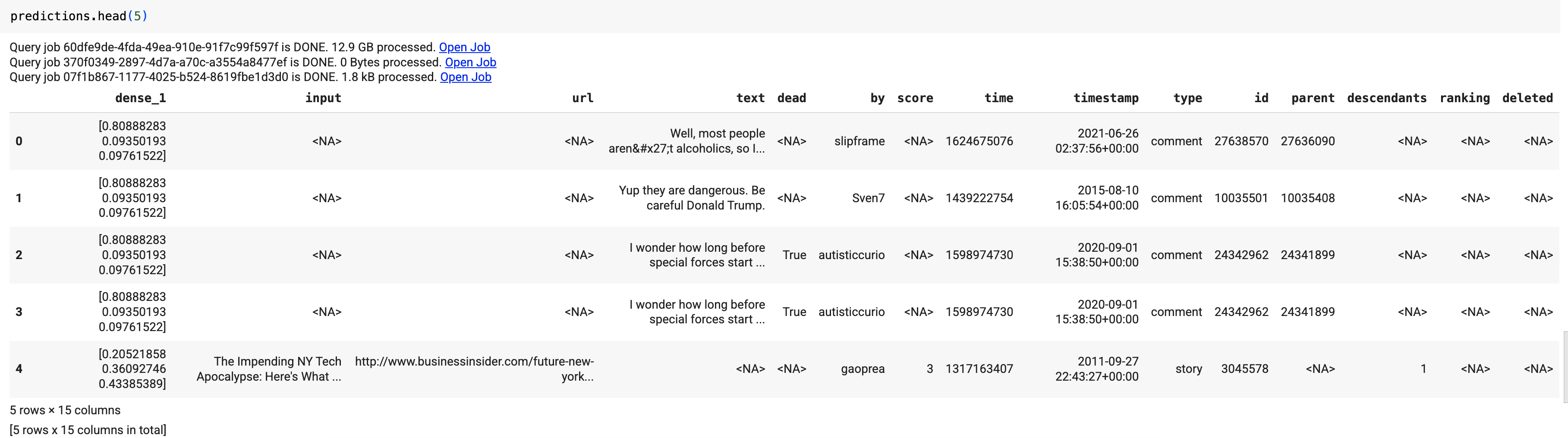
쿼리 결과에서 dense_1 열에는 확률 값 배열이 포함되고 input 열에는 입력 테이블의 해당 문자열 값이 포함됩니다. 각 배열 요소 값은 해당 입력 문자열이 특정 게시의 문서 제목일 가능성을 나타냅니다.