Présentation de l'IA générative
Ce document décrit les fonctionnalités d'intelligence artificielle (IA) générative compatibles avec BigQuery ML. Ces fonctionnalités vous permettent d'effectuer des tâches d'IA dans BigQuery ML à l'aide de modèles Vertex AI pré-entraînés et de modèles BigQuery ML intégrés.
Les tâches suivantes sont acceptées :
- Générer du texte
- Générer des données structurées
- Générer des valeurs d'un type spécifique par ligne
- Générer des embeddings
- Prévoir des séries temporelles
Vous accédez à un modèle Vertex AI pour exécuter l'une de ces fonctions en créant un dans BigQuery ML modèle distant qui représente le point de terminaison du modèle Vertex AI. Une fois que vous avez créé un modèle distant basé sur le modèle Vertex AI que vous souhaitez utiliser, vous accédez aux fonctionnalités de ce modèle en exécutant une fonction BigQuery ML sur le modèle distant.
Cette approche vous permet d'utiliser les fonctionnalités de ces modèles Vertex AI dans des requêtes SQL pour analyser les données BigQuery.
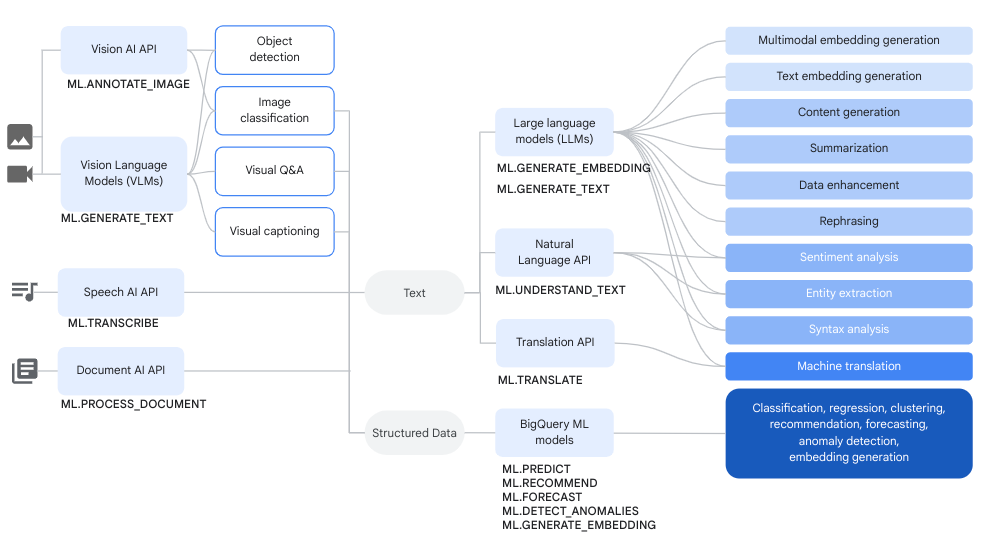
Workflow
Vous pouvez utiliser des modèles distants basés sur des modèles Vertex AI et des modèles distants basés sur des services Cloud AI conjointement avec des fonctions BigQuery ML afin d'effectuer des tâches d'analyse de données et d'IA générative complexes.
Le schéma suivant illustre certains workflows types dans lesquels vous pouvez utiliser ces fonctionnalités conjointement :
Générer du texte
La génération de texte est une forme d'IA générative dans laquelle du texte est généré à partir d'une requête ou d'une analyse de données. Vous pouvez générer du texte à l'aide de données textuelles et multimodales.
Voici quelques cas d'utilisation courants de la génération de texte :
- Génération de contenus créatifs.
- Génération du code.
- Générer des réponses par chat ou par e-mail.
- Brainstorming, par exemple en suggérant des pistes pour de futurs produits ou services.
- Personnalisation du contenu, comme les suggestions de produits.
- Classification des données en appliquant une ou plusieurs étiquettes au contenu pour le trier dans des catégories.
- Identifier les sentiments clés exprimés dans le contenu.
- Résumer les principales idées ou impressions véhiculées par le contenu
- Identifier une ou plusieurs entités importantes dans des données textuelles ou visuelles.
- Traduction du contenu de données textuelles ou audio dans une autre langue.
- Génération de texte correspondant au contenu verbal des données audio.
- Ajouter des sous-titres ou répondre à des questions sur des données visuelles
L'enrichissement des données est une étape courante après la génération de texte. Il consiste à enrichir les insights issus de l'analyse initiale en les combinant avec des données supplémentaires. Par exemple, vous pouvez analyser des images d'ameublement pour générer du texte pour une colonne design_type, afin que le SKU d'ameublement ait une description associée, telle que mid-century modern ou farmhouse.
Modèles compatibles
Pour effectuer des tâches d'IA générative, vous pouvez utiliser des modèles distants dans BigQuery ML pour faire référence à des modèles déployés ou hébergés dans Vertex AI. Vous pouvez créer les types de modèles distants suivants :
- Modèles à distance sur l'un des modèles Gemini disponibles en général ou en preview.
Modèles distants sur les modèles partenaires suivants :
Utiliser des modèles de génération de texte
Après avoir créé un modèle distant, vous pouvez utiliser la fonction ML.GENERATE_TEXT pour interagir avec ce modèle :
Pour les modèles distants basés sur des modèles Gemini, vous pouvez effectuer les opérations suivantes :
Utilisez la fonction
ML.GENERATE_TEXTpour générer du texte à partir d'une invite que vous spécifiez dans une requête ou que vous extrayez d'une colonne d'une table standard. Lorsque vous spécifiez la requête dans une requête, vous pouvez faire référence aux types de colonnes de table suivants dans la requête :- Colonnes
STRINGpour fournir des données textuelles. - Colonnes
STRUCTqui utilisent le formatObjectRefpour fournir des données non structurées. Vous devez utiliser la fonctionOBJ.GET_ACCESS_URLdans la requête pour convertir les valeursObjectRefen valeursObjectRefRuntime.
- Colonnes
Utilisez la fonction
ML.GENERATE_TEXTpour analyser le contenu texte, image, audio, vidéo ou PDF d'une table d'objets avec une requête que vous fournissez en tant qu'argument de fonction.
Pour tous les autres types de modèles distants, vous pouvez utiliser la fonction
ML.GENERATE_TEXTavec une invite que vous fournissez dans une requête ou à partir d'une colonne d'une table standard.
Utilisez les rubriques suivantes pour essayer la génération de texte dans BigQuery ML :
- Générez du texte à l'aide d'un modèle Gemini et de la fonction
ML.GENERATE_TEXT. - Générez du texte à l'aide d'un modèle Gemma et de la fonction
ML.GENERATE_TEXT. - Analyser des images avec un modèle Gemini
- Générez du texte à l'aide de la fonction
ML.GENERATE_TEXTavec vos données. - Réglez un modèle à l'aide de vos données.
Ancrage et attributs de sécurité
Vous pouvez utiliser l'ancrage et les attributs de sécurité lorsque vous utilisez des modèles Gemini avec la fonction ML.GENERATE_TEXT, à condition d'utiliser un tableau standard pour l'entrée. L'ancrage permet au modèle Gemini d'utiliser des informations supplémentaires provenant d'Internet pour générer des réponses plus spécifiques et factuelles. Les attributs de sécurité permettent au modèle Gemini de filtrer les réponses qu'il renvoie en fonction des attributs que vous spécifiez.
Réglage supervisé
Lorsque vous créez un modèle distant faisant référence à l'un des modèles suivants, vous pouvez éventuellement choisir de configurer le réglage supervisé en même temps :
gemini-2.5-progemini-2.5-flash-litegemini-2.0-flash-001gemini-2.0-flash-lite-001
Toutes les inférences s'effectuent dans Vertex AI. Les résultats sont stockés dans BigQuery.
Débit provisionné Vertex AI
Pour les modèles Gemini compatibles, vous pouvez utiliser Vertex AI Provisioned Throughput avec la fonction ML.GENERATE_TEXT pour fournir un débit élevé et cohérent pour les requêtes. Pour en savoir plus, consultez Utiliser le débit provisionné Vertex AI.
Générer des données structurées
La génération de données structurées est très semblable à la génération de texte, sauf que vous pouvez également mettre en forme la réponse du modèle en spécifiant un schéma SQL.
Pour générer des données structurées, créez un modèle distant sur l'un des modèles Gemini disponibles en général ou en preview. Vous pouvez ensuite utiliser la fonction AI.GENERATE_TABLE pour interagir avec ce modèle. Pour essayer de créer des données structurées, consultez Générer des données structurées à l'aide de la fonction AI.GENERATE_TABLE.
Vous pouvez spécifier des attributs de sécurité lorsque vous utilisez des modèles Gemini avec la fonction AI.GENERATE_TABLE afin de filtrer les réponses du modèle.
Générer des valeurs d'un type spécifique par ligne
Vous pouvez utiliser des fonctions d'IA générative scalaire avec les modèles Gemini pour analyser les données dans les tables standards BigQuery. Les données incluent à la fois des données textuelles et des données non structurées provenant de colonnes contenant des valeurs ObjectRef.
Pour chaque ligne du tableau, ces fonctions génèrent une sortie contenant un type spécifique.
Les fonctions d'IA suivantes sont disponibles :
AI.GENERATE, qui génère une valeurSTRINGAI.GENERATE_BOOLAI.GENERATE_DOUBLEAI.GENERATE_INT
Lorsque vous utilisez la fonction AI.GENERATE avec des modèles Gemini compatibles, vous pouvez utiliser Vertex AI Provisioned Throughput pour fournir un débit élevé et cohérent pour les requêtes. Pour en savoir plus, consultez Utiliser le débit provisionné Vertex AI.
Générer des embeddings
Un embedding est un vecteur numérique de grande dimension qui représente une entité donnée, comme un exemple de texte ou un fichier audio. La génération d'embeddings vous permet de capturer la sémantique de vos données de manière à faciliter le raisonnement et la comparaison des données.
Voici quelques cas d'utilisation courants de la génération d'embeddings :
- Utiliser la génération augmentée par récupération (RAG) pour augmenter les réponses du modèle aux requêtes des utilisateurs en référençant des données supplémentaires provenant d'une source fiable. Le RAG offre une meilleure précision factuelle et une meilleure cohérence des réponses. Il permet également d'accéder à des données plus récentes que celles utilisées pour entraîner le modèle.
- Effectuer une recherche multimodale. Par exemple, en utilisant une saisie de texte pour rechercher des images.
- Effectuer une recherche sémantique pour trouver des éléments similaires à des fins de recommandation, de substitution et de déduplication des enregistrements.
- Créer des embeddings à utiliser avec un modèle de k-moyennes pour le clustering.
Modèles compatibles
Les modèles suivants sont acceptés :
Pour créer des embeddings de texte, vous pouvez utiliser les modèles Vertex AI suivants :
gemini-embedding-001(Preview)text-embeddingtext-multilingual-embedding- Modèles ouverts compatibles (Aperçu)
Pour créer des embeddings multimodaux, qui peuvent incorporer du texte, des images et des vidéos dans le même espace sémantique, vous pouvez utiliser le modèle
multimodalembeddingde Vertex AI.Pour créer des embeddings pour des données de variables indépendantes et identiquement distribuées (IID) structurées, vous pouvez utiliser un modèle d'analyse des composants principaux (ACP) BigQuery ML ou un modèle auto-encodeur.
Pour créer des embeddings pour des données utilisateur ou d'éléments, vous pouvez utiliser un modèle de factorisation matricielle BigQuery ML.
Pour obtenir un embedding textuel plus petit, essayez d'utiliser un modèle TensorFlow pré-entraîné tel que NNLM, SWIVEL ou BERT.
Utiliser des modèles de génération d'embeddings
Après avoir créé le modèle, vous pouvez utiliser la fonction ML.GENERATE_EMBEDDING pour interagir avec lui. Pour tous les types de modèles compatibles, ML.GENERATE_EMBEDDING fonctionne avec les données structurées des tables standards. Pour les modèles d'embedding multimodaux, ML.GENERATE_EMBEDDING fonctionne également avec le contenu visuel provenant de colonnes de tables standards contenant des valeurs ObjectRef ou de tables d'objets.
Pour les modèles distants, toutes les inférences ont lieu dans Vertex AI. Pour les autres types de modèles, toutes les inférences ont lieu dans BigQuery. Les résultats sont stockés dans BigQuery.
Utilisez les rubriques suivantes pour essayer la génération de texte dans BigQuery ML :
- Générer des embeddings textuels à l'aide de la fonction
ML.GENERATE_EMBEDDING - Générer des embeddings d'images à l'aide de la fonction
ML.GENERATE_EMBEDDING - Générer des embeddings de vidéo à l'aide de la fonction
ML.GENERATE_EMBEDDING - Générer et rechercher des embeddings multimodaux
- Effectuer une recherche sémantique et une génération augmentée de récupération
Prévision
La prévision est une technique qui vous permet d'analyser les données historiques des séries temporelles afin de réaliser une prédiction éclairée sur les tendances futures. Vous pouvez utiliser le modèle de séries temporelles TimesFM intégré à BigQuery ML (aperçu) pour effectuer des prévisions sans avoir à créer votre propre modèle. Le modèle TimesFM intégré fonctionne avec la fonction AI.FORECAST pour générer des prévisions basées sur vos données.
Emplacements
Les zones géographiques acceptées pour les modèles de génération et d'embedding de texte varient en fonction du type et de la version du modèle que vous utilisez. Pour en savoir plus, consultez Emplacements. Contrairement aux autres modèles d'IA générative, la prise en charge des zones géographiques ne s'applique pas au modèle de série temporelle TimesFM intégré. Le modèle TimesFM est disponible dans toutes les régions compatibles avec BigQuery.
Tarifs
Les ressources de calcul que vous utilisez pour exécuter des requêtes sur des modèles vous sont facturées. Les modèles distants appellent les modèles Vertex AI. Par conséquent, les requêtes envoyées aux modèles distants entraînent également des frais Vertex AI.
Pour en savoir plus, consultez la page Tarifs de BigQuery ML.
Étapes suivantes
- Pour découvrir l'IA et le ML dans BigQuery, consultez la présentation de l'IA et du ML dans BigQuery.
- Pour en savoir plus sur l'exécution d'inférences sur des modèles de machine learning, consultez la page Présentation de l'inférence de modèle.
- Pour en savoir plus sur les instructions et les fonctions SQL compatibles avec les modèles d'IA générative, consultez Parcours utilisateur de bout en bout pour les modèles d'IA générative.