使用变更数据捕获来流式插入表更新
BigQuery 变更数据捕获 (CDC) 通过处理流式插入的更改并将其应用于现有数据来更新 BigQuery 表。此同步通过更新/插入和删除行操作来完成,BigQuery Storage Write API 会实时流式插入这些操作,您应该先熟悉此 API,然后再继续操作。
准备工作
授予为用户提供执行本文档中的每个任务所需权限的 Identity and Access Management (IAM) 角色,并确保您的工作流满足所有前提条件。
所需权限
如需获得使用 Storage Write API 所需的权限,请让您的管理员为您授予 BigQuery Data Editor (roles/bigquery.dataEditor) IAM 角色。如需详细了解如何授予角色,请参阅管理对项目、文件夹和组织的访问权限。
此预定义角色可提供 bigquery.tables.updateData 权限,使用 Storage Write API 需要该权限。
如需详细了解 BigQuery 中的 IAM 角色和权限,请参阅 IAM 简介。
前提条件
如需使用 BigQuery CDC,您的工作流必须满足以下条件:
- 您必须在默认数据流中使用 Storage Write API。
- 您必须使用 protobuf 格式作为注入格式。不支持 Apache Arrow 格式。
- 您必须在 BigQuery 中为目标表声明主键。系统支持最多包含 16 列的复合主键。
- 必须有足够的 BigQuery 计算资源可用于执行 CDC 行操作。请注意,如果 CDC 行修改操作失败,您可能会无意中保留您要删除的数据。如需了解详情,请参阅已删除的数据注意事项。
指定对现有记录的更改
在 BigQuery CDC 中,伪列 _CHANGE_TYPE 表示要针对每行处理的更改类型。如需使用 CDC,请在使用 Storage Write API 流式插入行修改时设置 _CHANGE_TYPE。伪列 _CHANGE_TYPE 仅接受 UPSERT 和 DELETE 值。当 Storage Write API 以这种方式流式传输行修改时,表被视为支持 CDC。
使用 UPSERT 和 DELETE 值的示例
请考虑 BigQuery 中的以下表:
| ID | Name | Salary |
|---|---|---|
| 100 | Charlie | 2000 |
| 101 | Tal | 3000 |
| 102 | Lee | 5000 |
Storage Write API 会流式插入以下行修改:
| ID | Name | Salary | _CHANGE_TYPE |
|---|---|---|---|
| 100 | DELETE | ||
| 101 | Tal | 8000 | UPSERT |
| 105 | Izumi | 6000 | UPSERT |
更新后的表格如下所示:
| ID | Name | Salary |
|---|---|---|
| 101 | Tal | 8000 |
| 102 | Lee | 5000 |
| 105 | Izumi | 6000 |
管理表格过时情况
默认情况下,每次您运行查询时,BigQuery 都会返回最新的结果。为了在查询启用了 CDC 的表时提供最新结果,BigQuery 必须在查询开始之前应用每个流式插入的行修改,以便查询最新版本的表。在查询运行时应用这些行修改会增加查询延迟时间和费用。但是,如果您不需要全新的查询结果,则可以对表设置 max_staleness 选项来降低查询费用和延迟时间。设置此选项后,BigQuery 会在 max_staleness 值定义的时间间隔内至少应用一次行修改,让您可以运行查询,而无需等待应用更新,但代价是一些数据过时。
此行为对于数据新鲜度不是必需的信息中心和报告很有用。它还可以让您更好地控制 BigQuery 应用行修改的频率,从而有助于成本管理。
查询设置了 max_staleness 选项的表
当您查询设置了 max_staleness 选项的表时,BigQuery 会根据 max_staleness 的值以及上次发生应用作业的时间(由表的 upsert_stream_apply_watermark 时间戳表示)返回结果。
请考虑以下示例,其中某个表的 max_staleness 选项设置为 10 分钟,并且最近的应用作业发生在 T20:
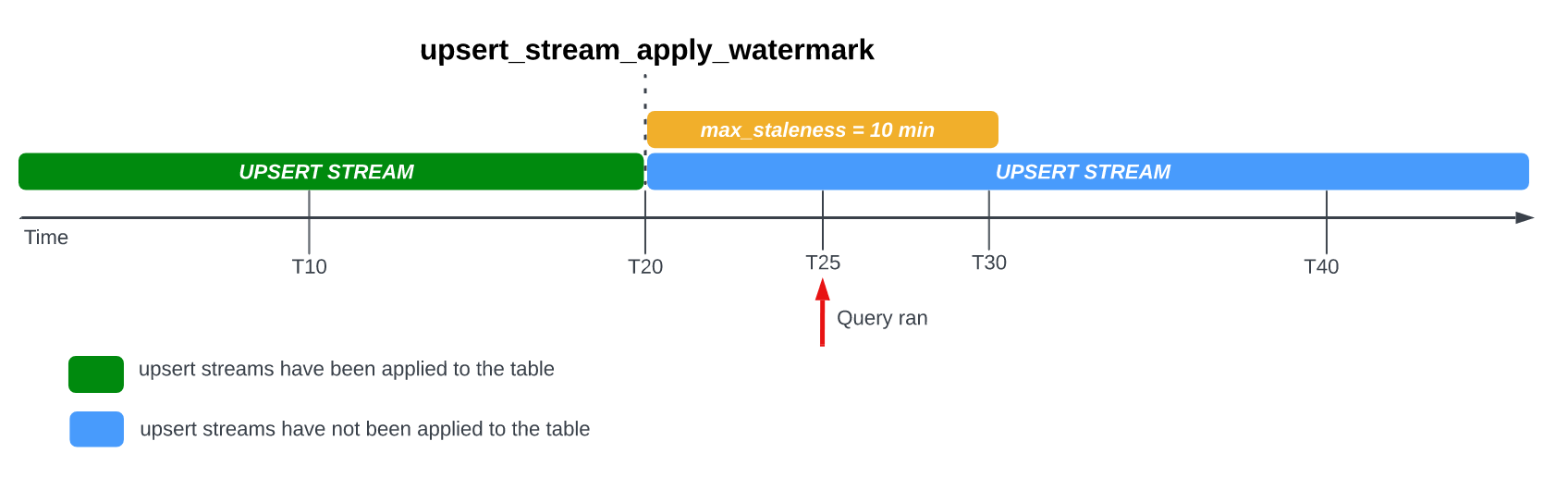
如果您在 T25 查询表,则表的当前版本过时 5 分钟,小于 10 分钟的 max_staleness 时间间隔。在本例中,BigQuery 返回 T20 处的表版本,这意味着返回的数据也过时 5 分钟。
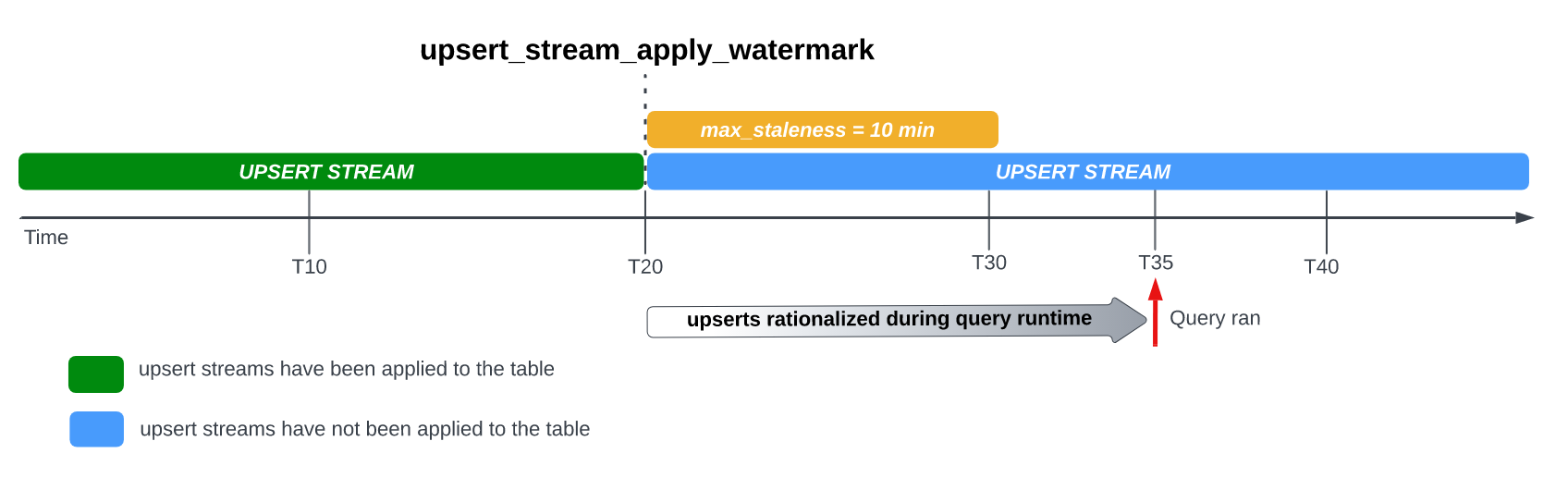
如果您对表设置 max_staleness 选项,BigQuery 会在 max_staleness 时间间隔内至少应用一次待处理的行修改。但是,在某些情况下,BigQuery 可能无法完成在该时间间隔内应用这些待处理的行修改的过程。
例如,如果您在 T35 查询表,并且应用待处理的行修改的过程尚未完成,则表的当前版本过时 15 分钟,该值大于 10 分钟的 max_staleness 时间间隔。在本例中,查询运行时,BigQuery 会针对当前查询应用 T20 和 T35 之间的所有行修改,这意味着查询的数据是完全最新的,但代价是额外增加一些查询延迟时间。此作业被视为运行时合并作业。
建议的表格 max_staleness 值
表格的 max_staleness 值通常应为以下两个值中的较高值:
- 工作流的最大可容忍数据过时。
- 将更新/插入更改应用到表中的最长时间的两倍,再加上一些额外的缓冲时间。
如需计算将更新替换应用到现有表所需的时间,请使用以下 SQL 查询来确定后台应用作业的第 95 个百分位的时长,再加上 7 分钟的缓冲区,以便进行 BigQuery 写入优化存储空间(流式缓冲区)转换。
SELECT project_id, destination_table.dataset_id, destination_table.table_id, APPROX_QUANTILES((TIMESTAMP_DIFF(end_time, creation_time,MILLISECOND)/1000), 100)[OFFSET(95)] AS p95_background_apply_duration_in_seconds, CEILING(APPROX_QUANTILES((TIMESTAMP_DIFF(end_time, creation_time,MILLISECOND)/1000), 100)[OFFSET(95)]*2/60)+7 AS recommended_max_staleness_with_buffer_in_minutes FROM `region-REGION`.INFORMATION_SCHEMA.JOBS AS job WHERE project_id = 'PROJECT_ID' AND DATE(creation_time) BETWEEN DATE_SUB(CURRENT_DATE(), INTERVAL 7 DAY) AND CURRENT_DATE() AND job_id LIKE "%cdc_background%" GROUP BY 1,2,3;
替换以下内容:
REGION:项目所在的区域名称。例如us。PROJECT_ID:包含 BigQuery CDC 所修改的 BigQuery 表的项目的 ID。
后台应用作业的时长受多种因素影响,包括在过期时间间隔内发出的 CDC 操作的数量和复杂性、表大小和 BigQuery 资源可用性。如需详细了解资源可用性,请参阅调整 BACKGROUND 预留的大小并进行监控。
创建使用 max_staleness 选项的表
如需创建使用 max_staleness 选项的表,请使用 CREATE TABLE 语句。以下示例会创建表 employees,并将 max_staleness 限制为 10 分钟:
CREATE TABLE employees ( id INT64 PRIMARY KEY NOT ENFORCED, name STRING) CLUSTER BY id OPTIONS ( max_staleness = INTERVAL 10 MINUTE);
修改现有表的 max_staleness 选项
如需在现有表中添加或修改 max_staleness 限制,请使用 ALTER TABLE 语句。以下示例会将 employees 表的 max_staleness 限制更改为 15 分钟:
ALTER TABLE employees SET OPTIONS ( max_staleness = INTERVAL 15 MINUTE);
确定表的当前 max_staleness 值
如需确定表的当前 max_staleness 值,请查询 INFORMATION_SCHEMA.TABLE_OPTIONS 视图。以下示例会检查表 mytable 的当前 max_staleness 值:
SELECT option_name, option_value FROM DATASET_NAME.INFORMATION_SCHEMA.TABLE_OPTIONS WHERE option_name = 'max_staleness' AND table_name = 'TABLE_NAME';
请替换以下内容:
DATASET_NAME:启用了 CDC 的表所在的数据集的名称。TABLE_NAME:启用了 CDC 的表的名称。
结果显示 max_staleness 值为 10 分钟:
+---------------------+--------------+ | Row | option_name | option_value | +---------------------+--------------+ | 1 | max_staleness | 0-0 0 0:10:0 | +---------------------+--------------+
监控表 upsert 操作进度
如需监控表的状态并检查上次应用行修改的时间,请查询 INFORMATION_SCHEMA.TABLES 视图以获取 upsert_stream_apply_watermark 时间戳。
以下示例会检查表 mytable 的 upsert_stream_apply_watermark 值:
SELECT upsert_stream_apply_watermark FROM DATASET_NAME.INFORMATION_SCHEMA.TABLES WHERE table_name = 'TABLE_NAME';
请替换以下内容:
DATASET_NAME:启用了 CDC 的表所在的数据集的名称。TABLE_NAME:启用了 CDC 的表的名称。
结果类似于以下内容:
[{
"upsert_stream_apply_watermark": "2022-09-15T04:17:19.909Z"
}]
插入/更新操作由 bigquery-adminbot@system.gserviceaccount.com 服务账号执行,并显示在包含启用了 CDC 的表的项目的作业历史记录中。
管理自定义排序
将 upsert 流式传输到 BigQuery 时,使用相同主键对记录进行排序的默认行为取决于将记录提取到 BigQuery 时的 BigQuery 系统时间。换句话说,最近以最新时间戳提取的记录优先于之前以较早时间戳提取的记录。对于某些用例(例如,在非常短的时间窗口内对同一主键进行非常频繁的 upsert 操作,或者无法保证 upsert 顺序),这可能还不够。对于这些场景,可能需要用户提供的排序键。
如需配置用户提供的排序键,请使用伪列 _CHANGE_SEQUENCE_NUMBER 来指明 BigQuery 应根据具有相同主键的两个匹配记录之间的较大 _CHANGE_SEQUENCE_NUMBER 来应用记录的顺序。伪列 _CHANGE_SEQUENCE_NUMBER 是可选列,并且仅接受固定格式 STRING 的值。
_CHANGE_SEQUENCE_NUMBER 格式
伪列 _CHANGE_SEQUENCE_NUMBER 仅接受以固定格式编写的 STRING 值。此固定格式使用以十六进制编写的 STRING 值,并用正斜杠 / 将其分隔成多个部分。每个部分最多可用 16 个十六进制字符表示,每个 _CHANGE_SEQUENCE_NUMBER 最多允许 4 个部分。_CHANGE_SEQUENCE_NUMBER 的允许范围支持介于 0/0/0/0 和 FFFFFFFFFFFFFFFF/FFFFFFFFFFFFFFFF/FFFFFFFFFFFFFFFF/FFFFFFFFFFFFFFFF 之间的值。_CHANGE_SEQUENCE_NUMBER 值支持大写和小写字符。
您可以使用单个部分来表达基本排序键。例如,要仅根据应用服务器的记录处理时间戳排序键,您可以使用一个部分:'2024-04-30 11:19:44 UTC',通过将时间戳转换为自纪元以来的毫秒数来表示十六进制(在本例中为 '18F2EBB6480')。将数据转换为十六进制数据的逻辑由使用 Storage Write API 向 BigQuery 发出写入操作的客户端负责。
支持多个部分可让您将多个处理逻辑值合并到一个键中,以满足更复杂的用例。例如,如需根据应用服务器的记录处理时间戳、日志序列号和记录状态对键进行排序,您可以使用三个部分:'2024-04-30 11:19:44 UTC' / '123' / 'complete',每个部分都以十六进制表示。在对处理逻辑进行排序时,各部分的顺序是一个重要考虑因素。BigQuery 通过比较第一个部分来比较 _CHANGE_SEQUENCE_NUMBER 值,然后仅在前面部分相等的情况下比较下一个部分。
BigQuery 使用 _CHANGE_SEQUENCE_NUMBER 来执行排序,方法是将两个或更多 _CHANGE_SEQUENCE_NUMBER 字段作为无符号数值进行比较。
请考虑以下 _CHANGE_SEQUENCE_NUMBER 比较示例及其优先级结果:
示例 1:
- 记录 #1:
_CHANGE_SEQUENCE_NUMBER= '77' - 记录 2:
_CHANGE_SEQUENCE_NUMBER= '7B'
结果:记录 #2 被视为最新记录,因为 '7B' > '77'(即 '123' > '119')
- 记录 #1:
示例 2:
- 记录 #1:
_CHANGE_SEQUENCE_NUMBER= 'FFF/B' - 记录 #2:
_CHANGE_SEQUENCE_NUMBER= 'FFF/ABC'
结果:记录 #2 被视为最新记录,因为 'FFF/ABC' > 'FFF/B'(即 '4095/2748' > '4095/11')
- 记录 #1:
示例 3:
- 记录 #1:
_CHANGE_SEQUENCE_NUMBER= 'BA/FFFFFFFF' - 记录 #2:
_CHANGE_SEQUENCE_NUMBER= 'ABC'
结果:记录 2 被视为最新记录,因为 'ABC' > 'BA/FFFFFFFF'(即 '2748' > '186/4294967295')
- 记录 #1:
示例 4:
- 记录 #1:
_CHANGE_SEQUENCE_NUMBER= 'FFF/ABC' - 记录 #2:
_CHANGE_SEQUENCE_NUMBER= 'ABC'
结果:记录 1 被视为最新记录,因为 'FFF/ABC' > 'ABC'(即 '4095/2748' > '2748')
- 记录 #1:
如果两个 _CHANGE_SEQUENCE_NUMBER 值相同,则具有最新 BigQuery 系统提取时间的记录优先于之前提取的记录。
对表使用自定义排序时,应始终提供 _CHANGE_SEQUENCE_NUMBER 值。任何未指定 _CHANGE_SEQUENCE_NUMBER 值的写入请求都会导致包含和不包含 _CHANGE_SEQUENCE_NUMBER 值的行混合在一起,从而导致排序不可预测。
配置 BigQuery 预留以用于 CDC
您可以使用 BigQuery 预留为 CDC 行修改操作分配专用的 BigQuery 计算资源。借助预留,您可以设置这些操作的费用上限。此方法对于针对大型表执行频繁 CDC 操作的工作流特别有用,由于执行每个操作时要处理大量字节,因此按需费用较高。
在 max_staleness 时间间隔内应用待处理行修改的 BigQuery CDC 作业会被视为后台作业,并使用 BACKGROUND 分配类型,而不是 QUERY 分配类型。相比之下,超出 max_staleness 时间间隔的需要在查询运行时应用行修改的查询会使用 QUERY 分配类型。未设置 max_staleness 或 max_staleness 设置为 0 的表也会使用 QUERY 分配类型。在没有 BACKGROUND 分配的情况下执行的 BigQuery CDC 后台作业会使用按需价格。在为 BigQuery CDC 设计工作负载管理策略时,此考虑因素非常重要。
如需配置 BigQuery 预留以用于 CDC,请先在 BigQuery 表所在的区域中配置预留。如需查看有关预留大小的指导信息,请参阅调整 BACKGROUND 预留的大小并进行监控。创建预留后,为预留分配 BigQuery 项目,并通过运行以下 CREATE ASSIGNMENT 语句将 job_type 选项设置为 BACKGROUND。
CREATE ASSIGNMENT `ADMIN_PROJECT_ID.region-REGION.RESERVATION_NAME.ASSIGNMENT_ID` OPTIONS ( assignee = 'projects/PROJECT_ID', job_type = 'BACKGROUND');
请替换以下内容:
ADMIN_PROJECT_ID:拥有预留的管理项目的 ID。REGION:项目所在的区域名称。例如us。RESERVATION_NAME:预留的名称。ASSIGNMENT_ID:分配的 ID。此 ID 对项目和位置来说必须是唯一的,以小写字母或数字开头和结尾,并且只能包含小写字母、数字和短划线。PROJECT_ID:包含 BigQuery CDC 所修改的 BigQuery 表的项目的 ID。此项目已分配到预留。
调整 BACKGROUND 预留的大小并进行监控
预留决定了可用于执行 BigQuery 计算操作的计算资源数量。预留大小不足可能会增加 CDC 行修改操作的处理时间。如需准确调整预留大小,请通过查询 INFORMATION_SCHEMA.JOBS_TIMELINE 视图来监控执行 CDC 操作的项目的历史槽用量:
SELECT period_start, SUM(period_slot_ms) / (1000 * 60) AS slots_used FROM region-REGION.INFORMATION_SCHEMA.JOBS_TIMELINE_BY_PROJECT WHERE DATE(job_creation_time) BETWEEN DATE_SUB(CURRENT_DATE(), INTERVAL 7 DAY) AND CURRENT_DATE() AND job_id LIKE '%cdc_background%' GROUP BY period_start ORDER BY period_start DESC;
将 REGION 替换为项目所在的区域名称。例如 us。
已删除的数据注意事项
- BigQuery CDC 操作会使用 BigQuery 计算资源。如果 CDC 操作配置为使用按需结算,则系统会使用内部 BigQuery 资源定期执行 CDC 操作。如果 CDC 操作使用
BACKGROUND预留进行配置,则 CDC 操作将受限于已配置的预留的资源可用性。如果已配置的预留中没有足够的资源,则处理 CDC 操作(包括删除)的时间可能会超出预期。 - 仅当
upsert_stream_apply_watermark时间戳超过 Storage Write API 流式插入操作的时间戳时,才会考虑应用 CDCDELETE操作。 如需详细了解upsert_stream_apply_watermark时间戳,请参阅监控表 upsert 操作进度。 - 为了应用到达顺序不正确的 CDC
DELETE操作,BigQuery 会保留两天的删除保留期。系统会在此时间段内存储表DELETE操作,然后才会开始标准Google Cloud 数据删除流程。在删除保留窗口内执行的DELETE操作会按照标准 BigQuery 存储价格计费。
限制
- BigQuery CDC 不会强制要求使用键,因此主键必须是唯一的。
- 主键不能超过 16 列。
- 启用了 CDC 的表中,由表的架构定义的顶级列不得超过 2,000 个。
- 启用了 CDC 的表不支持以下各项:
- 变更型数据操纵语言 (DML) 语句,例如
DELETE、UPDATE和MERGE - 查询通配符表
- 搜索索引
- 变更型数据操纵语言 (DML) 语句,例如
- 由于表的
max_staleness值过低,执行运行时合并作业的启用了 CDC 的表无法支持以下各项: - BigQuery 对已启用 CDC 的表执行的导出操作不会导出尚未由后台作业应用的最近流式传输的行修改。如需导出完整表格,请使用
EXPORT DATA语句。 - 如果您的查询触发了分区表上的运行时合并,则系统会扫描整个表,无论查询是否仅限于一部分分区。
- 如果您使用的是标准版,则
BACKGROUND预留不可用,因此应用待处理的行修改时使用的是按需价格模式。但是,无论您使用什么版本,都可以查询启用 CDC 的表。 - 执行表读取时,伪列
_CHANGE_TYPE和_CHANGE_SEQUENCE_NUMBER不是可查询的列。 - 不支持在同一连接中将具有
_CHANGE_TYPE的UPSERT或DELETE值的行与具有INSERT或未指定_CHANGE_TYPE值的行混合使用,这会导致以下验证错误:The given value is not a valid CHANGE_TYPE。
BigQuery CDC 价格
BigQuery CDC 使用 Storage Write API 注入数据,使用 BigQuery 存储存储数据,并使用 BigQuery 计算执行行修改操作,所有这些都会产生费用。如需了解价格信息,请参阅 BigQuery 价格。
估算 BigQuery CDC 费用
除了一般的 BigQuery 费用估算最佳实践,估算 BigQuery CDC 的费用对于具有大量数据、低 max_staleness 配置或频繁更改的数据的工作流可能很重要。
BigQuery 数据注入价格和 BigQuery 存储价格直接按您注入和存储的数据量计算,包括伪列。不过,BigQuery 计算价格可能更难估算,因为它与用于运行 BigQuery CDC 作业的计算资源的消耗有关。
BigQuery CDC 作业分为三类:
- 后台应用作业:在后台定期运行的作业,这些作业由表的
max_staleness值定义。这些作业会应用最近流式插入到启用了 CDC 的表的行修改。 - 查询作业:在
max_staleness时段内运行且仅从 CDC 基准表中读取的 GoogleSQL 查询。 - 运行时合并作业:由
max_staleness时段之外运行的临时 GoogleSQL 查询触发的作业。这些作业必须在查询运行时对 CDC 基准表和最近流式插入的行修改执行即时合并。
只有查询作业才会利用 BigQuery 分区。后台应用作业和运行时合并作业不能使用分区,因为在应用最近流式插入的行修改时,无法保证最近流式插入的 upsert 会应用于哪个表分区。换句话说,系统会在后台应用作业和运行时合并作业期间读取完整的基准表。出于同样的原因,只有查询作业才能从 BigQuery 聚簇列的过滤条件中受益。了解执行 CDC 操作要读取的数据量有助于估算总费用。
如果从表基准中读取的数据量很大,请考虑使用 BigQuery 容量价格模式,该模式并非基于处理的数据量。
BigQuery CDC 费用最佳实践
除了一般的 BigQuery 费用最佳实践之外,您还可以使用以下方法优化 BigQuery CDC 操作的费用:
- 除非必要,否则请避免将表的
max_staleness选项配置为非常低的值。max_staleness值可能会增加后台应用作业和运行时合并作业的出现次数,这些作业比查询作业的费用更高且速度更慢。如需获取详细指导,请参阅建议的表max_staleness值。 - 考虑配置 BigQuery 预留以用于 CDC 表。否则,后台应用作业和运行时合并作业使用按需价格,由于数据处理量较多,按需价格的费用可能更高。如需了解详情,请参阅 BigQuery 预留,并按照有关如何调整
BACKGROUND预留的大小并进行监控以用于 BigQuery CDC 的指导操作。
后续步骤
- 了解如何实现 Storage Write API 默认数据流。
- 了解 Storage Write API 的最佳实践。
- 了解如何通过 BigQuery CDC 使用 Datastream 将事务型数据库复制到 BigQuery。