Présentation de l'optimisation des performances des requêtes
Parfois, les requêtes sont plus lentes que vous le souhaitez. En général, les requêtes qui impliquent le moins d'opérations sont plus performantes. Elles s'exécutent plus rapidement et consomment moins de ressources, ce qui peut entraîner des coûts inférieurs et moins d'échecs. Ce document offre un aperçu des techniques d'optimisation permettant d'améliorer les performances des requêtes dans BigQuery.
Performances des requêtes
L'évaluation des performances des requêtes dans BigQuery implique plusieurs facteurs :
- Données d'entrée et sources de données (E/S) : combien d'octets votre requête lit-elle ?
- Communication entre les nœuds (brassage) : combien d'octets votre requête passe-t-elle à l'étape suivante ? Combien d'octets votre requête transmet-elle à chaque emplacement ?
- Calcul : quelle est la capacité du processeur nécessaire pour votre requête ?
- Sorties (matérialisation) : combien d'octets votre requête écrit-elle ?
- Capacité et simultanéité : combien d'emplacements sont disponibles et combien d'autres requêtes sont exécutées simultanément ?
- Schémas de requêtes : vos requêtes suivent-elles les bonnes pratiques relatives aux instructions SQL ?
Pour déterminer si des requêtes spécifiques posent problème ou si vous rencontrez des conflits de ressources, vous pouvez utiliser Cloud Monitoring ou les graphiques de ressources d'administration BigQuery pour surveiller la manière dont vos jobs BigQuery consomment des ressources au fil du temps. Si vous identifiez une requête lente ou exigeante en ressources, vous pouvez concentrer vos optimisations de performances sur cette requête.
Certains modèles de requêtes, en particulier ceux générés par des outils d'informatique décisionnelle, peuvent être accélérés à l'aide de BigQuery BI Engine. BI Engine est un service rapide d'analyse en mémoire qui accélère de nombreuses requêtes SQL dans BigQuery, en assurant une mise en cache intelligente des données que vous utilisez le plus fréquemment. BI Engine est intégré à BigQuery, ce qui vous permet souvent d'obtenir de meilleures performances sans aucune modification de requête.
Comme pour n'importe quel système, l'optimisation des performances implique parfois des compromis. Par exemple, l'utilisation de la syntaxe SQL avancée peut occasionnellement complexifier les requêtes et les rendre moins claires aux yeux des utilisateurs moins expérimentés. En outre, la micro-optimisation de charges de travail non critiques peut également monopoliser vos ressources, vous empêchant ainsi de développer de nouvelles fonctionnalités ou d'optimiser plus efficacement votre infrastructure. Pour vous aider à dégager le meilleur retour sur investissement possible, nous vous recommandons donc de vous concentrer sur l'optimisation des charges de travail les plus importantes pour vos pipelines d'analyse de données.
Capacité et simultanéité
BigQuery propose deux modèles de tarification pour les requêtes : à la demande et en fonction de la capacité. Le modèle à la demande fournit un pool de capacité partagé, et les tarifs dépendent de la quantité de données traitées par chaque requête exécutée.
Le modèle basé sur la capacité est recommandé si vous souhaitez définir le budget des dépenses mensuelles cohérentes ou si vous avez besoin de plus de capacité que celle disponible avec le modèle à la demande. Lorsque vous utilisez la tarification basée sur la capacité, vous allouez une capacité dédiée au traitement de requêtes, qui est mesurée en nombre d'emplacements. Le coût de tous les octets traités est inclus dans le tarif basé sur la capacité. En plus des engagements d'emplacements fixes, vous pouvez utiliser des emplacements d'autoscaling, qui fournissent une capacité dynamique basée sur votre charge de travail de requête.
Lors du traitement des requêtes SQL, BigQuery décompose la capacité de calcul nécessaire pour exécuter chaque étape d'une requête en emplacements. BigQuery détermine automatiquement le nombre de requêtes pouvant s'exécuter simultanément comme suit :
- Modèle à la demande : nombre d'emplacements disponibles dans le projet
- Modèle basé sur la capacité : nombre d'emplacements disponibles dans la réservation
Les requêtes nécessitant plus d'emplacements que ce qui est disponible sont mis en file d'attente jusqu'à ce que les ressources de traitement soient disponibles. Une fois que l'exécution d'une requête commence, BigQuery calcule le nombre d'emplacements utilisés par chaque étape de requête en fonction de la taille et de la complexité de l'étape, ainsi que du nombre d'emplacements disponibles. BigQuery utilise une technique appelée planification équitable pour garantir que chaque requête dispose d'une capacité suffisante pour progresser.
L'accès à un plus grand nombre d'emplacements n'entraîne pas toujours de meilleures performances pour une requête. Une augmentation du nombre d'emplacements peut cependant améliorer les performances pour des requêtes volumineuses ou complexes, ou à l'échelle d'un grand nombre de charges de travail simultanées. Pour améliorer les performances des requêtes, vous pouvez modifier vos réservations d'emplacements ou définir une limite plus élevée pour l'autoscaling des emplacements.
Plan et chronologie de requête
BigQuery génère un plan de requête chaque fois que vous exécutez une requête. Il est essentiel de comprendre ce plan pour une optimisation efficace des requêtes. Le plan de requête inclut des statistiques d'exécution telles que le nombre d'octets lus et le temps d'emplacement consommé. Le plan de requête inclut également des informations sur les différentes étapes d'exécution, ce qui peut vous aider à diagnostiquer et à améliorer les performances des requêtes. Le graphique d'exécution de la requête fournit une interface graphique permettant d'afficher le plan de requête et de diagnostiquer les problèmes de performances des requêtes.
Vous pouvez également utiliser la méthode API jobs.get ou la vue INFORMATION_SCHEMA.JOBS pour récupérer les informations sur le plan et la chronologie des requêtes. Ces informations sont utilisées par BigQuery Visualiser, un outil Open Source qui représente visuellement le déroulement des phases d'exécution d'une tâche BigQuery.
Lorsque BigQuery exécute une tâche de requête, il convertit l'instruction SQL déclarative en un graphe d'exécution. Ce graphe est divisé en une série de phases de requête, elles-mêmes composées d'ensembles d'étapes d'exécution plus précis. BigQuery exploite une architecture parallèle fortement distribuée pour exécuter ces requêtes. Les phases modélisent les unités de travail que de nombreux nœuds de calcul potentiels peuvent exécuter en parallèle. Les phases communiquent entre elles via une architecture de brassage distribuée rapide.
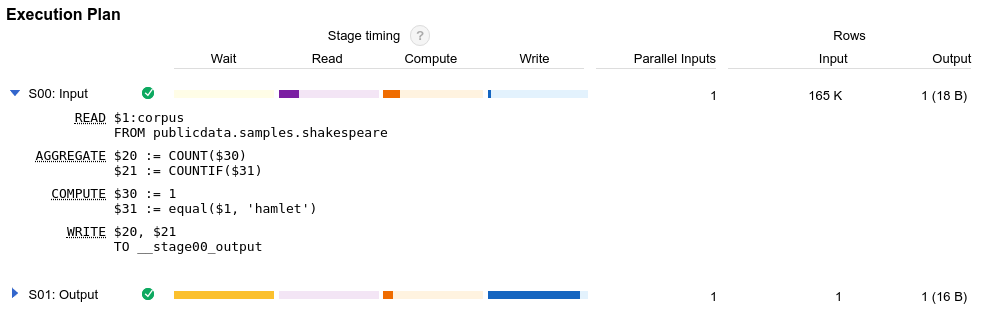
En plus du plan de requête, les tâches de requête présentent également une chronologie d'exécution, qui fournit le compte des unités de travail réalisées, en attente et actives au sein des nœuds de calcul de la requête. Une requête peut comporter simultanément plusieurs phases avec des nœuds de calcul actifs, de sorte que la chronologie permet de montrer la progression globale de la requête.
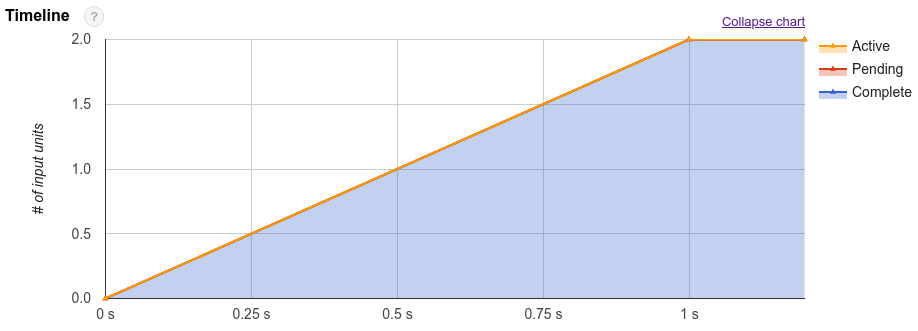
Pour estimer le coût en ressources d'une requête, vous pouvez consulter le nombre de secondes d'emplacement qu'elle utilise. Plus ce nombre est faible, moins une requête est exigeante en ressources, car cela indique que davantage de ressources sont disponibles au même moment pour les autres requêtes du projet.
Les statistiques du plan et de la chronologie de requête peuvent vous aider à comprendre comment BigQuery exécute les requêtes et à savoir si certaines phases utilisent davantage de ressources. Par exemple, une phase JOIN qui génère beaucoup plus de lignes de sortie que de lignes d'entrée peut indiquer la possibilité de filtrer plus tôt dans la requête.
La gestion du service limite toutefois l'exploitation directe de certaines informations. Pour connaître les bonnes pratiques et les techniques permettant d'améliorer l'exécution et les performances des requêtes, consultez la page Optimiser le calcul des requêtes.
Étape suivante
- Découvrez comment résoudre les problèmes d'exécution de requêtes à l'aide des journaux d'audit BigQuery.
- Découvrez d'autres techniques de contrôle des coûts pour BigQuery.
- Affichez les métadonnées en temps quasi réel sur les tâches BigQuery à l'aide de la vue
INFORMATION_SHEMA.JOBS. - Découvrez comment surveiller votre utilisation de BigQuery à l'aide des rapports sur les tables système de BigQuery.