Intégré aux tâches de requête, BigQuery inclut des informations de diagnostic sur le plan et la chronologie de la requête. Ces informations sont similaires à celles fournies par des instructions telles que EXPLAIN dans d'autres systèmes de bases de données et d'analyse. Ces informations peuvent être extraites des réponses d'API de méthodes telles que jobs.get.
BigQuery met régulièrement à jour ces statistiques pour les requêtes de longue durée. Ces mises à jour ont lieu indépendamment de la fréquence d'interrogation de l'état de la tâche. Elles sont généralement effectuées à des intervalles d'au moins 30 secondes. Par ailleurs, les tâches de requête qui n'utilisent pas de ressources d'exécution, telles que les requêtes de simulation ou les résultats pouvant être diffusés à partir de résultats mis en cache, n'incluent pas les informations de diagnostic supplémentaires. Cependant, d'autres statistiques peuvent être incluses.
Arrière-plan
Lorsque BigQuery exécute une tâche de requête, il convertit l'instruction SQL déclarative en un graphe d'exécution divisé en une série de phases de requête. Celles-ci sont composées d'ensembles d'étapes d'exécution plus précis. BigQuery s'appuie sur une architecture parallèle fortement distribuée pour exécuter ces requêtes. Les phases modélisent les unités de travail que de nombreux nœuds de calcul potentiels peuvent exécuter en parallèle. Les étapes communiquent entre elles à l'aide d'une architecture de brassage distribuée rapide.
Dans le plan de requête, les termes unités de travail et nœuds de calcul sont utilisés pour transmettre des informations spécifiques sur le parallélisme. Ailleurs dans BigQuery, vous pouvez rencontrer le terme emplacement, qui est une représentation abstraite des multiples attributs de l'exécution de requêtes, comme les ressources de calcul, de mémoire et d'E/S. Les statistiques d'une tâche de niveau supérieur fournissent une estimation du coût de la requête individuelle en utilisant l'estimation totalSlotMs de la requête à l'aide de cette comptabilité abstraite.
Autre caractéristique importante : l'architecture d'exécution des requêtes est dynamique, ce qui signifie que le plan de requête peut être modifié lorsqu'une requête est en cours d'exécution. Les phases introduites lors de l'exécution d'une requête permettent souvent d'améliorer la distribution des données au sein des nœuds de calcul de la requête. Dans les plans de requête où c'est le cas, ces phases sont généralement libellées en tant que phases de répartition.
En plus du plan de requête, les tâches de requête présentent également une chronologie d'exécution, qui fournit le compte des unités de travail réalisées, en attente et actives au sein des nœuds de calcul de la requête. Une requête peut comporter simultanément plusieurs phases avec des nœuds de calcul actifs, et la chronologie permet de montrer la progression globale de la requête.
Afficher des informations avec la console Google Cloud
Dans la consoleGoogle Cloud , vous pouvez afficher les détails du plan d'une requête terminée en cliquant sur le bouton Détails de l'exécution (près du bouton Résultats).
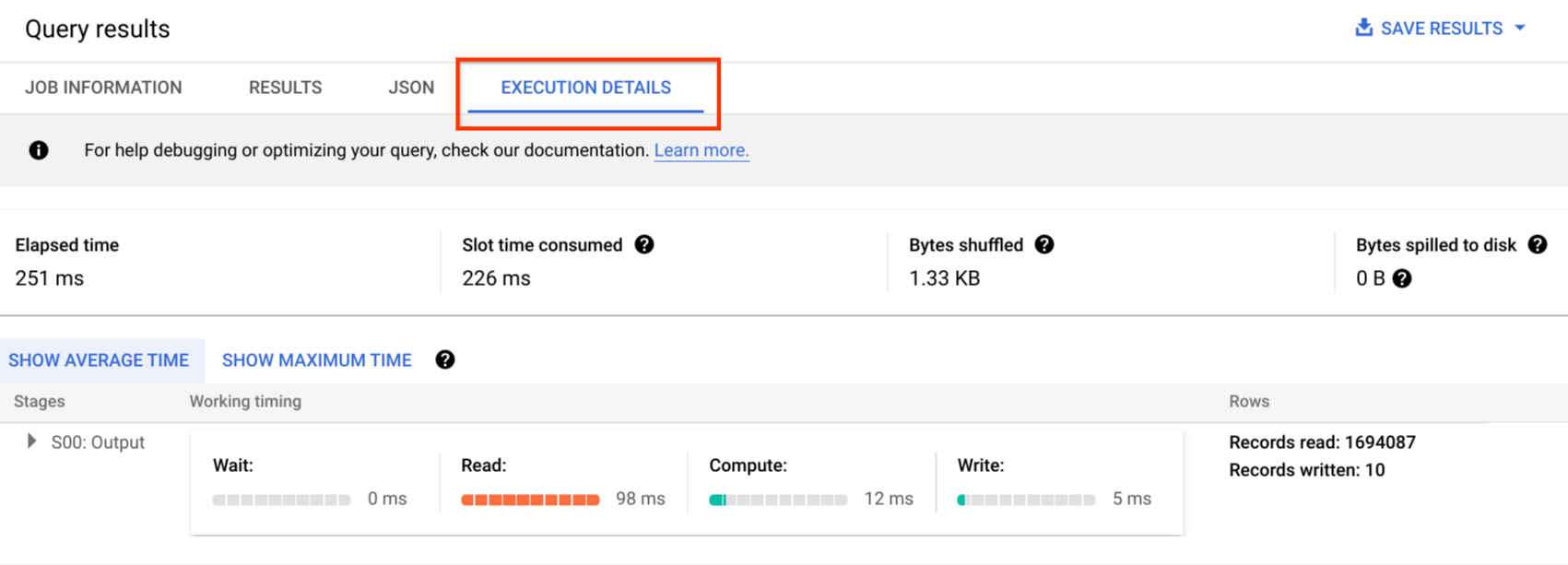
Informations sur le plan de requête
Dans la réponse de l'API, les plans de requête sont représentés sous la forme d'une liste de phases de requête. Chaque élément de la liste affiche des statistiques de présentation par phase, des informations détaillées sur chacune d'elles et une classification de leur durée. Tous les détails ne s'affichent pas dans la console Google Cloud , mais ils peuvent tous être présents dans les réponses de l'API.
Aperçu de la phase
Les champs d'aperçu de chaque phase peuvent inclure les éléments suivants :
| Champ de l'API | Description |
|---|---|
id |
ID numérique unique de la phase. |
name |
Nom simple résumant la phase. Les steps constituant la phase fournissent des informations supplémentaires sur les étapes d'exécution. |
status |
État d'exécution de la phase. Les états possibles incluent PENDING (EN ATTENTE), RUNNING (EN COURS D'EXÉCUTION), COMPLETE (TERMINÉE), FAILED (ÉCHOUÉE) et CANCELLED (ANNULÉE). |
inputStages |
Liste des ID qui forment le graphe de dépendance de la phase. Par exemple, une phase JOIN (jointure) nécessite souvent deux phases dépendantes qui préparent les données à gauche et à droite de la relation JOIN. |
startMs |
Horodatage en millisecondes d'itération qui représente le début de l'exécution du premier nœud de calcul au sein de la phase. |
endMs |
Horodatage en millisecondes d'itération qui représente la fin de l'exécution du dernier nœud de calcul. |
steps |
Liste plus détaillée des étapes d'exécution qui constituent la phase. Consultez la section suivante pour plus d'informations. |
recordsRead |
Taille d'entrée de la phase sous forme de nombre d'enregistrements pour tous les nœuds de calcul de la phase. |
recordsWritten |
Taille de sortie de la phase sous forme de nombre d'enregistrements pour tous les nœuds de calcul de la phase. |
parallelInputs |
Nombre d'unités de travail chargeables en parallèle pour la phase. En fonction de la phase et de la requête, représente le nombre de segments en colonnes dans une table ou le nombre de partitions dans un brassage intermédiaire. |
completedParallelInputs |
Nombre d'unités de travail de la phase qui ont été achevées. Pour certaines requêtes, il n'est pas nécessaire que toutes les entrées d'une phase soient achevées pour que la phase se termine. |
shuffleOutputBytes |
Représente le nombre total d'octets écrits pour tous les nœuds de calcul au sein d'une phase de requête. |
shuffleOutputBytesSpilled |
Les requêtes qui transmettent des données importantes entre les phases peuvent nécessiter un retour vers une transmission sur disque. La statistique d'octets répandus indique la quantité de données répandues sur le disque. Il dépend d'un algorithme d'optimisation. Il n'est donc pas déterministe pour une requête donnée. |
Classification des durées par phase
Les phases de requête fournissent des classifications de durées des phases, sous forme relative et absolue. Chaque phase d'exécution correspondant à un travail effectué par un ou plusieurs nœuds de calcul, ces informations concernent à la fois la durée moyenne et la durée la moins bonne. Ces durées représentent les performances moyennes de tous les nœuds de calcul d'une phase, ainsi que les exécutions des nœuds de calcul les plus lentes pour une classification donnée. Les durées moyennes et maximales sont en outre divisées en représentations absolues et relatives. Pour les statistiques basées sur les ratios, les données sont fournies sous forme de fraction de la durée la plus longue passée par un nœud de calcul dans un segment quelconque.
La console Google Cloud présente la durée des phases à l'aide de représentations temporelles relatives.
Les informations relatives à la durée des phases sont présentées comme suit :
| Durée relative | Durée absolue | Numérateur de taux |
|---|---|---|
waitRatioAvg |
waitMsAvg |
Temps passé par le nœud de calcul moyen à attendre d'être planifié. |
waitRatioMax |
waitMsMax |
Temps passé par le nœud de calcul le plus lent à attendre d'être planifié. |
readRatioAvg |
readMsAvg |
Temps passé par le nœud de calcul moyen à lire les données d'entrée. |
readRatioMax |
readMsMax |
Temps passé par le nœud de calcul le plus lent à lire les données d'entrée. |
computeRatioAvg |
computeMsAvg |
Temps passé par le nœud de calcul moyen à être lié au processeur. |
computeRatioMax |
computeMsMax |
Temps passé par le nœud de calcul le plus lent à être lié au processeur. |
writeRatioAvg |
writeMsAvg |
Temps passé par le nœud de calcul moyen à écrire les données de sortie. |
writeRatioMax |
writeMsMax |
Temps passé par le nœud de calcul le plus lent à écrire les données de sortie. |
Aperçu des étapes
Les étapes contiennent les opérations que chaque nœud de calcul d'une phase exécute. Elles sont présentées sous la forme d'une liste numérotée d'opérations. Chaque opération d'étape est associée à une catégorie, et certaines opérations fournissent des informations plus détaillées. Les catégories d'opérations présentes dans le plan de requête sont les suivantes :
| Catégorie d'étape | Description |
|---|---|
READ |
Lecture d'une ou plusieurs colonnes d'une table d'entrée ou d'un brassage intermédiaire. Seules les seize premières colonnes lues sont renvoyées dans les détails de l'étape. |
WRITE |
Écriture d'une ou plusieurs colonnes dans une table de sortie ou un brassage intermédiaire. Pour les sorties d'une phase partitionnées en HASH, cela inclut également les colonnes servant de clé de partition. |
COMPUTE |
Évaluation des expressions et fonctions SQL. |
FILTER |
Utilisé par les clauses WHERE, OMIT IF et HAVING. |
SORT |
Opération ORDER BY qui inclut les clés de colonne et l'ordre de tri. |
AGGREGATE |
Implémente des agrégations pour des clauses telles que GROUP BY ou COUNT, entre autres. |
LIMIT |
Implémente la clause LIMIT. |
JOIN |
Implémente des jointures pour des clauses telles que JOIN, entre autres. Inclut le type de jointure et éventuellement les conditions de jointure. |
ANALYTIC_FUNCTION |
Invocation d'une fonction de fenêtrage (également appelée "fonction analytique"). |
USER_DEFINED_FUNCTION |
Appel d'une fonction définie par l'utilisateur. |
Comprendre les détails des étapes
BigQuery fournit des détails sur les étapes qui expliquent ce que chaque étape a fait au cours d'une phase. Il est nécessaire de comprendre les étapes d'une phase pour identifier la source des problèmes de performances des requêtes.
Pour trouver les détails d'une étape d'un état, procédez comme suit :
Dans le volet Résultats de la requête, cliquez sur Graphique d'exécution.
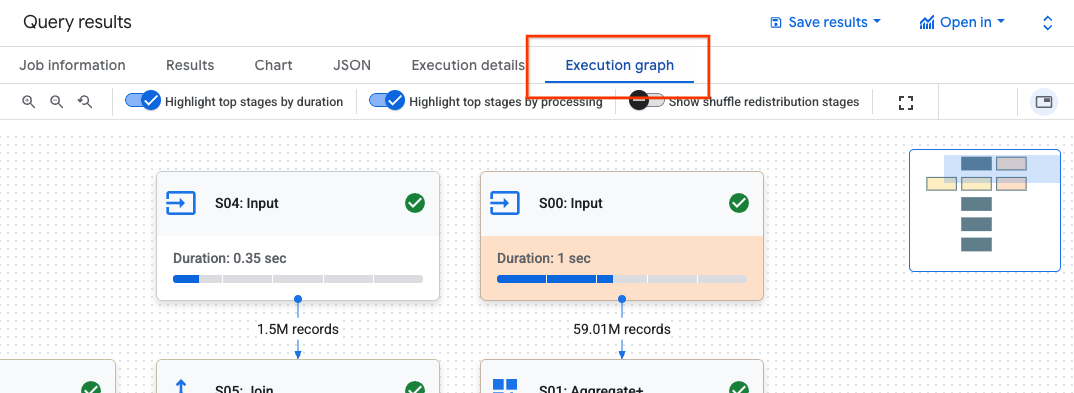
Cliquez sur l'étape qui vous intéresse pour ouvrir un panneau contenant des informations sur l'étape.
Dans le panneau contenant les informations sur l'étape, accédez à la section Détails de l'étape.

Chaque étape se compose de sous-étapes qui décrivent ce qui a été fait. Les sous-étapes utilisent des variables pour décrire les relations entre les étapes. Les variables commencent par un signe dollar suivi d'un numéro unique.
Voici un exemple de détails d'une étape avec des variables partagées entre les étapes :
READ $30:l_orderkey, $31:l_quantity FROM lineitem AGGREGATE GROUP BY $100 := $30 $70 := SUM($31) WRITE $100, $70 TO __stage00_output BY HASH($100)
Les détails de l'étape de l'exemple effectuent les opérations suivantes :
L'étape a lu les colonnes
l_orderkeyetl_quantityde la tablelineitemà l'aide des variables$30et$31, respectivement.Étape agrégée sur les variables
$30et$31, stockant les agrégations dans les variables$100et$70, respectivement.L'étape a écrit les résultats des variables
$100et$70à mélanger. L'étape$100a été utilisée pour ordonner les résultats de l'étape de manière aléatoire.
BigQuery peut tronquer les détails des étapes lorsque le graphique d'exécution de la requête était suffisamment complexe pour que la fourniture de détails complets sur les étapes de la phase entraîne des problèmes de taille de charge utile lors de la récupération des informations sur la requête.
Comprendre les étapes avec le texte de la requête
Pour obtenir de l'aide pendant la version preview, envoyez un e-mail à bq-query-inspector-feedback@google.com.
Il peut être difficile de comprendre le lien entre les étapes et la requête. La section Texte de la requête montre le lien entre certaines étapes et le texte de la requête d'origine.
La section Texte de la requête met en évidence différentes parties du texte de la requête d'origine et affiche les étapes qui correspondent au texte de la requête immédiatement avant le texte de la requête d'origine mis en évidence. Seules les étapes immédiatement au-dessus d'une partie en surbrillance du texte de la requête d'origine s'appliquent au texte de la requête en surbrillance.
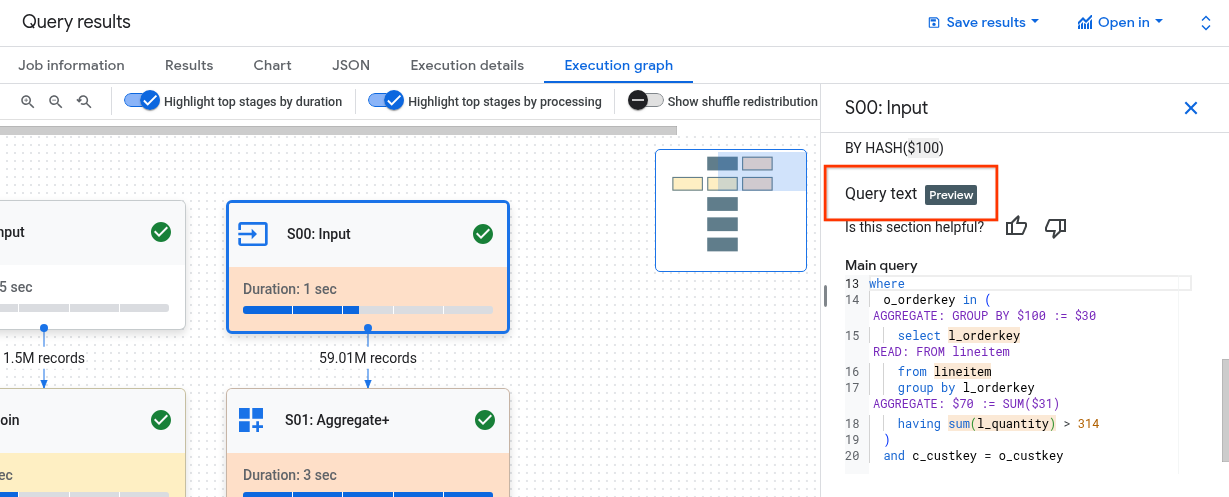
L'exemple de capture d'écran montre les mappages suivants :
L'étape
AGGREGATE: GROUP BY $100 := $30correspond au texte de la requêteselect l_orderkey.L'étape
READ: FROM lineitemcorrespond au texte de la requêteselect ... from lineitem.L'étape
AGGREGATE: $70 := SUM($31)correspond au texte de la requêtesum(l_quantity).
Toutes les étapes ne peuvent pas être mises en correspondance avec le texte de la requête.
Si une requête utilise des vues et que les étapes de la phase sont mappées au texte de requête d'une vue, la section Texte de la requête affiche le nom de la vue et le texte de requête de la vue avec leurs mappages. Toutefois, si la vue est supprimée ou si vous perdez l'autorisation IAM bigquery.tables.get pour la vue, la section Texte de la requête n'affiche pas les mappages des étapes de la vue.
Interpréter et optimiser les étapes
Les sections suivantes expliquent comment interpréter les étapes d'un plan de requête et fournissent des moyens d'optimiser vos requêtes.
READ étape
L'étape READ signifie qu'une étape accède aux données pour les traiter. Les données peuvent être lues directement à partir des tables référencées dans une requête ou à partir de la mémoire de shuffle.
Lorsque des données d'une étape précédente sont lues, BigQuery lit les données à partir de la mémoire de shuffle. La quantité de données analysées a un impact sur les coûts lorsque vous utilisez des emplacements à la demande et sur les performances lorsque vous utilisez des réservations.
Problèmes de performances potentiels
- Analyse volumineuse d'une table non partitionnée : si la requête n'a besoin que d'une petite partie des données, cela peut indiquer qu'une analyse de table est inefficace. Le partitionnement peut être une bonne stratégie d'optimisation.
- Analyse d'une grande table avec un faible ratio de filtre : cela suggère que le filtre ne réduit pas efficacement les données analysées. Envisagez de modifier les conditions de filtre.
- Octets Shuffle déversés sur le disque : cela suggère que les données ne sont pas stockées efficacement à l'aide de techniques d'optimisation telles que le clustering, qui pourrait maintenir des données similaires dans des clusters.
Optimiser
- Filtrage ciblé : utilisez les clauses
WHEREde manière stratégique pour filtrer les données non pertinentes le plus tôt possible dans la requête. Cela réduit la quantité de données devant être traitées par la requête. - Partitionnement et clustering : BigQuery utilise le partitionnement et le clustering des tables pour localiser efficacement des segments de données spécifiques.
Assurez-vous que vos tables sont partitionnées et mises en cluster en fonction de vos modèles de requêtes habituels afin de minimiser les données analysées lors des étapes
READ. - Sélectionnez les colonnes pertinentes : évitez d'utiliser des instructions
SELECT *. Sélectionnez plutôt des colonnes spécifiques ou utilisezSELECT * EXCEPTpour éviter de lire des données inutiles. - Vues matérialisées : les vues matérialisées peuvent précalculer et stocker les agrégations fréquemment utilisées, ce qui peut réduire la nécessité de lire les tables de base lors des étapes
READpour les requêtes qui utilisent ces vues.
COMPUTE étape
À l'étape COMPUTE, BigQuery effectue les actions suivantes sur vos données :
- Évalue les expressions dans les clauses
SELECT,WHERE,HAVINGet autres de la requête, y compris les calculs, les comparaisons et les opérations logiques. - Exécute les fonctions SQL intégrées et les fonctions définies par l'utilisateur.
- Filtre les lignes de données en fonction des conditions de la requête.
Optimiser
Le plan de requête peut révéler des goulots d'étranglement dans l'étape COMPUTE. Recherchez les étapes avec des calculs complexes ou un grand nombre de lignes traitées.
- Corrélez l'étape
COMPUTEavec le volume de données : si une étape présente un calcul important et traite un grand volume de données, elle peut être un bon candidat pour l'optimisation. - Données asymétriques : pour les étapes où le calcul maximal est nettement supérieur au calcul moyen, cela indique que l'étape a passé un temps disproportionné à traiter quelques segments de données. Envisagez d'examiner la distribution des données pour voir s'il y a un décalage.
- Tenez compte des types de données : utilisez les types de données appropriés pour vos colonnes. Par exemple, l'utilisation d'entiers, de valeurs de date et heure et d'horodatages au lieu de chaînes peut améliorer les performances.
WRITE étape
WRITE étapes sont effectuées pour les données intermédiaires et la sortie finale.
- Écriture dans la mémoire de shuffle : dans une requête à plusieurs étapes, l'étape
WRITEimplique souvent l'envoi des données traitées à une autre étape pour un traitement ultérieur. C'est le cas de la mémoire de lecture aléatoire, qui combine ou agrège des données provenant de plusieurs sources. Les données écrites au cours de cette étape sont généralement un résultat intermédiaire, et non la sortie finale. - Résultat final : le résultat de la requête est écrit dans la table de destination ou dans une table temporaire.
Partitionnement par hachage
Lorsqu'une étape du plan de requête écrit des données dans une sortie partitionnée par hachage, BigQuery écrit les colonnes incluses dans la sortie et la colonne choisie comme clé de partitionnement.
Optimiser
Bien que l'étape WRITE elle-même ne soit pas directement optimisée, comprendre son rôle peut vous aider à identifier les éventuels goulots d'étranglement dans les étapes précédentes :
- Minimisez les données écrites : concentrez-vous sur l'optimisation des étapes précédentes avec le filtrage et l'agrégation pour réduire la quantité de données écrites lors de cette étape.
Partitionnement : l'écriture bénéficie grandement du partitionnement des tables. Si les données que vous écrivez sont limitées à des partitions spécifiques, BigQuery peut effectuer des écritures plus rapides.
Si l'instruction LMD comporte une clause
WHEREavec une condition statique par rapport à une colonne de partition de table, BigQuery ne modifie que les partitions de table concernées.Compromis de dénormalisation : la dénormalisation peut parfois entraîner des ensembles de résultats plus petits lors de l'étape intermédiaire
WRITE. Toutefois, il existe des inconvénients, tels qu'une utilisation accrue de l'espace de stockage et des problèmes de cohérence des données.
JOIN étape
À l'étape JOIN, BigQuery combine les données de deux sources de données.
Les jointures peuvent inclure des conditions de jointure. Les jointures sont gourmandes en ressources. Lorsque vous joignez de grandes quantités de données dans BigQuery, les clés de jointure sont brassées indépendamment pour s'aligner sur le même emplacement, de sorte que la jointure est effectuée localement sur chaque emplacement.
Le plan de requête pour l'étape JOIN révèle généralement les informations suivantes :
- Modèle de jointure : indique le type de jointure utilisé. Chaque type définit le nombre de lignes des tables jointes incluses dans l'ensemble de résultats.
- Colonnes de jointure : colonnes utilisées pour faire correspondre les lignes entre les sources de données. Le choix des colonnes est essentiel pour les performances de la jointure.
Modèles de jointure
- Jointure par diffusion : lorsque l'une des tables (généralement la plus petite) peut tenir en mémoire sur un seul nœud de calcul ou emplacement, BigQuery peut la diffuser sur tous les autres nœuds pour effectuer la jointure de manière efficace. Recherchez
JOIN EACH WITH ALLdans les détails de l'étape. - Jointure par hachage : une jointure par hachage peut être utilisée lorsque les tables sont volumineuses ou qu'une jointure de diffusion ne convient pas. BigQuery utilise des opérations de hachage et de réorganisation pour réorganiser les tables de gauche et de droite afin que les clés correspondantes se retrouvent dans le même emplacement pour effectuer une jointure locale. Les jointures par hachage sont une opération coûteuse, car les données doivent être déplacées. Toutefois, elles permettent une mise en correspondance efficace des lignes entre les hachages. Recherchez
JOIN EACH WITH EACHdans les détails de l'étape. - Autojointure : antipattern SQL dans lequel une table est jointe à elle-même.
- Jointure croisée : antipattern SQL qui peut entraîner des problèmes de performances importants, car il génère des données de sortie plus volumineuses que les entrées.
- Jointure asymétrique : la distribution des données dans la clé de jointure d'une table est très asymétrique et peut entraîner des problèmes de performances. Recherchez les cas où le temps de calcul maximal est beaucoup plus élevé que le temps de calcul moyen dans le plan de requête. Pour en savoir plus, consultez Jointure à cardinalité élevée et Asymétrie de partition.
Débogage
- Volume de données important : si le plan de requête indique une quantité importante de données traitées lors de l'étape
JOIN, examinez la condition de jointure et les clés de jointure. Envisagez de filtrer les données ou d'utiliser des clés de jointure plus sélectives. - Distribution asymétrique des données : analysez la distribution des données des clés de jointure. Si une table est très biaisée, explorez des stratégies telles que la division de la requête ou le préfiltrage.
- Jointures à cardinalité élevée : les jointures qui génèrent beaucoup plus de lignes que le nombre de lignes d'entrée de gauche et de droite peuvent réduire considérablement les performances des requêtes. Évitez les jointures qui génèrent un très grand nombre de lignes.
- Ordre incorrect des tables : assurez-vous d'avoir choisi le type de jointure approprié, tel que
INNERouLEFT, et d'avoir ordonné les tables de la plus grande à la plus petite en fonction des exigences de votre requête.
Optimiser
- Clés de jointure sélectives : pour les clés de jointure, utilisez
INT64au lieu deSTRINGlorsque cela est possible. Les comparaisonsSTRINGsont plus lentes que les comparaisonsINT64, car elles comparent chaque caractère d'une chaîne. Les entiers ne nécessitent qu'une seule comparaison. - Filtrer avant la jointure : appliquez des filtres de clause
WHEREsur des tables individuelles avant la jointure. Cela réduit la quantité de données impliquées dans l'opération de jointure. - Évitez les fonctions sur les colonnes de jointure : évitez d'appeler des fonctions sur les colonnes de jointure. À la place, standardisez les données de vos tables pendant le processus d'ingestion ou après l'ingestion à l'aide de pipelines ELT SQL. Cette approche élimine la nécessité de modifier dynamiquement les colonnes de jointure, ce qui permet des jointures plus efficaces sans compromettre l'intégrité des données.
- Évitez les autojointures : les autojointures sont couramment utilisées pour calculer les relations dépendantes des lignes. Toutefois, les autojointures peuvent potentiellement quadrupler le nombre de lignes de sortie, ce qui peut entraîner des problèmes de performances. Au lieu de vous appuyer sur des autojointures, envisagez d'utiliser des fonctions de fenêtrage (analytiques).
- Tables volumineuses en premier : même si l'optimiseur de requête SQL peut déterminer quelle table doit figurer sur tel côté de la jointure, ordonnez vos jointures de façon appropriée. La bonne pratique consiste à placer la table la plus grande en premier, suivie de la plus petite, puis de continuer par taille décroissante.
- Dénormalisation : dans certains cas, la dénormalisation stratégique des tables (ajout de données redondantes) peut éliminer complètement les jointures. Toutefois, cette approche présente des inconvénients en termes de stockage et de cohérence des données.
- Partitionnement et clustering : le partitionnement des tables en fonction des clés de jointure et le clustering des données colocalisées peuvent accélérer considérablement les jointures en permettant à BigQuery de cibler les partitions de données pertinentes.
- Optimiser les jointures asymétriques : pour éviter les problèmes de performances associés aux jointures asymétriques, préfiltrez les données de la table le plus tôt possible ou divisez la requête en deux ou plusieurs requêtes.
AGGREGATE étape
À l'étape AGGREGATE, BigQuery agrège et regroupe les données.
Débogage
- Détails de l'étape : vérifiez le nombre de lignes d'entrée et de sortie de l'agrégation, ainsi que la taille du shuffle pour déterminer l'ampleur de la réduction des données obtenue par l'étape d'agrégation et si un shuffle de données a été effectué.
- Taille du shuffle : une taille de shuffle importante peut indiquer qu'une quantité importante de données a été déplacée entre les nœuds de calcul lors de l'agrégation.
- Vérifiez la distribution des données : assurez-vous que les données sont réparties de manière égale entre les partitions. Une distribution asymétrique des données peut entraîner des charges de travail déséquilibrées lors de l'étape d'agrégation.
- Examiner les agrégations : analysez les clauses d'agrégation pour vérifier qu'elles sont nécessaires et efficaces.
Optimiser
- Clustering : regroupez vos tables sur les colonnes fréquemment utilisées dans les clauses
GROUP BY,COUNTou d'autres clauses d'agrégation. - Partitionnement : choisissez une stratégie de partitionnement qui correspond à vos modèles de requête. Envisagez d'utiliser des tables partitionnées par date d'ingestion pour réduire la quantité de données analysées lors de l'agrégation.
- Regroupez les données plus tôt : si possible, effectuez les agrégations plus tôt dans le pipeline de requête. Cela peut réduire la quantité de données à traiter lors de l'agrégation.
- Optimisation du mélange : si le mélange est un goulot d'étranglement, cherchez des moyens de le minimiser. Par exemple, dénormalisez les tables ou utilisez le clustering pour colocaliser les données pertinentes.
Cas extrêmes
- Agrégats DISTINCT : les requêtes avec des agrégats
DISTINCTpeuvent être coûteuses en termes de calcul, en particulier sur les grands ensembles de données. Envisagez d'utiliser des alternatives commeAPPROX_COUNT_DISTINCTpour obtenir des résultats approximatifs. - Grand nombre de groupes : si la requête génère un grand nombre de groupes, elle peut consommer une quantité importante de mémoire. Dans ce cas, pensez à limiter le nombre de groupes ou à utiliser une autre stratégie d'agrégation.
REPARTITION étape
REPARTITION et COALESCE sont des techniques d'optimisation que BigQuery applique directement aux données mélangées dans la requête.
REPARTITION: cette opération vise à rééquilibrer la distribution des données entre les nœuds de calcul. Supposons qu'après le mélange, un nœud de calcul se retrouve avec une quantité de données disproportionnée. L'étapeREPARTITIONredistribue les données de manière plus uniforme, ce qui évite qu'un nœud de calcul unique ne devienne un goulot d'étranglement. Cela est particulièrement important pour les opérations gourmandes en ressources de calcul, comme les jointures.COALESCE: cette étape se produit lorsque vous avez de nombreux petits buckets de données après le mélange. L'étapeCOALESCEcombine ces buckets en buckets plus grands, ce qui réduit les frais généraux associés à la gestion de nombreux petits éléments de données. Cela peut s'avérer particulièrement utile lorsque vous traitez des ensembles de résultats intermédiaires très petits.
Si vous voyez des étapes REPARTITION ou COALESCE dans votre plan de requête, cela ne signifie pas nécessairement qu'il y a un problème avec votre requête. Cela signifie souvent que BigQuery optimise de manière proactive la distribution des données pour améliorer les performances. Toutefois, si vous voyez ces opérations se répéter, cela peut indiquer que vos données sont intrinsèquement asymétriques ou que votre requête provoque un brassage excessif des données.
Optimiser
Pour réduire le nombre d'étapes REPARTITION, essayez ce qui suit :
- Distribution des données : assurez-vous que vos tables sont partitionnées et regroupées de manière efficace. Des données bien réparties réduisent la probabilité de déséquilibres importants après le mélange.
- Structure de la requête : analysez la requête pour identifier les sources potentielles d'asymétrie des données. Par exemple, existe-t-il des filtres ou des jointures très sélectifs qui entraînent le traitement d'un petit sous-ensemble de données sur un seul nœud de calcul ?
- Stratégies de jointure : testez différentes stratégies de jointure pour voir si elles permettent d'obtenir une distribution de données plus équilibrée.
Pour réduire le nombre d'étapes COALESCE, essayez ce qui suit :
- Stratégies d'agrégation : pensez à effectuer les agrégations plus tôt dans le pipeline de requête. Cela peut aider à réduire le nombre de petits ensembles de résultats intermédiaires susceptibles de provoquer des étapes
COALESCE. - Volume de données : si vous traitez des ensembles de données très petits,
COALESCEne devrait pas être un problème majeur.
N'optimisez pas trop. Une optimisation prématurée peut rendre vos requêtes plus complexes sans apporter d'avantages significatifs.
Explication pour les requêtes fédérées
Les requêtes fédérées vous permettent d'envoyer une instruction de requête à une source de données externe à l'aide de la fonction EXTERNAL_QUERY.
Les requêtes fédérées sont soumises à la technique d'optimisation appelée pushdown SQL, et le plan de requête affiche les opérations transmises à la source de données externe, le cas échéant. Par exemple, si vous exécutez la requête suivante :
SELECT id, name
FROM EXTERNAL_QUERY("<connection>", "SELECT * FROM company")
WHERE country_code IN ('ee', 'hu') AND name like '%TV%'
Le plan de requête affiche les étapes suivantes :
$1:id, $2:name, $3:country_code
FROM table_for_external_query_$_0(
SELECT id, name, country_code
FROM (
/*native_query*/
SELECT * FROM company
)
WHERE in(country_code, 'ee', 'hu')
)
WHERE and(in($3, 'ee', 'hu'), like($2, '%TV%'))
$1, $2
TO __stage00_output
Dans ce plan, table_for_external_query_$_0(...) représente la fonction EXTERNAL_QUERY. La requête exécutée par la source de données externe est entre parenthèses. Sur cette base, vous pouvez constater les éléments suivants :
- Une source de données externe ne renvoie que trois colonnes sélectionnées.
- Une source de données externe ne renvoie que les lignes pour lesquelles
country_codecorrespond à'ee'ou'hu'. - L'opérateur
LIKEn'est pas transmis et est évalué par BigQuery.
À des fins de comparaison, s'il n'y a pas de pushdown, le plan de requête affiche les étapes suivantes :
$1:id, $2:name, $3:country_code
FROM table_for_external_query_$_0(
SELECT id, name, description, country_code, primary_address, secondary address
FROM (
/*native_query*/
SELECT * FROM company
)
)
WHERE and(in($3, 'ee', 'hu'), like($2, '%TV%'))
$1, $2
TO __stage00_output
Cette fois, une source de données externe renvoie toutes les colonnes et toutes les lignes de la table company, et BigQuery effectue le filtrage.
Métadonnées de chronologie
La chronologie de la requête indique les progrès réalisés à des moments précis et fournit des aperçus instantanés de la progression globale de la requête. La chronologie est représentée par une série d'échantillons qui indiquent les informations suivantes :
| Champ | Description |
|---|---|
elapsedMs |
Millisecondes écoulées depuis le début de l'exécution de la requête. |
totalSlotMs |
Représentation cumulée des intervalles de millisecondes utilisés par la requête. |
pendingUnits |
Nombre total d'unités de travail planifiées et en attente d'exécution. |
activeUnits |
Nombre total d'unités de travail actives en cours de traitement par les nœuds de calcul. |
completedUnits |
Nombre total d'unités de travail effectuées lors de l'exécution de cette requête. |
Exemple de requête
La requête suivante compte le nombre de lignes de l'ensemble de données public Shakespeare et comporte un deuxième compteur conditionnel qui limite les résultats aux lignes faisant référence à "hamlet" :
SELECT
COUNT(1) as rowcount,
COUNTIF(corpus = 'hamlet') as rowcount_hamlet
FROM `publicdata.samples.shakespeare`
Cliquez sur Execution details (Détails d'exécution) pour afficher le plan de requête :
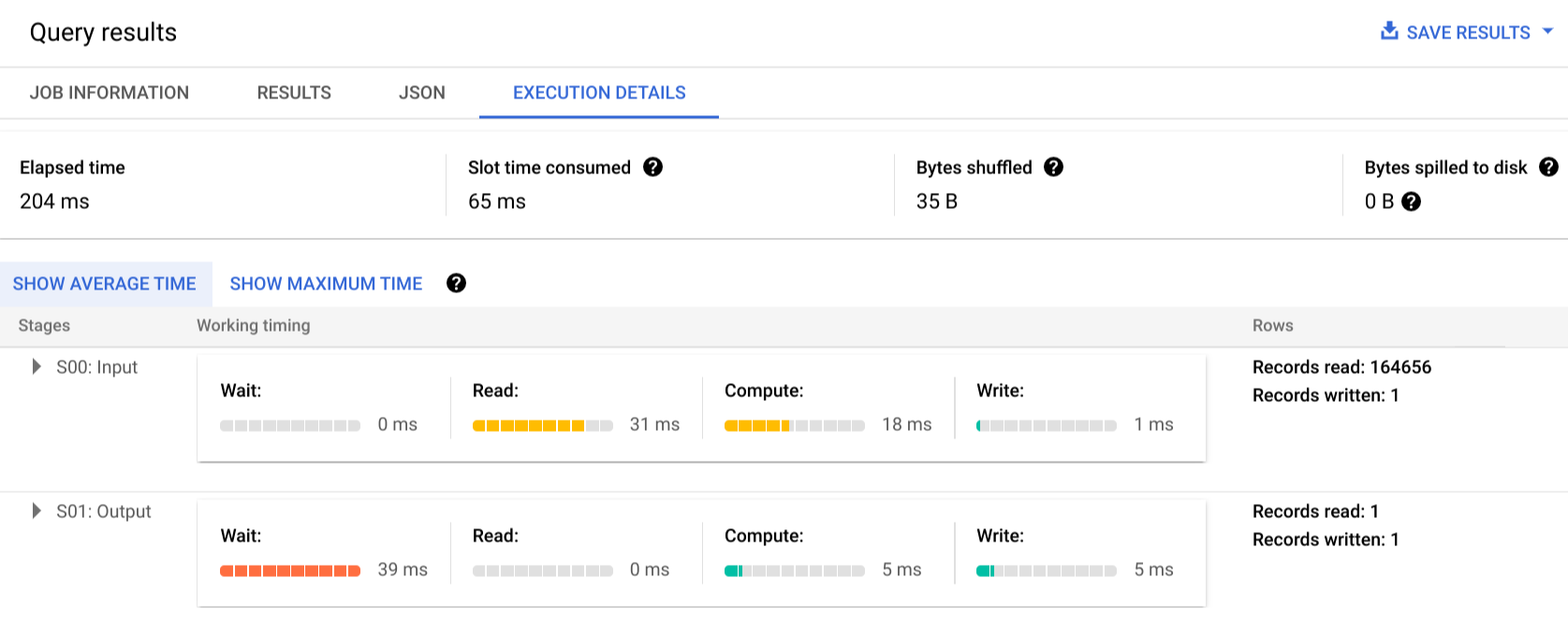
Les indicateurs de couleur affichent les temps relatifs correspondant à chaque étape de chaque phase.
Pour en savoir plus sur les étapes des phases d'exécution, cliquez sur pour développer les détails de la phase :
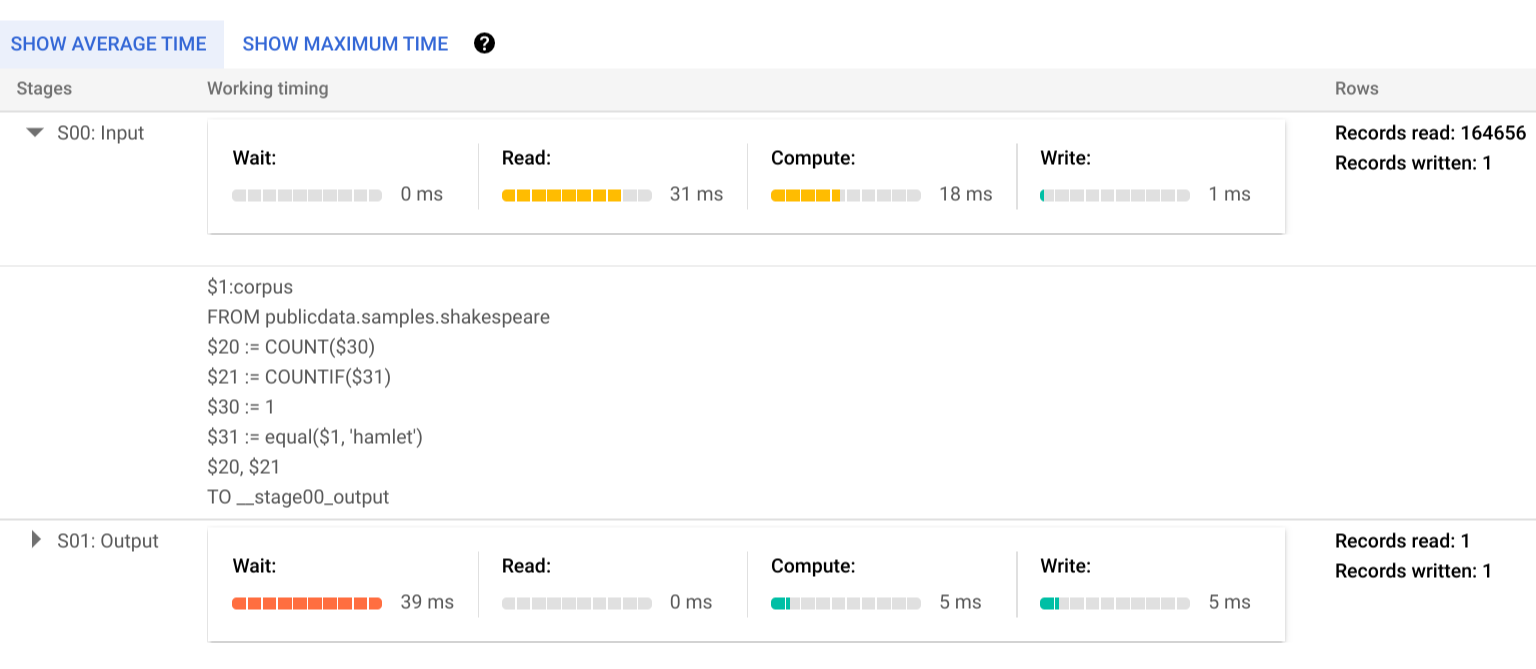
Dans cet exemple, la durée de segment la plus longue correspond au temps passé par le seul nœud de calcul de la phase 01 à attendre que la phase 00 se termine. Cela est dû au fait que la phase 01 est dépendante de l'entrée de la phase 00 et n'a pas pu démarrer tant que la première phase n'avait pas écrit sa sortie en brassage intermédiaire.
Création de rapports d'erreur
Il est possible que les tâches de requête échouent en cours d'exécution. Les informations du plan étant régulièrement mises à jour, vous pouvez observer où l'échec a eu lieu sur le graphe d'exécution. Dans la console Google Cloud , les étapes réussies ou échouées sont identifiées par une coche ou un point d'exclamation situés à côté du nom de l'étape.
Pour plus d'informations sur l'interprétation et la résolution des erreurs, consultez le guide de dépannage.
Exemple de représentation de l'API
Les informations du plan de requête sont intégrées dans les informations de réponse de la tâche. Elles peuvent être extraites simplement en appelant jobs.get.
Par exemple, l'extrait suivant d'une réponse JSON d'une tâche renvoyant l'échantillon de requête "hamlet" affiche à la fois le plan de la requête et les informations sur la chronologie.
"statistics": {
"creationTime": "1576544129234",
"startTime": "1576544129348",
"endTime": "1576544129681",
"totalBytesProcessed": "2464625",
"query": {
"queryPlan": [
{
"name": "S00: Input",
"id": "0",
"startMs": "1576544129436",
"endMs": "1576544129465",
"waitRatioAvg": 0.04,
"waitMsAvg": "1",
"waitRatioMax": 0.04,
"waitMsMax": "1",
"readRatioAvg": 0.32,
"readMsAvg": "8",
"readRatioMax": 0.32,
"readMsMax": "8",
"computeRatioAvg": 1,
"computeMsAvg": "25",
"computeRatioMax": 1,
"computeMsMax": "25",
"writeRatioAvg": 0.08,
"writeMsAvg": "2",
"writeRatioMax": 0.08,
"writeMsMax": "2",
"shuffleOutputBytes": "18",
"shuffleOutputBytesSpilled": "0",
"recordsRead": "164656",
"recordsWritten": "1",
"parallelInputs": "1",
"completedParallelInputs": "1",
"status": "COMPLETE",
"steps": [
{
"kind": "READ",
"substeps": [
"$1:corpus",
"FROM publicdata.samples.shakespeare"
]
},
{
"kind": "AGGREGATE",
"substeps": [
"$20 := COUNT($30)",
"$21 := COUNTIF($31)"
]
},
{
"kind": "COMPUTE",
"substeps": [
"$30 := 1",
"$31 := equal($1, 'hamlet')"
]
},
{
"kind": "WRITE",
"substeps": [
"$20, $21",
"TO __stage00_output"
]
}
]
},
{
"name": "S01: Output",
"id": "1",
"startMs": "1576544129465",
"endMs": "1576544129480",
"inputStages": [
"0"
],
"waitRatioAvg": 0.44,
"waitMsAvg": "11",
"waitRatioMax": 0.44,
"waitMsMax": "11",
"readRatioAvg": 0,
"readMsAvg": "0",
"readRatioMax": 0,
"readMsMax": "0",
"computeRatioAvg": 0.2,
"computeMsAvg": "5",
"computeRatioMax": 0.2,
"computeMsMax": "5",
"writeRatioAvg": 0.16,
"writeMsAvg": "4",
"writeRatioMax": 0.16,
"writeMsMax": "4",
"shuffleOutputBytes": "17",
"shuffleOutputBytesSpilled": "0",
"recordsRead": "1",
"recordsWritten": "1",
"parallelInputs": "1",
"completedParallelInputs": "1",
"status": "COMPLETE",
"steps": [
{
"kind": "READ",
"substeps": [
"$20, $21",
"FROM __stage00_output"
]
},
{
"kind": "AGGREGATE",
"substeps": [
"$10 := SUM_OF_COUNTS($20)",
"$11 := SUM_OF_COUNTS($21)"
]
},
{
"kind": "WRITE",
"substeps": [
"$10, $11",
"TO __stage01_output"
]
}
]
}
],
"estimatedBytesProcessed": "2464625",
"timeline": [
{
"elapsedMs": "304",
"totalSlotMs": "50",
"pendingUnits": "0",
"completedUnits": "2"
}
],
"totalPartitionsProcessed": "0",
"totalBytesProcessed": "2464625",
"totalBytesBilled": "10485760",
"billingTier": 1,
"totalSlotMs": "50",
"cacheHit": false,
"referencedTables": [
{
"projectId": "publicdata",
"datasetId": "samples",
"tableId": "shakespeare"
}
],
"statementType": "SELECT"
},
"totalSlotMs": "50"
},
Utiliser les informations d'exécution
Les plans de requête BigQuery fournissent des informations sur la manière dont le service exécute les requêtes, mais la nature gérée du service limite la possibilité d'exploiter directement certaines informations. De nombreuses optimisations sont effectuées automatiquement lors de l'utilisation du service, ce qui peut différer d'autres environnements où le réglage, l'approvisionnement et la surveillance nécessitent un personnel spécialisé et qualifié.
Pour connaître les techniques spécifiques susceptibles d'améliorer l'exécution et les performances des requêtes, consultez la documentation sur les bonnes pratiques. Les statistiques du plan et de la chronologie de requête peuvent vous aider à savoir si certaines phases utilisent davantage de ressources. Par exemple, une phase JOIN qui génère beaucoup plus de lignes de sortie que de lignes d'entrée peut indiquer la possibilité de filtrer plus tôt dans la requête.
En outre, les informations de chronologie peuvent permettre de savoir si une requête donnée est lente par elle-même ou à cause des effets d'autres requêtes en concurrence pour les mêmes ressources. Si le nombre d'unités actives reste limité tout au long de la durée de la requête, alors que le nombre d'unités de travail en file d'attente reste élevé, la réduction du nombre de requêtes simultanées peut considérablement améliorer le temps global d'exécution de certaines requêtes.