Utilizzare campi nidificati e ripetuti
BigQuery può essere utilizzato con molti metodi diversi di definizione del modello di dati e generalmente offre un rendimento elevato in molte metodologie di modelli di dati. Per ottimizzare ulteriormente un modello di dati in termini di prestazioni, puoi prendere in considerazione la denormalizzazione dei dati, ovvero l'aggiunta di colonne di dati a una singola tabella per ridurre o rimuovere i join delle tabelle.
Best practice:utilizza campi nidificati e ripetuti per denormalizzare lo stoccaggio dei dati e aumentare le prestazioni delle query.
La denormalizzazione è una strategia comune per aumentare le prestazioni di lettura per set di dati relazionali precedentemente normalizzati. Il modo consigliato per denormalizzare i dati in BigQuery è utilizzare campi nidificati e ripetuti. È preferibile utilizzare questa strategia quando le relazioni sono gerarchiche e spesso oggetto di query insieme, ad esempio nelle relazioni padre-figlio.
Il risparmio di spazio di archiviazione derivante dall'utilizzo di dati normalizzati ha un effetto minore nei sistemi moderni. Gli aumenti dei costi di archiviazione valgono i vantaggi in termini di prestazioni dell'utilizzo di dati denormalizzati. I join richiedono il coordinamento dei dati (larghezza di banda della comunicazione). La denormalizzazione localizza i dati in singoli slot, in modo che l'esecuzione possa essere eseguita in parallelo.
Per mantenere le relazioni durante la denormalizzazione dei dati, puoi utilizzare campi nidificati e ripetuti anziché appiattire completamente i dati. Quando i dati relazionali sono completamente appiattiti, la comunicazione di rete (rimescolamento) può influire negativamente sul rendimento delle query.
Ad esempio, la denormalizzazione di uno schema degli ordini senza utilizzare campi nidificati e ripetuti potrebbe richiedere di raggruppare i dati in base a un campo come order_id
(se esiste una relazione uno a molti). A causa dello smistamento, il raggruppamento dei dati è meno efficace della denormalizzazione dei dati mediante l'utilizzo di campi nidificati e ripetuti.
In alcuni casi, la denormalizzazione dei dati e l'utilizzo di campi nidificati e ripetuti non comporta un aumento del rendimento. Ad esempio, gli schemi a stella sono solitamente schemi ottimizzati per l'analisi e, di conseguenza, il rendimento potrebbe non essere notevolmente diverso se si tenta di denormalizzare ulteriormente.
Utilizzare campi nidificati e ripetuti
BigQuery non richiede una denormalizzazione completamente piatta. Puoi utilizzare i campi nidificati e ripetuti per mantenere le relazioni.
Dati di nidificazione (
STRUCT)- L'annidamento dei dati ti consente di rappresentare le entità esterne in linea.
- L'esecuzione di query sui dati nidificati utilizza la sintassi "punto" per fare riferimento ai campi foglia, che è simile alla sintassi che utilizza un'unione.
- I dati nidificati sono rappresentati come
tipo
STRUCTin GoogleSQL.
Dati ripetuti (
ARRAY)- La creazione di un campo di tipo
RECORDcon la modalità impostata suREPEATEDconsente di mantenere una relazione one-to-many in linea (a condizione che la relazione non sia di cardinalità elevata). - Con i dati ripetuti, non è necessario mescolare.
- I dati ripetuti sono rappresentati come
ARRAY. Puoi utilizzare una funzioneARRAYin GoogleSQL quando esegui query sui dati ripetuti.
- La creazione di un campo di tipo
Dati nidificati e ripetuti (
ARRAYdiSTRUCT)- Il nesting e la ripetizione si completano a vicenda.
- Ad esempio, in una tabella di record di transazioni, puoi includere un array di elementi pubblicitari
STRUCT.
Per ulteriori informazioni, consulta Specificare colonne nidificate e ripetute negli schemi delle tabelle.
Per ulteriori informazioni sulla denormalizzazione dei dati, consulta Denormalizzazione.
Esempio
Prendi in considerazione una tabella Orders con una riga per ogni elemento pubblicitario venduto:
| Order_Id | Item_Name |
|---|---|
| 001 | A1 |
| 001 | B1 |
| 002 | A1 |
| 002 | C1 |
Se vuoi analizzare i dati di questa tabella, devi utilizzare una clausola GROUP BY, simile alla seguente:
SELECT COUNT (Item_Name) FROM Orders GROUP BY Order_Id;
La clausola GROUP BY comporta un sovraccarico computazionale aggiuntivo, ma questo può essere evitato nidificando i dati ripetuti. Puoi evitare di utilizzare una clausola GROUP BY
creando una tabella con un ordine per riga, in cui gli elementi pubblicitari dell'ordine si trovano in un
campo nidificato:
| Order_Id | Item_Name |
|---|---|
| 001 |
A1 B1 |
| 002 |
A1 C1 |
In BigQuery, in genere specifichi uno schema nidificato come ARRAY
di oggetti STRUCT. Utilizza l'operatore UNNEST per appiattire i dati nidificati, come mostrato nella seguente query:
SELECT * FROM UNNEST( [ STRUCT('001' AS Order_Id, ['A1', 'B1'] AS Item_Name), STRUCT('002' AS Order_Id, ['A1', 'C1'] AS Item_Name) ] );
Questa query restituisce risultati simili ai seguenti:
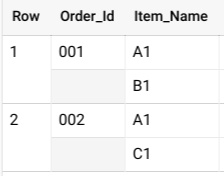
Se questi dati non fossero nidificati, potresti avere potenzialmente più righe per ogni ordine, una per ogni articolo venduto nell'ordine, il che si tradurrebbe in una tabella di grandi dimensioni e in un'operazione GROUP BY costosa.
Esercizio
Puoi vedere la differenza di rendimento nelle query che utilizzano campi nidificati rispetto a quelle che non lo fanno seguendo i passaggi descritti in questa sezione.
Crea una tabella basata sul set di dati pubblico
bigquery-public-data.stackoverflow.comments:CREATE OR REPLACE TABLE `PROJECT.DATASET.stackoverflow` AS ( SELECT user_id, post_id, creation_date FROM `bigquery-public-data.stackoverflow.comments` );
Utilizzando la tabella
stackoverflow, esegui la seguente query per visualizzare il commento più antico per ogni utente:SELECT user_id, ARRAY_AGG(STRUCT(post_id, creation_date AS earliest_comment) ORDER BY creation_date ASC LIMIT 1)[OFFSET(0)].* FROM `PROJECT.DATASET.stackoverflow` GROUP BY user_id ORDER BY user_id ASC;
L'esecuzione di questa query richiede circa 25 secondi ed elabora 1,88 GB di dati.
Crea una seconda tabella con dati identici che crea un campo
commentsutilizzando un tipoSTRUCTper archiviare i datipost_idecreation_date, anziché due singoli campi:CREATE OR REPLACE TABLE `PROJECT.DATASET.stackoverflow_nested` AS ( SELECT user_id, ARRAY_AGG(STRUCT(post_id, creation_date) ORDER BY creation_date ASC) AS comments FROM `bigquery-public-data.stackoverflow.comments` GROUP BY user_id );
Utilizzando la tabella
stackoverflow_nested, esegui la seguente query per visualizzare il primo commento di ciascun utente:SELECT user_id, (SELECT AS STRUCT post_id, creation_date as earliest_comment FROM UNNEST(comments) ORDER BY creation_date ASC LIMIT 1).* FROM `PROJECT.DATASET.stackoverflow_nested` ORDER BY user_id ASC;
L'esecuzione di questa query richiede circa 10 secondi ed elabora 1,28 GB di dati.
Elimina le tabelle
stackoverflowestackoverflow_nestedquando non ti servono più.