Dans ce tutoriel, vous allez apprendre à accélérer de manière significative l'entraînement d'un ensemble de modèles de série temporelle univariée ARIMA_PLUS afin d'effectuer plusieurs prévisions de séries temporelles dans une seule et même requête. Vous apprendrez également à évaluer la précision des prévisions.
Ce tutoriel effectue des prévisions pour plusieurs séries temporelles. Les valeurs prévues sont calculées pour chaque point temporel, pour chaque valeur d'une ou de plusieurs colonnes spécifiées. Par exemple, si vous souhaitez prévoir la météo et que vous spécifiez une colonne contenant des données sur les villes, les données prévues contiendront les prévisions pour tous les points temporels de la ville A, puis les valeurs prévues pour tous les points temporels de la ville B, et ainsi de suite.
Ce tutoriel utilise les données des tables publiques bigquery-public-data.new_york.citibike_trips et iowa_liquor_sales.sales. Les données sur les trajets à vélo ne contiennent que quelques centaines de séries temporelles. Elles sont donc utilisées pour illustrer diverses stratégies permettant d'accélérer l'entraînement des modèles.
Les données sur les ventes d'alcool comportent plus d'un million de séries temporelles. Elles sont donc utilisées pour montrer la prévision de séries temporelles à grande échelle.
Avant de lire ce tutoriel, consultez Prévoir plusieurs séries temporelles avec un modèle univarié et Bonnes pratiques de prévision de séries temporelles à grande échelle.
Objectifs
Dans ce tutoriel, vous allez utiliser :
- Créez un modèle de série temporelle à l'aide de l'instruction
CREATE MODEL. - Évaluer la justesse du modèle à l'aide de la fonction
ML.EVALUATE. - Utilisez les options
AUTO_ARIMA_MAX_ORDER,TIME_SERIES_LENGTH_FRACTION,MIN_TIME_SERIES_LENGTHetMAX_TIME_SERIES_LENGTHde l'instructionCREATE MODELpour réduire considérablement la durée d'entraînement du modèle.
Par souci de simplicité, ce tutoriel n'explique pas comment générer des prévisions à l'aide des fonctions ML.FORECAST ou ML.EXPLAIN_FORECAST. Pour découvrir comment utiliser ces fonctions, consultez Prévoir plusieurs séries temporelles avec un modèle univarié.
Coûts
Ce tutoriel utilise des composants facturables de Google Cloud, y compris :
- BigQuery
- BigQuery ML
Pour en savoir plus sur les coûts, consultez les pages Tarifs de BigQuery et Tarifs de BigQuery ML.
Avant de commencer
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
- BigQuery est automatiquement activé dans les nouveaux projets.
Pour activer BigQuery dans un projet préexistant, accédez à
Enable the BigQuery API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. Pour créer l'ensemble de données, vous devez disposer de l'autorisation IAM
bigquery.datasets.create.Pour créer le modèle, vous avez besoin des autorisations suivantes :
bigquery.jobs.createbigquery.models.createbigquery.models.getDatabigquery.models.updateData
Pour exécuter une inférence, vous devez disposer des autorisations suivantes :
bigquery.models.getDatabigquery.jobs.create
Autorisations requises
Pour plus d'informations sur les rôles et les autorisations IAM dans BigQuery, consultez la page Présentation d'IAM.
Créer un ensemble de données
Créez un ensemble de données BigQuery pour stocker votre modèle de ML.
Console
Dans la console Google Cloud , accédez à la page BigQuery.
Dans le volet Explorateur, cliquez sur le nom de votre projet.
Cliquez sur Afficher les actions > Créer un ensemble de données.
Sur la page Créer un ensemble de données, procédez comme suit :
Dans le champ ID de l'ensemble de données, saisissez
bqml_tutorial.Pour Type d'emplacement, sélectionnez Multirégional, puis sélectionnez US (plusieurs régions aux États-Unis).
Conservez les autres paramètres par défaut, puis cliquez sur Créer un ensemble de données.
bq
Pour créer un ensemble de données, exécutez la commande bq mk en spécifiant l'option --location. Pour obtenir la liste complète des paramètres possibles, consultez la documentation de référence sur la commande bq mk --dataset.
Créez un ensemble de données nommé
bqml_tutorialavec l'emplacement des données défini surUSet une description deBigQuery ML tutorial dataset:bq --location=US mk -d \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
Au lieu d'utiliser l'option
--dataset, la commande utilise le raccourci-d. Si vous omettez-det--dataset, la commande crée un ensemble de données par défaut.Vérifiez que l'ensemble de données a été créé :
bq ls
API
Appelez la méthode datasets.insert avec une ressource d'ensemble de données définie.
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
BigQuery DataFrames
Avant d'essayer cet exemple, suivez les instructions de configuration pour BigQuery DataFrames du guide de démarrage rapide de BigQuery DataFrames. Pour en savoir plus, consultez la documentation de référence sur BigQuery DataFrames.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer les ADC pour un environnement de développement local.
Créer un tableau de données d'entrée
L'instruction SELECT de la requête suivante utilise la fonction EXTRACT pour extraire les informations de date de la colonne starttime. La requête utilise la clause COUNT(*) pour obtenir le nombre quotidien total de trajets Citi Bike.
table_1 a 679 séries temporelles. La requête utilise une logique INNER JOIN supplémentaire pour sélectionner toutes les séries temporelles ayant plus de 400 points temporels, soit un total de 383 séries temporelles.
Pour créer le tableau de données d'entrée, procédez comme suit :
Dans la console Google Cloud , accédez à la page BigQuery.
Dans l'éditeur de requête, collez la requête suivante, puis cliquez sur Exécuter :
CREATE OR REPLACE TABLE `bqml_tutorial.nyc_citibike_time_series` AS WITH input_time_series AS ( SELECT start_station_name, EXTRACT(DATE FROM starttime) AS date, COUNT(*) AS num_trips FROM `bigquery-public-data.new_york.citibike_trips` GROUP BY start_station_name, date ) SELECT table_1.* FROM input_time_series AS table_1 INNER JOIN ( SELECT start_station_name, COUNT(*) AS num_points FROM input_time_series GROUP BY start_station_name) table_2 ON table_1.start_station_name = table_2.start_station_name WHERE num_points > 400;
Créer un modèle pour plusieurs séries temporelles avec des paramètres par défaut
Vous souhaitez prévoir le nombre de trajets à vélo pour chaque station Citi Bike, ce qui nécessite de nombreux modèles de séries temporelles (un pour chaque station Citi Bike incluse dans les données d'entrée). Vous pouvez écrire plusieurs requêtes CREATE MODEL pour ce faire, mais cela peut être un processus fastidieux et chronophage, en particulier lorsque vous avez un grand nombre de séries temporelles. Vous pouvez utiliser une seule requête pour créer et ajuster un ensemble de modèles de séries temporelles afin de prévoir plusieurs séries temporelles à la fois.
La clause OPTIONS(model_type='ARIMA_PLUS', time_series_timestamp_col='date', ...) indique que vous créez un ensemble de modèles de série temporelle ARIMA_PLUS basés sur ARIMA. L'option time_series_timestamp_col spécifie la colonne contenant les séries temporelles, l'option time_series_data_col spécifie la colonne pour laquelle effectuer des prévisions, et time_series_id_col spécifie une ou plusieurs dimensions pour lesquelles vous souhaitez créer des séries temporelles.
Cet exemple n'affiche pas les points temporels de la série temporelle postérieurs au 1er juin 2016 , afin que ces points puissent être utilisés ultérieurement pour évaluer la précision des prévisions à l'aide de la fonction ML.EVALUATE.
Pour créer le modèle, procédez comme suit :
Dans la console Google Cloud , accédez à la page BigQuery.
Dans l'éditeur de requête, collez la requête suivante, puis cliquez sur Exécuter :
CREATE OR REPLACE MODEL `bqml_tutorial.nyc_citibike_arima_model_default` OPTIONS (model_type = 'ARIMA_PLUS', time_series_timestamp_col = 'date', time_series_data_col = 'num_trips', time_series_id_col = 'start_station_name' ) AS SELECT * FROM bqml_tutorial.nyc_citibike_time_series WHERE date < '2016-06-01';
L'exécution de la requête prend environ 15 minutes.
Évaluer la précision des prévisions pour chaque série temporelle
Évaluez la précision des prévisions du modèle à l'aide de la fonction ML.EVALUATE.
Pour évaluer le modèle, procédez comme suit :
Dans la console Google Cloud , accédez à la page BigQuery.
Dans l'éditeur de requête, collez la requête suivante, puis cliquez sur Exécuter :
SELECT * FROM ML.EVALUATE(MODEL `bqml_tutorial.nyc_citibike_arima_model_default`, TABLE `bqml_tutorial.nyc_citibike_time_series`, STRUCT(7 AS horizon, TRUE AS perform_aggregation));
Cette requête renvoie plusieurs métriques de prévision, telles que :
Les résultats doivent ressembler à ce qui suit :
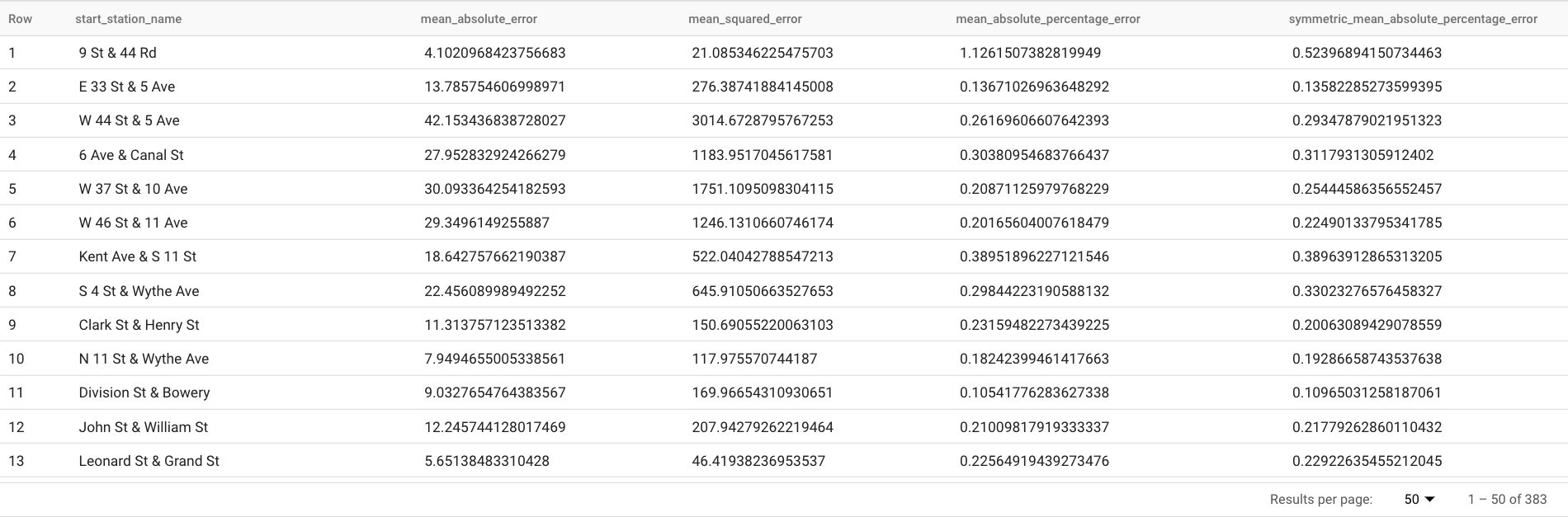
La clause
TABLEde la fonctionML.EVALUATEidentifie une table contenant les données de vérité terrain. Les résultats de prévision sont comparés aux données de vérité terrain pour calculer les métriques de précision. Dans ce cas,nyc_citibike_time_seriescontient à la fois les points de série temporelle antérieurs et postérieurs au 1er juin 2016. Les points postérieurs au 1er juin 2016 sont les données de vérité terrain. Les points antérieurs au 1er juin 2016 sont utilisés pour entraîner le modèle à générer des prévisions après cette date. Seuls les points postérieurs au 1er juin 2016 sont nécessaires pour calculer les métriques. Les points antérieurs au 1er juin 2016 sont ignorés dans le calcul des métriques.La clause
STRUCTde la fonctionML.EVALUATEspécifiait les paramètres de la fonction. La valeurhorizonest7, ce qui signifie que la requête calcule la précision des prévisions sur la base d'une prévision à sept points. Notez que si les données de vérité terrain contiennent moins de sept points pour la comparaison, les métriques de précision sont calculées en fonction des points disponibles uniquement. La valeurperform_aggregationestTRUE, ce qui signifie que les métriques de précision des prévisions sont agrégées individuellement pour chaque point de série temporelle. Si vous spécifiez une valeurperform_aggregationdeFALSE, la précision des prévisions est renvoyée pour chaque point de temps de série temporelle prévu.Pour en savoir plus sur les colonnes de sortie, consultez la fonction
ML.EVALUATE.
Évaluer la précision globale des prévisions
Évaluez la précision des prévisions pour l'ensemble des 383 séries temporelles.
Parmi les métriques de prévision renvoyées par ML.EVALUATE, seules les erreurs absolues de pourcentage moyen et les erreurs de pourcentage absolu symétrique sont indépendantes des valeurs de la série temporelle. Par conséquent, pour évaluer la précision globale des prévisions de l'ensemble des séries temporelles, seul l'agrégation de ces deux métriques est pertinente.
Pour évaluer le modèle, procédez comme suit :
Dans la console Google Cloud , accédez à la page BigQuery.
Dans l'éditeur de requête, collez la requête suivante, puis cliquez sur Exécuter :
SELECT AVG(mean_absolute_percentage_error) AS MAPE, AVG(symmetric_mean_absolute_percentage_error) AS sMAPE FROM ML.EVALUATE(MODEL `bqml_tutorial.nyc_citibike_arima_model_default`, TABLE `bqml_tutorial.nyc_citibike_time_series`, STRUCT(7 AS horizon, TRUE AS perform_aggregation));
Cette requête renvoie une valeur MAPE de 0.3471 et une valeur sMAPE de 0.2563.
Créer un modèle pour prévoir plusieurs séries temporelles avec un espace de recherche d'hyperparamètres plus petit
Dans la section Créer un modèle pour plusieurs séries temporelles avec des paramètres par défaut, vous avez utilisé les valeurs par défaut pour toutes les options d'entraînement, y compris l'option auto_arima_max_order. Cette option contrôle l'espace de recherche pour le réglage d'hyperparamètres dans l'algorithme auto.ARIMA.
Dans le modèle créé par la requête suivante, vous utilisez un espace de recherche plus petit pour les hyperparamètres en modifiant la valeur de l'option auto_arima_max_order de la valeur par défaut 5 à 2.
Pour évaluer le modèle, procédez comme suit :
Dans la console Google Cloud , accédez à la page BigQuery.
Dans l'éditeur de requête, collez la requête suivante, puis cliquez sur Exécuter :
CREATE OR REPLACE MODEL `bqml_tutorial.nyc_citibike_arima_model_max_order_2` OPTIONS (model_type = 'ARIMA_PLUS', time_series_timestamp_col = 'date', time_series_data_col = 'num_trips', time_series_id_col = 'start_station_name', auto_arima_max_order = 2 ) AS SELECT * FROM `bqml_tutorial.nyc_citibike_time_series` WHERE date < '2016-06-01';
L'exécution de la requête prend environ deux minutes. Rappelez-vous que le modèle précédent prenait environ 15 minutes à s'entraîner lorsque la valeur
auto_arima_max_orderétait5. Cette modification permet donc de multiplier par sept la vitesse d'entraînement du modèle. Si vous vous demandez pourquoi le gain de vitesse n'est pas de5/2=2.5x, c'est parce que l'augmentation de la valeurauto_arima_max_orderentraîne non seulement une augmentation du nombre de modèles candidats, mais également de leur complexité. Cela augmente le temps d'entraînement du modèle.
Évaluer la précision des prévisions pour un modèle avec un espace de recherche d'hyperparamètres plus petit
Pour évaluer le modèle, procédez comme suit :
Dans la console Google Cloud , accédez à la page BigQuery.
Dans l'éditeur de requête, collez la requête suivante, puis cliquez sur Exécuter :
SELECT AVG(mean_absolute_percentage_error) AS MAPE, AVG(symmetric_mean_absolute_percentage_error) AS sMAPE FROM ML.EVALUATE(MODEL `bqml_tutorial.nyc_citibike_arima_model_max_order_2`, TABLE `bqml_tutorial.nyc_citibike_time_series`, STRUCT(7 AS horizon, TRUE AS perform_aggregation));
Cette requête renvoie une valeur MAPE de 0.3337 et une valeur sMAPE de 0.2337.
Dans la section Évaluer la précision globale des prévisions, vous avez évalué un modèle avec un espace de recherche d'hyperparamètres plus grand, où la valeur de l'option auto_arima_max_order est 5. Cela a entraîné une valeur MAPE de 0.3471 et une valeur sMAPE de 0.2563. Dans ce cas, vous pouvez constater qu'un espace de recherche d'hyperparamètres plus petit permet en fait d'améliorer la précision des prévisions. Une raison expliquant ce comportement est que l'algorithme auto.ARIMA n'effectue le réglage des hyperparamètres que pour le module de tendance de l'ensemble du pipeline de modélisation. Le meilleur modèle ARIMA sélectionné par l'algorithme auto.ARIMA peut ne pas générer les meilleurs résultats de prévision pour l'ensemble du pipeline.
Créer un modèle pour prévoir plusieurs séries temporelles avec un espace de recherche d'hyperparamètres plus petit et des stratégies d'entraînement rapides et intelligentes
Au cours de cette étape, vous utilisez un espace de recherche d'hyperparamètres plus petit avec une stratégie d'entraînement rapide et intelligent et en utilisant une ou plusieurs des options d'entraînement max_time_series_length, max_time_series_length ou time_series_length_fraction.
Bien que la modélisation périodique (par exemple la saisonnalité) nécessite un certain nombre de points temporels, la modélisation des tendances en nécessite moins. D'un autre côté, la modélisation des tendances est beaucoup plus coûteuse en ressources de calcul que les autres composants de séries temporelles tels que la saisonnalité. En utilisant les options d'entraînement rapide ci-dessus, vous pouvez modéliser efficacement le composant de tendance avec un sous-ensemble de séries temporelles, tandis que les autres composants de séries temporelles utilisent l'intégralité des séries temporelles.
L'exemple suivant utilise l'option max_time_series_length pour effectuer un entraînement rapide. En définissant la valeur de l'option max_time_series_length sur 30, seuls les 30 points temporels les plus récents sont utilisés pour modéliser le composant de tendance. Cela dit, la modélisation de composants autres que le composant de tendance utilise toujours l'intégralité des 383 séries temporelles.
Pour créer le modèle, procédez comme suit :
Dans la console Google Cloud , accédez à la page BigQuery.
Dans l'éditeur de requête, collez la requête suivante, puis cliquez sur Exécuter :
CREATE OR REPLACE MODEL `bqml_tutorial.nyc_citibike_arima_model_max_order_2_fast_training` OPTIONS (model_type = 'ARIMA_PLUS', time_series_timestamp_col = 'date', time_series_data_col = 'num_trips', time_series_id_col = 'start_station_name', auto_arima_max_order = 2, max_time_series_length = 30 ) AS SELECT * FROM `bqml_tutorial.nyc_citibike_time_series` WHERE date < '2016-06-01';
L'exécution de la requête prend environ 35 secondes. Cette méthode est trois fois plus rapide que la requête que vous avez utilisée dans la section Créer un modèle pour prévoir plusieurs séries temporelles avec un espace de recherche d'hyperparamètres plus petit. En raison de la surcharge de temps constante de la partie non-entraînement de la requête (prétraitement des données, etc.), le gain de temps est bien plus important si vous utilisez un nombre de séries temporelles plus important que dans cet exemple. Pour un million de séries temporelles, le gain de temps se rapproche du rapport entre la longueur de la série temporelle et la valeur de l'option
max_time_series_length. Dans ce cas, le gain de temps est plus de 10 fois supérieur.
Évaluer la précision des prévisions pour un modèle comportant un espace de recherche d'hyperparamètres plus petit et des stratégies d'entraînement rapides et intelligentes
Pour évaluer le modèle, procédez comme suit :
Dans la console Google Cloud , accédez à la page BigQuery.
Dans l'éditeur de requête, collez la requête suivante, puis cliquez sur Exécuter :
SELECT AVG(mean_absolute_percentage_error) AS MAPE, AVG(symmetric_mean_absolute_percentage_error) AS sMAPE FROM ML.EVALUATE(MODEL `bqml_tutorial.nyc_citibike_arima_model_max_order_2_fast_training`, TABLE `bqml_tutorial.nyc_citibike_time_series`, STRUCT(7 AS horizon, TRUE AS perform_aggregation));
Cette requête renvoie une valeur MAPE de 0.3515 et une valeur sMAPE de 0.2473.
Rappelez-vous que, sans l'utilisation de stratégies d'entraînement rapides, les résultats de la précision des prévisions sont pour les MAPE de 0.3337 et pour les sMAPE de 0.2337.
La différence entre les deux ensembles de valeurs de métriques est de 3 %, ce qui n'est pas significatif d'un point de vue statistique.
En résumé, vous avez utilisé un espace de recherche d'hyperparamètres plus petit et des stratégies d'entraînement rapides et intelligentes pour entraîner votre modèle jusqu'à deux fois plus rapidement sans sacrifier la précision des prévisions. Comme indiqué précédemment, avec un plus grand nombre de séries temporelles, le gain de temps généré par les stratégies d'entraînement rapide peut être considérablement plus élevé. De plus, la bibliothèque ARIMA sous-jacente utilisée par les modèles ARIMA_PLUS a été optimisée pour fonctionner cinq fois plus rapidement qu'avant. Ensemble, ces gains permettent de prévoir des millions de séries temporelles en seulement quelques heures.
Créer un modèle pour prévoir un million de séries temporelles
Dans cette étape, vous prévoyez les ventes de plus d'un million de produits alcoolisés dans différents magasins en utilisant les données publiques sur les ventes d'alcool de l'Iowa. L'entraînement du modèle utilise un petit espace de recherche d'hyperparamètres ainsi que la stratégie d'entraînement rapide et intelligent.
Pour évaluer le modèle, procédez comme suit :
Dans la console Google Cloud , accédez à la page BigQuery.
Dans l'éditeur de requête, collez la requête suivante, puis cliquez sur Exécuter :
CREATE OR REPLACE MODEL `bqml_tutorial.liquor_forecast_by_product` OPTIONS( MODEL_TYPE = 'ARIMA_PLUS', TIME_SERIES_TIMESTAMP_COL = 'date', TIME_SERIES_DATA_COL = 'total_bottles_sold', TIME_SERIES_ID_COL = ['store_number', 'item_description'], HOLIDAY_REGION = 'US', AUTO_ARIMA_MAX_ORDER = 2, MAX_TIME_SERIES_LENGTH = 30 ) AS SELECT store_number, item_description, date, SUM(bottles_sold) as total_bottles_sold FROM `bigquery-public-data.iowa_liquor_sales.sales` WHERE date BETWEEN DATE("2015-01-01") AND DATE("2021-12-31") GROUP BY store_number, item_description, date;
L'exécution de la requête prend environ une heure et 16 minutes.
Effectuer un nettoyage
Pour éviter que les ressources utilisées lors de ce tutoriel soient facturées sur votre compte Google Cloud, supprimez le projet contenant les ressources, ou conservez le projet et supprimez les ressources individuelles.
- Supprimez le projet que vous avez créé.
- Ou conservez le projet et supprimez l'ensemble de données.
Supprimer l'ensemble de données
Si vous supprimez votre projet, tous les ensembles de données et toutes les tables qui lui sont associés sont également supprimés. Si vous préférez réutiliser le projet, vous pouvez supprimer l'ensemble de données que vous avez créé dans ce tutoriel :
Si nécessaire, ouvrez la page BigQuery dans la consoleGoogle Cloud .
Dans le panneau de navigation, cliquez sur l'ensemble de données bqml_tutorial que vous avez créé.
Cliquez sur Supprimer l'ensemble de données pour supprimer l'ensemble de données, la table, ainsi que toutes les données.
Dans la boîte de dialogue Supprimer l'ensemble de données, confirmez la commande de suppression en saisissant le nom de votre ensemble de données (
bqml_tutorial), puis cliquez sur Supprimer.
Supprimer votre projet
Pour supprimer le projet :
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Étapes suivantes
- Découvrez comment prévoir une seule série temporelle avec un modèle univarié.
- Découvrez comment prévoir une seule série temporelle avec un modèle multivarié.
- Découvrez comment prévoir plusieurs séries temporelles avec un modèle univarié.
- Découvrez comment prévoir hiérarchiquement plusieurs séries temporelles avec un modèle univarié.
- Pour obtenir plus d'informations sur BigQuery ML, consultez la présentation de l'IA et du ML dans BigQuery.