Ce tutoriel vous explique comment utiliser un modèle de série temporelle multivariée pour prévoir la valeur future d'une colonne donnée, en fonction de la valeur historique de plusieurs caractéristiques d'entrée.
Ce tutoriel prévoit une seule série temporelle. Les valeurs prévues sont calculées une fois pour chaque point temporel des données d'entrée.
Ce tutoriel utilise les données de l'ensemble de données public bigquery-public-data.epa_historical_air_quality. Cet ensemble de données contient des informations quotidiennes sur les particules fines (PM2,5), la température et la vitesse du vent, collectées pour plusieurs villes américaines.
Objectifs
Ce tutoriel vous guide à travers les tâches suivantes :
- Créer un modèle de série temporelle pour prévoir les valeurs de PM2.5 à l'aide de l'instruction
CREATE MODEL. - Évaluation des informations de moyenne mobile intégrée autorégressive (ARIMA) dans le modèle à l'aide de la fonction
ML.ARIMA_EVALUATE. - Inspecter les coefficients du modèle à l'aide de la fonction
ML.ARIMA_COEFFICIENTS. - Récupérer les valeurs de PM2.5 prévues à partir du modèle à l'aide de la fonction
ML.FORECAST. - Évaluer la justesse du modèle à l'aide de la fonction
ML.EVALUATE. - Récupérer les composants de la série temporelle, tels que la saisonnalité, la tendance et les attributions de caractéristiques, à l'aide de la fonction
ML.EXPLAIN_FORECAST. Vous pouvez inspecter ces composants de série temporelle pour expliquer les valeurs prévues.
Coûts
Ce tutoriel utilise des composants facturables de Google Cloud, y compris :
- BigQuery
- BigQuery ML
Pour plus d'informations sur les coûts de BigQuery, consultez la page Tarifs de BigQuery.
Pour en savoir plus sur les coûts associés à BigQuery ML, consultez la page Tarifs de BigQuery ML.
Avant de commencer
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
- BigQuery est automatiquement activé dans les nouveaux projets.
Pour activer BigQuery dans un projet préexistant, accédez à
Enable the BigQuery API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. Pour créer l'ensemble de données, vous devez disposer de l'autorisation IAM
bigquery.datasets.create.Pour créer le modèle, vous avez besoin des autorisations suivantes :
bigquery.jobs.createbigquery.models.createbigquery.models.getDatabigquery.models.updateData
Pour exécuter une inférence, vous devez disposer des autorisations suivantes :
bigquery.models.getDatabigquery.jobs.create
Autorisations requises
Pour plus d'informations sur les rôles et les autorisations IAM dans BigQuery, consultez la page Présentation d'IAM.
Créer un ensemble de données
Créez un ensemble de données BigQuery pour stocker votre modèle de ML.
Console
Dans la console Google Cloud , accédez à la page BigQuery.
Dans le volet Explorateur, cliquez sur le nom de votre projet.
Cliquez sur Afficher les actions > Créer un ensemble de données.
Sur la page Créer un ensemble de données, procédez comme suit :
Dans le champ ID de l'ensemble de données, saisissez
bqml_tutorial.Pour Type d'emplacement, sélectionnez Multirégional, puis sélectionnez US (plusieurs régions aux États-Unis).
Conservez les autres paramètres par défaut, puis cliquez sur Créer un ensemble de données.
bq
Pour créer un ensemble de données, exécutez la commande bq mk en spécifiant l'option --location. Pour obtenir la liste complète des paramètres possibles, consultez la documentation de référence sur la commande bq mk --dataset.
Créez un ensemble de données nommé
bqml_tutorialavec l'emplacement des données défini surUSet une description deBigQuery ML tutorial dataset:bq --location=US mk -d \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
Au lieu d'utiliser l'option
--dataset, la commande utilise le raccourci-d. Si vous omettez-det--dataset, la commande crée un ensemble de données par défaut.Vérifiez que l'ensemble de données a été créé :
bq ls
API
Appelez la méthode datasets.insert avec une ressource d'ensemble de données définie.
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
BigQuery DataFrames
Avant d'essayer cet exemple, suivez les instructions de configuration pour BigQuery DataFrames du guide de démarrage rapide de BigQuery DataFrames. Pour en savoir plus, consultez la documentation de référence sur BigQuery DataFrames.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer les ADC pour un environnement de développement local.
Créer un tableau de données d'entrée
Créez un tableau de données que vous pouvez utiliser pour entraîner et évaluer le modèle. Cette table combine des colonnes de plusieurs tables de l'ensemble de données bigquery-public-data.epa_historical_air_quality afin de fournir des données météorologiques quotidiennes. Vous devez également créer les colonnes suivantes à utiliser comme variables d'entrée pour le modèle :
date: date de l'observationpm25: concentration moyenne de particules fines PM2,5 enregistrée chaque jourwind_speed: vitesse moyenne du vent enregistrée chaque jourtemperature: température la plus élevée enregistrée chaque jour
Dans la requête GoogleSQL suivante, la clause FROM bigquery-public-data.epa_historical_air_quality.*_daily_summary indique que vous interrogez les tables *_daily_summary de l'ensemble de données epa_historical_air_quality. Ces tables sont des tables partitionnées.
Pour créer le tableau de données d'entrée, procédez comme suit :
Dans la console Google Cloud , accédez à la page BigQuery.
Dans l'éditeur de requête, collez la requête suivante, puis cliquez sur Exécuter :
CREATE TABLE `bqml_tutorial.seattle_air_quality_daily` AS WITH pm25_daily AS ( SELECT avg(arithmetic_mean) AS pm25, date_local AS date FROM `bigquery-public-data.epa_historical_air_quality.pm25_nonfrm_daily_summary` WHERE city_name = 'Seattle' AND parameter_name = 'Acceptable PM2.5 AQI & Speciation Mass' GROUP BY date_local ), wind_speed_daily AS ( SELECT avg(arithmetic_mean) AS wind_speed, date_local AS date FROM `bigquery-public-data.epa_historical_air_quality.wind_daily_summary` WHERE city_name = 'Seattle' AND parameter_name = 'Wind Speed - Resultant' GROUP BY date_local ), temperature_daily AS ( SELECT avg(first_max_value) AS temperature, date_local AS date FROM `bigquery-public-data.epa_historical_air_quality.temperature_daily_summary` WHERE city_name = 'Seattle' AND parameter_name = 'Outdoor Temperature' GROUP BY date_local ) SELECT pm25_daily.date AS date, pm25, wind_speed, temperature FROM pm25_daily JOIN wind_speed_daily USING (date) JOIN temperature_daily USING (date);
Visualiser les données d'entrée
Avant de créer le modèle, vous pouvez éventuellement visualiser vos données de série temporelle d'entrée pour avoir une idée de la distribution. Pour ce faire, utilisez Looker Studio.
Pour visualiser les données de série temporelle, procédez comme suit :
Dans la console Google Cloud , accédez à la page BigQuery.
Dans l'éditeur de requête, collez la requête suivante, puis cliquez sur Exécuter :
SELECT * FROM `bqml_tutorial.seattle_air_quality_daily`;
Une fois la requête terminée, cliquez sur Explorer les données > Explorer avec Looker Studio. Looker Studio s'ouvre dans un nouvel onglet. Procédez comme suit dans le nouvel onglet.
Dans Looker Studio, cliquez sur Insérer > Graphique de séries temporelles.
Dans le volet Graphique, sélectionnez l'onglet Configuration.
Dans la section Métrique, ajoutez les champs pm25, temperature et wind_speed, puis supprimez la métrique par défaut Nombre d'enregistrements. Le graphique obtenu ressemble à ceci :
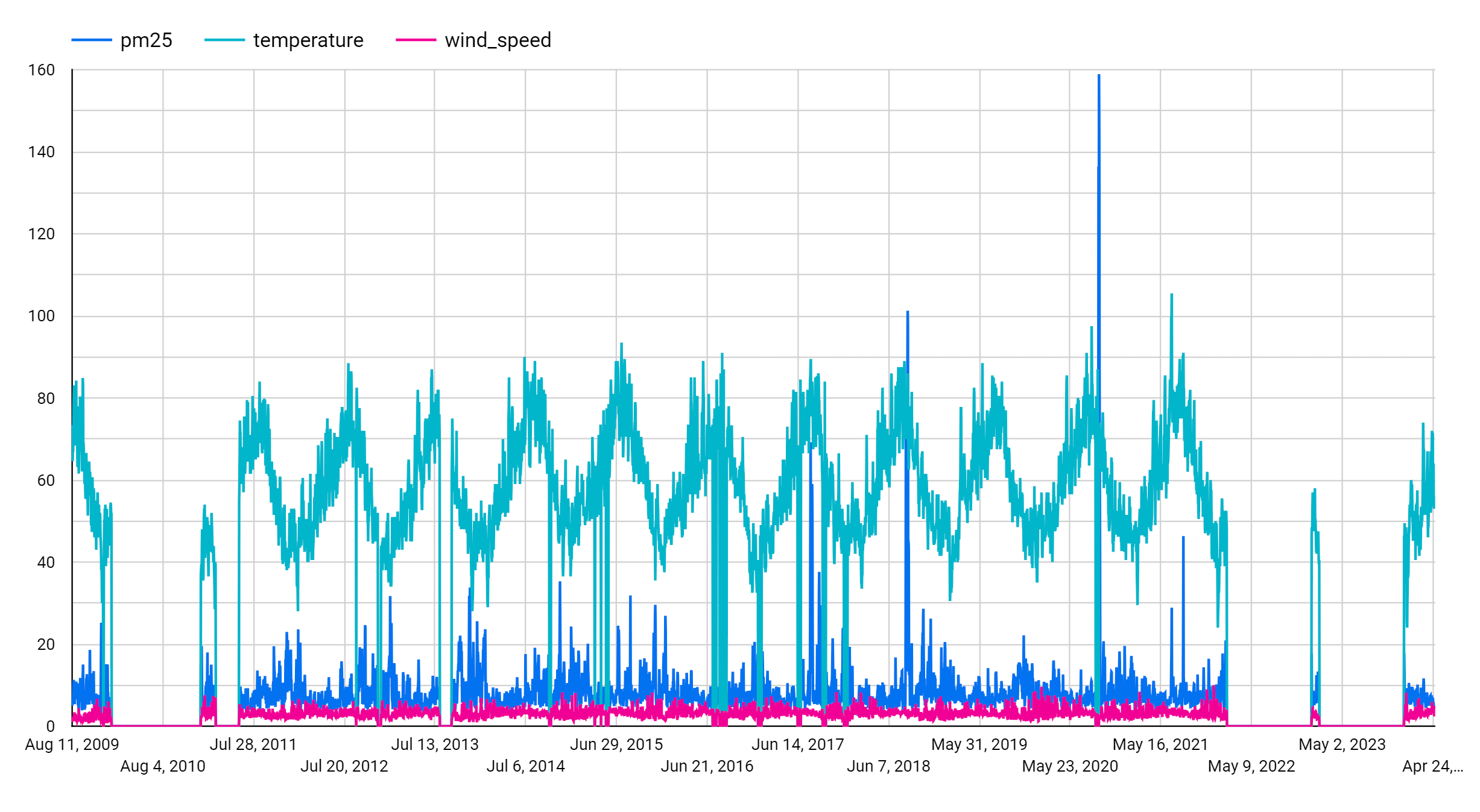
Le graphique montre que la série temporelle d'entrée présente une tendance saisonnière hebdomadaire.
Créer le modèle de série temporelle
Créez un modèle de série temporelle pour prévoir les valeurs des particules, telles que représentées par la colonne pm25, en utilisant les valeurs des colonnes pm25, wind_speed et temperature comme variables d'entrée. Entraînez le modèle sur les données de qualité de l'air de la table bqml_tutorial.seattle_air_quality_daily, en sélectionnant les données collectées entre le 1er janvier 2012 et le 31 décembre 2020.
Dans la requête suivante, la clause OPTIONS(model_type='ARIMA_PLUS_XREG',
time_series_timestamp_col='date', ...) indique que vous créez un modèle ARIMA avec des régresseurs externes. L'option auto_arima de l'instruction CREATE MODEL est définie par défaut sur TRUE. L'algorithme auto.ARIMA ajuste donc automatiquement les hyperparamètres du modèle. L'algorithme s'adapte à des dizaines de modèles candidats et choisit le meilleur d'entre eux, qui présente l'AIC (Akaike information criterion) le plus faible.
L'option data_frequency des instructions CREATE MODEL est définie par défaut sur AUTO_FREQUENCY. Le processus d'entraînement déduit donc automatiquement la fréquence des données de la série temporelle d'entrée.
Pour créer le modèle, procédez comme suit :
Dans la console Google Cloud , accédez à la page BigQuery.
Dans l'éditeur de requête, collez la requête suivante, puis cliquez sur Exécuter :
CREATE OR REPLACE MODEL `bqml_tutorial.seattle_pm25_xreg_model` OPTIONS ( MODEL_TYPE = 'ARIMA_PLUS_XREG', time_series_timestamp_col = 'date', # Identifies the column that contains time points time_series_data_col = 'pm25') # Identifies the column to forecast AS SELECT date, # The column that contains time points pm25, # The column to forecast temperature, # Temperature input to use in forecasting wind_speed # Wind speed input to use in forecasting FROM `bqml_tutorial.seattle_air_quality_daily` WHERE date BETWEEN DATE('2012-01-01') AND DATE('2020-12-31');
L'exécution de la requête prend environ 20 secondes, après quoi le modèle
seattle_pm25_xreg_modelapparaît dans le volet Explorateur. Étant donné que la requête utilise une instructionCREATE MODELpour créer un modèle, les résultats de la requête ne sont pas affichés.
Évaluer les modèles candidats
Évaluez les modèles de séries temporelles à l'aide de la fonction ML.ARIMA_EVALUATE. La fonction ML.ARIMA_EVALUATE affiche les métriques d'évaluation de tous les modèles candidats évalués lors du processus de réglage automatique des hyperparamètres.
Pour évaluer le modèle, procédez comme suit :
Dans la console Google Cloud , accédez à la page BigQuery.
Dans l'éditeur de requête, collez la requête suivante, puis cliquez sur Exécuter :
SELECT * FROM ML.ARIMA_EVALUATE(MODEL `bqml_tutorial.seattle_pm25_xreg_model`);
Le résultat doit ressembler à ce qui suit :

Les colonnes de sortie
non_seasonal_p,non_seasonal_d,non_seasonal_qethas_driftdéfinissent un modèle ARIMA dans le pipeline d'entraînement. Les colonnes de sortielog_likelihood,AICetvariancesont pertinentes pour le processus d'ajustement du modèle ARIMA.L'algorithme
auto.ARIMAutilise le test KPSS pour déterminer la meilleure valeur pournon_seasonal_d, qui est1dans ce cas. Lorsquenon_seasonal_dest défini sur1, l'algorithmeauto.ARIMAentraîne 42 modèles ARIMA candidats différents en parallèle. Dans cet exemple, les 42 modèles candidats sont valides. La sortie contient donc 42 lignes, une pour chaque modèle ARIMA candidat. Si certains modèles ne sont pas valides, ils sont exclus de la sortie. Ces modèles candidats sont renvoyés par ordre croissant de l'AIC. Le modèle de la première ligne présente l'AIC le plus bas, et il est considéré comme le meilleur modèle. Le meilleur modèle est enregistré en tant que modèle final. Il est utilisé lorsque vous appelez des fonctions telles queML.FORECASTsur le modèle.La colonne
seasonal_periodscontient des informations sur la tendance saisonnière identifiée dans les données de série temporelle. Il n'a rien à voir avec la modélisation ARIMA. Par conséquent, il présente la même valeur sur toutes les lignes de sortie. Il indique un schéma hebdomadaire, ce qui correspond aux résultats que vous avez obtenus si vous avez choisi de visualiser les données d'entrée.Les colonnes
has_holiday_effect,has_spikes_and_dipsethas_step_changesfournissent des informations sur les données de série temporelle d'entrée et ne sont pas liées à la modélisation ARIMA. Ces colonnes sont renvoyées, car la valeur de l'optiondecompose_time_seriesdans l'instructionCREATE MODELestTRUE. Ces colonnes ont également les mêmes valeurs dans toutes les lignes de sortie.La colonne
error_messageindique les erreurs survenues lors du processus d'ajustementauto.ARIMA. Les erreurs peuvent s'expliquer par le fait que les colonnesnon_seasonal_p,non_seasonal_d,non_seasonal_qethas_driftsélectionnées ne peuvent pas stabiliser la série temporelle. Pour récupérer le message d'erreur de tous les modèles candidats, définissez l'optionshow_all_candidate_modelssurTRUElorsque vous créez le modèle.Pour en savoir plus sur les colonnes de sortie, consultez la fonction
ML.ARIMA_EVALUATE.
Inspecter les coefficients du modèle
Inspectez les coefficients du modèle de série temporelle à l'aide de la fonction ML.ARIMA_COEFFICIENTS.
Pour récupérer les coefficients du modèle, procédez comme suit :
Dans la console Google Cloud , accédez à la page BigQuery.
Dans l'éditeur de requête, collez la requête suivante, puis cliquez sur Exécuter :
SELECT * FROM ML.ARIMA_COEFFICIENTS(MODEL `bqml_tutorial.seattle_pm25_xreg_model`);
Le résultat doit ressembler à ce qui suit :
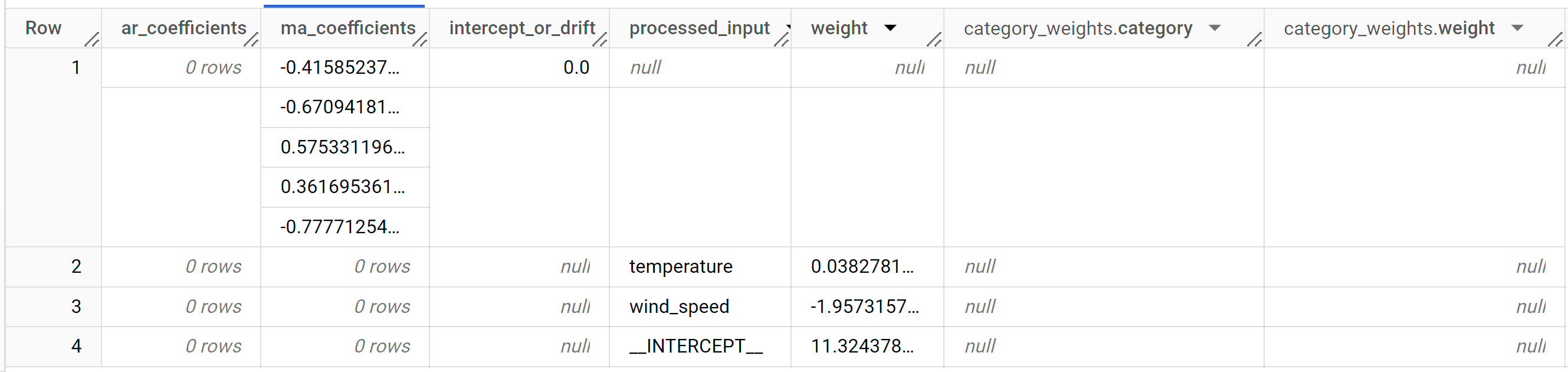
La colonne de sortie
ar_coefficientsaffiche les coefficients de modèle de la partie autorégressive (AR) du modèle ARIMA. De même, la colonne de sortiema_coefficientsaffiche les coefficients de modèle de la partie moyenne mobile (MA) du modèle ARIMA. Ces deux colonnes contiennent des valeurs de tableau, dont la longueur est respectivement égale ànon_seasonal_petnon_seasonal_q. Dans la sortie de la fonctionML.ARIMA_EVALUATE, vous avez vu que le meilleur modèle avait une valeurnon_seasonal_pde0et une valeurnon_seasonal_qde5. Par conséquent, dans la sortieML.ARIMA_COEFFICIENTS, la valeurar_coefficientsest un tableau vide et la valeurma_coefficientsest un tableau à cinq éléments. La valeurintercept_or_driftest le terme constant dans le modèle ARIMA.Les colonnes de sortie
processed_input,weightetcategory_weightsindiquent la pondération de chaque caractéristique et l'interception dans le modèle de régression linéaire. Si la caractéristique est une caractéristique numérique, la pondération se trouve dans la colonneweight. Si la caractéristique est une caractéristique catégorielle, la valeurcategory_weightsest un tableau de valeurs structurées, où chaque valeur structurée contient le nom et la pondération d'une catégorie donnée.Pour en savoir plus sur les colonnes de sortie, consultez la fonction
ML.ARIMA_COEFFICIENTS.
Utiliser le modèle pour prévoir des données
Prévoyez les valeurs futures des séries temporelles à l'aide de la fonction ML.FORECAST.
Dans la requête GoogleSQL suivante, la clause STRUCT(30 AS horizon, 0.8 AS confidence_level) indique que la requête prévoit 30 points temporels futurs et génère un intervalle de prédiction avec un niveau de confiance de 80 %.
Pour prévoir des données avec le modèle, procédez comme suit :
Dans la console Google Cloud , accédez à la page BigQuery.
Dans l'éditeur de requête, collez la requête suivante, puis cliquez sur Exécuter :
SELECT * FROM ML.FORECAST( MODEL `bqml_tutorial.seattle_pm25_xreg_model`, STRUCT(30 AS horizon, 0.8 AS confidence_level), ( SELECT date, temperature, wind_speed FROM `bqml_tutorial.seattle_air_quality_daily` WHERE date > DATE('2020-12-31') ));
Le résultat doit ressembler à ce qui suit :
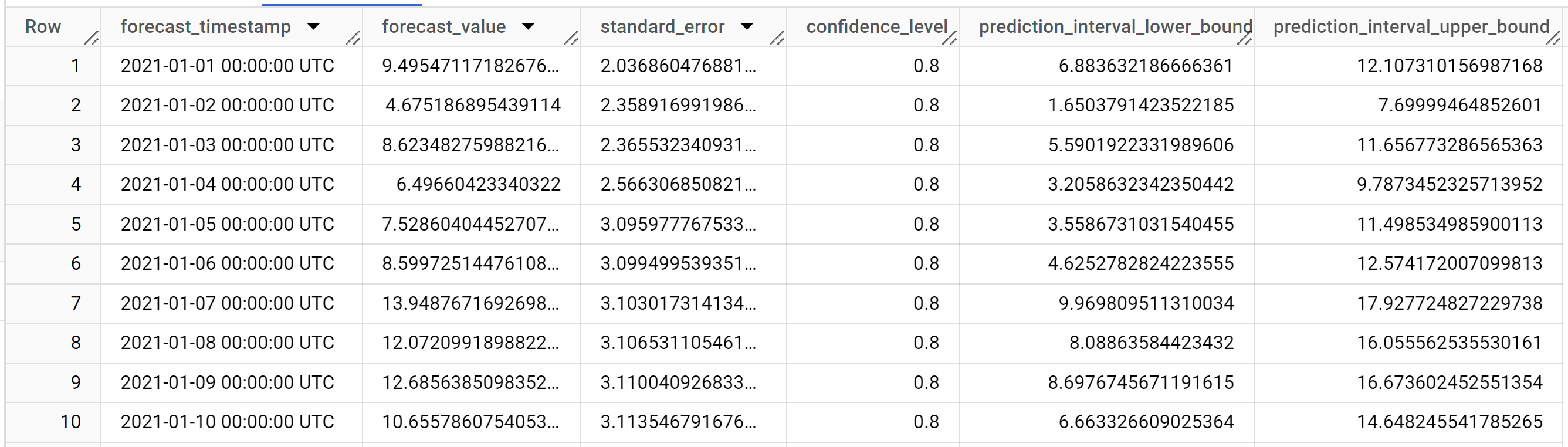
Les lignes de sortie sont dans l'ordre chronologique de la valeur de la colonne
forecast_timestamp. Dans les prévisions de séries temporelles, l'intervalle de prédiction, tel qu'il est représenté par les valeurs des colonnesprediction_interval_lower_boundetprediction_interval_upper_bound, est aussi important que la valeur de la colonneforecast_value. La valeurforecast_valueest le point central de l'intervalle de prédiction. L'intervalle de prédiction dépend des valeurs des colonnesstandard_erroretconfidence_level.Pour en savoir plus sur les colonnes de sortie, consultez la fonction
ML.FORECAST.
Évaluer la précision des prévisions
Évaluez la précision des prévisions du modèle à l'aide de la fonction ML.EVALUATE.
Dans la requête GoogleSQL suivante, la deuxième instruction SELECT fournit les données avec les caractéristiques futures, qui permettent de prévoir les valeurs futures à comparer aux données réelles.
Pour évaluer la précision du modèle, procédez comme suit :
Dans la console Google Cloud , accédez à la page BigQuery.
Dans l'éditeur de requête, collez la requête suivante, puis cliquez sur Exécuter :
SELECT * FROM ML.EVALUATE( MODEL `bqml_tutorial.seattle_pm25_xreg_model`, ( SELECT date, pm25, temperature, wind_speed FROM `bqml_tutorial.seattle_air_quality_daily` WHERE date > DATE('2020-12-31') ), STRUCT( TRUE AS perform_aggregation, 30 AS horizon));
Les résultats doivent ressembler à ce qui suit :

Pour en savoir plus sur les colonnes de sortie, consultez la fonction
ML.EVALUATE.
Expliquer les résultats des prévisions
Vous pouvez obtenir des métriques d'explicabilité en plus des données de prévision à l'aide de la fonction ML.EXPLAIN_FORECAST. La fonction ML.EXPLAIN_FORECAST prédit les valeurs futures des séries temporelles et renvoie également tous les composants distincts de la série temporelle.
Comme la fonction ML.FORECAST, la clause STRUCT(30 AS horizon, 0.8 AS confidence_level) utilisée dans la fonction ML.EXPLAIN_FORECAST indique que la requête prévoit 30 points temporels futurs et génère un intervalle de prédiction avec un indice de confiance de 80 %.
Pour expliquer les résultats du modèle, procédez comme suit :
Dans la console Google Cloud , accédez à la page BigQuery.
Dans l'éditeur de requête, collez la requête suivante, puis cliquez sur Exécuter :
SELECT * FROM ML.EXPLAIN_FORECAST( MODEL `bqml_tutorial.seattle_pm25_xreg_model`, STRUCT(30 AS horizon, 0.8 AS confidence_level), ( SELECT date, temperature, wind_speed FROM `bqml_tutorial.seattle_air_quality_daily` WHERE date > DATE('2020-12-31') ));
Le résultat doit ressembler à ce qui suit :
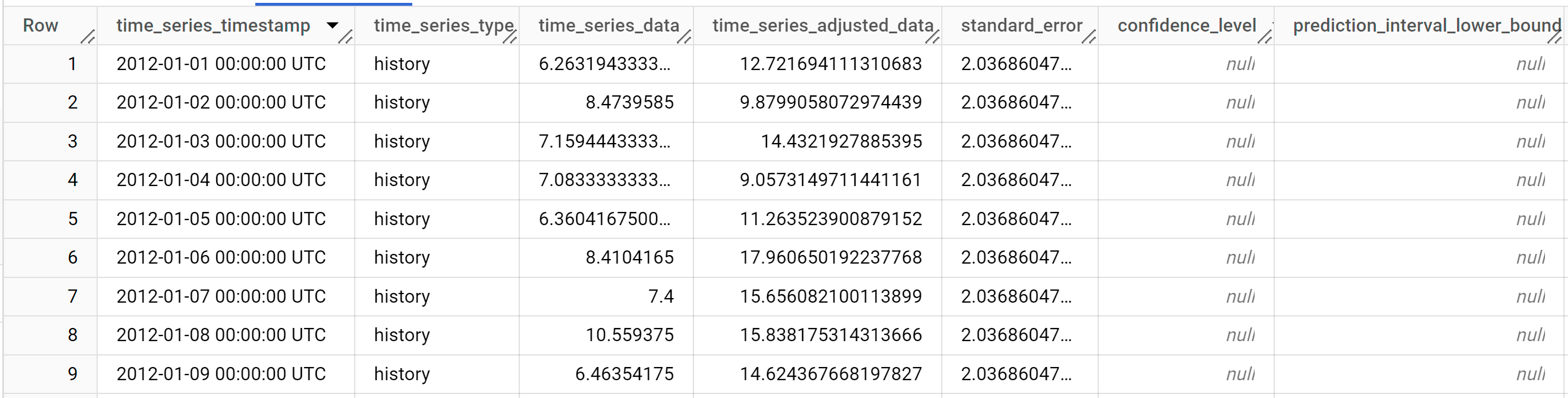
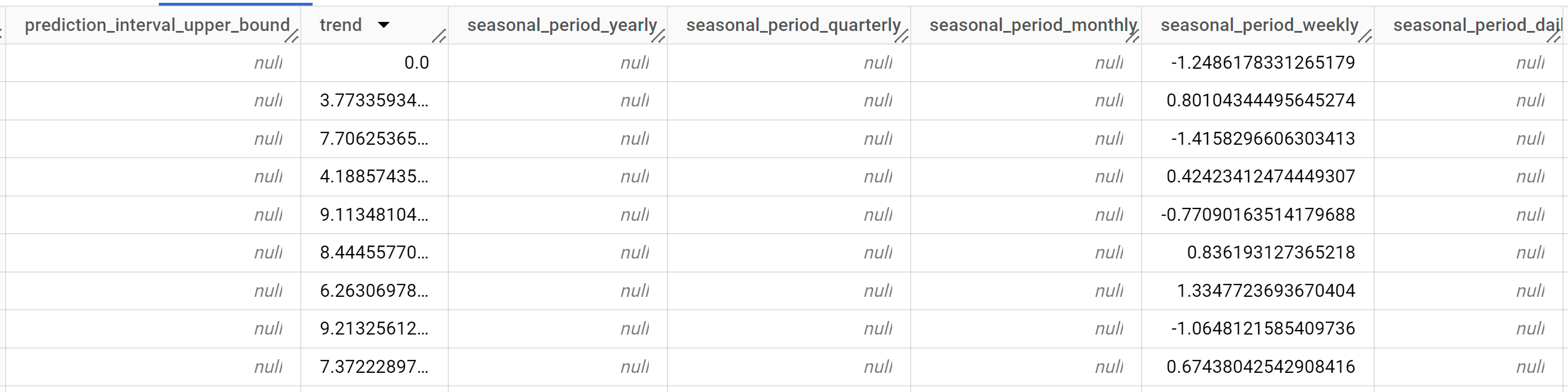
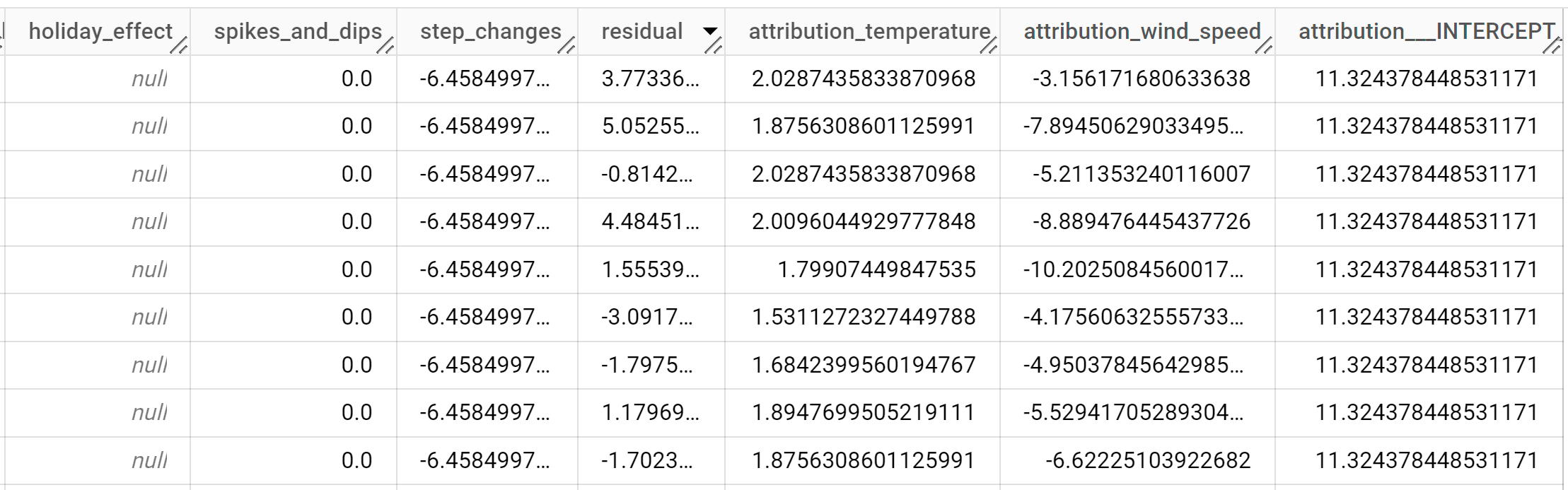
Les lignes de sortie sont triées par ordre chronologique en fonction de la valeur de la colonne
time_series_timestamp.Pour en savoir plus sur les colonnes de sortie, consultez la fonction
ML.EXPLAIN_FORECAST.
Effectuer un nettoyage
Pour éviter que les ressources utilisées lors de ce tutoriel soient facturées sur votre compte Google Cloud, supprimez le projet contenant les ressources, ou conservez le projet et supprimez les ressources individuelles.
- Supprimez le projet que vous avez créé.
- Ou conservez le projet et supprimez l'ensemble de données.
Supprimer l'ensemble de données
Si vous supprimez votre projet, tous les ensembles de données et toutes les tables qui lui sont associés sont également supprimés. Si vous préférez réutiliser le projet, vous pouvez supprimer l'ensemble de données que vous avez créé dans ce tutoriel :
Si nécessaire, ouvrez la page BigQuery dans la consoleGoogle Cloud .
Dans le panneau de navigation, cliquez sur l'ensemble de données bqml_tutorial que vous avez créé.
Cliquez sur Delete dataset (Supprimer l'ensemble de données) dans la partie droite de la fenêtre. Cette action supprime l'ensemble de données, la table et toutes les données.
Dans la boîte de dialogue Supprimer l'ensemble de données, confirmez la commande de suppression en saisissant le nom de votre ensemble de données (
bqml_tutorial), puis cliquez sur Supprimer.
Supprimer votre projet
Pour supprimer le projet :
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Étapes suivantes
- Découvrez comment prévoir une seule série temporelle avec un modèle univarié.
- Découvrez comment prévoir plusieurs séries temporelles avec un modèle univarié.
- Découvrez comment mettre à l'échelle un modèle univarié lorsque vous prévoyez plusieurs séries temporelles sur plusieurs lignes.
- Découvrez comment prévoir hiérarchiquement plusieurs séries temporelles avec un modèle univarié.
- Pour obtenir plus d'informations sur BigQuery ML, consultez la présentation de l'IA et du ML dans BigQuery.