本教程介绍了如何使用单变量时序模型根据给定列的历史值来预测该列的未来值。
本教程介绍了如何预测多个时序。系统会针对一个或多个指定列中的每个值,为每个时间点计算预测值。例如,如果您要预测天气,并指定了包含城市数据的列,则预测数据将包含城市 A 的所有时间点的预测值,然后是城市 B 的所有时间点的预测值,以此类推。
本教程使用公共 bigquery-public-data.new_york.citibike_trips 表中的数据。此表包含有关纽约市花旗单车行程的信息。
在阅读本教程之前,我们强烈建议您阅读使用单变量模型预测单个时序。
目标
本教程将指导您完成以下任务:
- 使用
CREATE MODEL语句创建时序模型,以预测骑行次数。 - 使用
ML.ARIMA_EVALUATE函数评估模型中的自动回归集成移动平均线 (ARIMA) 信息。 - 使用
ML.ARIMA_COEFFICIENTS函数检查模型系数。 - 使用
ML.FORECAST函数从模型中检索预测的骑行信息。 - 使用
ML.EXPLAIN_FORECAST函数检索时序的组件,例如季节性和趋势。您可以检查这些时序组成部分,以便解释预测值。
费用
本教程使用 Google Cloud 的以下收费组件:
- BigQuery
- BigQuery ML
如需详细了解 BigQuery 费用,请参阅 BigQuery 价格页面。
如需详细了解 BigQuery ML 费用,请参阅 BigQuery ML 价格。
准备工作
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
- 新项目会自动启用 BigQuery。如需在现有项目中激活 BigQuery,请前往
Enable the BigQuery API.
所需权限
- 如需创建数据集,您需要拥有
bigquery.datasets.createIAM 权限。 如需创建连接资源,您需要以下权限:
bigquery.connections.createbigquery.connections.get
如需创建模型,您需要以下权限:
bigquery.jobs.createbigquery.models.createbigquery.models.getDatabigquery.models.updateDatabigquery.connections.delegate
如需运行推理,您需要以下权限:
bigquery.models.getDatabigquery.jobs.create
如需详细了解 BigQuery 中的 IAM 角色和权限,请参阅 IAM 简介。
创建数据集
创建 BigQuery 数据集以存储您的机器学习模型:
在 Google Cloud 控制台中,转到 BigQuery 页面。
在探索器窗格中,点击您的项目名称。
点击 查看操作 > 创建数据集。
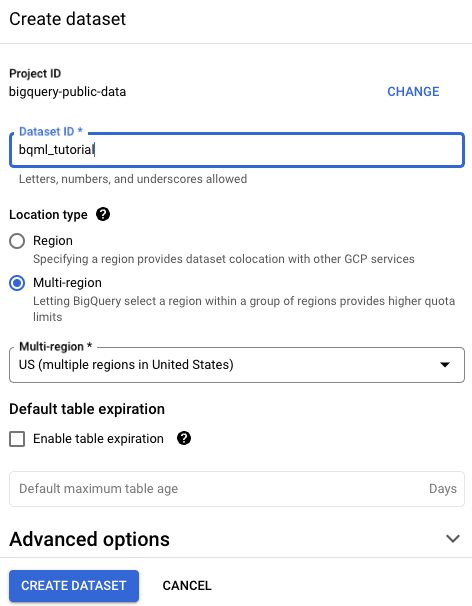
在创建数据集页面上,执行以下操作:
在数据集 ID 部分,输入
bqml_tutorial。在位置类型部分,选择多区域,然后选择 US (multiple regions in United States)(美国[美国的多个区域])。
公共数据集存储在
US多区域中。为简单起见,请将数据集存储在同一位置。保持其余默认设置不变,然后点击创建数据集。
直观呈现输入数据
在创建模型之前,您可以选择可视化输入时序数据,以了解其分布情况。您可以使用 Looker 数据洞察执行此操作。
以下查询的 SELECT 语句使用 EXTRACT 函数从 starttime 列中提取日期信息。该查询使用 COUNT(*) 子句获取花旗单车的每日总行程数。
如需可视化时序数据,请按以下步骤操作:
在 Google Cloud 控制台中,转到 BigQuery 页面。
在查询编辑器中,粘贴以下查询,然后点击运行:
SELECT EXTRACT(DATE from starttime) AS date, COUNT(*) AS num_trips FROM `bigquery-public-data.new_york.citibike_trips` GROUP BY date;
查询完成后,依次点击探索数据 > Explore with Looker Studio(使用 Looker 数据洞察探索)。Looker 数据洞察将在新标签页中打开。在该新标签页中完成以下步骤。
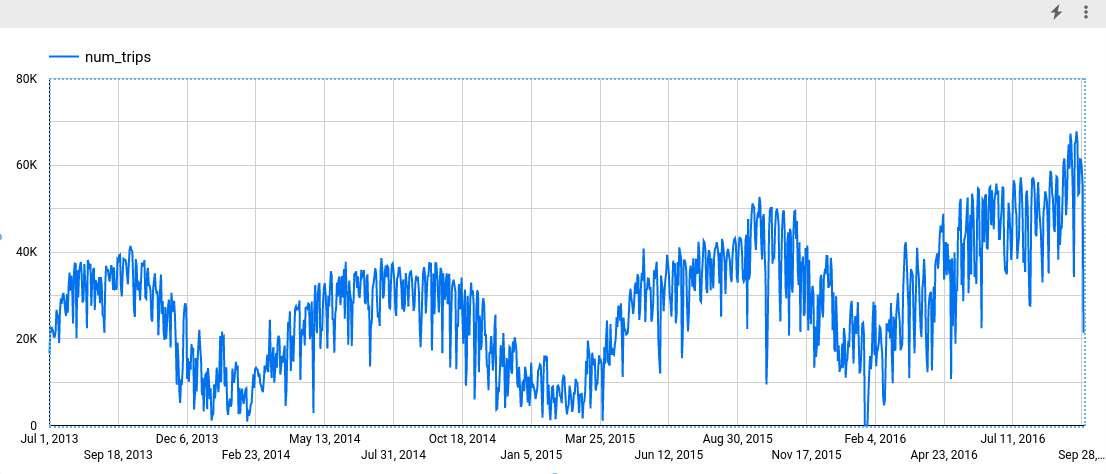
在 Looker Studio 中,依次点击插入 > 时间序列图表。
在图表窗格中,选择设置标签页。
在指标部分中,添加 num_trips 字段,然后移除默认的 Record Count 指标。生成的图表类似于以下内容:
创建时序模型
您希望预测每个 Citi Bike 站点的单车行程数,这需要许多时序模型;输入数据中包含的每个 Citi Bike 站点对应一个模型。您可以编写多个 CREATE MODEL 查询来执行此操作,但这可能会是一个单调乏味且耗时的过程,尤其是当您有大量时序时。相反,您可以使用单个查询创建和拟合一组时序模型,以便一次预测多个时序。
在以下查询中,OPTIONS(model_type='ARIMA_PLUS', time_series_timestamp_col='date', ...) 子句指示您正在创建一个基于 ARIMA 的时序模型。您可以使用 CREATE MODEL 语句的 time_series_id_col 选项指定输入数据中您想要获取预测结果的一个或多个列,在本例中,就是要预测的 Citi Bike 站,由 start_station_name 列表示。您可以使用 WHERE 子句将起始站点限定为名称中包含 Central Park 的站点。CREATE MODEL 语句的 auto_arima_max_order 选项可控制 auto.ARIMA 算法中超参数调节的搜索空间。CREATE MODEL 语句的 decompose_time_series 选项默认为 TRUE,以便在您在下一步中评估模型时返回有关时序数据的信息。
请按照以下步骤创建模型:
在 Google Cloud 控制台中,转到 BigQuery 页面。
在查询编辑器中,粘贴以下查询,然后点击运行:
CREATE OR REPLACE MODEL `bqml_tutorial.nyc_citibike_arima_model_group` OPTIONS (model_type = 'ARIMA_PLUS', time_series_timestamp_col = 'date', time_series_data_col = 'num_trips', time_series_id_col = 'start_station_name', auto_arima_max_order = 5 ) AS SELECT start_station_name, EXTRACT(DATE from starttime) AS date, COUNT(*) AS num_trips FROM `bigquery-public-data.new_york.citibike_trips` WHERE start_station_name LIKE '%Central Park%' GROUP BY start_station_name, date;
查询大约需要 24 秒才能完成,之后
nyc_citibike_arima_model_group模型会显示在探索器窗格中。由于查询使用CREATE MODEL语句,因此您看不到查询结果。
此查询将创建 12 个时序模型,输入数据中的 12 个 Citi Bike 起点站各对应一个模型。由于是并行执行的,因此时间成本(大约 24 秒)仅比创建单个时序模型的时间成本多 1.4 倍。但是,如果您移除 WHERE ... LIKE ... 子句,则系统将预测 600 多个时序;由于槽容量有限,系统将无法完全并行预测这些时序。在这种情况下,查询大约需要 15 分钟才能完成。如需降低查询运行时,同时模型质量可能略微降低,您可以将 auto_arima_max_order 选项的值从默认值 5 降低到 3 或 4。这会缩小 auto.ARIMA 算法中超参数调节的搜索空间。如需了解详情,请参阅 Large-scale time series forecasting best practices。
评估模型
使用 ML.ARIMA_EVALUATE 函数评估时序模型。ML.ARIMA_EVALUATE 函数会显示自动超参数调整过程中为模型生成的评估指标。
请按照以下步骤评估模型:
在 Google Cloud 控制台中,转到 BigQuery 页面。
在查询编辑器中,粘贴以下查询,然后点击运行:
SELECT * FROM ML.ARIMA_EVALUATE(MODEL `bqml_tutorial.nyc_citibike_arima_model_group`);
结果应如下所示:
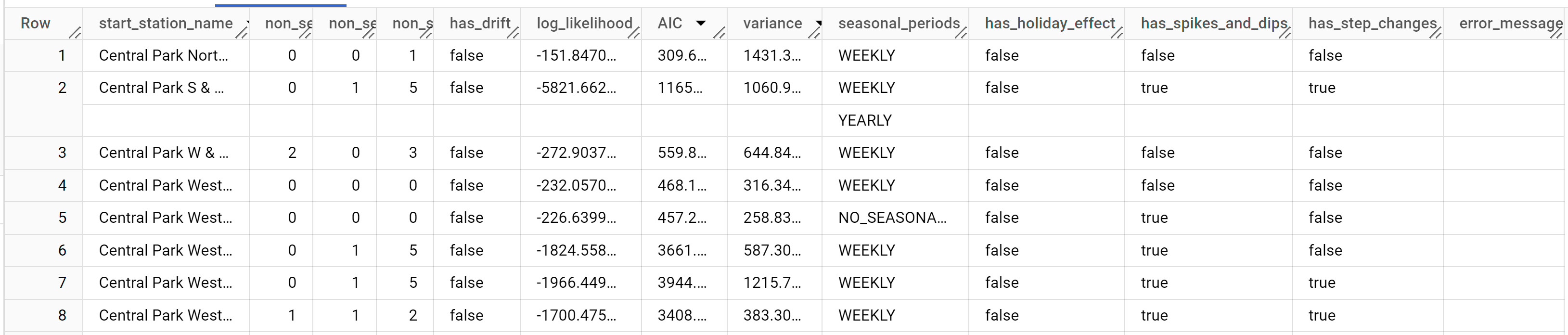
start_station_name列用于标识为创建时序而使用的输入数据列。这是您在CREATE MODEL语句的time_series_id_col选项中指定的列。non_seasonal_p、non_seasonal_d、non_seasonal_q和has_drift输出列定义了训练流水线中的 ARIMA 模型。log_likelihood、AIC和variance输出列与 ARIMA 模型拟合过程相关。拟合过程通过使用auto.ARIMA算法确定最佳的 ARIMA 模型(每个时序对应一个最佳模型)。auto.ARIMA算法使用 KPSS 测试来确定non_seasonal_d的最佳值,在本例中为1。当non_seasonal_d为1时,auto.ARIMA 算法会并行训练 42 个不同的候选 ARIMA 模型。在此示例中,所有 42 个候选模型均有效,因此输出将包含 42 行,每行对应一个候选 ARIMA 模型;如果其中一些模型无效,则会从输出中排除。这些候选模型将按照 AIC 升序返回。第一行中的模型具有最低的 AIC,它被视为最佳模型。此最佳模型将保存为最终模型,并在您调用ML.FORECAST、ML.EVALUATE和ML.ARIMA_COEFFICIENTS时使用,如以下步骤所示。seasonal_periods列包含有关时序数据中识别出的季节性模式的信息。每个时序可以有不同的季节性模式。例如,您可以从图中看到一个时序具有一个每年模式,而其他时序则没有。仅当
decompose_time_series=TRUE时,才会填充has_holiday_effect、has_spikes_and_dips和has_step_changes列。这些列还反映了输入时序数据的相关信息,与 ARIMA 建模无关。这些列在所有输出行中的值也相同。如需详细了解输出列,请参阅
ML.ARIMA_EVALUATE函数。
虽然 auto.ARIMA 会为每个时序评估几十个候选 ARIMA 模型,但 ML.ARIMA_EVALUATE 默认只会输出最佳模型的信息,以使得输出表紧凑。如需查看所有候选模型,您可以将 ML.ARIMA_EVALUATE 函数的 show_all_candidate_model 参数设置为 TRUE。
检查模型的系数
使用 ML.ARIMA_COEFFICIENTS 函数检查时序模型的系数。
如需检索模型的系数,请按以下步骤操作:
在 Google Cloud 控制台中,转到 BigQuery 页面。
在查询编辑器中,粘贴以下查询,然后点击运行:
SELECT * FROM ML.ARIMA_COEFFICIENTS(MODEL `bqml_tutorial.nyc_citibike_arima_model_group`);
查询只需不到一秒的时间即可完成。结果应如下所示:
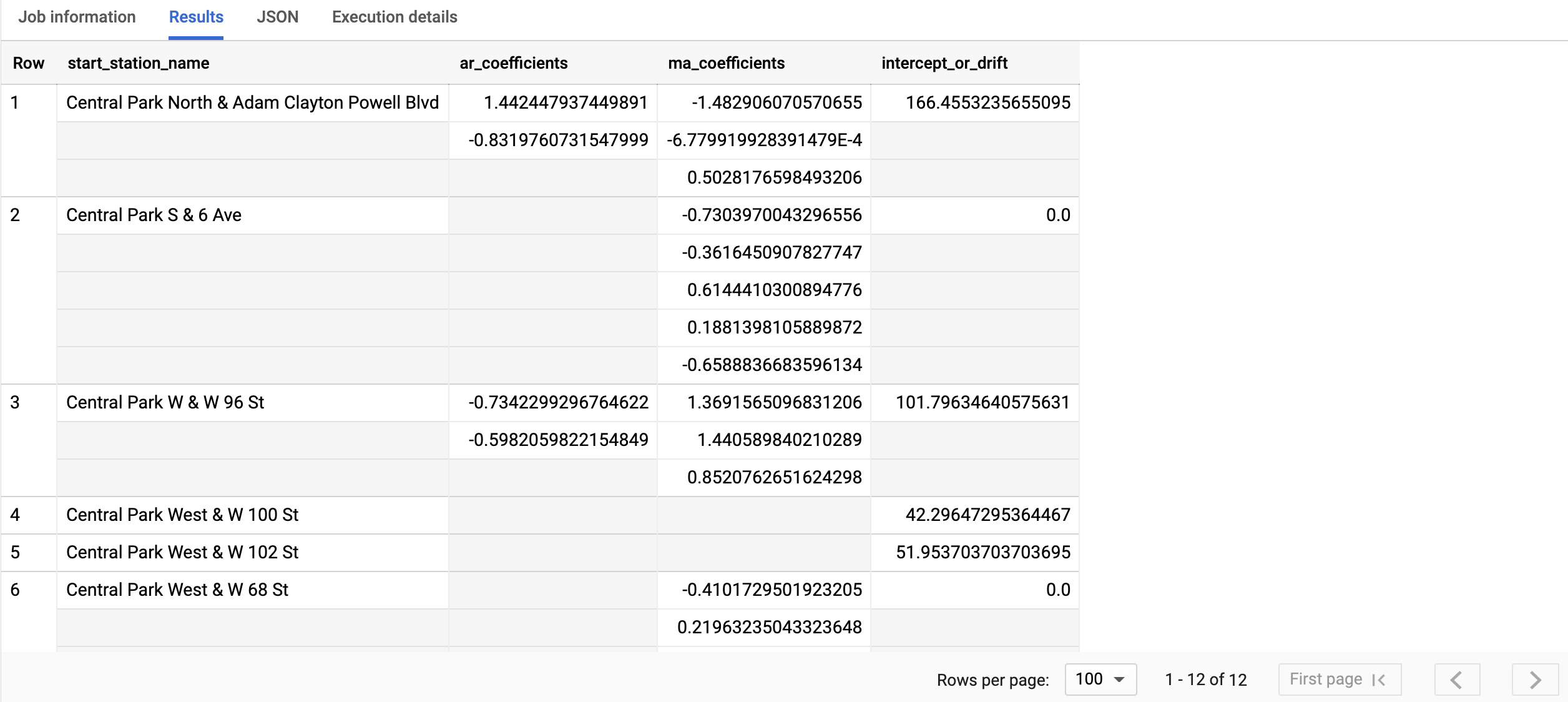
start_station_name列用于标识为创建时序而使用的输入数据列。这是您在CREATE MODEL语句的time_series_id_col选项中指定的列。ar_coefficients输出列显示了 ARIMA 模型的自动回归 (AR) 部分的模型系数。同样,ma_coefficients输出列显示了 ARIMA 模型的移动平均 (MA) 部分的模型系数。这两个列都包含数组值,其长度分别等于non_seasonal_p和non_seasonal_q。intercept_or_drift值是 ARIMA 模型中的常量项。如需详细了解输出列,请参阅
ML.ARIMA_COEFFICIENTS函数。
使用模型预测数据
使用 ML.FORECAST 函数预测未来的时序值。
在以下 GoogleSQL 查询中,STRUCT(3 AS horizon, 0.9 AS confidence_level) 子句指示查询会预测 3 个未来的时间点,并生成置信度为 90% 的预测区间。
如需使用模型预测数据,请按以下步骤操作:
在 Google Cloud 控制台中,转到 BigQuery 页面。
在查询编辑器中,粘贴以下查询,然后点击运行:
SELECT * FROM ML.FORECAST(MODEL `bqml_tutorial.nyc_citibike_arima_model_group`, STRUCT(3 AS horizon, 0.9 AS confidence_level))
点击运行。
查询只需不到一秒的时间即可完成。结果应如下所示:
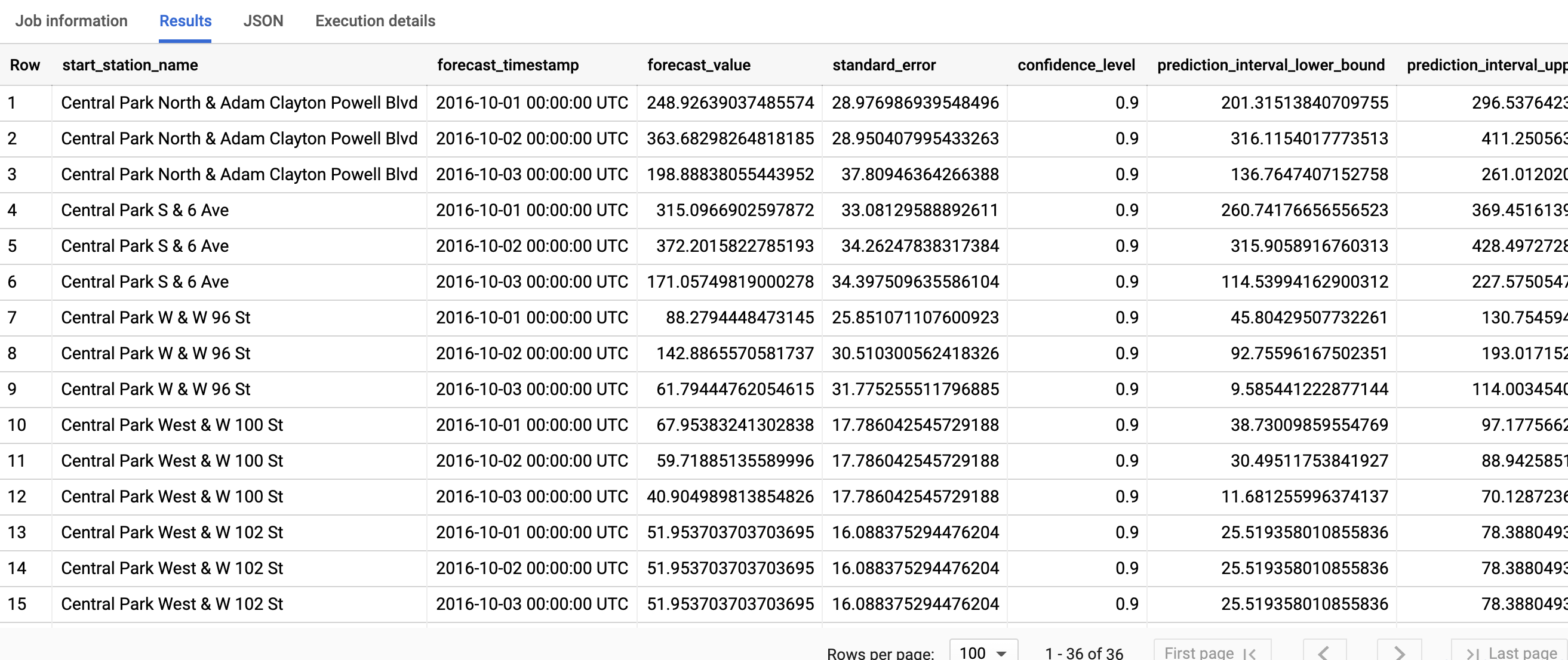
第一列
start_station_name注释系统拟合每个时序模型所依据的时序。每个start_station_name都有三行预测结果,如horizon值所指定。对于每个
start_station_name,输出行将按forecast_timestamp列值的时间顺序排序。在时序预测中,由prediction_interval_lower_bound和prediction_interval_upper_bound列值表示的预测区间与forecast_value列值一样重要。forecast_value值是预测区间的中点。预测区间取决于standard_error和confidence_level列值。如需详细了解输出列,请参阅
ML.FORECAST函数。
解释预测结果
除了预测数据之外,您还可以使用 ML.EXPLAIN_FORECAST 函数获取可解释性指标。ML.EXPLAIN_FORECAST 函数会预测未来的时序值,同时返回该时序的所有单独的组件。如果您只想返回预测数据,请改用 ML.FORECAST 函数,如使用模型预测数据中所示。
ML.EXPLAIN_FORECAST 函数中使用的 STRUCT(3 AS horizon, 0.9 AS confidence_level) 子句指示查询会预测 3 个未来的时间点,并生成置信度为 90% 的预测区间。
请按照以下步骤解释模型的结果:
在 Google Cloud 控制台中,转到 BigQuery 页面。
在查询编辑器中,粘贴以下查询,然后点击运行:
SELECT * FROM ML.EXPLAIN_FORECAST(MODEL `bqml_tutorial.nyc_citibike_arima_model_group`, STRUCT(3 AS horizon, 0.9 AS confidence_level));
查询只需不到一秒的时间即可完成。结果应如下所示:


返回的前几千行都是历史数据。您必须滚动浏览结果,才能查看预测数据。
输出行先按
start_station_name排序,然后按time_series_timestamp列值的时间顺序排序。在时序预测中,由prediction_interval_lower_bound和prediction_interval_upper_bound列值表示的预测区间与forecast_value列值一样重要。forecast_value值是预测区间的中点。预测区间取决于standard_error和confidence_level列值。如需详细了解输出列,请参阅
ML.EXPLAIN_FORECAST。
清理
为避免因本教程中使用的资源导致您的 Google Cloud 账号产生费用,请删除包含这些资源的项目,或者保留项目但删除各个资源。
- 删除您在教程中创建的项目。
- 或者,保留项目但删除数据集。
删除数据集
删除项目也将删除项目中的所有数据集和所有表。如果您希望重复使用该项目,则可以删除在本教程中创建的数据集:
如有必要,请在 Google Cloud 控制台中打开 BigQuery 页面。
在导航窗格中,点击您创建的 bqml_tutorial 数据集。
点击删除数据集以删除数据集、表和所有数据。
在删除数据集对话框中,通过输入数据集的名称 (
bqml_tutorial) 来确认该删除命令,然后点击删除。
删除项目
要删除项目,请执行以下操作:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
后续步骤
- 了解如何使用单变量模型预测单个时序
- 了解如何使用多变量模型预测单个时序
- 了解如何在预测包含多行数据的多个时序时扩展单变量模型。
- 了解如何使用单变量模型对多个时序进行分层预测
- 如需大致了解 BigQuery ML,请参阅 BigQuery 中的 AI 和机器学习简介。