In questo tutorial, utilizzi un modello di regressione logistica binario in BigQuery ML per prevedere la fascia di reddito delle persone in base ai loro dati demografici. Un modello di regressione logistica binaria prevede se un valore rientra in una delle due categorie, in questo caso se il reddito annuo di una persona è superiore o inferiore a 50.000 $.
Questo tutorial utilizza il set di dati
bigquery-public-data.ml_datasets.census_adult_income. Questo set di dati contiene informazioni demografiche e sul reddito dei residenti negli Stati Uniti
nel 2000 e nel 2010.
Obiettivi
In questo tutorial imparerai a:- Crea un modello di regressione logistica.
- Valutare il modello.
- Fare previsioni utilizzando il modello.
- Spiega i risultati prodotti dal modello.
Costi
Questo tutorial utilizza componenti fatturabili di Google Cloud, tra cui:
- BigQuery
- BigQuery ML
Per ulteriori informazioni sui costi di BigQuery, consulta la pagina Prezzi di BigQuery.
Per ulteriori informazioni sui costi di BigQuery ML, vedi Prezzi di BigQuery ML.
Prima di iniziare
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the BigQuery API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.
Autorizzazioni obbligatorie
Per creare il modello utilizzando BigQuery ML, devi disporre delle seguenti autorizzazioni IAM:
bigquery.jobs.createbigquery.models.createbigquery.models.getDatabigquery.models.updateDatabigquery.models.updateMetadata
Per eseguire l'inferenza, devi disporre delle seguenti autorizzazioni:
bigquery.models.getDatasul modellobigquery.jobs.create
Introduzione
Un'attività comune nel machine learning è classificare i dati in uno dei due tipi,
noti come etichette. Ad esempio, un rivenditore potrebbe voler prevedere se un determinato cliente acquisterà un nuovo prodotto, in base ad altre informazioni su quel cliente. In questo caso, le due etichette potrebbero essere will buy e won't buy. Il rivenditore può creare un set di dati in modo che una colonna rappresenti entrambe le etichette e contenga anche informazioni sui clienti, come la loro posizione, gli acquisti precedenti e le preferenze segnalate. Il rivenditore può quindi utilizzare un modello di regressione logistica binaria che utilizza queste informazioni sui clienti per prevedere quale etichetta rappresenta meglio ogni cliente.
In questo tutorial, creerai un modello di regressione logistica binaria che prevede se il reddito di un intervistato del censimento degli Stati Uniti rientra in uno dei due intervalli in base agli attributi demografici dell'intervistato.
Crea un set di dati
Crea un set di dati BigQuery per archiviare il modello:
Nella console Google Cloud , vai alla pagina BigQuery.
Nel riquadro Explorer, fai clic sul nome del progetto.
Fai clic su Visualizza azioni > Crea set di dati.
Nella pagina Crea set di dati:
In ID set di dati, inserisci
census.Per Tipo di località, seleziona Più regioni e poi Stati Uniti (più regioni negli Stati Uniti).
I set di dati pubblici sono archiviati nella
USmultiregione. Per semplicità, archivia il set di dati nella stessa posizione.Lascia invariate le restanti impostazioni predefinite e fai clic su Crea set di dati.
Esaminare i dati
Esamina il set di dati e identifica le colonne da utilizzare come
dati di addestramento per il modello di regressione logistica. Seleziona 100 righe dalla tabella
census_adult_income:
SQL
Nella console Google Cloud , vai alla pagina BigQuery.
Nell'editor di query, esegui la seguente query GoogleSQL:
SELECT age, workclass, marital_status, education_num, occupation, hours_per_week, income_bracket, functional_weight FROM `bigquery-public-data.ml_datasets.census_adult_income` LIMIT 100;
I risultati sono simili ai seguenti:

BigQuery DataFrames
Prima di provare questo esempio, segui le istruzioni di configurazione di BigQuery DataFrames nella guida rapida di BigQuery che utilizza BigQuery DataFrames. Per ulteriori informazioni, consulta la documentazione di riferimento di BigQuery DataFrames.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per maggiori informazioni, vedi Configurare ADC per un ambiente di sviluppo locale.
I risultati della query mostrano che la colonna income_bracket nella tabella
census_adult_income ha solo uno dei due valori: <=50K o >50K.
Prepara i dati di esempio
In questo tutorial, prevedi il reddito dei partecipanti al censimento in base ai valori delle
seguenti colonne della tabella census_adult_income:
age: l'età del rispondente.workclass: la classe di lavoro eseguita. Ad esempio, ente pubblico locale, privato o lavoratore autonomo.marital_statuseducation_num: il grado di istruzione più alto del rispondente.occupationhours_per_week: ore lavorate a settimana.
Escludi le colonne che duplicano i dati. Ad esempio, la colonna education,
perché i valori delle colonne education e education_num esprimono
gli stessi dati in formati diversi.
La colonna functional_weight indica il numero di persone che l'organizzazione
censuaria ritiene rappresentato da una determinata riga. Poiché il valore di questa
colonna non è correlato al valore di income_bracket per una determinata riga, puoi
utilizzare il valore di questa colonna per separare i dati in set di addestramento, valutazione
e previsione creando una nuova colonna dataframe derivata dalla
colonna functional_weight. Etichetti l'80% dei dati per l'addestramento del modello, il 10% dei dati per la valutazione e il 10% dei dati per la previsione.
SQL
Crea una visualizzazione con i dati di esempio.
Questa visualizzazione viene utilizzata dall'istruzione CREATE MODEL più avanti in questo tutorial.
Esegui la query che prepara i dati di esempio:
Nella console Google Cloud , vai alla pagina BigQuery.
Nell'editor di query, esegui la query seguente:
CREATE OR REPLACE VIEW `census.input_data` AS SELECT age, workclass, marital_status, education_num, occupation, hours_per_week, income_bracket, CASE WHEN MOD(functional_weight, 10) < 8 THEN 'training' WHEN MOD(functional_weight, 10) = 8 THEN 'evaluation' WHEN MOD(functional_weight, 10) = 9 THEN 'prediction' END AS dataframe FROM `bigquery-public-data.ml_datasets.census_adult_income`;
Visualizza i dati di esempio:
SELECT * FROM `census.input_data`;
BigQuery DataFrames
Crea un DataFrame chiamato input_data. Utilizzerai input_data più avanti in questo tutorial per addestrare il modello, valutarlo e fare previsioni.
Prima di provare questo esempio, segui le istruzioni di configurazione di BigQuery DataFrames nella guida rapida di BigQuery che utilizza BigQuery DataFrames. Per ulteriori informazioni, consulta la documentazione di riferimento di BigQuery DataFrames.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per maggiori informazioni, vedi Configurare ADC per un ambiente di sviluppo locale.
Crea un modello di regressione logistica
Crea un modello di regressione logistica con i dati di addestramento che hai etichettato nella sezione precedente.
SQL
Utilizza l'istruzione
CREATE MODEL
e specifica LOGISTIC_REG per il tipo di modello.
Di seguito sono riportati alcuni aspetti utili da conoscere in merito alla dichiarazione CREATE MODEL:
L'opzione
input_label_colsspecifica quale colonna dell'istruzioneSELECTutilizzare come colonna delle etichette. In questo caso, la colonna dell'etichetta èincome_bracket, quindi il modello apprende quale dei due valori diincome_bracketè più probabile per una determinata riga in base agli altri valori presenti in quella riga.Non è necessario specificare se un modello di regressione logistica è binario o multiclasse. BigQuery ML determina il tipo di modello da addestrare in base al numero di valori unici nella colonna dell'etichetta.
L'opzione
auto_class_weightsè impostata suTRUEper bilanciare le etichette delle classi nei dati di addestramento. Per impostazione predefinita, i dati di addestramento non sono ponderati. Se le etichette nei dati di addestramento sono sbilanciate, il modello potrebbe imparare a prevedere maggiormente la classe di etichette più popolare. In questo caso, la maggior parte degli intervistati nel set di dati rientra nella fascia di reddito inferiore. Ciò potrebbe portare a un modello che prevede una ponderazione eccessiva della fascia di reddito più bassa. I pesi delle classi bilanciano le etichette delle classi calcolando i pesi per ogni classe in proporzione inversa alla frequenza di quella classe.L'opzione
enable_global_explainè impostata suTRUEper consentirti di utilizzare la funzioneML.GLOBAL_EXPLAINsul modello più avanti nel tutorial.L'istruzione
SELECTesegue query sulla vistainput_datache contiene i dati di esempio. La clausolaWHEREfiltra le righe in modo che solo quelle etichettate come dati di addestramento vengano utilizzate per addestrare il modello.
Esegui la query che crea il modello di regressione logistica:
Nella console Google Cloud , vai alla pagina BigQuery.
Nell'editor di query, esegui la query seguente:
CREATE OR REPLACE MODEL `census.census_model` OPTIONS ( model_type='LOGISTIC_REG', auto_class_weights=TRUE, enable_global_explain=TRUE, data_split_method='NO_SPLIT', input_label_cols=['income_bracket'], max_iterations=15) AS SELECT * EXCEPT(dataframe) FROM `census.input_data` WHERE dataframe = 'training'
Nel riquadro Explorer, fai clic su Set di dati.
Nel riquadro Set di dati, fai clic su
census.Fai clic sul riquadro Modelli.
Fai clic su
census_model.La scheda Dettagli elenca gli attributi che BigQuery ML ha utilizzato per eseguire la regressione logistica.
BigQuery DataFrames
Utilizza il metodo
fit
per addestrare il modello e il metodo
to_gbq
per salvarlo nel set di dati.
Prima di provare questo esempio, segui le istruzioni di configurazione di BigQuery DataFrames nella guida rapida di BigQuery che utilizza BigQuery DataFrames. Per ulteriori informazioni, consulta la documentazione di riferimento di BigQuery DataFrames.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per maggiori informazioni, vedi Configurare ADC per un ambiente di sviluppo locale.
Valuta le prestazioni del modello
Dopo aver creato il modello, valuta le sue prestazioni rispetto ai dati di valutazione.
SQL
La funzione
ML.EVALUATE
valuta i valori previsti generati dal modello rispetto ai
dati di valutazione.
Come input, la funzione ML.EVALUATE accetta il modello addestrato e le righe
della vista input_data che hanno evaluation come valore della colonna dataframe. La funzione restituisce una singola riga di statistiche sul modello.
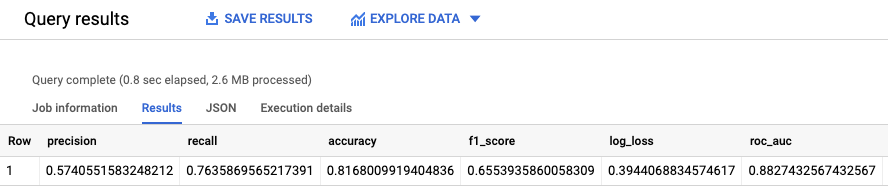
Esegui la query ML.EVALUATE:
Nella console Google Cloud , vai alla pagina BigQuery.
Nell'editor di query, esegui la query seguente:
SELECT * FROM ML.EVALUATE (MODEL `census.census_model`, ( SELECT * FROM `census.input_data` WHERE dataframe = 'evaluation' ) );
I risultati sono simili ai seguenti:
BigQuery DataFrames
Utilizza il metodo
score
per valutare il modello rispetto ai dati effettivi.
Prima di provare questo esempio, segui le istruzioni di configurazione di BigQuery DataFrames nella guida rapida di BigQuery che utilizza BigQuery DataFrames. Per ulteriori informazioni, consulta la documentazione di riferimento di BigQuery DataFrames.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per maggiori informazioni, vedi Configurare ADC per un ambiente di sviluppo locale.
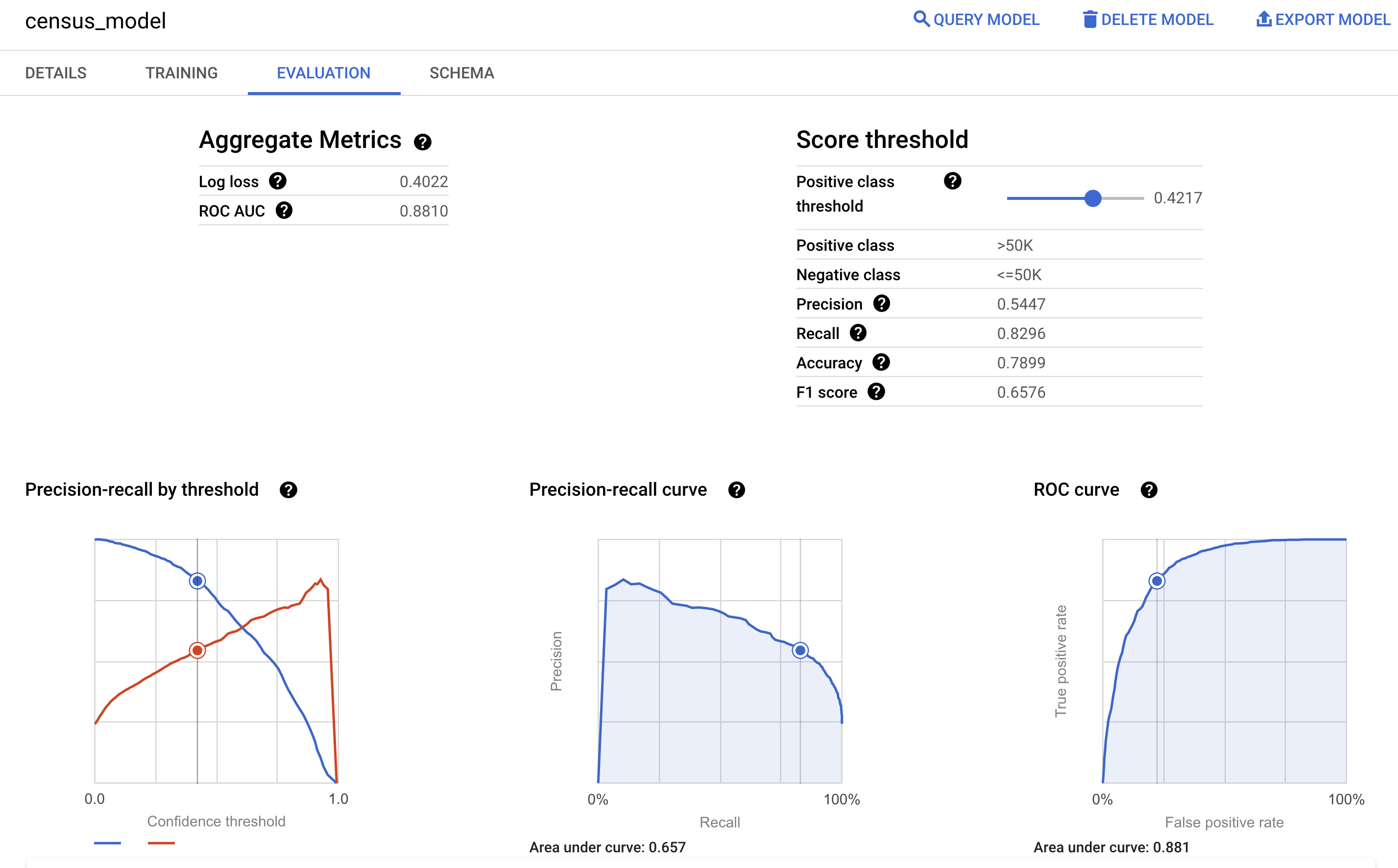
Puoi anche esaminare il riquadro Valutazione del modello nella console Google Cloud per visualizzare le metriche di valutazione calcolate durante l'addestramento:
Prevede la fascia di reddito
Utilizza il modello per prevedere la fascia di reddito più probabile per ogni intervistato.
SQL
Utilizza la
funzione ML.PREDICT
per fare previsioni sulla fascia di reddito probabile. Per l'input, la
funzione ML.PREDICT accetta il modello addestrato e le righe della
vista input_data che hanno prediction come valore della colonna dataframe.
Esegui la query ML.PREDICT:
Nella console Google Cloud , vai alla pagina BigQuery.
Nell'editor di query, esegui la query seguente:
SELECT * FROM ML.PREDICT (MODEL `census.census_model`, ( SELECT * FROM `census.input_data` WHERE dataframe = 'prediction' ) );
I risultati sono simili ai seguenti:
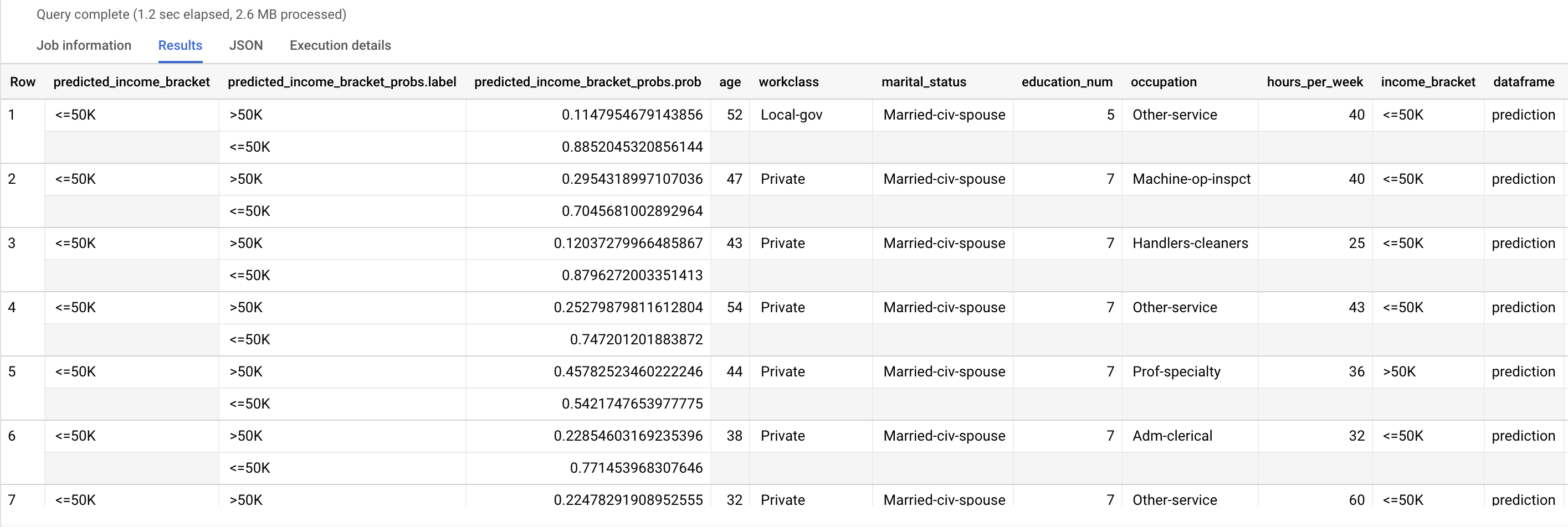
La colonna predicted_income_bracket contiene la fascia di reddito prevista
per il rispondente.
BigQuery DataFrames
Utilizza il metodo
predict
per fare previsioni sulla fascia di reddito probabile.
Prima di provare questo esempio, segui le istruzioni di configurazione di BigQuery DataFrames nella guida rapida di BigQuery che utilizza BigQuery DataFrames. Per ulteriori informazioni, consulta la documentazione di riferimento di BigQuery DataFrames.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per maggiori informazioni, vedi Configurare ADC per un ambiente di sviluppo locale.
Spiega i risultati della previsione
Per capire perché il modello sta generando questi risultati di previsione, puoi utilizzare
la
funzione ML.EXPLAIN_PREDICT.
ML.EXPLAIN_PREDICT è una versione estesa della funzione ML.PREDICT.
ML.EXPLAIN_PREDICT non solo restituisce i risultati della previsione, ma anche
colonne aggiuntive per spiegare i risultati della previsione. Per ulteriori informazioni
sull'interpretabilità, consulta
Panoramica di BigQuery Explainable AI.
Esegui la query ML.EXPLAIN_PREDICT:
Nella console Google Cloud , vai alla pagina BigQuery.
Nell'editor di query, esegui la query seguente:
SELECT * FROM ML.EXPLAIN_PREDICT(MODEL `census.census_model`, ( SELECT * FROM `census.input_data` WHERE dataframe = 'evaluation'), STRUCT(3 as top_k_features));
I risultati sono simili ai seguenti:
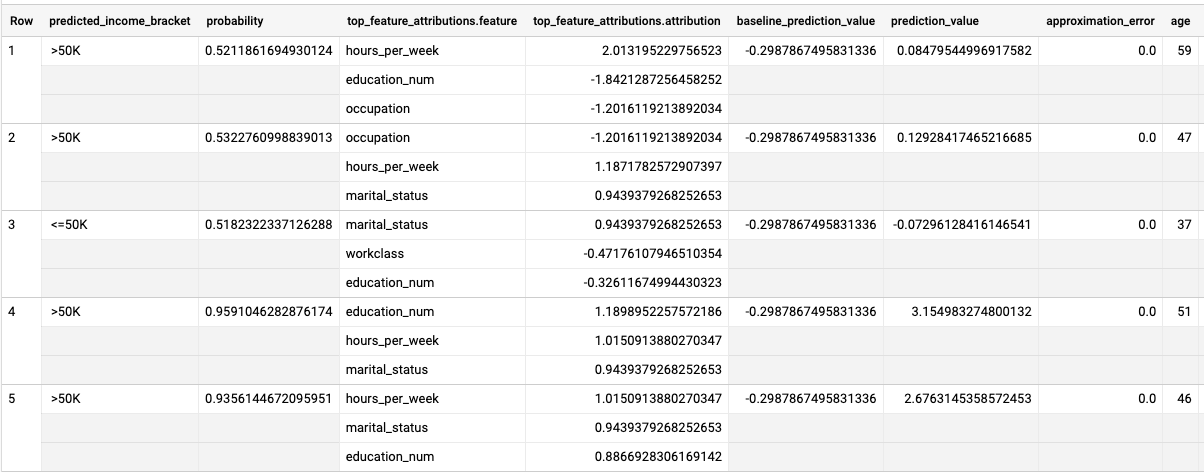
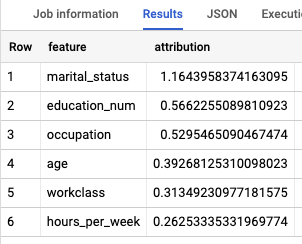
Per i modelli di regressione logistica, i valori di
Shapley vengono utilizzati per determinare l'attribuzione
relativa delle caratteristiche per ogni caratteristica nel modello. Poiché l'opzione top_k_features
è stata impostata su 3 nella query, ML.EXPLAIN_PREDICT restituisce le prime tre
attribuzioni di caratteristiche per ogni riga della visualizzazione input_data. Queste attribuzioni
sono mostrate in ordine decrescente in base al valore assoluto dell'attribuzione.
Spiega il modello a livello globale
Per sapere quali caratteristiche sono le più importanti per determinare la fascia di reddito,
utilizza la
funzione ML.GLOBAL_EXPLAIN.
Ottieni spiegazioni globali per il modello:
Nella console Google Cloud , vai alla pagina BigQuery.
Nell'editor di query, esegui la seguente query per ottenere le spiegazioni globali:
SELECT * FROM ML.GLOBAL_EXPLAIN(MODEL `census.census_model`)
I risultati sono simili ai seguenti:
Esegui la pulizia
Per evitare che al tuo account Google Cloud vengano addebitati costi relativi alle risorse utilizzate in questo tutorial, elimina il progetto che contiene le risorse oppure mantieni il progetto ed elimina le singole risorse.
Elimina il set di dati
L'eliminazione del progetto rimuove tutti i set di dati e tutte le tabelle nel progetto. Se preferisci riutilizzare il progetto, puoi eliminare il set di dati creato in questo tutorial:
Se necessario, apri la pagina BigQuery nella consoleGoogle Cloud .
Nel menu di navigazione, fai clic sul set di dati censimento che hai creato.
Fai clic su Elimina set di dati sul lato destro della finestra. Questa azione elimina il set di dati e il modello.
Nella finestra di dialogo Elimina set di dati, conferma il comando di eliminazione digitando il nome del set di dati (
census) e poi fai clic su Elimina.
Elimina il progetto
Per eliminare il progetto:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Passaggi successivi
- Per una panoramica di BigQuery ML, consulta Introduzione a BigQuery ML.
- Per informazioni sulla creazione di modelli, consulta la pagina
CREATE MODELdella sintassi.