Questo tutorial ti insegna a utilizzare un modello k-means in BigQuery ML per identificare i cluster in un insieme di dati.
L'algoritmo k-means che raggruppa i dati in cluster è una forma di machine learning non supervisionato. A differenza del machine learning supervisionato, che si occupa di analisi predittiva, il machine learning non supervisionato si occupa di analisi descrittive. Il machine learning non supervisionato può aiutarti a comprendere i tuoi dati in modo da poter prendere decisioni basate sui dati.
Le query in questo tutorial utilizzano funzioni geografiche disponibili in Dati geospaziali. Per ulteriori informazioni, consulta la pagina Introduzione all'analisi geospaziale.
Questo tutorial utilizza il set di dati pubblico London Bicycle Hires. I dati includeranno i timestamp di inizio e di fine, i nomi delle stazioni e la durata della corsa.
Obiettivi
Questo tutorial ti guida nella realizzazione delle seguenti attività:- Esamina i dati utilizzati per addestrare il modello.
- Crea un modello di clustering K-means.
- Interpreta i cluster di dati prodotti utilizzando la visualizzazione dei cluster di BigQuery ML.
- Esegui la
funzione
ML.PREDICTsul modello K-means per prevedere il probabile cluster per un insieme di stazioni di noleggio biciclette.
Costi
Questo tutorial utilizza i componenti fatturabili di Google Cloud, tra cui:
- BigQuery
- BigQuery ML
Per informazioni sui costi di BigQuery, consulta la pagina Prezzi di BigQuery.
Per informazioni sui costi di BigQuery ML, consulta Prezzi di BigQuery ML.
Prima di iniziare
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
- BigQuery viene attivato automaticamente nei nuovi progetti.
Per attivare BigQuery in un progetto preesistente, vai a
Enable the BigQuery API.
Autorizzazioni richieste
- Per creare il set di dati, devi disporre dell'autorizzazione IAM
bigquery.datasets.create. Per creare la risorsa di connessione, devi disporre delle seguenti autorizzazioni:
bigquery.connections.createbigquery.connections.get
Per creare il modello, devi disporre delle seguenti autorizzazioni:
bigquery.jobs.createbigquery.models.createbigquery.models.getDatabigquery.models.updateDatabigquery.connections.delegate
Per eseguire l'inferenza, devi disporre delle seguenti autorizzazioni:
bigquery.models.getDatabigquery.jobs.create
Per saperne di più sui ruoli e sulle autorizzazioni IAM in BigQuery, consulta Introduzione a IAM.
Crea un set di dati
Crea un set di dati BigQuery per archiviare il modello k-means:
Nella console Google Cloud, vai alla pagina BigQuery.
Nel riquadro Explorer, fai clic sul nome del progetto.
Fai clic su Visualizza azioni > Crea set di dati.
Nella pagina Crea set di dati:
In ID set di dati, inserisci
bqml_tutorial.Per Tipo di località, seleziona Più regioni e poi UE (più regioni nell'Unione Europea).
Il set di dati pubblico Noleggio biciclette a Londra è archiviato nella regione
EU. Il set di dati deve essere nella stessa posizione.Lascia invariate le restanti impostazioni predefinite e fai clic su Crea set di dati.

Esamina i dati di addestramento
Esamina i dati che utilizzerai per addestrare il modello k-means. In questo tutorial, raggruppi le stazioni di ricarica per biciclette in base ai seguenti attributi:
- Durata dei noleggi
- Numero di viaggi al giorno
- Distanza dal centro città
SQL
Questa query estrae i dati sulle prenotazioni di biciclette, incluse le colonne start_station_name
e duration, e li unisce alle informazioni sulle stazioni. Ciò include la creazione di una colonna calcolata contenente la distanza della stazione dal centro città. Quindi, calcola gli attributi della stazione in una colonna stationstats, inclusa la durata media delle corse e il numero di corse, nonché la colonna distance_from_city_center calcolata.
Per esaminare i dati di addestramento:
Nella console Google Cloud, vai alla pagina BigQuery.
Nell'editor di query, incolla la seguente query e fai clic su Esegui:
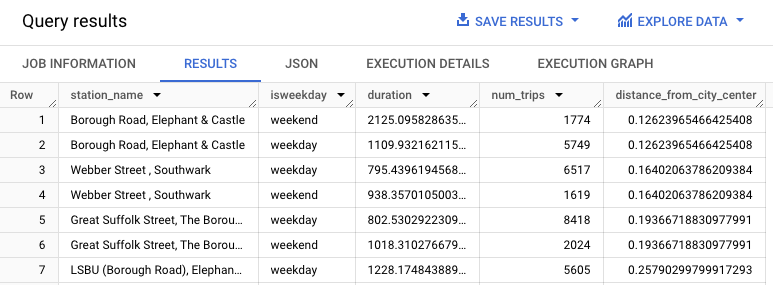
WITH hs AS ( SELECT h.start_station_name AS station_name, IF( EXTRACT(DAYOFWEEK FROM h.start_date) = 1 OR EXTRACT(DAYOFWEEK FROM h.start_date) = 7, 'weekend', 'weekday') AS isweekday, h.duration, ST_DISTANCE(ST_GEOGPOINT(s.longitude, s.latitude), ST_GEOGPOINT(-0.1, 51.5)) / 1000 AS distance_from_city_center FROM `bigquery-public-data.london_bicycles.cycle_hire` AS h JOIN `bigquery-public-data.london_bicycles.cycle_stations` AS s ON h.start_station_id = s.id WHERE h.start_date BETWEEN CAST('2015-01-01 00:00:00' AS TIMESTAMP) AND CAST('2016-01-01 00:00:00' AS TIMESTAMP) ), stationstats AS ( SELECT station_name, isweekday, AVG(duration) AS duration, COUNT(duration) AS num_trips, MAX(distance_from_city_center) AS distance_from_city_center FROM hs GROUP BY station_name, isweekday ) SELECT * FROM stationstats ORDER BY distance_from_city_center ASC;
I risultati dovrebbero essere simili ai seguenti:
BigQuery DataFrames
Prima di provare questo esempio, segui le istruzioni di configurazione di BigQuery DataFrames riportate nella guida introduttiva di BigQuery che utilizza BigQuery DataFrames. Per ulteriori informazioni, consulta la documentazione di riferimento di BigQuery DataFrames.
Per autenticarti in BigQuery, configura le Credenziali predefinite dell'applicazione. Per ulteriori informazioni, vedi Configurare l'autenticazione per un ambiente di sviluppo locale.
Creare un modello K-means
Crea un modello K-means utilizzando i dati di addestramento delle biciclette a noleggio di Londra.
SQL
Nella seguente query, l'istruzione CREATE MODEL specifica il numero di
cluster da utilizzare, ovvero quattro. Nell'istruzione SELECT, la clausola EXCEPT esclude la colonna station_name perché non contiene una funzionalità. La query crea una riga univoca per station_name e solo le funzionalità sono menzionate nell'istruzione SELECT.
Per creare un modello K-means:
Nella console Google Cloud, vai alla pagina BigQuery.
Nell'editor di query, incolla la seguente query e fai clic su Esegui:
CREATE OR REPLACE MODEL `bqml_tutorial.london_station_clusters` OPTIONS ( model_type = 'kmeans', num_clusters = 4) AS WITH hs AS ( SELECT h.start_station_name AS station_name, IF( EXTRACT(DAYOFWEEK FROM h.start_date) = 1 OR EXTRACT(DAYOFWEEK FROM h.start_date) = 7, 'weekend', 'weekday') AS isweekday, h.duration, ST_DISTANCE(ST_GEOGPOINT(s.longitude, s.latitude), ST_GEOGPOINT(-0.1, 51.5)) / 1000 AS distance_from_city_center FROM `bigquery-public-data.london_bicycles.cycle_hire` AS h JOIN `bigquery-public-data.london_bicycles.cycle_stations` AS s ON h.start_station_id = s.id WHERE h.start_date BETWEEN CAST('2015-01-01 00:00:00' AS TIMESTAMP) AND CAST('2016-01-01 00:00:00' AS TIMESTAMP) ), stationstats AS ( SELECT station_name, isweekday, AVG(duration) AS duration, COUNT(duration) AS num_trips, MAX(distance_from_city_center) AS distance_from_city_center FROM hs GROUP BY station_name, isweekday ) SELECT * EXCEPT (station_name, isweekday) FROM stationstats;
BigQuery DataFrames
Prima di provare questo esempio, segui le istruzioni di configurazione di BigQuery DataFrames riportate nella guida introduttiva di BigQuery che utilizza BigQuery DataFrames. Per ulteriori informazioni, consulta la documentazione di riferimento di BigQuery DataFrames.
Per autenticarti in BigQuery, configura le Credenziali predefinite dell'applicazione. Per ulteriori informazioni, vedi Configurare l'autenticazione per un ambiente di sviluppo locale.
Interpreta i cluster di dati
Le informazioni nella scheda Valutazione dei modelli possono aiutarti a interpretare i cluster prodotti dal modello.
Per visualizzare le informazioni sulla valutazione del modello:
Nella console Google Cloud, vai alla pagina BigQuery.
Nel riquadro Explorer, espandi il progetto, il set di dati
bqml_tutoriale la cartella Modelli.Seleziona il modello
london_station_clusters.Seleziona la scheda Valutazione. Questa scheda mostra le visualizzazioni dei cluster identificati dal modello k-means. Nella sezione Funzionalità numeriche, i grafici a barre mostrano i valori delle funzionalità numeriche più importanti per ciascun centroide. Ogni centroide rappresenta un determinato cluster di dati. Puoi selezionare le funzionalità da visualizzare dal menu a discesa.
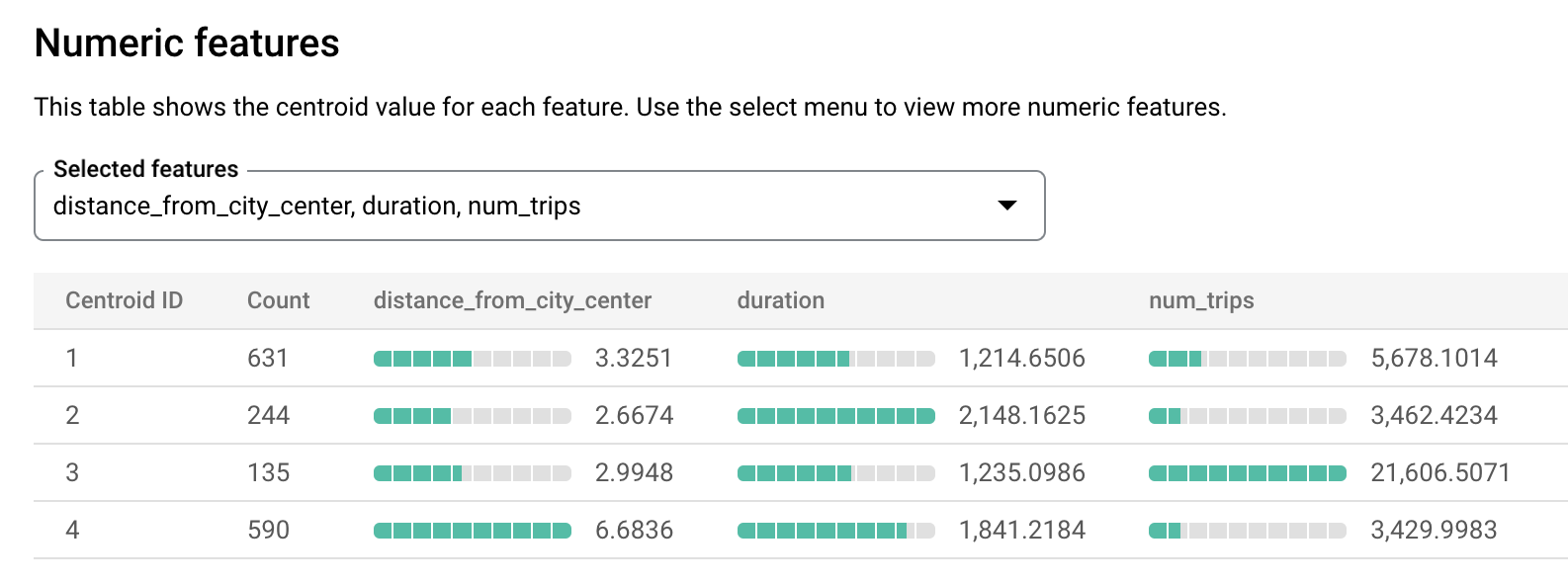
Questo modello crea i seguenti centroidi:
- Il centroide 1 mostra una stazione di città meno frequentata, con affitti di durata inferiore.
- Il baricentro 2 mostra la seconda stazione della città, meno frequentata e utilizzata per i noleggi di durata più lunga.
- Il centroide 3 mostra una stazione cittadina trafficata vicino al centro città.
- Il baricentro 4 mostra una stazione di periferia con viaggi più lunghi.
Se gestisci un'attività di noleggio biciclette, puoi utilizzare queste informazioni per prendere decisioni aziendali. Ad esempio:
Supponiamo che tu debba sperimentare con un nuovo tipo di serratura. Quale cluster di stazione dovresti scegliere come soggetto per questo esperimento? Le stazioni nel centro geometrico 1, nel centro geometrico 2 o nel centro geometrico 4 sembrano scelte logiche perché non sono le stazioni più frequentate.
Supponiamo che tu voglia fornire alcune stazioni di biciclette da corsa. Quali stazioni scegliere? Il centroide 4 è il gruppo di stazioni lontane dal centro città e con i viaggi più lunghi. Questi sono potenziali candidati per le biciclette da corsa.
Utilizzare la funzione ML.PREDICT per prevedere il cluster di una stazione
Identifica il cluster a cui appartiene una determinata stazione utilizzando la funzione SQL
ML.PREDICT o la funzione
predict DataFrames di BigQuery.
SQL
La seguente query utilizza la funzione
REGEXP_CONTAINS
per trovare tutte le voci nella colonna station_name contenenti la
stringa Kennington. La funzione ML.PREDICT utilizza questi valori per prevedere quali cluster potrebbero contenere queste stazioni.
Per prevedere il cluster di ogni stazione che contiene la stringa Kennington nel nome:
Nella console Google Cloud, vai alla pagina BigQuery.
Nell'editor di query, incolla la seguente query e fai clic su Esegui:
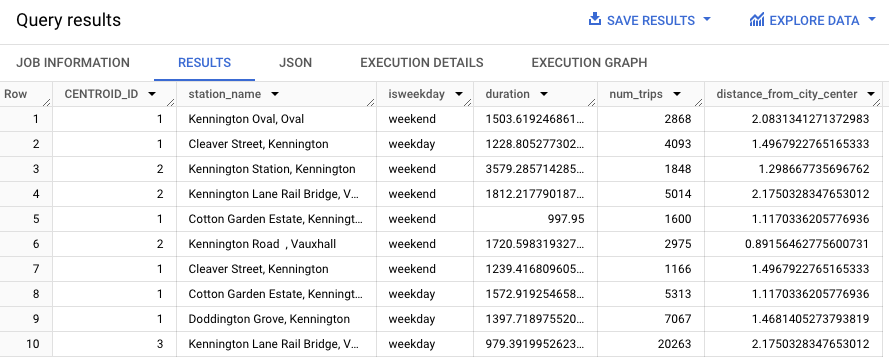
WITH hs AS ( SELECT h.start_station_name AS station_name, IF( EXTRACT(DAYOFWEEK FROM h.start_date) = 1 OR EXTRACT(DAYOFWEEK FROM h.start_date) = 7, 'weekend', 'weekday') AS isweekday, h.duration, ST_DISTANCE(ST_GEOGPOINT(s.longitude, s.latitude), ST_GEOGPOINT(-0.1, 51.5)) / 1000 AS distance_from_city_center FROM `bigquery-public-data.london_bicycles.cycle_hire` AS h JOIN `bigquery-public-data.london_bicycles.cycle_stations` AS s ON h.start_station_id = s.id WHERE h.start_date BETWEEN CAST('2015-01-01 00:00:00' AS TIMESTAMP) AND CAST('2016-01-01 00:00:00' AS TIMESTAMP) ), stationstats AS ( SELECT station_name, isweekday, AVG(duration) AS duration, COUNT(duration) AS num_trips, MAX(distance_from_city_center) AS distance_from_city_center FROM hs GROUP BY station_name, isweekday ) SELECT * EXCEPT (nearest_centroids_distance) FROM ML.PREDICT( MODEL `bqml_tutorial.london_station_clusters`, ( SELECT * FROM stationstats WHERE REGEXP_CONTAINS(station_name, 'Kennington') ));
I risultati dovrebbero essere simili al seguente.
BigQuery DataFrames
Prima di provare questo esempio, segui le istruzioni di configurazione di BigQuery DataFrames riportate nella guida introduttiva di BigQuery che utilizza BigQuery DataFrames. Per ulteriori informazioni, consulta la documentazione di riferimento di BigQuery DataFrames.
Per autenticarti in BigQuery, configura le Credenziali predefinite dell'applicazione. Per ulteriori informazioni, vedi Configurare l'autenticazione per un ambiente di sviluppo locale.
Esegui la pulizia
Per evitare che al tuo account Google Cloud vengano addebitati costi relativi alle risorse utilizzate in questo tutorial, elimina il progetto che contiene le risorse oppure mantieni il progetto ed elimina le singole risorse.
- Puoi eliminare il progetto che hai creato.
- In alternativa, puoi conservare il progetto ed eliminare il set di dati.
Eliminare il set di dati
L'eliminazione del progetto rimuove tutti i set di dati e tutte le tabelle nel progetto. Se preferisci riutilizzare il progetto, puoi eliminare il set di dati creato in questo tutorial:
Se necessario, apri la pagina BigQuery nella console Google Cloud.
Nella barra di navigazione, fai clic sul set di dati bqml_tutorial che hai creato.
Fai clic su Elimina set di dati sul lato destro della finestra. Questa azione elimina il set di dati e il modello.
Nella finestra di dialogo Elimina set di dati, conferma il comando di eliminazione digitando il nome del set di dati (
bqml_tutorial) e poi fai clic su Elimina.
Elimina il progetto
Per eliminare il progetto:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Passaggi successivi
- Per una panoramica di BigQuery ML, consulta Introduzione a BigQuery ML.
- Per informazioni sulla creazione dei modelli, consulta la pagina della sintassi di
CREATE MODEL.