This tutorial shows how to use
hyperparameter tuning in
BigQuery ML by specifying the NUM_TRIALS training option to enable
a set of model training trials.
In this tutorial, you use the
tlc_yellow_trips_2018 sample table
to create a model that predicts the tip of a taxi trip. With hyperparameter
tuning, the model shows a ~40% performance improvement in the
R2_SCORE hyperparameter tuning objective.
Objectives
In this tutorial, you use:
- BigQuery ML to create a linear regression model using the
CREATE MODELstatement with theNUM_TRIALSset to 20. - The
ML.TRIAL_INFOfunction to check the overview of all 20 trials - The
ML.EVALUATEfunction to evaluate the ML model - The
ML.PREDICTfunction to make predictions using the ML model
Costs
This tutorial uses billable components of Google Cloud, including:
- BigQuery
- BigQuery ML
For more information about BigQuery costs, see the BigQuery pricing page.
Before you begin
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
- BigQuery is automatically enabled in new projects.
To activate BigQuery in a pre-existing project, go to
Enable the BigQuery API.
Step one: Create your training dataset
Create a BigQuery dataset to store your ML model:
In the Google Cloud console, go to the BigQuery page.
In the Explorer pane, click your project name.
Click View actions > Create dataset.

On the Create dataset page, do the following:
For Dataset ID, enter
bqml_tutorial.For Location type, select Multi-region, and then select US (multiple regions in United States).
The public datasets are stored in the
USmulti-region. For simplicity, store your dataset in the same location.Leave the remaining default settings as they are, and click Create dataset.

Step two: Create your training input table
In this step, you materialize the training input table with 100k rows.
View the schema of the source table
tlc_yellow_trips_2018.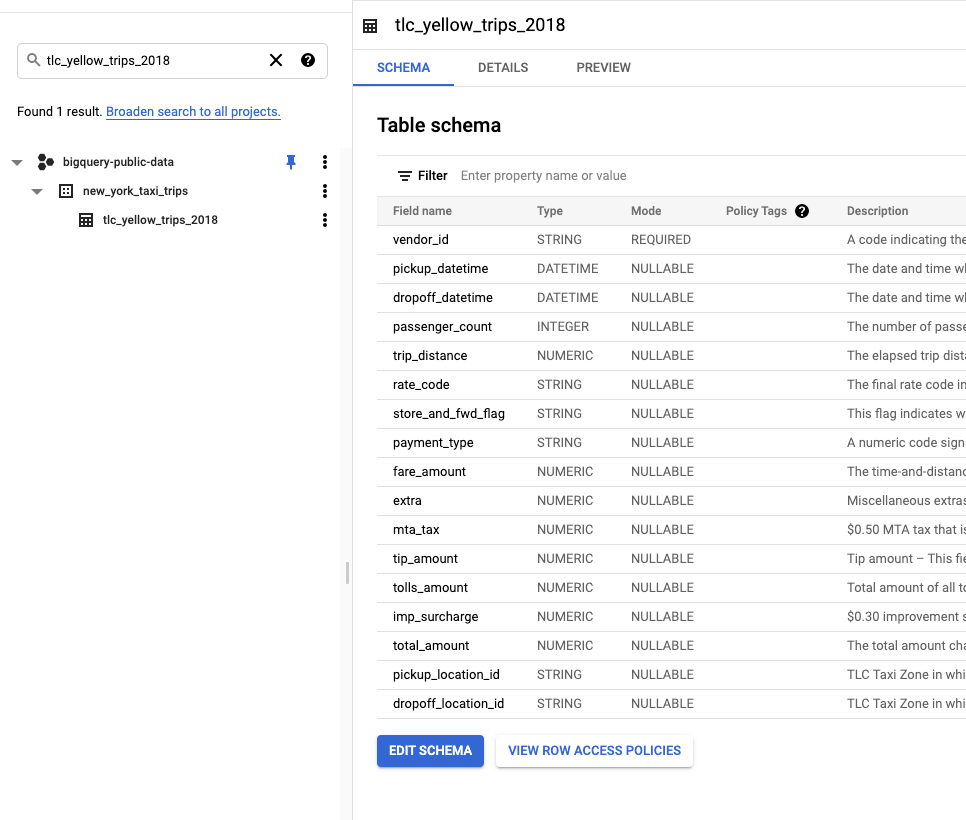
Create the training input data table.
CREATE TABLE `bqml_tutorial.taxi_tip_input` AS SELECT * EXCEPT(tip_amount), tip_amount AS label FROM `bigquery-public-data.new_york_taxi_trips.tlc_yellow_trips_2018` WHERE tip_amount IS NOT NULL LIMIT 100000
Step three: Create your model
Next, create a linear regression model with hyperparameter tuning using the
tlc_yellow_trips_2018 sample table in BigQuery. The following
GoogleSQL query is used to create the model with hyperparameter tuning.
CREATE MODEL `bqml_tutorial.hp_taxi_tip_model` OPTIONS (MODEL_TYPE='LINEAR_REG', NUM_TRIALS=20, MAX_PARALLEL_TRIALS=2) AS SELECT * FROM `bqml_tutorial.taxi_tip_input`
Query details
The LINEAR_REG model has two tunable hyperparameters: l1_reg and l2_reg.
The above query uses the default search space. You can also specify the search
space explicitly:
OPTIONS
(...
L1_REG=HPARAM_RANGE(0, 20),
L2_REG=HPARAM_CANDIDATES([0, 0.1, 1, 10]))
In addition, these other hyperparameter tuning training options also use their default values:
- HPARAM_TUNING_ALGORITHM:
"VIZIER_DEFAULT" - HPARAM_TUNING_OBJECTIVES:
["r2_score"]
MAX_PARALLEL_TRIALS is set to 2 to accelerate the tuning process. With 2
trials running at any time, the whole tuning should take roughly as long as 10
serial training jobs instead of 20. Note, however, that the two concurrent trials cannot
benefit from each other's training results.
Run the CREATE MODEL query
To run the CREATE MODEL query to create and train your model:
In the Google Cloud console, click the Compose new query button.
Enter the above GoogleSQL query in the Query editor text area.
Click Run.
The query takes about 17 minutes to complete. You can track the tuning progress in execution details under Stages:
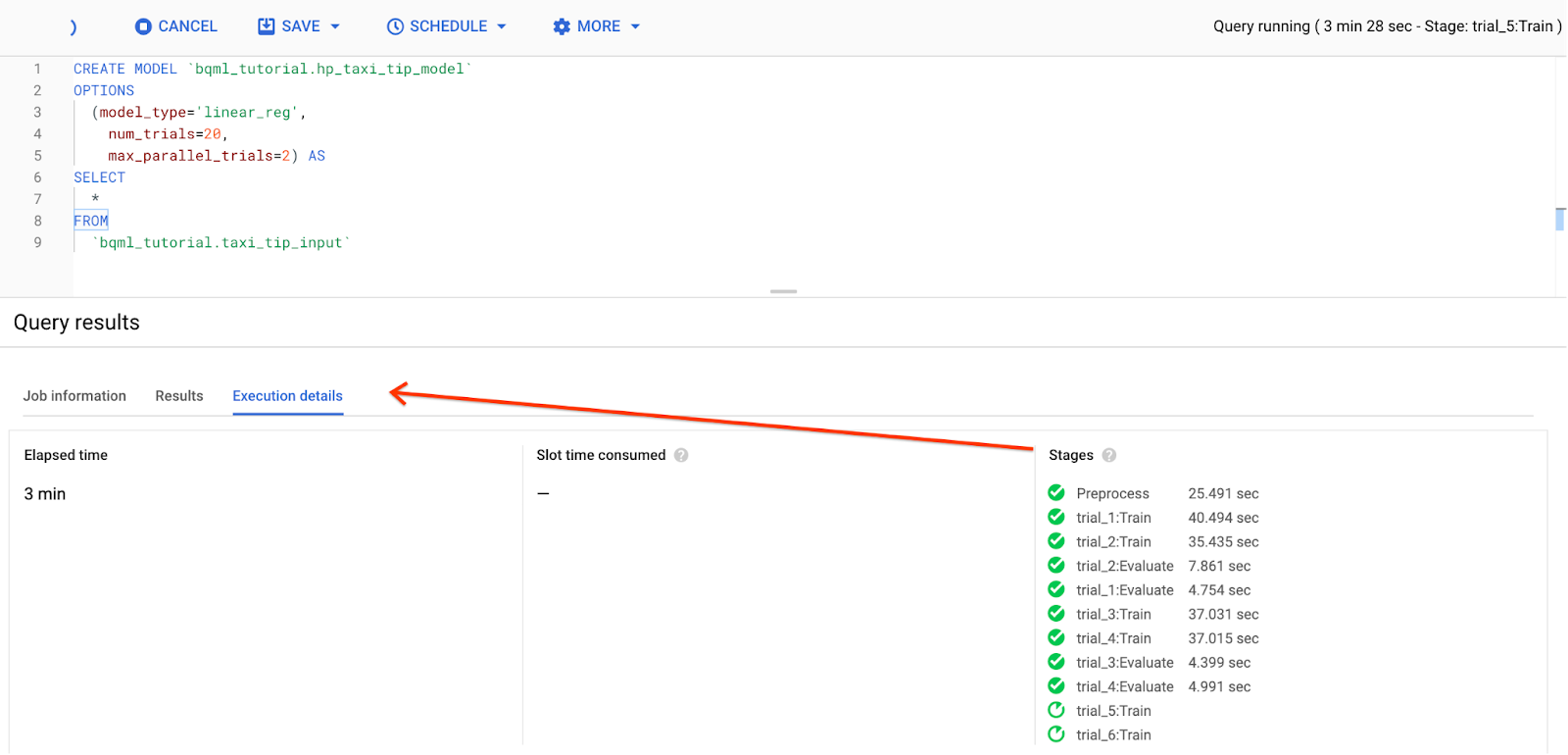
Step four: Get trials information
To see the overview of all trials including their hyperparameters, objectives,
status, and the optimal trial, you can use the
ML.TRIAL_INFO
function, and you can view the result in the Google Cloud console after running
the SQL.
SELECT * FROM ML.TRIAL_INFO(MODEL `bqml_tutorial.hp_taxi_tip_model`)
You can run this SQL query as soon as one trial is done. If the tuning is stopped in the middle, all already-completed trials will remain available to use.
Step five: Evaluate your model
After creating your model, you can get the evaluation metrics of all trials
by either using the ML.EVALUATE
function or through Google Cloud console.
Run ML.EVALUATE
SELECT * FROM ML.EVALUATE(MODEL `bqml_tutorial.hp_taxi_tip_model`)
This SQL fetches evaluation metrics for all trials calculated from the TEST
data. For more information about the difference between ML.TRIAL_INFO
objectives and ML.EVALUATE evaluation metrics, see
Model serving functions.
You can also evaluate a specific trial by providing your own data. For more information, see Model serving functions.
Check evaluation metrics through Google Cloud console
You can also check evaluation metrics by selecting the EVALUATION tab.
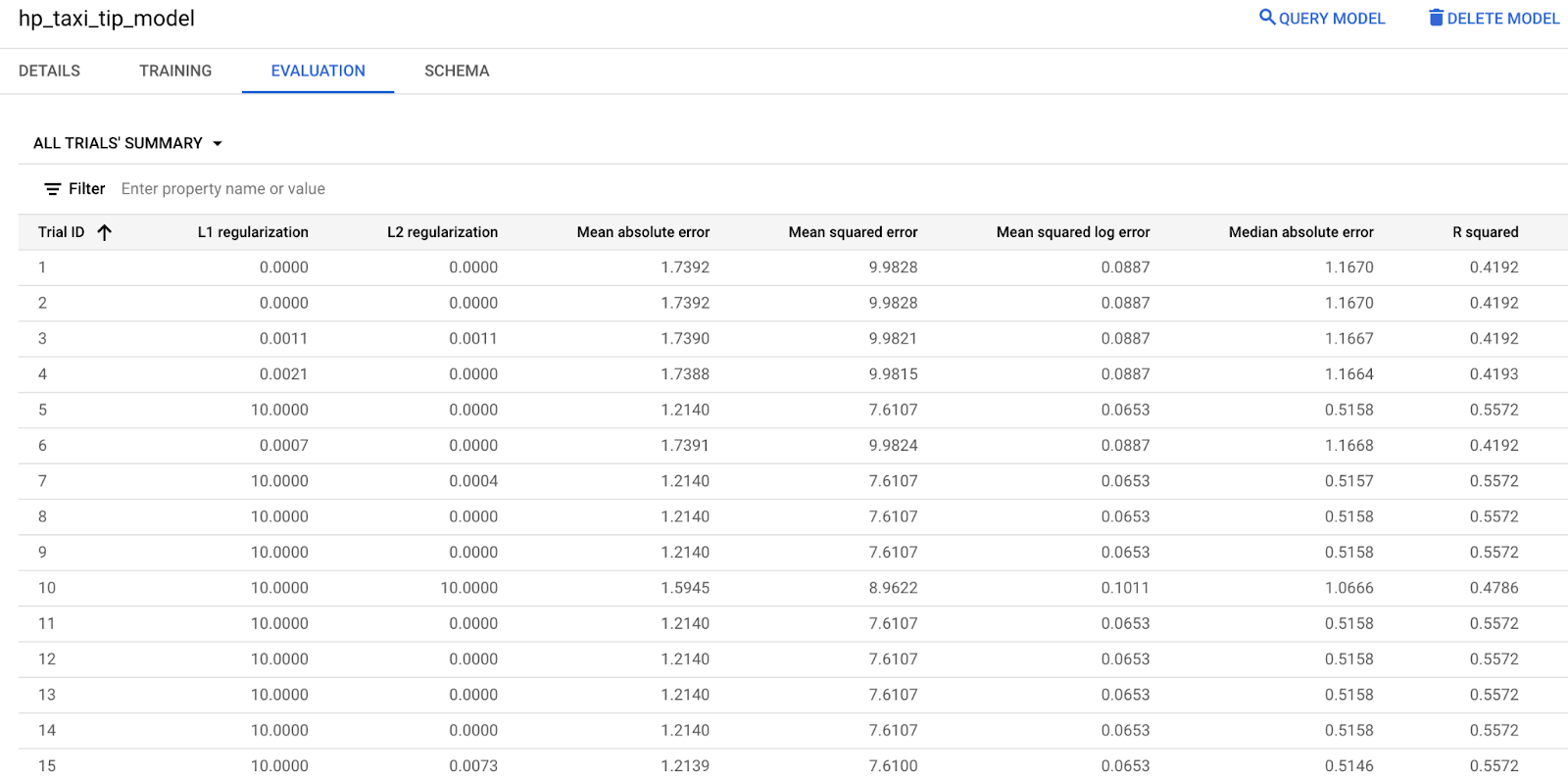
Step six: Use your model to predict taxi tips
Now that you have evaluated your model, the next step is to use it to predict the taxi tip.
The query used to predict the tip is as follows:
SELECT
*
FROM
ML.PREDICT(MODEL `bqml_tutorial.hp_taxi_tip_model`,
(
SELECT
*
FROM
`bqml_tutorial.taxi_tip_input`
LIMIT 10))
Query details
The top-most SELECT statement retrieves all columns including the
predicted_label column. This column is generated by the ML.PREDICT function.
When you use the ML.PREDICT function, the output column name for the model is
predicted_label_column_name.
The prediction is made against the optimal trial by default. You can select
other trial by specifying trial_id parameter.
SELECT
*
FROM
ML.PREDICT(MODEL `bqml_tutorial.hp_taxi_tip_model`,
(
SELECT
*
FROM
`bqml_tutorial.taxi_tip_input`
LIMIT
10),
STRUCT(3 AS trial_id))
For more details on how to use model serving functions, see Model serving functions.
Clean up
To avoid incurring charges to your Google Cloud account for the resources used in this tutorial, either delete the project that contains the resources, or keep the project and delete the individual resources.
- You can delete the project you created.
- Or you can keep the project and delete the dataset.
Delete your dataset
Deleting your project removes all datasets and all tables in the project. If you prefer to reuse the project, you can delete the dataset you created in this tutorial:
If necessary, open the BigQuery page in the Google Cloud console.
In the navigation panel, click the bqml_tutorial dataset you created.
On the right side of the window, click Delete dataset. This action deletes the dataset, the table, and all the data.
In the Delete dataset dialog box, confirm the delete command by typing the name of your dataset (
bqml_tutorial) and then click Delete.
Delete your project
To delete the project:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
What's next
- To learn more about machine learning, see the Machine learning crash course.
- For an overview of BigQuery ML, see Introduction to BigQuery ML.
- To learn more about the Google Cloud console, see Using the Google Cloud console.