Explore the Google Cloud console
The Google Cloud console provides a graphical interface that you can use to create and manage BigQuery resources and run SQL queries.
To try BigQuery in the Google Cloud console, see the quickstart Query a public dataset with the Google Cloud console.
Before you begin
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Enable the BigQuery API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.For new projects, the BigQuery API is automatically enabled.
- Optional: Enable billing for the project. If you don't want to enable billing or provide a credit card, the steps in this document still work. BigQuery provides you a sandbox to perform the steps. For more information, see Enable the BigQuery sandbox.
Open BigQuery in the Google Cloud console
Go to the Google Cloud console.
In the Google Cloud console toolbar, click Navigation menu.
Click Solutions > All products.
In the Analytics section, click BigQuery.
You can also open the BigQuery page by entering the following URL in your browser:
https://console.cloud.google.com/bigquery
BigQuery opens in your most recently accessed project.
To simplify navigation, you can add (or pin) BigQuery as a top product in the navigation menu:
In the Google Cloud console navigation menu, hold the pointer over BigQuery.
Click Pin.
Overview of the BigQuery page
The BigQuery page has the following main sections:
- The BigQuery navigation menu
- The left pane
- The details pane
The Add data dialog

Navigation menu
In the BigQuery navigation menu, you can select any option from the following categories:
Studio: displays your datasets, tables, and other BigQuery resources. In this workspace, you can perform common BigQuery tasks such as the following:
- Create, run, save, and share queries and Colab Enterprise notebooks.
- Work with tables, views, routines, and other BigQuery resources.
- See your BigQuery job history.
Search (Preview): lets you search for Google Cloud resources from BigQuery by using natural language queries.
Pipelines and integration
Data transfers: lets you access the BigQuery Data Transfer Service to create and configure data transfers.
Pipelines (Dataform): displays a list of Dataform repositories that are created for your Google Cloud project.
Scheduled queries: displays your scheduled queries.
Scheduling: provides a list of pipelines and schedules for your Google Cloud project.
Governance
Sharing (Analytics Hub): displays all of the data exchanges that you can access in your Google Cloud project.
Policy tags: displays a list of taxonomies that you can use to create hierarchical groups of policy tags.
Metadata curation: lets you scan data in Cloud Storage buckets to extract and then catalog metadata.
Administration
Monitoring: lets you monitor operational health and resource utilization across an organization.
Jobs explorer: helps you monitor jobs activity across your organization.
Capacity management: displays slot commitments, reservations, and reservation assignments.
BI Engine: lets you manage reservation capacity for query optimization using BigQuery BI Engine.
Disaster recovery: displays failover reservations and failover datasets.
Recommendations: displays a list of recommendations in your organization or project.
Migration
Assessment: lets you plan and review the migration of your existing data warehouse into BigQuery.
SQL translation: lets you convert your Teradata SQL queries so that they work in BigQuery.
Additional resources
Partner Center: provides tools and services from partners to accelerate your workflow.
Settings (Preview): contain the following tabs:
My settings: let you set default settings that are applied when you start a session in BigQuery Studio. Some settings are inherited from your project or organization, but can be overridden on the My settings page.
Configuration settings: let BigQuery administrators customize the BigQuery Studio experience for users within the selected project or organization. This is achieved by showing or hiding user interface elements such as Save results > CSV (Google Drive), Open in > Looker Studio, and Export > Explore with Sheets. These settings don't restrict access to the underlying data and tools, even if they are hidden in BigQuery Studio. You need the
bigquery.config.getpermission to make changes at the organization level.
Release notes: contains the latest product updates and announcements for BigQuery.
You can control how the BigQuery navigation menu is displayed:
To collapse the navigation menu so that only the icons are visible, click
 Toggle BigQuery navigation menu.
Toggle BigQuery navigation menu.To temporarily expand the menu when it's collapsed, hold the pointer over the menu.
To expand the menu so that the labels stay visible, click
 Toggle BigQuery navigation menu.
Toggle BigQuery navigation menu.
Left pane
The left pane is visible when you select Studio in the navigation menu. This pane consists of three panes: Explorer, Classic Explorer, and Git repository.
To collapse the left pane, click Collapse left pane. To expand the left pane, click Expand left pane.
Explorer pane
The Explorer pane lists different code assets and data resources. To open a new tab in the details pane, click a code asset type. This tab lists all files of that code asset type in your project. For example, click Notebooks to open the Notebooks tab, which lists all notebooks in your project. You can use the search bar or filters to find a file.
You can also go to the Home tab or open job histories and starred resources in a new tab.
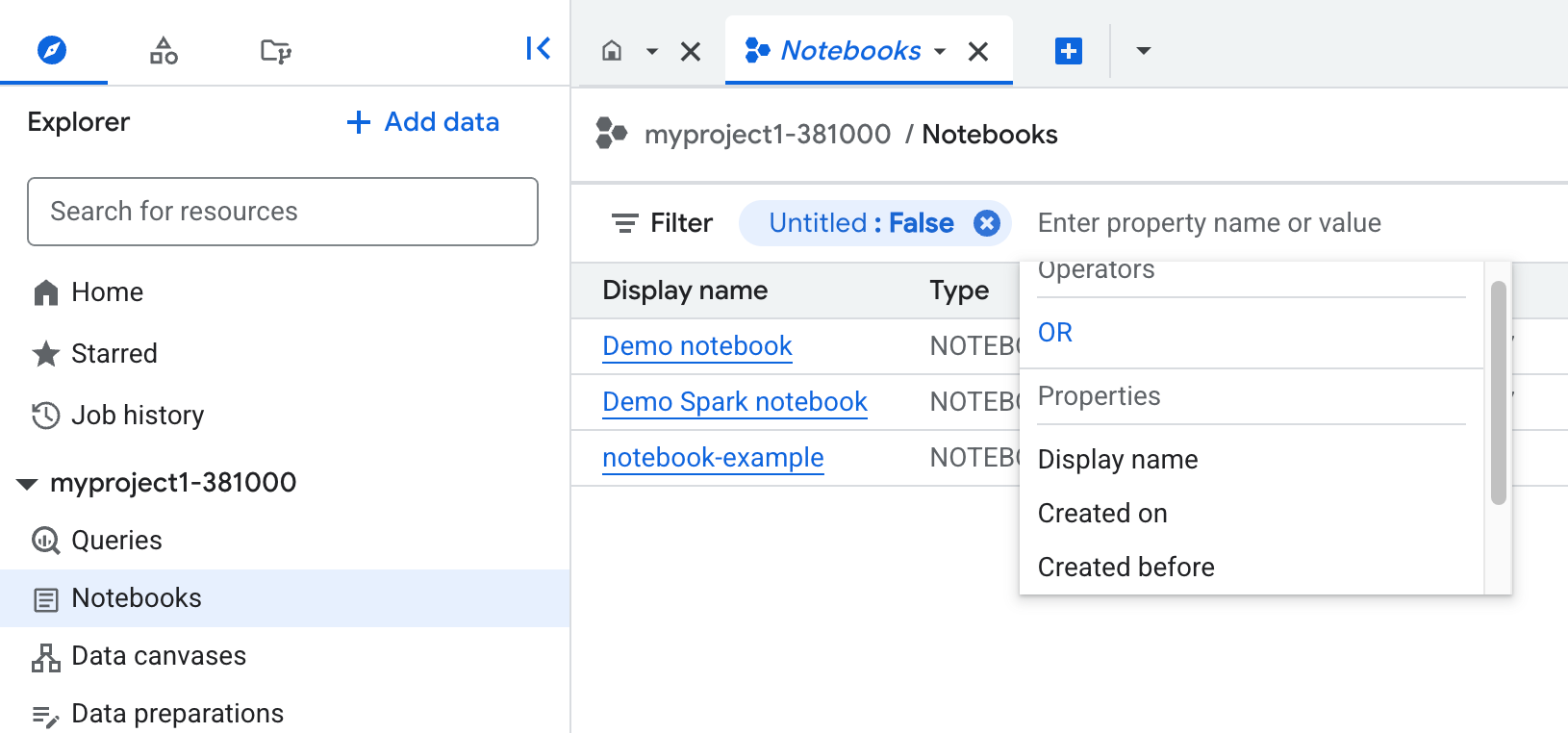
You can use the search feature in the Explorer pane to find resources in BigQuery. The results appear in a new tab in the details pane. You can narrow your search by projects and resources types, such as Dataset. This search feature covers BigQuery resources in your organization, while the Google Cloud toolbar's search feature covers all of Google Cloud.
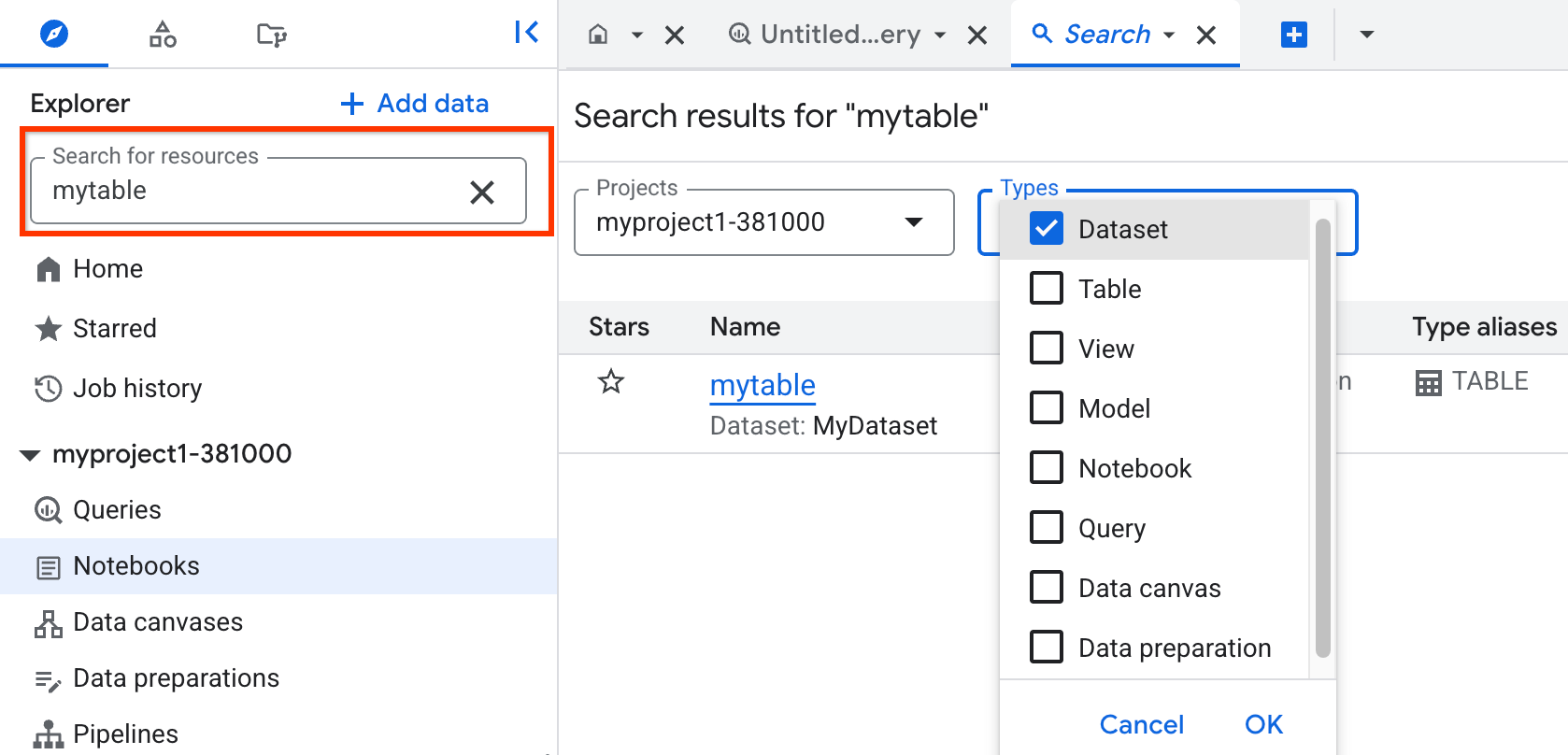
Classic Explorer pane
This pane lists current Google Cloud projects and any starred projects.
To view the resources in your projects and datasets, do the following:
To view the datasets that you have access to in a project, expand the project.
To view tables, views, and functions in a dataset, expand the dataset.
You can also use the search box to search for resources by name (dataset, table, or view name) or by label within your current and starred projects. The search feature finds the resources that directly match, or contain matches, to your search query. It might not show all the resources in the matched resource's level. To see all the resources, click Show more.
Git repository pane
You can use repositories to perform version control on files that you use in BigQuery. BigQuery uses Git to record changes and manage file versions. For more information, see Introduction to repositories.
You can use workspaces within repositories to edit the code stored in the repository. When you click a workspace in the Git repository pane, it opens in a tab in the details pane. For more information, see Introduction to workspaces.
Details pane
The details pane shows information about your BigQuery resources. When you select a dataset, table, view, or other resource in the Classic Explorer pane, a new tab is displayed in the details pane. On these tabs, you can view information about the resource, or you can create tables and views, modify table schemas, export data, and perform other actions.
You can drag the tab to the edge of the editor to open it in a new column so that you can compare the tabs, or drag the tab to a different position in the current or an adjacent column. This feature is in preview.
In the query editor, you can run an interactive query and explore the results in the Query results pane that opens after you run the query.
When you navigate through tabs, the resource corresponding to the focused tab is selected in the Classic Explorer pane. If you open BigQuery using your workspace URL, then your workspace query editor tab opens, and the corresponding resource is selected in the Classic Explorer pane.
You can use the search bar in the Google Cloud toolbar to search for resources (projects, datasets, or tables), documentation, and products (such as Compute Engine and Cloud Storage) across Google Cloud. You might need permissions, similar to BigQuery permissions, to access resources in different products.
Add data dialog
In the Add data dialog, you can use search and filtering capabilities to find a data source that you want to work with. After you select a data source, you can do the following based on the capabilities available for your data source.
Set up BigQuery table over external data (Federation): enables BigQuery to access external data without ingesting it into BigQuery. You can create a table to access external data or create a connection to an external source.
Load data to BigQuery: lets you load data to BigQuery by setting up a data transfer service or by using a partner capability. Loading data to BigQuery is recommended for optimal data processing at scale.
Change data capture to BigQuery: replicates data from a data source to BigQuery by capturing and applying changes. You can use applications such as datastream or partner solutions to ingest data from a data source.
Stream data to BigQuery: ingests data into BigQuery with low latency. You can use applications such as dataflow, Pub/Sub, or partner solutions to ingest data from a data source.
For more information about loading data into BigQuery, see Introduction to loading data.
Additionally, you can do the following:
- Access and query public datasets.
- Go to the Sharing (Analytics Hub) page. For more information, see Introduction to BigQuery sharing.
- Star a project by name.
Work with projects
All of the work that you perform in BigQuery is done within a Google Cloud project. You can see the project name on the Google Cloud console toolbar:

Any costs that you incur for using BigQuery are charged to the billing account that's attached to the project. For more information, see BigQuery pricing.
Switch to a project
To switch to a Google Cloud project in the Google Cloud console, follow these steps:
On the Google Cloud console toolbar, click the name of your project.
In the projects dialog, click the name of the project that you want to switch to.
This selection becomes your active project.
Star a project
You can star a Google Cloud project to the Explorer pane in the following ways:
If you have access to a dataset or table but don't have access to the project that contains that dataset, follow these steps:
On the Google Cloud console toolbar, click the name of your project.
In the projects dialog, search for the project that you want to star.
Hold the pointer over the name of the project, and then click Add star.
If you have the Viewer (
roles/viewer) IAM role on the project, do the following:Method 1
Switch to the project that you want to star.
In the Explorer pane, hold the pointer over the name of the project that you want to star, and then click Star.
Method 2
In the Explorer pane, click Add data.
In the Add data dialog, click Star a project by name.
In the dialog that opens, enter the name of the project that you want to star, and click Star.
You can star a Google Cloud project only through the Google Cloud console.
Remove a project
To remove a project from the Explorer pane, hold the pointer over the name of the project that you want to unstar, and then click Unstar.
Display resources
The Explorer pane lists datasets that you can browse in your current project or any projects that you starred. Consider the following when displaying resources:
- To display the datasets in a project, click Toggle node for that project, and then click Datasets. A new tab opens in the details tab with a list of all the datasets in the project. Click the dataset to see its details.
- To display the tables, views, and functions in a dataset, click Overview > Tables. You can also view a dataset's details, models, and routines in other tabs.
You can also use breadcrumbs to seamlessly navigate through different tabs and resources, as shown in the following screenshot:
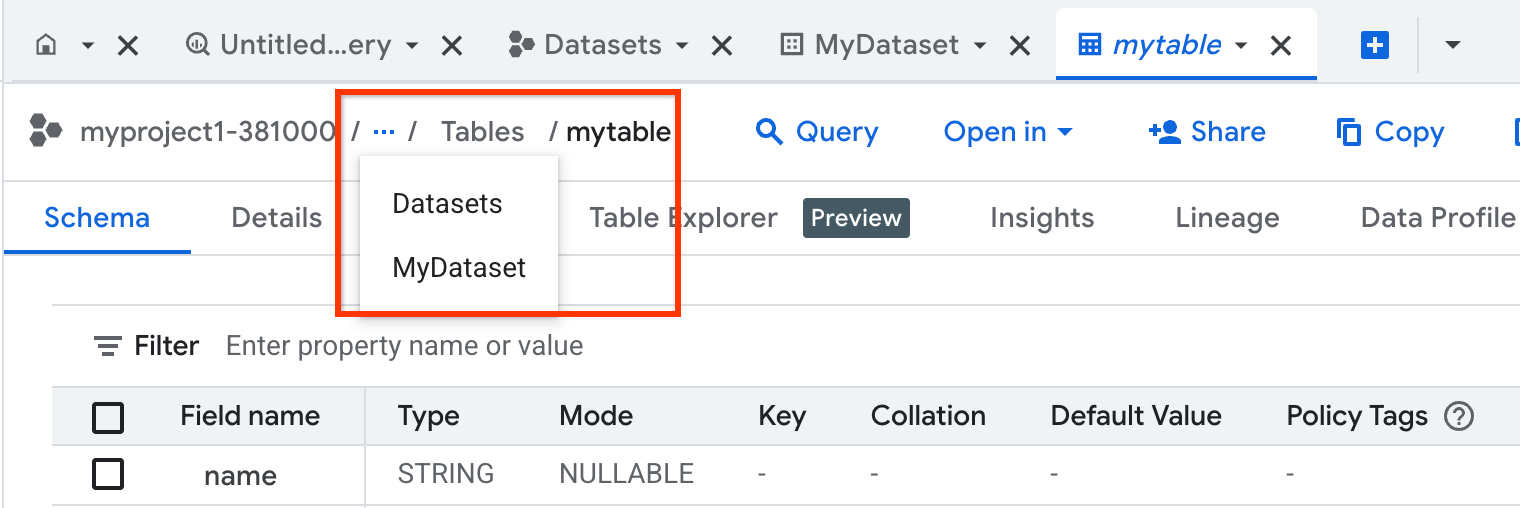
To reduce tab proliferation, clicking a resource opens it within the same tab. To open the resource in a separate tab, press Ctrl (or Command on macOS) and click the resource. To prevent the current tab from getting its content replaced, double-click the tab name (you will notice that its name changes from italicized to regular font). If you still lose your resource, click tab_recent Recent tabs in the details pane to find the resource.
Star resources
If you have important or current projects, datasets, or tables, you can star them in the Classic Explorer pane. To star a resource, hold the pointer over the name of the resource that you want to star, and then click Star.
For more information on starring a project, see Star a project.
View starred resources
To view the starred resources, click Starred in the Explorer pane. A new tab containing a list of all starred resources appears.
If you want to view all the resources as a resource tree, click the Classic Explorer pane, and turn off the Show starred only toggle.
Unstar resources
To unstar a resource, go to the Classic Explorer pane, and then click Unstar next to the resource.
Home tab
The first time you open BigQuery, you see the home tab and a query editor tab, with the home tab in focus. The home tab contains the following:
- The Check out what's new in Studio section that lists new features in BigQuery Studio. You can click Try it to view the features in the console. If the section isn't visible, click What's new in Studio to expand the section.
The Create new section that has options to create a new SQL query, notebook, Apache Spark notebook, data canvas, data preparation file, pipeline, or table.
The Recent section where you can view your 10 most recently accessed resources.
The following demo guides:
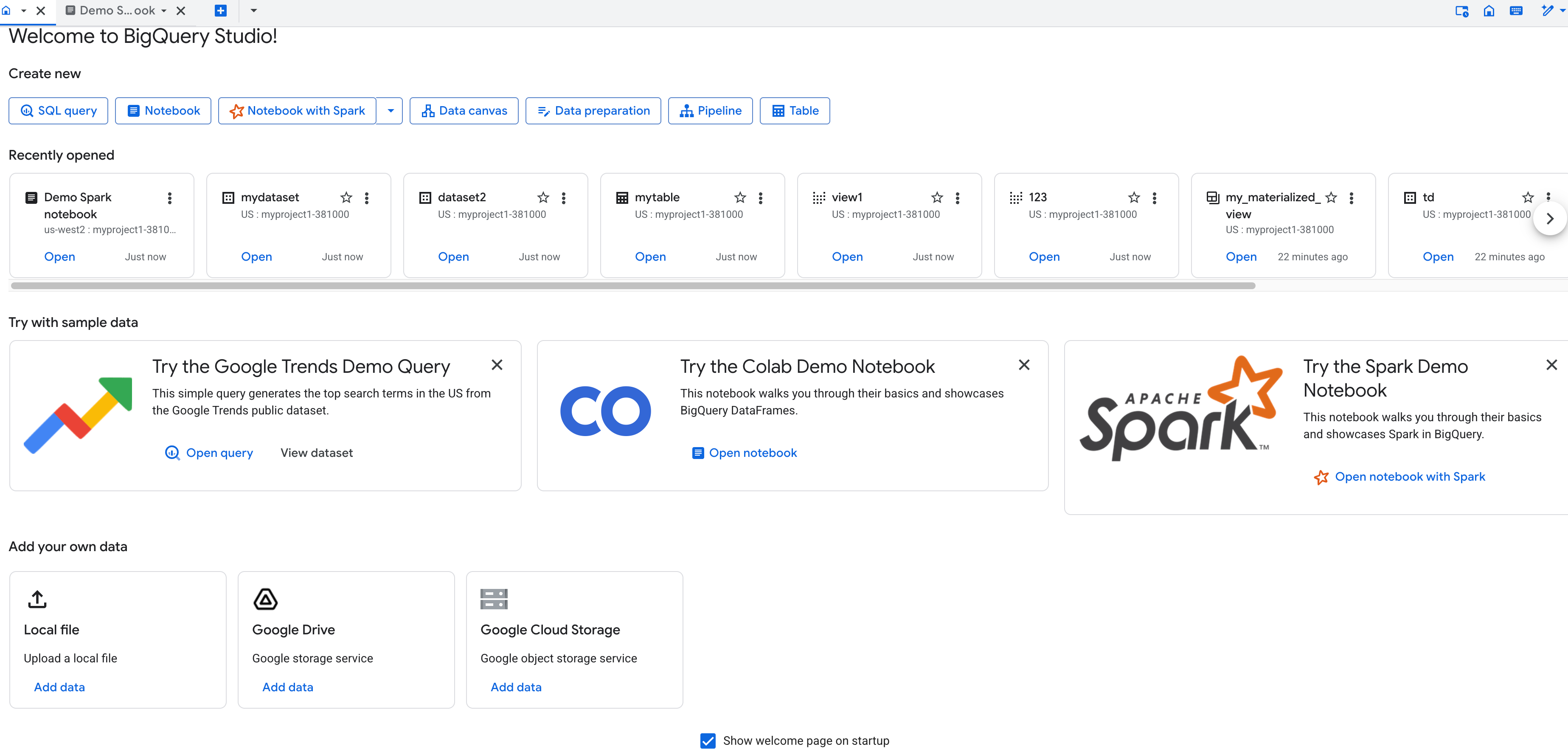
You can close the home tab. To go back to the home tab, click
 *Home in the Explorer pane.
*Home in the Explorer pane.
To open a query editor from the home tab, click SQL query. To access ways to import data and search data sources that work with BigQuery, click Add data.
If you open BigQuery using your workspace URL, then your workspace query editor tab opens first.
View recently accessed resources
In the Google Cloud console, you can view your 10 most recently accessed resources. These resources include tables, saved queries, models, and routines.
When you create or update a resource in the console or query editor, the resource is marked as recent. For a recently opened resource to be marked as recent, you have to open it in the workspace tab. If you run a query on a resource, then the resource is not marked as recent.
To view your recently accessed resources, follow these steps:
In the Google Cloud console, go to the BigQuery page.
Ensure that you are on the BigQuery home page. If necessary, click
Home in the Explorer pane.In the Recent section, you see your 10 recently accessed resources.
Run query demo guide
To run the demo guide for running a sample query on a Google Trends public dataset, follow these steps. To exit the demo at any time, click Close tour.
In the Google Cloud console, go to the BigQuery page.
Ensure that you are on the BigQuery home page. If necessary, click
Home in the Explorer pane.Click Open this query.
The
bigquery-public-dataproject is automatically added to the Explorer pane. The public project and thegoogle_trendsdataset are expanded, and the Google Trends Data dialog highlights the starredtop_termstable. Additionally, the query editor is opened with a predefined query.
In the Google Trends Data dialog, click Next.
In the Google Trends Query dialog, click Next.
To return to the previous step, click Back in the dialog.
In the Run this query dialog, click Try it.
To return to the previous step, click Back in the dialog.
In the Query results dialog, click Done.

You can run this demo multiple times.
To view the Google Trends public dataset, in the home page, click View dataset.
Run the Colab notebook demo guide
To run the demo guide, follow these steps. To exit the demo at any time, click Close tour. To return to the previous step, where applicable, click Back in the dialog.
In the Google Cloud console, go to the BigQuery page.
Ensure that you are on the BigQuery home page. If necessary, click
Home in the Explorer pane.Click Open Notebook.
The
Demo notebooknotebook is automatically added to Shared notebooks in the Explorer pane and opens in a tabbed editor.In the Notebook dialog, click Next.
In the Activity dialog, review information about locating file details and version history, and then click Next.
In the Connect dialog, see the highlighted Connect button that you can use to connect the notebook to the runtime. Click Next.
In the Cell dialog, review information about cells in the notebook, and then click Next.

In the Code dialog, see the highlighted Code button that you can use to add a new code cell into the notebook. Click Next.
In the Commands dialog, see the highlighted Commands button that you can use to open a list of notebook actions. Click Next.
In the Terminal dialog, see the highlighted Terminal button that you can use to open a terminal to access the runtime through a command line. Click Done.
Run Apache Spark notebook demo guide
To run the demo guide, follow these steps. To exit the demo at any time, click Close tour. To return to the previous step, where applicable, click Back in the dialog.
In the Google Cloud console, go to the BigQuery page.
Ensure that you are on the BigQuery home page. If necessary, click
Home in the Explorer pane.Click Open notebook with Spark.
Select a region and enable the BigQuery Unified API if you haven't already. A demo Spark notebook is automatically added to Shared notebooks in the Explorer pane and opens in a tabbed editor.
In the Notebook dialog, click Next.
In the Activity dialog, review information about locating file details and version history, and then click Next.
In the Connect dialog, see the highlighted Connect button that you can use to connect the notebook to the runtime. Click Next.
In the Cell dialog, review information about cells in the notebook, and then click Next.
In the Code dialog, see the highlighted Code button that you can use to add a new code cell into the notebook. Click Next.
In the Commands dialog, see the highlighted Commands button that you can use to open a list of notebook actions. Click Next.
In the Terminal dialog, see the highlighted Terminal button that you can use to open a terminal to access the runtime through a command line. Click Done.
Run add data demo guide
The Add your own data section contains the demo guide for adding data to BigQuery through popular sources.
To run the demo guide, follow these steps. To exit the demo at any time, click Close tour. To return to the previous step where applicable, click Back.
In the Google Cloud console, go to the BigQuery page.
Ensure that you are on the BigQuery home page. If necessary, click
Home in the Explorer pane.Click Launch this guide for one of the three options: Local file, Google Drive, or Googe Cloud Storage.
In the Open Add Data panel dialog, click Try it.
The source type that you selected is highlighted on the Add data pane.
In the Select source dialog, click Try it.
In the Configure source details dialog, click Next.
In the Configure destination details dialog, click Next.
In the Create table dialog, click Done.
You can run this demo guide only once through either of the three available sources in the Add your own data section. After you complete the demo, the Launch this guide buttons change to Add data and act as a shortcut to the Create table subtask.
Work with tabs
You can control how you work with tabs in the details pane.
Split two tabs
Whenever you select a resource or click Compose new query in the details pane, a new tab opens. If more than one tab is open, you can split the tabs into two panes and view them side by side.
To split tabs into two panes, follow these steps:
Next to the tab name, click Open menu.
Select one of the following options:
- To place the selected tab in the left pane, select Split tab to left.
- To place the selected tab in the right pane, select Split tab to right.
To unsplit the tabs, select Open menu on one of the open tabs, and then select Move tab to left pane or Move tab to right pane.
To split tabs when querying tables, follow these steps:
In the Explorer menu, click the table that you want to query.
Click Query, and then click In new tab or In split tab:

Click the field name that you want to query:

The following image shows the details pane with two open tabs. One tab has a SQL query, and the other tab shows details about a table.

Move a tab
To move a tab from one pane to the other pane, follow these steps:
Next to the tab name, click Open menu.
Select Move tab to right pane or Move tab to left pane (whichever option is available).
Close a tab
To close all tabs except for one, follow these steps:
Next to the tab name, click Open menu.
Select Close other tabs.
View personal and project history
Every time you load, export, query, or copy data, BigQuery automatically creates, schedules, and runs a job that tracks the progress of the task. To view job histories of your current billing project, do the following:
Go to the BigQuery page.
In the left pane, click Explorer:

In the Explorer pane, click Job history.
This opens the list of job histories in a new tab:

To view details of your own jobs, click Personal history.
To view details of recent jobs in your project, click Project history.
To see the details of a job or to open the query in an editor, do the following:
In the Actions column for a job or query, click Actions.
Select Show job details or View job in editor.
For more information about managing jobs, see Manage jobs.
Keyboard shortcuts
To view shortcuts in the Google Cloud console, click BigQuery Studio shortcuts. The following keyboard shortcuts are supported in the Google Cloud console:
| Action | Windows or Linux shortcut | macOS shortcut |
|---|---|---|
| Create a new tab |
|
|
| Close tab (keyboard focused tab) |
or
|
or
|
| Format query |
|
|
| Gemini code completion and generation |
|
|
| Jump to a specific tab |
|
|
| Jump to last tab |
|
|
| Jump to next open tab |
or
|
|
| Jump to previous open tab |
or
|
|
| Move tab left |
|
|
| Move tab right |
|
|
| Open tab menu (keyboard focused tab) |
|
|
| Run query or highlighted query |
or
|
or
|
| See list of editor shortcuts |
|
|
| Split or move active tab to left |
|
|
| Split or move active tab to right |
|
|
| SQL autosuggest |
or
|
or
|
| SQL generation tool |
|
|
| Toggle line comment |
|
|
Examples
You can find Google Cloud console examples throughout the how-to guides section of the BigQuery documentation.
To see examples of loading data and querying data using the Google Cloud console, see the Load and query data with the Google Cloud console.
What's next
- To learn about querying a public dataset and using the BigQuery sandbox, see Query a public dataset with the Google Cloud console.