导出模型
本页面介绍如何导出 BigQuery ML 模型。您可以将 BigQuery ML 模型导出到 Cloud Storage,并使用它们进行在线预测,或在 Python 中对其进行修改。您可以通过以下方式导出 BigQuery ML 模型:
- 使用 Google Cloud 控制台。
- 使用
EXPORT MODEL语句。 - 在 bq 命令行工具中使用
bq extract命令。 - 通过 API 或客户端库提交
extract作业。
您可以导出以下模型类型:
AUTOENCODERAUTOML_CLASSIFIERAUTOML_REGRESSORBOOSTED_TREE_CLASSIFIERBOOSTED_TREE_REGRESSORDNN_CLASSIFIERDNN_REGRESSORDNN_LINEAR_COMBINED_CLASSIFIERDNN_LINEAR_COMBINED_REGRESSORKMEANSLINEAR_REGLOGISTIC_REGMATRIX_FACTORIZATIONRANDOM_FOREST_CLASSIFIERRANDOM_FOREST_REGRESSORTENSORFLOW(导入的 TensorFlow 模型)PCATRANSFORM_ONLY
导出模型格式和示例
下表展示了每种 BigQuery ML 模型类型的导出目标格式,并提供了写入到 Cloud Storage 存储桶中的文件示例。
| 模型类型 | 导出模型格式 | 导出文件示例 |
|---|---|---|
| AUTOML_CLASSIFIER | TensorFlow SavedModel (TF 2.1.0) | gcs_bucket/
|
| AUTOML_REGRESSOR | ||
| AUTOENCODER | TensorFlow SavedModel(TF 1.15 或更高版本) | |
| DNN_CLASSIFIER | ||
| DNN_REGRESSOR | ||
| DNN_LINEAR_COMBINED_CLASSIFIER | ||
| DNN_LINEAR_COMBINED_REGRESSOR | ||
| KMEANS | ||
| LINEAR_REGRESSOR | ||
| LOGISTIC_REG | ||
| MATRIX_FACTORIZATION | ||
| PCA | ||
| TRANSFORM_ONLY | ||
| BOOSTED_TREE_CLASSIFIER | 增强器 (XGBoost 0.82) | gcs_bucket/
main.py 用于本地运行。如需了解详情,请参阅模型部署。 |
| BOOSTED_TREE_REGRESSOR | ||
| RANDOM_FOREST_REGRESSOR | ||
| RANDOM_FOREST_REGRESSOR | ||
| TENSORFLOW(导入的模型) | TensorFlow SavedModel | 与导入模型时存在的文件完全相同 |
导出使用 TRANSFORM 训练的模型
如果模型是使用 TRANSFORM 子句训练的,则一个额外的预处理模型会在 TRANSFORM 子句中执行相同的逻辑,并以 TensorFlow SavedModel 格式保存在子目录 transform 下。您可以将使用 TRANSFORM 子句训练的模型部署到 Vertex AI 以及本地。如需了解详情,请参阅模型部署。
| 导出模型格式 | 导出文件示例 |
|---|---|
|
预测模型:TensorFlow SavedModel 或增强器 (XGBoost 0.82)。 TRANSFORM 子句的预处理模型:TensorFlow SavedModel(TF 2.5 或更高版本) |
gcs_bucket/
|
该模型不包含训练期间在 TRANSFORM 子句之外执行的特征工程的信息,例如,SELECT 语句中的任何内容。因此,您需要在将输入数据输入到预处理模型之前手动转换输入数据。
支持的数据类型
导出使用 TRANSFORM 子句训练的模型时,系统支持将以下数据类型输入 TRANSFORM 子句。
| TRANSFORM 输入类型 | TRANSFORM 输入示例 | 导出的预处理模型输入示例 |
|---|---|---|
| INT64 |
10,
|
tf.constant(
|
| NUMERIC |
NUMERIC 10,
|
tf.constant(
|
| BIGNUMERIC |
BIGNUMERIC 10,
|
tf.constant(
|
| FLOAT64 |
10.0,
|
tf.constant(
|
| 布尔值 |
TRUE,
|
tf.constant(
|
| STRING |
'abc',
|
tf.constant(
|
| BYTES |
b'abc',
|
tf.constant(
|
| DATE |
DATE '2020-09-27',
|
tf.constant(
|
| DATETIME |
DATETIME '2023-02-02 02:02:01.152903',
|
tf.constant(
|
| 时间 |
TIME '16:32:36.152903',
|
tf.constant(
|
| 时间戳 |
TIMESTAMP '2017-02-28 12:30:30.45-08',
|
tf.constant(
|
| ARRAY |
['a', 'b'],
|
tf.constant(
|
| ARRAY< STRUCT< INT64, FLOAT64>> |
[(1, 1.0), (2, 1.0)],
|
tf.sparse.from_dense(
|
| NULL |
NULL,
|
tf.constant(
|
支持的 SQL 函数
导出使用 TRANSFORM 子句训练的模型时,您可以在 TRANSFORM 子句中使用以下 SQL 函数。
- 运算符
+,-,*,/,=,<,>,<=,>=,!=,<>,[NOT] BETWEEN,[NOT] IN,IS [NOT] NULL,IS [NOT] TRUE,IS [NOT] FALSE,NOT,AND,OR。
- 条件表达式
CASE expr,CASE,COALESCE,IF,IFNULL,NULLIF。
- 数学函数
ABS,ACOS,ACOSH,ASINH,ATAN,ATAN2,ATANH,CBRT,CEIL,CEILING,COS,COSH,COT,COTH,CSC,CSCH,EXP,FLOOR,IS_INF,IS_NAN,LN,LOG,LOG10,MOD,POW,POWER,SEC,SECH,SIGN,SIN,SINH,SQRT,TAN,TANH。
- 转换函数
CAST AS INT64,CAST AS FLOAT64,CAST AS NUMERIC,CAST AS BIGNUMERIC,CAST AS STRING,SAFE_CAST AS INT64,SAFE_CAST AS FLOAT64
- 字符串函数
CONCAT,LEFT,LENGTH,LOWER,REGEXP_REPLACE,RIGHT,SPLIT,SUBSTR,SUBSTRING,TRIM,UPPER。
- 日期函数
Date,DATE_ADD,DATE_SUB,DATE_DIFF,DATE_TRUNC,EXTRACT,FORMAT_DATE,PARSE_DATE,SAFE.PARSE_DATE
- 日期时间函数
DATETIME,DATETIME_ADD,DATETIME_SUB,DATETIME_DIFF,DATETIME_TRUNC,EXTRACT,PARSE_DATETIME,SAFE.PARSE_DATETIME
- 时间函数
TIME,TIME_ADD,TIME_SUB,TIME_DIFF,TIME_TRUNC,EXTRACT,FORMAT_TIME,PARSE_TIME,SAFE.PARSE_TIME
- 时间戳函数
TIMESTAMP,TIMESTAMP_ADD,TIMESTAMP_SUB,TIMESTAMP_DIFF,TIMESTAMP_TRUNC,FORMAT_TIMESTAMP,PARSE_TIMESTAMP,SAFE.PARSE_TIMESTAMP,TIMESTAMP_MICROS,TIMESTAMP_MILLIS,TIMESTAMP_SECONDS,EXTRACT,STRING,UNIX_MICROS,UNIX_MILLIS,UNIX_SECONDS
- 手动预处理函数
ML.IMPUTER,ML.HASH_BUCKETIZE,ML.LABEL_ENCODER,ML.MULTI_HOT_ENCODER,ML.NGRAMS,ML.ONE_HOT_ENCODER,ML.BUCKETIZE,ML.MAX_ABS_SCALER,ML.MIN_MAX_SCALER,ML.NORMALIZER,ML.QUANTILE_BUCKETIZE,ML.ROBUST_SCALER,ML.STANDARD_SCALER。
限制
导出模型时存在以下限制:
如果训练期间使用了以下任何特征,则不支持模型导出:
- 输入数据中存在
ARRAY、TIMESTAMP或GEOGRAPHY特征类型。
- 输入数据中存在
模型类型
AUTOML_REGRESSOR和AUTOML_CLASSIFIER的导出模型不支持用于在线预测的 Vertex AI 部署。对于矩阵分解模型导出,模型大小限制为 1 GB。模型大小与
num_factors大致成比例,因此,如果您在训练期间达到模型大小限制,可以减少num_factors以缩减模型大小。对于使用 BigQuery ML
TRANSFORM子句进行手动特征预处理训练的模型,请参阅导出支持的数据类型和函数。在 2023 年 9 月 18 日之前使用 BigQuery ML
TRANSFORM子句训练的模型必须重新训练,然后才能通过 Model Registry 部署以进行在线预测。在模型导出期间,系统支持
ARRAY<STRUCT<INT64, FLOAT64>>、ARRAY和TIMESTAMP作为预转换数据,但不支持作为转换后数据。
导出 BigQuery ML 模型
如需导出模型,请执行以下操作:
控制台
在 Google Cloud 控制台中打开 BigQuery 页面。
在导航面板的资源部分,展开您的项目并点击您的数据集以将其展开。找到并点击要导出的模型。
点击窗口右侧的导出模型。
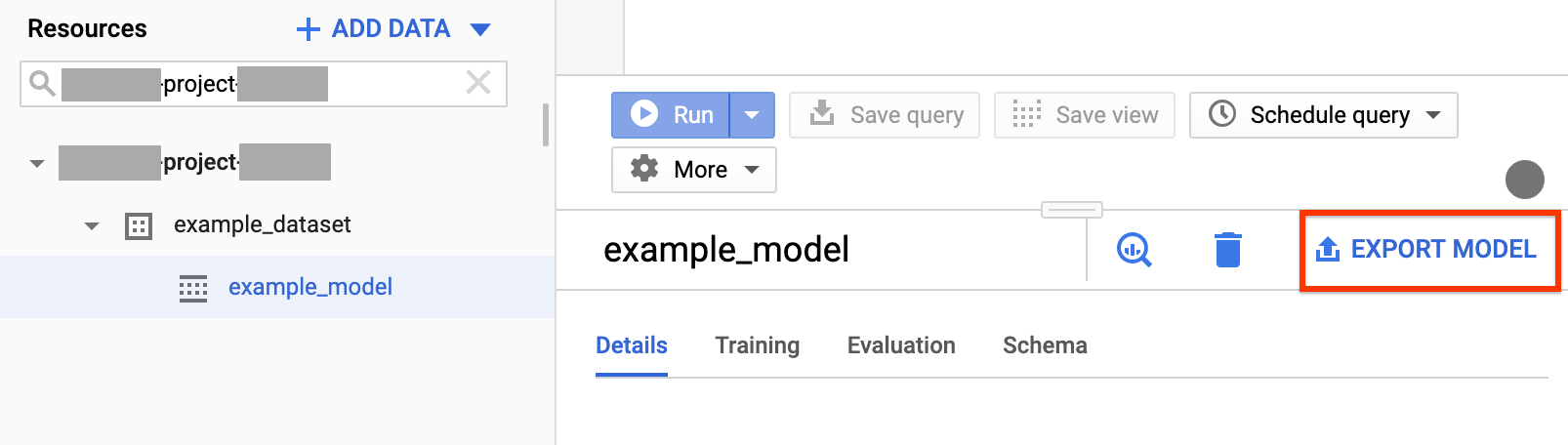
在导出到 Cloud Storage 对话框中,执行以下操作:
- 在选择 Cloud Storage 位置部分,浏览到要将模型导出到的目标存储桶或文件夹位置。
- 点击导出以导出模型。
如需检查作业进度,请在导航窗格顶部附近查找相应导出作业的作业记录。
SQL
借助 EXPORT MODEL 语句,您可以使用 GoogleSQL 查询语法将 BigQuery ML 模型导出到 Cloud Storage。
如需使用 EXPORT MODEL 语句在 Google Cloud 控制台中导出 BigQuery ML 模型,请按照以下步骤操作:
在 Google Cloud 控制台中,打开 BigQuery 页面。
点击编写新查询。
在查询编辑器字段中,输入
EXPORT MODEL语句。以下查询会将名为
myproject.mydataset.mymodel的模型导出到 URI 为gs://bucket/path/to/saved_model/的 Cloud Storage 存储桶。EXPORT MODEL `myproject.mydataset.mymodel` OPTIONS(URI = 'gs://bucket/path/to/saved_model/')
点击运行。查询完成后,查询结果窗格中会显示以下内容:
Successfully exported model。
bq
使用带有 --model 标志的 bq extract 命令。
(可选)提供 --destination_format 标志并选择导出的模型的格式。(可选)提供 --location 标志并将值设置为您所用的位置。
bq --location=location extract \ --destination_format format \ --model project_id:dataset.model \ gs://bucket/model_folder
其中:
- location 是位置的名称。
--location是可选标志。例如,如果您在东京区域使用 BigQuery,可将该标志的值设置为asia-northeast1。您可以使用 .bigqueryrc 文件设置默认位置值。 - destination_format 是导出模型的格式:
ML_TF_SAVED_MODEL(默认)或ML_XGBOOST_BOOSTER。 - project_id 是项目 ID。
- dataset 是源数据集的名称。
- model 是您要导出的模型。
- bucket 是要向其中导出数据的 Cloud Storage 存储分区的名称。BigQuery 数据集和 Cloud Storage 存储桶必须位于同一位置。
- model_folder 是将写入导出模型文件的文件夹的名称。
示例:
例如,以下命令将 TensorFlow SavedModel 格式的 mydataset.mymodel 导出到名为 mymodel_folder 的 Cloud Storage 存储分区。
bq extract --model \ 'mydataset.mymodel' \ gs://example-bucket/mymodel_folder
destination_format 的默认值为 ML_TF_SAVED_MODEL。
以下命令以 XGBoost 增强器格式将 mydataset.mymodel 导出到名为 mymodel_folder 的 Cloud Storage 存储桶。
bq extract --model \ --destination_format ML_XGBOOST_BOOSTER \ 'mydataset.mytable' \ gs://example-bucket/mymodel_folder
API
如需导出模型,请创建一个 extract 作业,并填充作业配置。
(可选)在作业资源的 jobReference 部分的 location 属性中指定您的位置。
创建一个 extract 作业,将其指向 BigQuery ML 模型和 Cloud Storage 目的地。
使用包含项目 ID、数据集 ID 和模型 ID 的
sourceModel配置对象指定源模型。destination URI(s)属性必须是完全限定的,格式为 gs://bucket/model_folder。通过设置
configuration.extract.destinationFormat属性来指定目的地格式。例如,如需导出提升树模型,请将此属性设置为ML_XGBOOST_BOOSTER值。如需检查作业状态,请使用初始请求返回的作业 ID 来调用 jobs.get(job_id)。
- 如果
status.state = DONE,则表示作业已成功完成。 - 如果出现
status.errorResult属性,则表示请求失败,并且该对象将包含描述问题的相关信息。 - 如果未出现
status.errorResult,则表示作业已成功完成,但可能存在一些非严重错误。返回的作业对象的status.errors属性中列出了非严重错误。
- 如果
API 说明:
在调用
jobs.insert来创建作业时,最佳做法是生成唯一 ID,并将其作为jobReference.jobId传递。此方法受网络故障影响较小,因为客户端可以对已知的作业 ID 进行轮询或重试。对指定的作业 ID 调用
jobs.insert具有幂等性,也就是说,您可以对同一作业 ID 进行无限次重试,但这些操作中最多只有一个操作会成功。
Java
试用此示例之前,请按照 BigQuery 快速入门:使用客户端库中的 Java 设置说明进行操作。 如需了解详情,请参阅 BigQuery Java API 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为客户端库设置身份验证。
模型部署
您可以将导出的模型部署到 Vertex AI 以及在本地部署导出的模型。如果模型的 TRANSFORM 子句包含日期函数、日期时间函数、时间函数或时间戳函数,您必须在容器中使用 bigquery-ml-utils 库。例外情况是通过 Model Registry 部署(不需要导出的模型或服务容器)。
Vertex AI 部署
| 导出模型格式 | 部署 |
|---|---|
| TensorFlow SavedModel(非 AutoML 模型) | 部署 TensorFlow SavedModel。您必须使用受支持的 TensorFlow 版本创建 SavedModel 文件。 |
| TensorFlow SavedModel(AutoML 模型) | 不受支持。 |
| XGBoost 增强器 |
使用自定义预测例程。对于 XGBoost 增强器模型,预处理和后处理信息会保存在导出的文件中,并且自定义预测例程可让您使用额外的导出文件部署模型。 您必须使用受支持版本的 XGBoost 创建模型文件。 |
本地部署
| 导出模型格式 | 部署 |
|---|---|
| TensorFlow SavedModel(非 AutoML 模型) | SavedModel 是一种标准格式,您可以在 TensorFlow Serving Docker 容器中部署此类模型。 您也可以利用 Vertex AI Online Prediction 的本地运行。 |
| TensorFlow SavedModel(AutoML 模型) | 将模型容器化并运行。 |
| XGBoost 增强器 | 如需在本地运行 XGBoost 增强器模型,您可以使用导出的 main.py 文件:
|
预测输出格式
本部分介绍每种模型类型的导出模型的预测输出格式。所有导出的模型均支持批量预测;它们可以一次处理多个输入行。例如,以下每个输出格式示例中都有两个输入行。
AUTOENCODER
| 预测输出格式 | 输出示例 |
|---|---|
+------------------------+------------------------+------------------------+
| LATENT_COL_1 | LATENT_COL_2 | ... |
+------------------------+------------------------+------------------------+
| [FLOAT] | [FLOAT] | ... |
+------------------------+------------------------+------------------------+
|
+------------------+------------------+------------------+------------------+
| LATENT_COL_1 | LATENT_COL_2 | LATENT_COL_3 | LATENT_COL_4 |
+------------------------+------------+------------------+------------------+
| 0.21384512 | 0.93457112 | 0.64978097 | 0.00480489 |
+------------------+------------------+------------------+------------------+
|
AUTOML_CLASSIFIER
| 预测输出格式 | 输出示例 |
|---|---|
+------------------------------------------+
| predictions |
+------------------------------------------+
| [{"scores":[FLOAT], "classes":[STRING]}] |
+------------------------------------------+
|
+---------------------------------------------+
| predictions |
+---------------------------------------------+
| [{"scores":[1, 2], "classes":['a', 'b']}, |
| {"scores":[3, 0.2], "classes":['a', 'b']}] |
+---------------------------------------------+
|
AUTOML_REGRESSOR
| 预测输出格式 | 输出示例 |
|---|---|
+-----------------+
| predictions |
+-----------------+
| [FLOAT] |
+-----------------+
|
+-----------------+
| predictions |
+-----------------+
| [1.8, 2.46] |
+-----------------+
|
BOOSTED_TREE_CLASSIFIER 和 RANDOM_FOREST_CLASSIFIER
| 预测输出格式 | 输出示例 |
|---|---|
+-------------+--------------+-----------------+
| LABEL_PROBS | LABEL_VALUES | PREDICTED_LABEL |
+-------------+--------------+-----------------+
| [FLOAT] | [STRING] | STRING |
+-------------+--------------+-----------------+
|
+-------------+--------------+-----------------+
| LABEL_PROBS | LABEL_VALUES | PREDICTED_LABEL |
+-------------+--------------+-----------------+
| [0.1, 0.9] | ['a', 'b'] | ['b'] |
+-------------+--------------+-----------------+
| [0.8, 0.2] | ['a', 'b'] | ['a'] |
+-------------+--------------+-----------------+
|
BOOSTED_TREE_REGRESSOR 和 RANDOM_FOREST_REGRESSOR
| 预测输出格式 | 输出示例 |
|---|---|
+-----------------+
| predicted_label |
+-----------------+
| FLOAT |
+-----------------+
|
+-----------------+
| predicted_label |
+-----------------+
| [1.8] |
+-----------------+
| [2.46] |
+-----------------+
|
DNN_CLASSIFIER
| 预测输出格式 | 输出示例 |
|---|---|
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| ALL_CLASS_IDS | ALL_CLASSES | CLASS_IDS | CLASSES | LOGISTIC (binary only) | LOGITS | PROBABILITIES |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [INT64] | [STRING] | INT64 | STRING | FLOAT | [FLOAT]| [FLOAT] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
|
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| ALL_CLASS_IDS | ALL_CLASSES | CLASS_IDS | CLASSES | LOGISTIC (binary only) | LOGITS | PROBABILITIES |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [0, 1] | ['a', 'b'] | [0] | ['a'] | [0.36] | [-0.53]| [0.64, 0.36] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [0, 1] | ['a', 'b'] | [0] | ['a'] | [0.2] | [-1.38]| [0.8, 0.2] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
|
DNN_REGRESSOR
| 预测输出格式 | 输出示例 |
|---|---|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| FLOAT |
+-----------------+
|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| [1.8] |
+-----------------+
| [2.46] |
+-----------------+
|
DNN_LINEAR_COMBINED_CLASSIFIER
| 预测输出格式 | 输出示例 |
|---|---|
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| ALL_CLASS_IDS | ALL_CLASSES | CLASS_IDS | CLASSES | LOGISTIC (binary only) | LOGITS | PROBABILITIES |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [INT64] | [STRING] | INT64 | STRING | FLOAT | [FLOAT]| [FLOAT] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
|
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| ALL_CLASS_IDS | ALL_CLASSES | CLASS_IDS | CLASSES | LOGISTIC (binary only) | LOGITS | PROBABILITIES |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [0, 1] | ['a', 'b'] | [0] | ['a'] | [0.36] | [-0.53]| [0.64, 0.36] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [0, 1] | ['a', 'b'] | [0] | ['a'] | [0.2] | [-1.38]| [0.8, 0.2] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
|
DNN_LINEAR_COMBINED_REGRESSOR
| 预测输出格式 | 输出示例 |
|---|---|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| FLOAT |
+-----------------+
|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| [1.8] |
+-----------------+
| [2.46] |
+-----------------+
|
KMEANS
| 预测输出格式 | 输出示例 |
|---|---|
+--------------------+--------------+---------------------+
| CENTROID_DISTANCES | CENTROID_IDS | NEAREST_CENTROID_ID |
+--------------------+--------------+---------------------+
| [FLOAT] | [INT64] | INT64 |
+--------------------+--------------+---------------------+
|
+--------------------+--------------+---------------------+
| CENTROID_DISTANCES | CENTROID_IDS | NEAREST_CENTROID_ID |
+--------------------+--------------+---------------------+
| [1.2, 1.3] | [1, 2] | [1] |
+--------------------+--------------+---------------------+
| [0.4, 0.1] | [1, 2] | [2] |
+--------------------+--------------+---------------------+
|
LINEAR_REG
| 预测输出格式 | 输出示例 |
|---|---|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| FLOAT |
+-----------------+
|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| [1.8] |
+-----------------+
| [2.46] |
+-----------------+
|
LOGISTIC_REG
| 预测输出格式 | 输出示例 |
|---|---|
+-------------+--------------+-----------------+
| LABEL_PROBS | LABEL_VALUES | PREDICTED_LABEL |
+-------------+--------------+-----------------+
| [FLOAT] | [STRING] | STRING |
+-------------+--------------+-----------------+
|
+-------------+--------------+-----------------+
| LABEL_PROBS | LABEL_VALUES | PREDICTED_LABEL |
+-------------+--------------+-----------------+
| [0.1, 0.9] | ['a', 'b'] | ['b'] |
+-------------+--------------+-----------------+
| [0.8, 0.2] | ['a', 'b'] | ['a'] |
+-------------+--------------+-----------------+
|
MATRIX_FACTORIZATION
注意:我们目前仅支持接受输入用户并输出按 predicted_rating 降序排列的前 50 个 (predicted_rating, predicted_item) 对。
| 预测输出格式 | 输出示例 |
|---|---|
+--------------------+--------------+
| PREDICTED_RATING | PREDICTED_ITEM |
+------------------+----------------+
| [FLOAT] | [STRING] |
+------------------+----------------+
|
+--------------------+--------------+
| PREDICTED_RATING | PREDICTED_ITEM |
+------------------+----------------+
| [5.5, 1.7] | ['A', 'B'] |
+------------------+----------------+
| [7.2, 2.7] | ['B', 'A'] |
+------------------+----------------+
|
TENSORFLOW(导入的模型)
| 预测输出格式 |
|---|
| 与导入的模型相同 |
PCA
| 预测输出格式 | 输出示例 |
|---|---|
+-------------------------+---------------------------------+
| PRINCIPAL_COMPONENT_IDS | PRINCIPAL_COMPONENT_PROJECTIONS |
+-------------------------+---------------------------------+
| [INT64] | [FLOAT] |
+-------------------------+---------------------------------+
|
+-------------------------+---------------------------------+
| PRINCIPAL_COMPONENT_IDS | PRINCIPAL_COMPONENT_PROJECTIONS |
+-------------------------+---------------------------------+
| [1, 2] | [1.2, 5.0] |
+-------------------------+---------------------------------+
|
TRANSFORM_ONLY
| 预测输出格式 |
|---|
与模型 TRANSFORM 子句中指定的列相同
|
XGBoost 模型可视化
您可以在模型导出后使用 plot_tree Python API 直观呈现提升树。例如,您可以利用 Colab 而不安装依赖项:
- 将提升树模型导出到 Cloud Storage 存储桶。
- 从 Cloud Storage 存储分区下载
model.bst文件。 - 在 Colab 笔记本中,将
model.bst文件上传到Files。 在笔记本中运行以下代码:
import xgboost as xgb import matplotlib.pyplot as plt model = xgb.Booster(model_file="model.bst") num_iterations = <iteration_number> for tree_num in range(num_iterations): xgb.plot_tree(model, num_trees=tree_num) plt.show
以下示例绘制了多个树(每个迭代一个树):
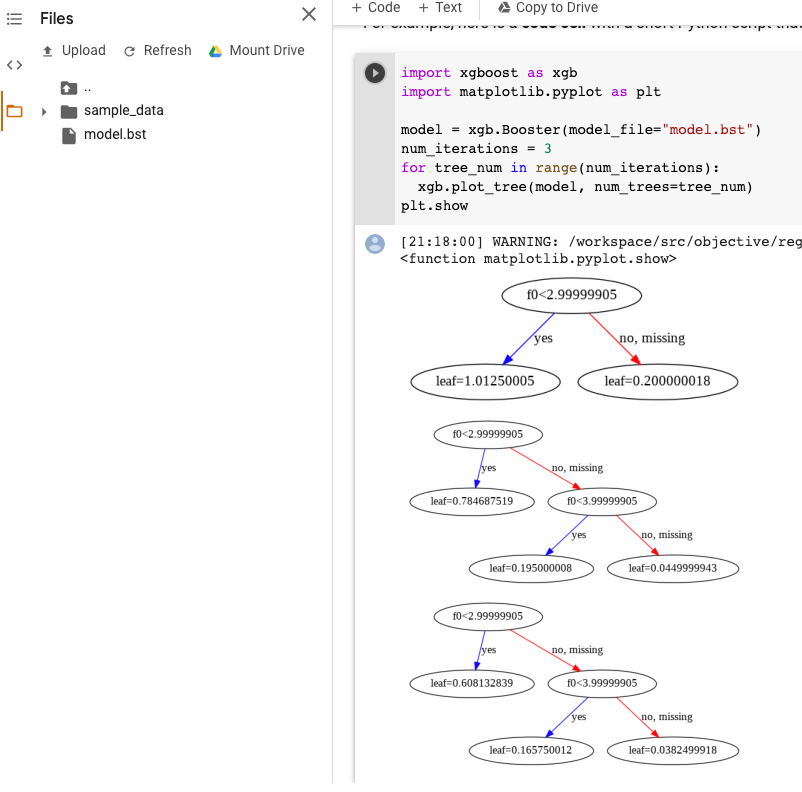
目前,我们不会在模型中保存特征名称,因此您会看到诸如“f0”“f1”之类的名称。您可以在使用这些名称(例如“f0”)作为索引的 assets/model_metadata.json 导出文件中找到相应的特征名称。
所需权限
如需将 BigQuery ML 模型导出到 Cloud Storage,您需要具有访问 BigQuery ML 模型、运行导出作业,以及将数据写入 Cloud Storage 存储桶的权限。
BigQuery 权限
如需导出模型,您至少必须具有
bigquery.models.export权限。以下预定义的 Identity and Access Management (IAM) 角色具有bigquery.models.export权限:bigquery.dataViewerbigquery.dataOwnerbigquery.dataEditorbigquery.admin
如需运行导出作业,您至少必须具有
bigquery.jobs.create权限。以下预定义的 IAM 角色具有bigquery.jobs.create权限:bigquery.userbigquery.jobUserbigquery.admin
Cloud Storage 权限
要将数据写入现有 Cloud Storage 存储分区,您必须具有
storage.objects.create权限。以下预定义的 IAM 角色具有storage.objects.create权限:storage.objectCreatorstorage.objectAdminstorage.admin
如需详细了解 BigQuery ML 中的 IAM 角色和权限,请参阅访问权限控制。
在不同位置之间移动 BigQuery 数据
您无法在创建数据集后更改其位置,但可以创建数据集的副本。
配额政策
如需了解导出作业配额,请参阅“配额和限制”页面中的导出作业。
价格
导出 BigQuery ML 模型不收取任何费用,但导出操作受 BigQuery 配额和限制的约束。如需详细了解 BigQuery 价格,请参阅价格页面。
导出数据后,如果您将数据存储在 Cloud Storage 中,则需要为此付费。如需详细了解 Cloud Storage 价格,请参阅 Cloud Storage 价格页面。